On Information Seeking "Agents"
Aadharsh Aadhithya A
On Information Seeking "Agents"
TL DR:
- Human-Computer Mixed Interaction Modality is Important. Agents should be able to ask when it is not clear.
- Current LLM-based Agents are Poor. There is still room for Improvement
- LLMs struggle to identify ambiguity and ask clarifying questions
- Performing well on Reasoning tasks might not necessarily mean it translates to good Information-seeking Abilities
- More so in Complex, Long Horizon Reasoning domains
- Lots of room for improvement
Principles of Mixed User Interfaces
Eric Horvitz
Principles of Mixed User Interfaces
intelligent services and users may often
collaborate efficiently to achieve the user’s goals.
The paper lists 12 factors for effective integration of this "Collaboration"
Principles of Mixed User Interfaces
"Look Out Service"
When invoked, Lookout parses the text in the body and
subject of an email message in focus and attempts to
identify a date and time associated with an event implied by the sender. The system then invokes Outlook’s calendaring subsystem, brings up the user’s online appointment book, and attempts to fill in relevant fields of an appointment record. The system displays its guesses to the user and allows the user to edit its guesses and to save the final result.
Principles of Mixed User Interfaces
"Look Out Service"
Parses a message, date, etc
If Lookout cannot identify an implied date and time, the
system degrades its goal to identifying a span of time that is most relevant given the text of the message and then displays a scoped view of
the calendar to the user. The user can directly manipulate the proposed view and, if appropriate, go on to scheduleappointments manually.
Tries to reduce the number of interactions and complexity of navigation for the user
Principles of Mixed User Interfaces
"Look Out Service"
Lookout processes the
header, subject, and body of the message and, based on this information, assigns a probability that a user would like to view the calendar or schedule an appointment, by
employing a probabilistic classification system that is
trained by watching the user working with email
Depending on the inferred probability-and on an
assessment of the expected costs and benefits of actionthe system decides to either
(1) do nothing but simply wait
for continued direct manipulation of Outlook or manual
invocation of Lookout
(2) to engage the user in a dialog
about his or her intentions with regards to providing a
service
(3) to go ahead and attempts to provide its
service by invoking its second phase of analysis.
Principles of Mixed User Interfaces
"Look Out Service"
Multiple Interaction Modalities
1) Mannual Mode
2) Basic Automaed Assistance Mode
3) Social-Agent Modality
Also Handles Invocation Failures Gracefully...
Principles of Mixed User Interfaces
"Look Out Service"
Inferring Beleifs about User's goals
Uses SVM for text classification / Intent Classification
training the system
on a set of messages that are calendar relevant and calendar
irrelevant. At runtime, for each email message being
reviewed, the linear SVM approximation procedure outputs
the likelihood that the user will wish to bring up a calendar
or schedule an appointment. The current version of
Lookout was trained initially on approximately 1000
messages, divided into 500 messages in the relevant and
500 irrelevant messages.
Principles of Mixed User Interfaces
"Look Out Service"
Taking Actions based on beliefs
Autonomous actions
should be taken only when an agent believes that they will
have greater expected value than inaction for the user

