Malware classification balancing comparison
Benchmark di un classificatore CNN ADFA-based
Gabriele Bottani - 65826A
Francesco Perna - 66095A
Matteo Celardo - 66094A
Process
Analisi
Una volta analizzato il codice, abbiamo optato per la generazione di 500 sequenze finte tramite GAN, al fine di ribilanciare il dataset di partenza
1.
2.
Implementazione
Sono stati creati due modelli:
- uno bilanciato tramite i dati generati dalla GAN
- uno sbilanciato, basato unicamente sul dataset di patenza
Per l'addestramento sono state usate 20 epoche in entrambi i casi
3.
Valutazione
Le prestazioni dei due modelli sono state misurate tramite 5 metriche:
- precision
- recall
- F1-score
- loss
- accuracy
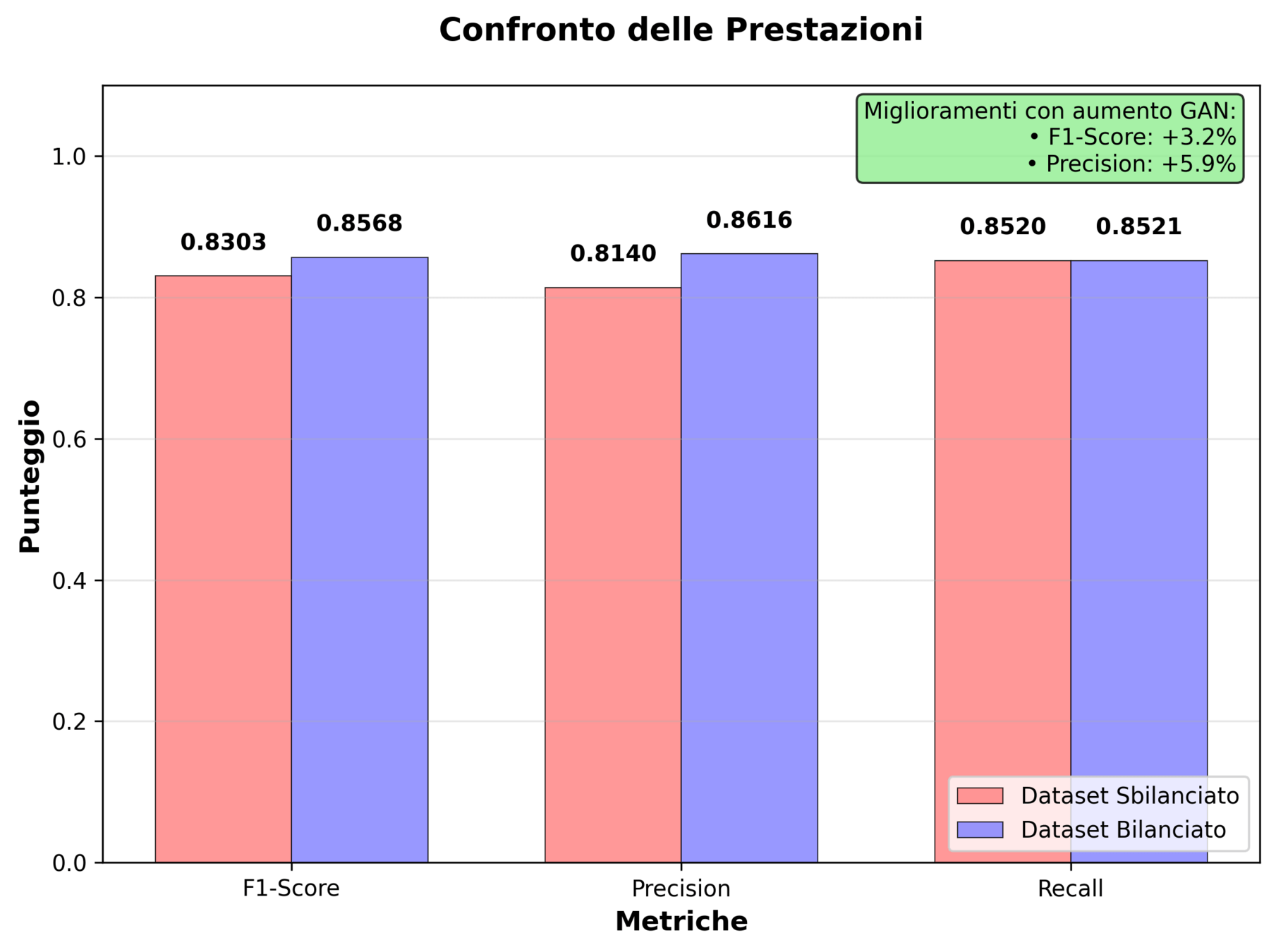
I risultati mostrano una maggiore performance del modello bilanciato:
- Aumento precision: maggiore efficacia del modello bilanciato per classificare i veri malware
- Aumento recall: migliore capacità di riconoscere i malware
- Aumento F1-score: precision e recall rimangono ben bilanciate
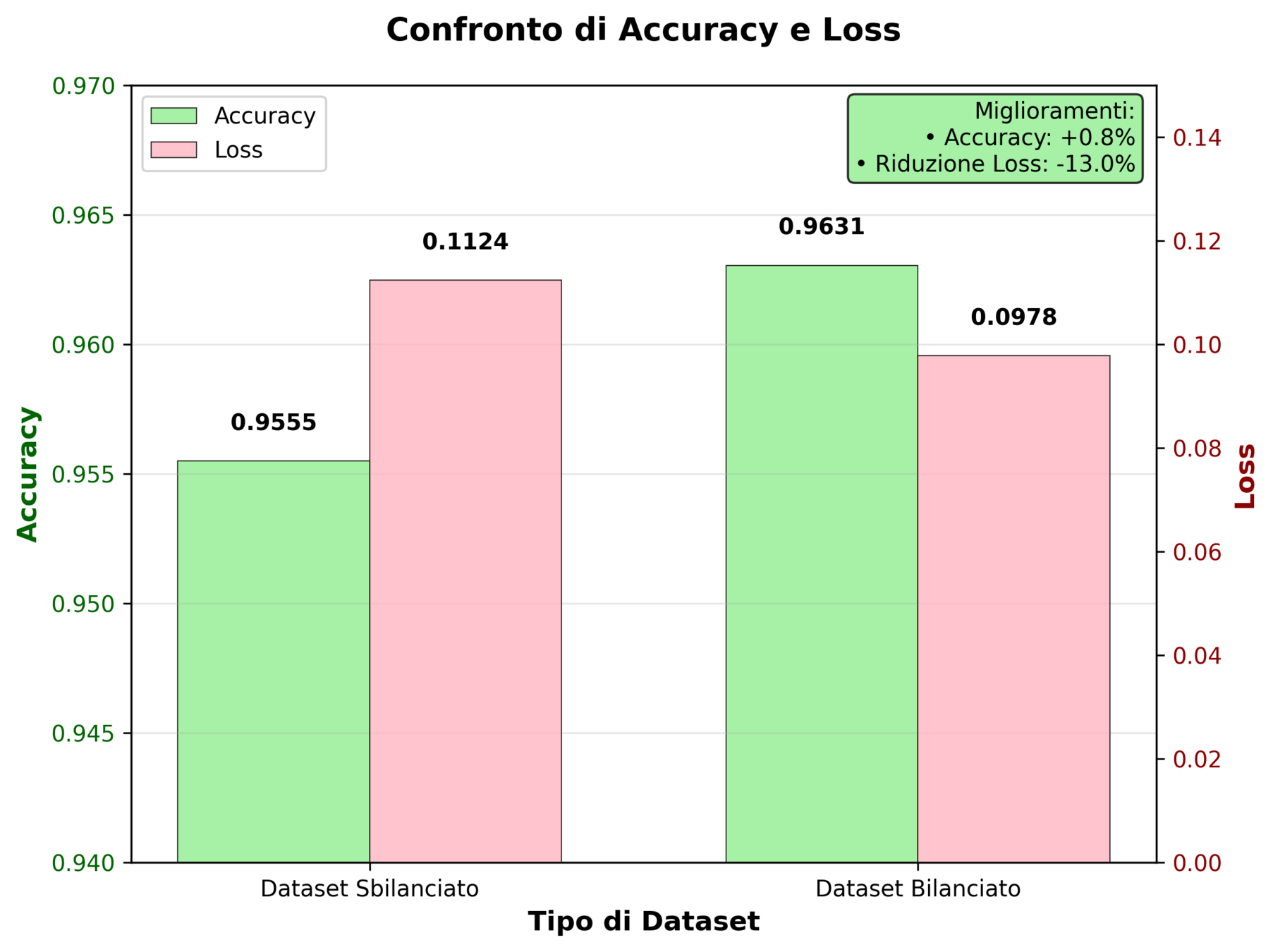
Ulteriori conferme di miglioramento:
