From dozens to thousands:
important lessons when scaling up
structural MRI processing
using CAT
Felix Hoffstaedter
Systems Medicine
Institute of Neuroscience and Medicine
Brain and Behaviour (INM-7)
Forschungszentrum Jülich
Institute of Systems Neuroscience
Heinrich-Heine University Düsseldorf
Germany

Acknowledgments:

DataLad Team &
Contributors

Christian Gaser &
Robert Dahnke

-
Voxel-Based Morphometry -
Computational Anatomy Toolbox -
Why Large Scale Neuroscience? -
Reproducible Data Processing -
What's DataLad anyway -
The FAIRly Big Workflow: Bootstrap-Execute-Consolidate
-
Important lessons
The Plan
Bootstrapping FAIRly Big
Set up FAIRly Big Workflow in Linux
https://jugit.fz-juelich.de/f.hoffstaedter/lsn_cat12/
- Install & setup DataLad (0.16.3)
- get OSF account & datalad-OSF extension
EXECUTE the following to create and publish the Workflow dataset:
# clone Repo wit Workflow bootstrap scripts and build workflow
git clone git@jugit.fz-juelich.de:f.hoffstaedter/lsn_cat12.git
./lsn_cat12/LSN_Tutorial_bootstrap_CAT-MCR_AOMIC-PIOP2.sh
# start processing of 3 subjects in parallel
cd AOMIC-PIOP2_LSN_cat12.8/; ./code/process.sub sub-0001 &
./code/process.sub sub-0012 &; ./code/process.sub sub-0123;
# consolidate results and publish dataset to OSF
./code/results.merger
datalad get *
datalad create-sibling-osf --title LSN_Tutorial_CAT-MCR_AOMIC-PIOP2 -s osf
datalad push --to osfBootstrapping FAIRly Big
Set up FAIRly Big Workflow on Mac
https://jugit.fz-juelich.de/f.hoffstaedter/lsn_cat12/
- Install & setup DataLad (0.16.3)
- Install MCR_R2017b in ../[workflowDIR]/MCR/v93
- get OSF account & datalad-OSF extension
EXECUTE the following to create and publish the Workflow dataset:
# clone Repo wit Workflow bootstrap scripts and build workflow
git clone git@jugit.fz-juelich.de:f.hoffstaedter/lsn_cat12.git
./lsn_cat12/LSN_Tutorial_bootstrap_CAT-MCR_AOMIC-PIOP2_mac.sh
# start processing of 3 subjects in parallel
cd AOMIC-PIOP2_LSN_cat12.8/; ./code/process.sub sub-0001 &
./code/process.sub sub-0012 &; ./code/process.sub sub-0123;
# consolidate results and publish dataset to OSF
./code/results.merger; datalad get *
datalad create-sibling-osf --title LSN_Tutorial_CAT-MCR_AOMIC-PIOP2 -s osf
datalad push --to osf-
when you shouldn't look at all datasets (n>=200) -
when frequent reprocessing is not desirable
-
when the data is growing in size over time
-
when the data is used in other projects
-
when you actually want to share data & results
What is a large scale analysis?

Data

Results

Pipeline
DATA PROCESSING

Code
Data
Results
Pipeline
DATA PROCESSING
Code
- archived -
- archived -
Infrastructure
- changed -
I'll find the scripts,
give me a minute ...
Data
Results
Pipeline
Reproducible DATA PROCESSING
Code
- archived -
- archived -

Containerization


Singularity






Upload your Code
share data
Data
Results
Pipeline
DATA PROCESSING
Code


Data
Results
Pipeline
DATA PROCESSING
Code

tracking changes in any set of files
Data
Results
Pipeline
DATA PROCESSING
Code

Data


Containerized
Code
* Clone everything *
* everywhere *
* without *
* Data *
* content *
DATA PROCESSING
Data
Code
* quick'n'dirty *
Matlab Compiler Runtime

