
В гості до амазонок
Гейзе Ілля
- займаюсь розробкою для Web з 2005
- основний стек: LAMP, Symfony 2 (PHP)
- керую розробкою YouSeeU з 2010
- почав користуватися AWS у 2011
- не є професійним системним адміністратором
YouSeeU
- платформа для remote education (студенти, викладачі, завдання, оцінювання...)
- основний акцент: робота з video
- працює як окрема платформа так і в інтеграції з іншими Learning Management Systems
- основні клієнти - вищі навчальні заклади
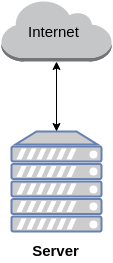
Коли дерева були великими ...
нам вистачало одного сервера, там було усе:
і база, і application і навіть cron jobs

Vertical scaling
давайте просто візьмемо більший сервер
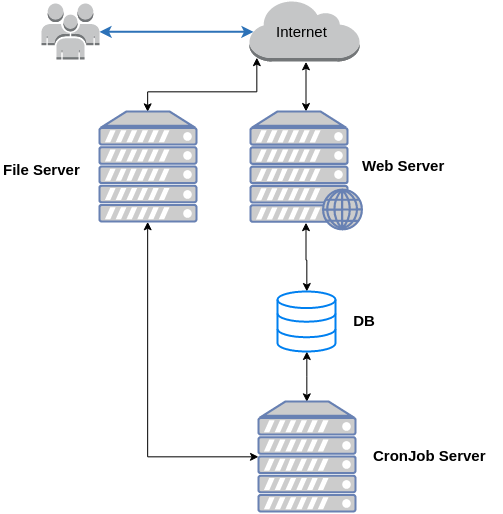
Коли великого серевера вже не вистачає

Horizontal scaling
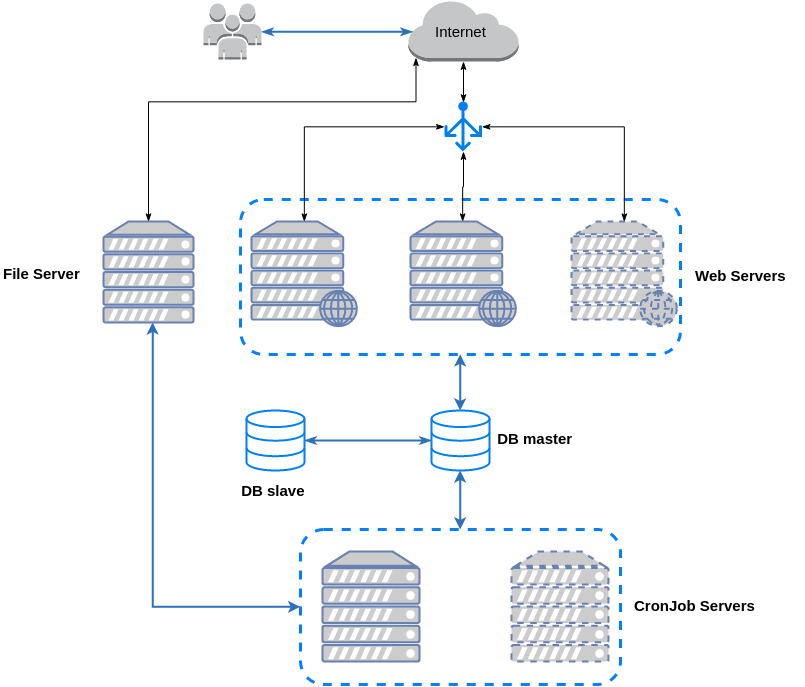
Horizontal scaling
- продукт має підтримувати horizontal scaling
- необхідно мати script для розгортання на новому сервері
- додавання новї ноди в группу може займати довгий час (особливо у випадку dedicated server)
- точки відмови: LB, DB, File server
- якщо відмовляє весь дата центр - нічого не допоможе
- хтось вже має це все адмініструвати
- "Неофициальные источник нам сообщил, что система пожаротушения не сработала не по причине технических проблем, а потому, что была отключена вручную."
-
"Сначала загорелось, потом приехали пожарники и дозалили."
-
"если помните буквы, с которых начинается ID сервера, то может быть, вам повезло:
A, B, C = надежда есть, что остались целые
D = обгорел примерно наполовину
E, F, G = сильно обгорели"
2010 - пожежа в датацентрі компанії Hosting.ua
взято з http://habrahabr.ru/post/89172/
Що впало, те пропало
- VPS купувався у відомої (в свій час) української компанії, однієї з лідерів ринку
- сервер перестав відповідати
- панель адміністрування не працює
- support не відповідає на пошту і телефон
- де бекапи ? на серверах тієї ж компанії !
