Arquitectura de análisis de datos estructurados mixtos multivariados de alta dimensionalidad con un enfoque de aprendizaje automático
Presents: Jacobo G. González León
6th PDTA
Thesis advisors:
- PhD. Miguel Félix Mata Rivera
- PhD. Rolando Menchaca Méndez



Introducción
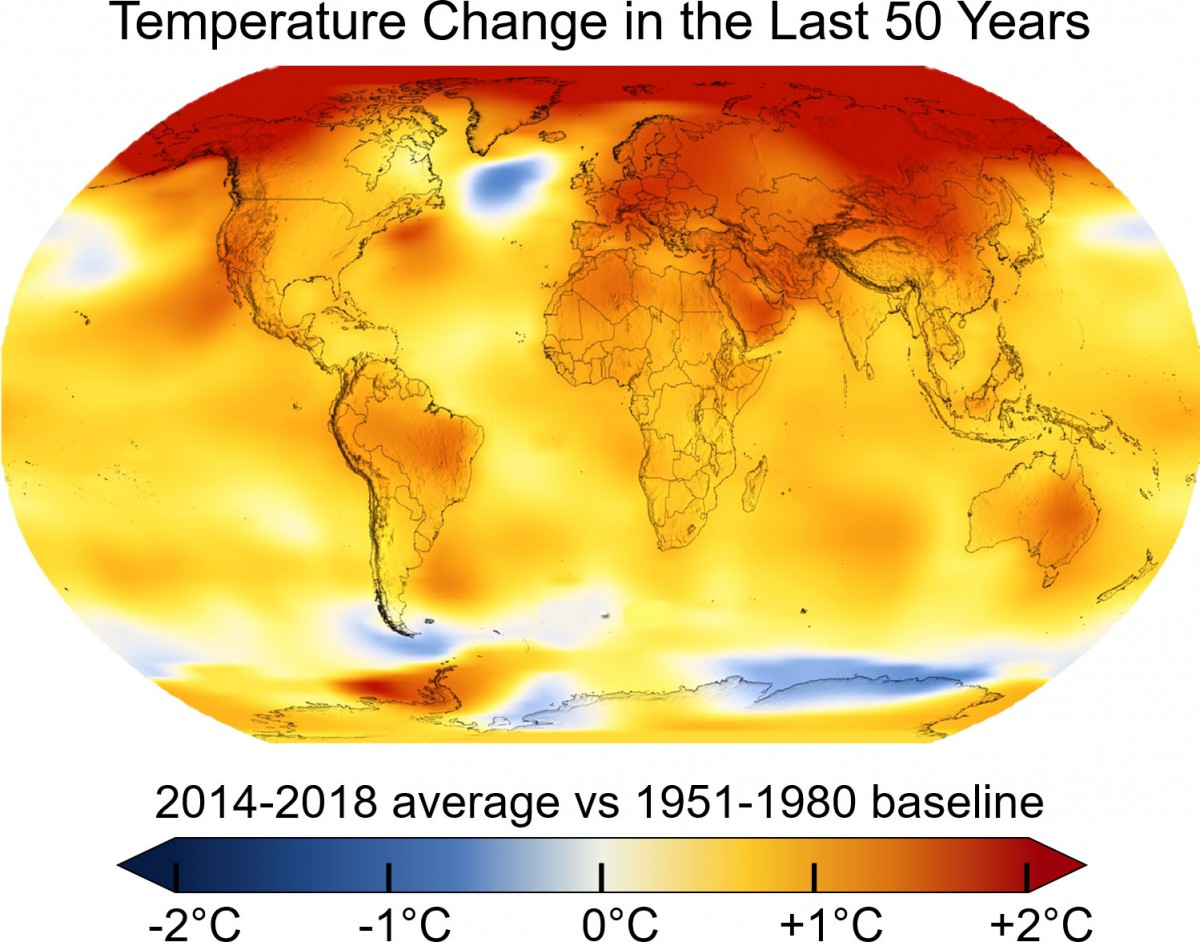
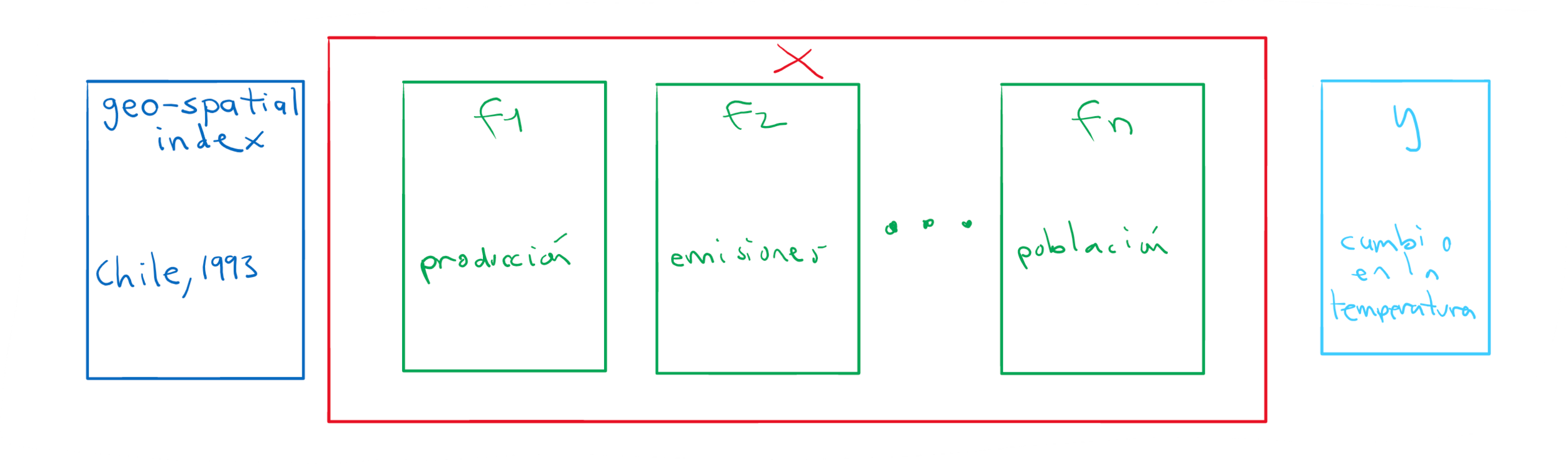
Caso de estudio: cambio climático.
Tesis: encontrar relaciones entre características (indicadores agrícolas) y el cambio de temperatura de los países.
Metodología de investigación: análisis de datos estructurados mixtos multivariados de alta dimensionalidad con un enfoque de aprendizaje automático.
Objetivo principal: encontrar relaciones entre características explicativas (X) y una variable explicada (y).
Hipótesis
Model
Data
«La ciencia (ἐπιστήμη) es un juicio verdadero acompañado de razón (λόγος).» Platón, Teeteto, 202, b-c
Tesis: encontrar relaciones entre características (indicadores agrícolas) y el cambio de temperatura de los países.
Tesis: encontrar relaciones entre características (indicadores agrícolas) y el cambio de temperatura de los países.
¿Cómo son estas relaciones?
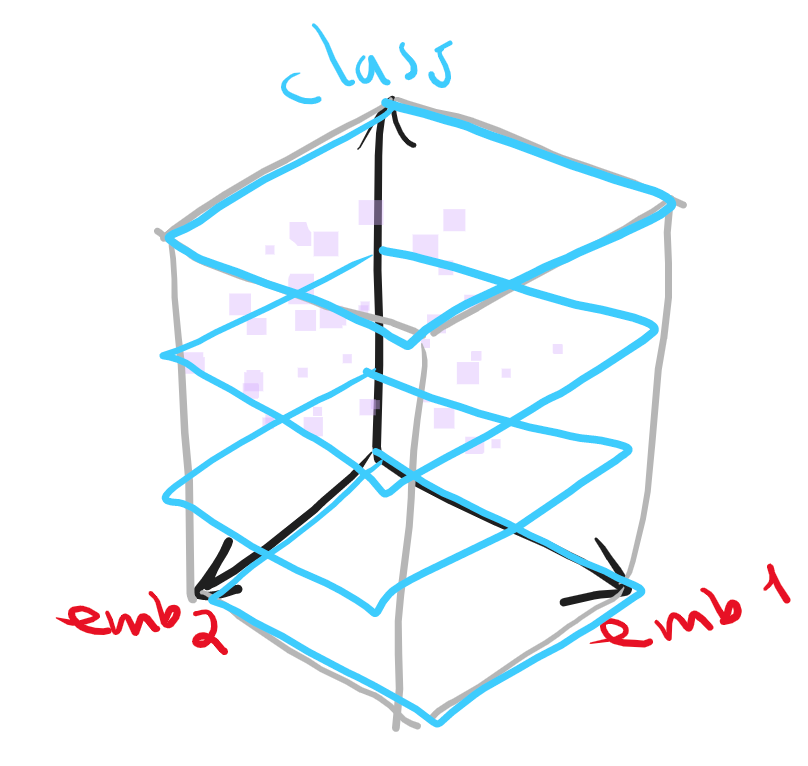
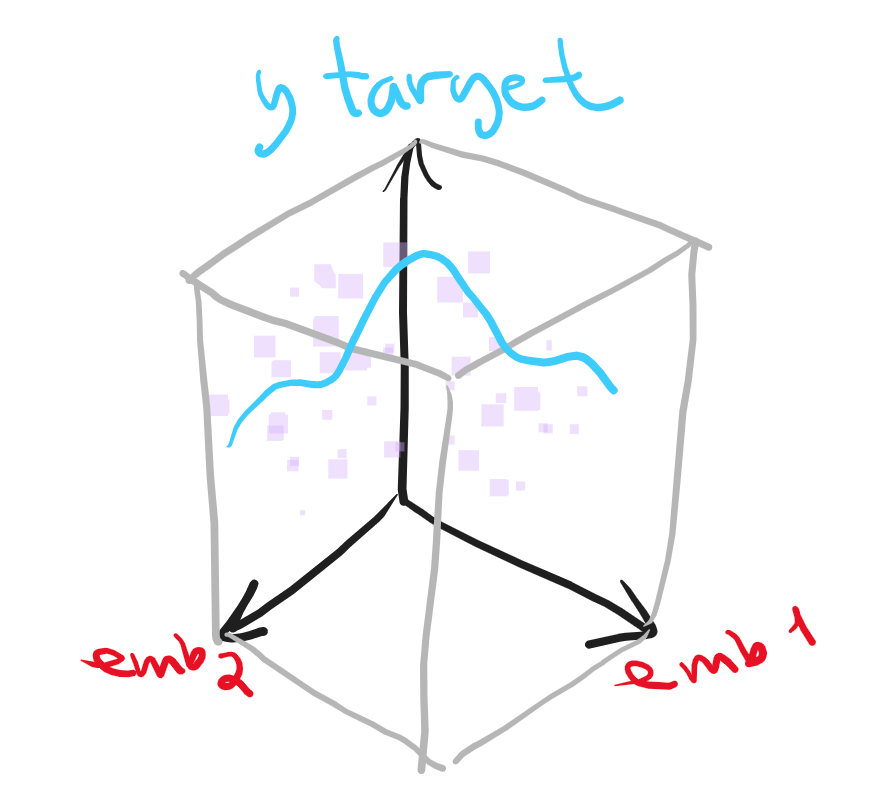
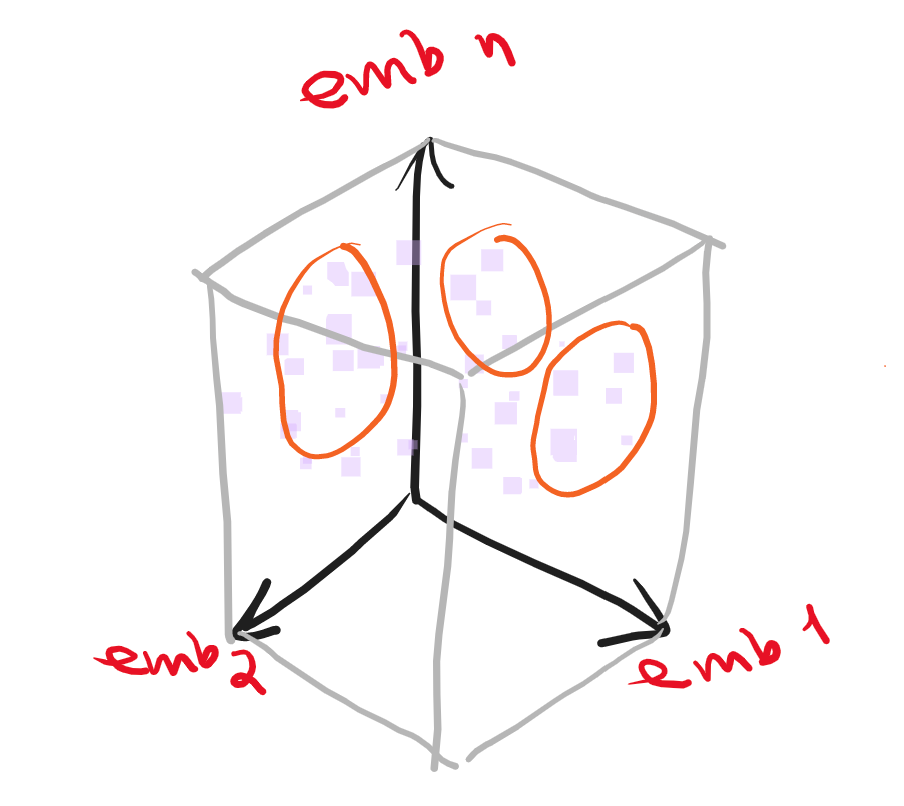
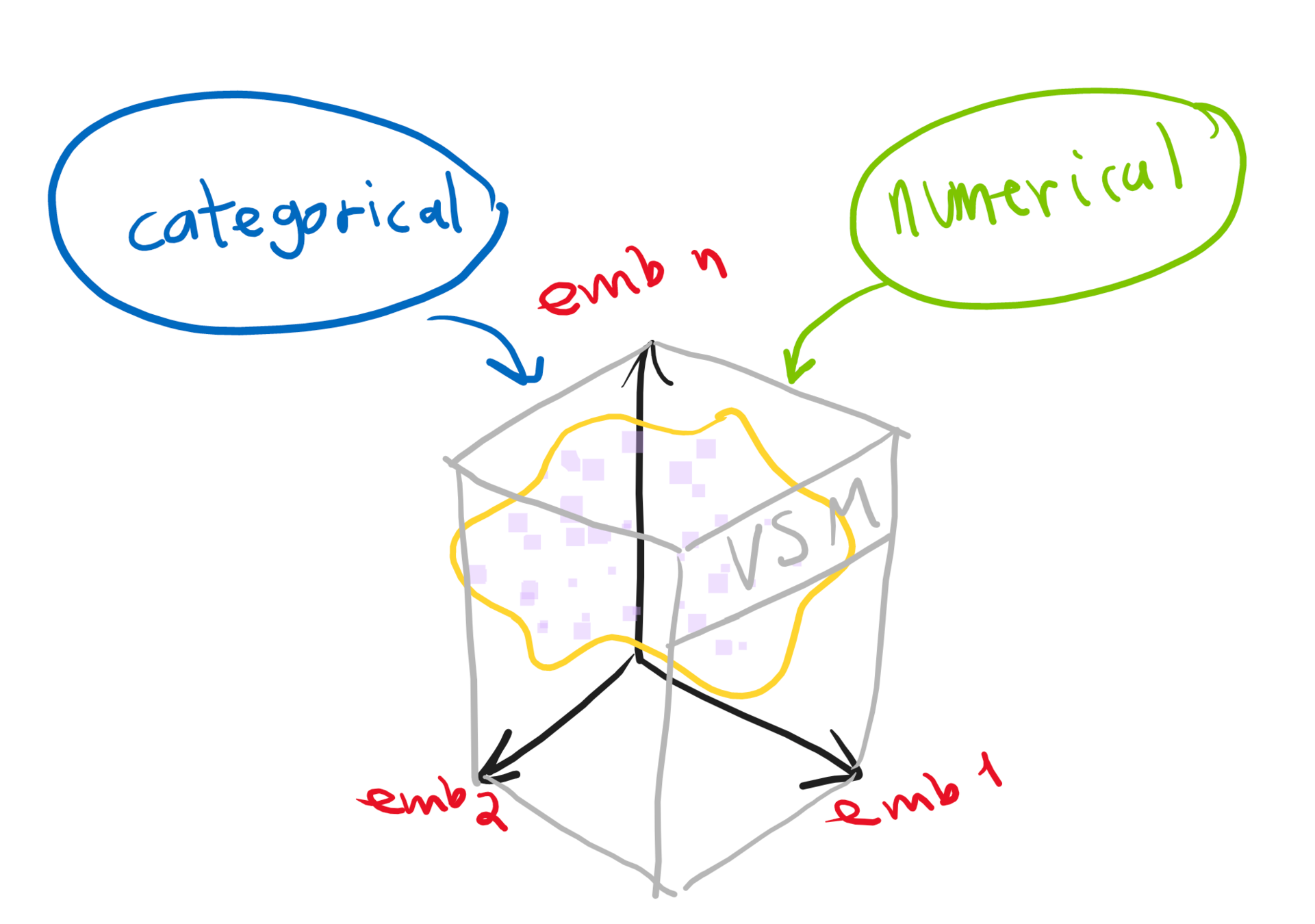
Modelos en el VSM (Vector Space Model)


Dimensiones del VSM
Tesis: encontrar relaciones entre características (indicadores agrícolas) y el cambio de temperatura de los países.
¿Cómo son estas relaciones?
Objetivo principal: encontrar relaciones entre características explicativas (X) y una variable explicada (y).
Supervised modeling approach: mediante la evaluación del modelo, medir la capacidad de la función de aproximación para predecir ciertas categorías o clases de datos.
Unsupervised modeling approach: mediante algún índice interno, encontrar la "estructura natural" del conjunto de datos.

