Agent memory
&
Web Scraping
Acme Design is a full service design agency.
- Agent memory & demo
- Web scraping & demo
Outline




Agent memory
The ability to store and retrieve information overtime
Maintain context across multiple tasks, remember past interactions
Stateless:
LLMs are designed to treat each input as a new, independent request, without retaining any memory of past interactions.
LLM memory
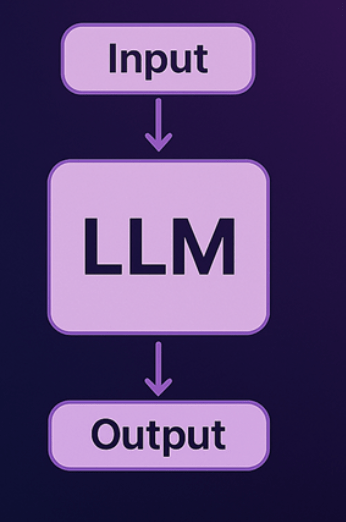
Stateful:
Agent memory allows AI systems to maintain context and learn from past interactions, becoming more effective over time
Agent memory
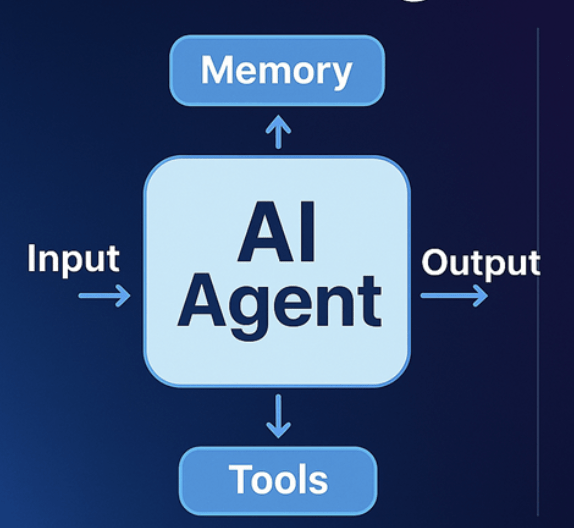
STM allows the agent to maintain context and recall recent interactions within a single conversation or session
Short-term memory (STM)
- Model’s context window
--> Time passes and information begins to accumulate, it becomes increasingly difficult for the model to handle all the information effectively
STM cons
- Does not persist once the current task ends
Ex: solve a complex problem today, but if it isn’t specifically trained to remember this solution, it will have to start from scratch the next time
STM cons

- In-memory (Ex: LangGraph uses a checkpointer)
- In a temporary storage (Ex: Redis cache)
STM storage
LTM enables the agent to store and recall information across multiple sessions, allowing for personalization and learning over time
Long-term memory (LTM)
- In persistent storage
- Databases
- Knowledge graphs
- Vector databases
LTM storage
RAG is a common technique used to integrate LTM with the agent's knowledge base
Real world example
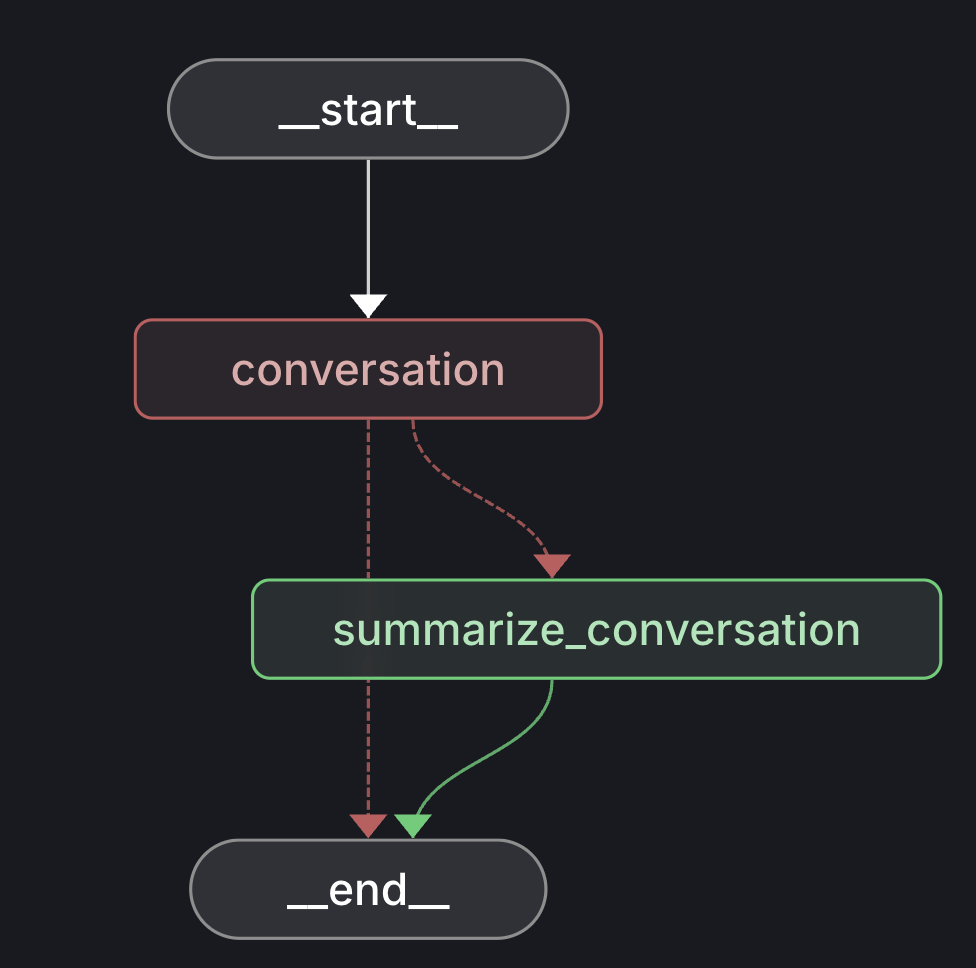
Mermaid chard
flowchart TD
A[User sends new message] --> B[Append message to short-term buffer]
B --> C{Buffer size > k?}
C -- No --> D[Send short-term buffer + long-term summary to LLM]
C -- Yes --> E[Extract oldest messages beyond k]
E --> F[Summarize extracted messages with previous long-term summary]
F --> G[Update long-term summary]
G --> H[Remove extracted messages from short-term buffer]
H --> D[Send short-term buffer + updated long-term summary to LLM]
D --> I[LLM generates response]
I --> J[Append response to short-term buffer]
Discussion?

Web scraping
A technique where bots, also known as crawlers or spiders, automatically browse the web to collect data
LLM needs:
- Data (Knowledge)
- Dynamic sources (Pricing data, news, job postings...)
- Specialized content
Relationship
LLM benefits Web Scraping:
- Automatically define and parse elements, saving time and effort
- Define the extraction strategy and convert the extracted data into a structured format
Relationship
Demo
Discussion?
Thank You!
Questions?
AI study group - section 9
By Hiếu Lê Minh