- через 3 тижні з нами вийшли на зв’язок: "компанія міняла власника"
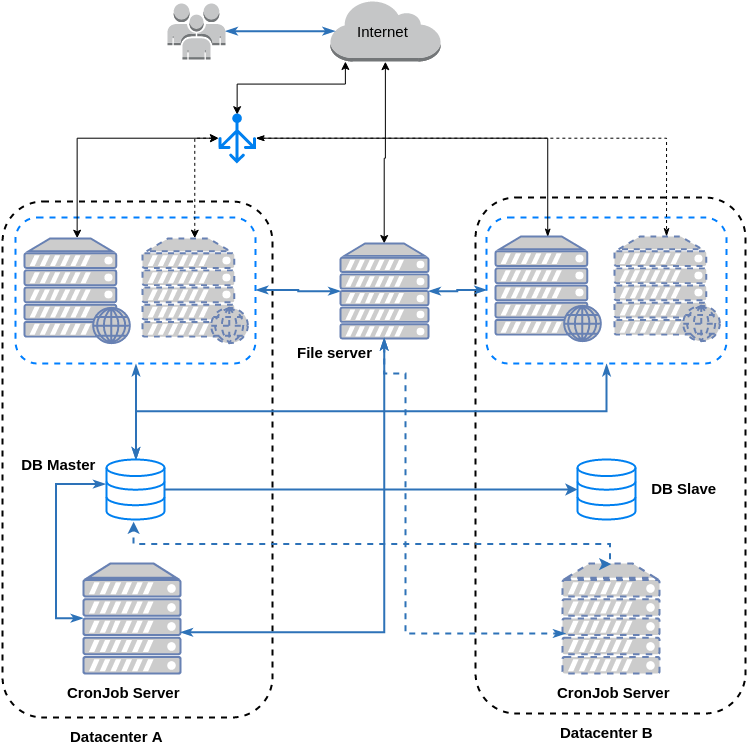
Horizontal scaling у різних датацентрах
- точки відмови: Load Balancer, File server, DB
- потрібен Load Balancer з підтримкою node failover
- якщо відмовляє весь дата центр ви набагато швидше відновите роботоздатність продукту
- потрібен гарний зв’язок між датацентрами для реплікації DB
- хтось ТОЧНО має за цим усім наглядати
Horizontal scaling у різних датацентрах
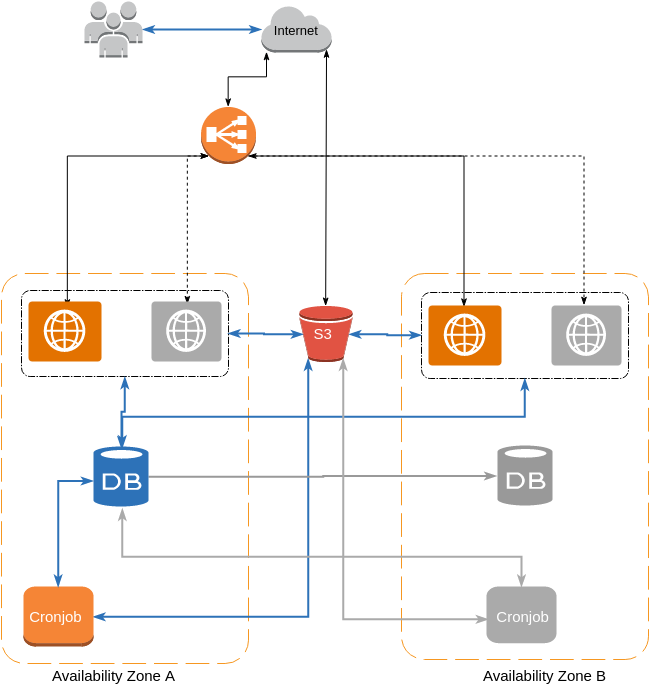
в AWS це виглядатиме майже так само
Переваги отриманої системи
- критичні вузли (DB, S3, ELB) продубльовані (прозоро для нас) і готові до високих навантажень
- вся реплікація і перемикання DB відбуваються автоматично
А що ще ми отримуємо від переходу на AWS
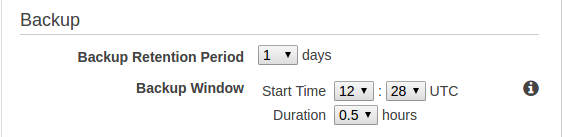
- Backups
- Security (Firewall, Identity Access Management)
- Monitoring (CloudWatch)
- можливість інтеграції з іншими сервісами AWS
- меньше часу і зусиль на підтримку
- для всього є CLI, можна автоматизовувати процеси
- ми майже готові до AutoScaling
AWS: просте вирішення рутинних задач
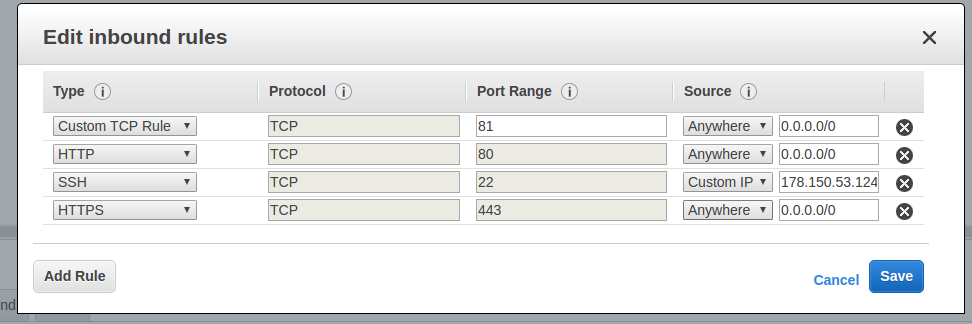
Firewall
MySQL backup
AWS: неочевидні важливі переваги
- стабільність інфраструктури
- більшість задач з адміністрування - рутинні і ви можете вирішити їх самі
- типові задачі легко вирішуються, для нетипових у вас є всі можливості вирішення самостійно
- ви концентруєтесь на розробці продукту а не на підтримці інфраструктури
