Research Salon
Accurate online training of dynamical spiking neural networks through Forward Propagation Through Time
https://arxiv.org/abs/2112.11231
Background
- Training Recurrent Neural Networks via Forward Propagation Through Time
https://icml.cc/virtual/2021/spotlight/10384
- Liquid Time-constant Networks https://arxiv.org/abs/2006.04439
- SNNs have demonstrated competitive and energy-efficient applications so far, e.g. Yin et al. 2021
Backprop Through Time (BPTT)
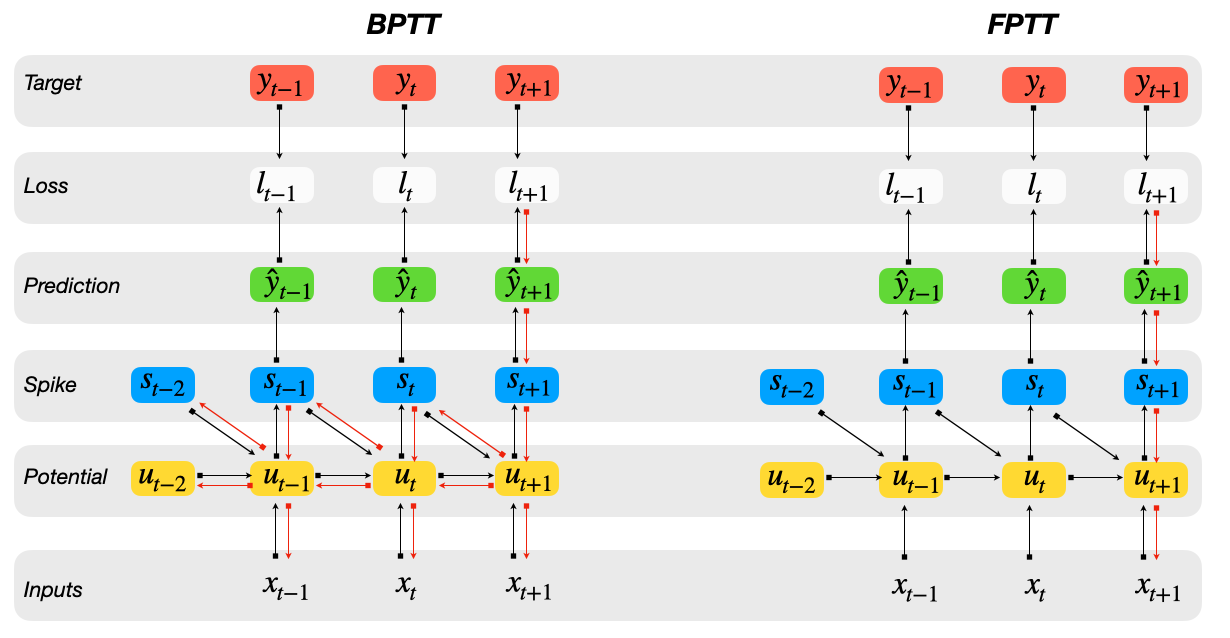
- Training instabilities: vanishing or exploding gradients
- Memory overhead Ω(T)
- cannot be applied online: network is 'locked' during backward pass
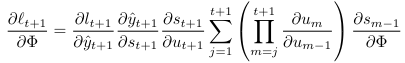
Forward Propagation Through Time (FPTT)
-
FPTT takes a gradient step to minimize an instantaneous risk function at each time step
-
straightforward application of FPTT to SNNs fails
FPTT objective functions
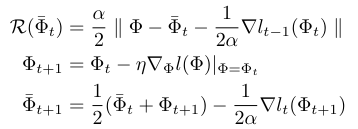
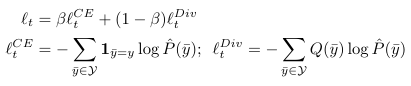
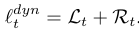
Intermediate Losses for Terminal Prediction
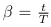
with
Pseudo code


