








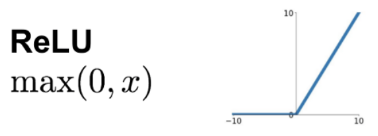

federica bianco PRO
astro | data science | data for good
dr.federica bianco | fbb.space | fedhere | fedhere
Neural Networks: CNNs
this slide deck:
0
NN are a vast topics and we only have 2 weeks!
Some FREE references!
michael nielsen
better pedagogical approach, more basic, more clear
ian goodfellow
mathematical approach, more advanced, unfinished
michael nielsen
better pedagogical approach, more basic, more clear
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
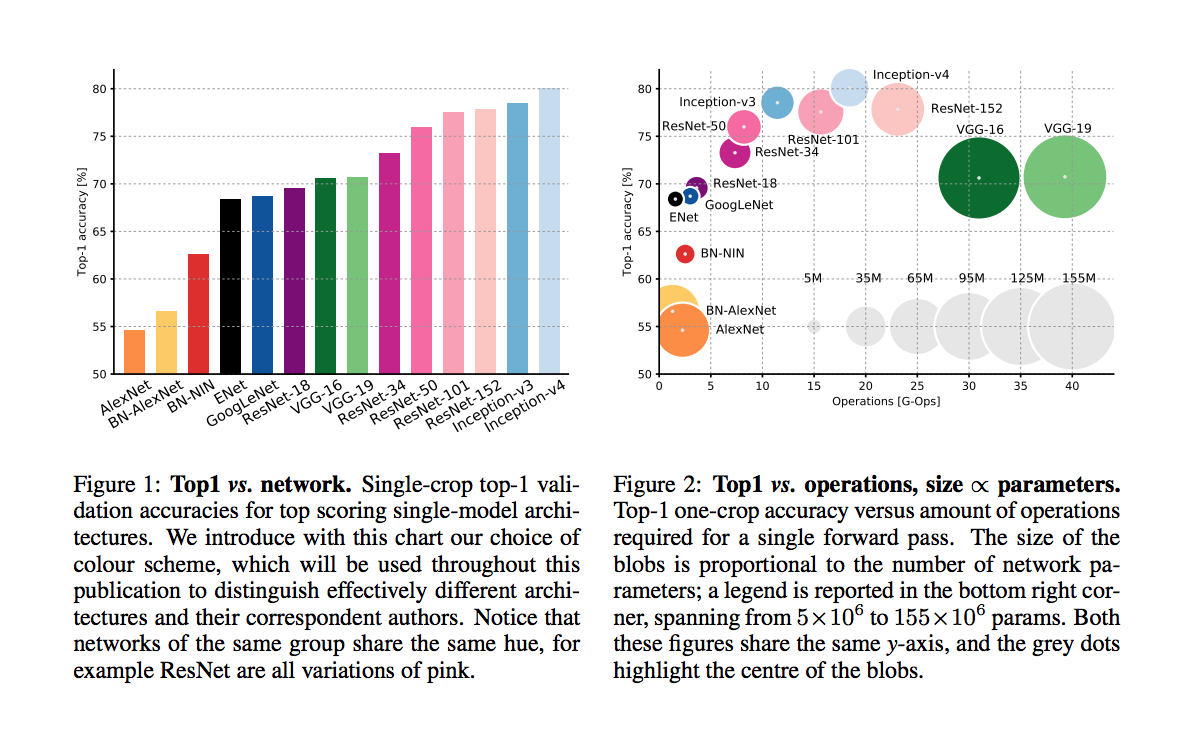
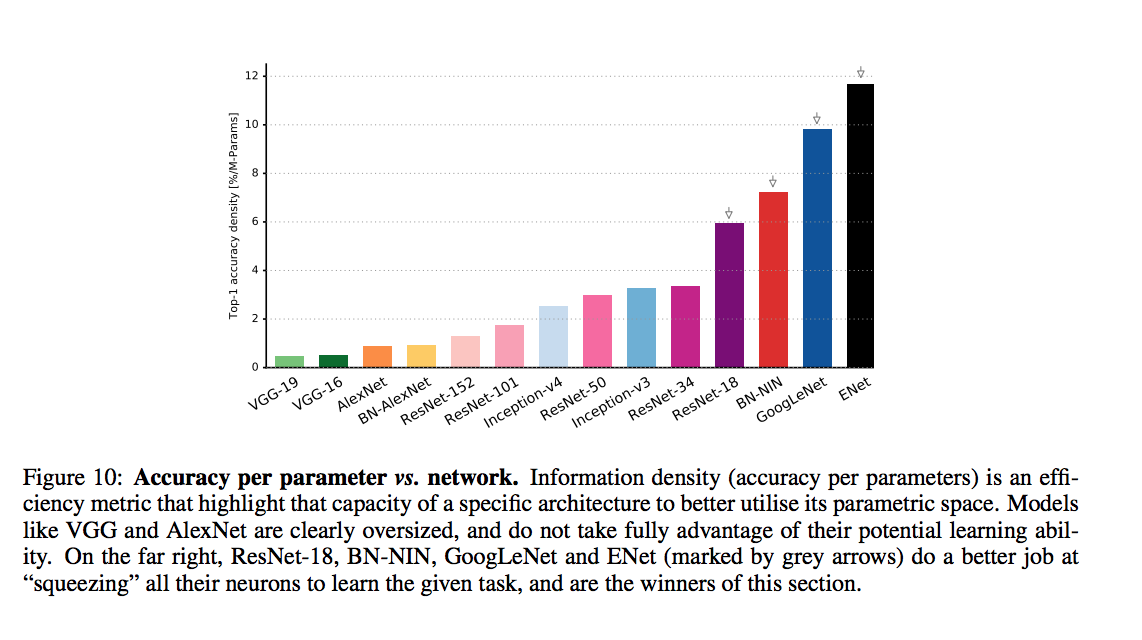
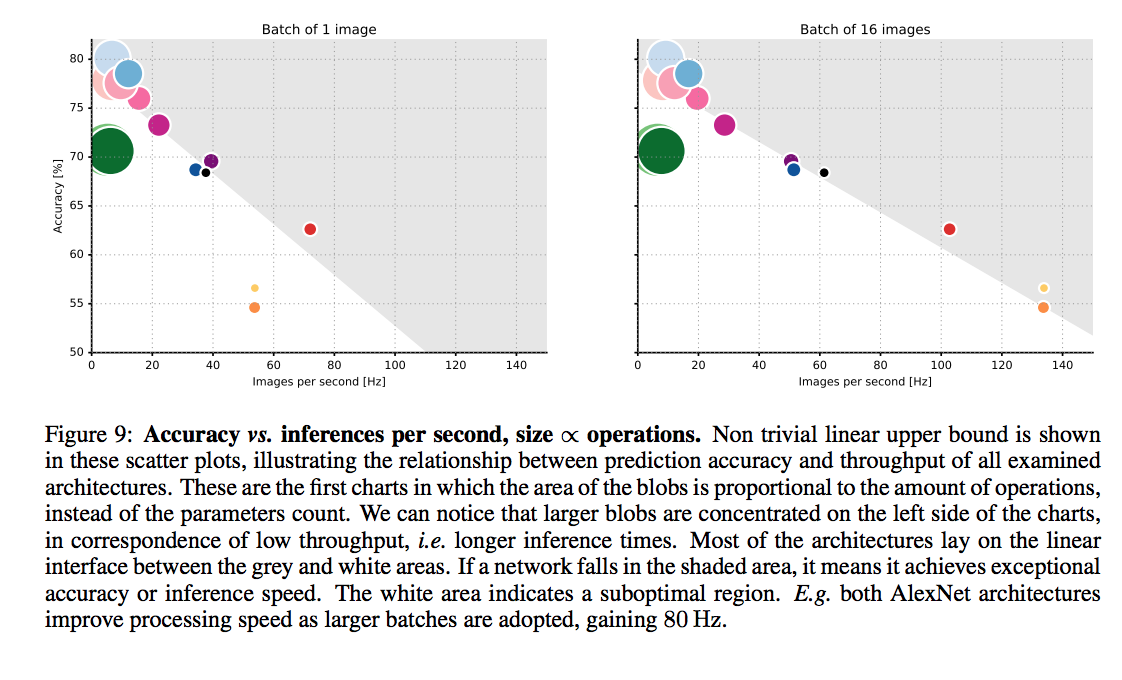
An article that compars various DNNs
An article that compars various DNNs
accuracy comparison
An article that compars various DNNs
accuracy comparison
An article that compars various DNNs
batch size
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
What should I choose for the loss function and how does that relate to the activation functiom and optimization?
Lots of parameters and lots of hyperparameters! What to choose?