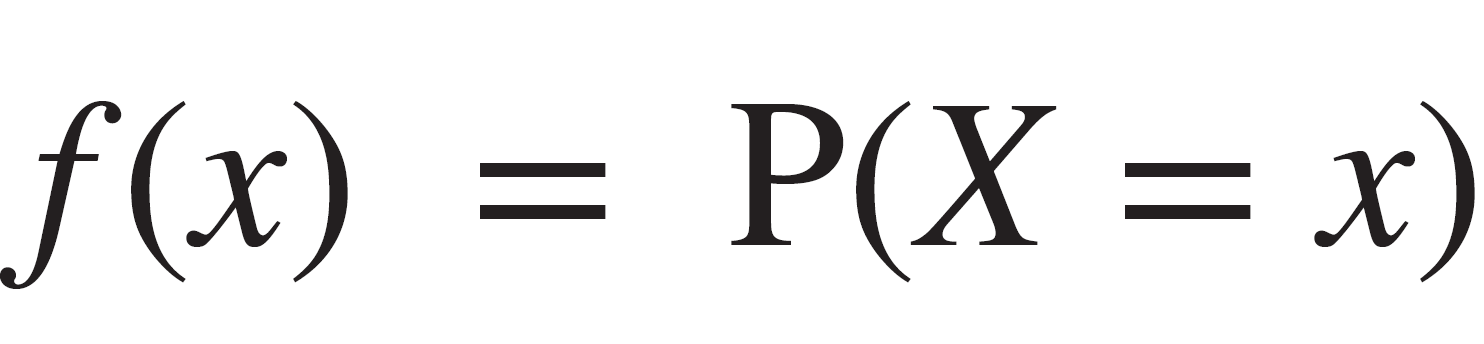
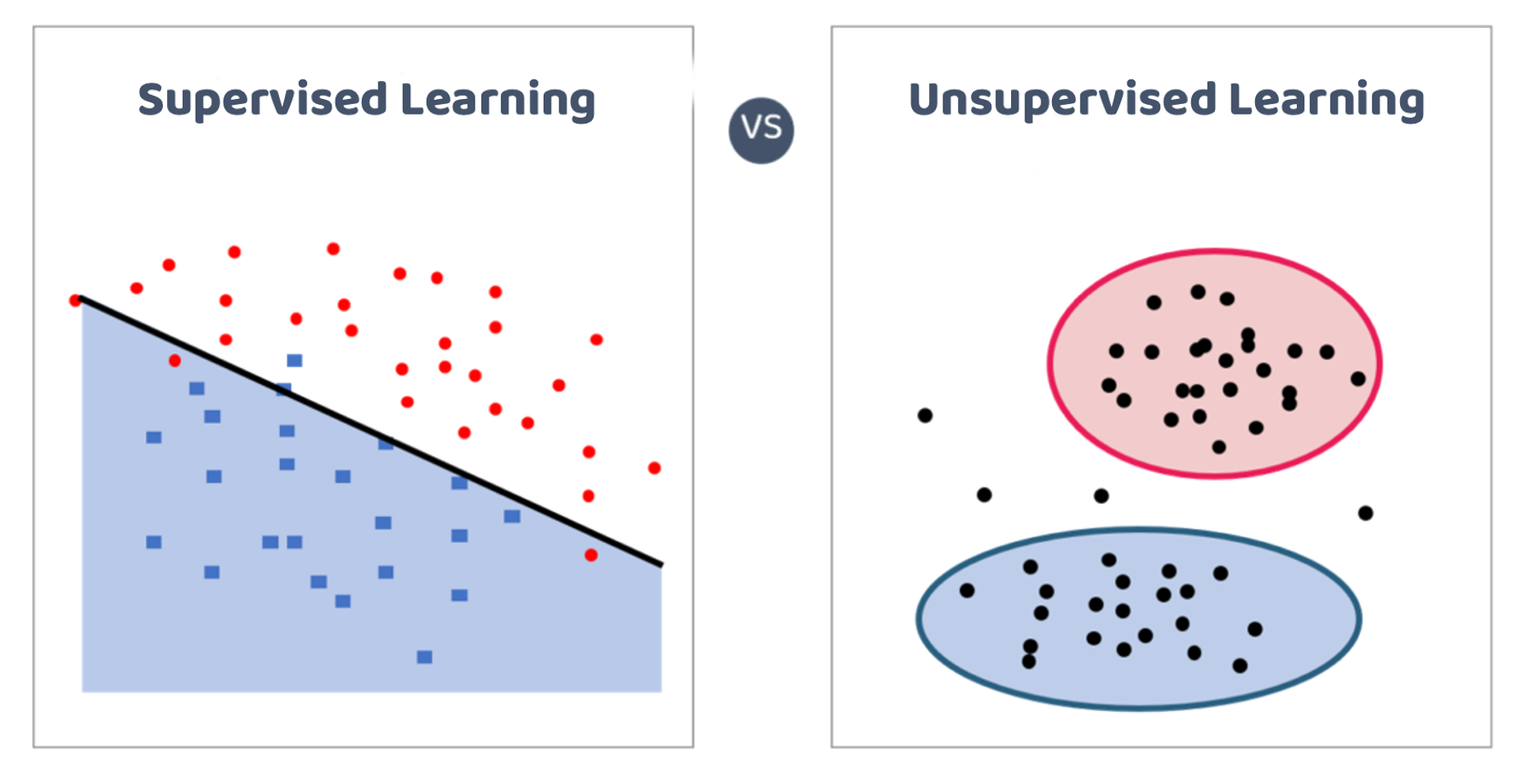
Enfoques y métodos de aprendizaje automático en el VSM
¿Cómo encontrar estas relaciones?
Metodología de investigación:
análisis de datos estructurados mixtos multivariados de alta dimensionalidad con un enfoque de aprendizaje automático
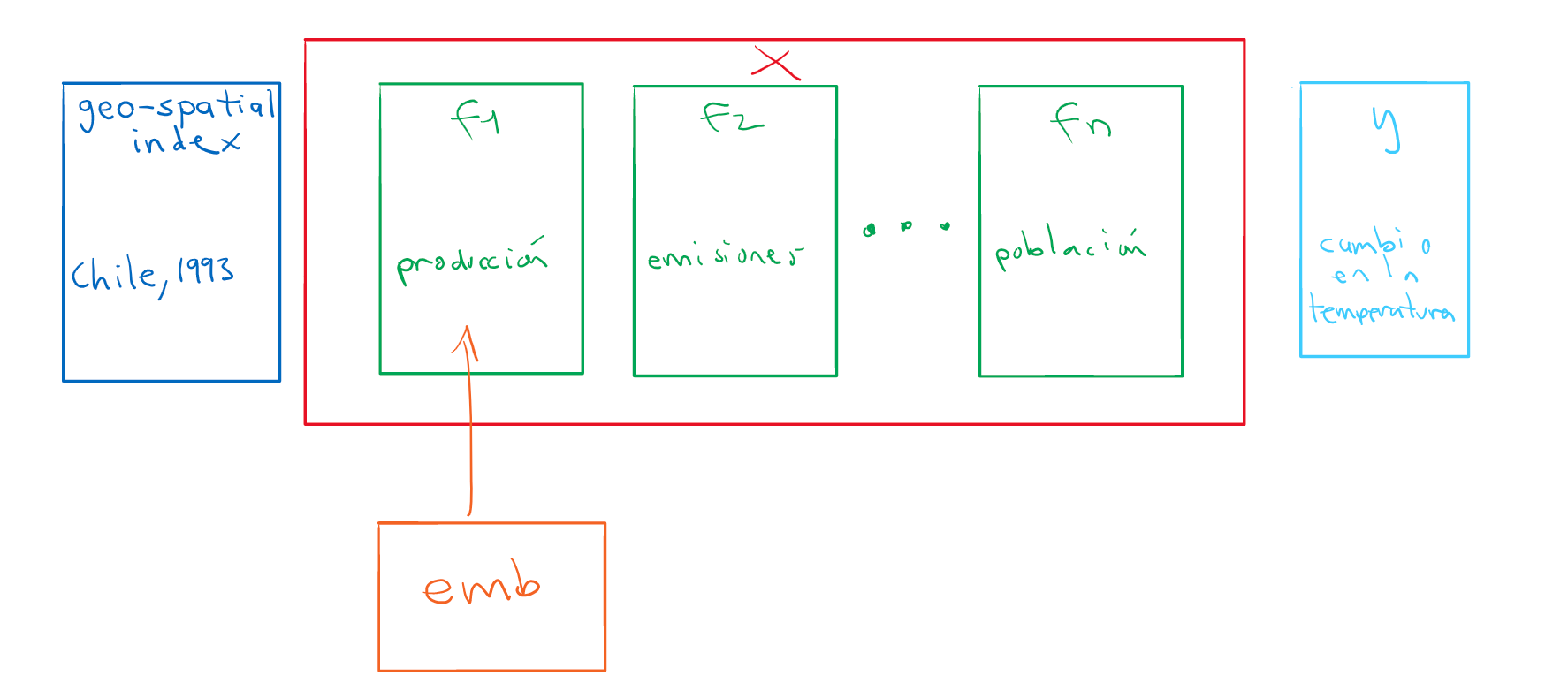
Representación vectorial:
- preprocessed data, dimensionalidad alta
- embeddings, dimensionalidad reducida
1
2
3
¿Cómo obtener esta representación reducida?
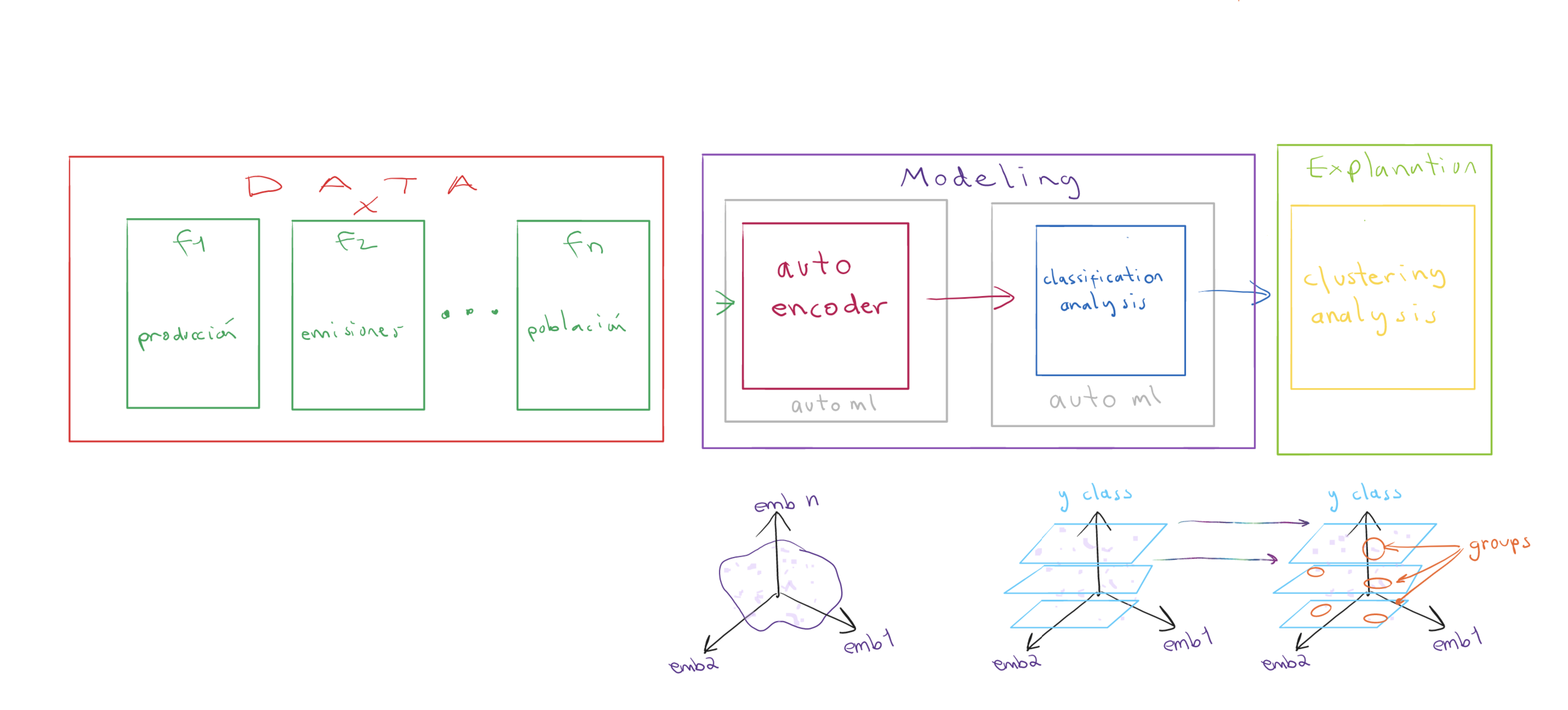
Flujo del procesamiento
(end-to-end pipeline)
Metodología de investigación:
análisis de datos estructurados mixtos multivariados de alta dimensionalidad con un enfoque de aprendizaje automático
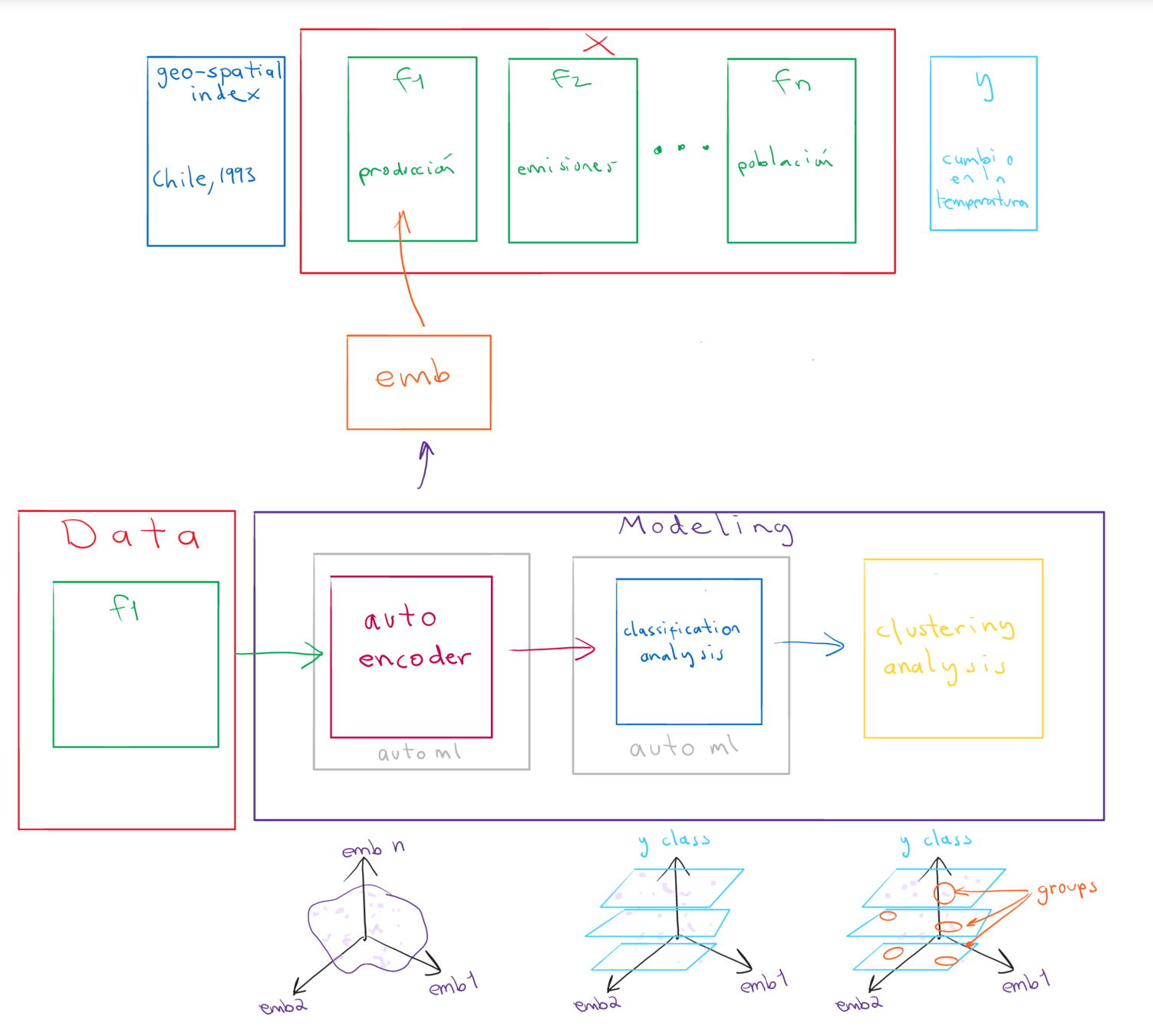
Metodología de investigación:
análisis de datos estructurados mixtos multivariados de alta dimensionalidad con un enfoque de aprendizaje automático
Preguntas de investigación:
- ¿Cuál es el preprocesamiento que deberían llevar los datos?
- ¿Cómo implementar métodos de aprendizaje automático en el flujo de procesamiento de la arquitectura de análisis de datos?
- ¿Cómo se define la función de aprendizaje del modelo encontrado?
Trabajos relacionados
Por datos : "supervised learning on tabular data"
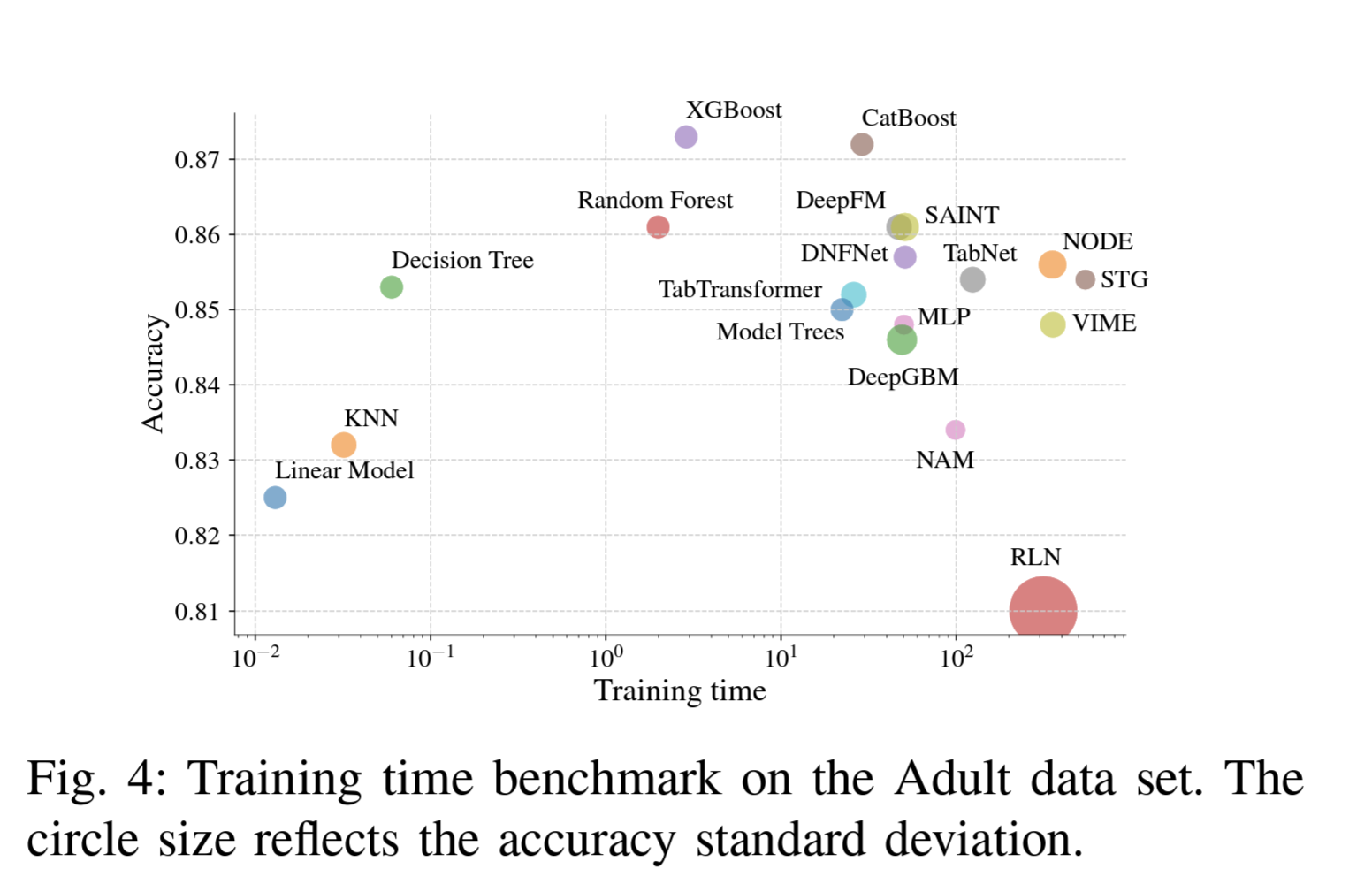
Open Research Questions:
- Information-theoretic Analysis of Encodings.
- Spezialized Regularizations.
- Novel Processes for Tabular Data Generation.
- Interpretablity.
- Transfer of Deep Learning Methods to Data Streams.
- Data Augmentation for Tabular Data.
- Self-supervised Learning.
Borisov, V., Leemann, T., Seßler, K., Haug, J., Pawelczyk, M., & Kasneci, G. (2021). Deep neural networks and tabular data: A survey. arXiv preprint arXiv:2110.01889.
Trabajos relacionados
Por datos : "latent space on tabular data"
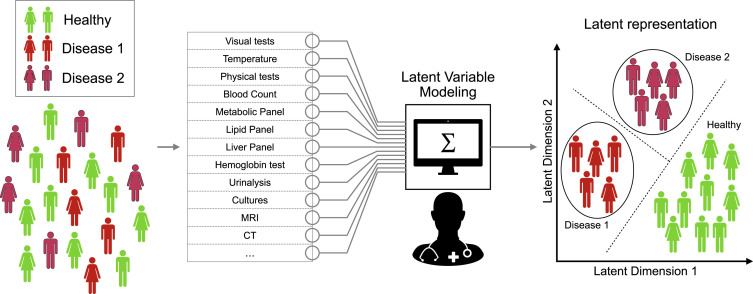
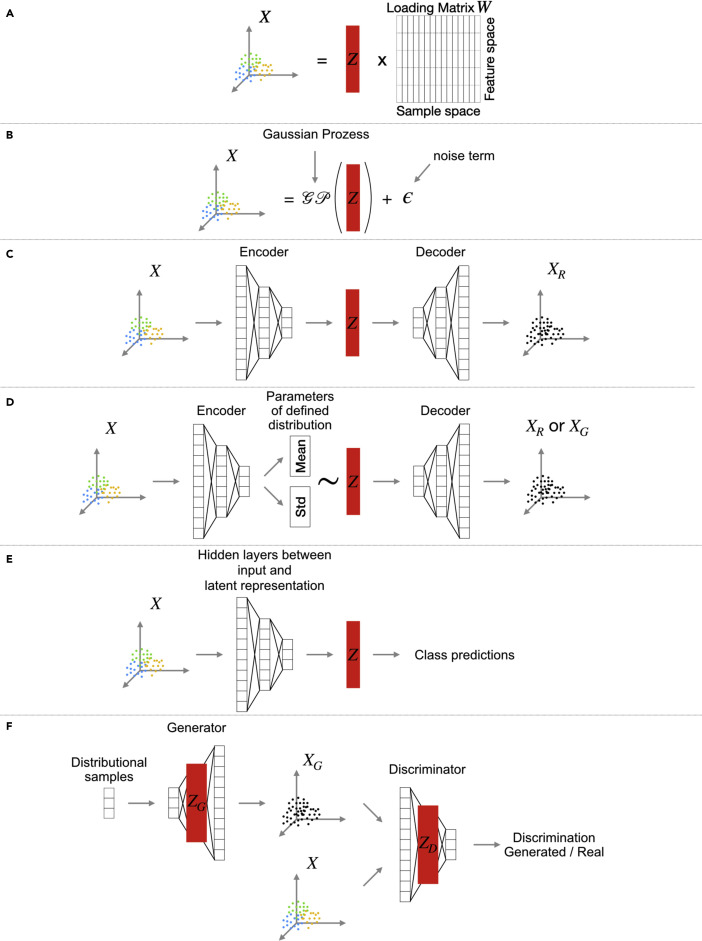
Andreas Kopf, Manfred Claassen, Latent representation learning in biology and translational medicine, Patterns, Volume 2, Issue 3, 2021, 100198, ISSN 2666-3899, https://doi.org/10.1016/j.patter.2021.100198.
Andreas Kopf, Manfred Claassen, Latent representation learning in biology and translational medicine, Patterns, Volume 2, Issue 3, 2021, 100198, ISSN 2666-3899, https://doi.org/10.1016/j.patter.2021.100198.
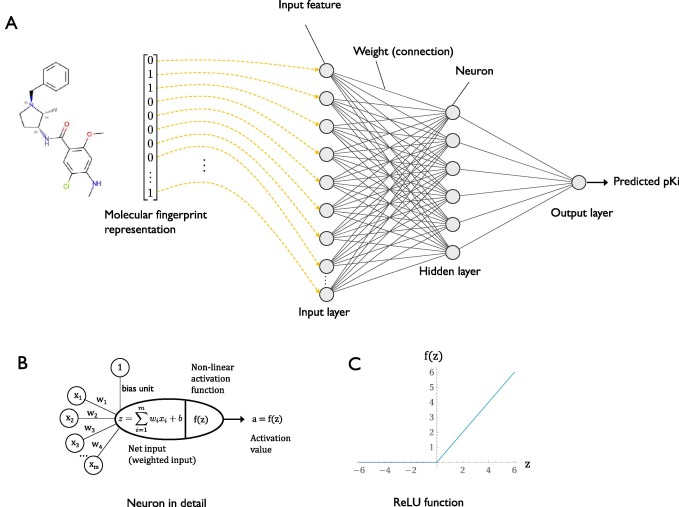
Andreas Kopf, Manfred Claassen, Latent representation learning in biology and translational medicine, Patterns, Volume 2, Issue 3, 2021, 100198, ISSN 2666-3899, https://doi.org/10.1016/j.patter.2021.100198.
Resultados preeliminares:
Entendimiento del caso de estudio

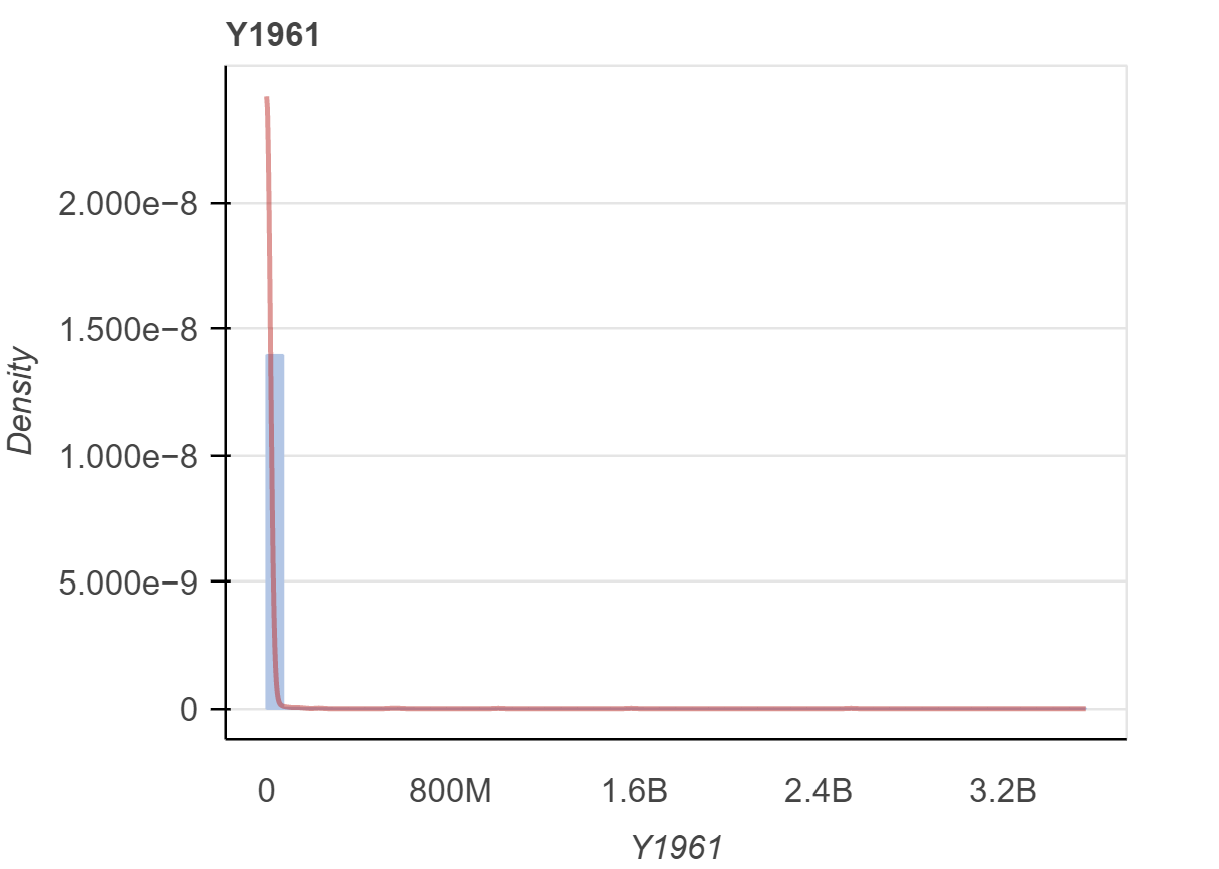
Resultados preeliminares:
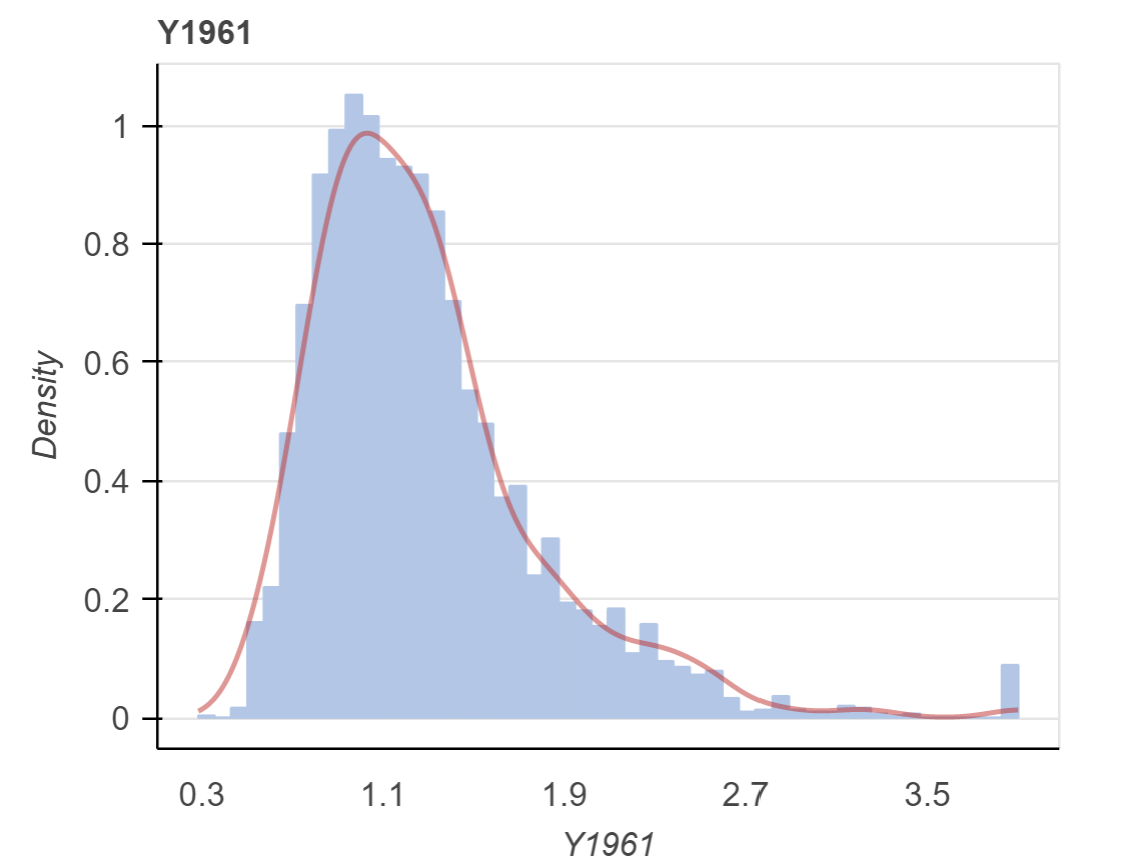
Transformación logarítmica al target

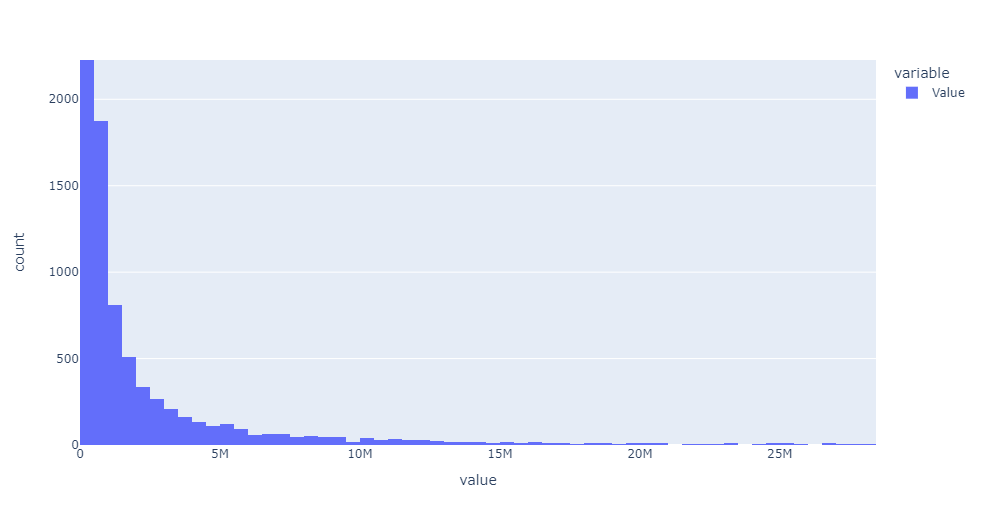
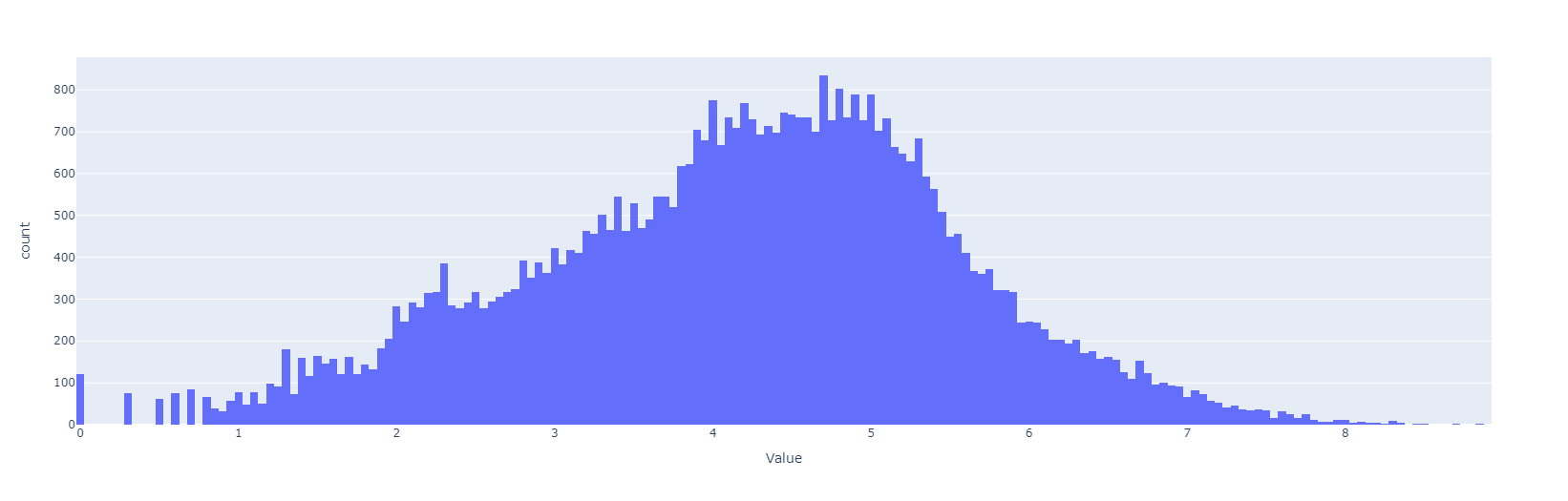
Total data dim: (2,371,943; 6)
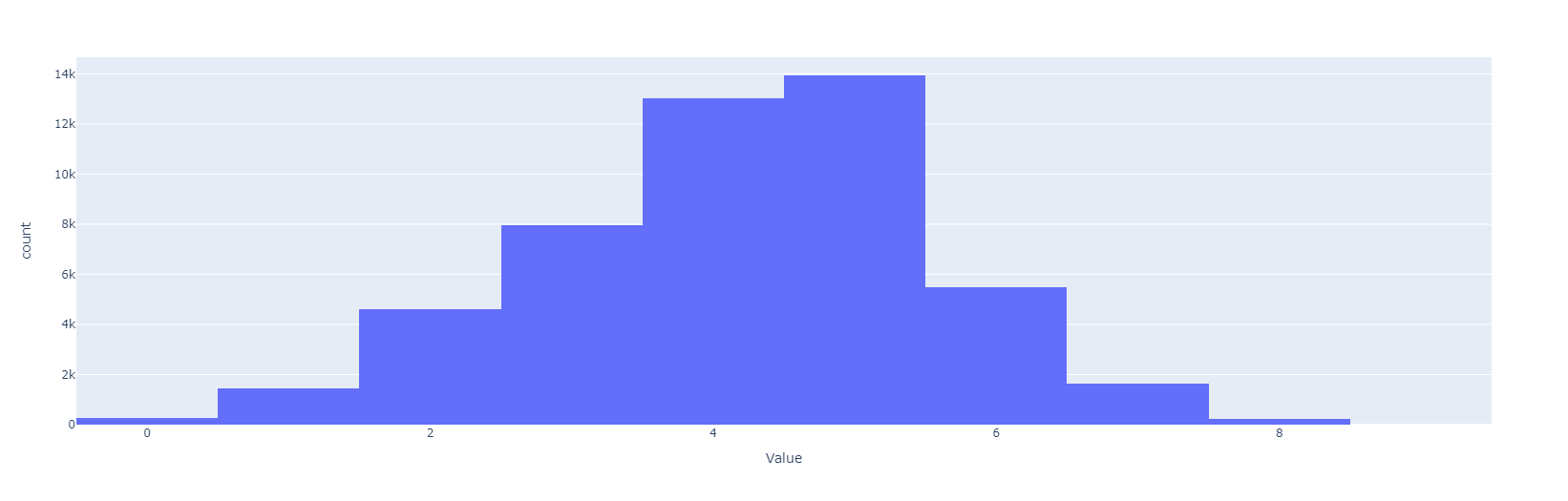
Resultados preeliminares:
Discretización de la transformación logarítmica al target
Resultados preeliminares:
Esquema integrado de las características