- готовність до майбутнього зростання
Наш досвід використання сервісів AWS
CDN
- до 2011 використовували CacheFly
- отримали проблеми з тим що треба чекати до 10 хв поки файл буде доступний на сервері після завантаження
Після переходу на S3
| Cachefly | S3 + CloudFront | |
|---|---|---|
| Storage | $1.00 / GB | $0.03/ GB |
| Traffic | $0.100 / GB | $0.085/GB |
- забули про проблеми з поширенням файлу по серверам
Кодування відео
- в нашому випадку 95% це просте перекодування з одного формату в інший
- використовували encoding.com
| Переваги | Недоліки |
|---|---|
| дуже широкиї функціонал для роботи з відео | кількість незакодованих з незрозумілих причин 1-2% |
| швидкість роботи |
Після переходу на Elastic Transcoder
- швидкість зросла в ~5 раз
- витрати зросли ~10%
- продовжуємо використовувати encoding.com для тих задач де невистачає можливостей Elastic Transcoder
Autoscaling
- ноди запускаються і вимикаються автоматично
- процес керується подіями у CloudWatch
- якщо нода "впаде" вона буде перезапущена автоматично
- раптове збільшення навантаження не призведе до падіння чи уповільнення роботи системи
Autoscaling неочевидні деталі
- має сенс навіть для single instance
- ноді аби запуститися потрібен час
- ноди можуть перезапускатися, коли AWS вирішить за потрібне, ставте захист, якщо є необхідність
Autoscaling дуже важко реалізувати поза cloud
А на практиці
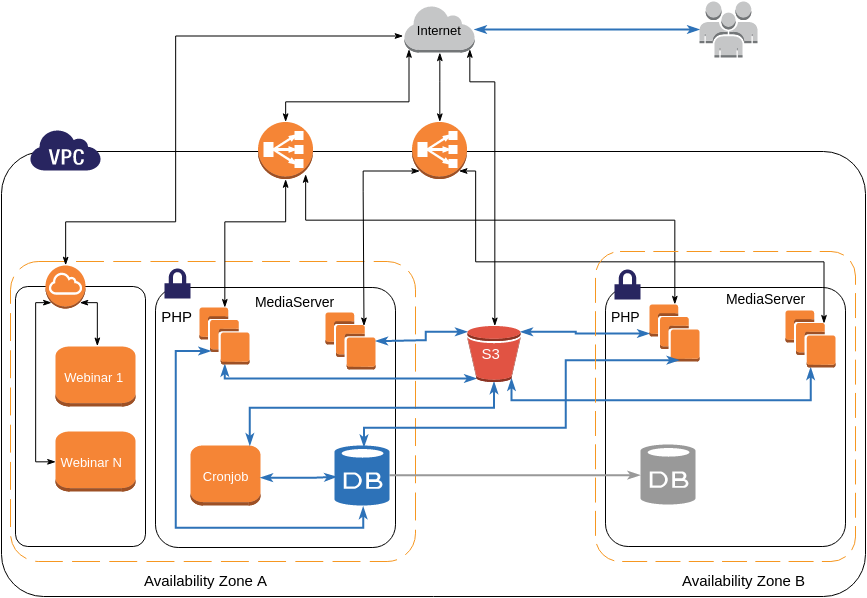
Перевіряйте ціни КОЖНОГО використаного сервісу AWS
Скільки це коштує ?
