The CAP Theorem: Balancing Distributed Systems
A Guide to Architecture Trade-offs
🏛️ The History
The Origin: Brewer's Conjecture
- 2000: Eric Brewer (UC Berkeley) presents the CAP principle as a "conjecture".
- The Insight: Based on building high-scale web services at Inktomi, he realized we cannot have it all in a distributed world.
The Proof: Gilbert & Lynch
- 2002: Seth Gilbert and Nancy Lynch (MIT) provide the formal mathematical proof.
- The Shift: What was once a rule of thumb became a fundamental Theorem of Computer Science.
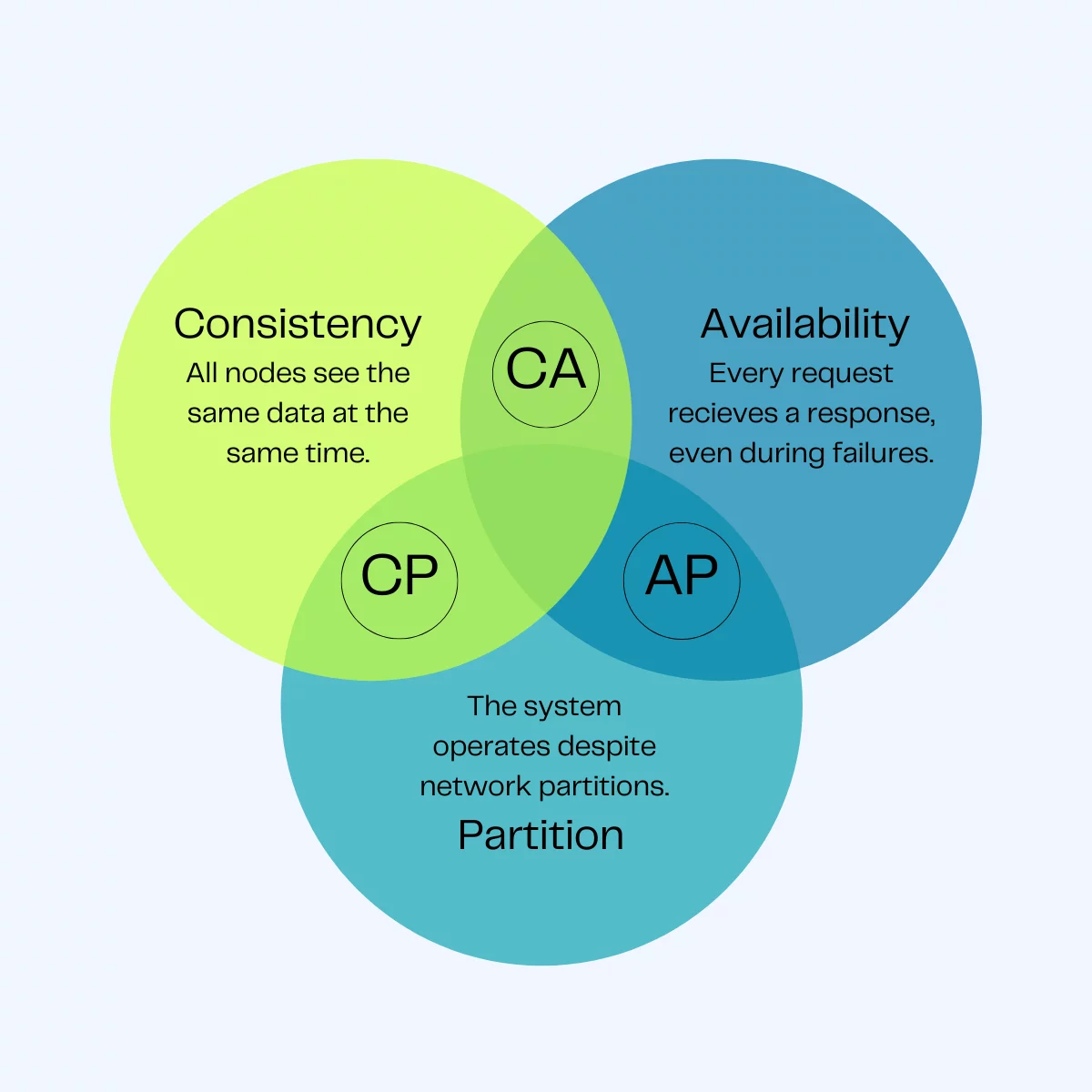
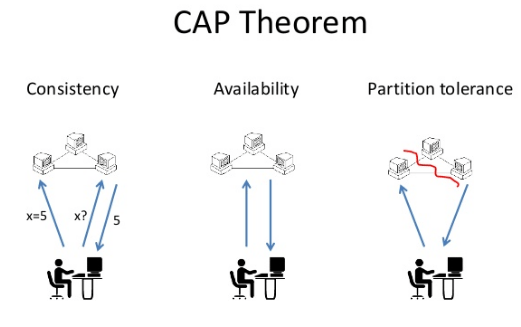
CAP Theorem
A distributed system can only guarantee two out of three key properties: Consistency (all nodes see the same data), Availability (every request gets a response), and Partition Tolerance (the system works despite network failures)
🧩 What is a Distributed System?
In the context of CAP, a system is distributed if:
- Multiple Nodes: Data is spread across independent machines.
- Network Links: Nodes communicate solely via message passing.
- Partition Risk: The network connecting these nodes will eventually fail.
📐 The Three Pillars
Consistency
- Every read receives the most recent write or an error.
- All nodes see the same data at the same time.
Availability
- Every request receives a non-error response, without the guarantee that it contains the most recent write.
- The system must stay "up" for every client.
Partition Tolerance
- The system continues to operate despite an arbitrary number of messages being dropped or delayed by the network between nodes.
⚡ The Hard Truth
In a distributed system, you can only pick TWO.
But wait... P is Mandatory!
- In real-world networks, partitions cannot be avoided.
