Huawei Research Talk
Henry Charlesworth, 31/08/23
Overview of this talk
Part I: "PlanGAN" - A model-based approach for multi-goal, sparse reward problems
Part II: Solving Complex Dexterous Manipulation Tasks With Trajectory Optimisation and Deep RL
Work carried out June 2019 - September 2020 as a Postdoc at the University of Warwick, working with Professor Giovanni Montana.
Part I: PlanGAN

"PlanGAN: Model-based Planning With Sparse Rewards and Multiple Goals", Charlesworth & Montana, NeurIPS (2020)
Project website: https://sites.google.com/view/plangan
General Motivation
- We want to train agents that can perform multiple tasks - goal-conditioned RL was/is quite popular.
Model can be used for planning, counterfactual reasoning, re-used for other tasks etc.
More sample efficient - not just learning from scalar reward signal.
- Various difficulties in designing well-shaped reward signals - sparse rewards are often much easier to specify.
- At the time, best RL methods for multi-goal, sparse reward environments were model-free (Hindsight Experience Replay).
- But various potential advantages of model-based approaches:
Basic Idea
- Same principle that underlies HER can be used more efficiently to train a goal-conditioned generative model.
- Underlying principle behind HER: trajectories that don't achieve the specified goal still contain useful information about how to achieve the goal(s) that were actually achieved during that trajectory.
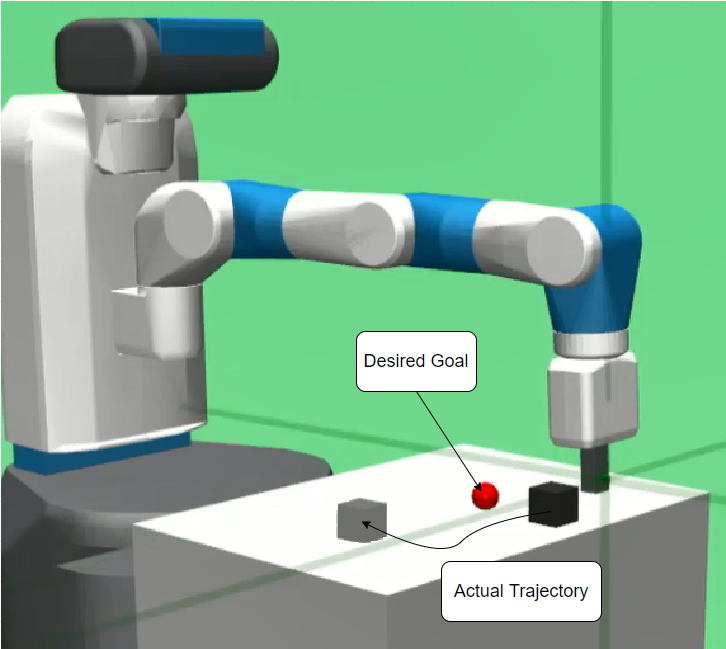
- Just need to re-label the desired goals in those trajectories.
Part II: Solving Complex Dexterous Manipulation Tasks With
"Solving Complex Dexterous Manipulation Tasks With Trajectory Optimisation and Deep Reinforcement Learning", Charlesworth & Montana, ICML (2021)
Trajectory Optimisation and Deep RL
Project website: https://dexterous-manipulation.github.io
General Motivation
- Develop more autonomous robots that can operate in unstructured and uncertain environments
Requires considerably more sophisticated manipulators than the typical "parallel jaw grippers" most robots in industry use today.
- Human hand is the most versatile and sophisticated manipulator we know of!
Natural to build robotic hands that try and mimic the human hand and train them to perform complex manipulation tasks.
Why Dexterous Manipulation is Hard
- Difficult to accurately model/optimise over Physics of complex, discontinuous contact patterns that occur between the hand and object(s).
Traditional robotics methods struggle. Motivates RL/ gradient-free trajectory optimisation.
- High-dimensional state/action spaces. Tasks often require precise coordination of large number of joints in order to perform well.
