



G. Lghd
web developper
Sujet de veille 3
Bastien S. & Gaëtan L.
13/01/2020
Liste est une séquence : [‘p’, ‘r’, ‘o’, ‘b’, ‘e’]
Séquence : ensemble fini et ordonné d’éléments indicés de 0 à n-1 (n éléments)
Les list, les tuple, les str et les bytes
N'est pas : {‘t’, ‘u’, ‘p’, ‘l’, ‘e’} ni (‘s’, ‘e’, ‘t’)
La liste est un itérable.
La liste ne stocke pas les objets. Elle ne stocke que des références vers les objets.
Elle est mutable.
Voici une listes des méthodes des objets de type liste :
dir(list)
[… 'append', 'clear', 'copy', 'count',
'extend', 'index', 'insert', 'pop',
'remove', 'reverse', 'sort']
De la théorie…
… à la pratique
Sujet de veille 3
Sujet de veille 3
0.0 Qu'est-ce qu'une liste en Python ?
0.1 Comment créer une liste vide ?
0.2 Comment y ajouter un ou plusieurs items ?
0.3 Comment savoir la longueur d'une liste ?
0.4 Comment accéder aux élément d'une liste ?
0.5 Comment manipuler une liste ?
0.6 Les méthodes
sommaire[0]
une_liste = ['a' , 'b' , 'c']
une_autre_liste = [1 , 2 , 3]
encore_une_liste = [a , 3 , 'du texte', False , 3.14] # liste hétérogène
une_liste_a_partir_d_un_range = list(range(1,16))
une_liste_a_partir_de_texte = list('du texte')
Les listes en python sont une variable dans laquelle on peut mettre plusieurs variables.
voici quelques exemple de liste :
On voit qu'il est possible de mélanger dans une même liste des variables de type différent.
On peut d'ailleurs mettre une liste dans une liste.
deux_listes_dans_une_liste = [[ 'a' , 'b' , 'c'] , [ 'd' , 'e' , 'f']]
une_liste_vide = []Pour créer une liste vide il suffit de déclarer une variable
et de lui assigner des crochets vides.
print(type(liste))
<class 'list'>
Quand on appelle le type sur notre variable, la class 'list' est retourné
Ou les ajouter après la création de la liste avec la méthode append :
une_liste.append('item')
print(une_liste)
[1, 2, 3, 'item']
Vous pouvez ajouter les valeurs que vous voulez lors de la création de la liste python :
une_liste = [1,2,3]
print(une_liste)
[1, 2, 3]
Pour connaitre le nombre d'items dans une liste nous utilisons la fonction len()
une_liste = [1,2,3,5,10]
print(len(une_liste))
5une_liste = ["a","a","a","b","c","c"]
une_liste.count("a")
3
une_liste.count("c")
2
une_liste = ["a","a","a","b","c","c"]
une_liste.index("b")
3Pour connaitre le nombre d'occurences d'une valeur dans une liste, nous pouvons utiliser la méthode count .
La méthode index nous permet de connaitre la position de l'item cherché.
une_liste = ["a","a","a","b","c","c"]
une_liste.index("b")
3Pour accéder à une élément dans une liste nous allons chercher à voir l'index de la valeur qui nous intéresse
une_liste = [1, 10, 100, 250, 500]
une_liste[0]
1
une_liste[-1] # Cherche la dernière occurence
500
une_liste[-4:] # Affiche les 4 dernières occurrences
[500, 250, 100, 10]
une_liste[:] # Affiche toutes les occurences
[1, 10, 100, 250, 500]Un index négatif part de la fin.
