Reproducible data processing
with Datalad: intro to
What // Why // How
Felix Hoffstaedter
Systems Medicine
Institute of Neuroscience and Medicine
Brain and Behaviour (INM-7)
Forschungszentrum Jülich
Institute of Systems Neuroscience
Heinrich-Heine University Düsseldorf
Germany

-
jonas.github.io/tig -
handbook.datalad.org -
container Software
Needed for trying out examples




Singularity
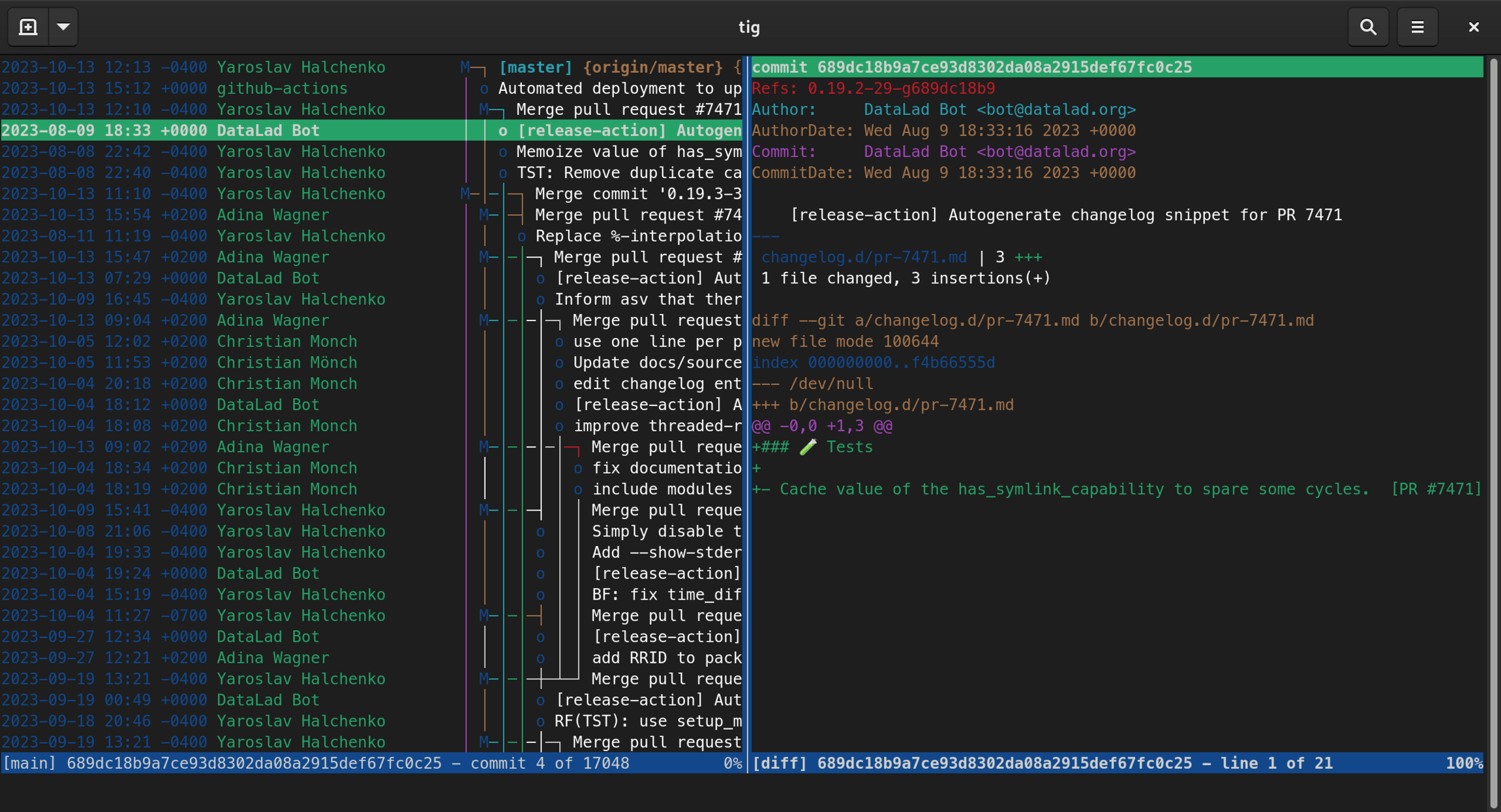




Data

Results

Pipeline
DATA PROCESSING

Code
Data
Results
Pipeline
DATA PROCESSING
Code
- archived -
- archived -
Infrastructure
- changed -
I'll find the scripts,
give me a minute ...
Data
Results
Pipeline
Reproducible DATA PROCESSING
Code
- archived -
- archived -