Despite some successes, dexterous manipulation remains a significant challenge for RL (and other methods).
Background - Previous Work
- Open AI Gym Environments (2018) - achieved partial success with "Hindsight Experience Replay".


- Goal-conditioned RL - match orientation and/or position of target.

Background - Previous Work
- "Learning Complex Dexterous Manipulation with Deep RL and Demonstrations" - 2018
Background - Previous Work
- Open AI - Dactyl. Very large scale RL experiments trained purely in simulation. Transfer to real hardware with automatic domain randomisation.
- Very impressive but required enormous amounts of compute (training Rubik's cube policy involved 64 V100 GPUs and ~30,000 CPU cores for several months).
Our Contributions
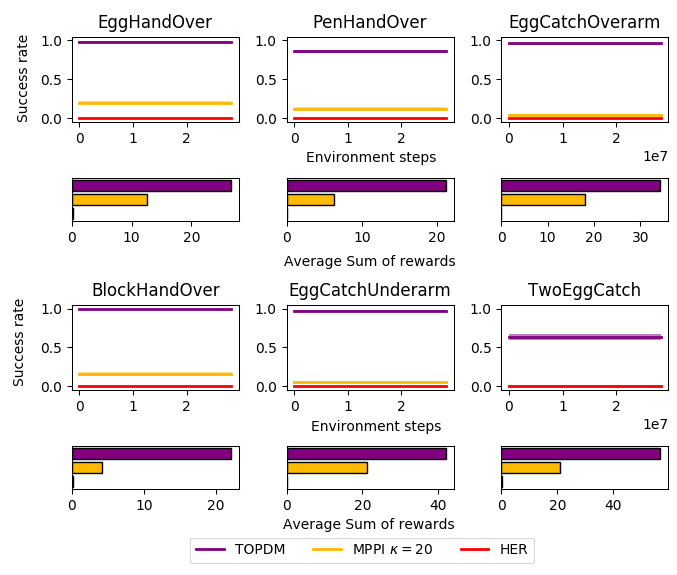
1. Introduced "Dexterous Gym" - a suite of challenging extensions to the Gym manipulation environments.
2. Develop a gradient-free trajectory optimisation algorithm that can solve many of these tasks significantly more reliably than existing methods.
3. Demonstrated that the most challenging task, "Pen Spin", could be "solved" by combining examples generated with the trajectory optimisation method with off-policy deep RL.
Dexterous Gym
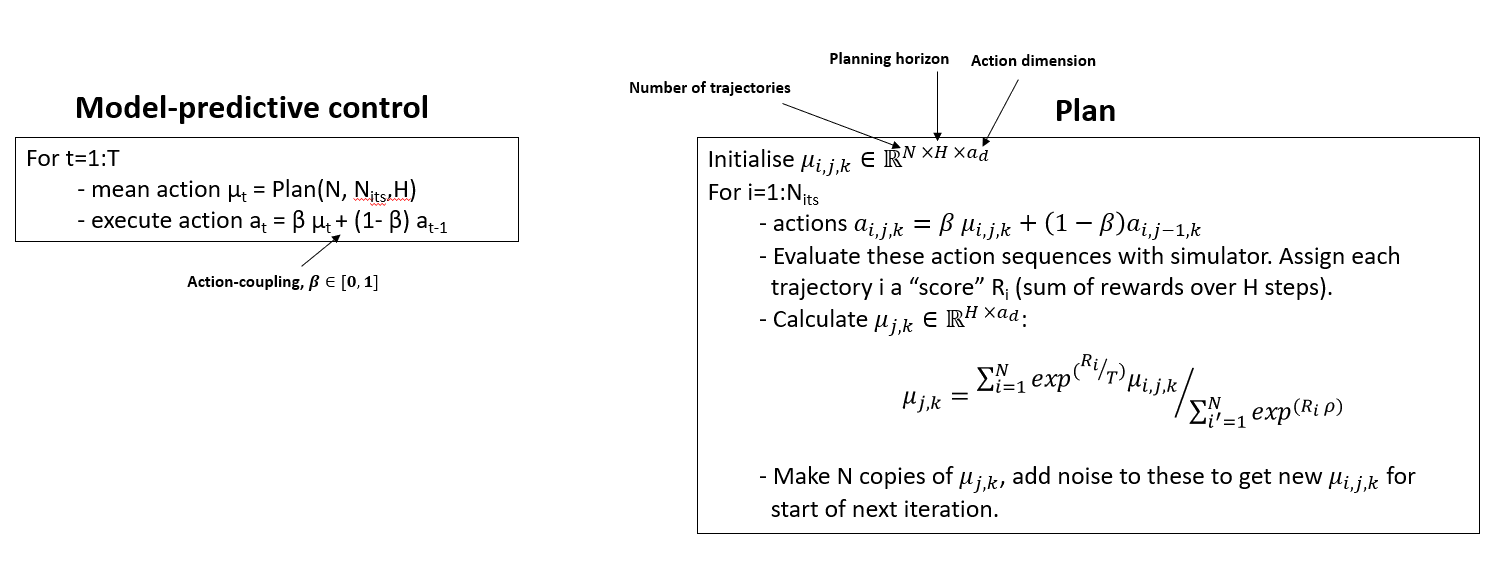
Trajectory Optimisation - MPPI (Model-Predictive Path Integral Control)
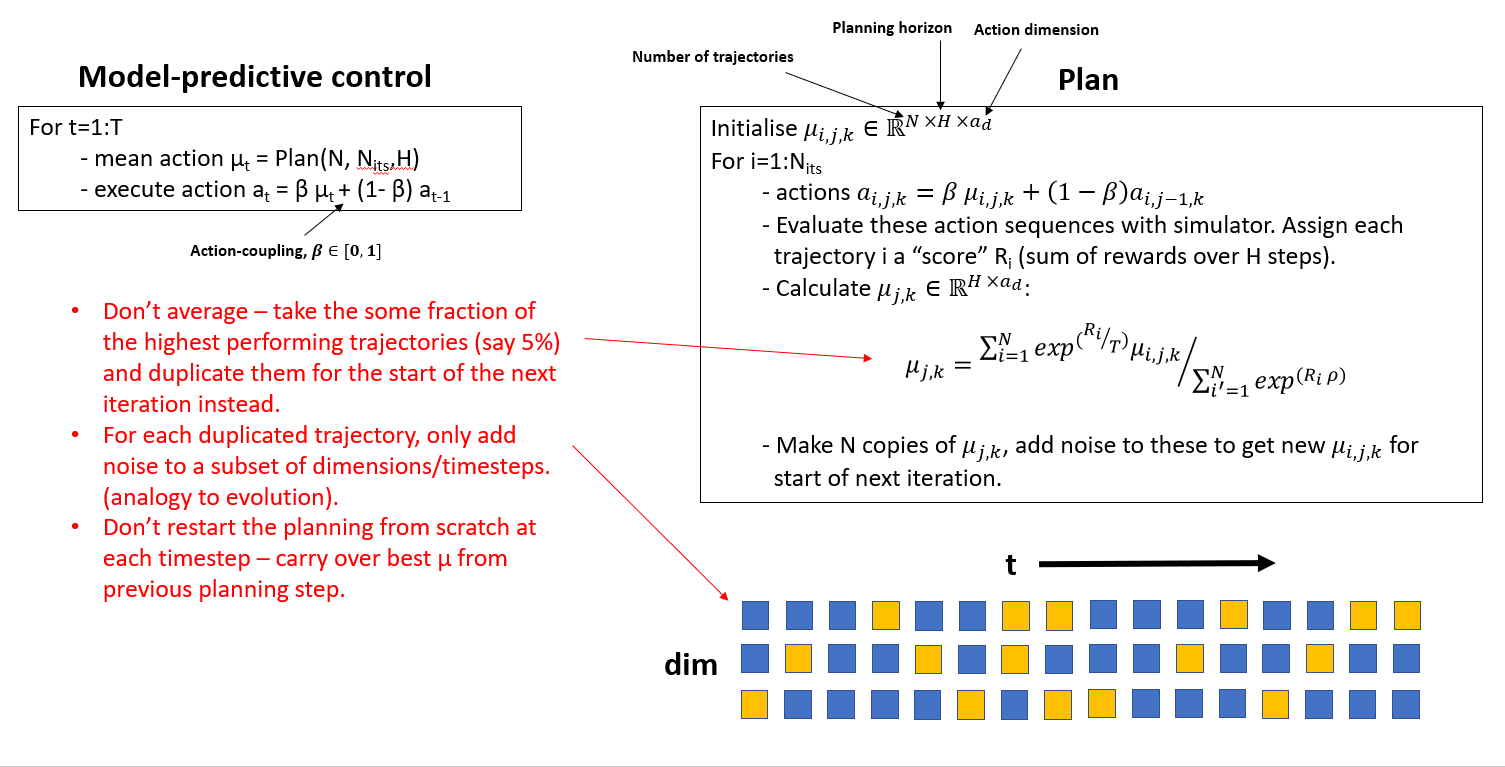
Trajectory Optimisation - Our Modifications (TOPDM)
