A Framework for Email Clustering and Automatic Answering Method
S0354034 廖元豪
S0354021林昱安
Abstract
- 現今生活中,email交流數量遽增,無法快速在時間內找到重要的email
- 論文以email的主旨、寄件者、內容、時間和大小為基礎來做叢集法,將email進行分類,並且加上自動回覆的功能。
INTRODUCTION
Email as a Database
- 將email的資訊做前處理存進資料庫
- email的寄件者、收件者、時間等等資訊都是資料庫中一筆資料的其中一個屬性
Email Mining
- 從email中找出有用資訊的過程
- 應用到以下的技術:
- Data mining
- Machine learning
- Text mining
Clustering Email
- 以叢集法將email分類,並應用到Email Mining中
- 根據被分在同一群的email的共通點來為該群組命名
Algorithm
- 將資料進行前處理:
- 將HTML標籤和標點符號去除
- 將Stop words(I、am、and...)去除
- 找出相似的email
- 主要使用以下的演算法:
-
Brute-Force Algorithm
-
Cosine Similarity Matching Algorithm
-
K-means Algorithm for Clustering
-
Brute-Force Algorithm
- 用來去除stop words
- lookup table:存取單字原本的形式還有它的變化形式(Ex:過去式、完成式)
- 不可能存取所有的單字和其變化 -> Suffix-striping(詞綴提取),用來去除單字的前後綴
- 變化較不規則的單字 -> 直接存入table
Cosine Similaryity Matching Algorithm
- 用來比對兩筆資料的相似度
- 算出的值介在1到-1之間,1為相似度最高 -1最低


K-means Algorithm Clustering
- 用來分割出群集
- formula(WCSS):
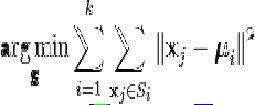
K-means Algorithm Clustering
Text
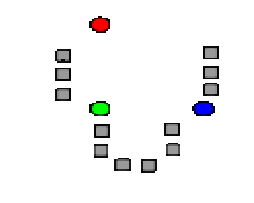
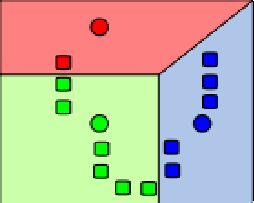

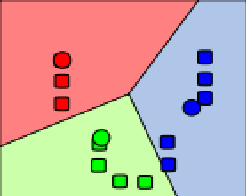
EXISTING OR RELATED WORK
Application
- 舉出一些現有實例,如辨識垃圾郵件,郵件分類等其他人的研究或實作成果
- message type:
- unstructured
- categorical
- numeric data
PROPOSED WORK
Approach
-
可分開為4個步驟
- pre-processing
- Key-word matching
- clustering determination
- automatic answering
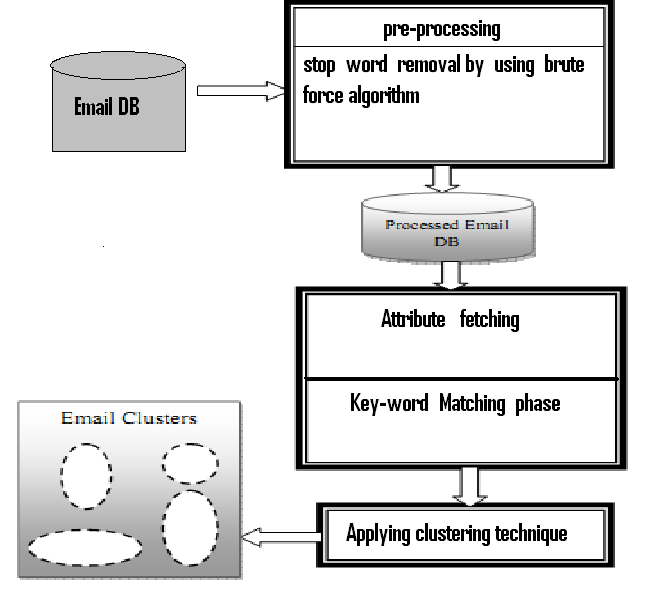
Pre-Processing
- 用Brute-force algorithm 去除stop word
- 利用HTML parser去除HTML tag
- 分析過的資料可用來定義email的屬性
Keyword Matching
- 利用Cosine similarity matching algorithm 來作關鍵字的相似度比對,如比對成功則進行下一步clustering
Clustering determination
- 用 K-means algorithm 將相似的email分在同一個folder
- 用啟發式搜尋法(heuristic rule searching)將郵件分類
- 依照使用者自己的法則來命名folder
- 範例:
- if(sender=”John Smith” OR sender=”Mary Smith”) then (moveInto FAMILY)
- if(body contains “call for papers”) then{(moveInto CFP) (forwardTo “COLLEAGUES”)}
Automatic Answering
- 利用分類後的結果進行適當的回覆
IMPLEMENTATION
- 程式語言:java
- IDE:My Eclipse
- library:JFreeChart
EXPERMENTAL ANALYSIS
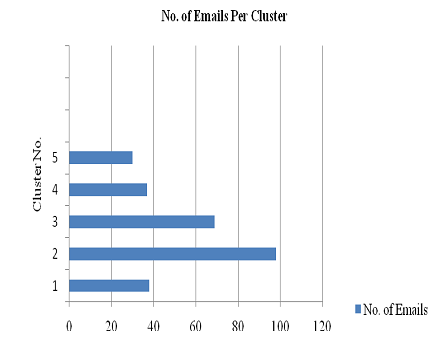
資料來源:Enron Email dataset
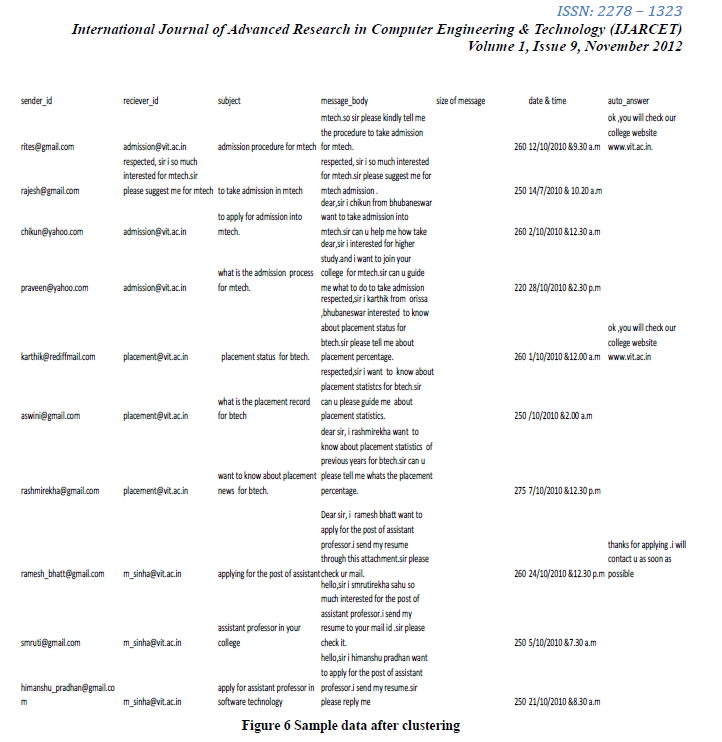
分類結果:

表格
圖表
CONCLUSION AND FUTURE SCOPE
- 以上Email-Miniing 都基於文字分析
- 未來期望能加入其他方法來對郵件附件或圖片進行分析
Data mining報告
By IAN LINS