Containerization
Singularity





Upload your Code
share data

Data
Results
Pipeline
DATA PROCESSING
Code

tracking changes in any set of files
Data
Results
Pipeline
DATA PROCESSING
Code

Data


Containerized
Code
* Clone everything *
* everywhere *
* without *
* Data *
* content *
Reproducible DATA PROCESSING
Data
Results
Pipeline
DATA PROCESSING
Code
Why Datalad?
-
Seeing everything without carrying everything
- metadata without data content
-
Having different versions of the same data at once
- metadata versioning relating to same data
-
Data carries their own (git) history
- documentation is only as good as we make it
- Dataset nesting relates datasets (raw-derivatives)
Why Datalad?
-
Seeing everything without carrying everything
- metadata without data content
How?
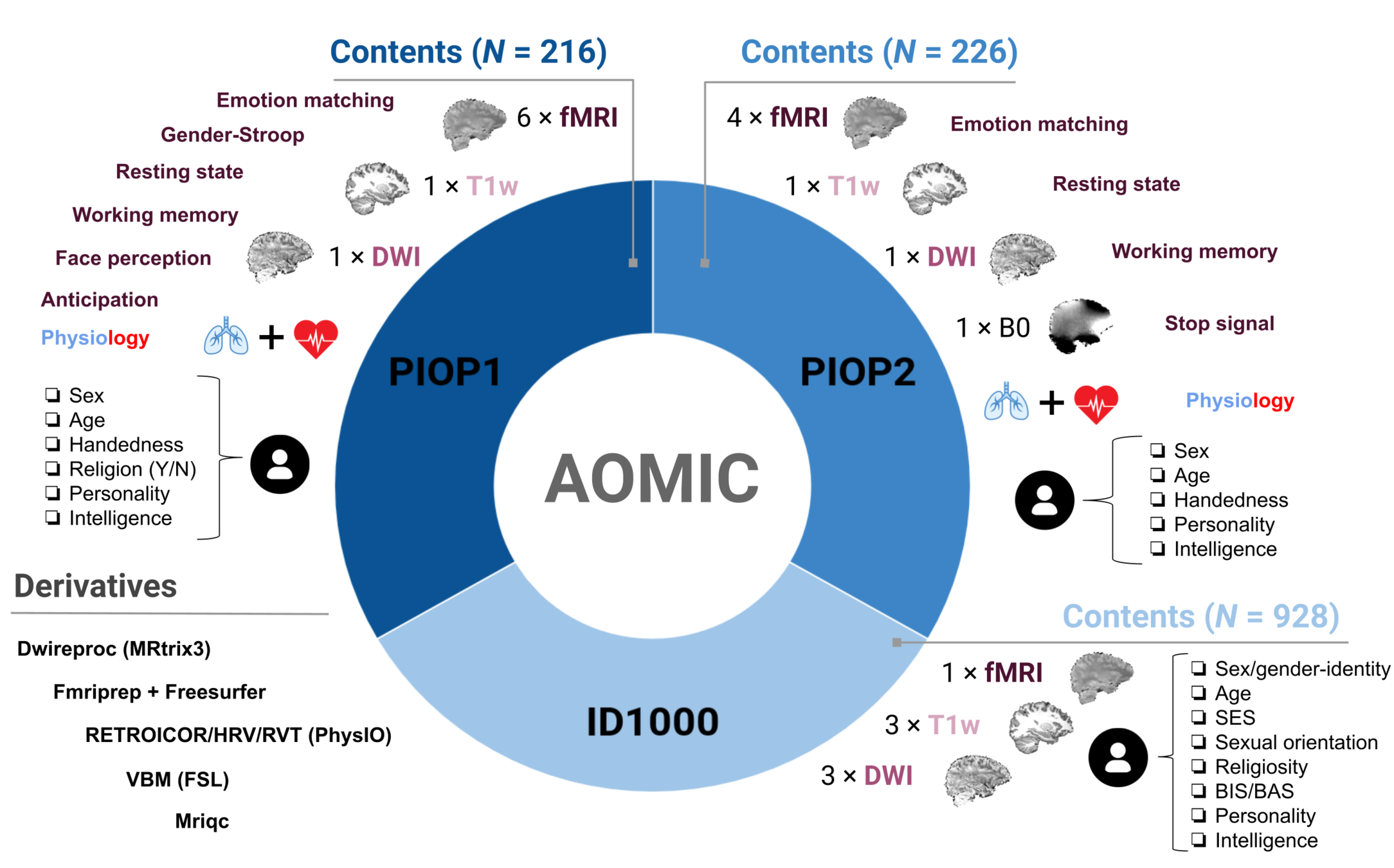
Why Datalad?
-
Seeing everything without carrying everything
- metadata without data content