D'autres méthodes peuvent être utilisées pour pointer l'élément ou les éléments qui nous intéressent - plus de détails dans la partie slicing
Pour inverser l'ordre d'une liste nous utilisons la fonction reverse()
une_liste = ["a", "b", "c"]
une_liste.reverse()
print(une_liste)
['c', 'b', 'a']
nums = [1, 2, 3]
print(nums + [4, 5, 6])
[1, 2, 3, 4, 5, 6]
print(nums * 4)
[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]Les opérateurs + et * permettent aussi de manipuler les listes :
list.append(x)Ajoute un élément à la fin de la liste. Équivalent à a[len(a):] = [x].
list.extend(iterable)Étend la liste en y ajoutant tous les éléments de l'itérable. Équivalent à a[len(a):] = iterable.
list.insert(i, x)
Insère un élément à la position indiquée. Le premier argument est la position de l'élément courant avant lequel l'insertion doit s'effectuer, donc a.insert(0, x) insère l'élément en tête de la liste et a.insert(len(a), x) est équivalent à a.append(x).
list.remove(x)
Supprime de la liste le premier élément dont la valeur est égale à x. Une exception ValueError est levée s'il n'existe aucun élément avec cette valeur.
list.pop(i)
Enlève de la liste l'élément situé à la position indiquée et le renvoie en valeur de retour. Si aucune position n'est spécifiée, a.pop() enlève et renvoie le dernier élément de la liste (les crochets autour du i dans la signature de la méthode indiquent que ce paramètre est facultatif et non que vous devez placer des crochets dans votre code !
list.clear()Supprime tous les éléments de la liste. Équivalent à del a[:].
list.index(x[, start[, end]])
Renvoie la position du premier élément de la liste dont la valeur égale x (en commençant à compter les positions à partir de zéro). Une exception ValueError est levée si aucun élément n'est trouvé.
Les arguments optionnels start et end sont interprétés de la même manière que dans la notation des tranches et sont utilisés pour limiter la recherche à une sous-séquence particulière. L'index renvoyé est calculé relativement au début de la séquence complète et non relativement à start.
list.count(x)Renvoie le nombre d'éléments ayant la valeur x dans la liste.
list.sort(key=None, reverse=False)
Ordonne les éléments dans la liste (les arguments peuvent personnaliser l'ordonnancement, voir sorted() pour leur explication).
list.reverse()
Inverse l'ordre des éléments dans la liste.
list.copy()
Renvoie une copie superficielle de la liste. Équivalent à a[:].
Sujet de veille 3
1.0 Une illustration
1.1 La syntaxe
1.2 Quelques tournures utiles
sommaire[1]
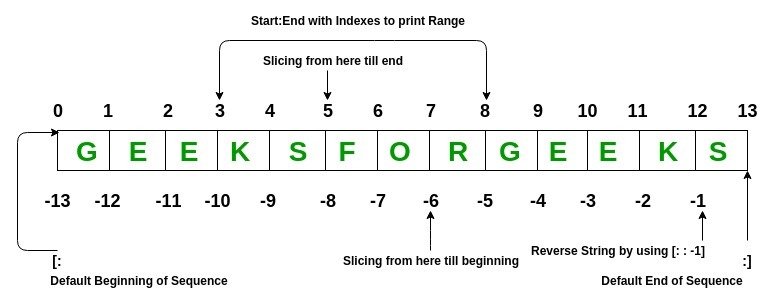
https://www.geeksforgeeks.org/python-list/
a = ['G', 'E', 'E', 'K', 'S', 'F', 'O', 'R', 'G', 'E', 'E', 'K', 'S']
tranche = a[3:8]
print(tranche)
[ 'K', 'S', 'F', 'O', 'R']Le slicing est un découpage en "tranches" d'une liste
en utilisant les crochets et trois valeurs séparées par deux points : FROM:TO:STEP
FROM est inclu, et TO est exclu. Quand il n'y a qu'un seul opérateur ":", la valeur STEP est absente et vaut 1 par défaut
Ces valeurs sont facultatives. Par défaut, FROM vaut 0 et TO la longueur de la liste. Leur absence extrait donc la totalité de la liste.
Négatives, ces valeurs indiquent le sens inverse.