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
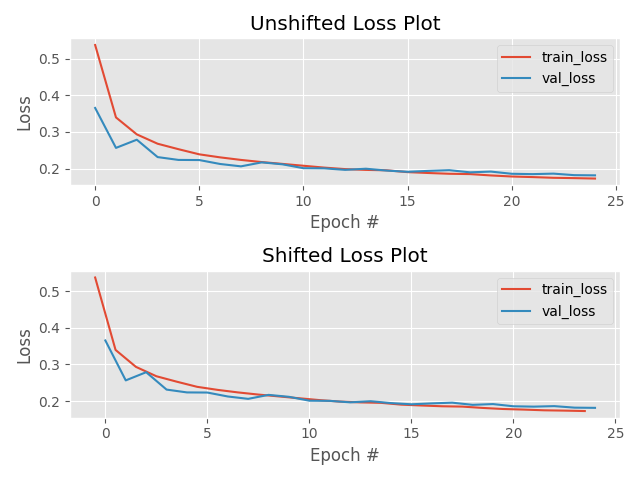
always check your loss function! it should go down smoothly and flatten out at the end of the training.
not flat? you are still learning!
too flat? you are overfitting...
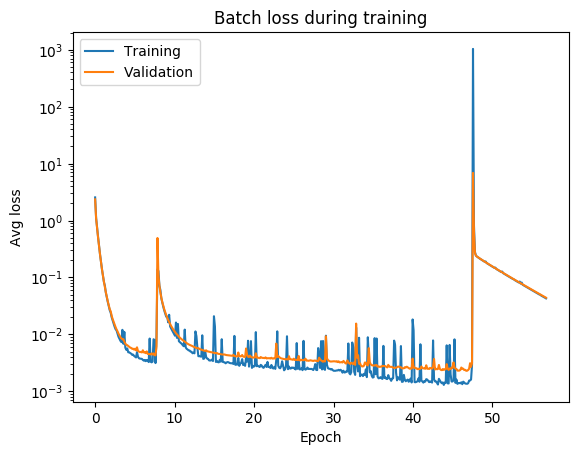
loss (gallery of horrors)
jumps are not unlikely (and not necessarily a problem) if your activations are discontinuous (e.g. relu)
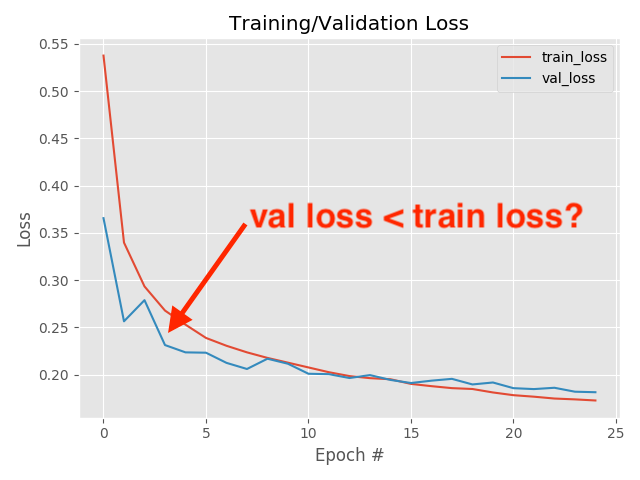
when you use validation you are introducing regularizations (e.g. dropout) so the loss can be smaller than for the training set
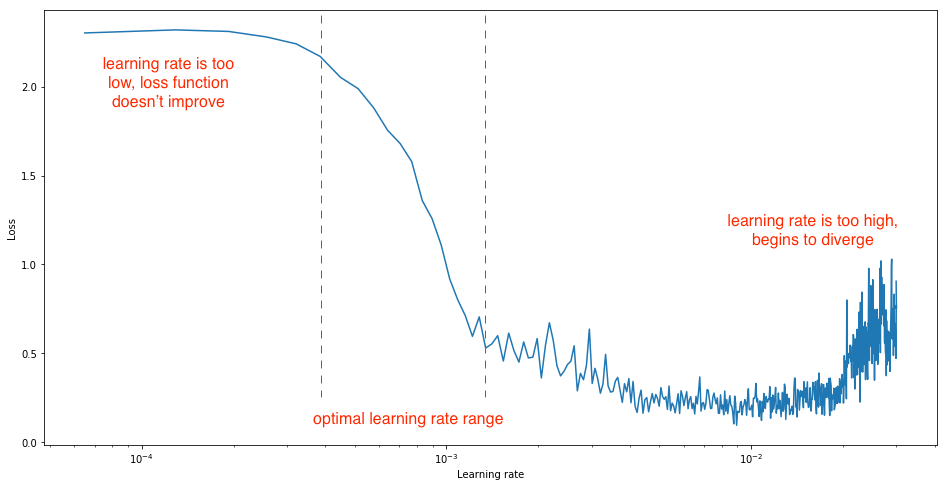
loss and learning rate (not that the appropriate learning rate depends on the chosen optimization scheme!)