Resultados preeliminares:
Preprocesamiento de datos numéricos
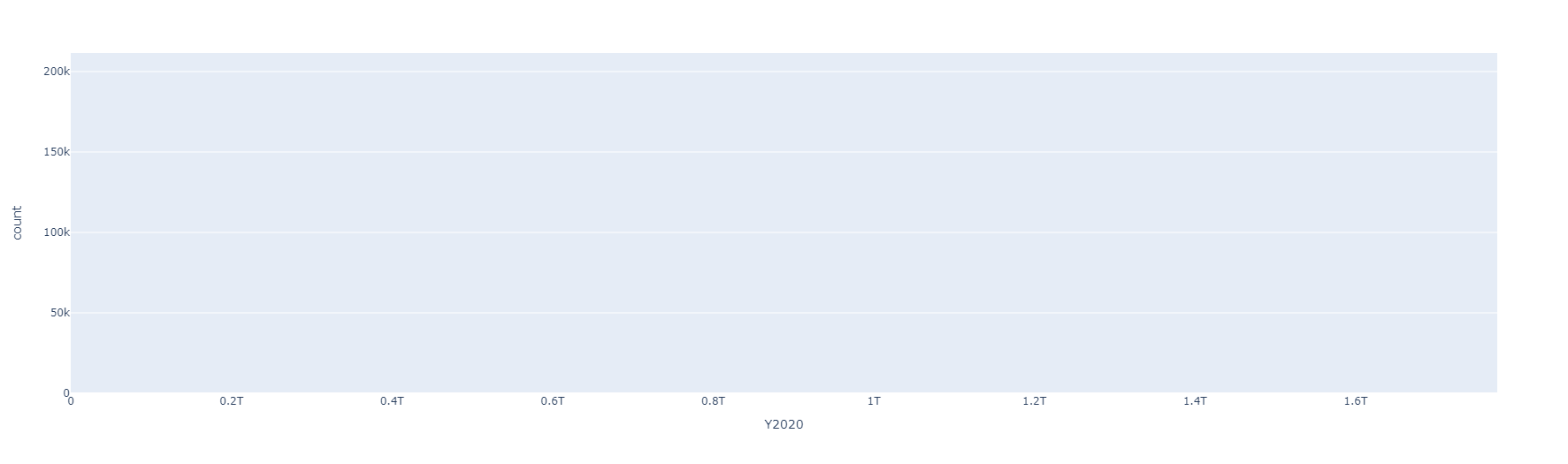
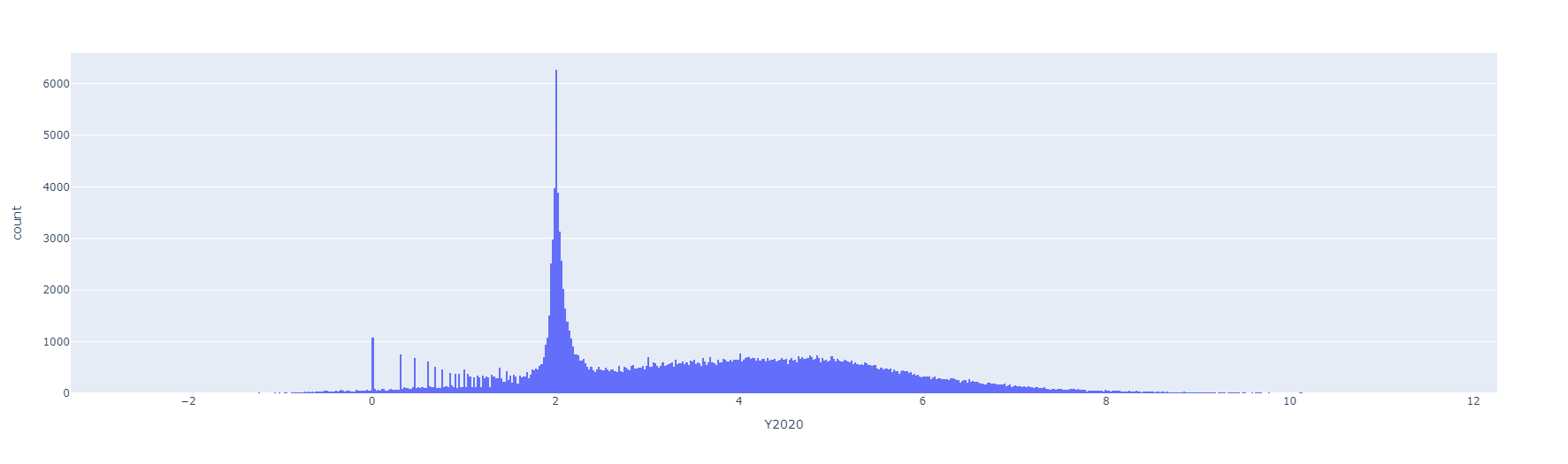
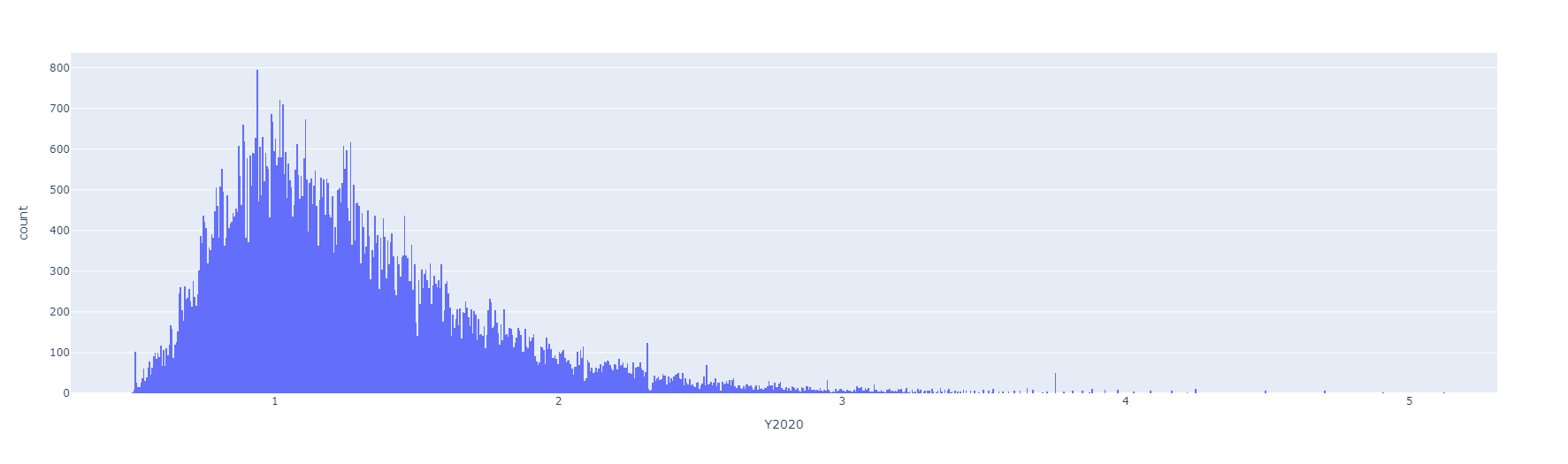
Resultados preeliminares:
Preprocesamiento de datos categóricos
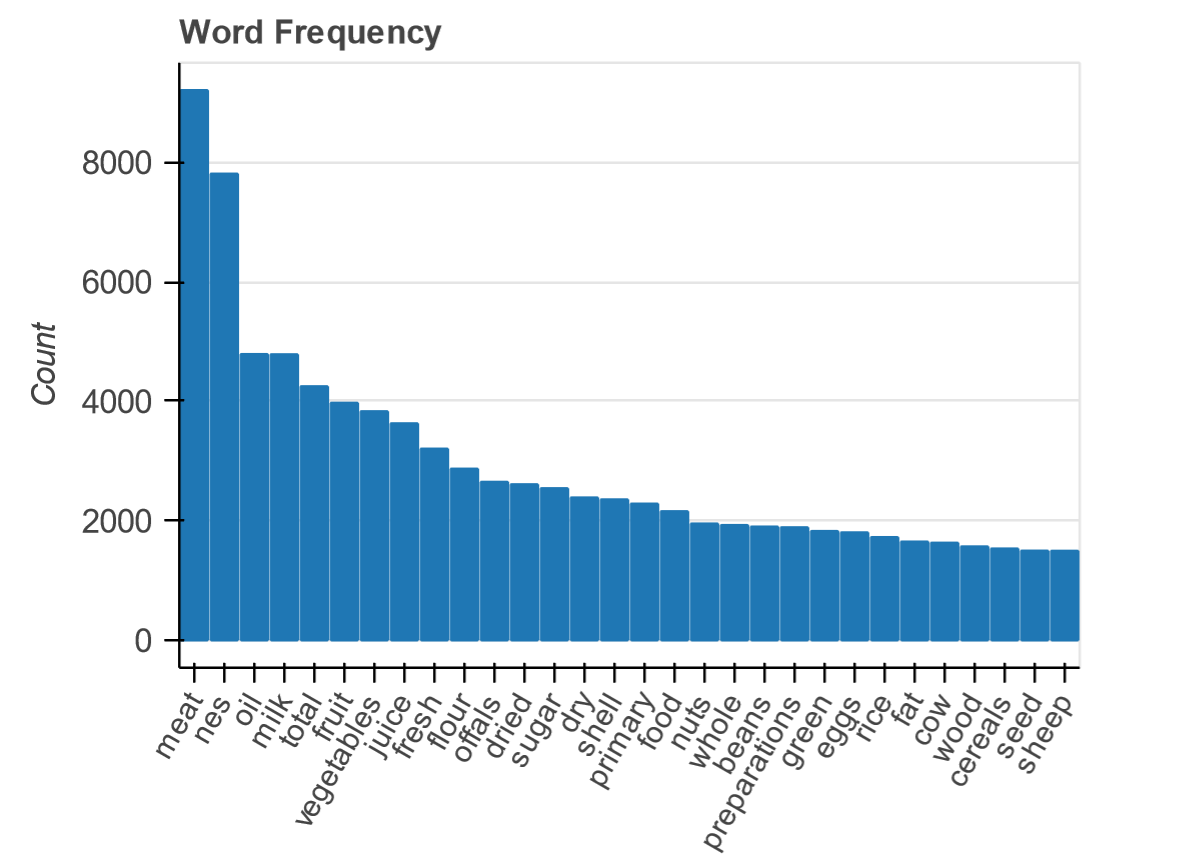
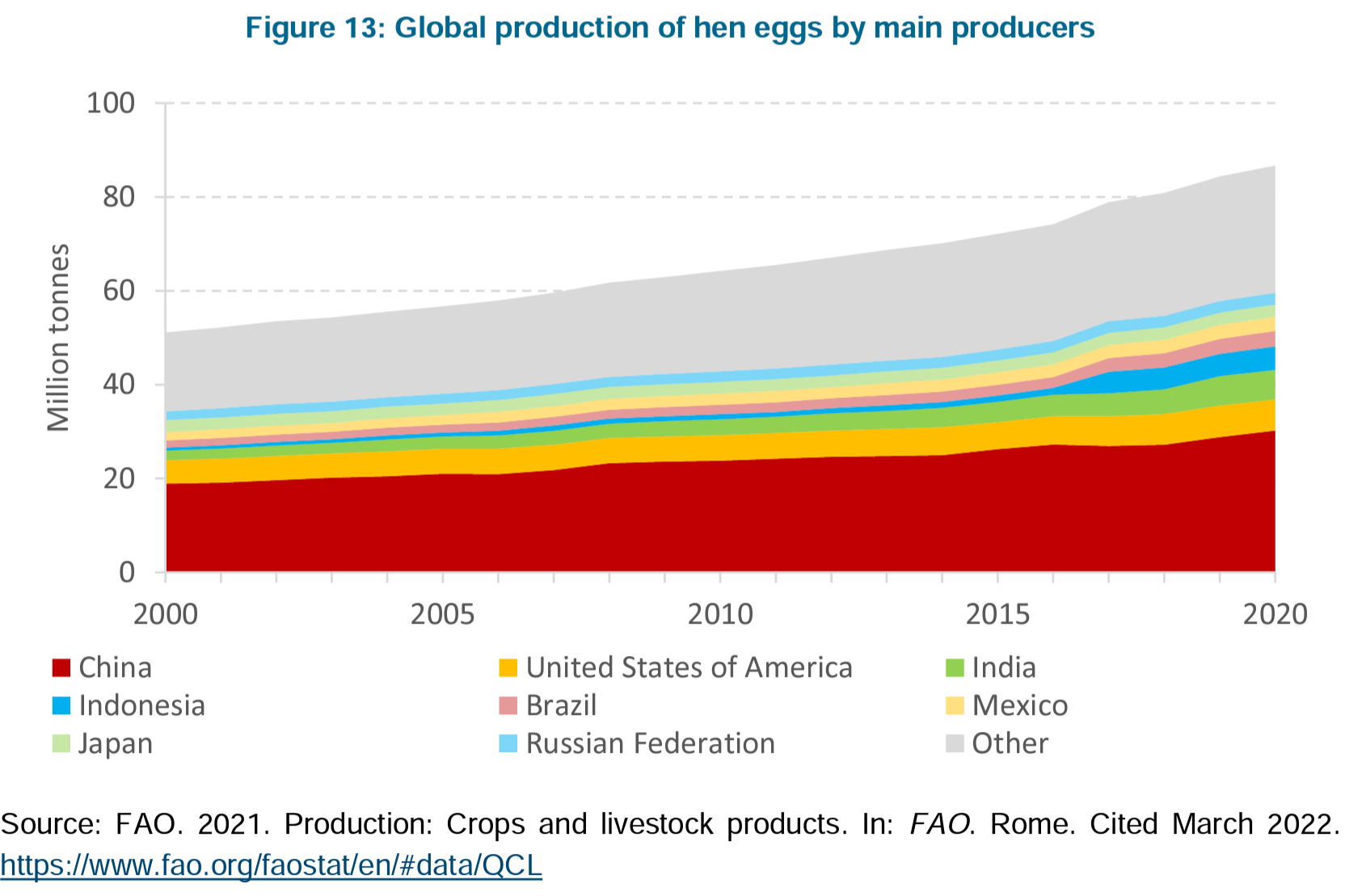
Top 5 países:
'china', 'mexico', 'turkey', 'spain', 'morocco',
Top 5 actividades económicas:
'production', 'yield', 'area harvested', 'producing animals/slaughtere', 'stocks',
Top 5 productos:
'eggs hen in shell', 'meat poultry', 'vegetables primary', 'eggs primary, 'meat chicken',
Resultados preeliminares:
Subcojuntos estratificados de entrenamiento, prueba, y validación
| Train: 80% | Test: 10% | Val: 10% |
|---|
| Train-I: 40% | Train-II: 40% |
|---|
| Train-IIa: 20% |
|---|
| Train-IIb: 20% |
| Train-Ia: 20% |
|---|
| Train-Ib: 20% |
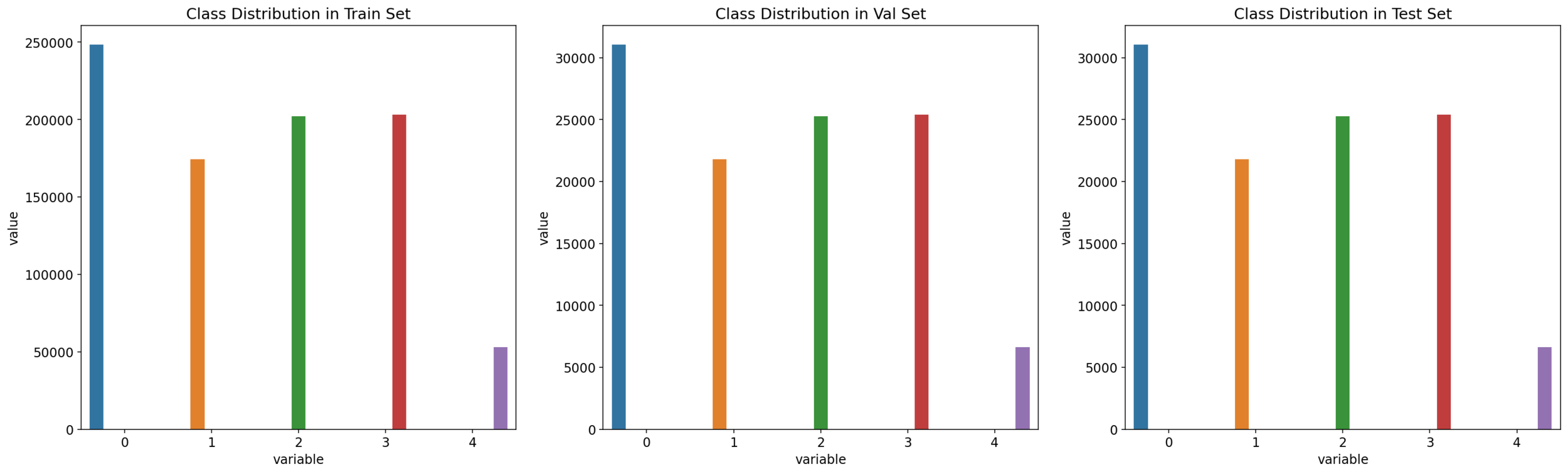
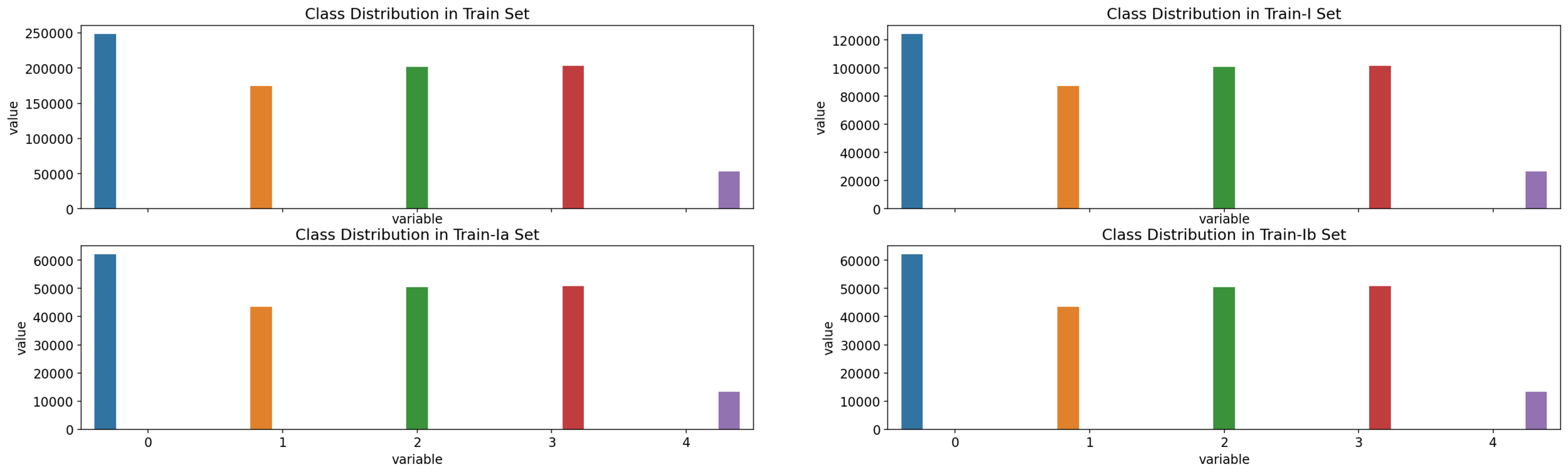
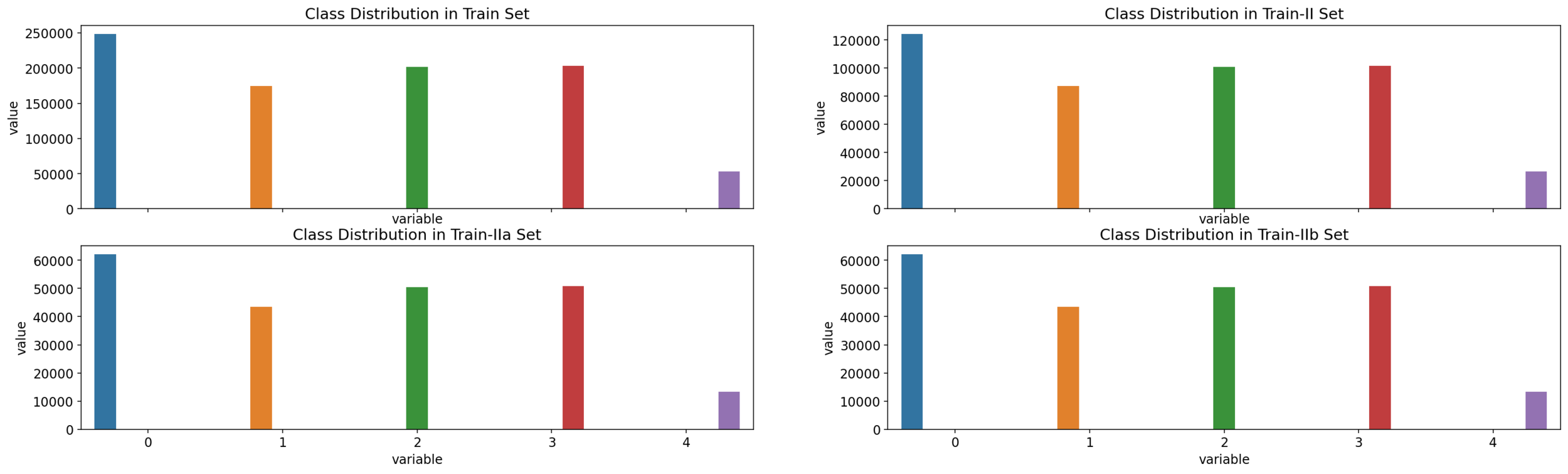
Resultados preeliminares:
VSM con datos preprocesados
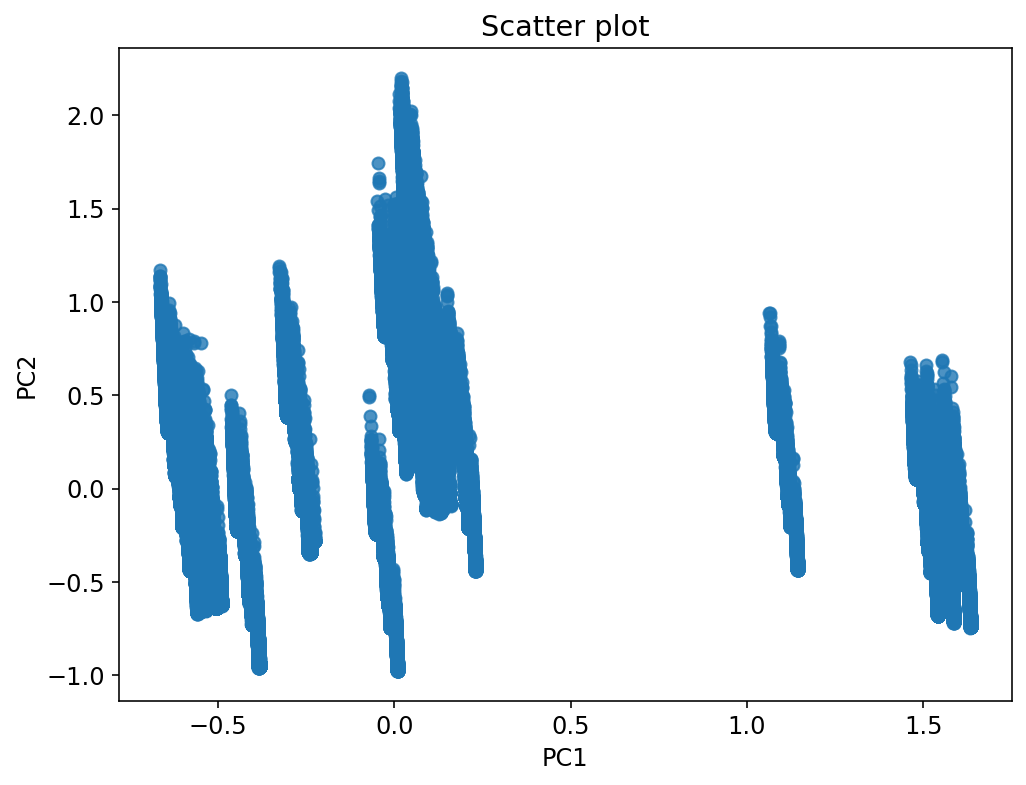
Resultados preeliminares:
Autoencoder y el espacio latente
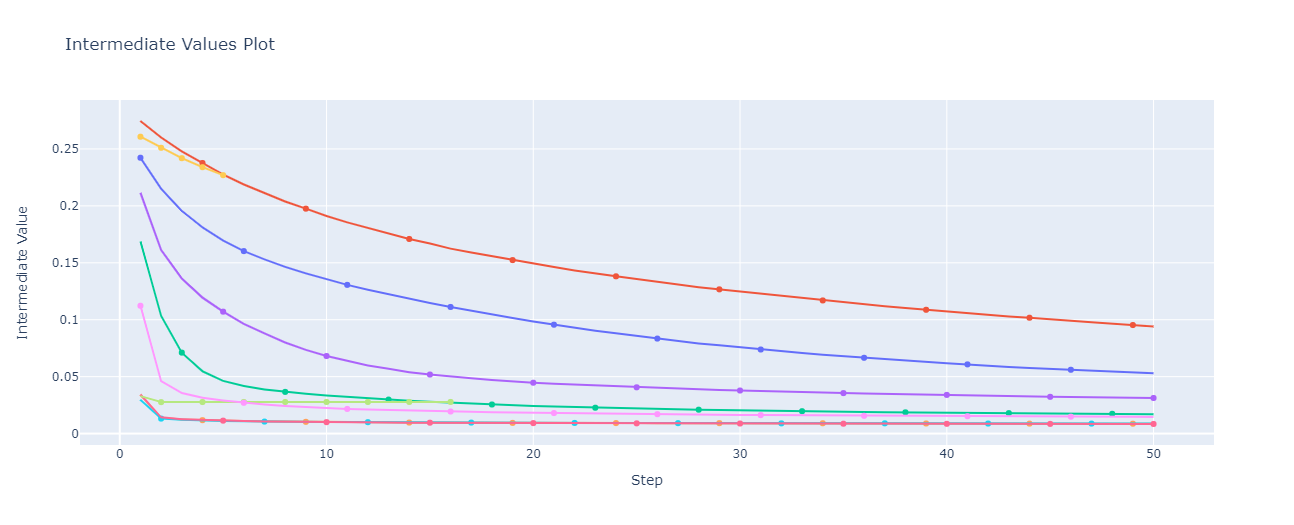
Error de reconstrucción
Arquitectura del autoencoder
-
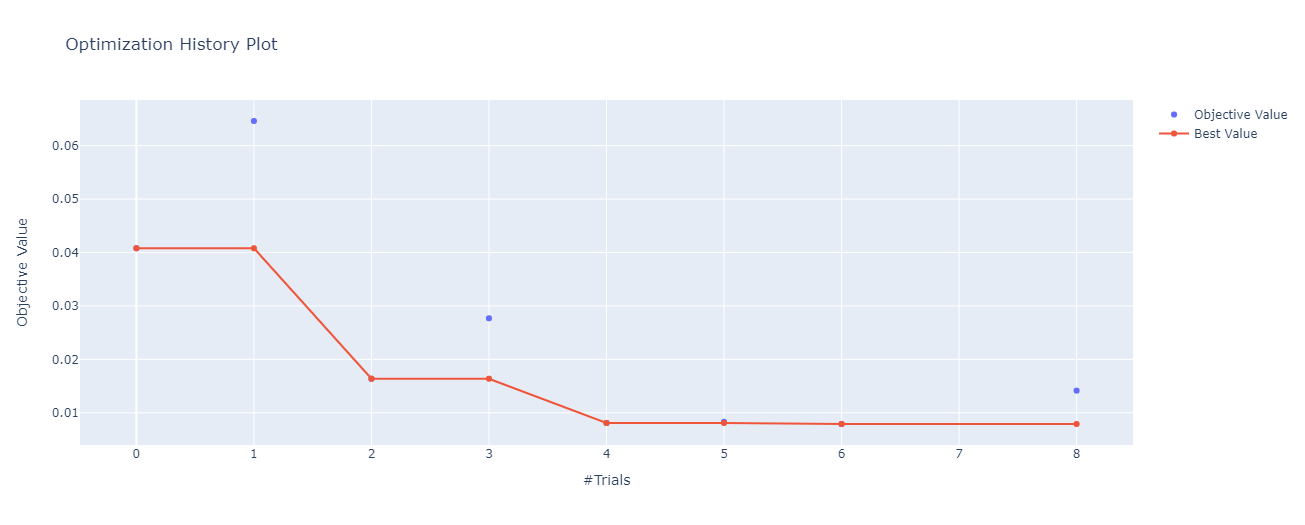
Study statistics:
- Number of finished trials: 10
- Number of pruned trials: 2
- Number of complete trials: 8
-
Best trial:
- Value: 0.007892153076014048
-
Params:
- fc1_encoder_dim: 88
- fc2_encoder_dim: 48
- fc3_encoder_dim: 24
- latent_space_dim: 16