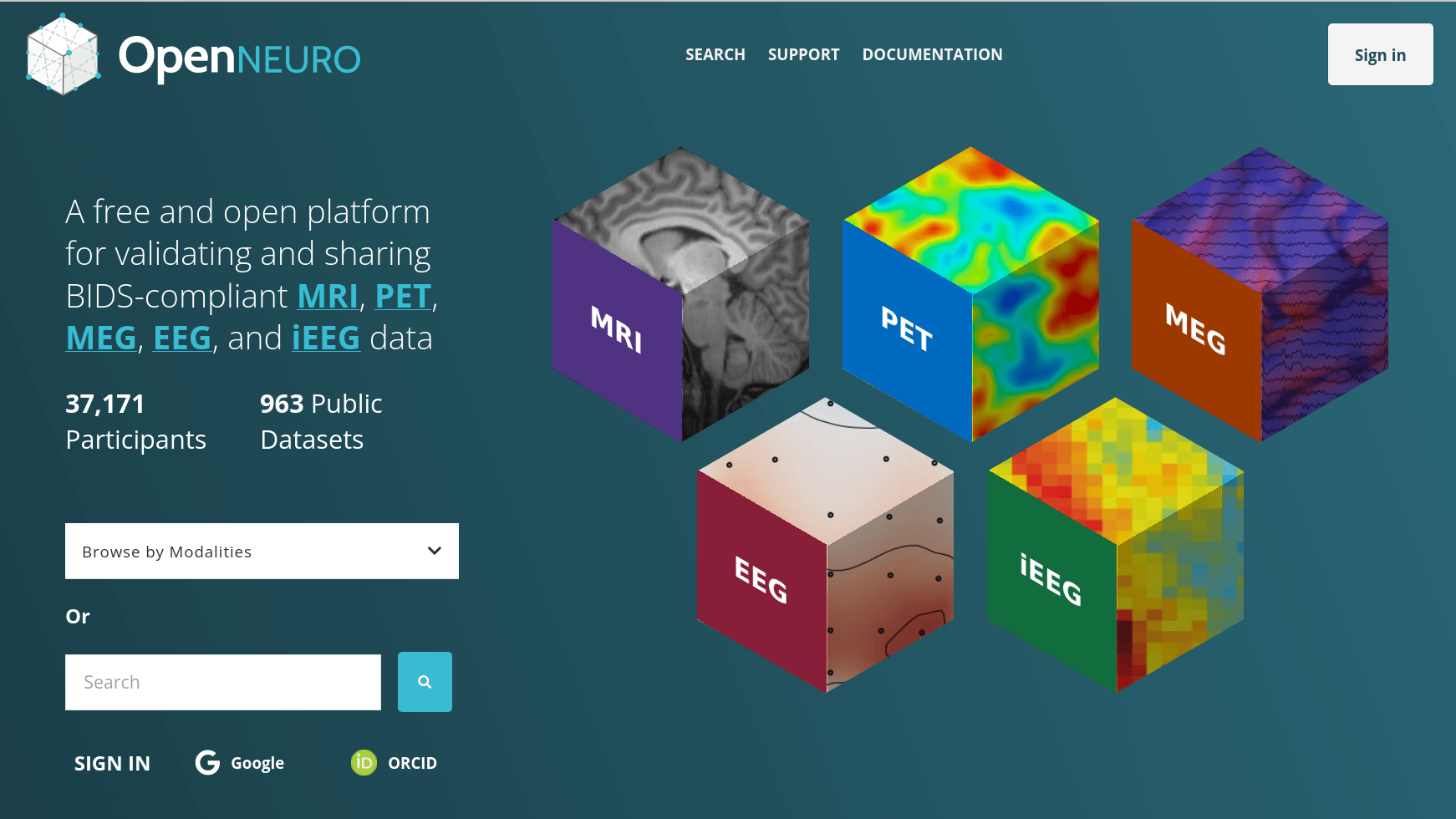
# get datalad.datasets
datalad install ///openneuro
cd ds003097
datalad get -n .
How?
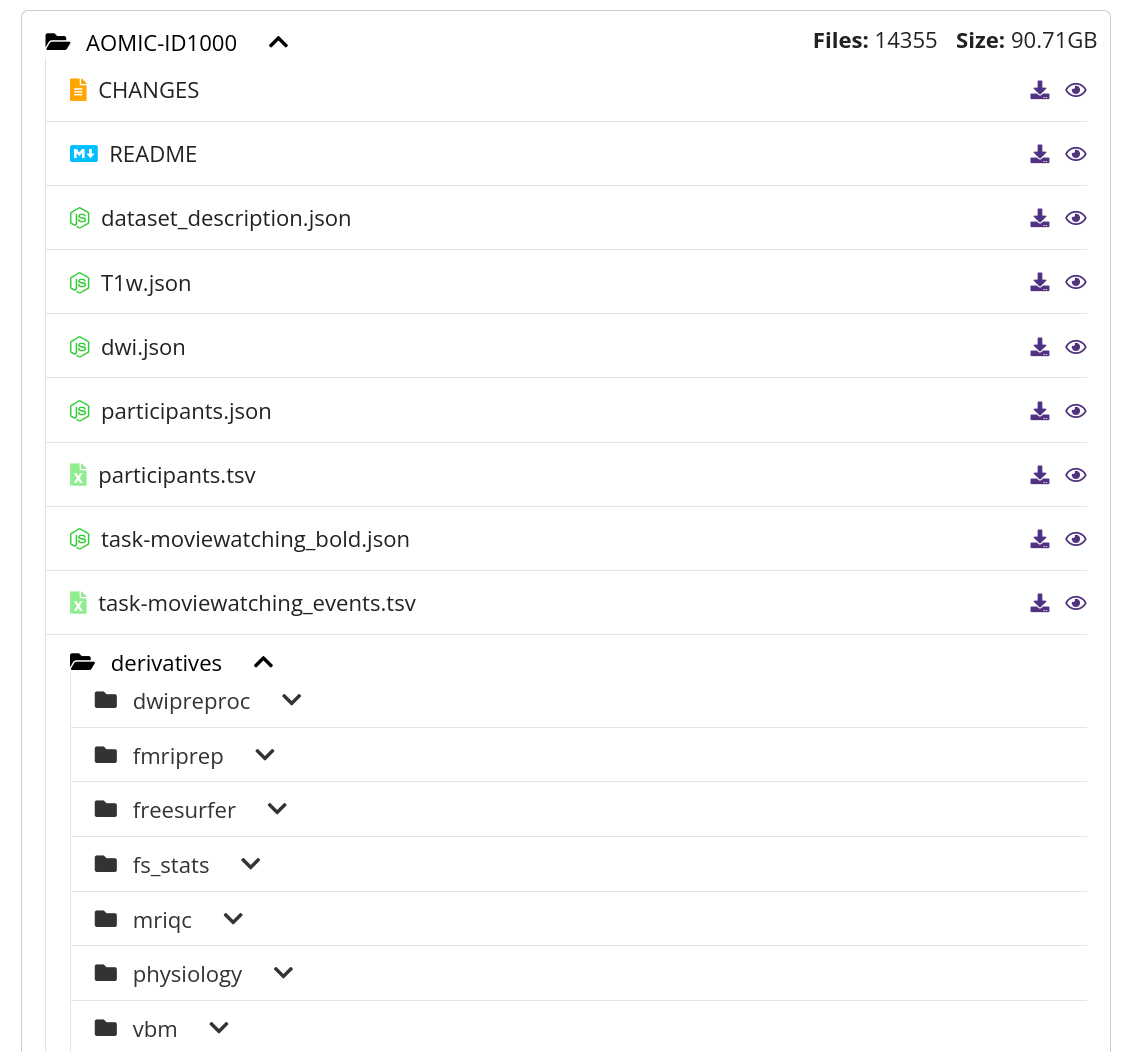
Why Datalad?
-
Seeing everything without carrying everything
- metadata without data content
-
Having different versions of the same data at once
- metadata versioning relating to same data
# let's BIDSify HCP data
datalad clone https://github.com/datalad-datasets/hcp-structural-preprocessed.git
cd hcp-structural-preprocessed
datalad run -m "BIDSify data" "./.bids_conversion/convert.sh"
Why Datalad?
-
Seeing everything without carrying everything
- metadata without data content
-
Having different versions of the same data at once
- metadata versioning relating to same data
-
Data carries their own (git) history
- documentation is only as good as we make it
- Dataset nesting relates datasets (raw-derivatives)