De slicing résulte un extrait qui est un objet de type liste
Que cet extrait soit vide [] ou ne contienne qu'un seul élément ['k'], c'est toujours une liste
A gauche de l'opérateur =, le slicing modifie la liste en affectant une valeur qui est une liste
liste de longueur indépendante de celle du slicing,
et qui est toujours une liste, même vide [] ou réduite à un élément [4]
a = [1, 2, 4, 5]
a[2:4] = [3, 4]
print(a)
[1, 2, 3, 4]b = a[2:4]
print(b)
[3, 4]A droite de l'opérateur =, le slicing affecte une liste extraite de la liste initiale
si TO excède la longueur de la liste dans un slicing d'affectation,
sa valeur est ramenée à cette longueur
Supprimer des éléments
a = [1, 3, 3]
a[1:2] = [2]
print(a)
[1, 2, 3]a = [1, 4, 4]
a[1:2] = [2, 3]
print(a)
[1, 2, 3, 4]
a = [1, 3]
a[1:1] = [2]
print(a)
[1, 2, 3]a = [1, 4]
a[1:1] = [2, 3]
print(a)
[1, 2, 3, 4]
a = [1, 3, 2]
a[1:2] = []
print(a)
[1, 2]a = [1, 3, 4, 2]
a[1:3] = []
print(a)
[1, 2]
a = [1, 4, 4, 3]
a[1:3] = [2]
print(a)
[1, 2, 3]a = [1, 2, 3, 4]
a[:] = []
print(a)
[] #cf. partie 0.5a = [1, 3, 2]
a[1:2] = []
print(a)
[1, 2]a = [1, 3, 2]
a[1:2] = []
print(a)
[1, 2]a = [4, 3, 2, 1]
b = a[::-1]
print(b)
[1, 2, 3, 4]a = list(range(1,11))
a[1::2] = [0] * (len(a) // 2)
print(a)
[1, 0, 3, 0, 5, 0, 7, 0, 9, 0]D'après une idée de Tony N. :
NB : dans la modification par pas, les longueurs des deux listes doivent sans doute coïncider
Vider, inverser,
modifier une liste
Remplacer des éléments
Insérer des éléments
Sujet de veille 3
2.0 La syntaxe
2.1 Filtrer une liste
2.2 Règles avancées
sommaire[2]
Les listes en compréhension sont une syntaxe présente dans le langage Python (entre autres) permettant de filtrer un itérable (comme une liste). En gros, cela permet l’écriture d’une boucle for dont la finalité est de créer une nouvelle liste. Un exemple sera plus parlant.
# une liste de compréhension
une_liste = [expression
for value in collection
if condition]
# est équivalent à :
un_liste = []
for value in collection
if condition:
une_liste.append(expression)
Les compréhensions de listes fournissent un moyen plus concis de créer des listes dans des situations où les boucles, les fonctions map() et filter() seraient utilisées.
Prenons un exemple d'une liste:
une_liste = [1,4,2,7,1,9,0,3,4,6,6,6,8,3]Nous voulons filtrer les valeurs de cette liste et ne garder que ceux dont la valeur est supérieure à 5:
une_liste_superieur_a_5 = []
for item in une_liste:
if item > 5:
une_liste_superieur_a_5.append(item)
print(une_liste_superieur_a_5)
[7, 9, 6, 6, 6, 8]Il est possible de faire exactement ce que fait ce bloc de code en une seule ligne :
une_liste_superieur_a_5 = [item for item in une_liste if item > 5]
print(une_liste_superieur_a_5)
[7, 9, 6, 6, 6, 8]
numeros = [1, 2, 3, 4]
fruits = ["Pommes", "Peches", "Poires", "Bananes"]
liste_de_numero_et_de_fruits = [[n, f] for n in numeros for f in fruits]
[[1, 'Pommes'], [1, 'Peches'], [1, 'Poires'], [1, 'Bananes'],
[2, 'Pommes'], [2, 'Peches'], [2, 'Poires'], [2, 'Bananes'],
[3, 'Pommes'], [3, 'Peches'], [3, 'Poires'], [3, 'Bananes'],
[4, 'Pommes'], [4, 'Peches'], [4, 'Poires'], [4, 'Bananes']]
Une compréhension de liste consiste à placer entre crochets une expression suivie par une clause for puis par zéro ou plus clauses for ou if.
