Transfer Learning in NLP
Hamish - OVO
Part 1: Transfer learning
Hi! I'm hamish 👋
- Joined ACE team ~2 months ago
- Background in physics
- Previously at startups doing MLE/DE/FP stuff
- Kinds of things I know a bit about
- Sequence models, NLP stuff
- Building models quickly
- Building models with very little labelled data
- Getting things deployed
Text
Transformer models
Killer app idea: potato/not-potato

- build a potato/not-potato app
- just a few hundred images
- just a few lines of code
Problem 1: Architecture
Often best first step is to see what everyone else is using
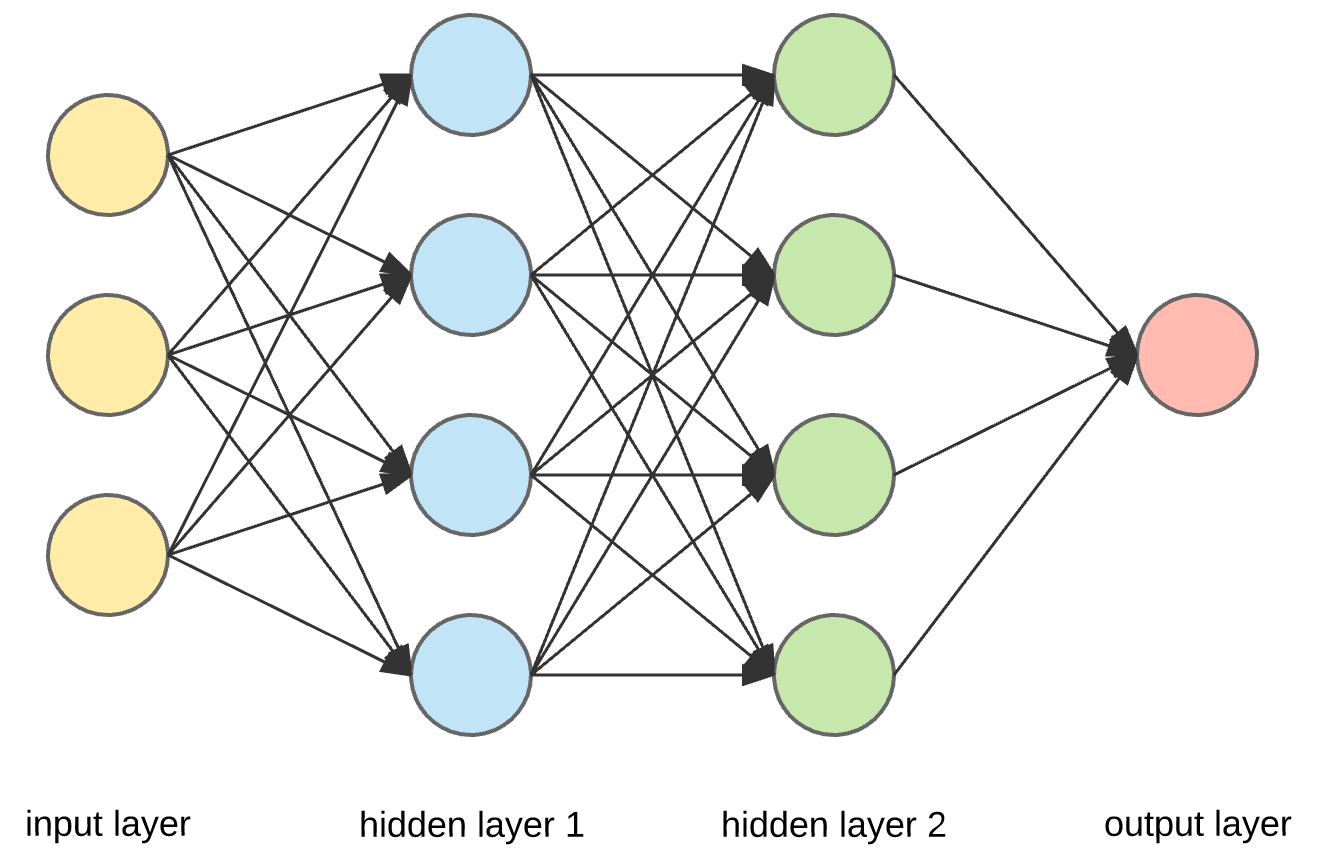
????
🥔/❌

