Adatbázis kezelés alapjai
Hogy nézz ki egy adatbázis?
Fizikailag így:



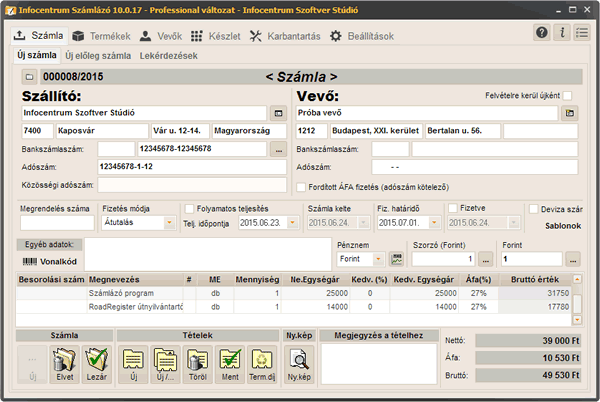
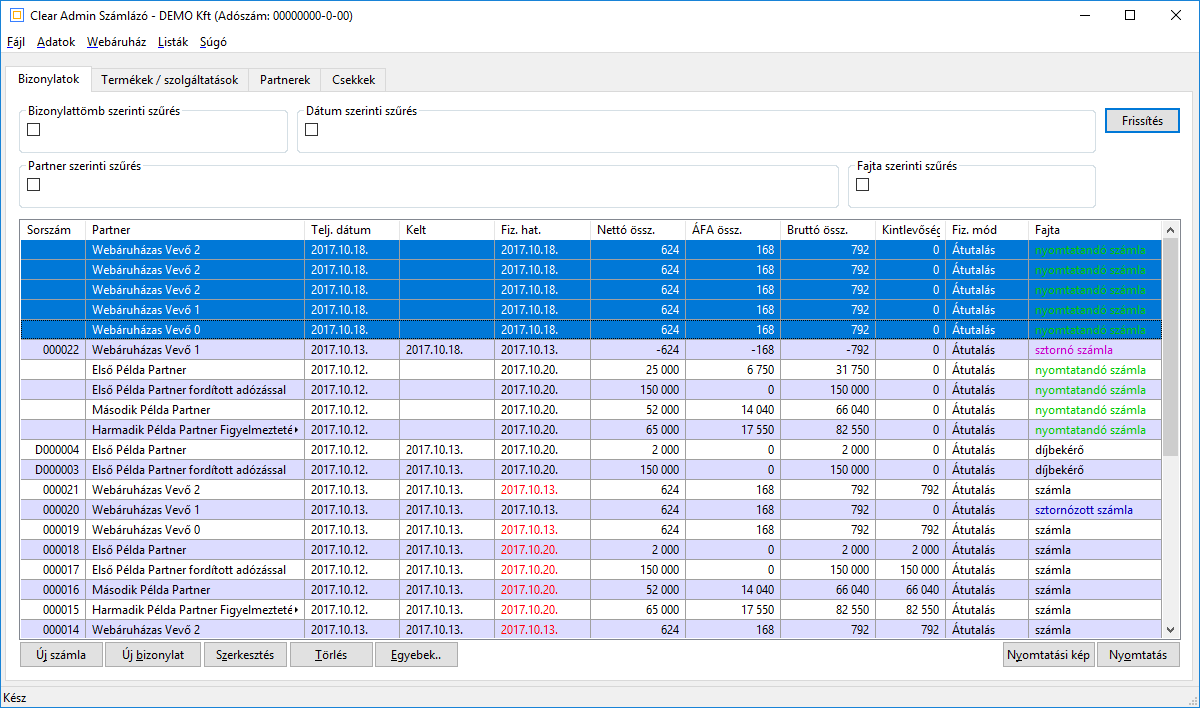
mégis hol találkozhatok adatbázissal?







Na de akkor mi is az adatbázis?
(most jön a száraz rész)
Az adatbázis azonos minőségű (jellemzőjű), többnyire strukturált adatok összessége,
amelyet egy azok tárolására, lekérdezésére és szerkesztésére alkalmas szoftvereszköz kezel.