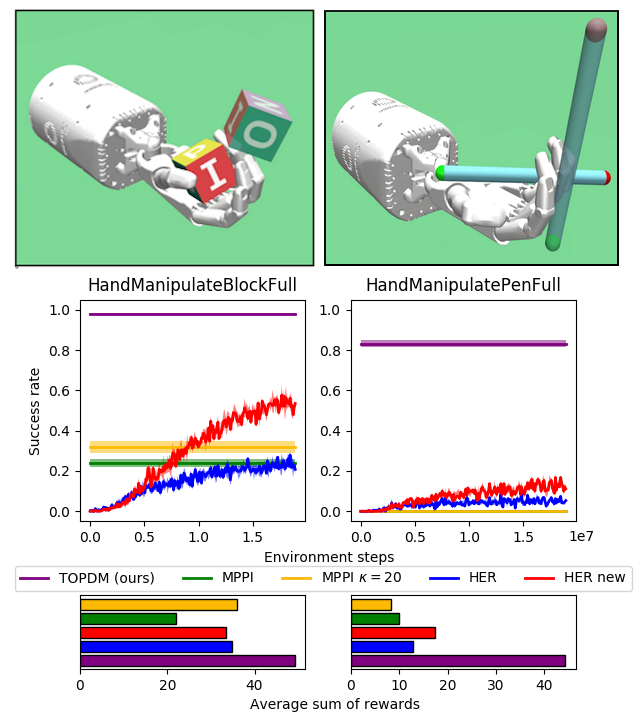
Results on Most Difficult OpenAI Gym Envs
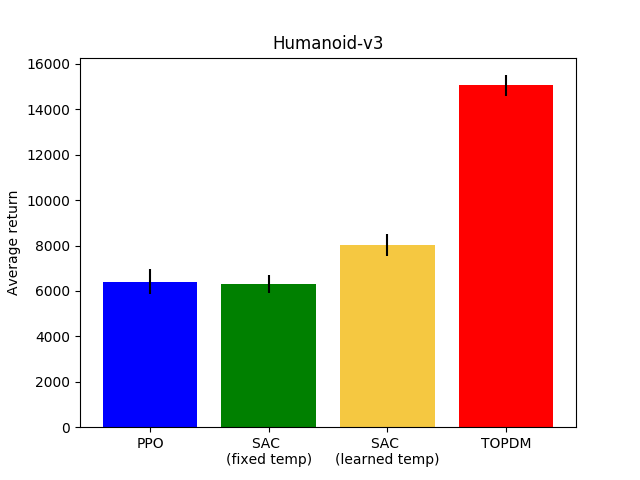
Results on Custom Environments (and Humanoid)
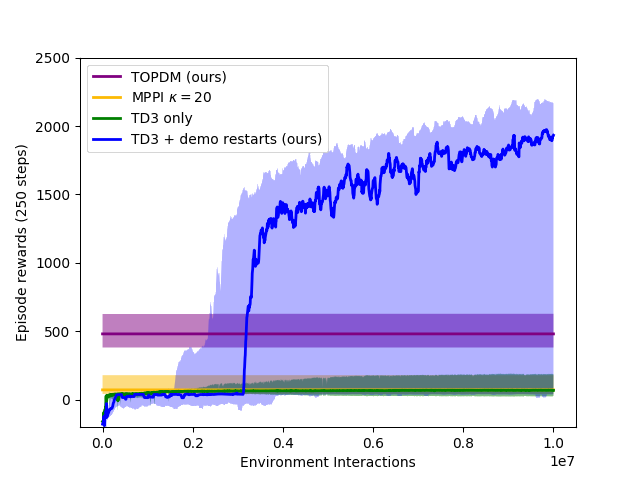
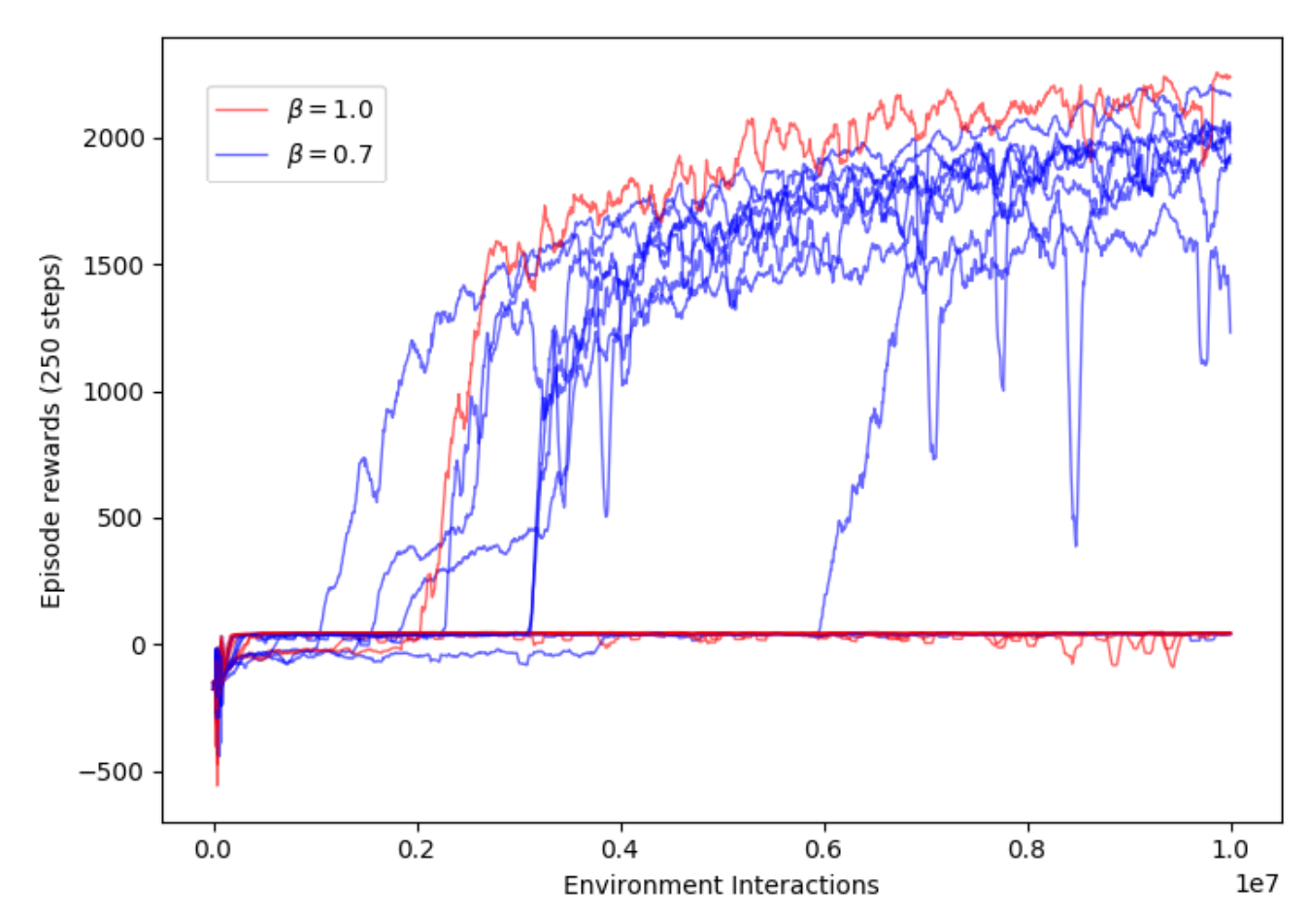
Combining TOPDM with Deep RL
- Use example trajectories generated by TOPDM to "guide" the deep RL
- Regularly re-load the simulator to states seen on the example trajectories. Gather short rollouts from there, train an off-policy RL algorithm (TD3) on these (and normal) trajectories.
- Still fully autonomous - no expert/VR demonstrations required.
- This approach works really well on the very challenging Pen Spin environment.
