pgMemento
{ "name": "Felix Kunde" , "email": "fkunde@beuth-hochschule.de"}
Background
Motivation
Implementation
Roadmap
Initial Idea:
Version control for 3D city models

Existent solution for 3DCityDB
Version control of a proprietary DBMS
Linear versioning with timestamps
Working in different "workspaces" (hierachical versioning)
Merging of workspaces is possible
Great in theory, but working not so well in the field ...
Conclusion
Clear separation between production and archive state
Handling former DB states should be understandable
Performance matters
Motivation
Developing a version control for PostgreSQL
Linear versioning by using audit triggers
Access to former DB states by copying the logged information into a separate schema (either as VIEW or TABLE)
But: Being able to revert single transactions
Hierarchical versioning could be done in the same way
Some existent solutions
(Did not know there were so many in advance)
- audit trigger 91plus by ringerc
- tablelog by Andreas Scherbaum
- Cyan Audit by Moshe Jacobsen
- wingspan-auditing by Gary Sieling
- pgaudit by 2ndQuadrant
QGIS DB Manager

Version control of spatial data
- QGIS Versioning Plugin by OSLandia
-
pgVersion by Horst Düster
- GeoGig by Boundless
PostgreSQL Logical Decoding
New API since PG 9.4 to access replication streams
Decoding the WAL logs
Allows for bidirectional replication >> Multi-Master-Cluster
Export changes to replication slots
Auditing and versioning are both possible
Output plugins: WAL-Format >> wished format
More Infos: Docu, FOSS4G NA, Postgres Open, FOSDEM, PgConfRu
How it all started with pgMemento
Table row >> row_to_json(OLD) >> JSON
JSON >> json_populate_record(null::test_table, JSON) >> Table row
Generic tracking of changes

Setup
Run PL/pgSQL scripts
Create triggers
Create Audit_ID columns
Log existing data as "INSERT"ed
Log tables
transaction_log ( txid BIGINT, stmt_date TIMESTAMP, user_name TEXT, client_name TEXT); table_event_log ( id SERIAL, transaction_id BIGINT, op_id SMALLINT, table_operation VARCHAR(8), schema_name TEXT, table_name TEXT, table_relid OID); row_log ( id BIGSERIAL, event_id INTEGER, audit_id BIGINT, changes JSONB);
INSERT case

... and how it affects the log tables

UPDATE case
UPDATE building SET measured_height = 12.8 WHERE id = 1;
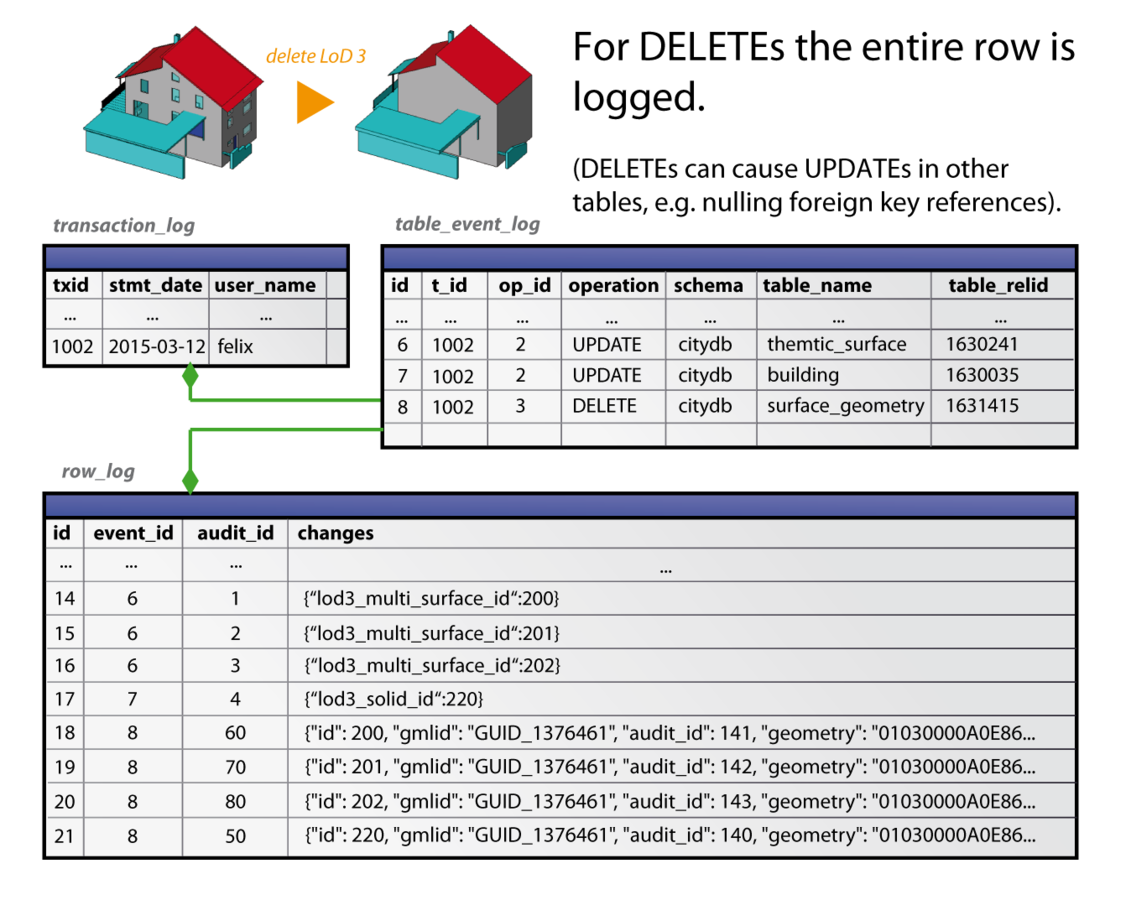
DELETE case
Fast queries thanks to GIN index
CREATE INDEX row_log_changes_idx ON pgmemento.row_log USING GIN (changes); JSON query: Which transactions has changed a certain column?
SELECT t.txid
FROM pgmemento.transaction_log t
JOIN pgmemento.table_event_log e ON t.txid = e.transaction_id
JOIN pgmemento.row_log r ON r.event_id = e.id
WHERE
r.audit_id = 4
AND
(r.changes ? 'measured_height');
-> Index Scan using row_log_audit_idx on row_log r
Index Cond: (audit_id = 4)
Filter: (changes ? 'measured_height'::text) JSON query 2: Searching for a specific key-value combination
SELECT DISTINCT audit_id FROM pgmemento.row_log
WHERE
changes @> '{"measured_height": 0.0}'::jsonb;
-> Bitmap Index Scan on row_log_changes_idx
Index Cond: (changes @> '{"measured_height": 0.0}'::jsonb)
Restore a former table
or database state
SELECT pgmemento.restore_schema_state(
1, -- Start of time slice
1002, -- End of time slice
'citydb', -- Source schema
'state_before_delete', -- Target schema
'TABLE', -- Relation type
ARRAY['spatial_ref_sys'] -- Exclude tables
);
What happens internally?
- Get valid rows for the given time slice?
- Fetch Audit_IDs smaller that transaction ID (Distinct)
- Exclude Audit_IDs of already deleted entries