ResNet
from torchvision import models
model = models.resnet32()
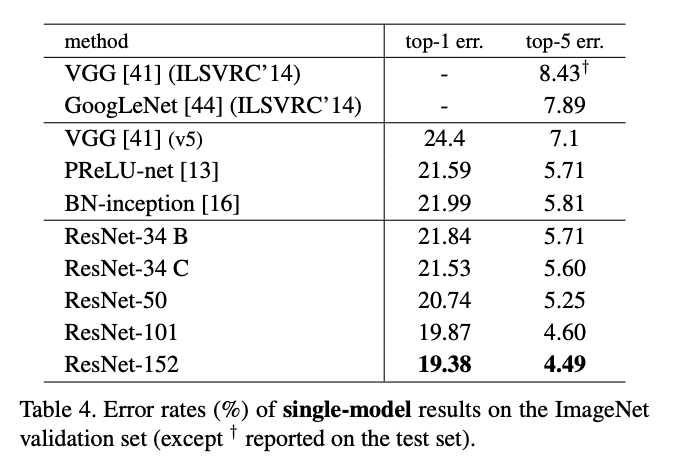
Problem 2: Training
- Training SOTA models isn't easy
- Lots of data: 1M+ images, 1000 categories
- Resource heavy: 50GPUs for 100 epochs
- Can't expect to have 1M+ images, 50GPUs, 1000 categories
- What can we reasonably do?
What do NN's learn?
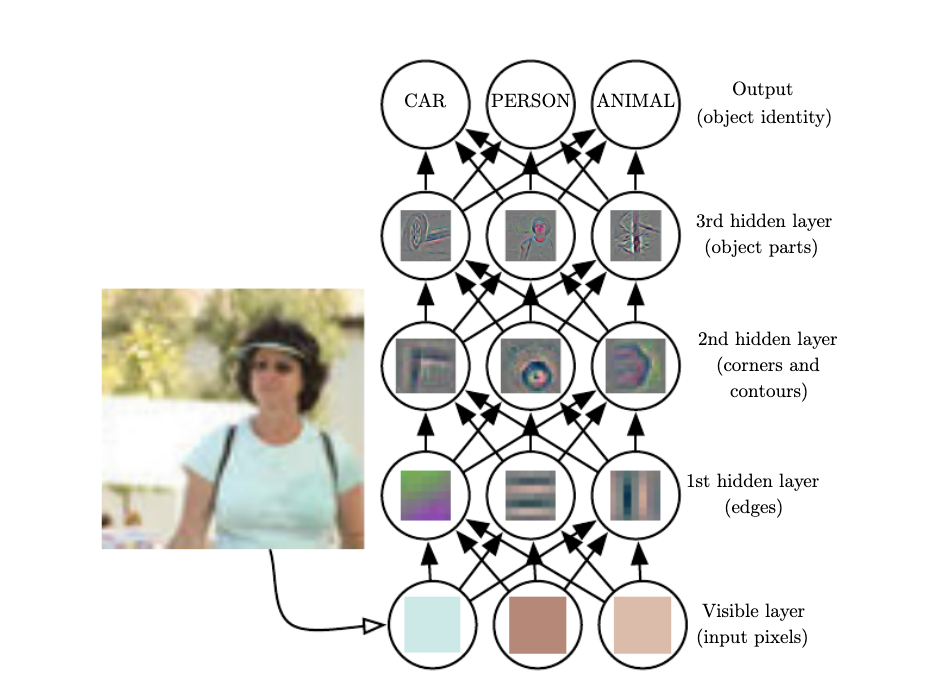
Zeiler et al 2016
Can exploit this
- get a pretrained model close to what we want
- fix layers (transfer learning)
- or keep them trainable (fine tuning)
- replace the old output with something matching what we need
- randomly initialise new output layer and train
# get pre-trained model
model = models.resnet18(pretrained=True)
# fix the parameters so they don't train
for param in model.parameters():
param.requires_grad = False
# define a new last layer with random initialistion
model.fc = nn.Linear(512, 1)Wait! I have code!
Why does this work?
Not a golden hammer
- Very common in CV
- Never see this in NLP
- Need a pretrained NN close to what you want to do
- Doesn't help if you're going to train big anyway (link to FAIR paper)

Transfer Learning
By Hamish dickson