Le résultat est une nouvelle liste résultant de
l'évaluation de l'expression dans le contexte
des clauses for et if qui la suivent.
Par exemple, cette compréhension de liste combine les éléments de deux listes sans conditions :
une_liste = [[x, y] for x in [1,2,3] for y in [3,1,4] if x != y]
[[1, 3], [1, 4], [2, 3], [2, 1], [2, 4], [3, 1], [3, 4]]
Cette compréhension de liste combine les éléments de deux listes s'ils ne sont pas égaux :
Merci à Laien W. pour le complément concernant else :
[expr1 if condition else expr2 for valeur in valeurs]
-> if isolé appartient à la syntaxe des compréhensions : filtre
-> le couple if else joue comme opérateur ternaire : d'où sa position
nb : elif ne peut ainsi être utilisé, il faudrait imbriquer les ternaires
ex. : [2 if n % 2 == 0 else (3 if n % 3 == 0 else (5 if n % 5 == 0 else 7)) for n in range(2, 11)]
Sujet de veille 3
3.0 Sorted
3.1 Sort
sommaire[3]
3.2 Nature des données
3.3 Tri inverse
3.4 Tri personnalisé : les fonctions clef
3.5 Tri personnalisé (suite)
3.6 Le module operator
En tant qu'itérable : la fonction sorted
Elle renvoie une copie de la liste (la liste n'est pas modifiée)
a = [5, 2, 3, 1, 4]
print(sorted(a))
print(a)
[1, 2, 3, 4, 5]
[5, 2, 3, 1, 4]
Homogénéité des données à comparer (sinon : TypeError)
càd entre elles des données littérales, ou bien numériques, ou bien booléennes
(homogénéité faible : possibilité de trier [True, False, 0])
Une méthode propre aux listes : sort
Cette méthode modifie la liste
a = [5, 2, 3, 1, 4]
a.sort()
print(a)
[1, 2, 3, 4, 5]
Quand les valeurs sont identiques, l'ordre original est préservé (stabilité)
Cette fonction renvoie None (son action ayant directement modifié la liste triée)
Même remarque qu'en 3.0 Sorted quand à l' homogénéité (faible) des données à comparer
Quand il s'agit de données numériques, les valeurs sont directement comparées
print(sorted([11, 9])
=> [9, 11]
Quand il s'agit de données littérales, les caractères sont évalués d'après leur position UNICODE. C'est cette position qui est prise en compte pour la comparaison
print(sorted(['arc', 'Zoé']))
=> ['Zoé', 'arc']
Faire attention aux caractères accentués
Extrait de la doc. :
"Pour du tri de texte localisé, utilisez locale.strxfrm() en tant que fonction clef
ou locale.strcoll() comme fonction de comparaison."
print(sorted(['9', '11'])
=> ['11', '9']
Par défaut, le tri est ascendant càd qu'il y a un paramètre 'reverse' réglé à False
Pour obtenir un tri descendant, comme avec la fonction reversed(),
il suffit d'expliciter ce paramètre afin de le régler à True
a = [5, 2, 3, 1, 4]
print(sorted(a, reverse=True))
[5, 4, 3, 2, 1]
a.sort(reverse=True)
print(a)
[5, 4, 3, 2, 1]
Ces fonctions acceptent aussi un paramètre de personnalisation du tri
Ce paramètre est une autre fonction (anonyme ou non)
Cette fonction va va traiter les items de la liste un par un, de façon à ce que le tri s'effectue sur la valeur renvoyée
a = ['motPresqueTropLong', 'zut', 'etantMedian']
print(sorted(a, key=lambda mot: len(mot))) # ou print(sorted(a, key=len))['etantMedian', 'motPresqueTropLong', 'zut']
['zut', 'motPresqueTropLong', 'etantMedian']
['zut', 'etantMedian', 'motPresqueTropLong']
Quel est le résultat ?