- fc1_decoder_dim: 48
- fc2_decoder_dim: 48
- fc3_decoder_dim: 88
- optimizer: Adam
- lr: 0.001
- batch_size: 256
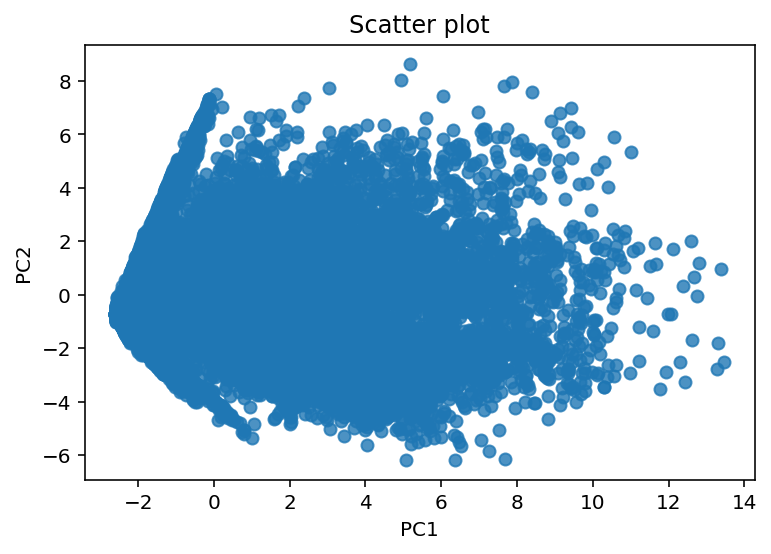
Resultados preeliminares:
VSM del espacio latente
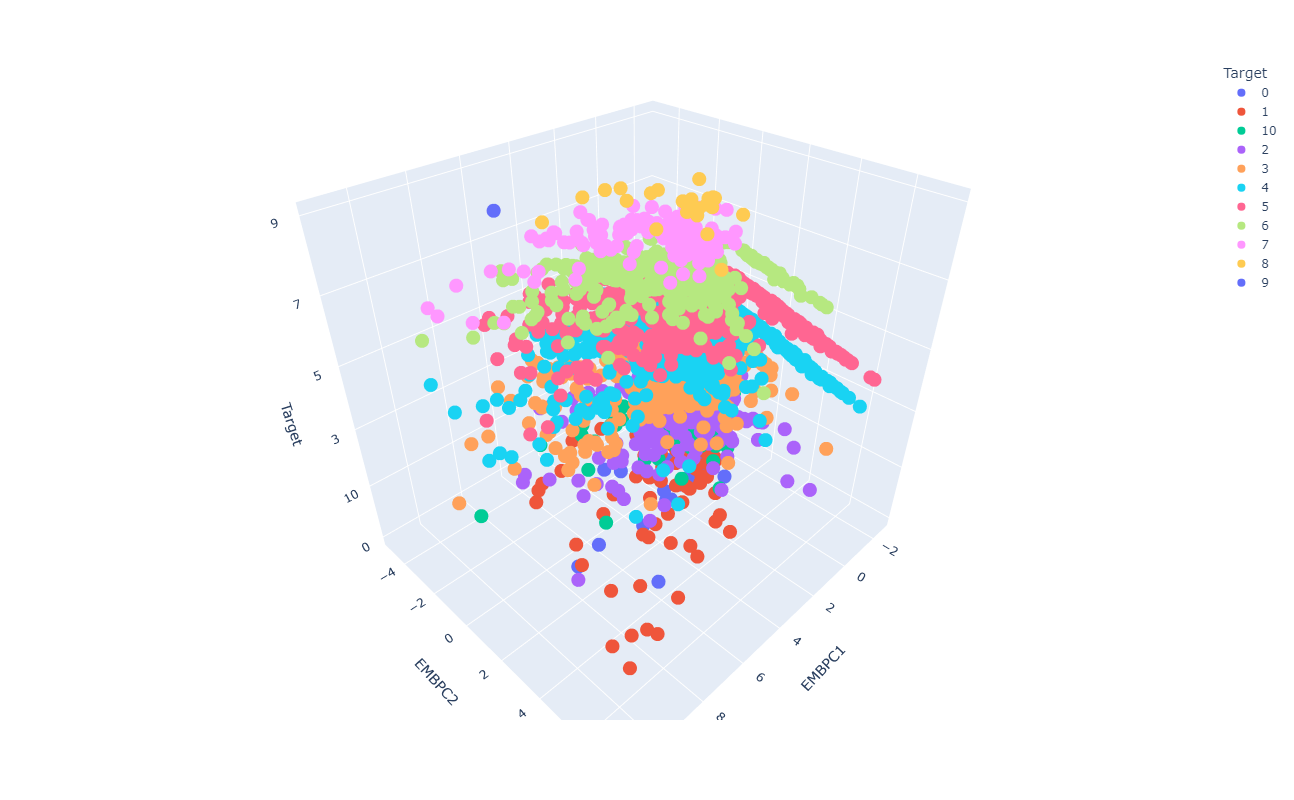
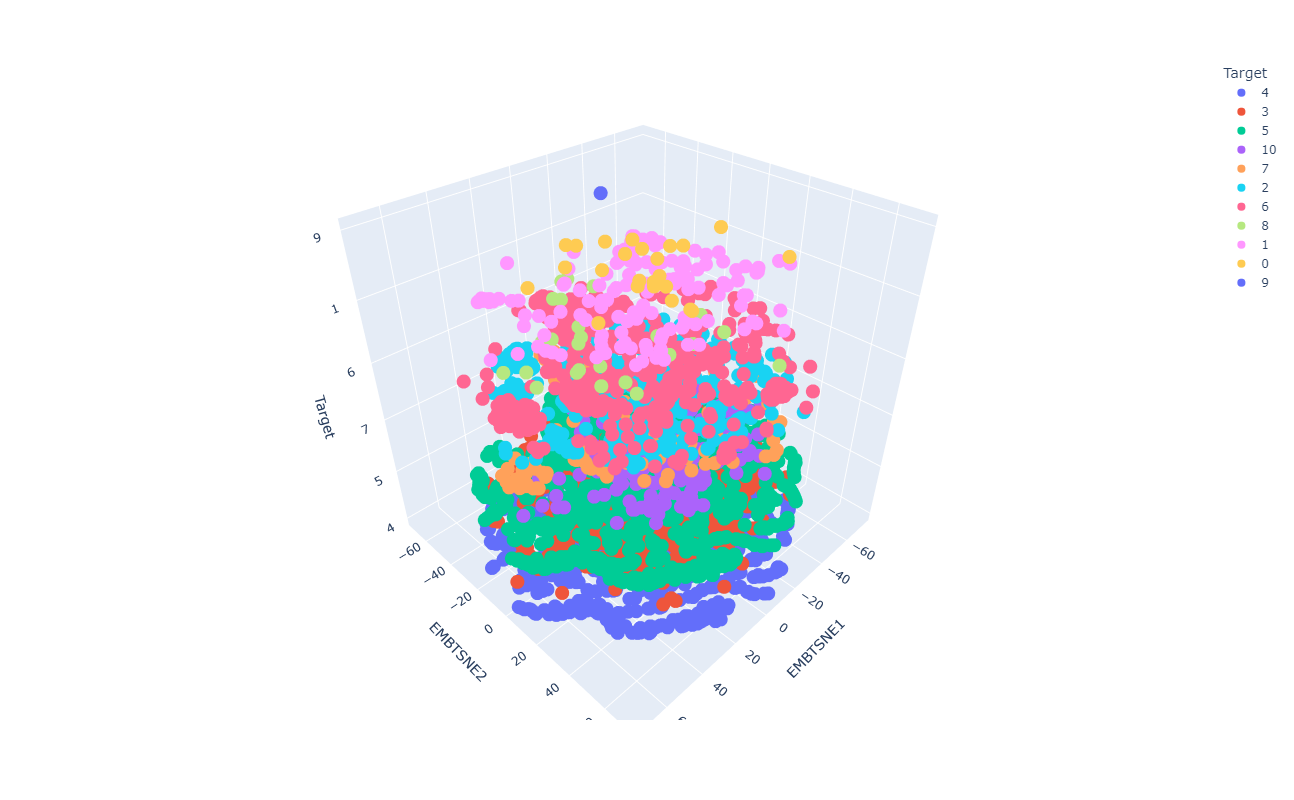
Resultados preeliminares:
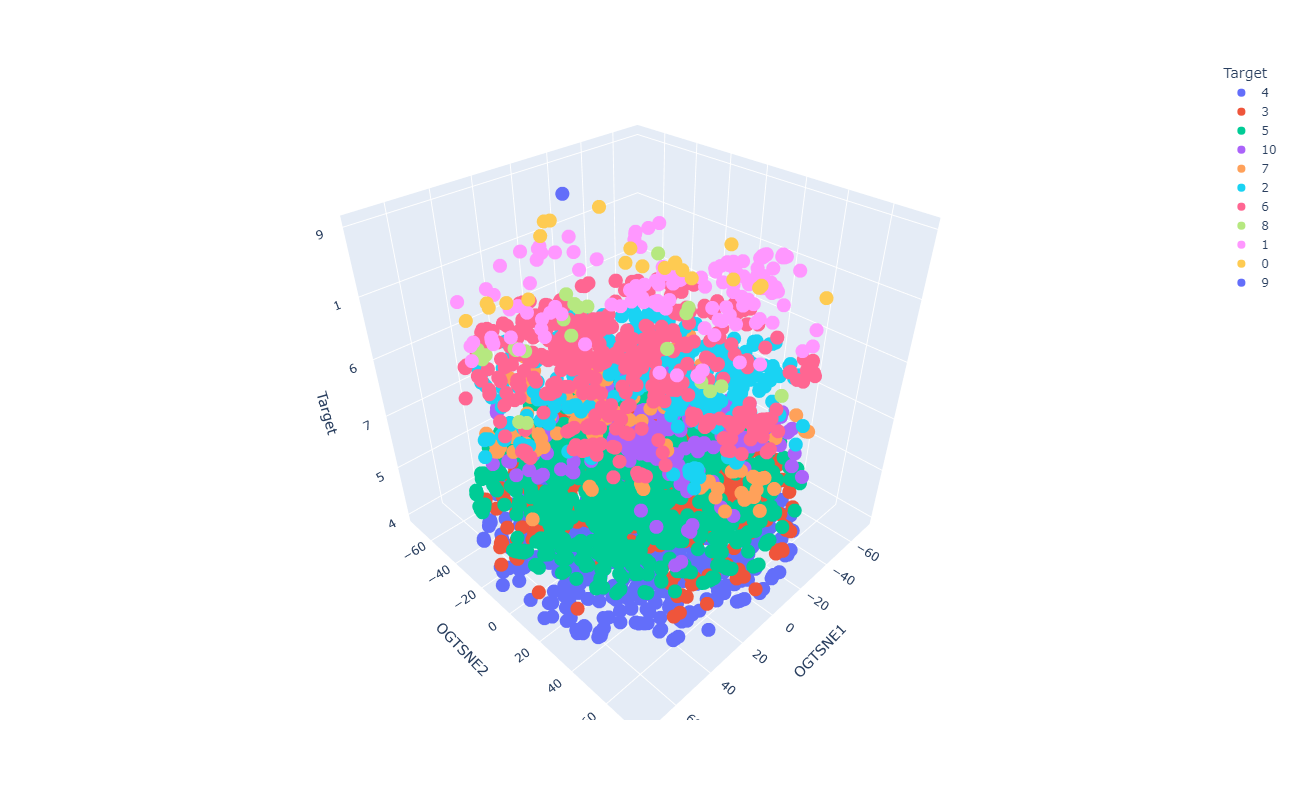
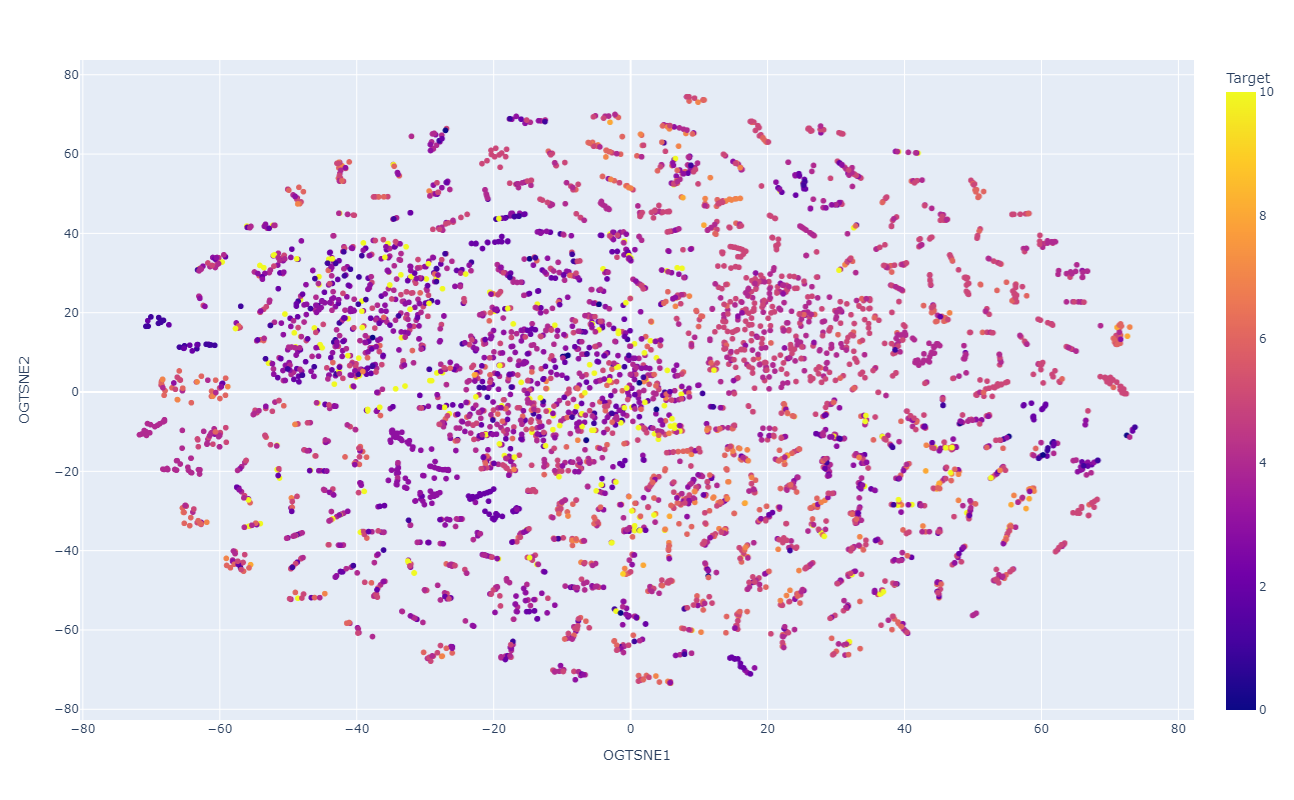
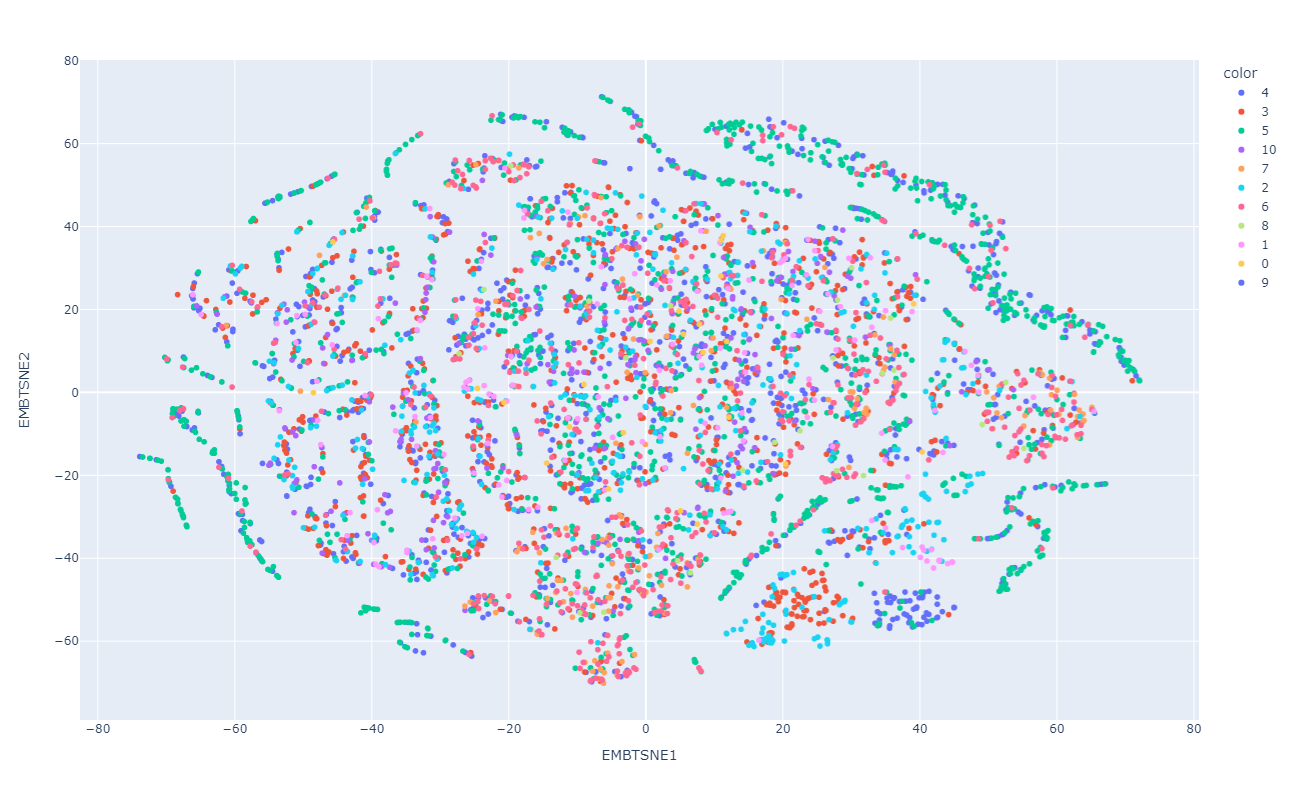
VSM de los datos preprocesados
VSM del espacio latente
-
Study statistics:
- Number of finished trials: 10
- Number of pruned trials: 0
- Number of complete trials: 10
-
Best trial:
- Value: 30.5921
-
Params:
- nn_layer_1: 121
- nn_layer_2: 121
- lr: 0.01
- batch_size: 128
-
Study statistics:
- Number of finished trials: 10
- Number of pruned trials: 0
- Number of complete trials: 10
-
Best trial:
- Value: 13.0232
-
Params:
- nn_layer_1: 67
- nn_layer_2: 121
- lr: 0.001
- batch_size: 256
Resultados preeliminares:
Clasificadores
Clasificador con datos preprocesados
Clasificador con el espacio latente
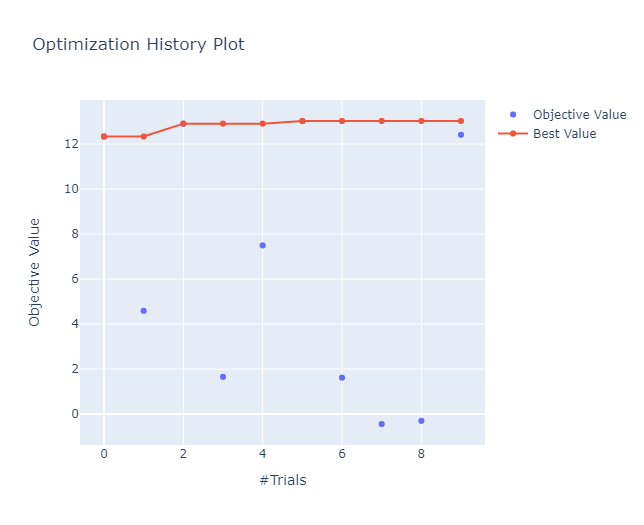
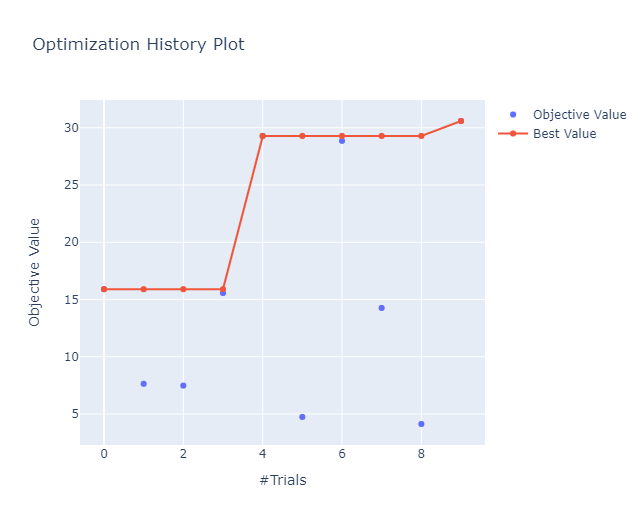
Clasificador con datos preprocesados
Clasificador con el espacio latente
Resultados preeliminares:
Exactitud de los clasificadores
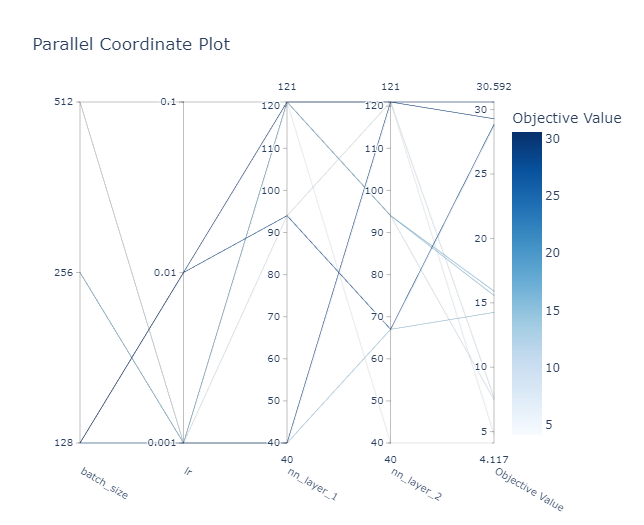
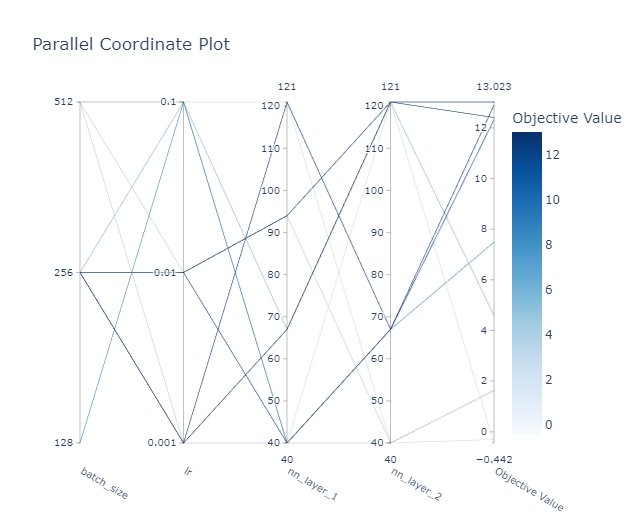
Clasificador con datos preprocesados
Clasificador con el espacio latente
Resultados preeliminares:
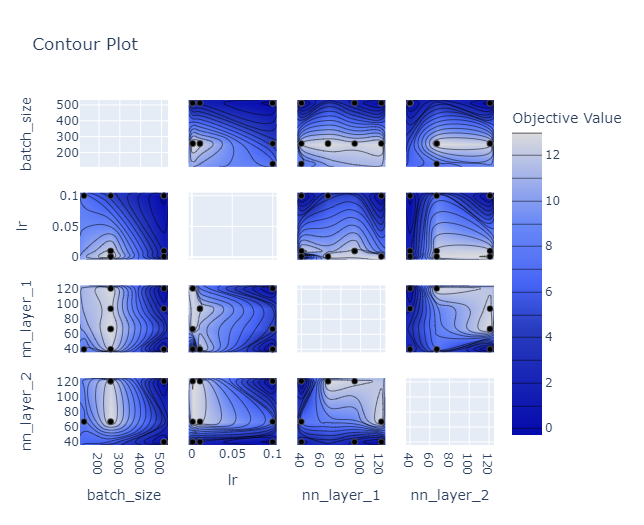
Espacio de búsqueda de la optimización de hyperparámetros de de los clasificadores