Liquid Time Constant SNN
Hasani et al., 2020
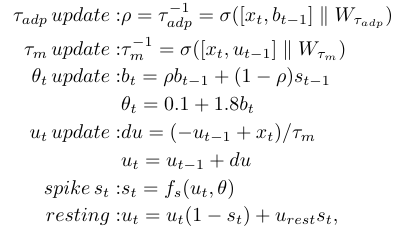
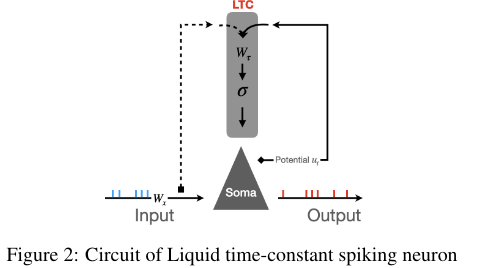
--> time constants are a function of inputs and hidden states
The Add task
One data point consists of two sequences (x1, x2) of length T and a target label y.
Example:
x1: <0, 0, 0, 1, 0, 0, 1, 0>
x2: <0.1, 0.6, 0.7, 0.2, 0.5, 0.8, 0.4, 0.3>
y: <0, 0, 0, 0.2, 0.2, 0.2, 0.6, 0.6>

ASRNN: Adaptive Spiking RNN
LTC-SRNN: Liquid Time Constant Spiking RNN
The Add task
DVS Gesture
- 20 - 500 frames are pre-processed using an SCNN
- pre-processed input is flattened to 1D inputs
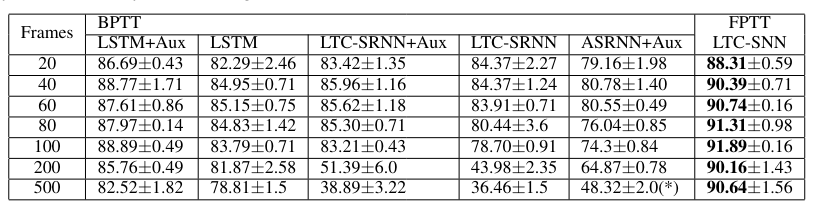
FPTT improves over online approximations of BPTT
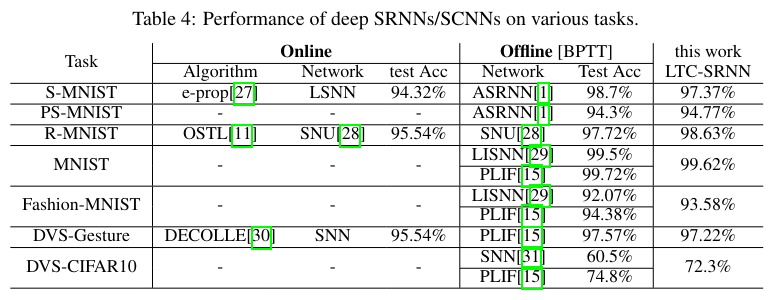
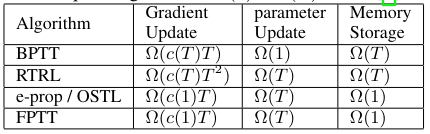
Memory requirements and training time

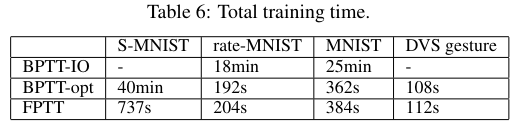
Conclusions
- FPTT works very well for long sequence learning with recurrent SNNs as long as LTC neurons are used.
- It's not slower (with room for improvement) and has constant memory requirements.
- Potentially very interesting in an online setting on neuromorphic hardware
Open Questions
- How stable is training really?
- Could this be applied to non-recurrent architectures?
- Could this be combined with self-supervised learning?
FPTT research salon
By Gregor Lenz