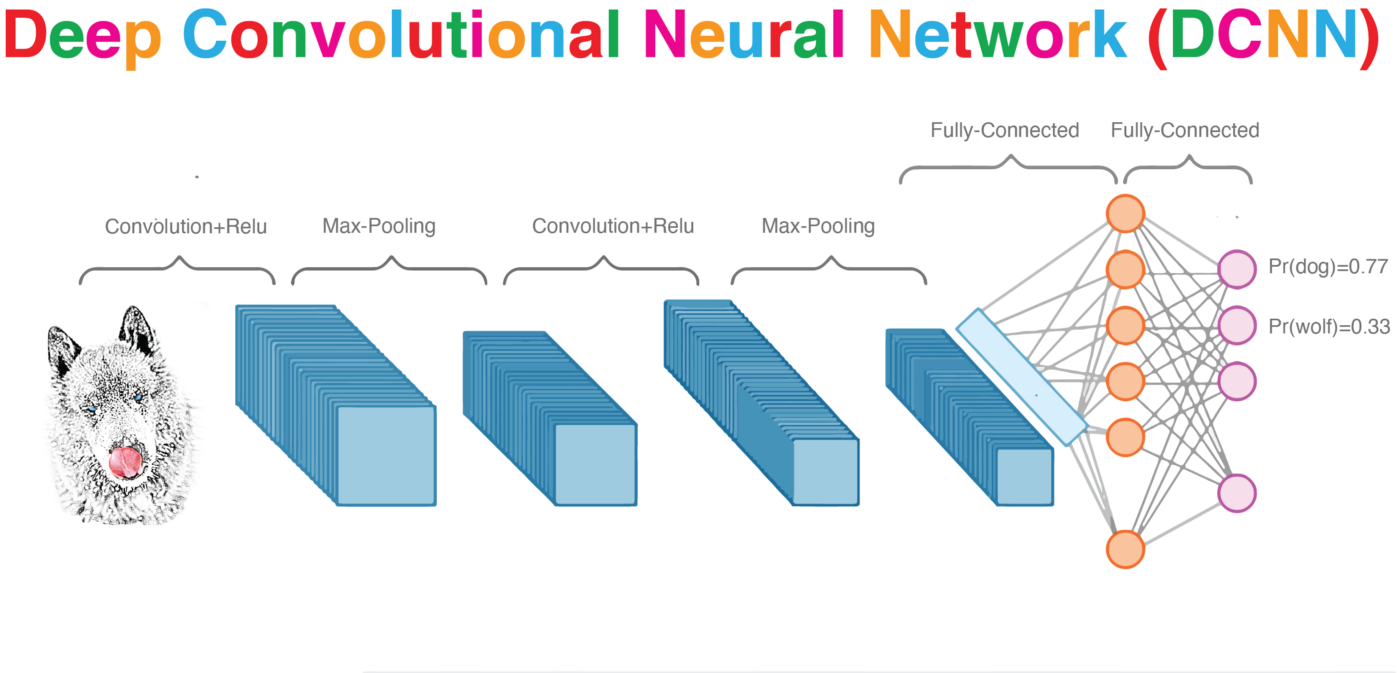
Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
What should I choose for the loss function and how does that relate to the activation functiom and optimization?