Clasificador con datos preprocesados
Clasificador con el espacio latente
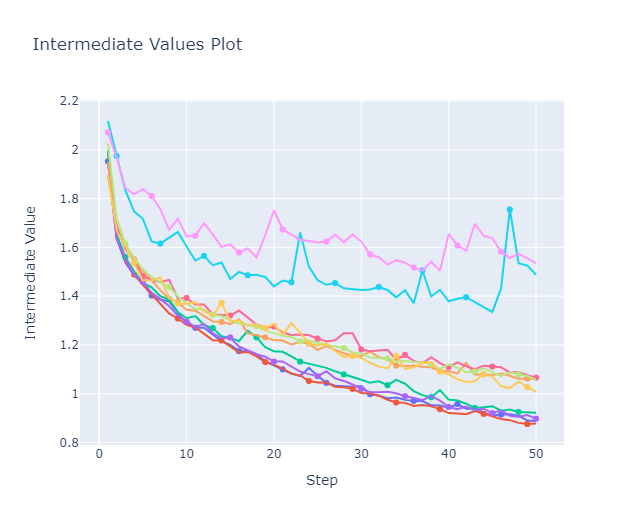
Resultados preeliminares:
Espacio de búsqueda de la optimización de hyperparámetros de de los clasificadores

Clasificador con datos preprocesados
Clasificador con el espacio latente
Resultados preeliminares:
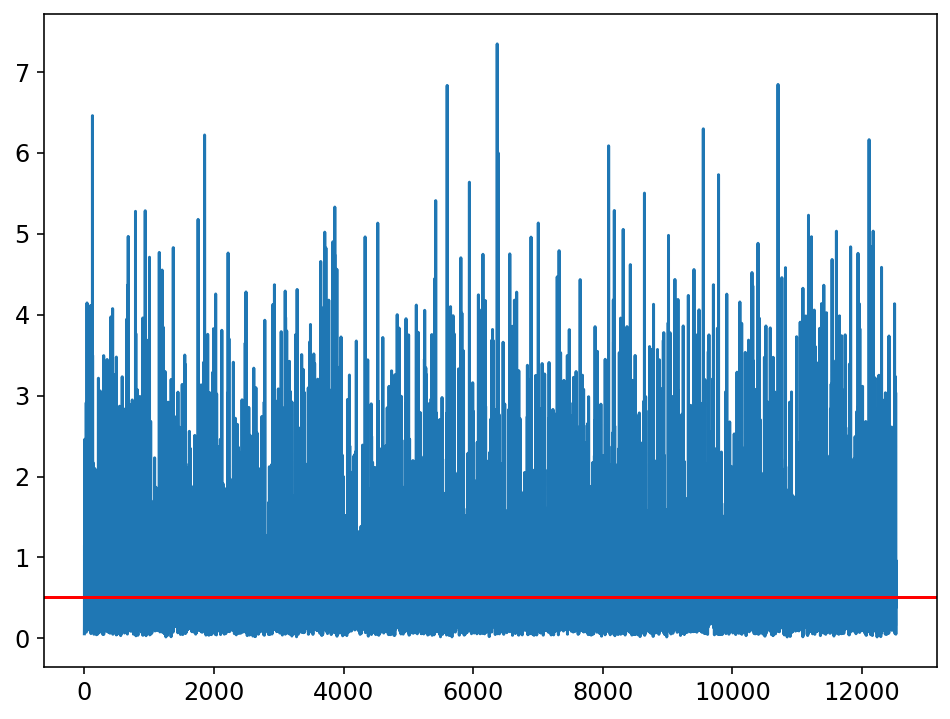
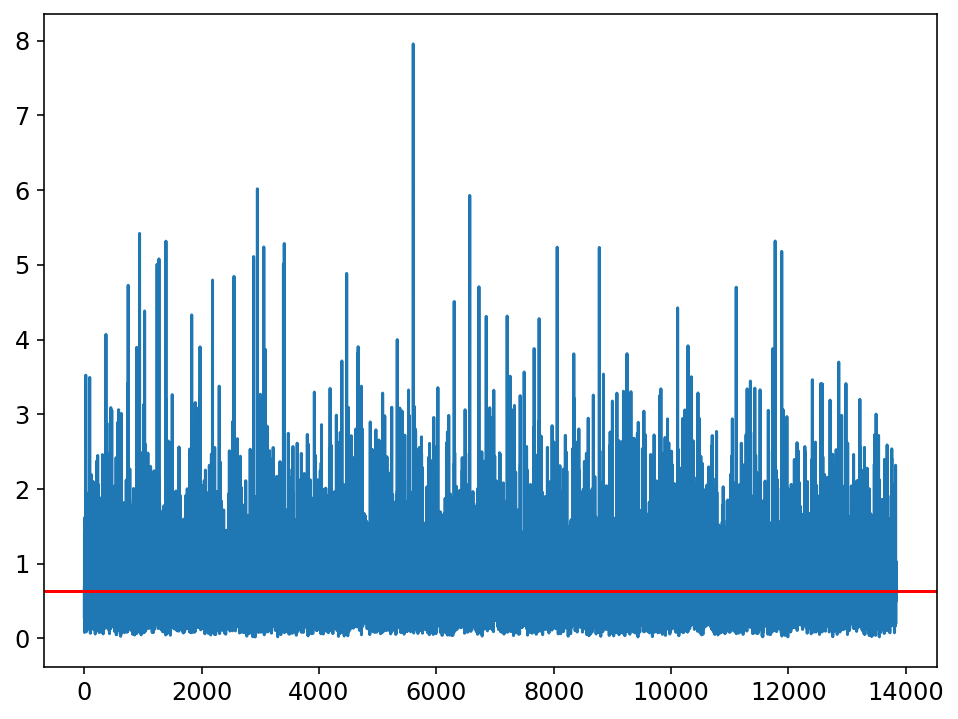
Error de aprendizaje en la optimización de hyperparámetros de los clasificadores
Clasificador con datos de prueba preprocesados
Clasificador con datos de prueba en el espacio latente
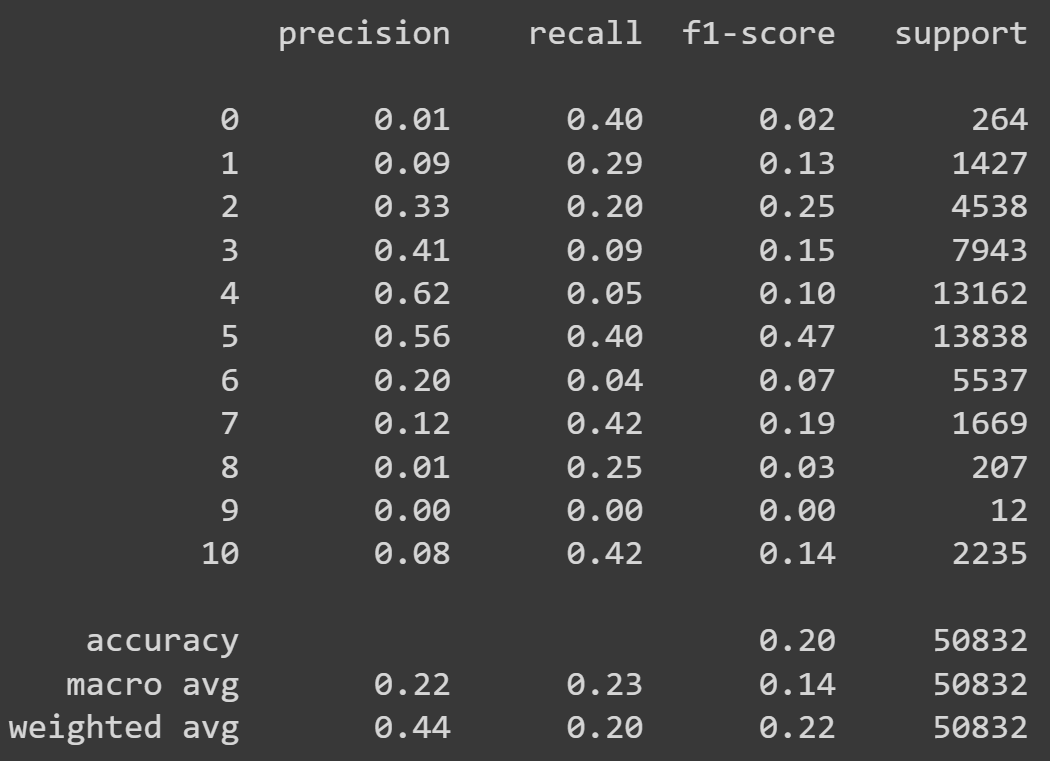
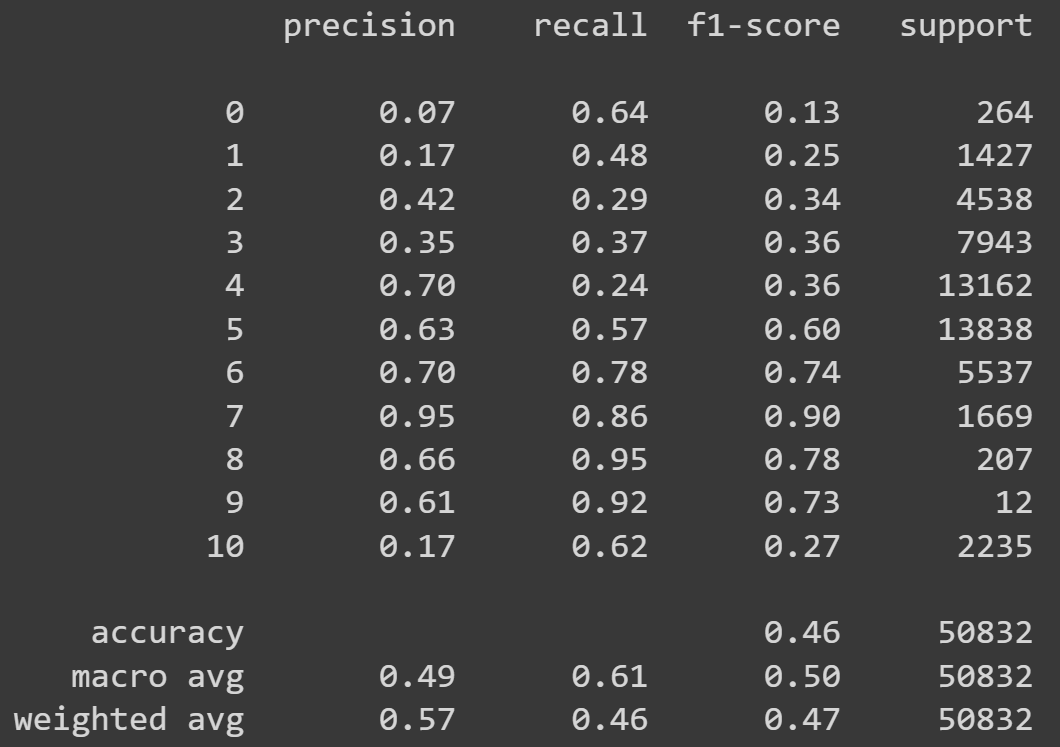
Resultados preeliminares:
Reporte de clasificación
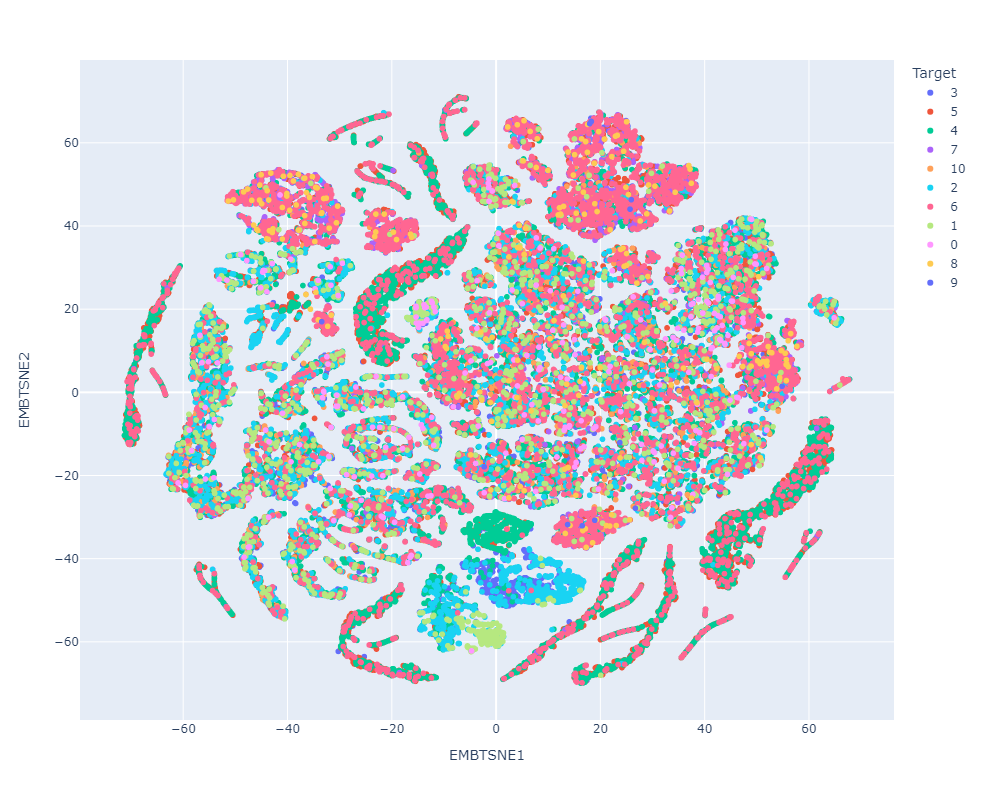
Resultados preeliminares:
Dataviz
Clasificador con datos de prueba preprocesados
Clasificador con datos de prueba en el espacio latente
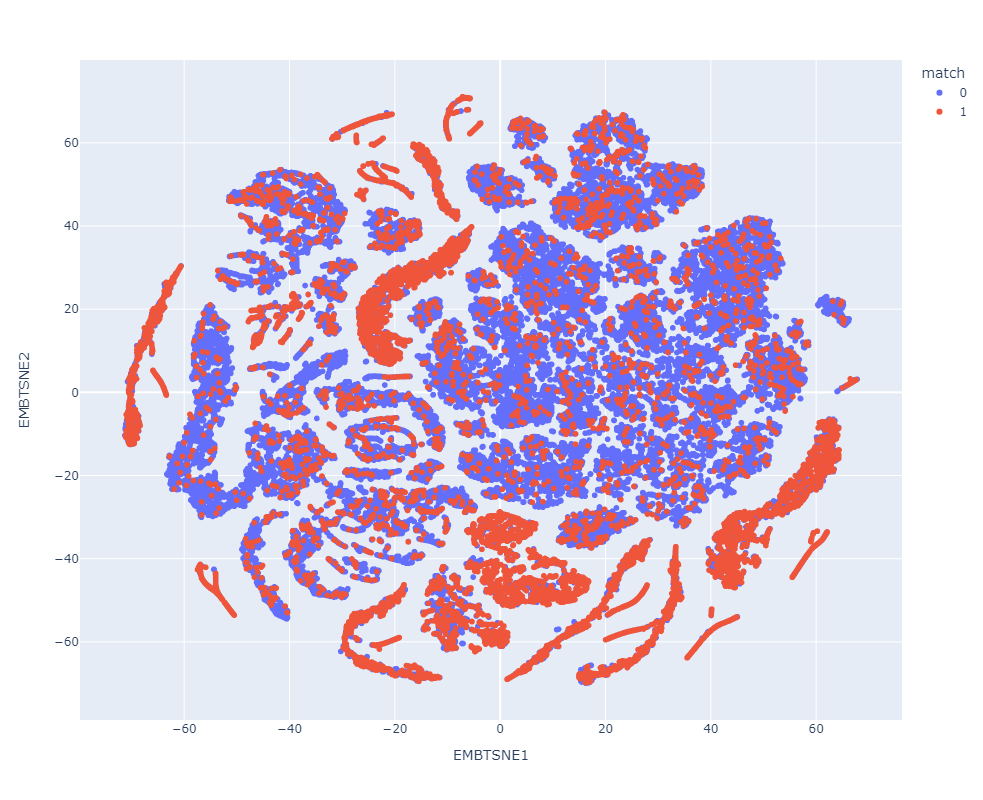
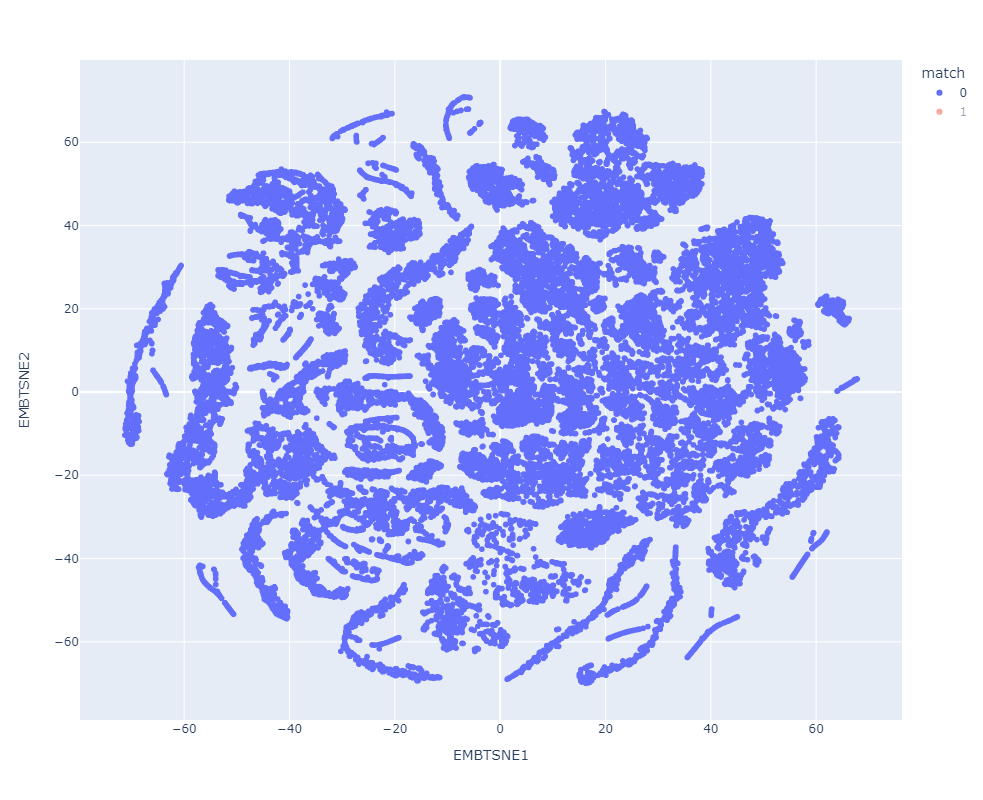
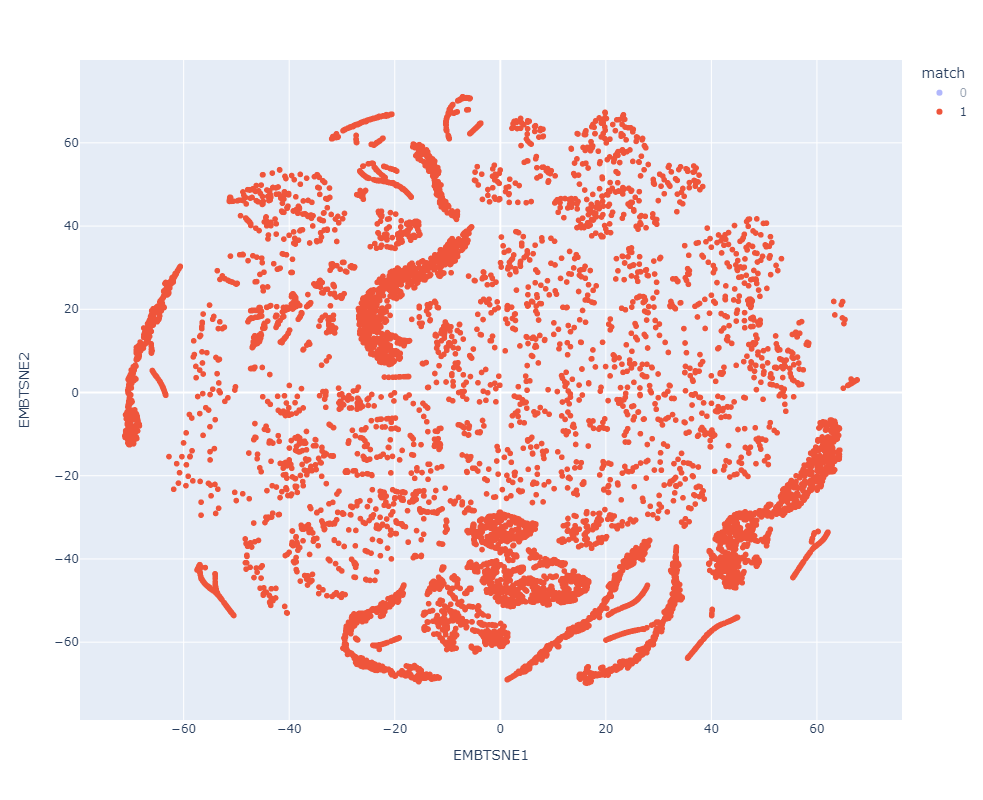
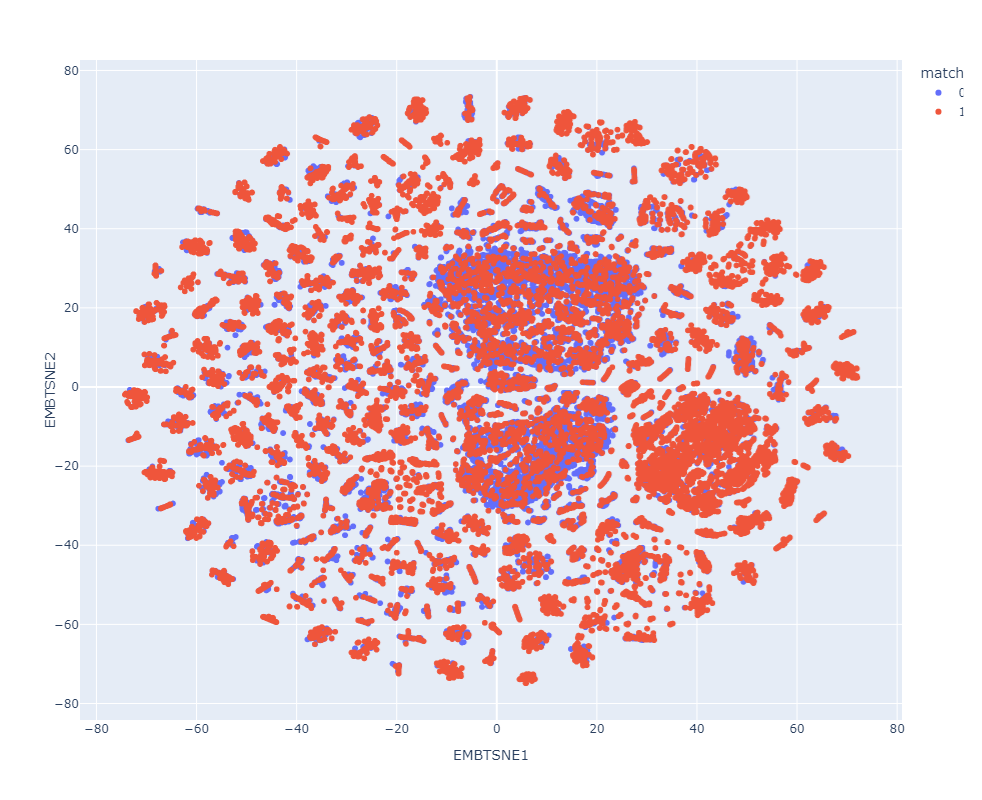
