Proyecto Mineria de Datos
Fernando Moreno Gómez
Data set Adult
Barry Becker realizó la extracción de la base de datos del censo de 1994. Se extrajo un conjunto de registros razonablemente limpios utilizando las siguientes condiciones:
- edad > 16
- fnlwgt > 1
- horas por semana>0
Objetivo
Determinar si una persona gana más de 50 mil al año.
Analisis del data set
Porcentaje de salarios
La figura 1 muestra el porcentaje de personas que ganan <=50K y >50K
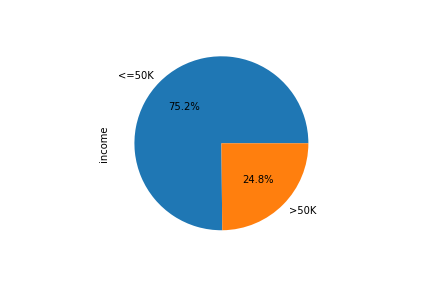
figura 1. Porcentaje de salarios del data set
Porcentaje de salario
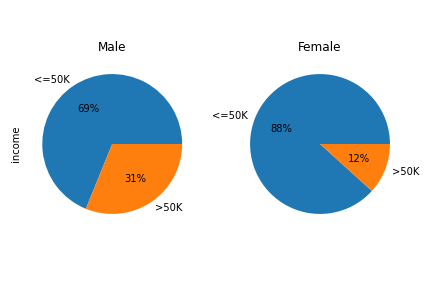
Figura 2. Porcentaje de salario por sexo.