P(G \mid E)
Principles of Mixed User Interfaces
"Look Out Service"
Taking Actions based on beliefs
Autonomous actions
should be taken only when an agent believes that they will
have greater expected value than inaction for the user
P(G \mid E)
Prob. of goal given evidence
Principles of Mixed User Interfaces
"Look Out Service"
Taking Actions based on beliefs
Autonomous actions
should be taken only when an agent believes that they will
have greater expected value than inaction for the user
P(G \mid E)
Prob. of goal given evidence
E [ u(A \mid E)] = P(G \mid E)u(A,G) + P(\neg G \mid E ) u(A, \neg G)
= P(G \mid E)u(A,G) + (1-P(G \mid E)) u(A, \neg G)
Principles of Mixed User Interfaces
"Look Out Service"
P(G \mid E)
Prob. of goal given evidence
E [ u(A \mid E)] = P(G \mid E)u(A,G) + P(\neg G \mid E ) u(A, \neg G)
= P(G \mid E)u(A,G) + (1-P(G \mid E)) u(A, \neg G)
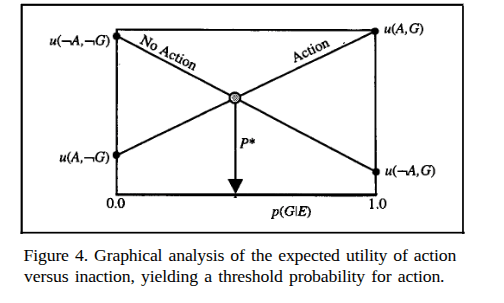
The best decision to make
at any value of p(GIE) is the action associated with the
greatest expected utility at that likelihood of the user having
the goal.
Principles of Mixed User Interfaces
E [ u(A \mid E)] = P(G \mid E)u(A,G) + P(\neg G \mid E ) u(A, \neg G)
= P(G \mid E)u(A,G) + (1-P(G \mid E)) u(A, \neg G)
The best decision to make at any value of p(GIE) is the action associated with the greatest expected utility at that likelihood of the user having
the goal.
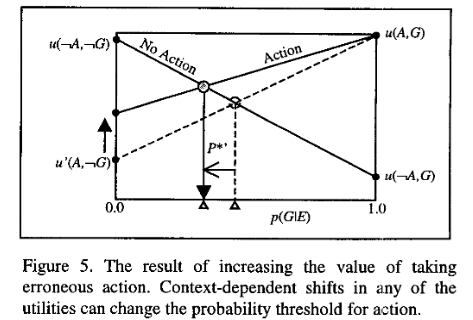
Principles of Mixed User Interfaces
Dialogue as an Option
u(D, \neg G)
u(D, G)
E [ u(D \mid E)] = P(G \mid E)u(D,G) + P(\neg G \mid E ) u(D, \neg G)
= P(G \mid E)u(D,G) + (1-P(G \mid E)) u(D, \neg G)
Principles of Mixed User Interfaces
Timing of Service
They found the relationship between message size and the preferred time for deferring offers of service can be approximated by a sigmoid function
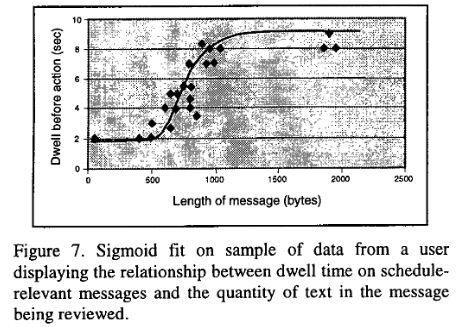
In the general case, we can construct a model of attention
from such timing studies and make the utility of outcomes
time-dependent functions of message length. Alternatively,
we can use timing information separately to defer service
until a user is likely ready to receive it.
Principles of Mixed User Interfaces
Life Long Learning
Stores user emails and actions to retrain model periodically.
Questions?
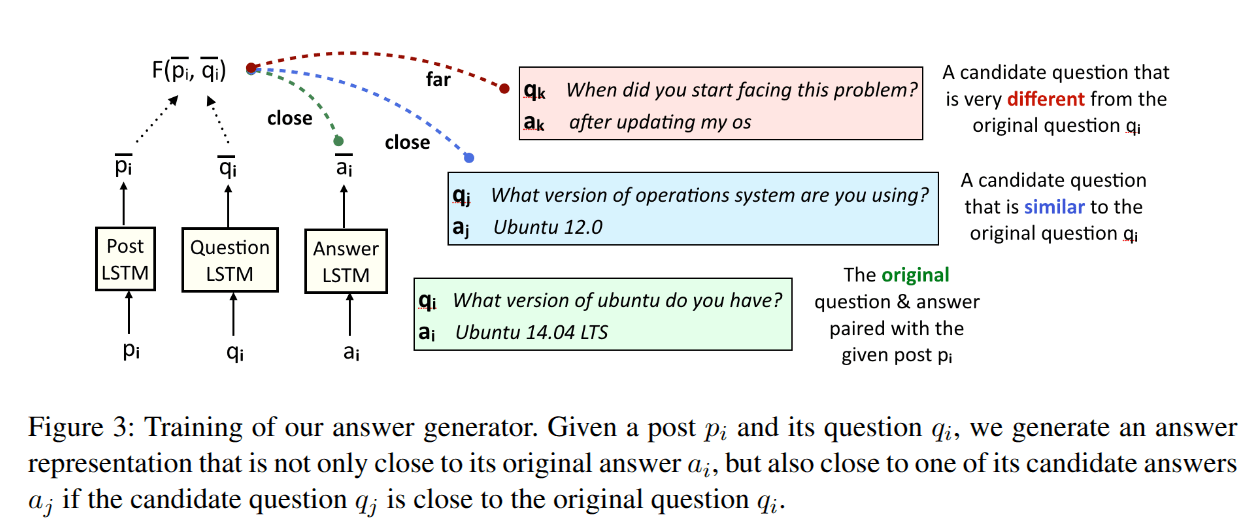
Learning to Ask Good Questions: Ranking Clarification Questions using Neural Expected Value of Perfect Information
Sudha Rao, Hal Daume III
Consider This Situation....
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....