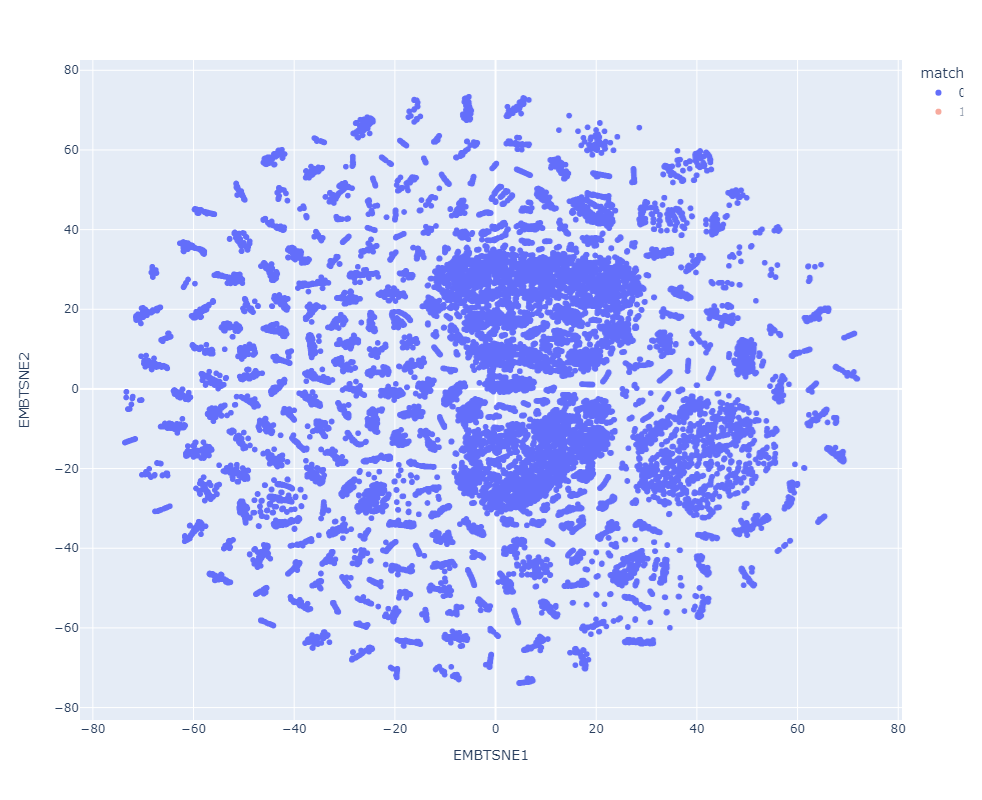
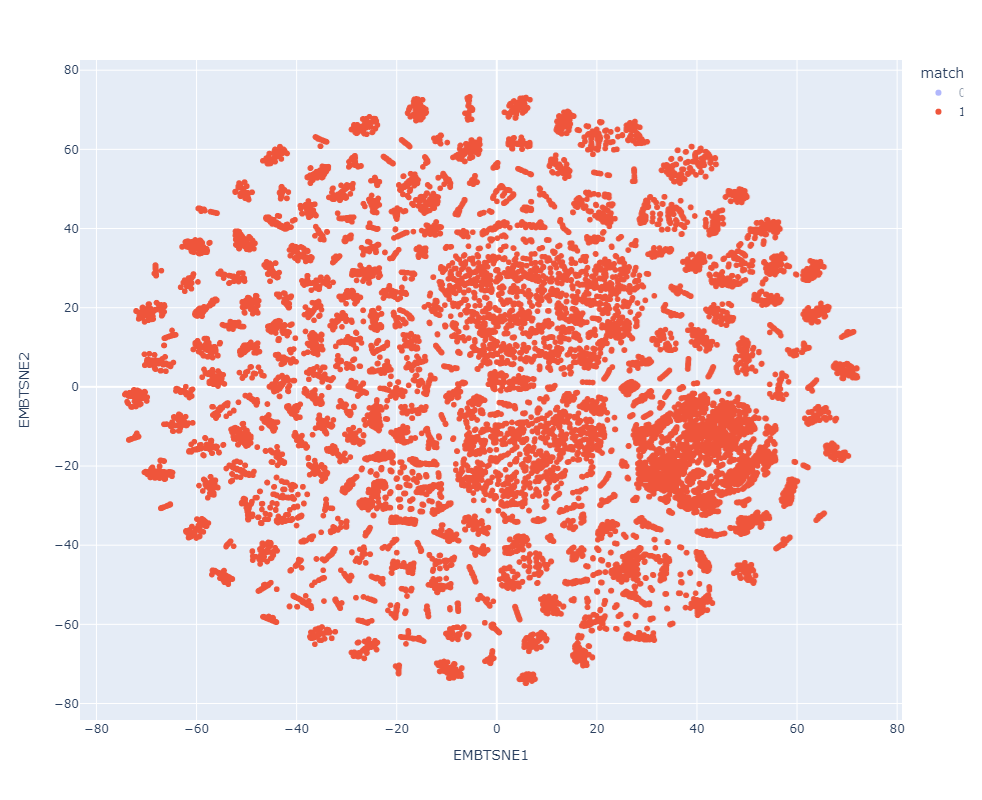
Resultados preeliminares:
Match
Clasificador con datos de prueba preprocesados
Clasificador con datos de prueba en el espacio latente
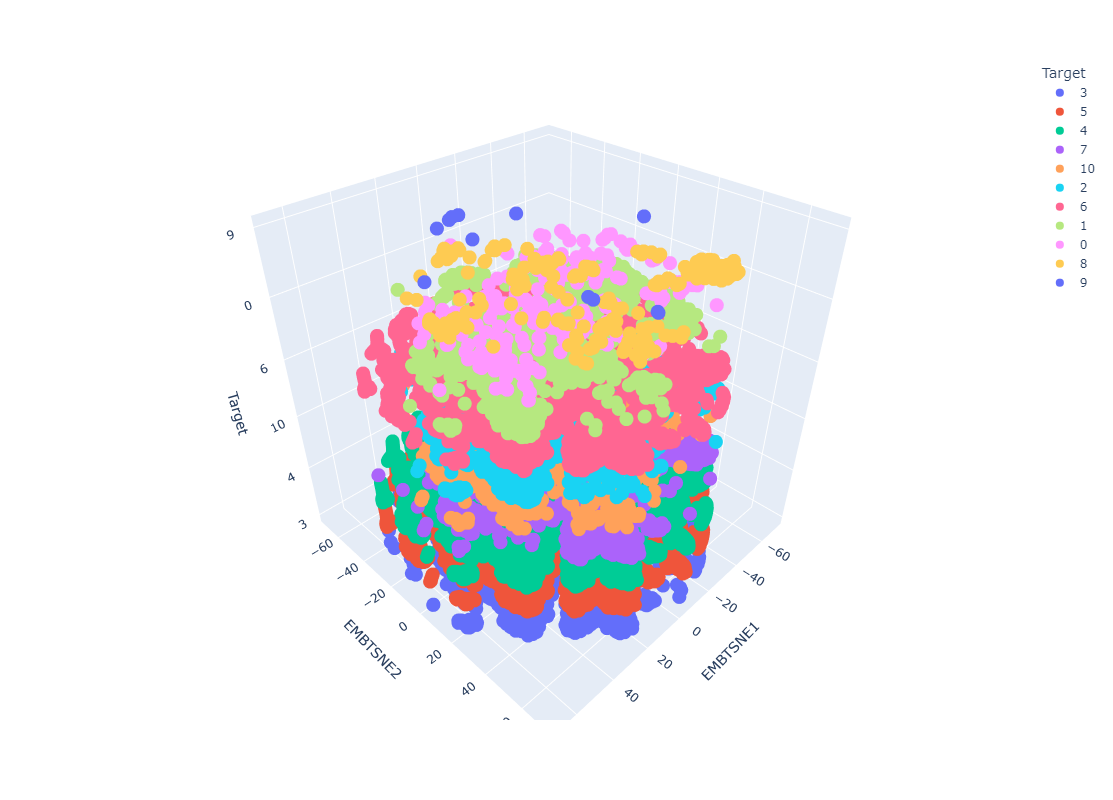
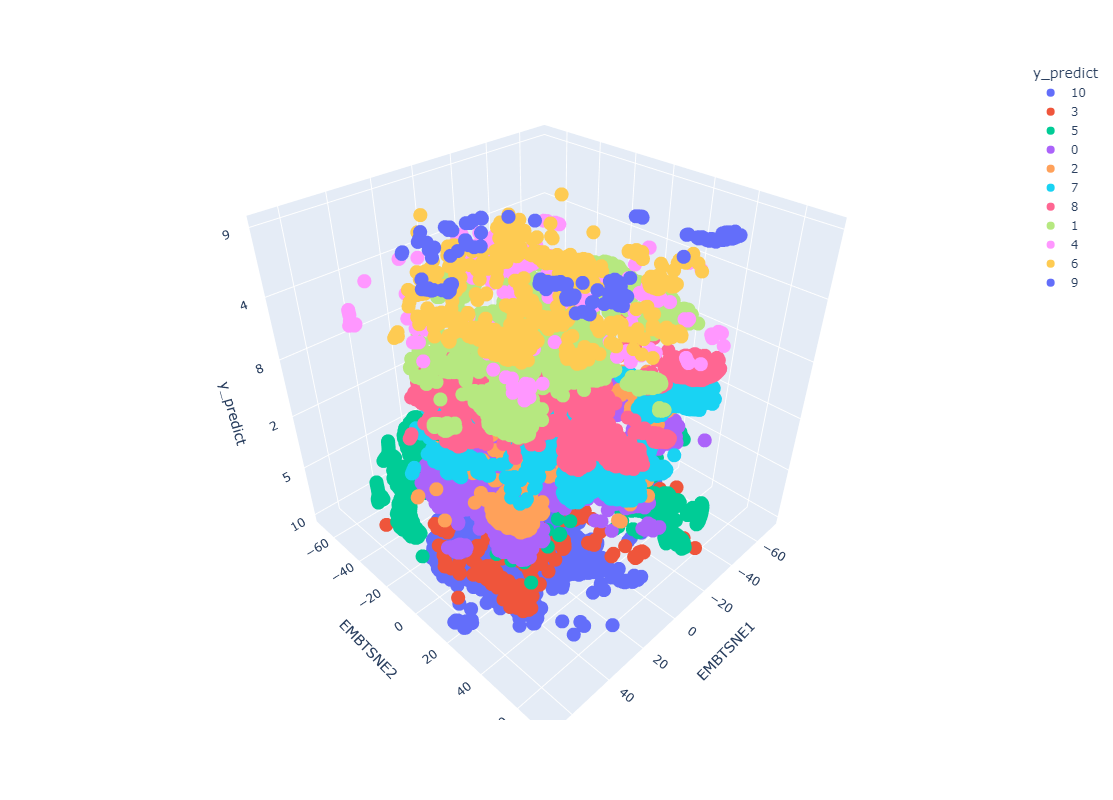
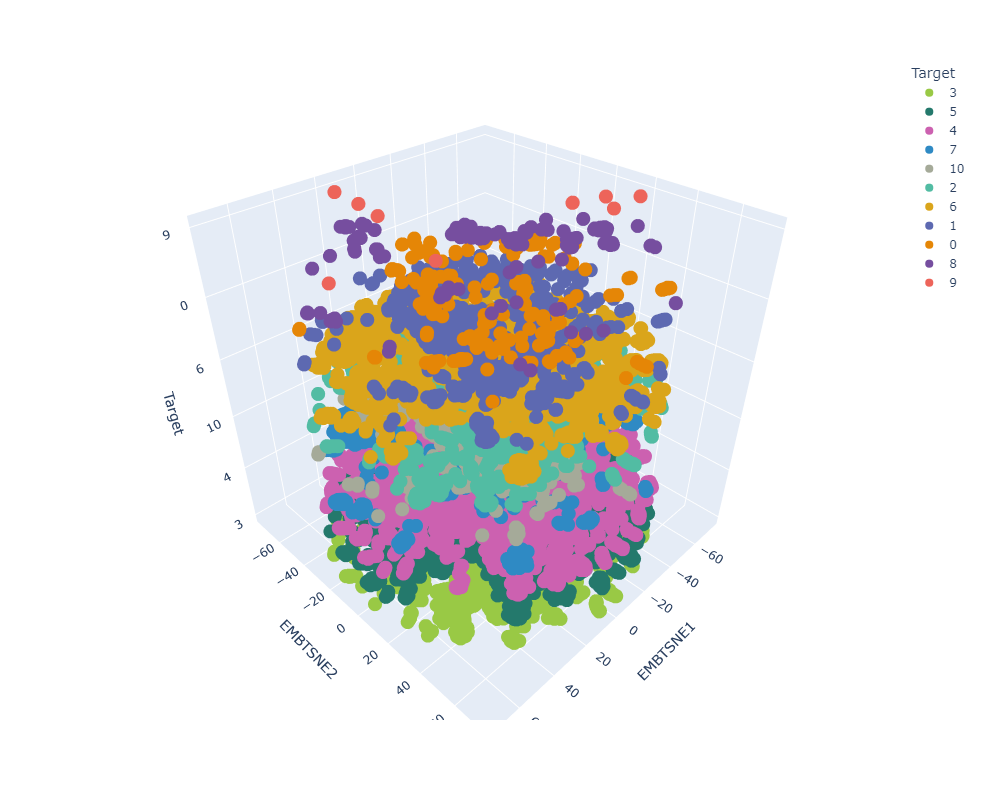
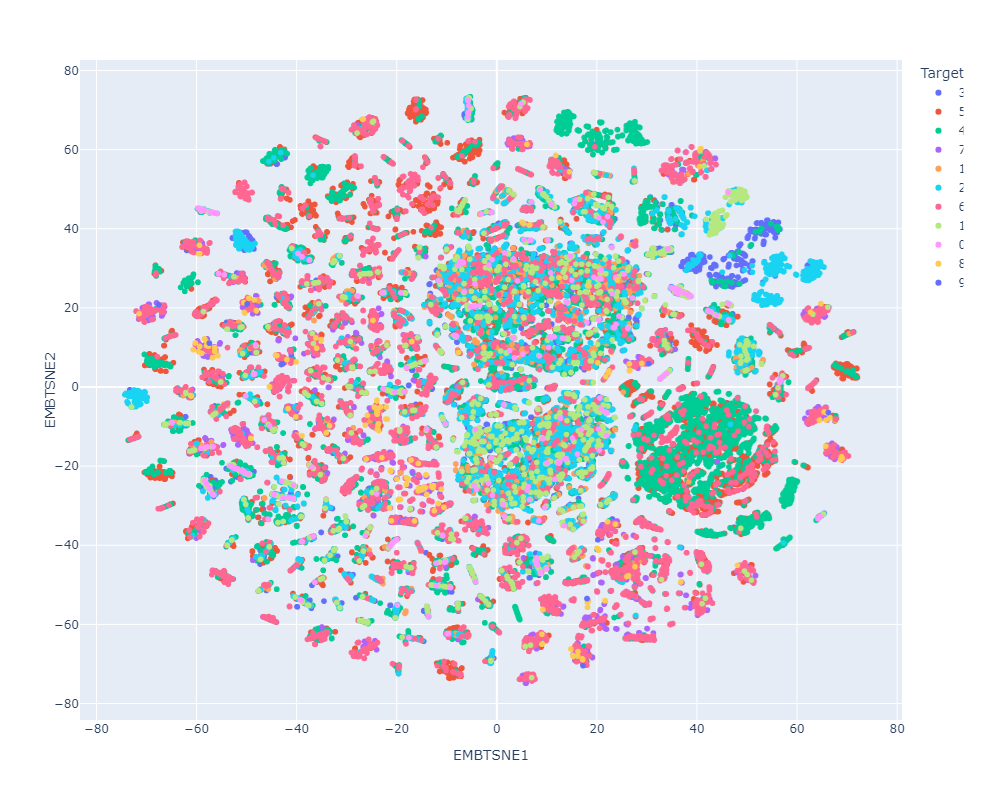
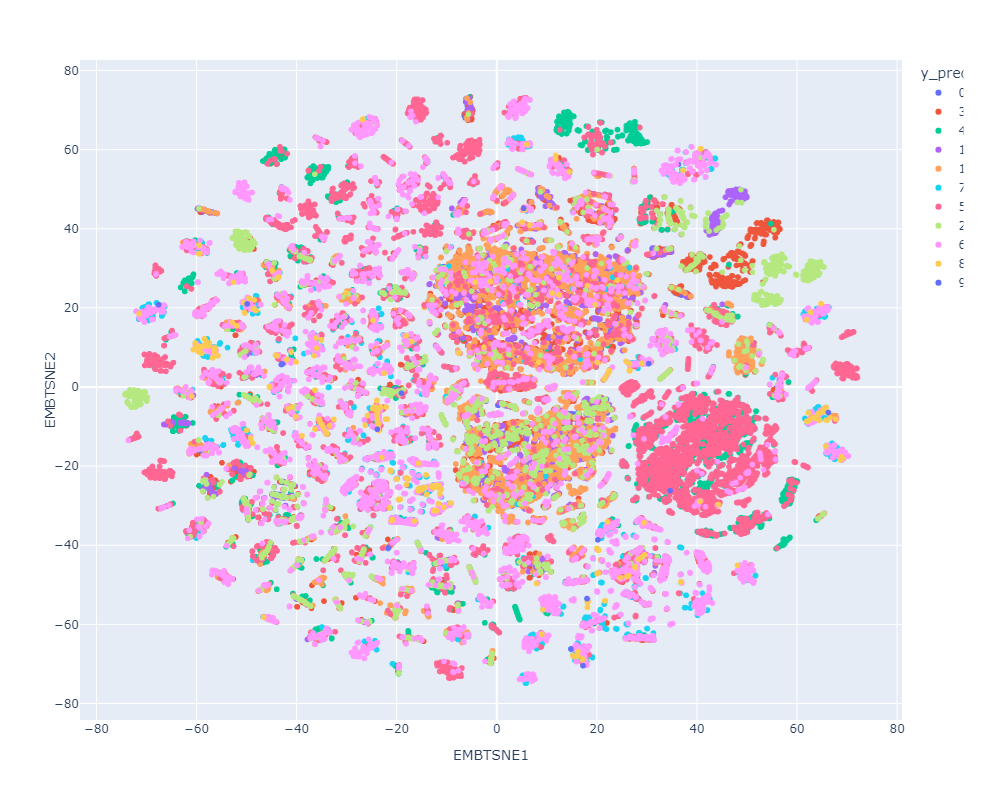
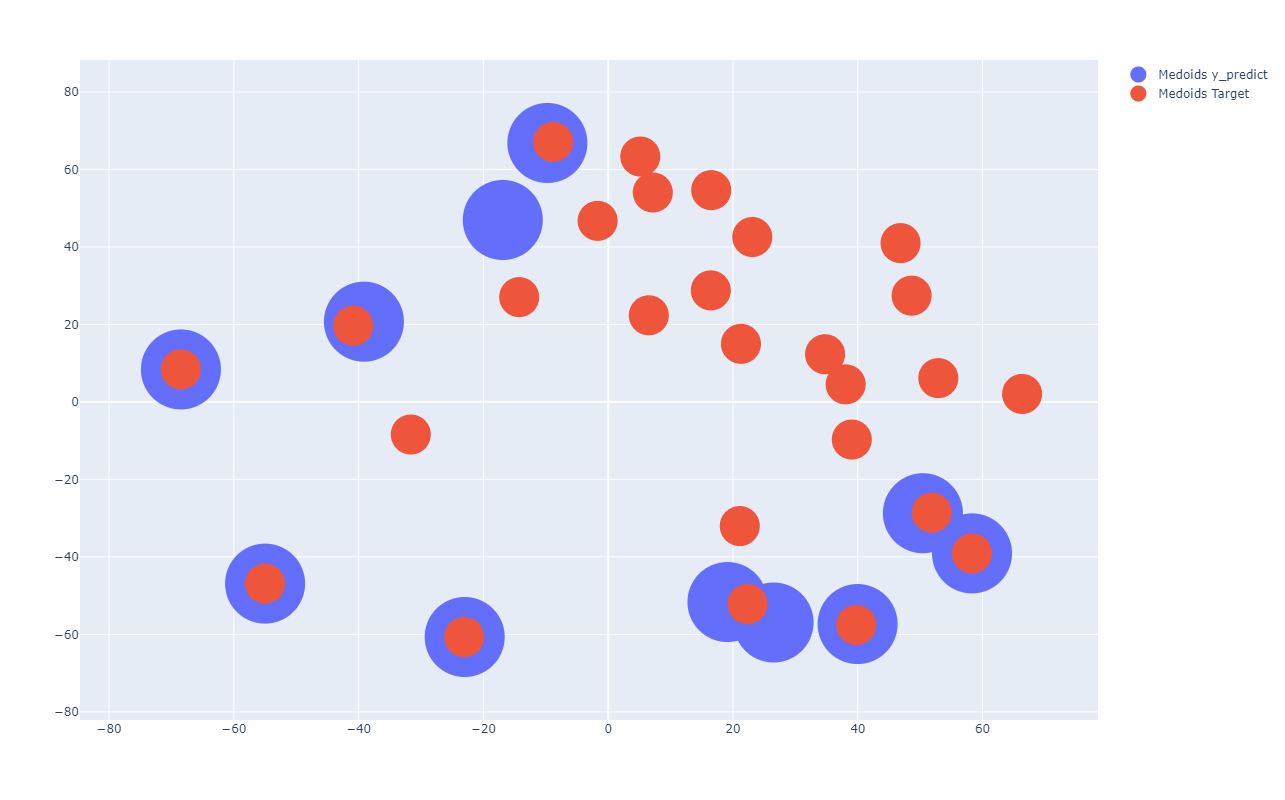
Resultados preeliminares:
Target vs Prediction
Clasificador con datos de prueba preprocesados
Clasificador con datos de prueba en el espacio latente
Resultados preeliminares:
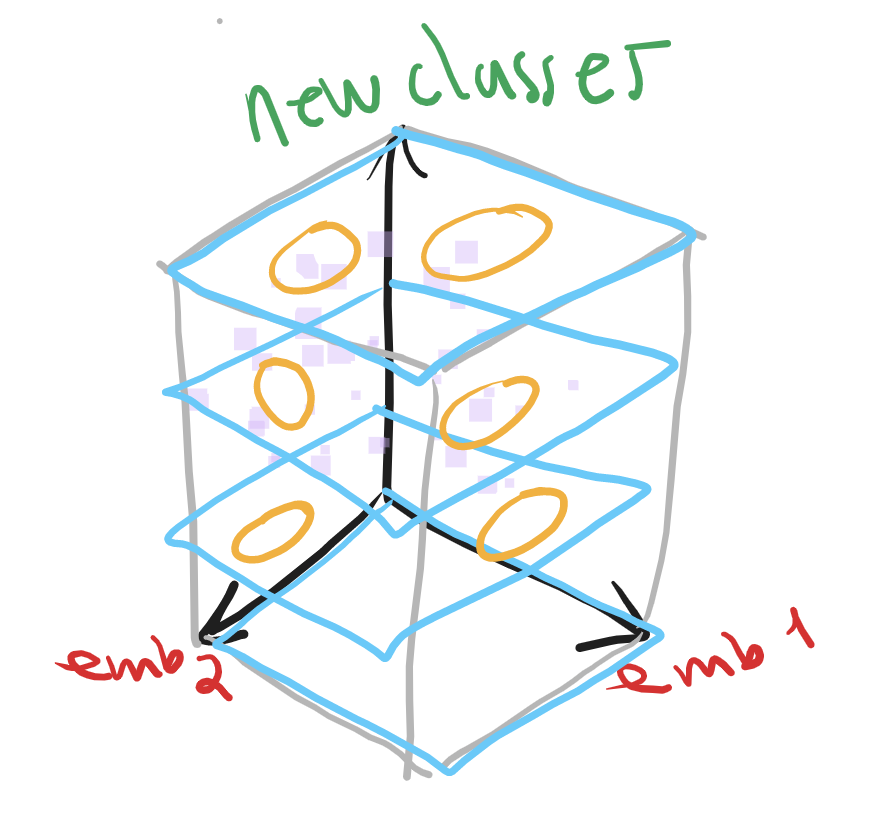
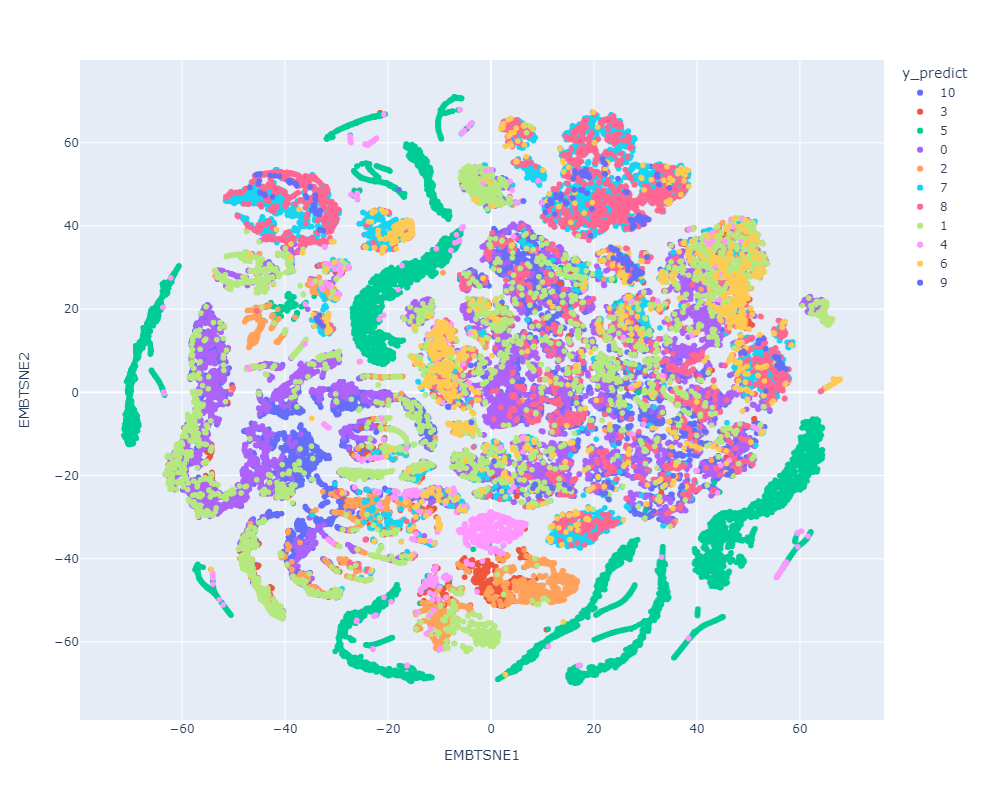
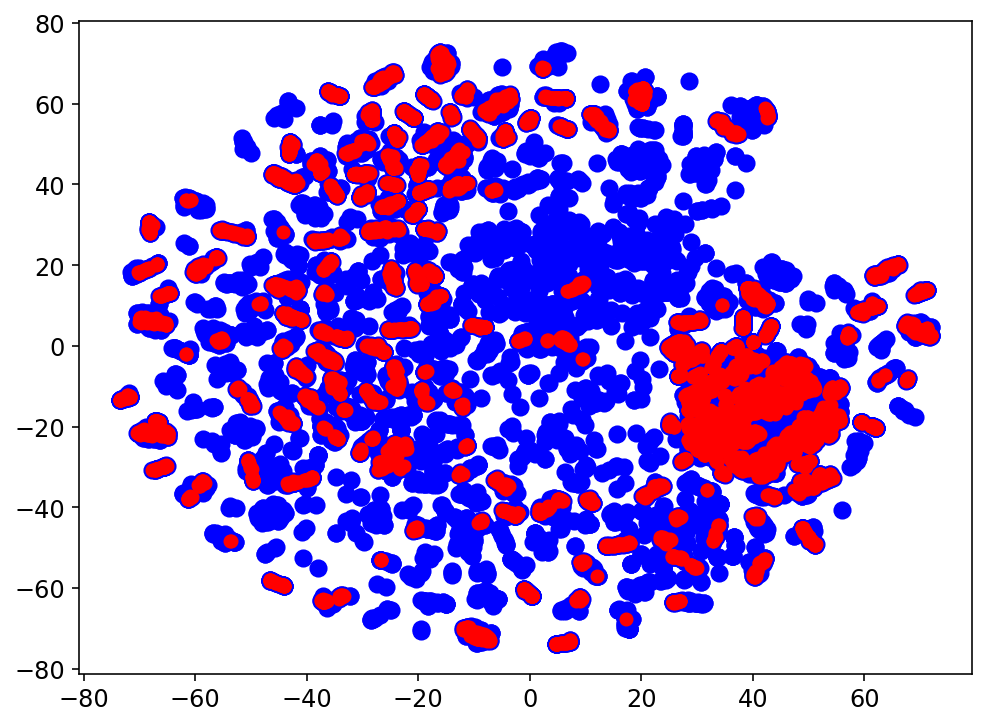
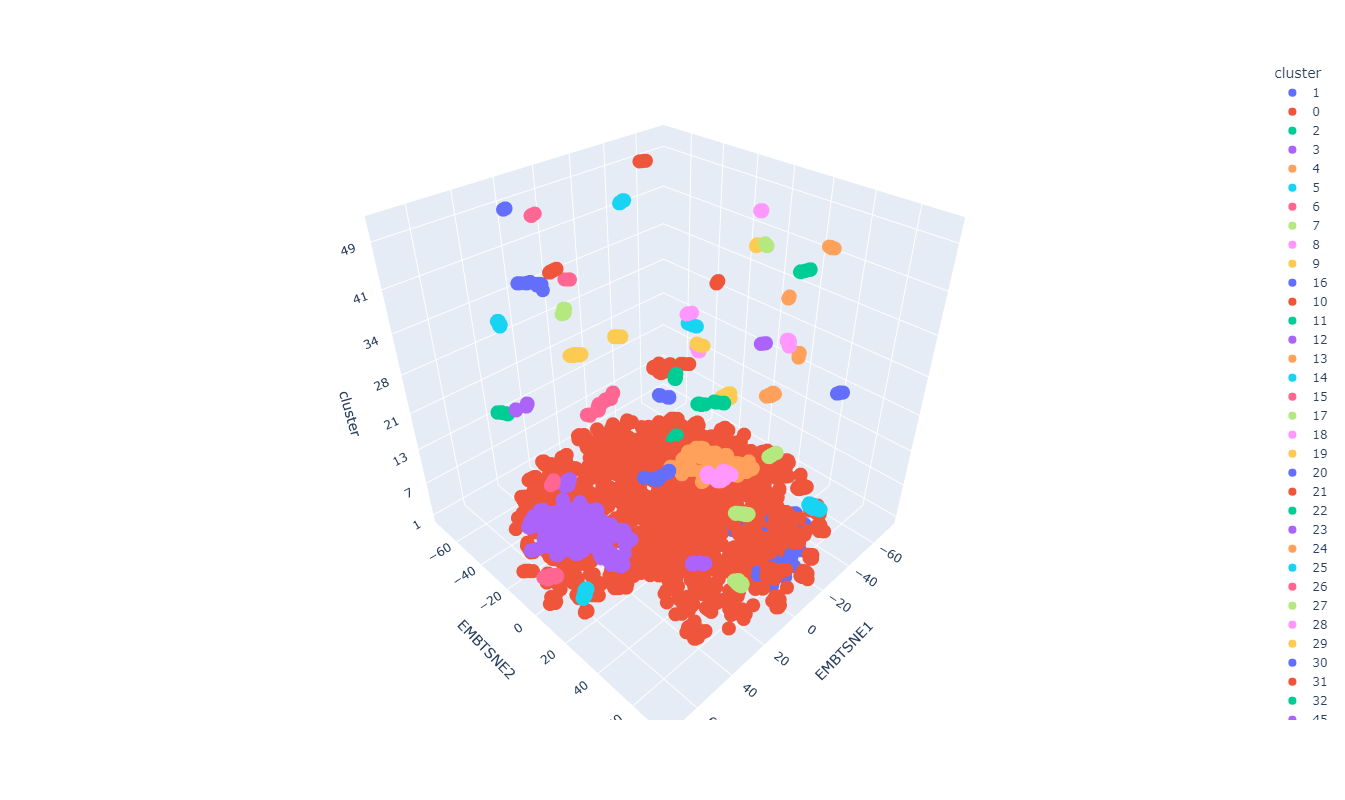
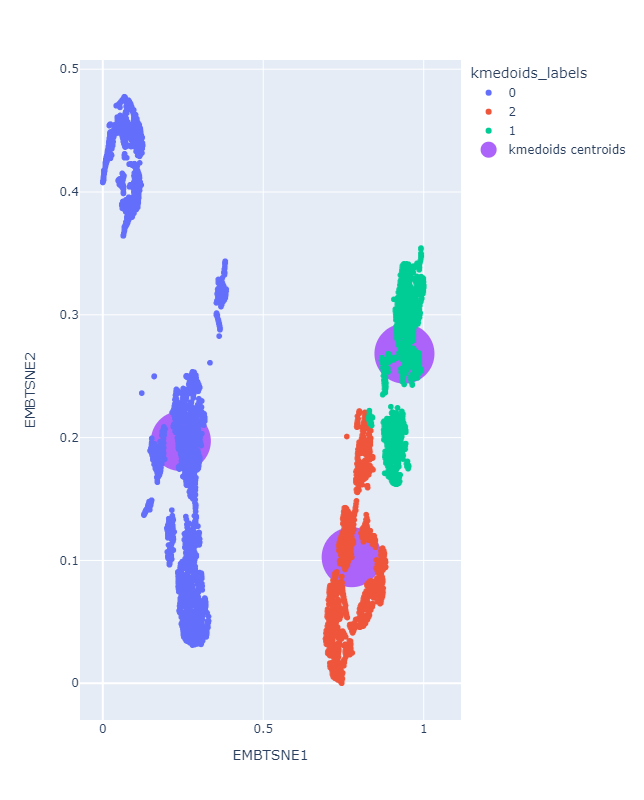
Clustering como método de explicación
Resultados preeliminares:
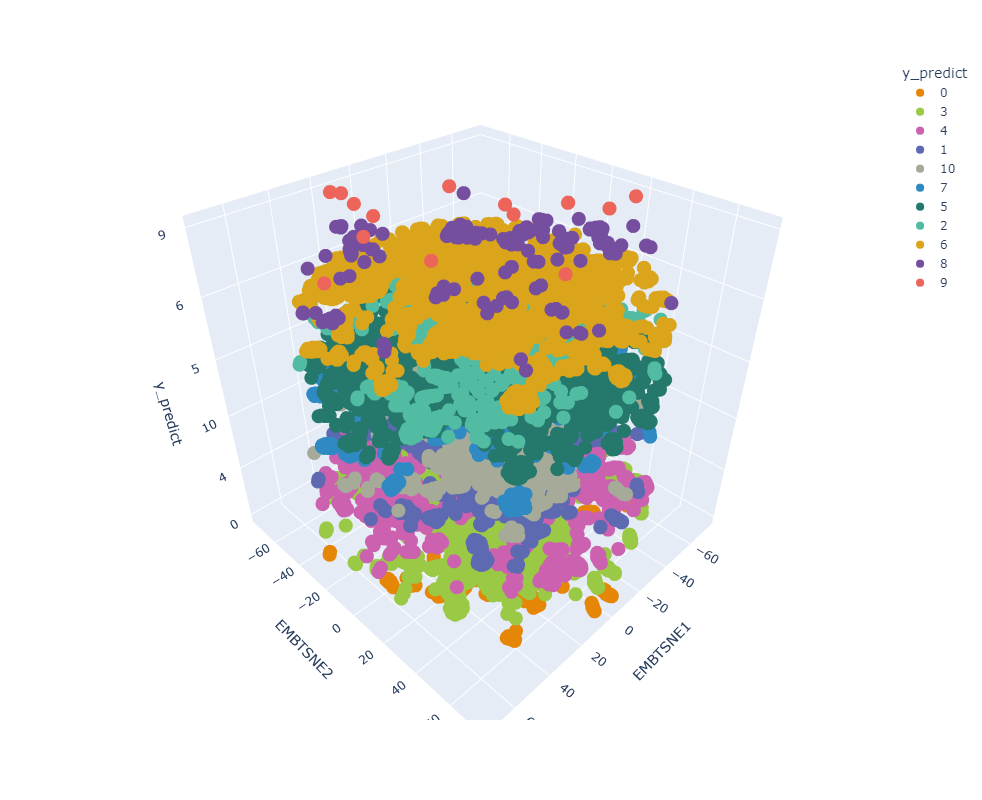
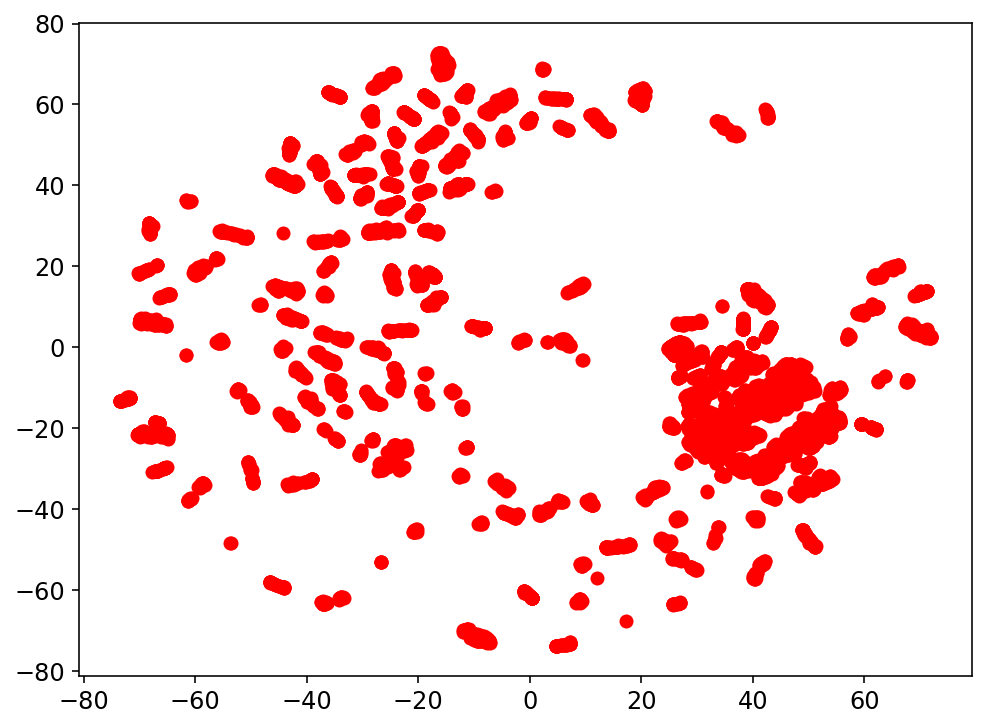
Clustering: Clase 5
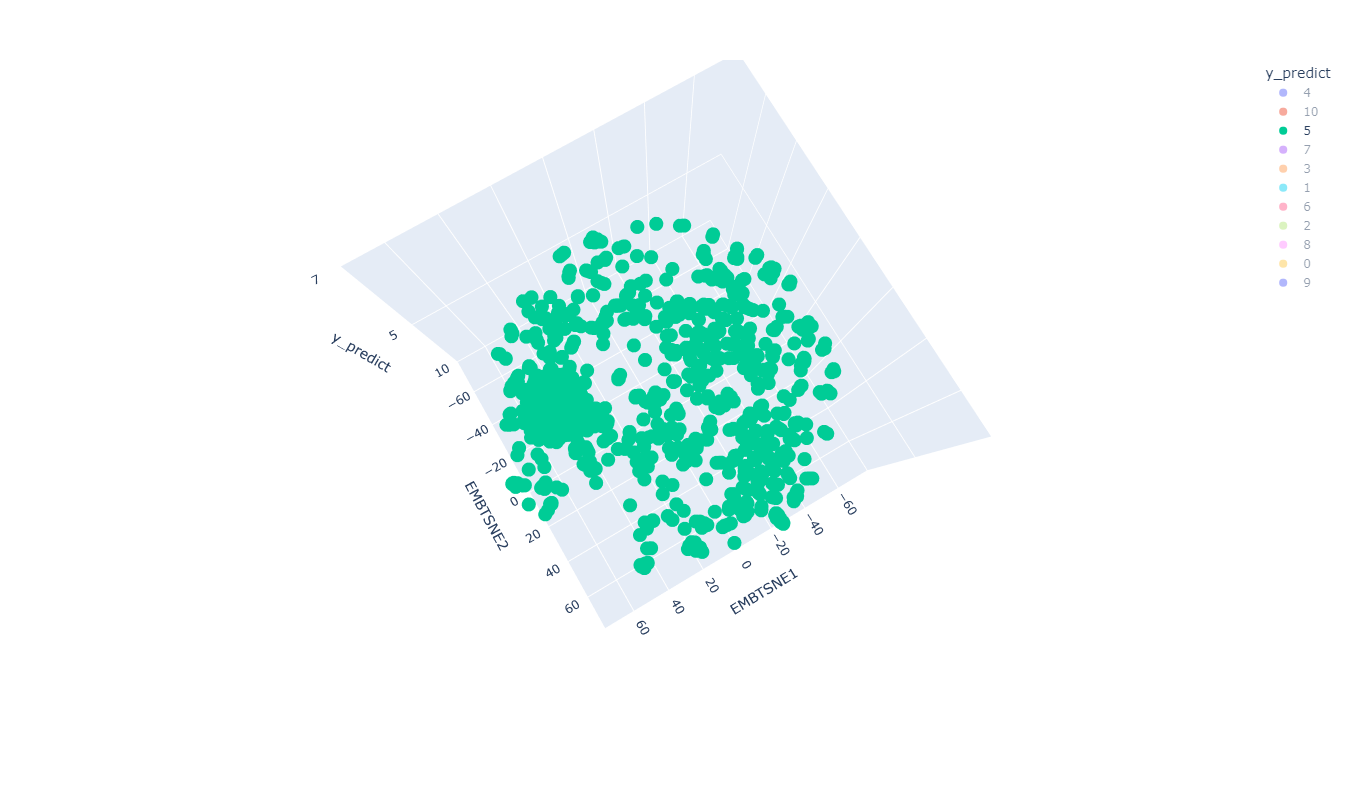
Resultados preeliminares:
Clustering: Clase 5