- If you want a system that works on more than one machine, you must have P.
- The Real Choice: When a partition happens, do you choose Consistency or Availability?
🛡️ CP Systems: Consistency + Partition Tolerance
If the network breaks, we stop talking to prevent "wrong" data.
- Behavior: If a node can't talk to its peers, it shuts down or returns an error.
- Motto: "Better to be offline than to be wrong."
-
Examples:
- ZooKeeper / etcd (Coordination)
- MongoDB (Strongly consistent reads by default, but configurable)
🚀 AP Systems: Availability + Partition Tolerance
If the network breaks, keep serving the user.
- Behavior: Every node stays online and accepts writes/reads, even if it can't sync with others.
- Result: Data becomes Eventually Consistent.
- Motto: "Better to show old data than an error page."
-
Examples:
- Cassandra
- DynamoDB
🔍 Use Case Comparison
| CP (Consistency) | AP (Availability) |
|---|---|
| Banking: Prevent double-spending. | Social Media: Feeds can be slightly stale. |
| Distributed Locks: Only one master. | Shopping Carts: Never block "Add to Item". |
| K8s Scheduling: One source of truth. | Metrics/Logs: High-speed ingestion. |
🏁 Summary
- P is not a choice: You must design for network failure.
- CP is for data integrity (Transactions).
- AP is for user experience (High Scale/Uptime).
💡 Beyond the Theorem: A Starting Point
CAP is a mental model for learning, not the final destination.
- Theory vs. Practice: In reality, designing distributed systems is significantly more complex than a three-letter acronym.
- It's a Spectrum: Most modern systems (Aurora, MongoDB) offer "Tunable Consistency," allowing you to move the slider between C and A based on the specific needs.
🙋 Questions?
Based on our current stack, how do we think of CAP?
CAP Theorem
By Minh Hoàng Nguyễn