- Aumento accuracy: il modello bilanciato garantisce maggiore capacità di classificare correttamente sia true postive che true negative
- Diminuzione loss: indica maggiore confidenza nelle predizioni del modello, grazie a una migliore convergenza dell'addestramento
gan.G.eval()
# Fake sample creati con rumore
z = gan._sample_noise(500)
print(f"Shape of z: {z.shape}")
with torch.no_grad():
# Genera le sequenze finte con GAN.G
fake_sequences = gan.G(z)
fake_sequences = fake_sequences.view(500,
seq_len,
vocab_size)
fake_sequences = torch.softmax(fake_sequences,
dim=-1)
fake_sequences = fake_sequences.argmax(dim=-1)
torch.save(fake_sequences, "fake_sequences.pt") Generazione delle sequenze finte
trainer = pl.Trainer(
max_epochs=MAX_EPOCHS,
max_steps=classifier_max_steps,
val_check_interval=5, # validazione ogni 10 passi
log_every_n_steps=5,
accelerator="auto",
devices="auto",
callbacks=[RichProgressBar()], # progress bar
enable_progress_bar=True,
logger=logger,
)
trainer.fit(model_1,
train_dataloaders=train_loader,
val_dataloaders=val_loader)
torch.save(model_1.state_dict(),
"./model/not-balanced.pt")Addestramento del modello sbilanciato