Consider This Situation....
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....
To answer questions related to error, you might need some extra information so that you can answer faithfully.
Consider This Situation....
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....
To answer questions related to error, you might need some extra information so that you can answer faithfully.
You can ask....
a) What version of ubuntu you have?
b) What is the make of your wifi card?
c) Are you running ubuntu 14.10 kernel 4.4.0-59.....?
Consider This Situation....
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....
To answer questions related to error, you might need some extra information so that you can answer faithfully.
You can ask....
a) What version of ubuntu you have?
b) What is the make of your wifi card?
c) Are you running ubuntu 14.10 kernel 4.4.0-59.....?
Different Questions Elicit Different Information
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....
Different Questions Elicit Different Information
p
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....
Different Questions Elicit Different Information
p

q_i
a_1
a_j
a_N
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....
Different Questions Elicit Different Information
p
q_i
a_1
a_j
a_N
p
a_j
+
Suppose there is some "Utility Gain", U(.) because of adding the elicited answer to the problem
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....
Different Questions Elicit Different Information
p
q_i
a_1
a_j
a_N
p
a_j
+
U(p+a_j)
P(a_j \mid p,q_i)
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....
Different Questions Elicit Different Information
p
q_i
a_1
a_j
a_N
p
a_j
+
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....
Different Questions Elicit Different Information
p
q_i
a_1
a_j
a_N
p
a_j
+
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
I am aiming to Install ape, A simple code for Pseudopotential generation, I am having this error message....
Different Questions Elicit Different Information
p
q_i
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
Expected Value of Perfect Information
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
1. Generate set of candidate Q and A
2. Given post p and Question q_i, how likely is this question to be answered using one of our answer candidates
3. Given Post P and answer candidate a_j, calculate U(p+a_j)
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
1. Generate set of candidate Q and A
2. Given post p and Question q_i, how likely is this question to be answered using one of our answer candidates
3. Given Post P and answer candidate a_j, calculate U(p+a_j)
U(p+a_j)
P(a_j \mid p,q_i)
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
1. Generate set of candidate Q and A
q_i
VDB
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
1. Generate set of candidate Q and A
q_i
VDB
\begin{bmatrix}
q_{i} \\
q_{i2} \\
\vdots \\
q_{i10}
\end{bmatrix}
consider the questions
asked to these 10 posts as our set of question candidates Q
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
1. Generate set of candidate Q and A
q_i
VDB
\begin{bmatrix}
q_{i} \\
q_{i2} \\
\vdots \\
q_{i10}
\end{bmatrix}
consider the questions
asked to these 10 posts as our set of question candidates Q
edits made to the posts in response to the questions as our set of answer candidates A
consider the questions
asked to these 10 posts as our set of question candidates Q
(p,q,a)
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
1. Generate set of candidate Q and A
2. Given post p and Question q_i, how likely is this question to be answered using one of our answer candidates
3. Given Post P and answer candidate a_j, calculate U(p+a_j)
U(p+a_j)
P(a_j \mid p,q_i)
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
2. Given post p and Question q_i, how likely is this question to be answered using one of our answer candidates
p
q_i
a_j
p
q_i
F_\theta
\hat{\alpha_i}
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
2. Given post p and Question q_i, how likely is this question to be answered using one of our answer candidates
p
q_i
a_j
p
q_i
F_\theta
\hat{\alpha_i}
A
a_1
a_2
a_j
a_N
a_k
D(\cdot)
q_k
P(a_j \mid p , q_i)
e^{-D(\hat{\alpha_i}, a_j)}
sim(q_i,q_k)
\propto
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
2. Given post p and Question q_i, how likely is this question to be answered using one of our answer candidates
p
q_i
a_j
p
q_i
F_\theta
\hat{\alpha_i}
A
a_1
a_2
a_j
a_N
a_k
D(\cdot)
q_k
P(a_j \mid p , q_i)
e^{-D(\hat{\alpha_i}, a_j)}
sim(q_i,q_k)
\propto
High probability if, similar answer coming from similar question
