Deep Generative models (VAEs) for ODEs with knows and unknowns
Harshavardhan Kamarthi
Data Seminar
Variational Auto-Encoder
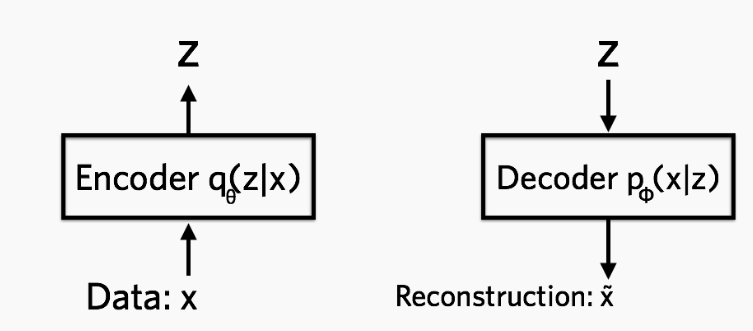
- Goal: Learn distribution p(X)
- Encode x towards a known distribution on latent variable z. Decode z to x
Variational Auto-Encoder
Encoder
Prior on latent variable . Usually set as standard Gaussian.
Decoder
Variational ELBO Loss
q(z|x)
p(z)
p(x|z)
-E_{q(z|x)}[\log p(x|z)] + KL[q(z|x)||p(z)]
Physics based VAEs
- Model data from complex ODEs
- Learn low-dimensional latent representations from data
- Learn relation between observed state and latent state where latent states are governed by ODE
- Learn parameters of the latent ODE
ODE2VAE: Deep generative second order ODEs with Bayesian neural networks
z_1
z_2
z_3
\dots
\dots
z_N
x_1
x_2
x_3
\dots
\dots
x_N

Yidiz et al (NIPS '19)
ODE2VAE: Deep generative second order ODEs with Bayesian neural networks
No information about the functional form
Goals:
- Learn low lank representations from sequential data
- Extrapolate/forecast
Z
\{x_{N+1}, x_{N+2}, \dots\}
Second-order Bayesian ODE
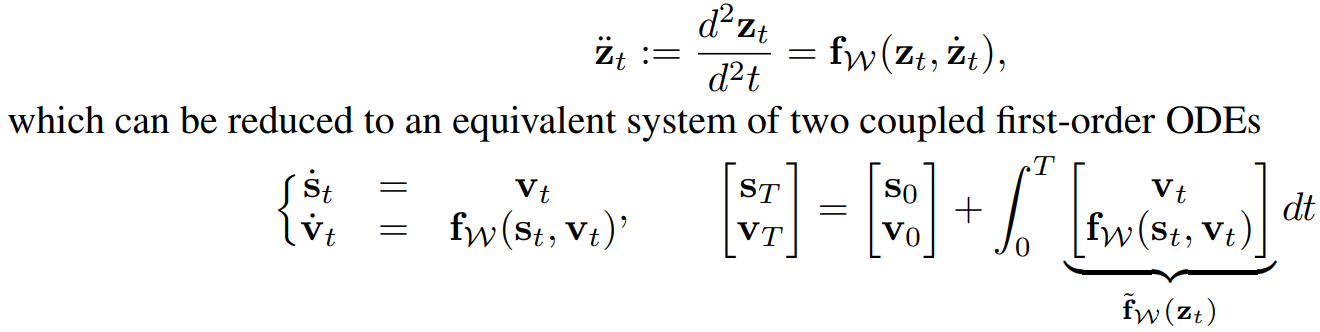