| loss | good for | activation last layer | size last layer |
|---|---|---|---|
| mean_squared_error | regression | linear | one node |
| mean_absolute_error | regression | linear | one node |
| mean_squared_logarithmit_error | regression | linear | one node |
| binary_crossentropy | binary classification | sigmoid | one node |
| categorical_crossentropy | multiclass classification | sigmoid | N nodes |
| Kullback_Divergence | multiclass classification, probabilistic inerpretation | sigmoid | N nodes |
On the interpretability of DNNs
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
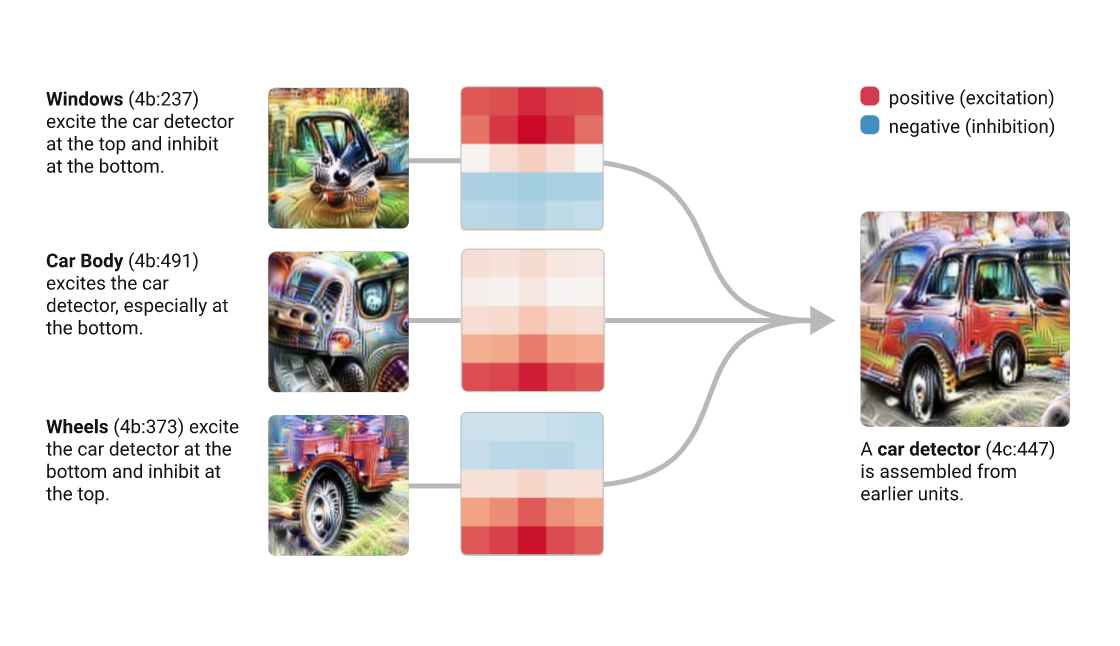
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
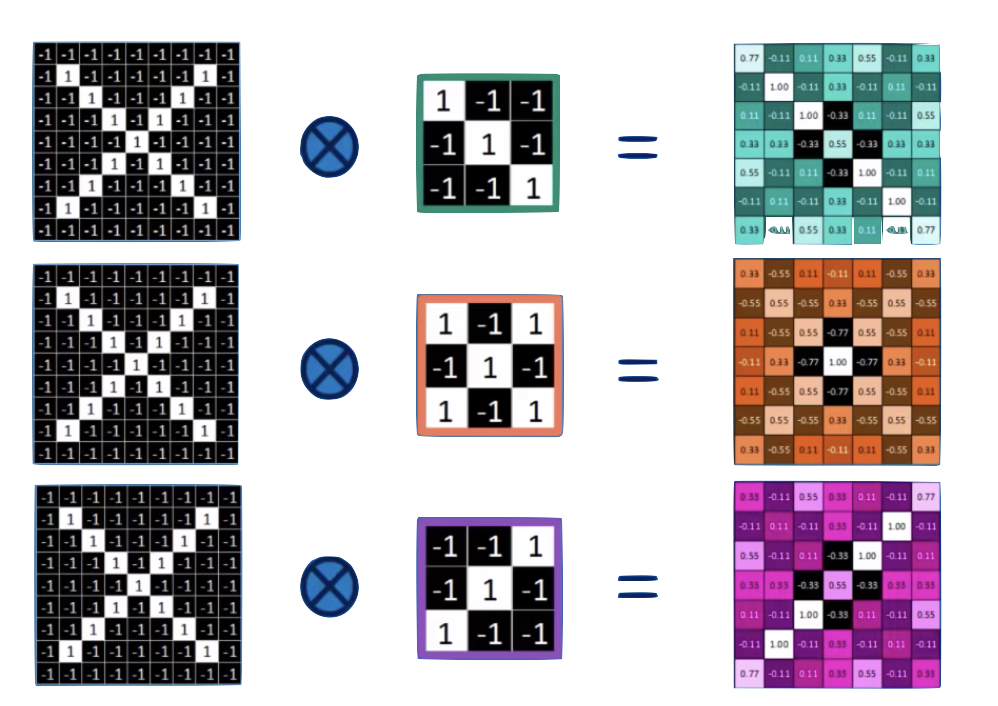
Convolution
convolution is a mathematical operator on two functions
f and g
that produces a third function
f x g
expressing how the shape of one is modified by the other.
o
two images.