Тож скільки це коштує ?
Тож скільки це коштує ?
| Роль | Кількість | Характеристики | Ціна |
|---|---|---|---|
| Web | 2 | t2.medium (2 vCPU, 4 GB RAM, 32 GB HDD) |
$ 82.14 |
| Cronjob | 1 | c4.large (2 vCPU, 3.75 GB RAM, 64 GB HDD) | $ 78.12 |
| DB node | 2 | db.t2.medium (2 CPU, 4 GB RAM, 10 GB HDD) MultiAZ | $ 104.71 |
| Monitoring | 4 | CloudWatch | $ 14.00 |
| ELB | $ 18.30 | ||
| S3 | 100 GB | storage only no traffic | $ 3.00 |
| Traffic | 100 GB | $ 9.00 | |
| $ 309.27 |
За рік ($309.27 * 12) = $ 3711.24 (у випадку reserved $ 2757.35)
Порахуємо Dedicated ?
-
Intel Xeon D-1520 32 GB RAM (DDR3) 2x2 TB Disk
-
Backup: 500 GB of storage space
-
Traffic: unlimited
| Роль | Кількість | Ціна |
|---|---|---|
| Web + Cronjob + DB | 2 | $ 156.50 |
| Administration | 2 | $ 100.00 |
| $ 256.50 |
За рік ($ 256.50 * 12) = $ 3078
Адміністратор = людський фактор
AWS Free Tier
- node: t2.micro (1 vCPU, 1GB RAM)
- volume: 30GB (ssd possible), 1GB backups
- DB: db.t2.micro 20GB storage, 20GB backup
- S3: 5GB
- Data Transfer: 15 GB
- CloudFront: 50GB transfer out to Internet
Це надається безкоштовно
ТІЛЬКИ перші 12 місяців
після реєстрації