- Second-order: to model higher-order dynamics
- is a Bayesian Neural network with prior
- To capture uncertainty
f_{\mathcal{W}}
p(\mathcal{W})
ODE2VAE Model
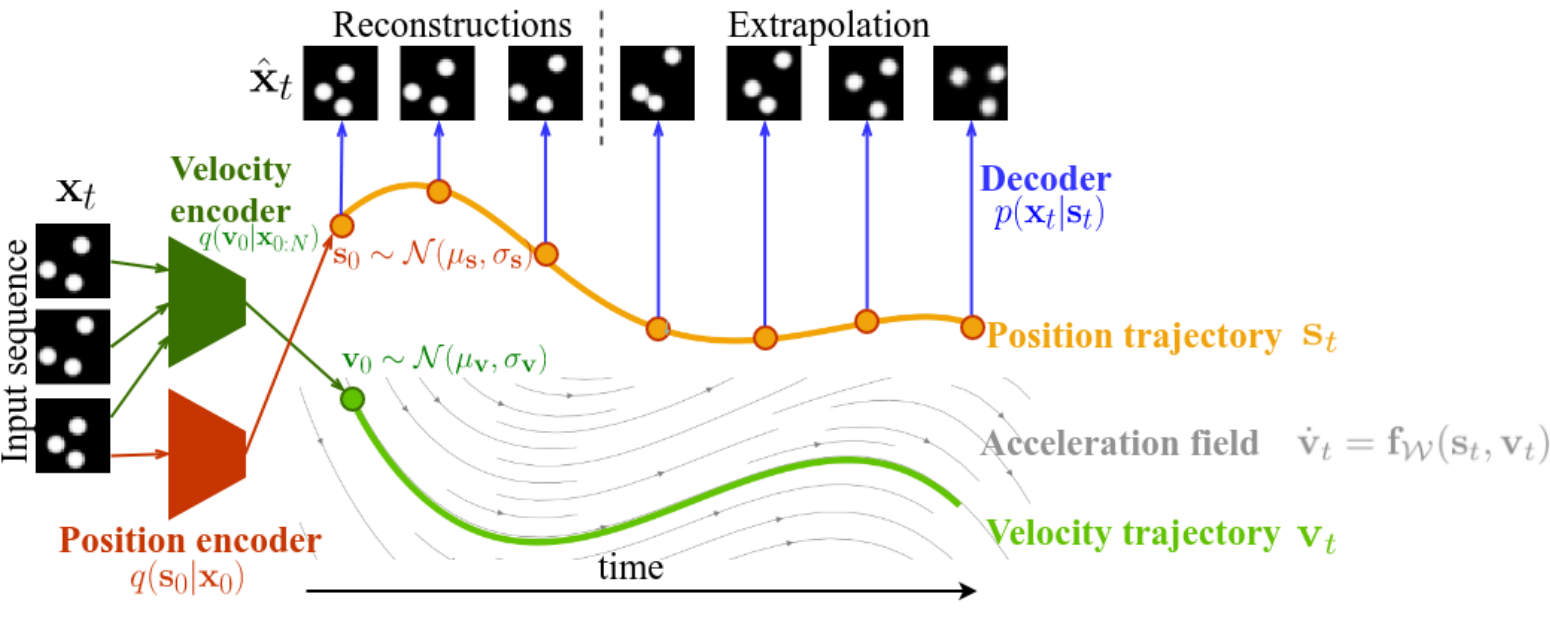
ODE2VAE Encoder
q(\mathcal{W}, Z|X) = q(\mathcal{W})q_{enc}(z_0|X)q_{ode}(Z[1:N]|X,z_0,\mathcal{W})\\
q_{enc}(z_0|X) = \mathcal{N}((\mu_s(x_0), \mu_{v}(X[0:M])), diag(\sigma_s(x_0), \sigma_v(X[0:M])))\\
\log q(z_T|\mathcal{W}) = \log q(z_0|\mathcal{W}) - \int_{0}^{T} Tr\left( \frac{\partial f_{\mathcal{W}(s_t, v_t)}}{\partial v_t} \right)
Note:
- Transition function is stochastic
- 3rd equation derived by "Change of variable" theorem (approximated by Runge-Kutta method)
ODE2VAE Decoder
p(x_t|z_t)
is deterministic NN decoder
ODE2VAE Learning

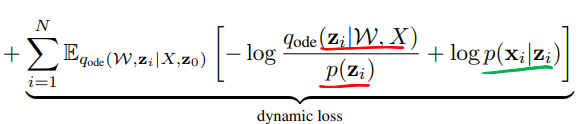
ODE2VAE Learning
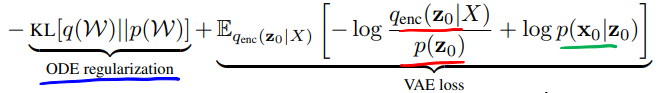
- Dynamic loss dominates VAE loss due to long trajectories
- Data may underfit to encoder distribution
- Add regularizer to make ode and encoder distribution similar
-\gamma E_{q(\mathcal{W})}[KL[q_{ode}(Z|X) || q_{enc}(Z|\mathcal{W},Z)]]
Extrapolation Results
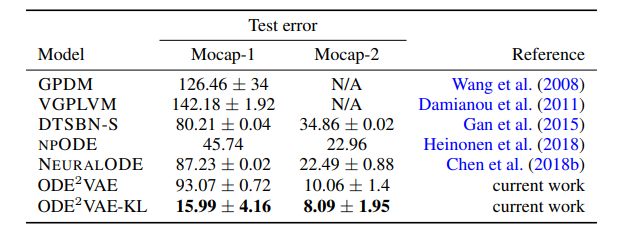