- Wikipédia
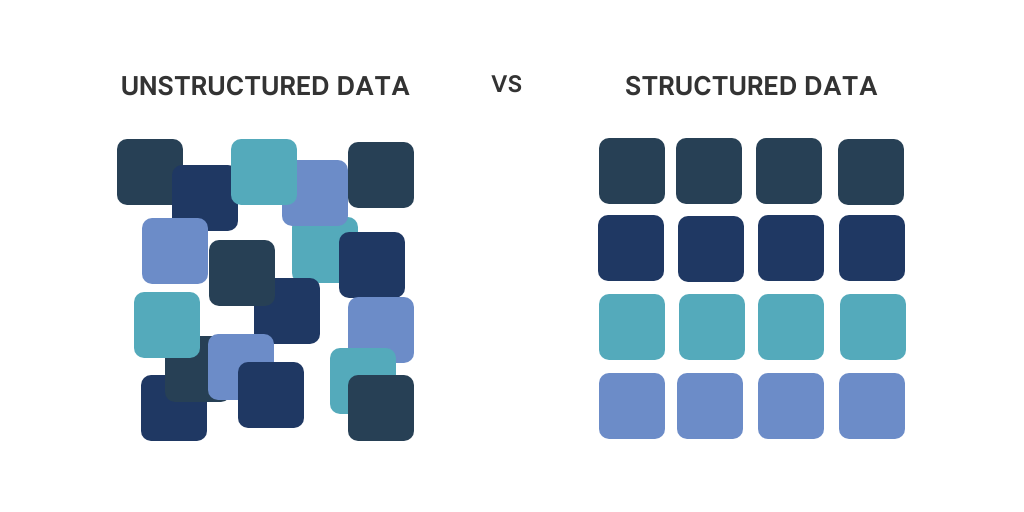
De mi az a strukturált adat
alma,banán,körte,banán,alma,alma,körte,dinnye,alma,cseresznye,banán,körte,alma,cseresznye,dinnye,alma,körte
6x alma
3x banán
2x dinnye
2x cseresznye
4x körte
De mik azok a strukturált adatok
"olyan adatok,mely elemei egy meghatározott tulajdonságuk révén összetartozóak."
"a “strukturált adatok” kifejezést olyan adatokra értjük, melyben az elemek közti kapcsolat explicit módon szerepel a számítógépen tárolt adatokban"
Adatbázis adatmodellek
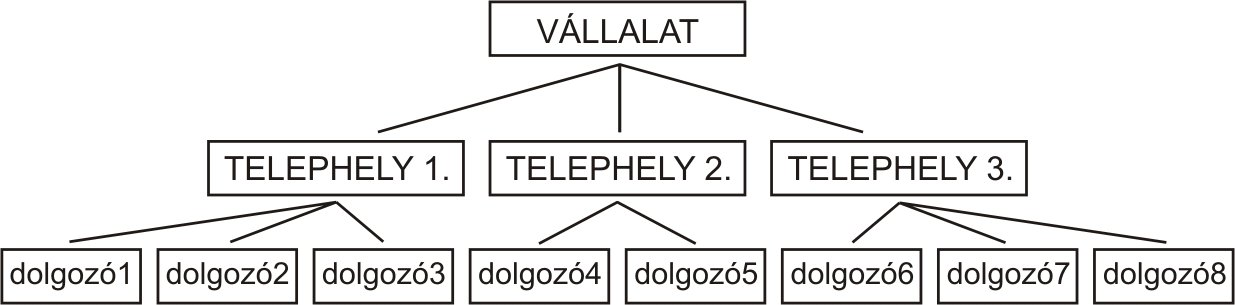
hiercharchikus adatmodell
hálós adatmodell
relációs adatmodell
objektum orientált adatmodell
Adatbázis adatmodellek
Hierarchikus adatmodell: A hierarchikus adatmodell szerkezetét gráffal adjuk meg, azon belül is fával. A csomópontok itt is egyedeket jelentenek és a nyilak a kapcsolatokat fejezik ki.
Hálos adatmodell: szerkezetét gráffal adjuk meg. Ebben a gráfban a csomópontok az egyedek, az élek pedig a kapcsolatot fejezik ki. Az egyedeket tulajdonságaikkal írjuk le. A hálós adatmodell adatbázisaiban az egyedek (tehát az előfordulásaik) közötti kapcsolatot listaszerkezettel (pointerek, mutatók használatával) adjuk meg.
Objektum Orientált adatmodell: olyan magasabb szintű implementációs adatmodellek egy új családjának tekinthető, amelyek közelebb állnak a koncepcionális adatmodellekhez. Az objektum adatmodelleket gyakran használják magas szintű koncepcionális modellekként is, elsősorban a szoftvertervezés területén.