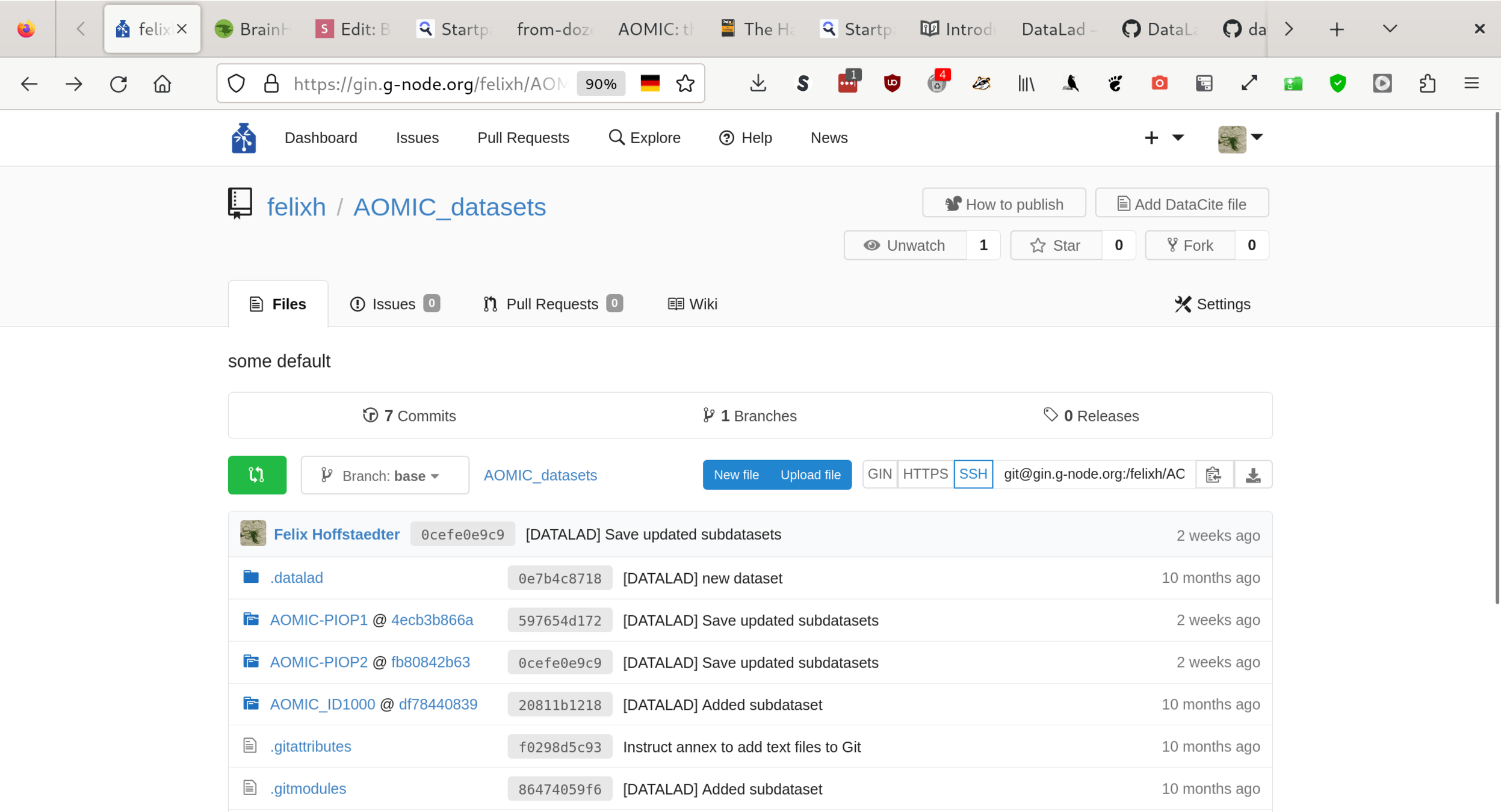
Why Datalad?