Le tri personnalisé est très utile quand on a une liste d'objets complexes.
Par exemple sur une liste de listes regroupant lieux et températures, l'on peut ainsi effectuer le tri sur les températures
a = [['Paris', 0], ['Montréal', -40], ['Tombouctou', 40]]
printed(sorted(a, key=lambda l: l[1]))
[['Montréal', -40], ['Paris', 0], ['Tombouctou', 40]]
Même principe avec une liste de dictionnaires (courant dans le traitement de données structurées) en remplaçant l'index par l'attribut nommé.
Pour creuser : la méthode DUD consiste à enrichir une liste
juste le temps d'un tri effectué sur valeurs provisoires
L'accès aux index et aux attributs étant récurrentes, le module operator propose les fonctions itemgetter(), attrgetter()…
from operator import itemgetter, attrgetter
a = [['Paris', 0], ['Montréal', -40], ['Tombouctou', 40]]
printed(sorted(a, key=itemgetter[1]))
[['Montréal', -40], ['Paris', 0], ['Tombouctou', 40]]Sujet de veille 3
4.0 Bon à savoir
4.1 La fonction zip
4.2 Une liste stocke des références : modifions, et puis ?
sommaire[4]
4.3 Une liste en argument ?
4.4 Une liste stocke des références : bonus ;-)
4.5 Les fonctions natives applicables aux listes
4.6 Les fonctions map() et filter()
l'exécution est plus rapide que len() - cf. http://media.jehaisleprintemps.net/talks/pep8-talk/#slide93
*) Une virgule en fin de liste est une pratique correcte
*) La fonction enumerate : retourne des tulpes associant index et valeur
a = []
print((not not a) == False)
Truea = []
if not a:
print("liste vide")
"liste vide"a = ['a', 'b', 'c']
print(enumerate(a))
[(0, 'a'), (1, 'b'), (2, 'c')]print(list(range(10)))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]print(list(range(9,0,-3)))
[9, 6, 3]*) Vérifier la présence d'un élément : in
*) L'indexation doit être comprise dans la liste, sinon une IndexError est levée
Le slicing, lui, peut jouer avec des index virtuels
*) Convertir un objet en liste avec list(), par ex. créer une liste à partir de range()
*) Pour vérifier qu'une liste soit vide, il suffit de l'évaluer en termes booléens à False
Veiller en cas de listes de longueurs différentes, à ce que les listes plus longues ne contiennent pas d'éléments importants
Dézipper : avec l'opérateur * devant l'objet zippé en argument
x = [1, 2, 3]
y = [4, 5, 6]
zipped = zip(x, y)
print(list(zipped))
[(1, 4), (2, 5), (3, 6)]x = [1, 2, 3]
y = [4, 5, 6]
zipped = zip(x, y)
dezipped = zip(*zipped)
print(list(dezipped))
[(1, 2, 3), (4, 5, 6)] # liste de tuplesLa fonction zip prend des listes en argument
et retourne un objet qui associe entre eux les éléments de ces listes
en fonction de leur index (limite : la liste la plus courte)
Voir : Valeurs et références en Python
Quand l'objet plusieurs fois référencé est un nombre :
sa modification reste simple
Mais quand l'objet plusieurs fois référencé est une liste, il est mutable :
quand on le modifie, on n'en crée donc pas une copie
# au fait, que vaut finalement a ?
a = [0, 1]
b = a
b[0] = 9
print(a)
# indice : a et b sont 2 références
# vers le même objeta = [0, 0, 0]
a[1] += 4
print(a)
[0, 4, 0]a = [[0]] * 3
a[1][0] += 4
print(a)
[[4], [4], [4]]un nombre est immuable : quand on le modifie, on crée un nouvel objet
a[1] contient ainsi une référence vers un nouvel objet
via a[1], l'on a modifié l'objet duquel les trois éléments sont des références
Ces deux exemples proviennent de l'article cité :
Merci à Tony N. pour sa vigilance (cet exemple ayant initialement été mal adapté)
liste1 = [1, 2, 3]
def modif_l1(l, a):
l[:] = [i * a for i in l]
modif_l1(liste1, 2)
print(liste1)