CMU-Walking data (Extrapolate last 1/3 rd trajectory)
Rotating MNIST


Bouncing Ball
Generative ODE Modelling with Known and Unknowns
z_1
z_2
z_3
\dots
\dots
z_N
x_1
x_2
x_3
\dots
\dots
x_N
(\omega_1, \dot{\omega}_1)
(\omega_2, \dot{\omega}_2)
(\omega_3, \dot{\omega}_3)
(\omega_N, \dot{\omega}_N)
Linial et al (CHIL '21)
Generative ODE Modelling with Known and Unknowns
Given the functional form:
\frac{dz_i}{dt} = f_{\theta}(z_i)
Estimate
1. Parameters
2. Extrapolate
\theta
\{x_{N+1}, x_{N+2}, \dots\}
Encoder
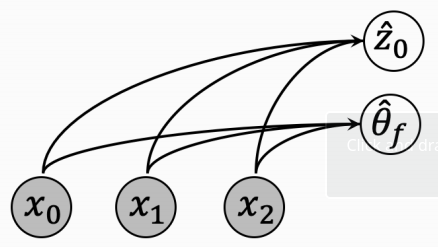
Use RNNs to encode latent variables and then transform to "physics grounded form"
[\mu_{\tilde{z}_0}, \sigma_{\tilde{z}_0}] = RNN_{\tilde{z}_0}(X)\\
q(\tilde{z_0}|X) = \mathcal{N}(\mu_{\tilde{z}_0}, \sigma_{\tilde{z}_0})\\
p(\tilde{z_0}) = \mathcal{N}(0,I)\\
z_0 = h_z(\tilde{z_0})
[\mu_{\tilde{\theta}_0}, \sigma_{\tilde{\theta}_0}] = RNN_{\tilde{\theta}_0}(X)\\
q(\tilde{\theta_0}|X) = \mathcal{N}(\mu_{\tilde{\theta}_0}, \sigma_{\tilde{\theta}_0})\\
p(\tilde{\theta_0}) = \mathcal{N}(0,I)\\
\theta_0 = h_\theta(\tilde{\theta_0})
Decoder
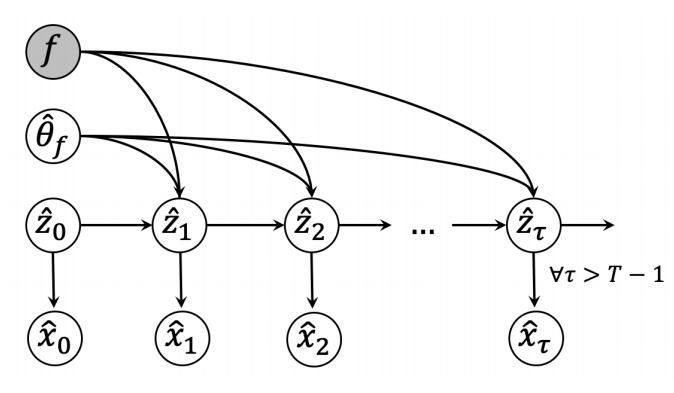