Relációs adatmodell: az adatokat egymással logikai kapcsolatban álló táblázatokba rendszerezzük, és ezen kapcsolatokat matematikai relációval írhatóak le. Egy táblázat oszlopainak és sorainak a következő feltételeknek kell megfelelniük:
- minden oszlopnak egyértelmű neve van,
- minden sorban ugyanazok az oszlopok vannak,
- az oszlopokban található adatok meghatározott értéket vehetnek fel,
- az oszlopok soronként csak egy értéket vehetnek fel,
- a táblázatot a neve egyértelműen azonosítja.
Relációs adatmodell bővebben
(ez tényleg csak tájékoztatás jellegű)
A hagyományos relációs adatmodell kulcsfogalma a reláció, amely Descartes-szorzat részhalmazát jelenti. A Descartes-szorzat lényegében elemi egységekként kezelt egyedeket (entitásokat) rendel egymás mellé.
A Descartes-szorzat egyes műveleti tényezői egy-egy halmazból, értékkészletből veszik fel értéküket, amelyeket végesnek tételezünk fel. Az azonos típusú és szerepű elemek halmazát jellemzőknek (attribútumoknak) nevezzük. A jellemzők egy névvel ellátott rendezett halmaza pedig a séma. A séma-attribútum-reláció hármas voltaképpen egyfajta táblázatot írnak le, ahol az attribútumok az oszlopokat jelölik, a reláció a ténylegesen előforduló, kitöltött sorok összességét jelenti, míg a séma nem más, mint a táblázat alapszerkezetének, az oszlopfejlécek sorrendjének elnevezése.
A relációs adatmodell műveletei között pontos öt alapműveletet és számos származtatott műveletet definiálhatunk. Az alapműveletek rendre a következők: Descartes-szorzat, Halmazelméleti unió, Halmazelméleti különbség, kiválasztás (szelekció), vetítés (projekció)
Descart szorzat egyszereűbben két halmaz minden érték szerinti össze rendezése
D1 = {1,2,3}
D2 = {x,y,z}
D1 x D2 = [ (1,x)(2,x)(3,x)
(1,y)(2,y)(3,y)
(1,z)(2,z)(3,z) ]
Egyesítés: feltétele, hogy az egyesítendő relációknak ugyanannyi attribtúmból kell álniuk
D1 = [{gyümölcs, alma}
{zöldség, répa}]
D2 = [{csirke, comb}
{marha, hátszín}]
D1 u D2 = [{gyümölcs, alma}
{zöldség, répa}
{csirke, comb}
{marha, hátszín}]
Különbség: nem egyező értékek halmaza
D1= [{alma,körte}
{répa,borsó}]
D2 = [{répa,borsó}
{dinnye,barack}]
D1\D2 = [{alma,körte}
{dinnye,barack}]
Vetités: reláció bizonyos elemeit használjuk csak fel új relácitót képezve
D=(A1,A2,A3,A4,A5,A6,A7)
{alma,gyümölcs,piros,Spanyolország,golden,53,2023-03-04}
π1,4,7 D= {alma,Spanyolország,2023-03-04}
Kiválasztás: A kiválasztás egy részhalmaz képzése R reláción, amelynek vezérlésre egy logikai formula szolgál
D1 =(áru név, darab, érték) | φ(darab›1500)D1 =
{alma,1200,53} | {körte,3200,78}
{körte,3200,78}
De egyszerűbben mi is a reláció?