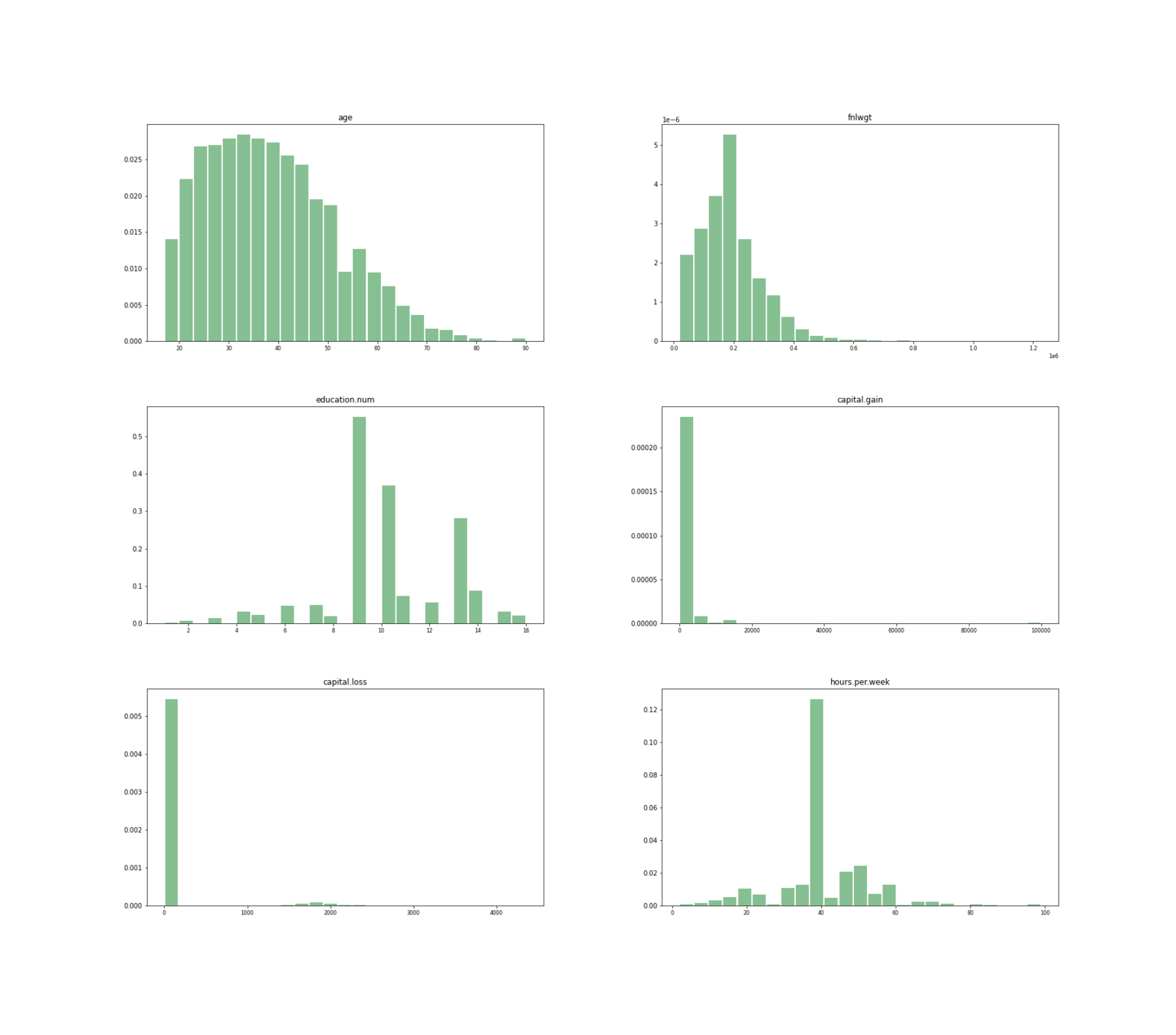
Distribución de edad, fnlwgt, educación, ganancia, perdida y hrs por semana.
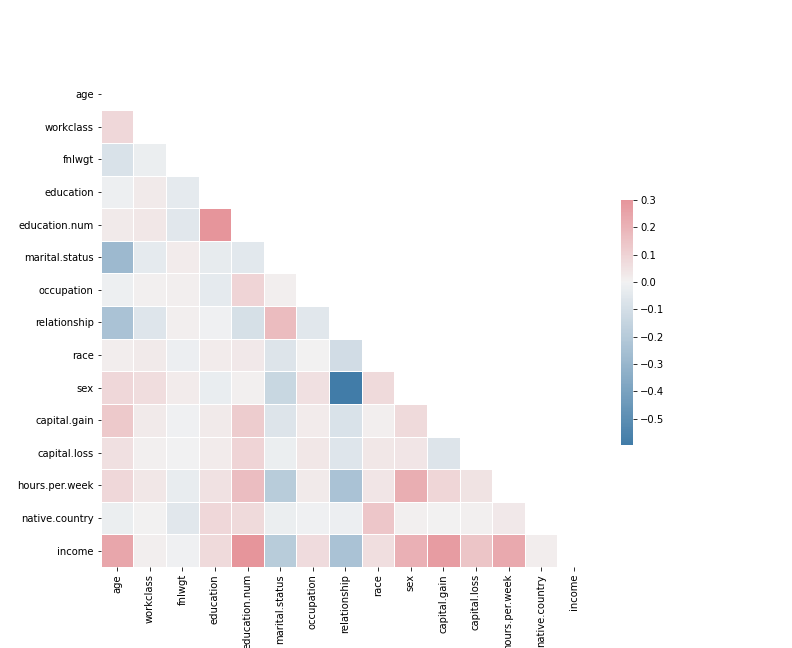
Matriz de correlación
Análisis de anomalias
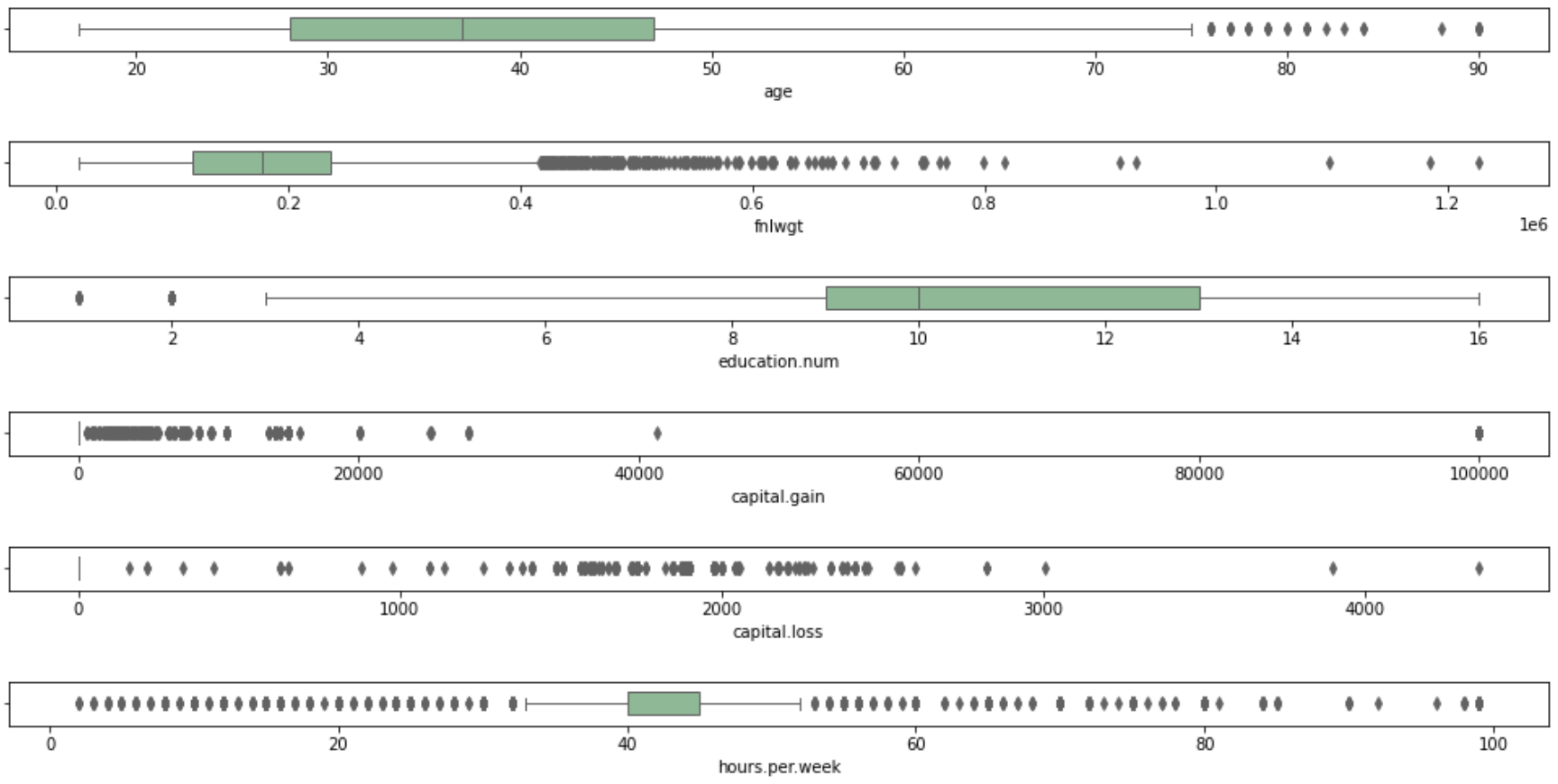
El paso más importante
Disminuir la cantidad de categorías por columna
categorias={'workclass':{'gov':['State-gov','Local-gov','Federal-gov']},
'education':{'pre-college':['5th-6th','11th','10th','1st-4th',
'12th','7th-8th','9th','Preschool'],
'assoc':['Assoc-acdm','Assoc-voc'],
'HS-grad':['Doctorate','HS-grad','Masters']},
'marital.status':{'single':['Never-married','Divorced','Widowed',
'Married-spouse-absent', 'Separated']},
'occupation':{'other':['Other-service','Priv-house-serv']},
'native.country':{'countrys':nc}}def preprocesamiento(df):
df['capital.gain'] = df['capital.gain'].apply(lambda x: np.log(x + 1))
df['capital.loss'] = df['capital.loss'].apply(lambda x: np.log(x + 1))
colC = (df.describe(include=np.object).columns)
columnsC = colC.tolist()
for c in columnsC:
df[c] = df[c].astype('category')
df[c] = df[c].cat.codes
if len(list(df.keys()))>12:
income_raw = df['income']
income = income_raw.apply(lambda x: 1 if x == 1 else 0)
df['income'] = income
return df¿Qué algoritmos utilizamos?