Transition probabilities on latent space is deterministic:
defined from
Transformation to observation space is deterministic via neural network:
defined from
q(z_t|z_{t-1}, \theta)
\frac{dz_i}{dt} = f_{\theta}(z_i)
x_i = g_{\phi}(z_i)
p(x_i|z_i)
Learning
Generative Distribution
p(X,Z,\theta, \tilde{z}_0, \tilde{\theta}_0) = p(\tilde{z}_0) p(\tilde{\theta}_0) p(z_0|\tilde{z}_0) p(\theta_0|\tilde{\theta}_0)
p(x_0|z_0)\prod{i=1}^{N}p(z_i|z_{i-1}, \theta) p(x_t|z_t)
Minimize ELBO
E_{q(Z,\theta, \tilde{\theta}, \tilde{z}_0)|X}[\log p(X|Z,\theta, \tilde{\theta}, \tilde{z}_0)] -
KL[q(Z,\theta, \tilde{\theta}, \tilde{z}_0)|X)|| p(Z,\theta, \tilde{\theta}, \tilde{z}_0)]
=\left( \sum_{n=0}^N E_{q(z_t|X)}[\log p(x_t|z_t)]\right)
- KL[q(\tilde{\theta}|X) | p(\tilde{\theta})]
- KL[q(\tilde{z}_0|X) | p(\tilde{z}_0)]
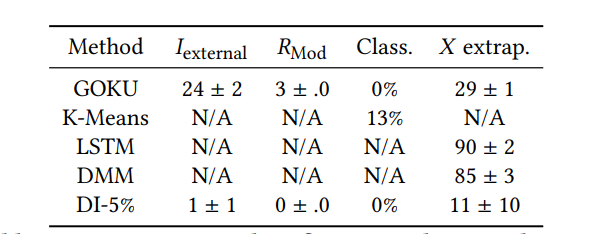
Results
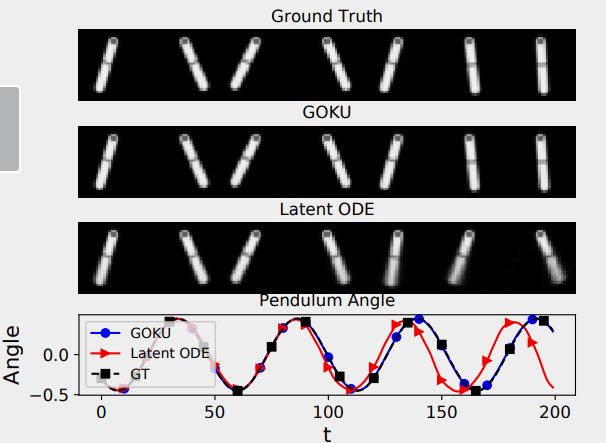
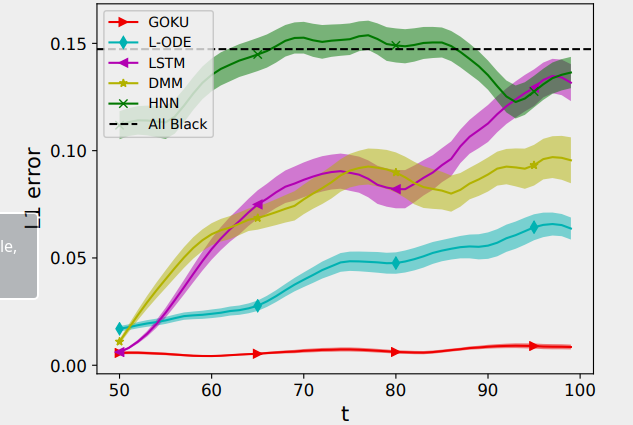
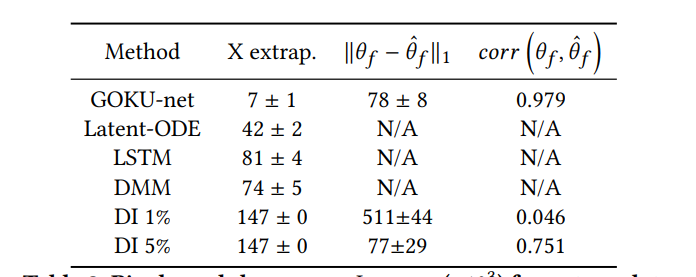
Similarly outperformed baselines significantly for double pendulum a CVS model
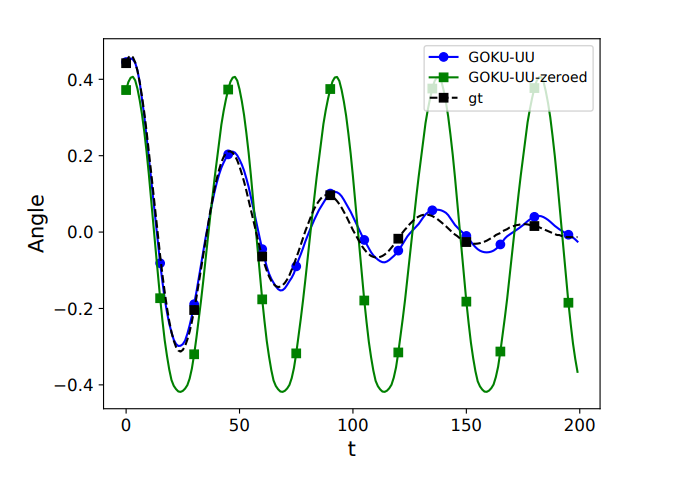
What if part of functional is unknown?