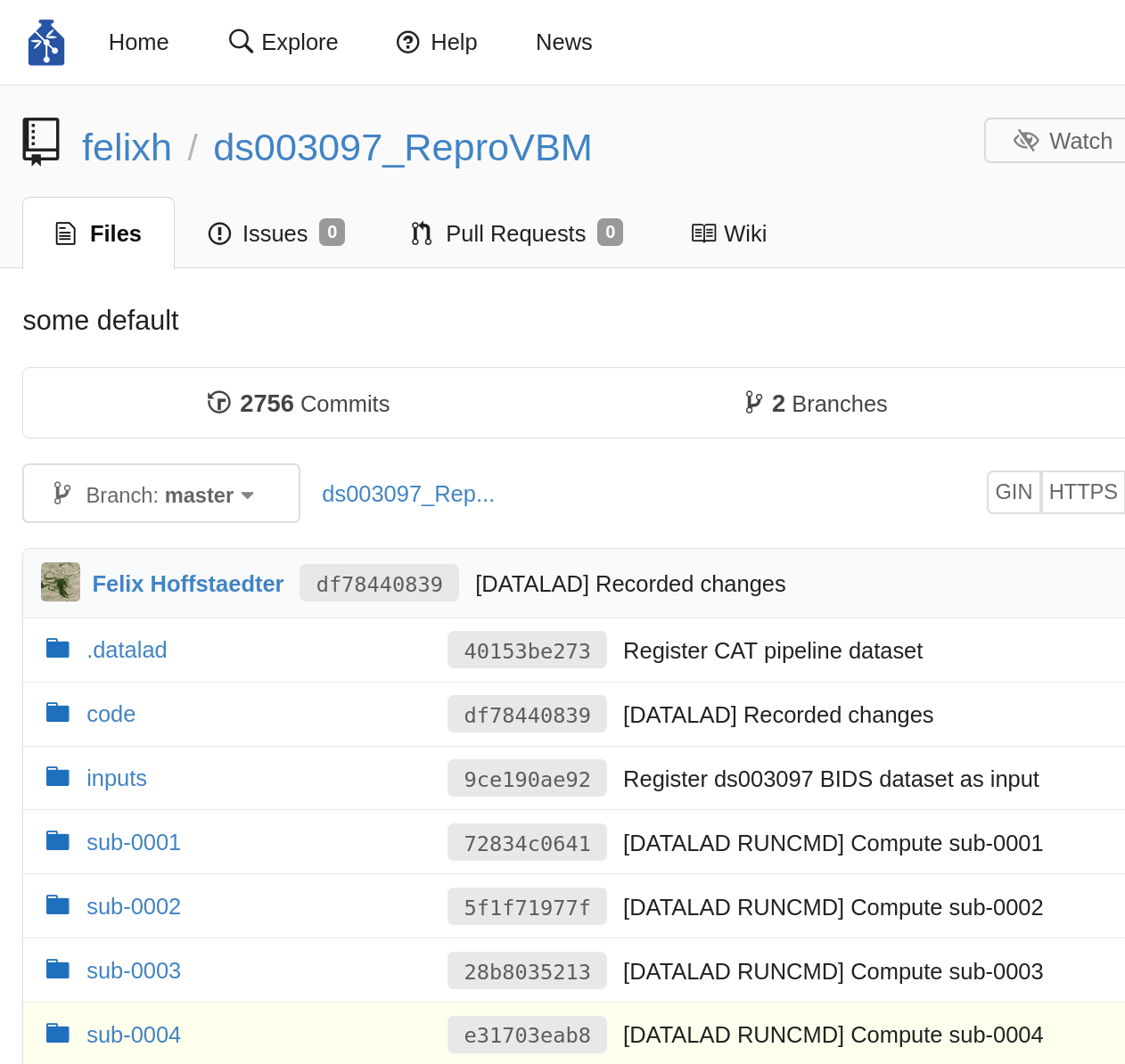
https://gin.g-node.org/