- Build in the same action-smoothing "trick" used in MPPI into TD3 - makes a surprisingly big difference!
Combining TOPDM with Deep RL
TOPDM only
TD3 + TOPDM demos
Conclusions
- Relatively simple modifications to existing trajectory optimisation method leads to substantial improvement in performance on variety of dexterous manipulation tasks.
- Can get best of both worlds (precise manipulation optimised over large time horizon) by combining examples generated with trajOpt into training an off-policy deep RL algorithm.
- Nothing hugely novel in any of the methodology - but good demonstration that focusing on getting the details right can lead to substantial performance improvement.
Extra Material (for questions, if relevant)
Continuous version of the model
- Would be nice to not have to break the agents' visual fields into an arbitary number of sensors.
- Calculating the mutual information (and hence empowerment) for continuous random variables is difficult - need to take a different approach.

Continuous version of the model
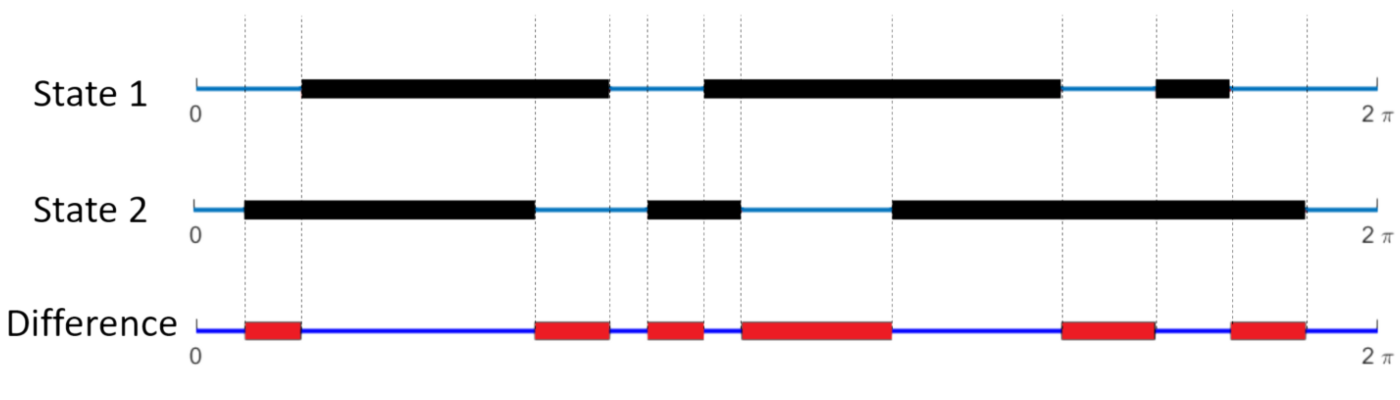
- Let \(f(\theta)\) to be 1 if angle \(\theta\) is occupied by the projection of another agent, or 0 otherwise
- Define the "difference" between two visual states i and j to be:
d_{ij} = \frac{1}{2\pi} \int_0^{2\pi} [f_i(\theta)(1-f_j(\theta)) + f_j(\theta)(1-f_i(\theta))]d\theta
- This is simply the fraction of the angular interval \([0, 2\pi)\) where they are different.