Tutorial
# project name space SAMPLE to be processed
PROJECT="LSN_cat12.8"
SAMPLE="AOMIC-PIOP2"
CWD=$(pwd) # get current work dir
### define the input RIA-store only to clone from
input_store="ria+file://${CWD}/inputstore"
### define the output RIA-store to push all results to
output_store="ria+file://${CWD}/dataladstore"
### define the location of the store all analysis inputs will be obtained from
raw_store="https://github.com/OpenNeuroDatasets/ds002790.git"
### define the container store -- container_store="XXX"
### define the temporary working directory to clone and process each subject on
temporary_store=/tmp
input_store: empty Workflow to clone from
output_store: storage to push Results to
raw_store: get raw Data from
container_store:
Bootstrap FAIRly Big Workflow
datalad create -c yoda AOMIC-PIOP2_LSN_cat12.8
cd AOMIC-PIOP2_LSN_cat12.8Bootstrap FAIRly Big Workflow
CAT="CAT12.8.1_r1980_R2017b_MCR_Linux"
SPM="http://www.neuro.uni-jena.de/cat12"
datalad run -m "download ${CAT} standalone version for Linux" \
"wget ${SPM}/${CAT}.zip; unzip -d code ${CAT}.zip; rm -f ${CAT}.zip;"


.
├── .gitattributes
├── CHANGELOG.md
├── code
│ ├── .gitattributes
│ └── README.md
└── README.md
datalad clone -d . ${raw_store} inputs/${SAMPLE}
git commit --amend -m "Register ${SAMPLE} BIDS dataset as input"
Bootstrap FAIRly Big Workflow
datalad create-sibling-ria -s ${PROJECT}_in "${input_store}" --new-store-ok
datalad create-sibling-ria -s ${PROJECT}_out "${output_store}" --new-store-okBootstrap FAIRly Big Workflow
input_store
output_store
# the actual compute job specification
cat > code/participant_job << EOT
#!/bin/bash
...
EOT
chmod +x code/participant_job
datalad save -m "Participant compute job implementation"
Bootstrap FAIRly Big Workflow
cat > code/process.sub << EOT
#!/bin/bash
# the job expects these environment variables for labeling and synchronization
...
EOT
chmod +x code/process.sub
datalad save -m "individual job submission"
# the logfiles folder is to be ignored by git
mkdir logs
echo logs >> .gitignore
cat > code/process.condor_submit << EOT
universe = vanilla
# resource requirements for each job
request_cpus = 1
request_memory = 4G
request_disk = 5G
# tell condor that a job is self contained and the executable
# is enough to bootstrap the computation on the execute node
...
Bootstrap FAIRly Big Workflow
cat > code/process.sbatch << EOT
#!/bin/bash -x
#SBATCH --account=runthings
#SBATCH --time=24:00:00
#SBATCH --job-name=FAIRlyBig
...


Bootstrap FAIRly Big Workflow
git remote -vLSN_cat12.8_in /home/DATA/inputstore/147/7683f-18a7-4c59-9e90-b1027865d0a2 (fetch)
LSN_cat12.8_in /home/DATA/inputstore/147/7683f-18a7-4c59-9e90-b1027865d0a2 (push)
LSN_cat12.8_in-storage
LSN_cat12.8_out /home/DATA/dataladstore/147/7683f-18a7-4c59-9e90-b1027865d0a2 (fetch)
LSN_cat12.8_out /home/DATA/dataladstore/147/7683f-18a7-4c59-9e90-b1027865d0a2 (push)
LSN_cat12.8_out-storage
AOMIC-PIOP2_LSN_cat12.8
├── CHANGELOG.md
├── code
│ ├── CAT12.8.1_r1980_R2017b_MCR_Linux
│ ├── cat_standalone_segment_enigmaTEST.m
│ ├── finalize_job_outputs_ENIGMA.sh
│ ├── participant_job
│ ├── process.condor_dag
│ ├── process.condor_submit
│ ├── process.sub
│ ├── README.md
│ └── results.merger
├── inputs
│ └── AOMIC-PIOP2
├── logs
└── README.md