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
2. Given post p and Question q_i, how likely is this question to be answered using one of our answer candidates
p
q_i
a_j
p
q_i
F_\theta
\hat{\alpha_i}
A
a_1
a_2
a_j
a_N
a_k
D(\cdot)
q_k
How is Theta obtained?
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
2. Given post p and Question q_i, how likely is this question to be answered using one of our answer candidates
p
q_i
a_j
p
q_i
F_\theta
\hat{\alpha_i}
A
a_1
a_2
a_j
a_N
a_k
D(\cdot)
q_k
How is Theta obtained?
\theta = \arg \min
(p_i,q_i,a_i)
(From Step 1)
D(F_{\theta}(p_i , q_i),a_i)
+ \sum_{j \in Q} D(F_{\theta}(p_i , q_i),a_j) \cdot sim(q_i,q_j)
Method
2. Given post p and Question q_i, how likely is this question to be answered using one of our answer candidates
\theta = \arg \min
D(F_{\theta}(p_i , q_i),a_i)
+ \sum_{j \in Q} D(F_{\theta}(p_i , q_i),a_j) \cdot sim(q_i,q_j)
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
1. Generate set of candidate Q and A
2. Given post p and Question q_i, how likely is this question to be answered using one of our answer candidates
3. Given Post P and answer candidate a_j, calculate U(p+a_j)
U(p+a_j)
P(a_j \mid p,q_i)
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
p
q_i
a_j
3. Given Post P and answer candidate a_j, calculate U(p+a_j)
(p_i,q_i,a_i)
(p_i,q_i,a_j)
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
3. Given Post P and answer candidate a_j, calculate U(p+a_j)
(p_i,q_i,a_i)
(p_i,q_i,a_j)
1
0
\}
U(p_i + a_k) = \sigma(F_{\phi}(p_i, q_k,a_k))
Method
U(p+a_j)
P(a_j \mid p,q_i)
\sum_j
3. Given Post P and answer candidate a_j, calculate U(p+a_j)
(p_i,q_i,a_i)
(p_i,q_j,a_j)
1
0
\}
U(p_i + a_k) = \sigma(F_{\phi}(p_i, q_k,a_k))
\phi = \arg \min \sum_i y_i log(\sigma(F_{\phi}(p_i, q_k,a_k)))
Method
- Word Embeddings Obtained using GloVe, sentence embeddings are obtained by averaging glove embeddings.
- All networks phi,theta,etc are paramtereized as LSTMs.
- Twoloss functions are jointly minimized
- Dataset created from stackexchange.
- Extracted total of 77,097 triplets (p,q,a)
Some Specifics...
Method
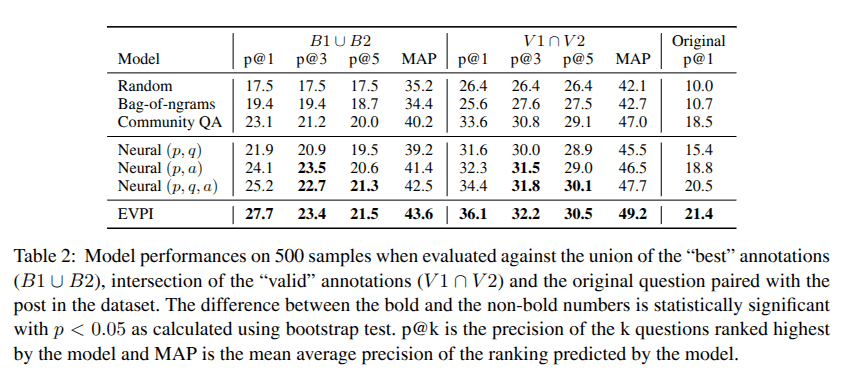
Evaluation
Questions?
CLAMBER: A Benchmark of Identifying and Clarifying Ambiguous Information Needs in Large Language Models
Tong Zhang, Peixin Qin, Yang Deng, Chen Huang, Wenqiang Lei, Junhong Liu, Dingnan Jin, Hongru Liang, Tat-Seng Chua
CLAMBER
Clarifying Ambiguous Query
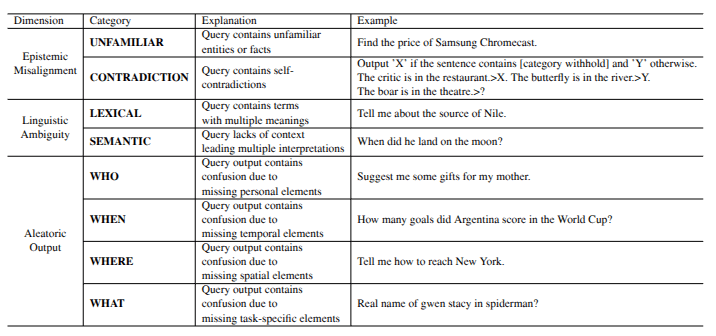
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
inherent knowledge stored within
LLMs have conflict understanding about the query
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
inherent knowledge stored within
LLMs have conflict understanding about the query
Unfamiliar
Contradiction
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
inherent knowledge stored within
LLMs have conflict understanding about the query
Unfamiliar
Contradiction
ALCUNA dataset, contain new entities fabricated by modifying
existing ones.
lassify the queries containing
new entities as ambiguous, while the rest are unambiguous. Subsequently, Also instruct GPT-4 to
generate a clarifying question for each ambiguousquery, focusing on the ambiguity of new entities
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
inherent knowledge stored within
LLMs have conflict understanding about the query
Unfamiliar
Contradiction
AmbiTask dataset to provide
ambiguous queries, which encodes contradiction
among queries and provided examples. Additionally, we create clarifying questions for ambiguous
queries by rule-based templates and manually transform ambiguous queries into unambiguous ones by
resolving contradictions
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
when a word, phrase, or statement can
be interpreted in multiple ways due to its imprecise
or unclear meaning
Lexical
Semantic
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
when a word, phrase, or statement can
be interpreted in multiple ways due to its imprecise
or unclear meaning
Lexical
Semantic
AmbER (Chen et al., 2021) and AmbiPun dataset (Mittal et al., 2022), which contain ambiguous entity names and ambiguous polysemy words
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
when a word, phrase, or statement can
be interpreted in multiple ways due to its imprecise
or unclear meaning
Lexical
Semantic
AmbiCoref dataset , which consists of minimal pairs featuring ambiguous and unambiguous referents
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
when the input is well-formed but the output contains potential confusion due to the lack of
essential elements