class FakeDataset(torch.utils.data.Dataset):
def __init__(self, fake_sequences, fake_labels):
self.sequences = fake_sequences
self.labels = fake_labels
def __len__(self):
return len(self.sequences)
def __getitem__(self, idx):
return self.sequences[idx], self.labels[idx]
fake_dataset = FakeDataset(fake_sequences,
fake_labels)
# Concatenazione dei dataset
balanced_dataset = ConcatDataset([train_dataset,
fake_dataset])Generazione fake dataset
trainer_2 = pl.Trainer(
max_epochs=MAX_EPOCHS,
max_steps=classifier_max_steps,
val_check_interval=5, # valida ogni 10 passi
log_every_n_steps=5,
accelerator="auto",
devices="auto",
callbacks=[RichProgressBar()], # progress bar
enable_progress_bar=True,
logger=logger,
)
trainer_2.fit(model_2,
train_dataloaders=train_loader,
val_dataloaders=val_loader)
torch.save(model_2.state_dict(),
"./model/balanced.pt")Addestramento del modello bilanciato
Conclusioni
- Il bilanciamento migliora le prestazioni complessive
- L'approccio GAN per data augmentation è stato efficace
{Q&A}
Grazie per l'attenzione
Code
By Gabriele Bottani (TheGaBr0_)