Execute FAIRly Big Workflow
input_store
output_store
temporal workdir
git merge -m "Merge results" $(git branch -al | grep 'job-' | tr -d ' ')
# clean git annex branch
git annex fsck -f LSN_cat12.8_out-storage
# declare local data clone as dead
git annex dead here
# datalad push merged results
datalad push --data nothing --to LSN_cat12.8_out
Consolidate FAIRly Big Workflow
output_store
- Merge results! 🐙
└── sub-0123
├── inforoi.tar.gz -> ../.git/annex/objects/4F/m9/MD5E-s584388--4adb0751878d8095a958b31a31589402.tar.gz/MD5E-s584388--4adb0751878d8095a958b31a31589402.tar.gz
├── native.tar.gz -> ../.git/annex/objects/J9/G7/MD5E-s12808637--50f4a108e3ff1d20fbb4b9101f57462e.tar.gz/MD5E-s12808637--50f4a108e3ff1d20fbb4b9101f57462e.tar.gz
├── surface.tar.gz -> ../.git/annex/objects/4g/x0/MD5E-s45--0791f35d8dde0bd16669b238b35eb389.tar.gz/MD5E-s45--0791f35d8dde0bd16669b238b35eb389.tar.gz
└── vbm.tar.gz -> ../.git/annex/objects/wk/gp/MD5E-s17103529--8108c63f231d80d7b7a034c26d70b8e4.tar.gz/MD5E-s17103529--8108c63f231d80d7b7a034c26d70b8e4.tar.gz
datalad clone osf://g2rmn LSN_CAT12.8_AOMIC-PIOP2
datalad clone osf://3w2zq LSN_CAT12.8_AOMIC-PIOP1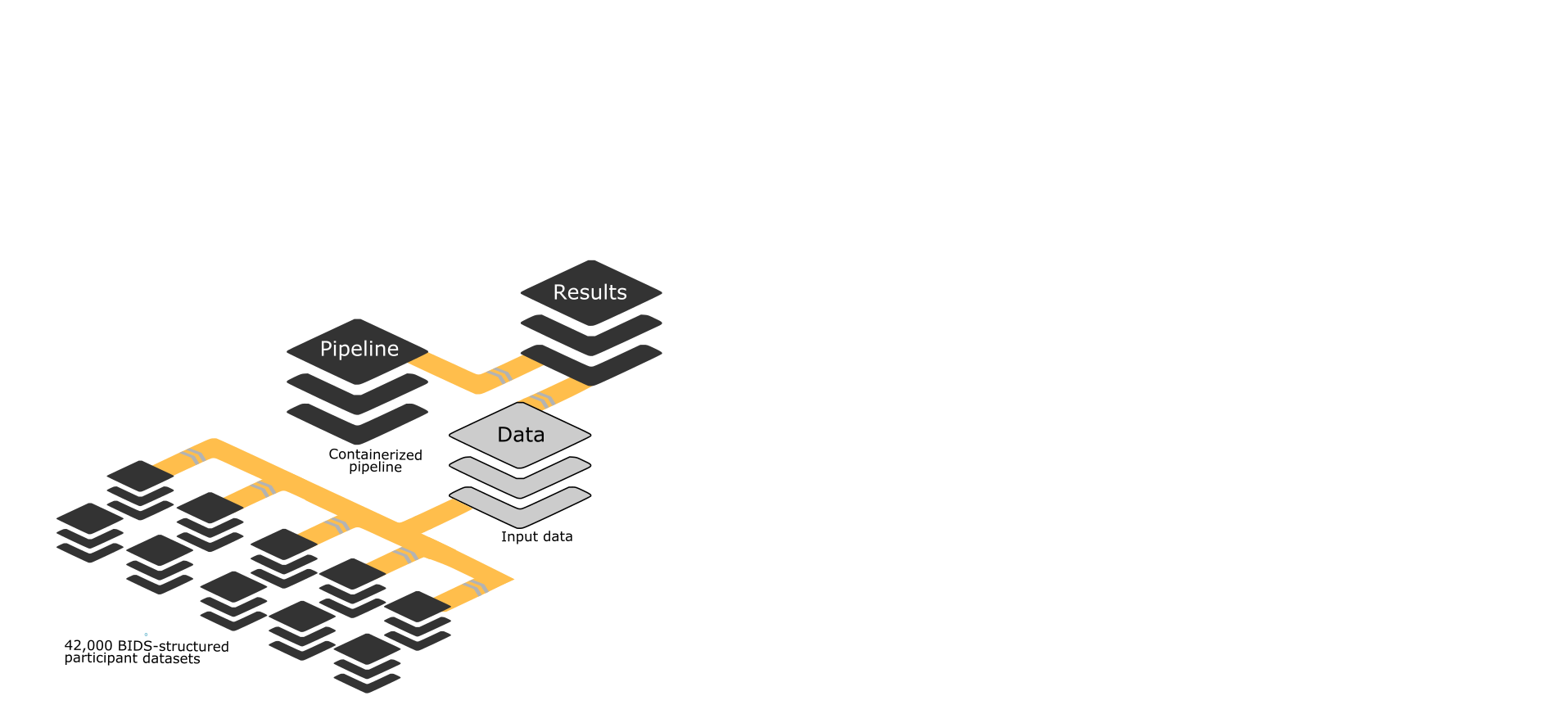
FAIRly Big Workflow
FAIRly Big Workflow
Text
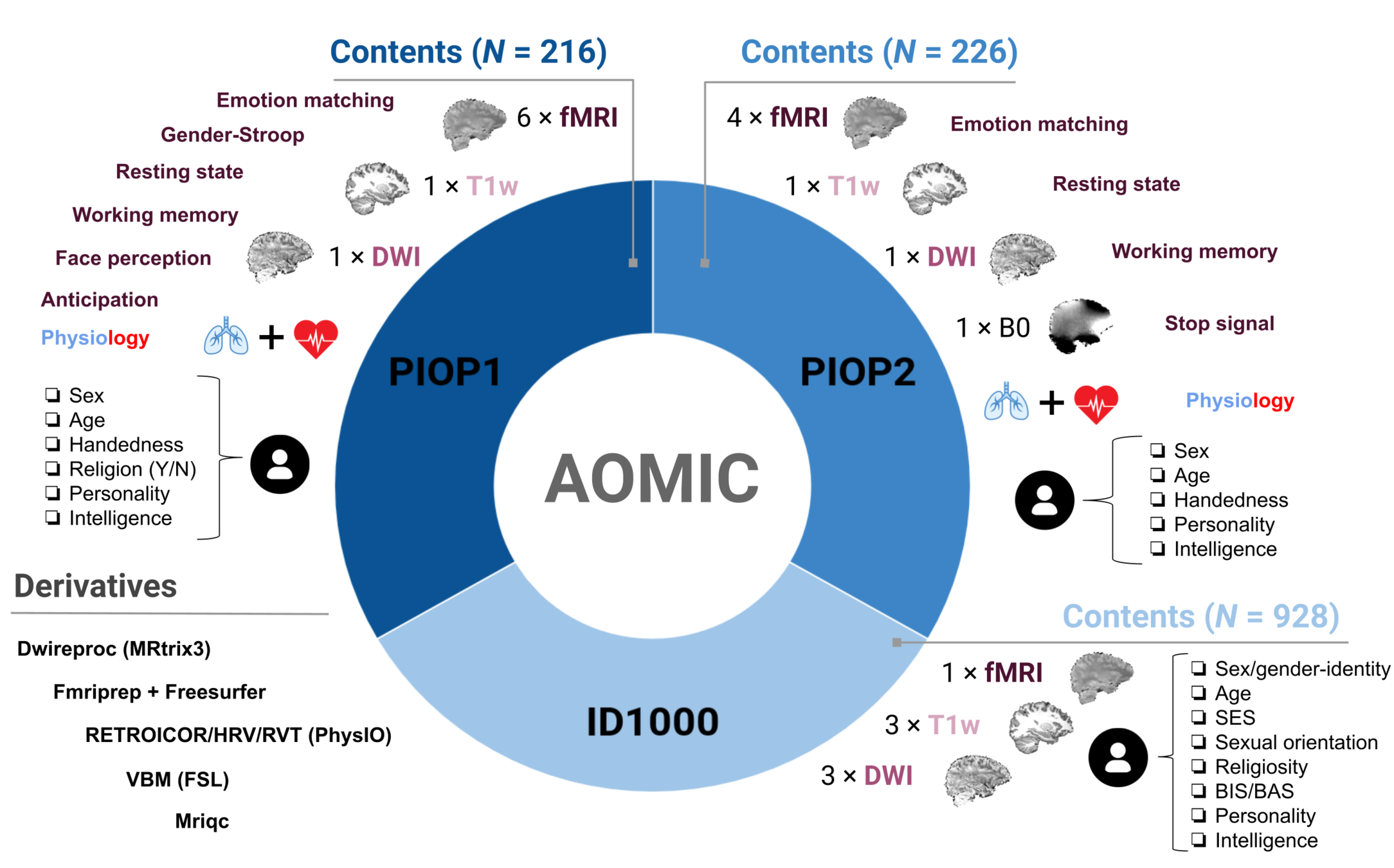
use case: large-scale medical data processing
- Tested on different computing infrastructures
- HPC system (inode limits) - JURECA | SLURM
- HTC system (storage limits) - Juseless | HTCondor
- Medical data under strict data usage constraints
- MATLAB-based software component - CAT
42,715 participants
76 TB of data
43 milion of files