- Árbol de decisión
- Adaboost
def treeModel(df):
X= df.drop('income', axis=1)
y = df['income']
oversample = SMOTE()
X, y = oversample.fit_resample(X, y)
Xtrain, Xtest, ytrain, ytest =train_test_split(X,y,stratify=y)
b_tree = DecisionTreeClassifier(criterion='entropy',max_depth=20,
splitter='random',max_features=12,
min_samples_split=6)
b_tree.fit(x,y)
y_pred = b_tree.predict(Xtrain)
y_predT = b_tree.predict(Xtest)
f1_t = f1_score(ytrain,y_pred,average='weighted')
f1_e = f1_score(ytest,y_predT,average='weighted')
at = accuracy_score(ytrain,y_pred)
ae = accuracy_score(ytest,y_predT)
return {'f1_t':f1_t,'f1_e':f1_e,'at':at,'ae':ae}def adaboostTree(df):
X = df.drop('income', axis=1)
y = df['income']
oversample = SMOTE()
X, y = oversample.fit_resample(X, y)
Xtrain, Xtest, ytrain, ytest =train_test_split(X,y,stratify=y)
b_tree = DecisionTreeClassifier(criterion='entropy',max_depth=8,
min_samples_leaf=5,min_samples_split=10)
clf = AdaBoostClassifier(b_tree,learning_rate=0.09,
n_estimators=1000, algorithm='SAMME')
clf.fit(Xtrain,ytrain)
y_pred = clf.predict(Xtrain)
y_predT = clf.predict(Xtest)
f1_t = f1_score(ytrain,y_pred,average='weighted')
f1_e = f1_score(ytest,y_predT,average='weighted')
at = accuracy_score(ytrain,y_pred)
ae = accuracy_score(ytest,y_predT)
return {'f1_t':f1_t,'f1_e':f1_e,'at':at,'ae':ae}Resultados
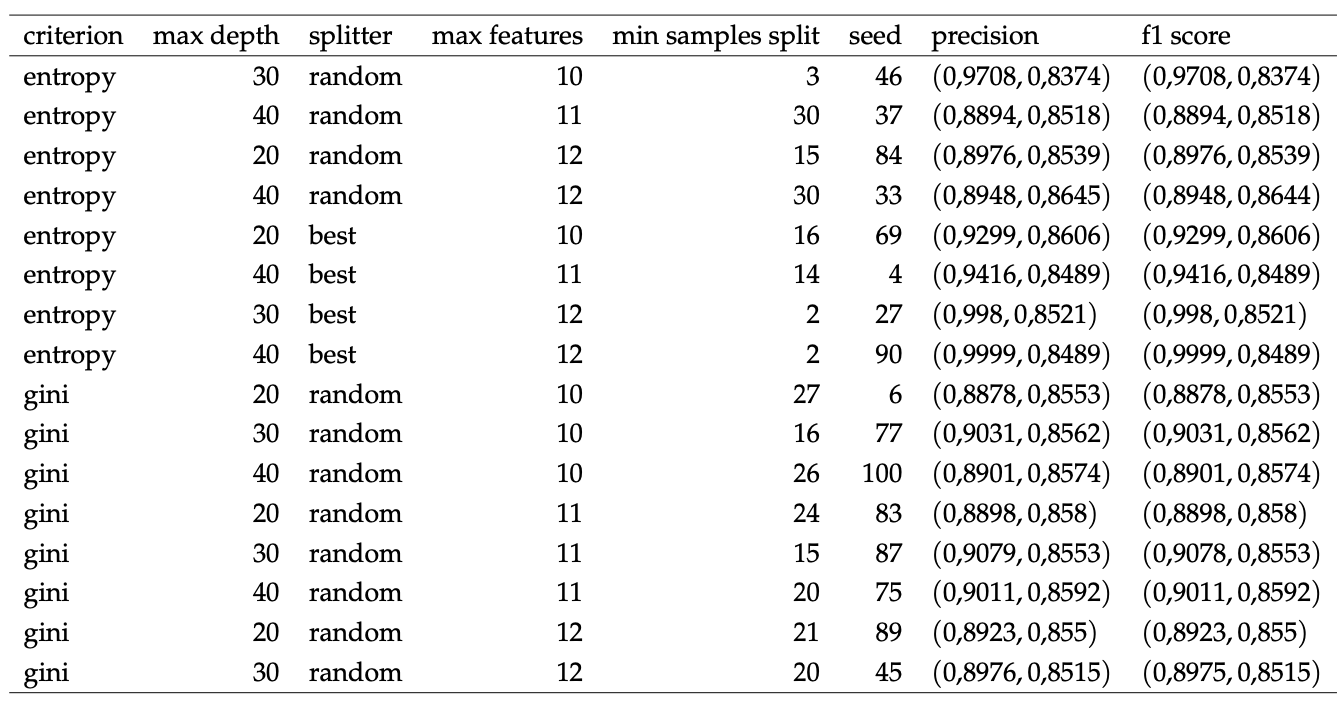
Resultados de arbol de decisión.