Who
Where
When
What
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
when the input is well-formed but the output contains potential confusion due to the lack of
essential elements

Who
Where
When
What
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
when the input is well-formed but the output contains potential confusion due to the lack of
essential elements
Who
Where
When

What
CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output
when the input is well-formed but the output contains potential confusion due to the lack of
essential elements
Who
Where
When
What

CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
1. Epistemic Misalignment
2. Linguistic Ambiguity
3. Aleatoric Output

CLAMBER
Clarifying Ambiguous Query
Introduces Taxonomy encompassing Three Dimensions
CLAMBER
Clarifying Ambiguous Query
Evaluation: Task 1 Identifying Ambiguity
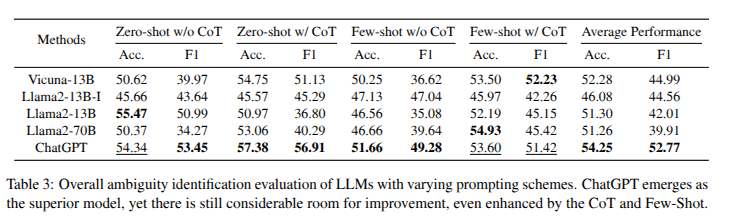
- Current LLMs struggle to identify Ambiguities.
- Small Scale LLMs show discrepancy between acc. and F1,Indicating perrformance variation when handling amb. vs unamb. qs.
CLAMBER
Clarifying Ambiguous Query
Evaluation: Task 1 Identifying Ambiguity
- these models
tend to classify most queries as ambiguous, even
those that are actually unambiguous.
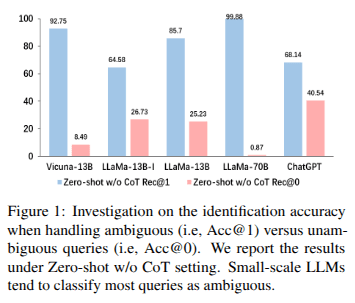
CLAMBER
Clarifying Ambiguous Query
Evaluation: Task 1 Identifying Ambiguity
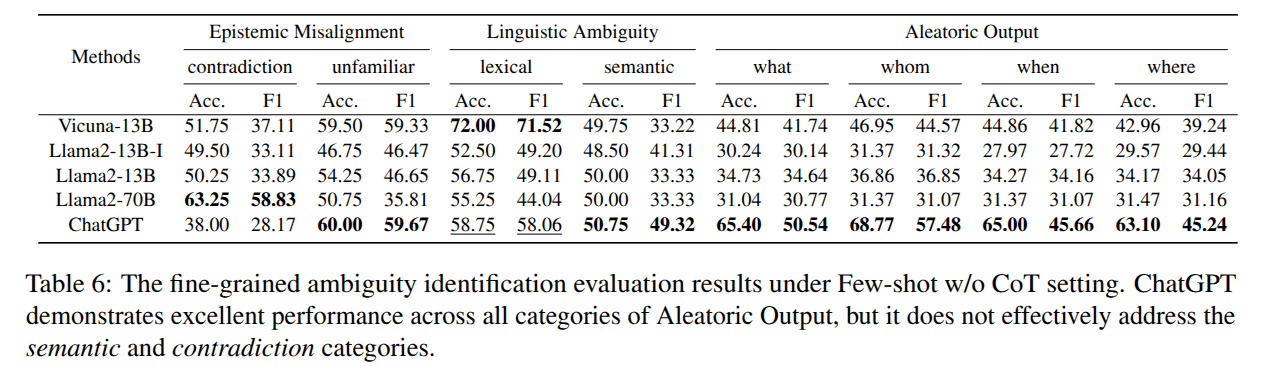
CLAMBER
Clarifying Ambiguous Query
Evaluation: Task 1 Identifying Ambiguity

CLAMBER
Clarifying Ambiguous Query
Evaluation: Task 1 Identifying Ambiguity


CLAMBER
Clarifying Ambiguous Query
Task 2: Asking Clarifying Questions
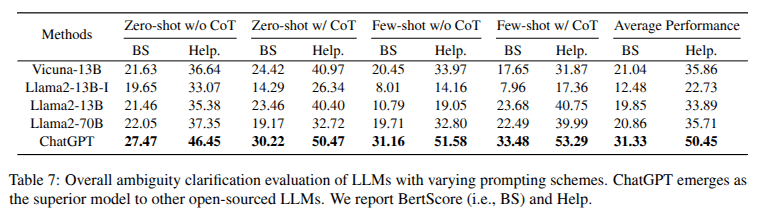
CLAMBER
Clarifying Ambiguous Query
Task 2: Asking Clarifying Questions
ChatGPT demonstrating its superior capabilities in generating clarifying questions compared
to small-scale LLMs
CLAMBER
Clarifying Ambiguous Query
Task 2: Asking Clarifying Questions
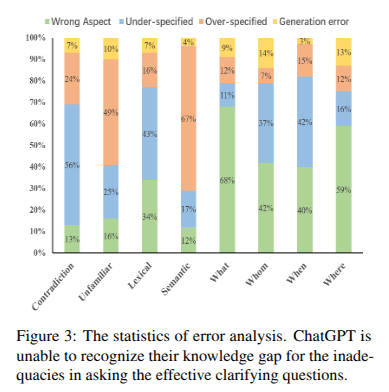