halmazokon végzett matematikai művelet melynek eredménye szintén egy halmaz

π(First Name, Last Name)φ(DateOfBirth›1998-01-01)Persons
SQL-ben ez így nézz ki:
SELECT FirstName,LastName FROM Persons WHERE DateOfBirth›1998-01-01
Eredmény

Adatbázis elemei
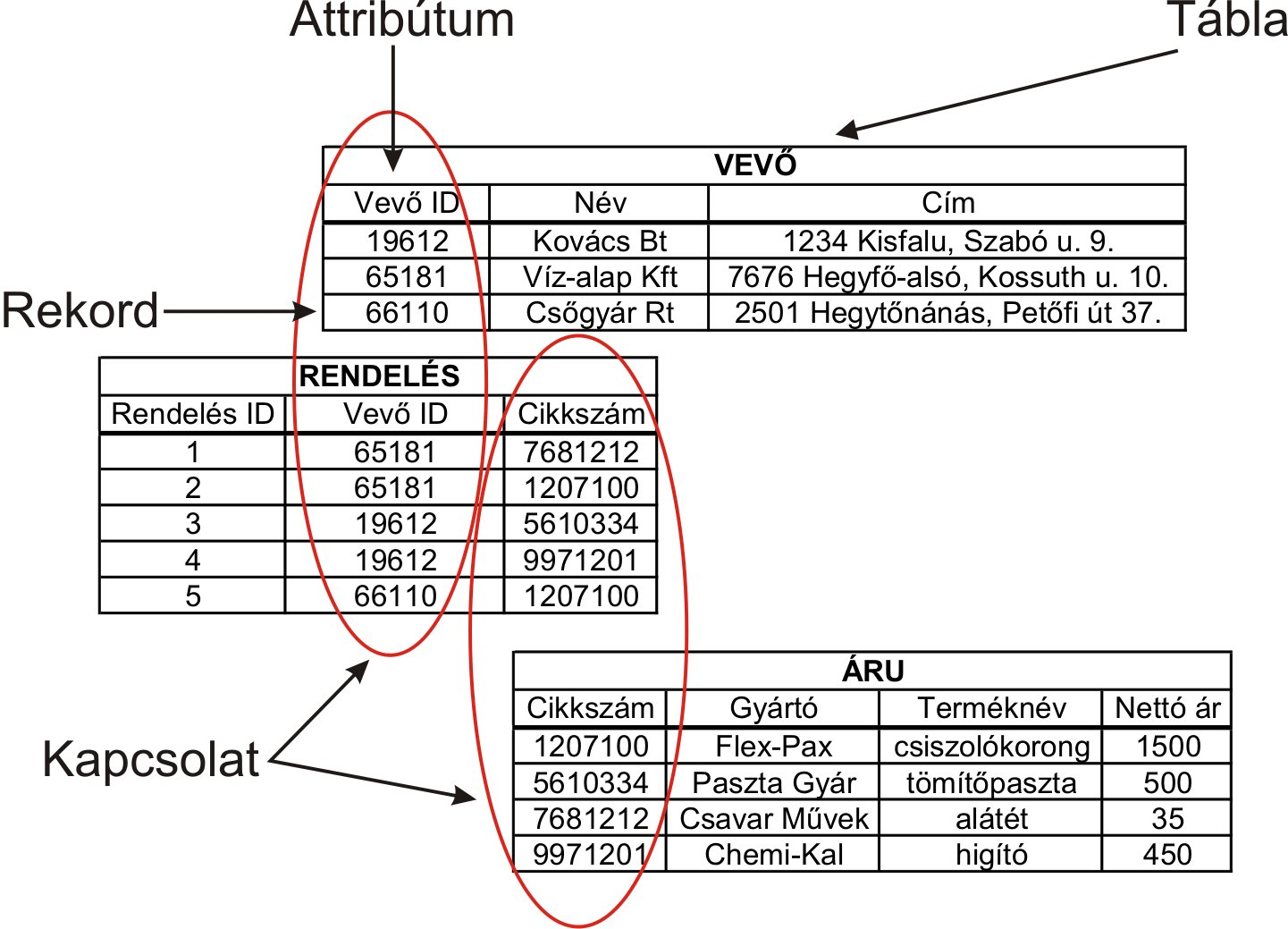
Az adatokat táblákba rendezzük
A rekord a tábla egy sora. Egy egyed adatait egy rekordban tároljuk.
A mező az adatbázis egy oszlopa, amelyben az egyedek tulajdonságértékeit tároljuk.
Az egyed(entity) az, amit le akarunk írni, amelynek az adatait tároljuk és gyűjtjük az adatbázisban.
Az attribútum vagyis tulajdonság az egyed valamely jellemzője. Az egyed az attribútumok összességével jellemezhető. Egy személy egy jellemzője lehet például a neve.

Kulcsok

Elsődleges kulcs: a táblázat rekordjainak egyértelmű azonosítója, értéke egyedi.
Idegen kulcs: olyan azonosító amelynek segítségével egy másik táblázat elsődleges kulcsára hivatkozhatunk.