\dot{\omega}(t) = -\frac{g}{l}sin(\theta) - \frac{b}{m}\omega(t)
Unknown
Then add NN to learn the unknown:
\frac{dz_t}{dt} = f_{\theta}(z_t) + f_{abs}(z_t, \theta)
What if part of functional is unknown?
Physics-Integrated Variational Autoencoders for Robust and Interpretable Generative Modeling
- Functional is partially known
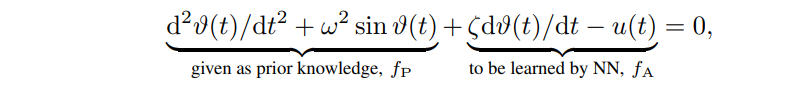
- known part of functional
- Model and extrapolate
f_P(v, \omega) = \ddot{v} + \omega^2 \sin (v)
\{v(0), v(\Delta t), \dots, v(\tau \Delta t)\}
Takeishi et al '21
Encoder
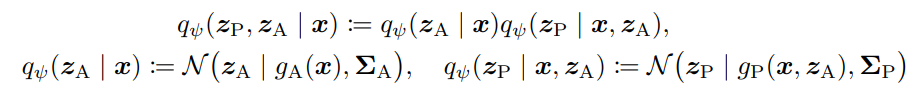
- are neural networks, are also trainable parameters
g_A, g_P
\Sigma_A, \Sigma_P
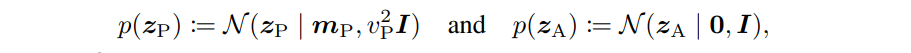
- are defined using domain information
\mathbf{m}_P, v_P^2
Divide latent encoding into known and unknown parts
Decoder
p_{\theta}(x|z_P, z_A) = \mathcal{N}(f_A(f_P(z_P), z_A), \Sigma_X)
- is neural network
- is from solution of ODE on
f_A
f_P
z_P
Focusing on Physics-based component
- can dominate training ignoring
- Define a Physics-only reduced model
- Where , the baseline function is another NN with trainable parameter
- Then add regularizer
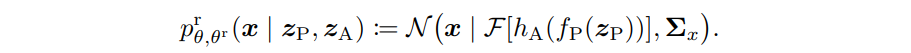
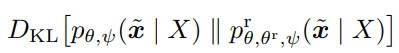
f_A
f_P
h_A
Physics-based data augmetation
- Goal: ground outputs of which are parameters of
- Idea: Use physics model as data augmentation to train
- Sample from
- Generate
- Train to estimate from
g_P
f_P
f_P
g_P
z_P
p(z_P)
x_P = h_A(f_P(z_P))
g_P
x_P
z_P
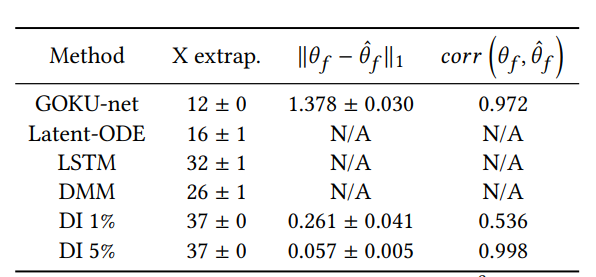
Results
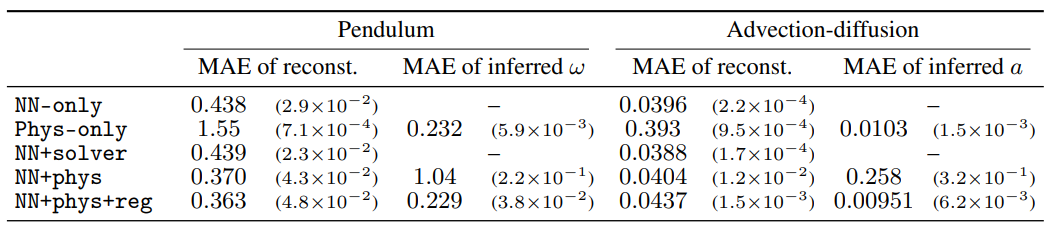

Physice ODE
By Harshavardhan Kamarthi