CLAMBER
Clarifying Ambiguous Query
Task 2: Asking Clarifying Questions

Questions?
QuestBench: Can LLMs ask the right question to acquire information in reasoning tasks?
Belinda Z. Li, Been Kim, Zi Wang
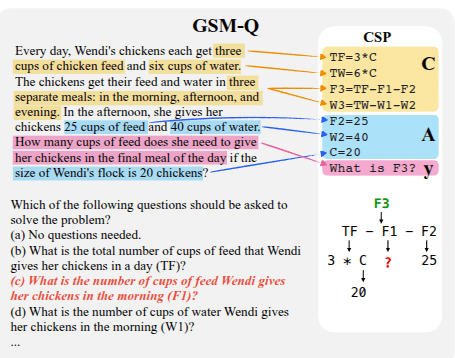
Please solve the math problem: Janet had some eggs (variable 𝑥0) and ate one (variable𝑥1). How many eggs does she have now (target variable 𝑦)?
y=x_0 - x_1
x_1=1
We need to know the value of x0 to compute y

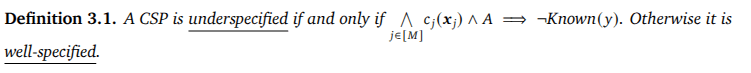
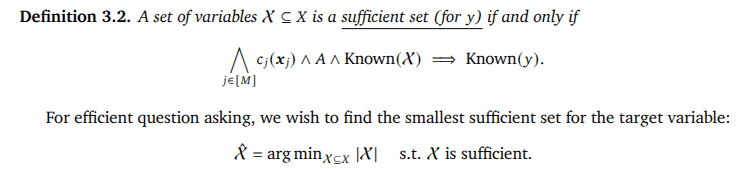