Find old values
- Get columns of a table at timestamp x.
- Search for the next appearance of the column inside the log tables (Audit_ID >= Transaction_ID, because Audit_ID < Transaction_ID only refers to values before the requested timestamp)
- If nothing was found, query the recent state of the table

Connect JSONB fragments
) -- end of WITH block, that has collected valid audit_ids
SELECT v.log_entry FROM valid_ids f
JOIN LATERAL ( -- has to be applied for each audit_id
SELECT json_build_object(
q1.key, q1.value,
q2.key, q2.value,
...)::jsonb AS log_entry
FROM ( -- search for old values (see previous slide)
SELECT q.key, q.value FROM (
SELECT 'id' AS key, r.changes -> 'id'
FROM pgmemento.row_log r ...
)q ) q1,
SELECT q.key, q.value FROM (
SELECT 'name' AS key, r.changes -> 'name'
FROM pgmemento.row_log r ...
)q ) q2, ...
Restoring the table
) -- previous steps are encapsulated in a WITH block
SELECT p.* FROM restore rq
JOIN LATERAL (
SELECT * FROM jsonb_populate_record(
null::citydb.building, -- template
rq.log_entry -- concatenated JSONB
)
) p ON (true)
Revert transactions
Case 1: If deleted >> INSERT
Case 2: If updated >> UPDATE
Case 3: If inserted >> DELETE
Foreign key violation is avoided due to correct sorting of Audit_IDs
Query for revert
SELECT * FROM (
(SELECT r.audit_id, r.changes, e.schema_name, e.table_name, e.op_id
FROM pgmemento.row_log r
JOIN pgmemento.table_event_log e ON r.event_id = e.id
JOIN pgmemento.transaction_log t ON t.txid = e.transaction_id
WHERE t.txid = $1 AND e.op_id > 2 -- DELETE or TRUNCATE
ORDER BY r.audit_id ASC) -- insert oldest values first
UNION ALL
(SELECT ...
WHERE t.txid = $1 AND e.op_id = 2 -- UPDATE
ORDER BY r.audit_id DESC) -- update youngest values first
UNION ALL
(SELECT ...
WHERE t.txid = $1 AND e.op_id = 1 -- INSERT
ORDER BY r.audit_id DESC -- delete youngest values first
) txid_content
ORDER BY op_id DESC -- first DELETEs, then UPDATEs and finally INSERTs
Caveats
Reverts maybe a bit too simple
Filter what to restore (by time, spatial extent etc.)
No tracking of DDL commands (event triggers might help)
No merging of schemas
Need more benchmarking
More thoughts on restrictions and protection for log tables
No GUI, just SQL coding at the moment
Additional notes
Probably not the right option for write-extensive databases (even though only deltas are stored)
Manipulation of log tables is very easy at the moment
pgMemento is no substitution for backup and recovery tools
Repository
https://github.com/pgMemento/pgMemento
Any questions ?
Contact:
Felix Kunde
fkunde@beuth-hochschule.de
+49(0)30 030 4504 3824
pgMemento
By fxku