А що там в дрібном’яких ?
| Vendor | Type | Cores | RAM | Disk | Per hour | Per month |
|---|---|---|---|---|---|---|
| Azure | A2 Standard | 2 | 7 GB | 100 GB | $ 0.154 | $ 115 |
| AWS | t2.medium | 2 | 8 GB | 100 GB | $ 0.117 | $ 87 |
| Azure | D3 | 4 | 14 GB | 200 GB | $ 0.268 | $ 199 |
| AWS | m4.xlarge | 4 | 16 GB | 200 GB | $ 0.266 | $ 198 |
| Azure | D5 v2 | 16 | 56 GB | 800 GB | $ 1.277 | $ 950 |
| AWS | m4.4xlarge | 16 | 64 GB | 800 GB | $ 1.066 | $ 793 |
AWS vs Azure
AWS Downtime
- 20 квітня 2011- проблеми з (EBS), два дні
до повного відновлення - 22 жовтня 2012 - проблеми торкнулися багатьох відомих сайтів (Reddit, Foursquare, Pinterest etc)
- 22 вересня 2015 - проблеми протягом 5 годин у US East region
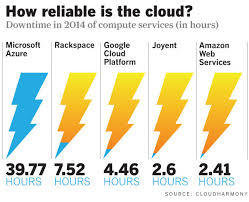

Як можна витрачати меньше

Секретна зброя

Як можна витрачати меньше
- Використовуємо дешевший регіон
Дешевший регіон
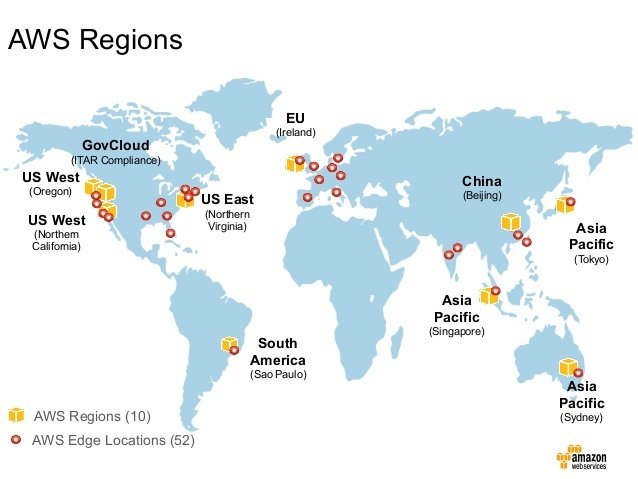
Дешевший регіон
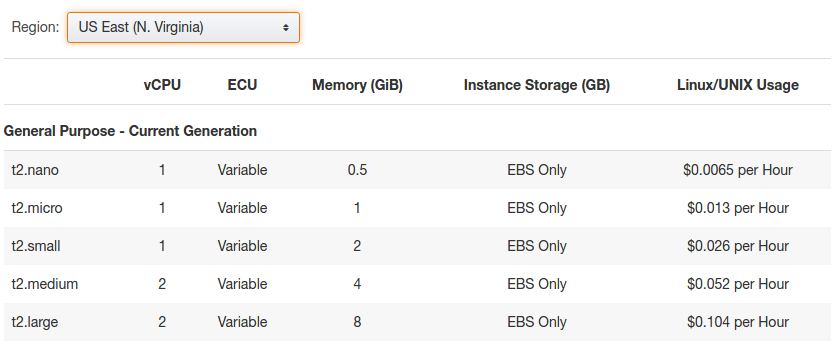
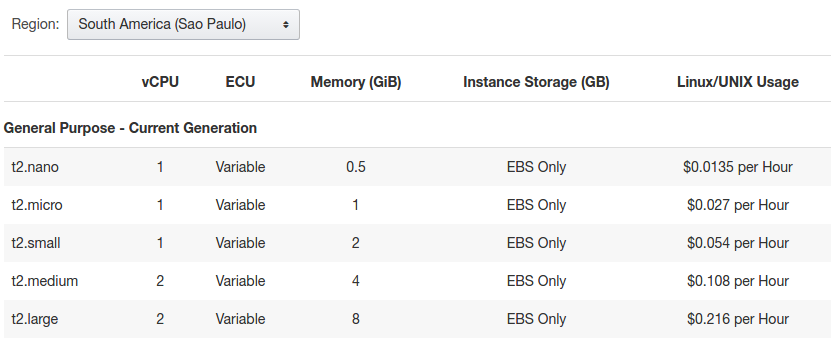
- Використовуємо дешевший регіон
- Замовляємо наперед (Reserved instances)
Як можна витрачати меньше
-
на 1 рік - економія 21-37%
-