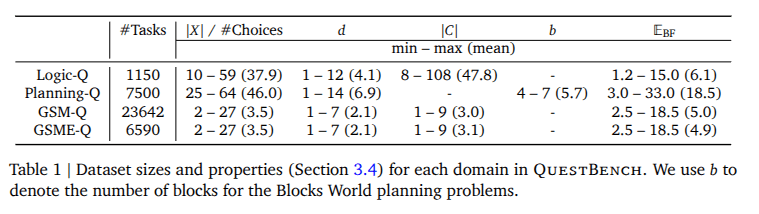
- Logic-Q: Logical reasoning tasks where the truth value of a missing proposition is needed to determine the correctness of a claim.
- Blocks world planning problems in Planning Domain Definition Language, with partially observed initial states, where one additional observation is
needed to disambiguate the shortest path to a goal. - GSM-Q/GSME-Q: Grade-school math problems that are missing conditions needed to derive the
solution. GSM-Q consists of verbalized forms of problems, while GSME-Q consists of equation
forms of problems. Both are annotated by humans.
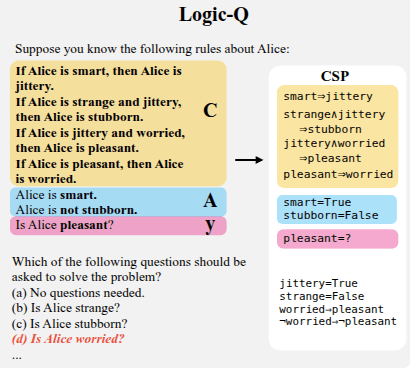
Constructed by using backwards search to obtain
1) a set of all possible variable
assignments that would imply 𝑦, and
2) another set for ¬𝑦. We take the
cross product between the sets and
identify pairs which differ on a single variable assignment, meaning assigning that variable deterministically
implies either 𝑦 or ¬𝑦
Logic-Q
Planning-Q
goal is to rearrange a set of blocks from an initial state to a goal state
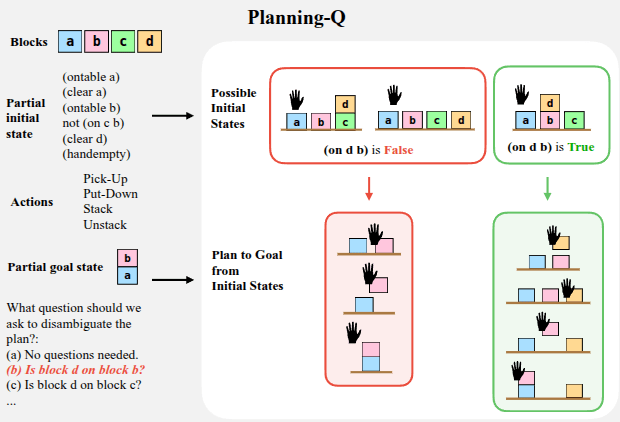
constructed Planning-Q by deriving all
possible initial states from which there is a single shortest path to the goal through backwards search,
then removing up to one atom.
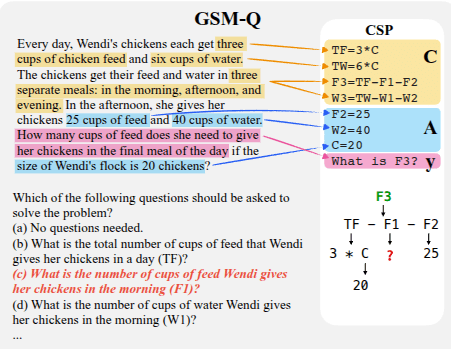
GSM-Q and GSME-Q