Prediction
Target
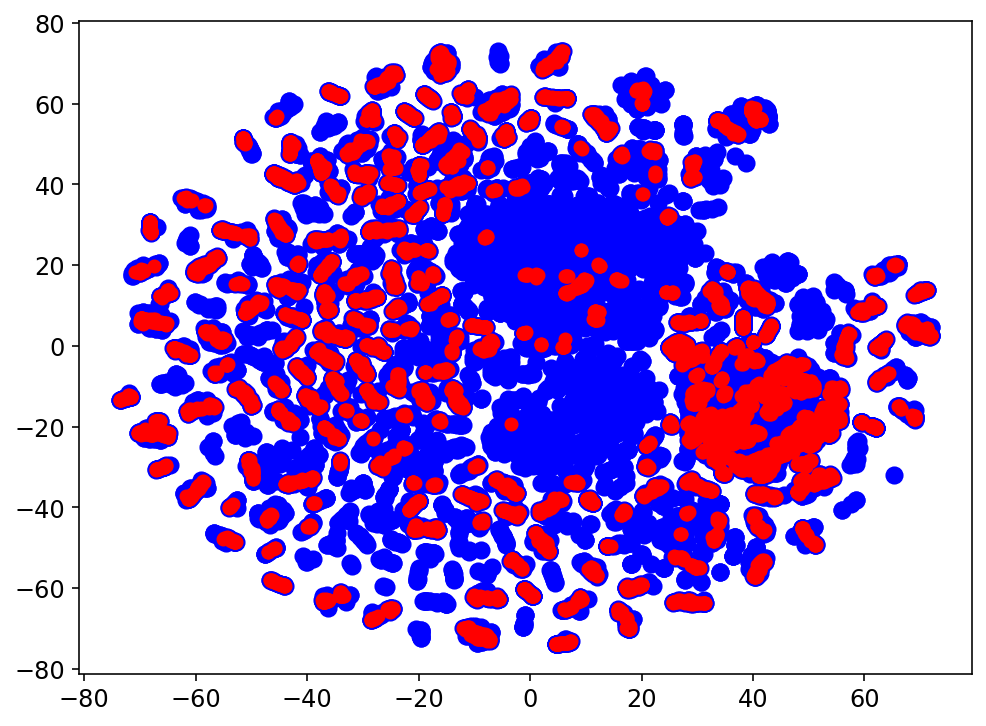

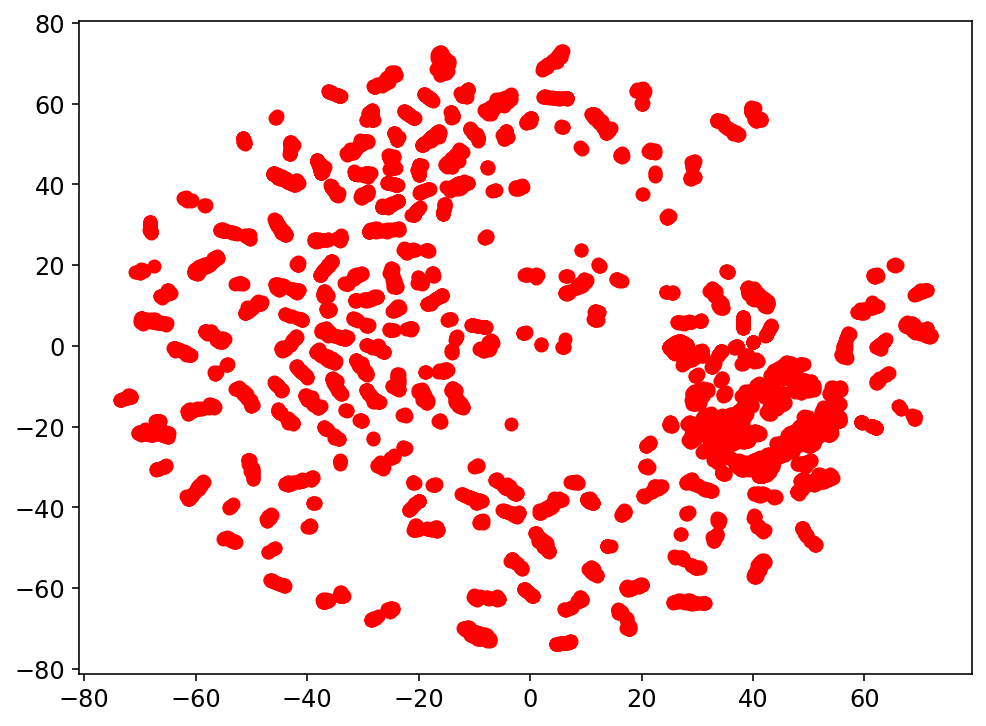
Resultados preeliminares:
Clustering: Clase 5

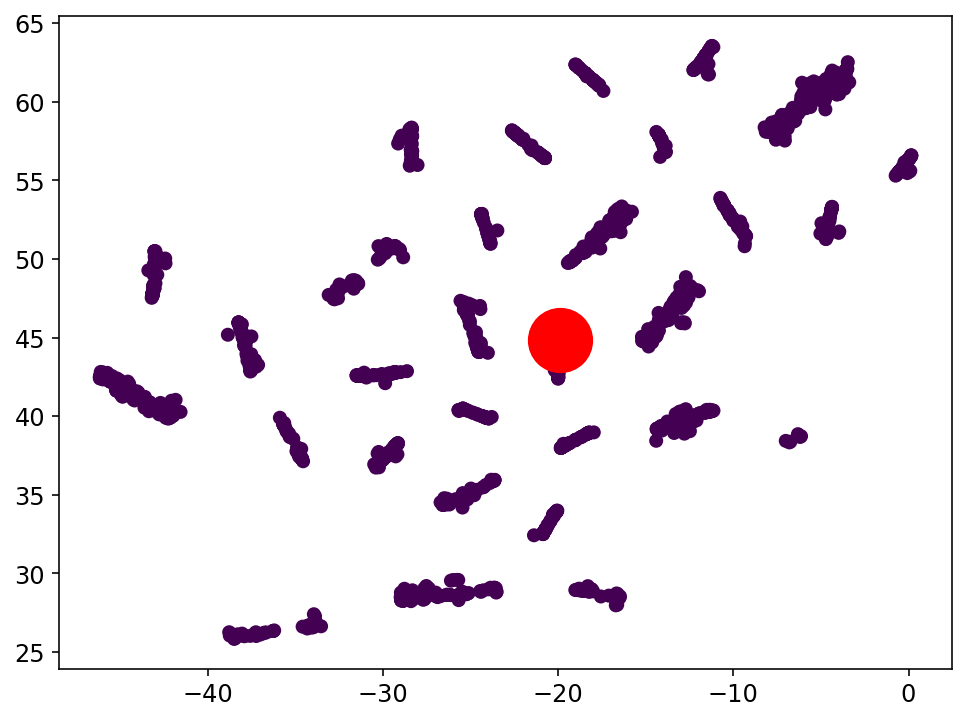
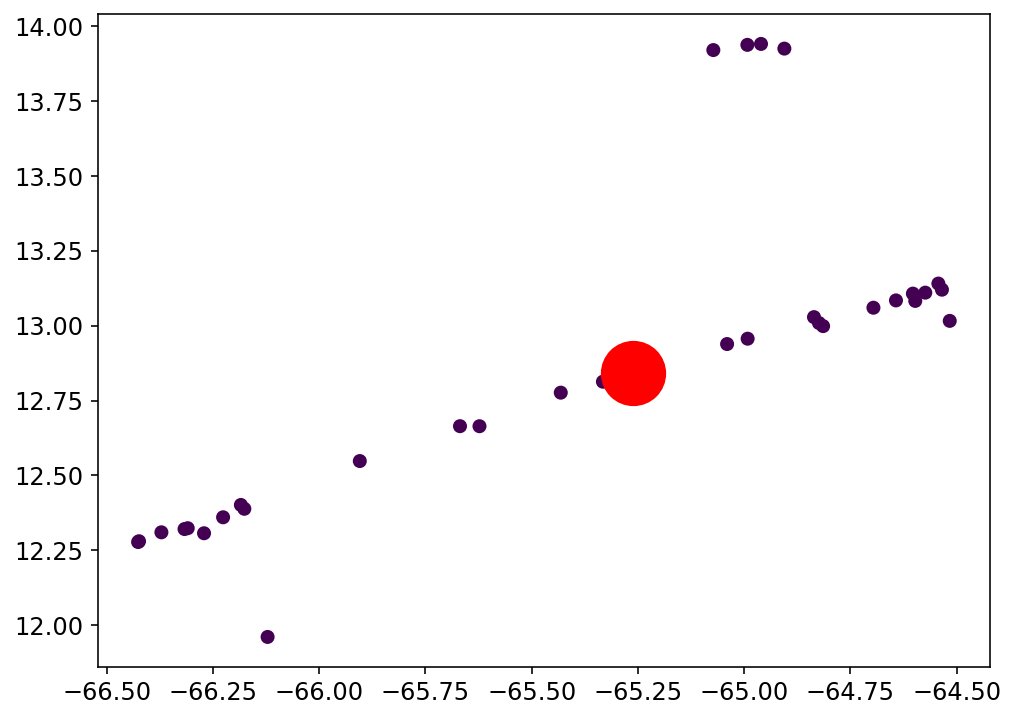
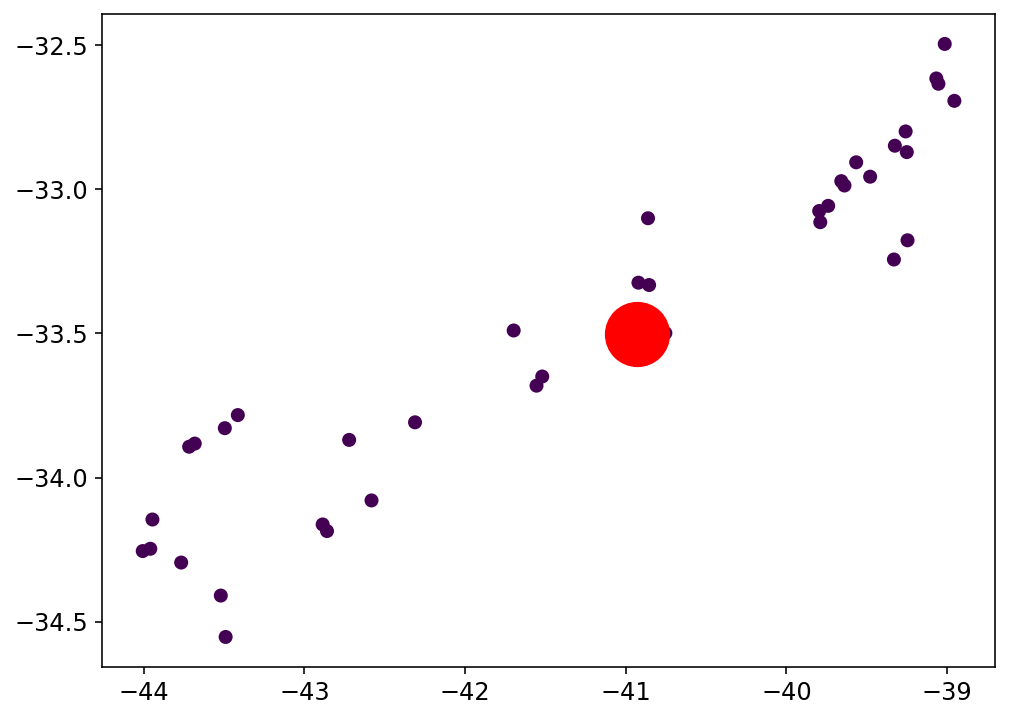