# ?
liste2 = [1, 2, 3]
def modif_l2(l, a):
l = [i * a for i in l]
modif_l2(liste2, 2)
print(liste2)
# ?Réponses :
liste1 et liste4
liste3 = [1, 2, 3]
def modif_l3(l):
l = 40
modif_l3(liste3)
print(liste3)
# ?
liste4 = [1, 2, 3]
def modif_l4(l):
l[1] = 40
modif_l4(liste4)
print(liste4)
# ?Le traitement du paramètre modifie-t-il l'argument ?
Un paramètre reste une référence vers l'objet passé en argument
Ce n'est pas la réaffectation du paramètre au sein de la fonction qui peut modifier la variable écrite en argument - elle pointera toujours vers une liste - mais le traitement des ses éléments
Quelles
sont les
variables
modifiées ?
a = [0, 1, 2, 3]
a[1] = a
print(a)
[0, [...], 2, 3]
print(a[1][1][1][1][1][1][1][1][1][1][1] == a)
True| reduce() | apply a particular function passed in its argument to all of the list elements stores the intermediate result and only returns the final summation value |
| sum() | Sums up the numbers in the list |
| ord() | Returns an integer representing the Unicode code point of the given Unicode character |
| cmp() | This function returns 1, if first list is “greater” than second list |
| max() | return maximum element of given list |
| min() | return minimum element of given list |
| all() | Returns true if all element are true or if list is empty |
| any() | return true if any element of the list is true. if list is empty, return false |
| len() | Returns length of the list or size of the list |
| enumerate() | Returns enumerate object of list |
| accumulate() | apply a particular function passed in its argument to all of the list elements returns a list containing the intermediate results |
| filter() | tests if each element of a list true or not |
| map() | returns a list of the results after applying the given function to each item of a given iterable |
| lambda() | This function can have any number of arguments but only one expression, which is evaluated and returned. |
extrait de Python List - GeeksforGeeks
Map() : retourne un objet correspondant à la liste transformée
2 paramètres : une fonction qui traite de façon itérative les éléments de la liste, et la liste
a = map(lambda i: i.upper(), ['a', 'b'])
a = list(a)
print(a)
['A', 'B']a = map(len, ['un', 'deu', 'troi', 'quatr'])
a = list(a)
print(a)
[2, 3, 4, 5]a = filter(lambda i: i % 2 == 0, list(range(11)))
a = list(a)
print(a)
[0, 2, 4, 6, 8, 10]Egalement utile (mais plus complexe) : la fonction reduce() - voir liens utiles à la fin
Filter() : retourne un objet correspondant à la liste filtrée par une fonction passé en argument
Quand cette fonction retourne True, l'élement est conservé
2 paramètres : cf. map()
Sujet de veille 3
5.0 Définition
5.1 Points communs avec les listes
5.2 Du string à la liste
sommaire[5]
Un string est une séquence immuable:
on ne peut donc pas la modifier
un_string = "bonjour"
un_string[0]="B"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
Ayant "bonjour" dans la variable nouveau_string, le code correct pour mettre la première lettre en majuscule est :
nouveau_string = "B" + un_string[1:]Par contre nous pouvons tout à fait faire une boucle for sur un string
un_string = "bonjour"
une_liste = []
for i in un_string:
une_liste.append(i)
print(une_liste)
['b', 'o', 'n', 'j', 'o', 'u', 'r']
Les listes répondent aux opérateurs + et * un peu comme les strings; ils signifient la concaténation et la répétition ici aussi, sauf que le résultat est une nouvelle liste, pas un nouveau strings.
En fait, les listes répondent à toutes les opérations de séquence générales que nous pouvons utilisées sur les strings.