на 3 роки - економія 54-61%
-
сервери, DB (EC2, RDS)
-
не знадобилося - є можливість продати
Як можна витрачати меньше
- Використовуємо дешевший регіон
- Замовляємо наперед (Reserved instances)
- Регулярно перевіряємо рівень використання замовлених ресурсів
Перевіряємо рівень використання
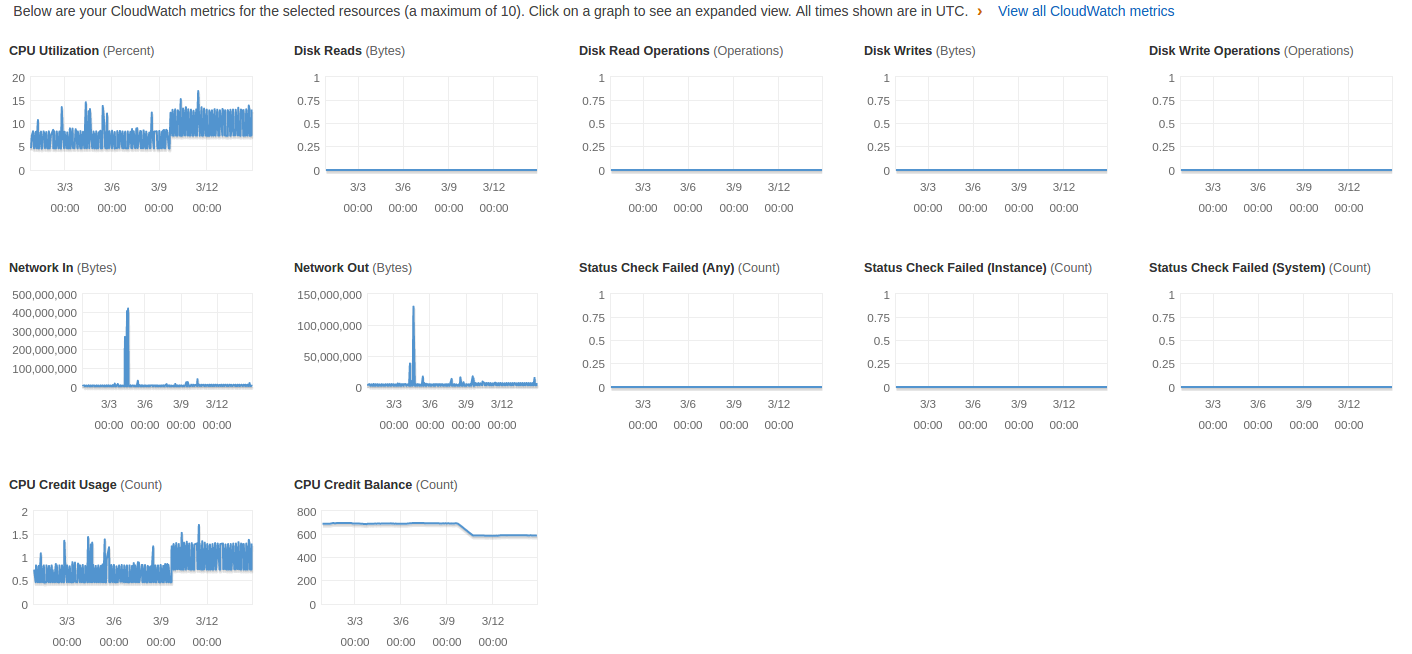
Як можна витрачати меньше
- Використовуємо дешевший регіон
- Замовляємо наперед (Reserved instances)
- Регулярно перевіряємо рівень використання замовлених ресурсів
- Регулярно перевіряємо структуру витрат
Перевіряємо структуру витрат
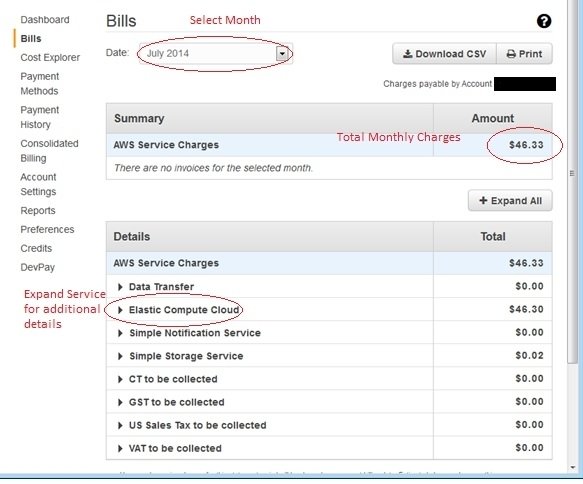
Рахунок
Перевіряємо структуру витрат
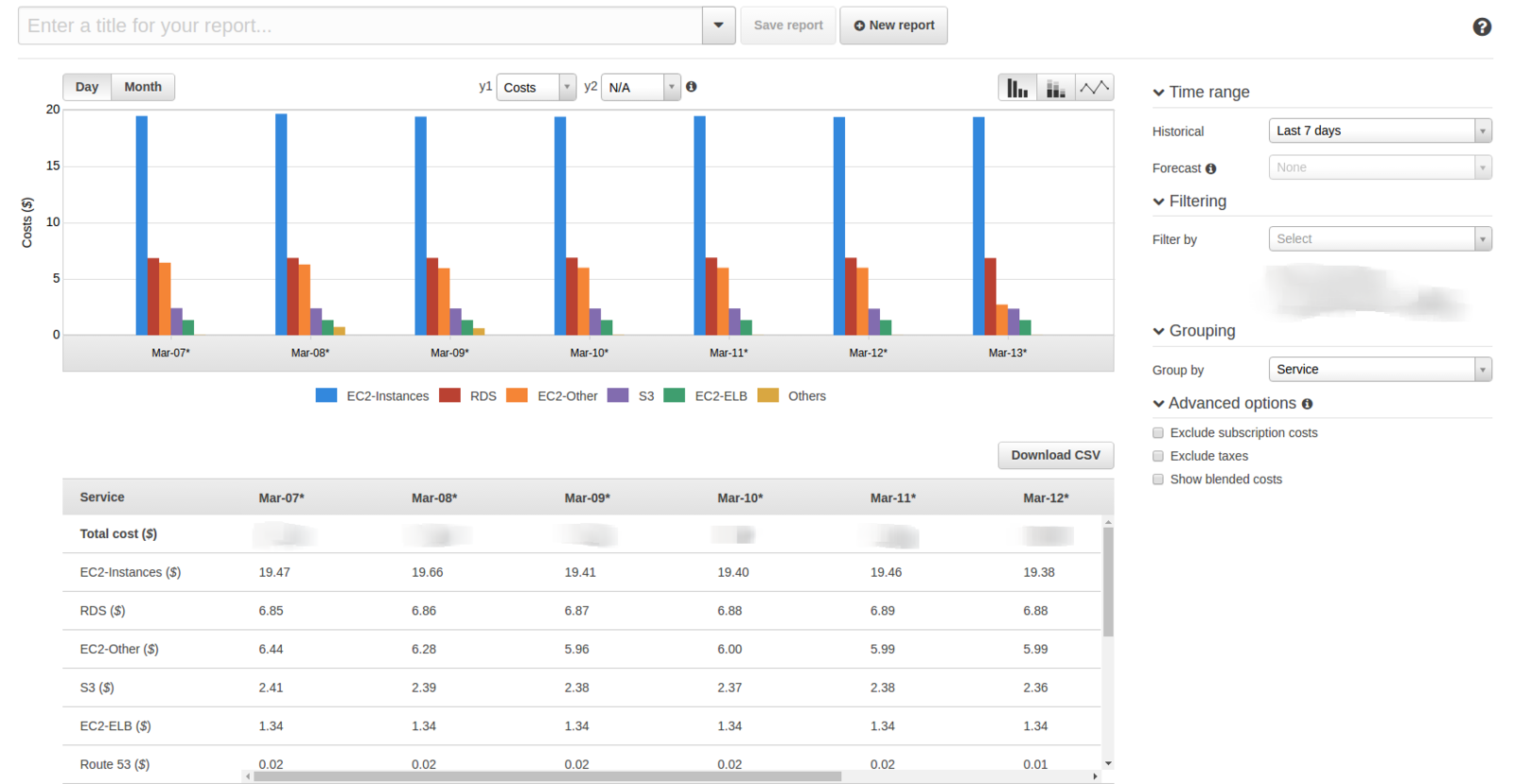
Cost Explorer
Як можна витрачати меньше
- Використовуємо дешевший регіон
- Замовляємо наперед (Reserved instances)
- Регулярно перевіряємо рівень використання замовлених ресурсів
- Регулярно перевіряємо структуру витрат
- Використовуємо Auto Scaling / Scheduled instances
Як можна витрачати ЩЕ меньше

Як можна витрачати ЩЕ меньше
- Контроль використаної суми
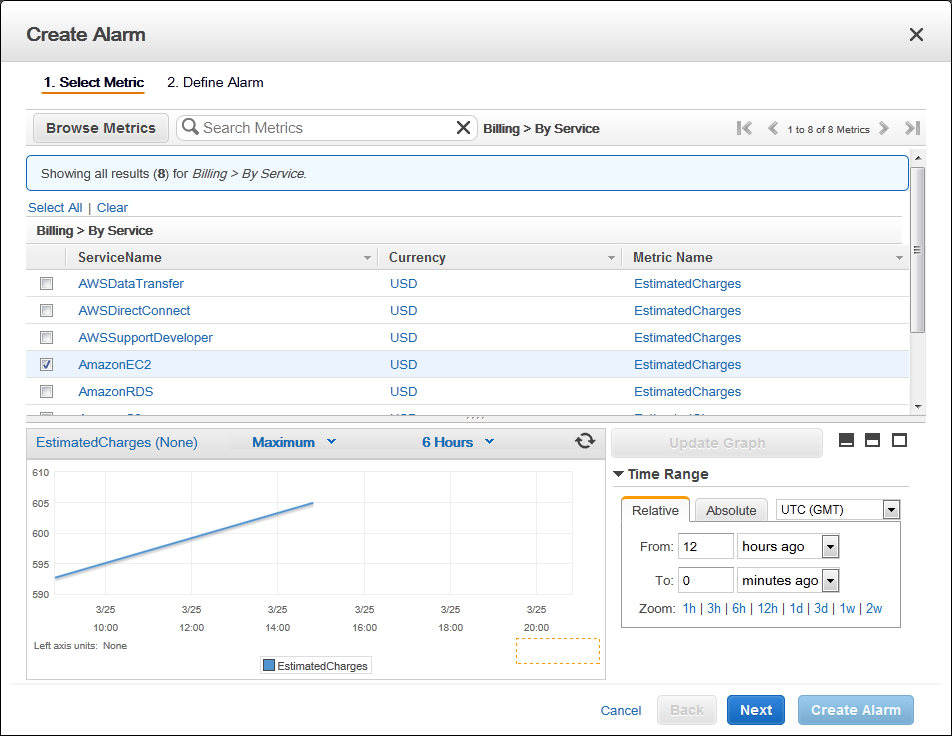
Як можна витрачати ЩЕ меньше
- Контроль використаної суми
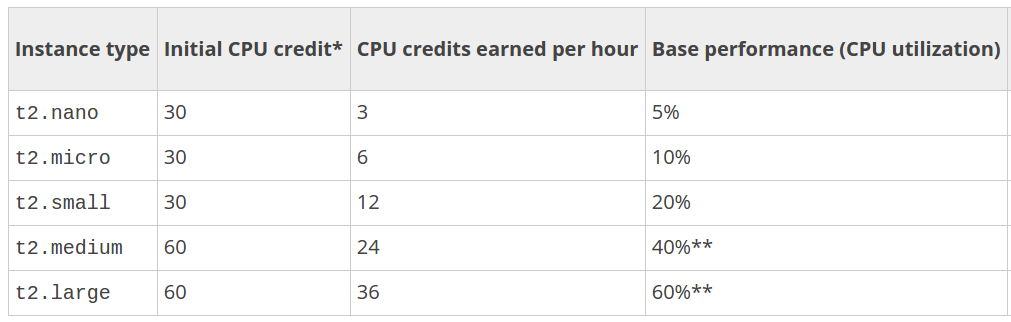