# let's get processed example data: VBM
datalad clone https://gin.g-node.org/felixh/AOMIC_datasets
datalad get -n AOMIC_ID1000
cd AOMIC_ID1000
datalad get sub-0111/report/catreportj_sub-0111_run-3_T1w.jpg
Why Datalad?
https://gin.g-node.org/
# let's get processed example data: VBM
datalad clone https://gin.g-node.org/felixh/AOMIC_datasets
datalad get -n AOMIC_ID1000
cd AOMIC_ID1000
datalad get sub-0111/report/catreportj_sub-0111_run-3_T1w.jpg
Important lessons
- Code:
- Data:
- Processing issues: redo everything (really)
- Results: script QC, look at 5% max
- Statistics: redo QC fitting your method
framework SETUP


DataLad YouTube channel
FAIRly Big Workflow

Text
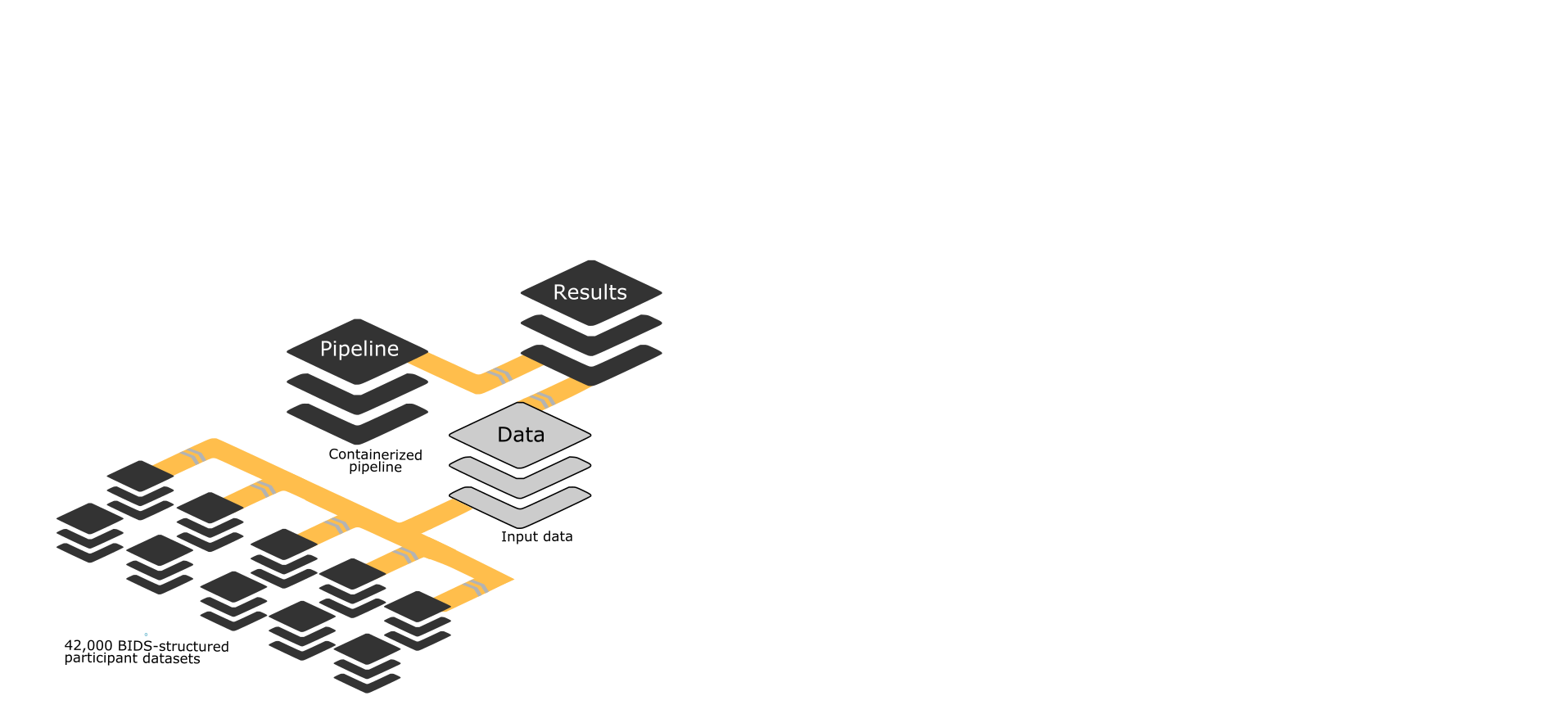
use case: large-scale medical data processing
- Tested on different computing infrastructures
- HPC system (inode limits) - JURECA | SLURM
- HTC system (storage limits) - Juseless | HTCondor
- Medical data under strict data usage constraints
- MATLAB-based software component - CAT
42,715 participants
76 TB of data
43 milion of files

What is FAIR?
This image was created by Scriberia for The Turing Way community and is used under a CC-BY licence.
Wilkinson et al. (2016) The FAIR Guiding Principles for scientific data management and stewardship, Sci. Data, doi: 10.1038/sdata.2016.18
results consolidation
- Final consolidation of results! 🐙
Reproducible data processing with Datalad
By Felix Hoffstaedter