La méthode list() et la méthode split() nous permettent de transformer un string en liste
un_string = 'Bonjour, cher ami !'
print(list(un_string))
['B', 'o', 'n', 'j', 'o', 'u', 'r', ',', ' ', 'c', 'h', 'e', 'r', ' ',
'a', 'm', 'i', ' ', '!'] Pour séparer les mots d'une liste nous utiliserons la fonction split()
print(list(un_string.split()))
['Bonjour,', 'cher', 'ami', '!']
et inversement avec la fonction join()
une_liste = ['B', 'o', 'n', 'j', 'o', 'u', 'r', ',', ' ', 'c', 'h', 'e', 'r', ' ',
'a', 'm', 'i', ' ', '!']
nouveau_string = "".join(une_liste)
print(nouveau_string)
'Bonjour, cher ami !'
Sujet de veille 3
6.0 Qu'est-ce qu'un module ?
6.1 Itertools
6.3 Numpy
sommaire[6]
6.2 Copy
Lorsque vous quittez et entrez à nouveau dans l’interpréteur Python, tout ce que vous avez déclaré dans la session précédente est perdu.
séparer votre code dans plusieurs fichiers. Ainsi, il vous est facile de réutiliser des fonctions écrites pour un programme dans un autre sans avoir à les copier.
Pour gérer cela, Python vous permet de placer des définitions dans un fichier et de les utiliser dans un script ou une session interactive. Un tel fichier est appelé un module et les définitions d’un module peuvent être importées dans un autre module ou dans le module main (qui est le module qui contient vos variables et définitions lors de l’exécution d’un script au niveau le plus haut ou en mode interactif).
Un module est un fichier contenant des définitions et des instructions. Son nom de fichier est le nom du module suffixé de .py. À l’intérieur d’un module, son propre nom est accessible par la variable __name__.
Afin de rédiger des programmes plus longs, vous devez utiliser un éditeur de texte, préparer votre code dans un fichier et exécuter Python avec ce fichier en paramètre. Cela s’appelle créer un script. Lorsque votre programme grandit, vous pouvez
Ce module standardise un ensemble de base d'outils rapides et efficaces en mémoire qui peuvent être utilisés individuellement ou en les combinant. Ensemble, ils forment une « algèbre d'itérateurs » rendant possible la construction rapide et efficace d'outils spécialisés en Python.
Par exemple, SML fournit un outil de tabulation tabulate(f) qui produit une séquence f(0), f(1), .... Le même résultat peut être obtenu en Python en combinant map() et count() pour former map(f, count()).
Ces outils et leurs équivalents natifs fonctionnent également bien avec les fonctions optimisées du module operator. Par exemple, l'opérateur de multiplication peut être appliqué à deux vecteurs pour créer un produit scalaire efficace : sum(map(operator.mul, vecteur1, vecteur2))
Les instructions d'affectation en Python ne copient pas les objets, elles créent des liens entre la cible et l'objet. Concernant les collections qui sont muables ou contiennent des éléments muables, une copie est parfois nécessaire, pour pouvoir modifier une copie sans modifier l'autre. Ce module met à disposition des opérations de copie génériques superficielle et récursive, profonde
Numpy ajoute le type array qui est similaire à une liste (list) avec la condition supplémentaire que tous les éléments sont du même type. Nous concernant ce sera donc un tableau d’entiers, de flottants voire de booléens.
Sujet de veille 3
sommaire[7]
avantage des listes : rapidité d'accès
inconvénient : taille de stockage
=> CPU versus barrettes
Quand une liste prend beaucoup de place en mémoire,
l'on peut utiliser ce qu'on appelle des générateurs, qui sont des fonctions itérables générant leurs éléments au fur et à mesure de leurs invocations (de façon potentiellement infinie)
NB : un générateur fini peut être converti en liste en le passant comme argument à list()
# exemple tiré de http://sametmax.com/valeurs-et-references-en-python/
def encore_une_fonction_d_exemple_inutile(l):
for x in l:
yield x
yield 4
By G. Lghd
Veille sur les listes, Bastien S. et Gaëtan L. : version linéaire et sans animation, support de la version avec styles pdf [adaptée de la mauvaise version (1 : vo corr) importée via HTML]