- t2 instance type
t2 instance type
- дешевші за аналогічні звичайні (приблизно у 2 рази)
- дають можливість тільки тимчасового CPU Boost до вказаної потужності
- накопичують кредити до 24 годин
Як можна витрачати ЩЕ меньше
- Контроль використаної суми
- t2 instance type
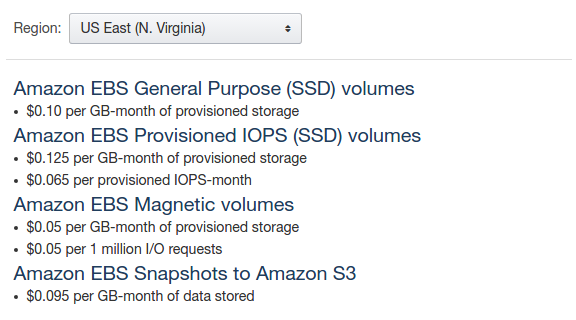
- Правильний volume type
Як можна витрачати ЩЕ меньше
- Контроль використаної суми
- t2 instance type
- Правильний volume type
- Spot instances & Lambda
Spot instances
- стандартні EC2 інстанси
- обіцяють економію до 90%
- "Аукціон"
- Instance можуть вимкнути у будь який момент (попередять за 2хв)
- платите тільки за повністю використані години
- стандарнтий сценарій використання - batch processing
- у Вас взагалі немає серверу
- платимо тільки за час коли виконується наш код на стандартизованому інстансі
- event based, event sources: S3, DynamoDB, Kinesis, SNS, SES, CloudWatch
- підтримуються NodeJS, Python, Java
Lambda
Як можна витрачати ЩЕ меньше
- Контроль використаної суми
- t2 instance type
- Правильний volume type
- Spot instances & Lambda
- Перевіряємо нові сервіси, зміни цін і умов
Як можна витрачати ЩЕ меньше
- Контроль використаної суми
- t2 instance type
- Правильний volume type
- Spot instances & Lambda
- Перевіряємо нові сервіси, зміни цін і умов
- Використовуємо AWS тільки для частини нашої інфраструктури
Резюмуємо
Недоліки
- вища "середня вартість" серверів у порівнянні з dedicated
- присутній Vendor Lock
- треба докласти деякі зусилля і почитати доку (хоч іноді)
- в AWS ще не має кнопки "зробити усе за мене"
Переваги для Бізнесу
- висока стабільність інфраструктури
- зменьшення людського фактору у адмініструванні
- гарна масштабуємість (autoscaling)
- Vendor Lock не "жорсткий"
- можливість автоматизації процессів
- оперативний і адекватний support у випадку проблем
- вагомий аргумент для клієнтів бізнесу =)
Переваги для стартапів
- простота вирішення щоденних типових задач
- можете обійтися без системного адміністратора
- підвищення базового рівня безпеки
- багато готових надійних рішень "з коробки"
- легко і дешево експериментувати
- можна скористатися Free Tier
- ви готові до зростання
Жодна із згаданих в цій доповіді компаній не платила за рекламу
Disclaimer:
Радо відповім
на Ваші запитання


migration-to-amazon
By greenworld