What is FAIR?
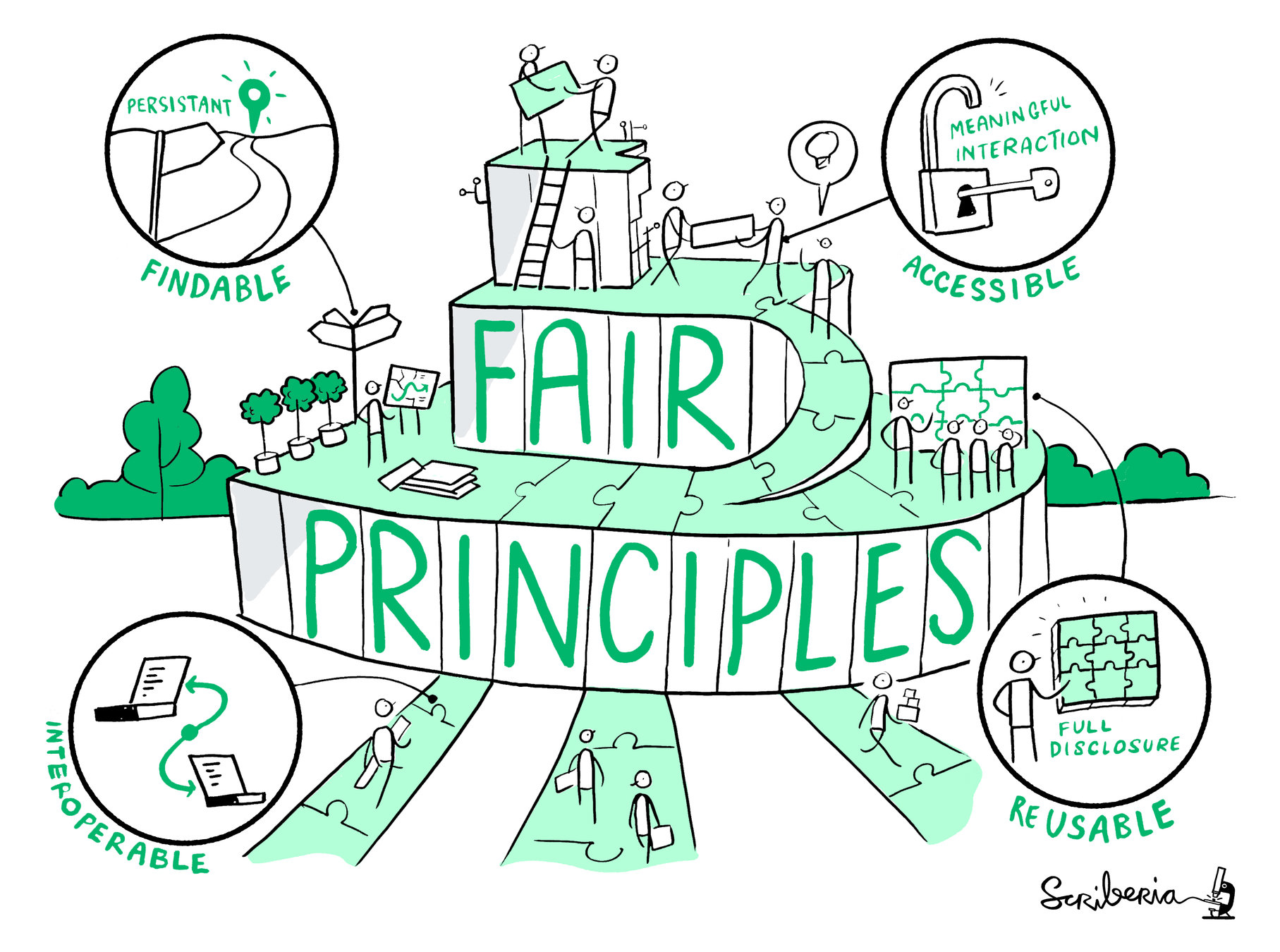
This image was created by Scriberia for The Turing Way community and is used under a CC-BY licence.
Wilkinson et al. (2016) The FAIR Guiding Principles for scientific data management and stewardship, Sci. Data, doi: 10.1038/sdata.2016.18
results consolidation
- Final consolidation of results! 🐙
Important lessons
- Code:
- Data:
- Processing issues: redo everything (really)
- Results: script QC, look at 5% max
- Statistics: redo QC fitting your method
framework SETUP


DataLad YouTube channel

From dozens to thousands: important lessons when scaling up structural MRI processing using CAT
By Felix Hoffstaedter