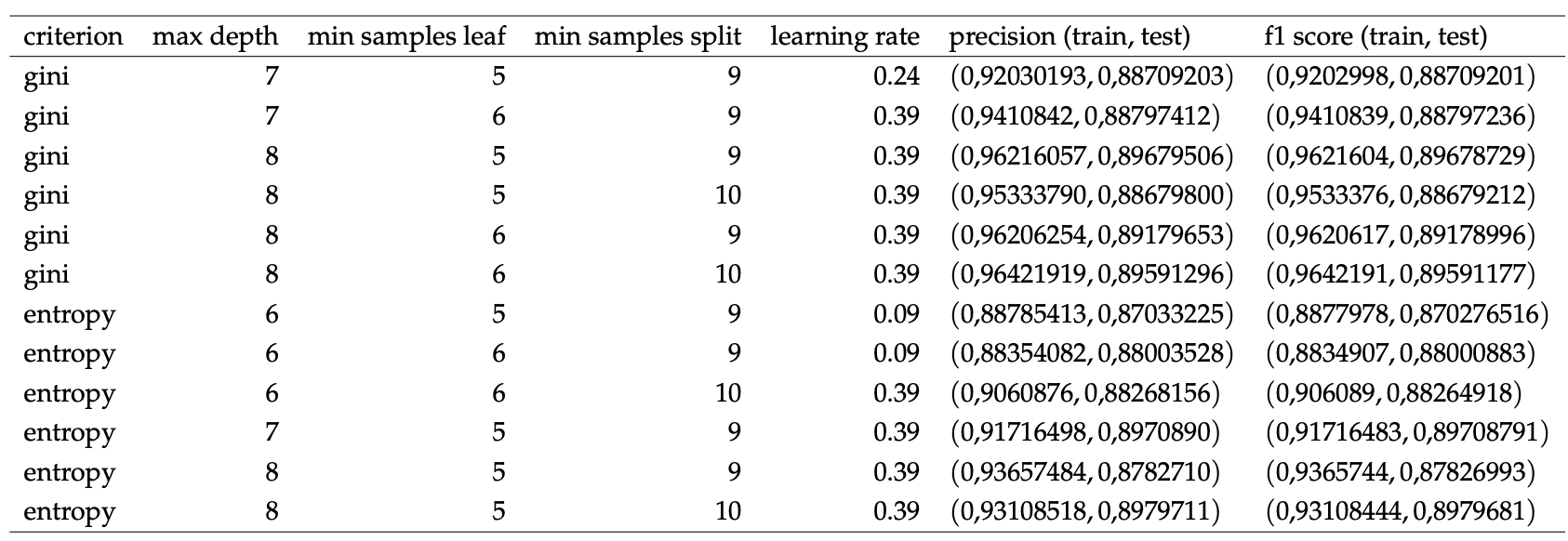
Tabla de resultados con Adaboost
Alternativas
Conclusiones
Trabajo a futuro
Gracias !!!
Proyecto Mineria de datos Fernando Moreno
By Fernando Moreno Gomez