Resultados preeliminares:
Análisis de Clustering para la clasificación con el espacio latente: Clase 5
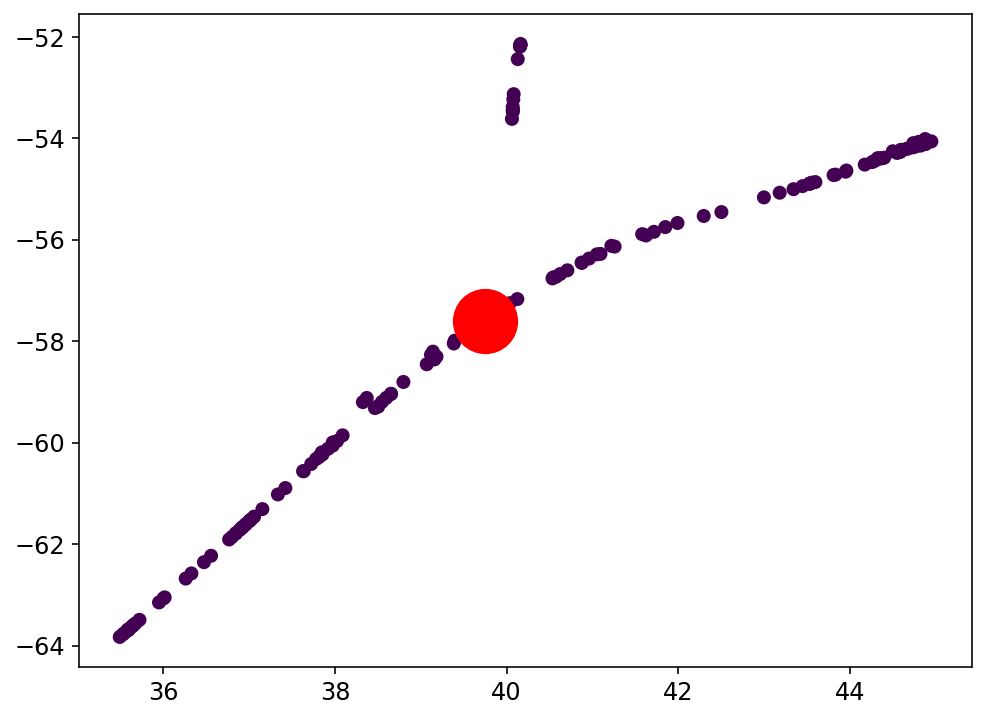
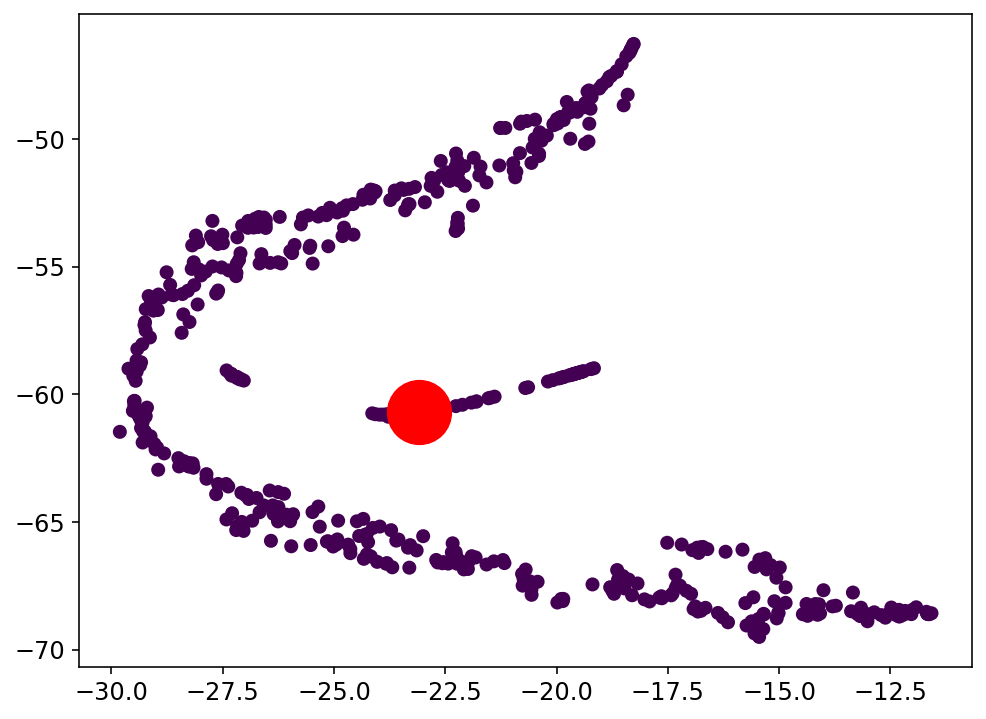
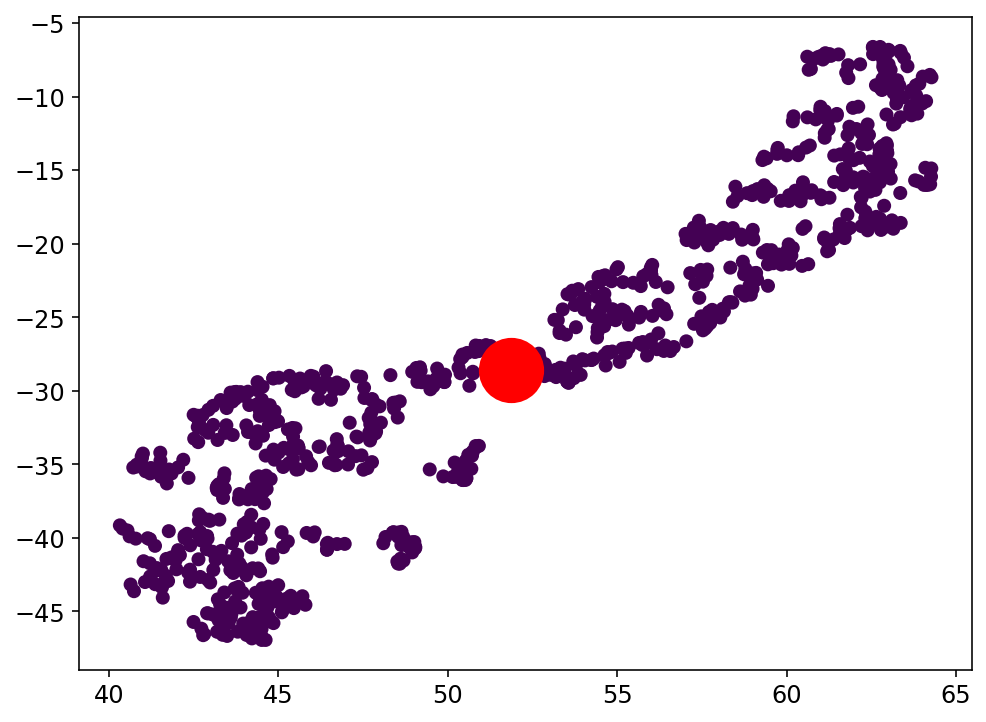
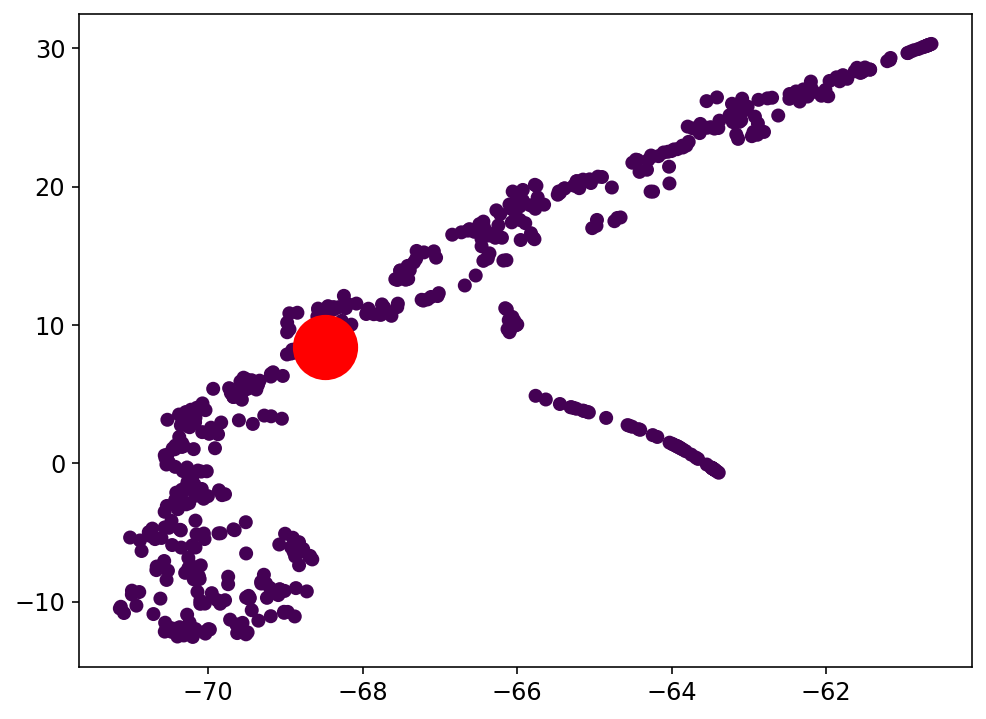
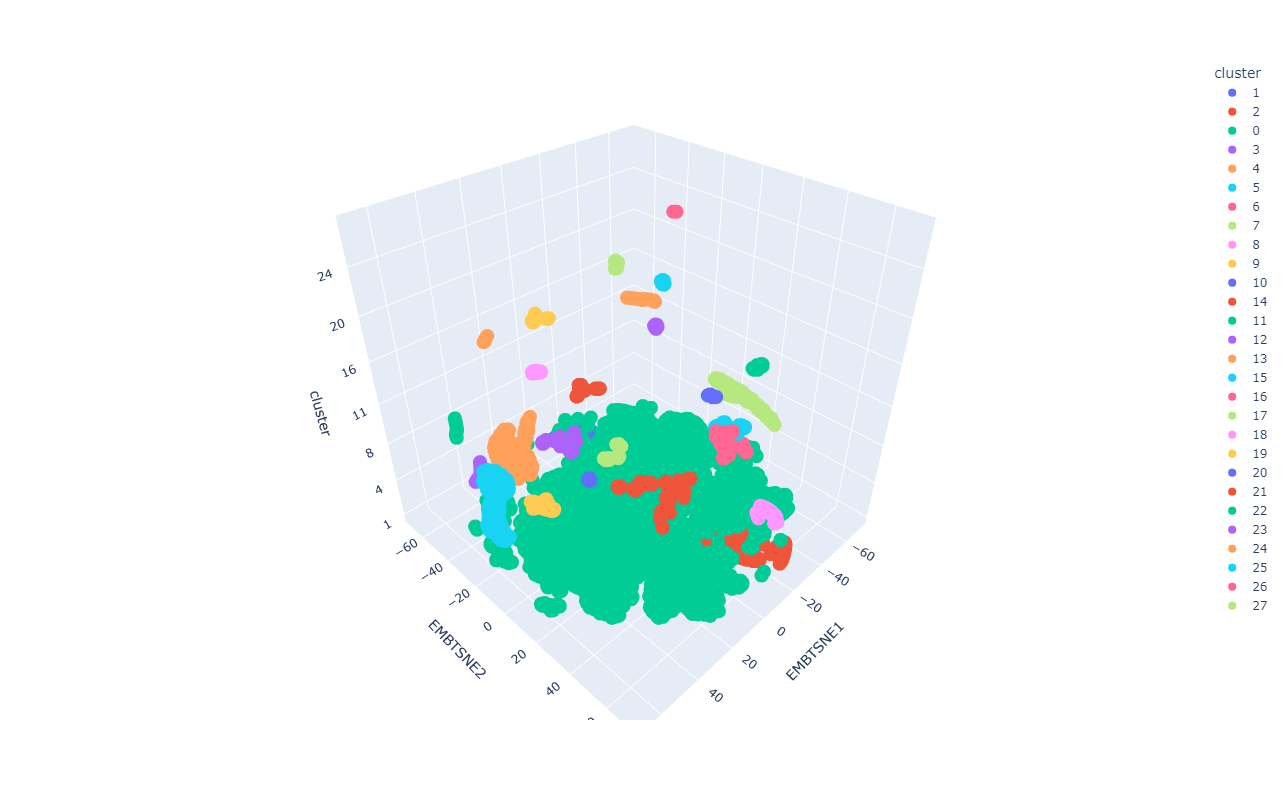




Trabajo actual
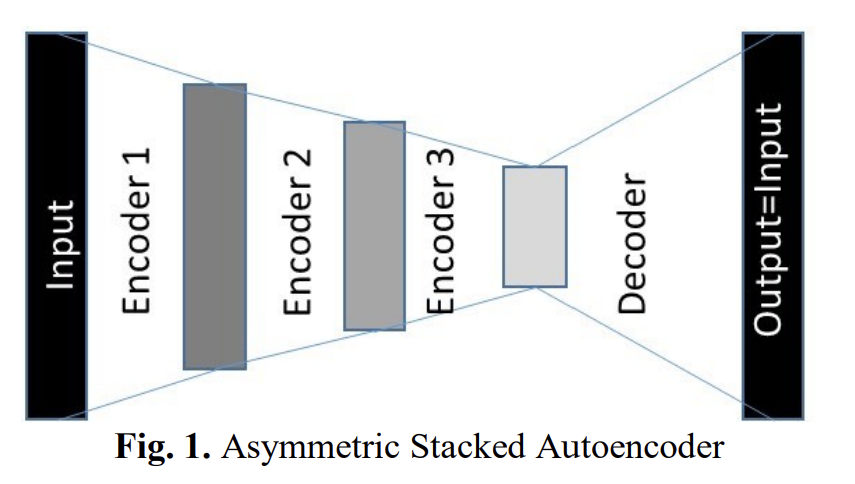
Majumdar, A., & Tripathi, A. (2017). Asymmetric stacked autoencoder. 2017 International Joint Conference on Neural Networks (IJCNN). doi:10.1109/ijcnn.2017.7965949

Wen et al. A Discriminative Feature Learning Approach for Deep Face Recognition. ECCV 2016.
Trabajo actual
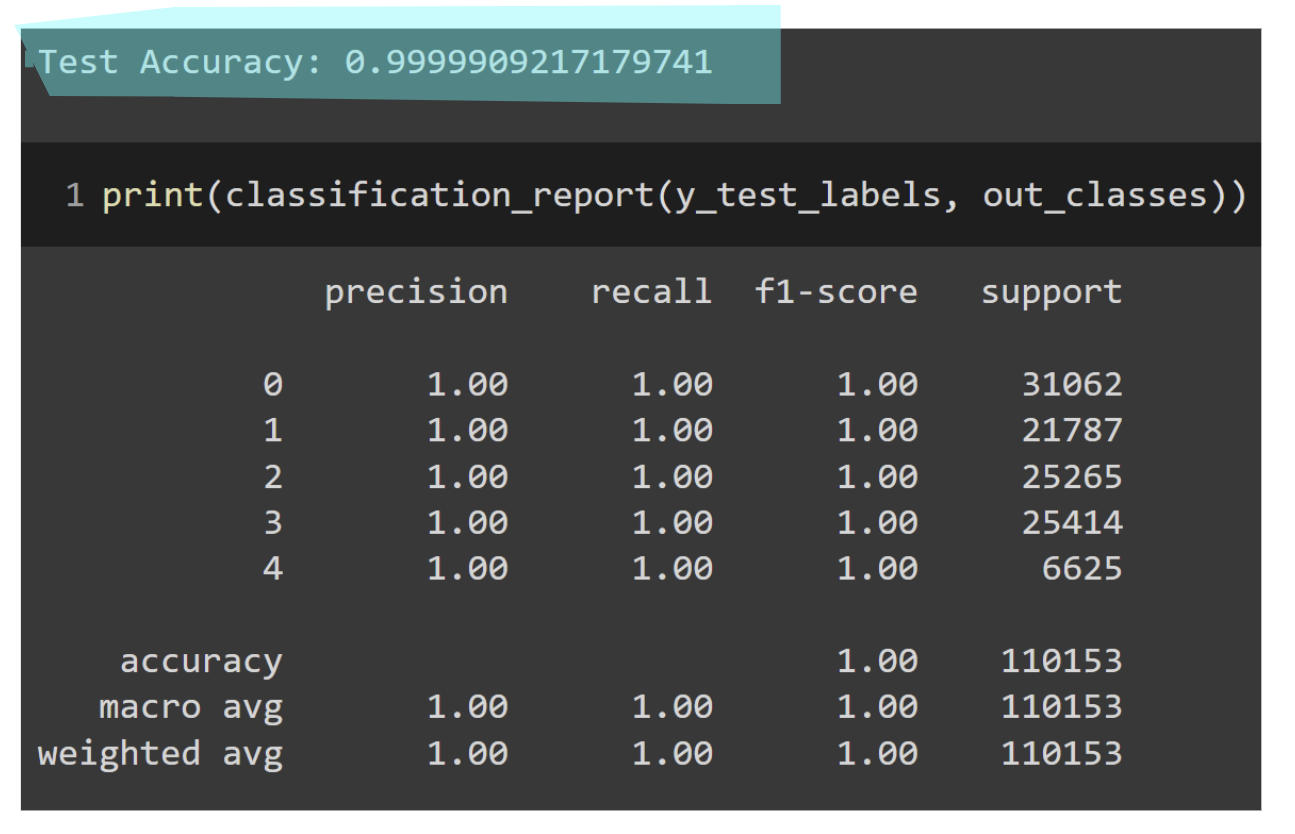
Preprocessed
Data
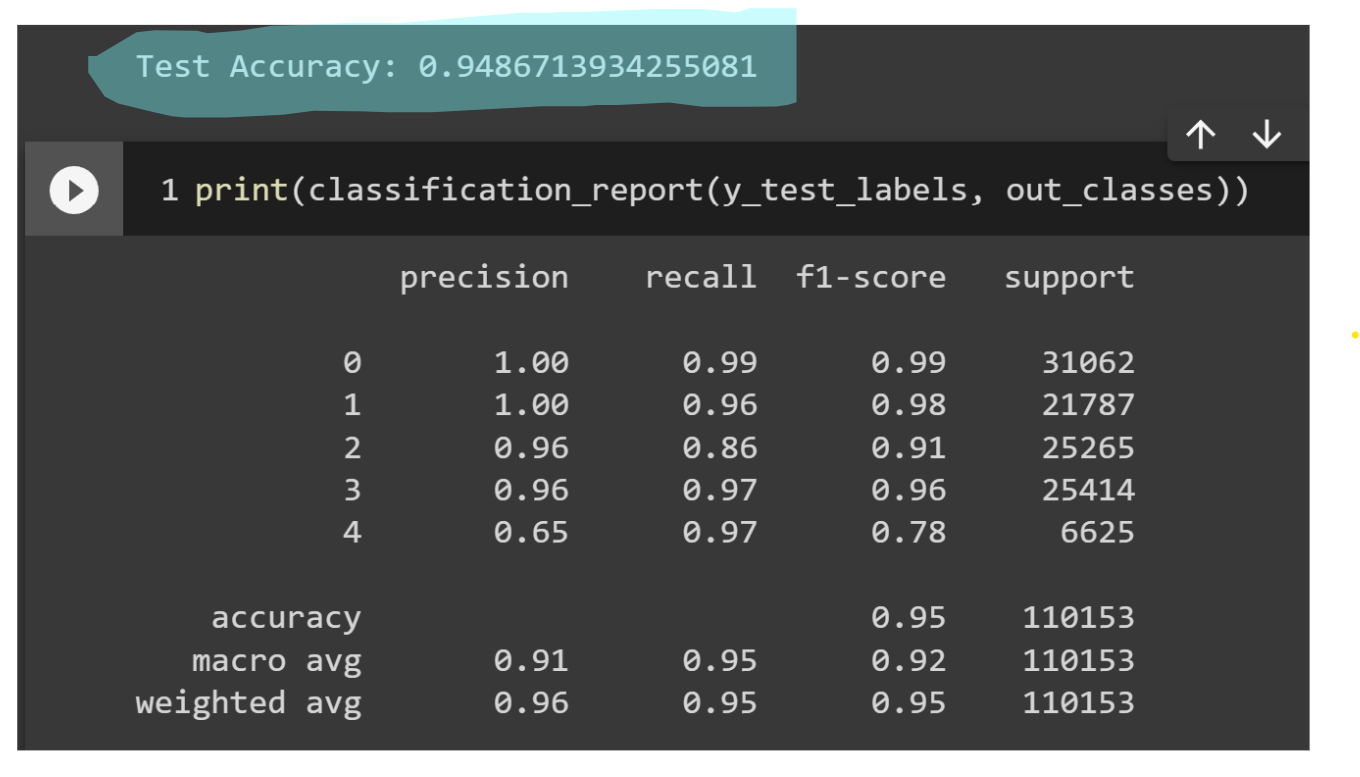
Encoded
Data
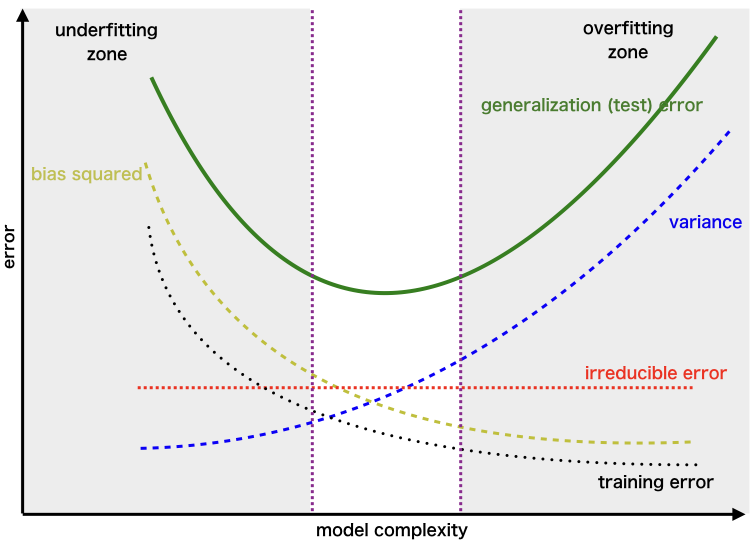
Trabajo actual
Función de aprendizaje del modelo
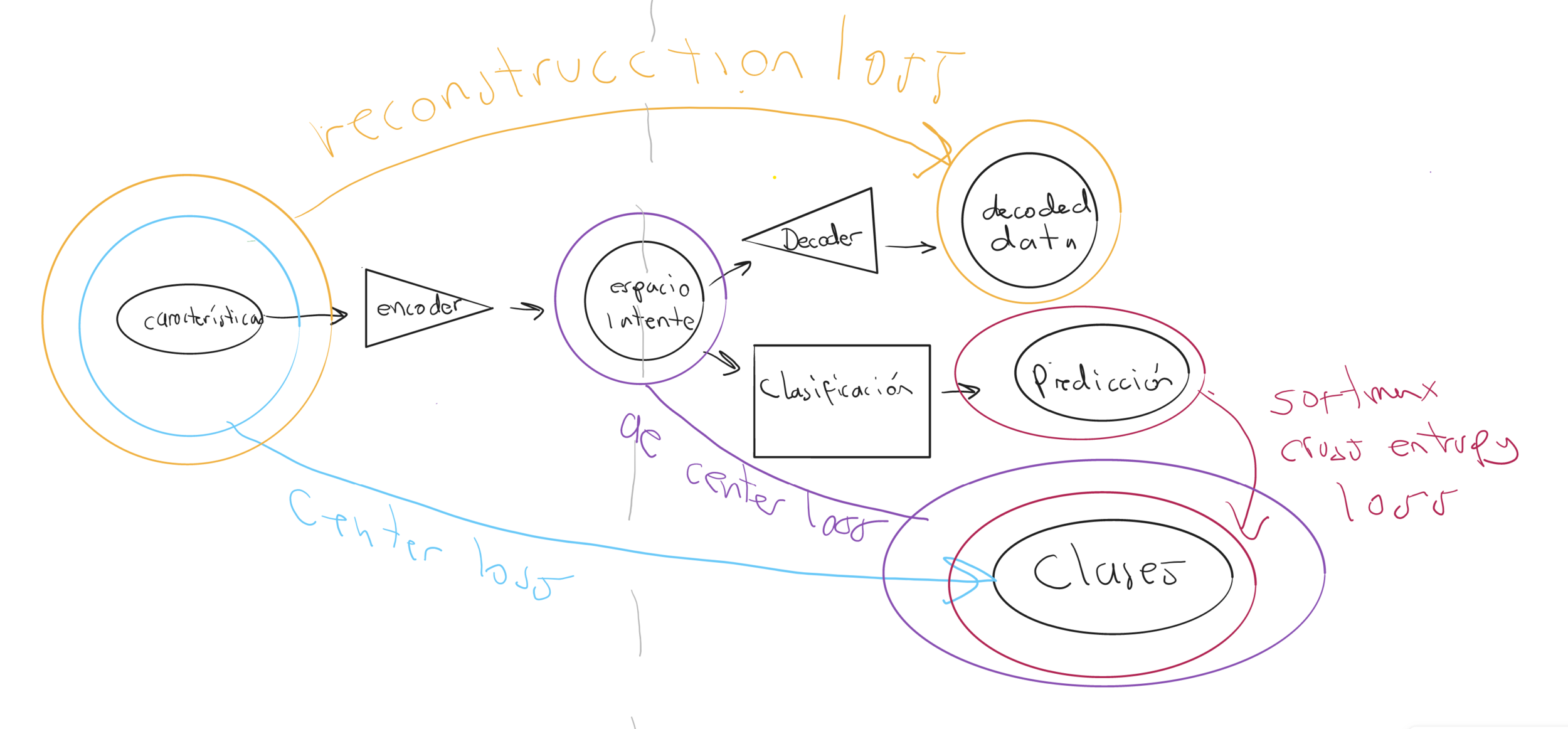
Conclusiones
- Arquitectura: modelo agnóstico
- Soporta alta dimensionalidad
- Mínimo preprocesamiento
- Propiedades interclase
- Compresión y agrupamiento
- One loss, one backbone
- Augmented tabular data
Trabajo a futuro
¡Mejorar reentrenando los módulos!
Baseline
With Embeddings


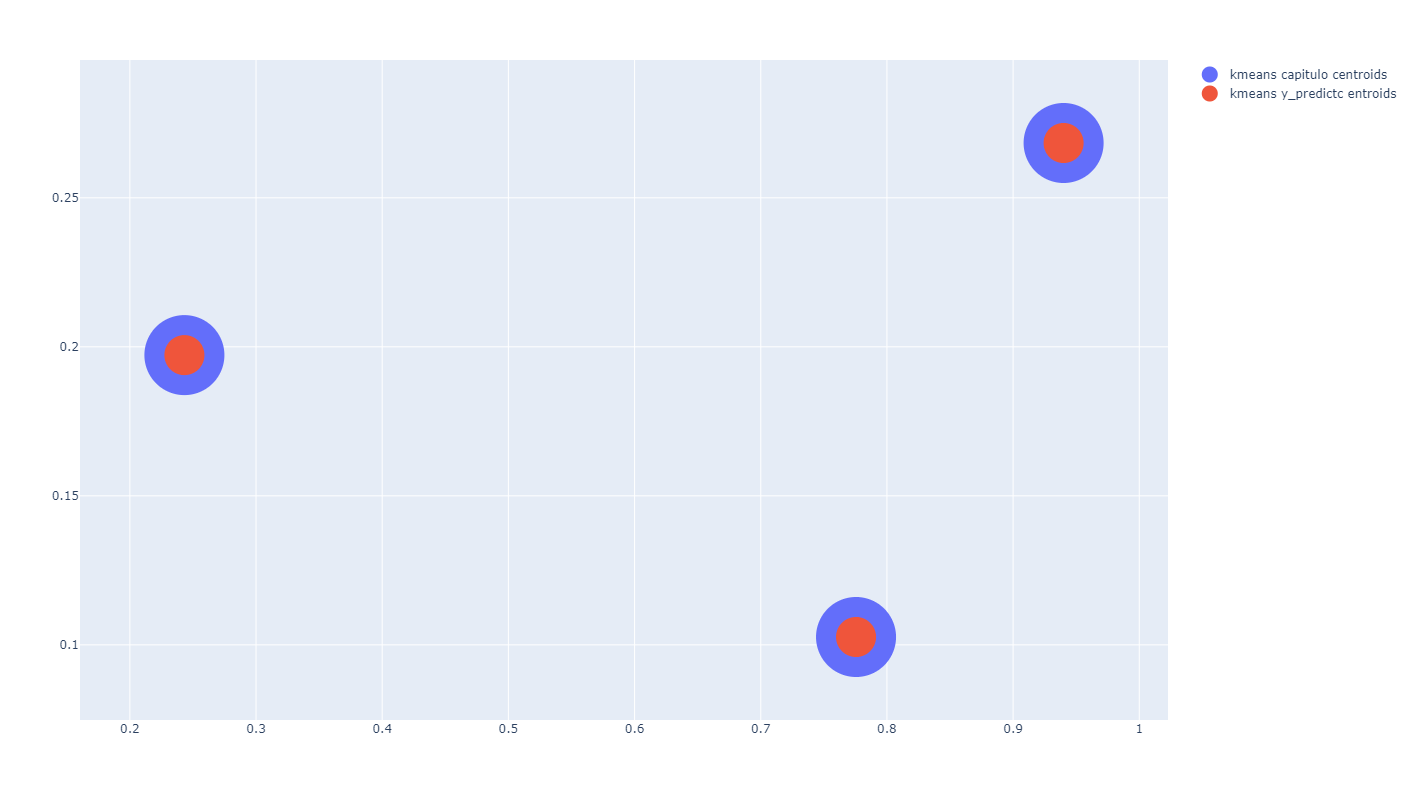
Añadir estadísticas al análisis de clustering
¡Muchísimas gracias por su tiempo y atención!
🤗
Copy of deck
By Goa J