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
1
1
1
1
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | -1 | -1 |
| -1 | -1 | -1 | -1 | -1 |
| -1 | -1 | -1 | -1 | -1 |
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| -1 | -1 | 1 |
| -1 | 1 | -1 |
| 1 | -1 | -1 |
feature maps
1
1
1
1
1
convolution
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | ||
|---|---|---|
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -3 | |
|---|---|---|
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -3 | 3 |
|---|---|---|
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -1 | 3 |
|---|---|---|
| ? | ||
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -1 | 3 |
|---|---|---|
| ? | ? | |
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -1 | 3 |
|---|---|---|
| ? | ? | |
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -3 | 3 |
| -3 | 5 | -3 |
| 3 | -1 | 7 |
=
input layer
feature map
convolution layer
the feature map is "richer": we went from binary to R
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -3 | 3 |
| -3 | 5 | -3 |
| 3 | -1 | 7 |
=
input layer
feature map
convolution layer
the feature map is "richer": we went from binary to R
and it is reminiscent of the original layer
7
5
7
Convolve with different feature: each neuron is 1 feature
| 7 | -3 | 3 |
| -3 | 5 | -3 |
| 3 | -1 | 7 |
7
5
7
ReLu: normalization that replaces negative values with 0's
| 7 | 0 | 3 |
| 0 | 5 | 0 |
| 3 | 0 | 7 |
7
5
7
Max-Pool
MaxPooling: reduce image size, generalizes result
| 7 | 0 | 3 |
| 0 | 5 | 0 |
| 0 | 0 | 7 |
7
5
7
MaxPooling: reduce image size, generalizes result
| 7 | 0 | 3 |
| 0 | 5 | 0 |
| 3 | 0 | 7 |
7
5
7
2x2 Max Poll
| 7 | 5 |
MaxPooling: reduce image size, generalizes result
| 7 | 0 | 3 |
| 0 | 5 | 0 |
| 3 | 0 | 7 |
7
5
7
2x2 Max Poll
| 7 | 5 |
| 5 |
MaxPooling: reduce image size, generalizes result
| 7 | 0 | 3 |
| 0 | 5 | 0 |
| 3 | 0 | 7 |
7
5
7
2x2 Max Poll
| 7 | 5 |
| 5 | 7 |
MaxPooling: reduce image size & generalizes result
By reducing the size and picking the maximum of a sub-region we make the network less sensitive to specific details
Deep Neural Net are not some fancy-pants methods, they are just linear models with a bunch of parameters
Because they have many parameters they are difficult to "interpret" (no easy feature extraction)
tha is ok becayse they are prediction machines
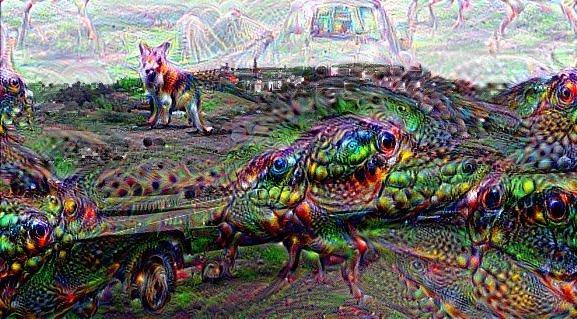
Deep Dream (DD) is a google software, a pre-trained NN (originally created on the Cafe architecture, now imported on many other platforms including tensorflow).
The high level idea relies on training a convolutional NN to recognize common objects, e.g. dogs, cats, cars, in images. As the network learns to recognize those objects is developes its layers to pick out "features" of the NN, like lines at a cetrain orientations, circles, etc.
The DD software runs this NN on an image you give it, and it loops on some layers, thus "manifesting" the things it knows how to recognize in the image.
@akumadog
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
Neural Network and Deep Learning
an excellent and free book on NN and DL
http://neuralnetworksanddeeplearning.com/index.html
Deep Learning An MIT Press book in preparation
Ian Goodfellow, Yoshua Bengio and Aaron Courville
https://www.deeplearningbook.org/lecture_slides.html
History of NN
https://cs.stanford.edu/people/eroberts/courses/soco/projects/neural-networks/History/history2.html
By federica bianco
CNNs