Continuous version of the model
W_{\alpha} = \frac{1}{n_{\alpha}} \sum_{i=1}^{n_{\alpha}} \sum_{j=1}^{n_{\alpha}} d_{ij}
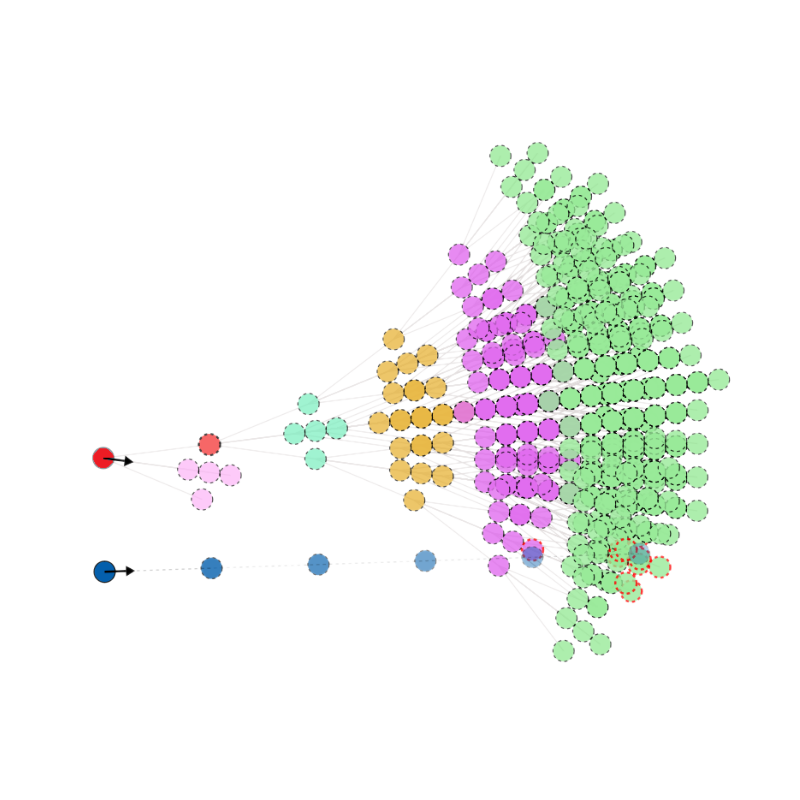
branch \(\alpha\)
For each initial move, \( \alpha \), define a weight as follows:
- Rather than counting the number of distinct visual states on each branch, this weights every possible future state by its average difference between all other states on the same branch.
- Underlying philosophy of FSM remains the same.
Can we do this without a full search of future
- This algorithm is very computationally expensive. Can we generate a heuristic that acts to mimic this behaviour?
- Train a neural network on trajectories generated by the FSM algorithm to learn which actions it takes, given only the currently available visual information (i.e. no modelling of future trajectories).
states?
Visualisation of the neural network
previous visual sensor input
current visual sensor input
hidden layers of neurons
output: predicted probability of action
non-linear activation function: f(Aw+b)
How does it do?
Some other things you can do
Making the swarm turn
Guiding the swarm to
follow a trajectory
A bit of fun: FSM at different scales:
Copy of Research Talk
By Henry Charlesworth