elsődleges
idegen
Kulcsok
Egyszerű kulcs: egyetlen tulajdonságból (attribútum) áll
Öszetett kulcs: több tulajdonságból (attribútum) áll
egyszerű
összetett

Táblák közti kapcsolatok
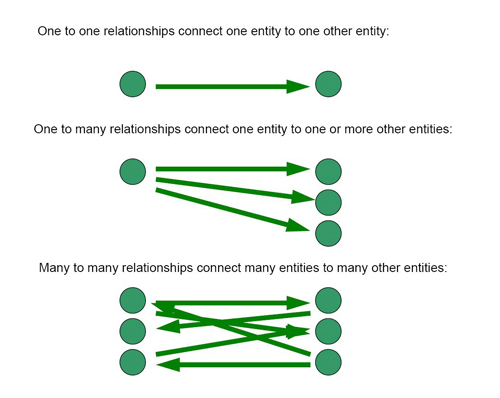
1 : 1
1 : N
N : N
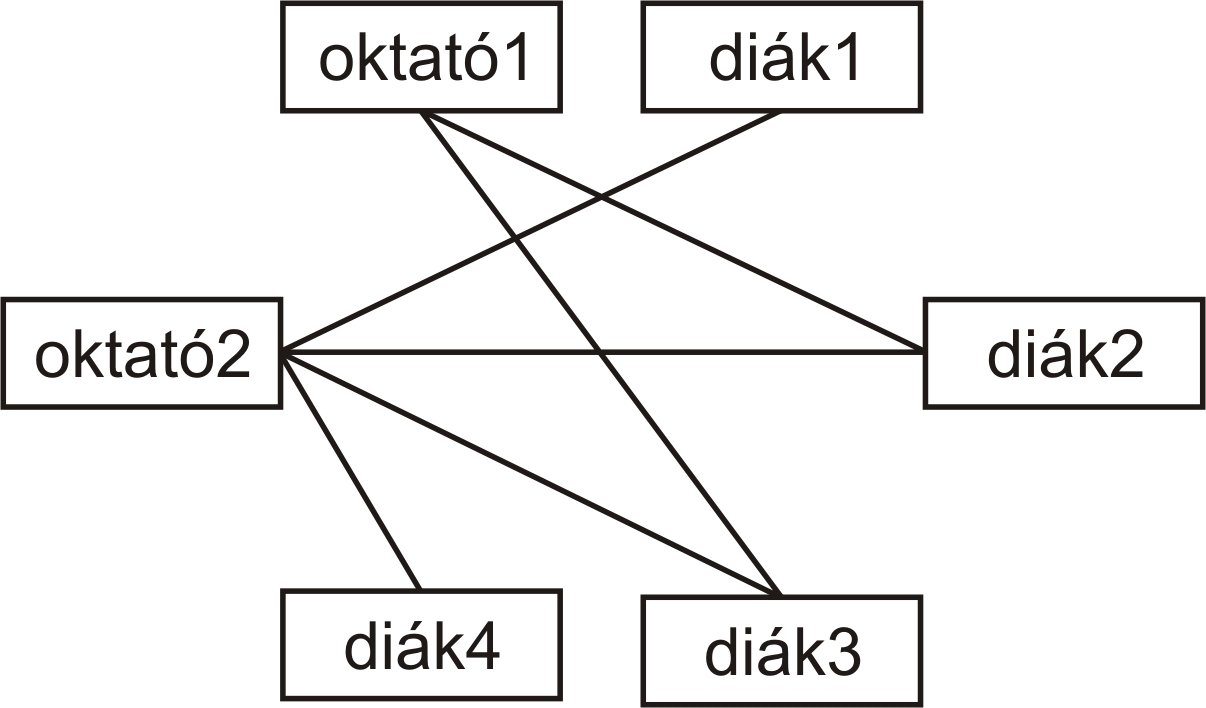
És egy kis példa, ki mit vesz észre a kövi adatbázisban?
Vége
Felhasznált irodalom:
https://www.nive.hu/Downloads/Szakkepzesi_dokumentumok/Bemeneti_kompetenciak_meresi_ertekelesi_eszkozrendszerenek_kialakitasa/17_0061_010_101030.pdf
http://users.atw.hu/kisstamas/informatika/9A_Access%20fogalmak.pdf
https://hu.wikipedia.org/wiki/Adatb%C3%A1zis
https://hu.wikipedia.org/wiki/Rel%C3%A1ci%C3%B3s_adatmodell
https://hu.wikipedia.org/wiki/Adatb%C3%A1zis-kezel%C5%91_rendszer
https://gyires.inf.unideb.hu/KMITT/b01/ch02.html
https://tudasbazis.sulinet.hu/hu/szakkepzes/informatika/adatbazis-kezeles/adatbazis-kezeles-alapfogalmai/adatbazismodellek-az-adatbazisok-szerkezete
Könyv: Gajdos Sándor - Adatbázisok (Műegyetemi Kiadó 2006)
Adatbázis kezelés alapjai
By Gábor Opitzer