- In general, grade-school math problems can be parsed into simple algebra problems where a sequence
of variable substitutions can fully solve the problem. - Constructed underspecified grade-school math
problems from GSM-Plus’ “distractor” setting , which was derived from adding
a single piece of distractor information to math problems in GSM8k (that is
irrelevant to deriving the goal variable.
To construct GSM-Q/GSME-Q dataset out of GSM-Plus, they use human annotators to 1) check word problems for semantic ambiguity,
2) translate each word problem into a CSP
Results
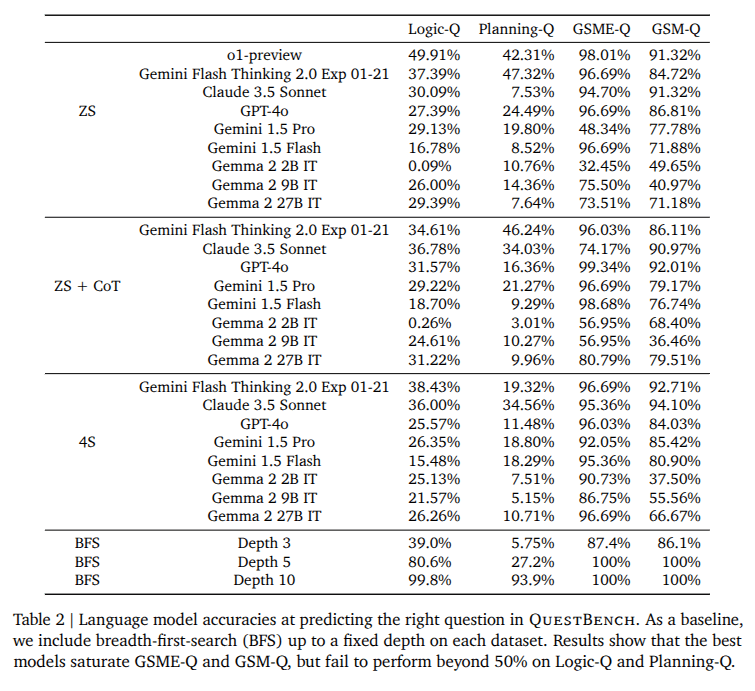
Generally, all models tested struggled to perform beyond 50% on our Logic-Q and Planning-Q
domains.
CoT, Few shot did not help
Results
Generally, all models we tested struggled to perform beyond 50% on our Logic-Q and Planning-Q
domains.
CoT, Few shot did not help
- They found that models generally had a harder time reasoning about verbalized versions of problems than if they were presented in raw equation forms.
- for the problems in QuestBench, identifying missing information requires building up a search tree, which can be easier if the problem were presented symbolically than verbally.
Results

We can approximately quantify the difficulty of each problem in QuestBench based on the
runtime of each search algorithm on that problem
Results
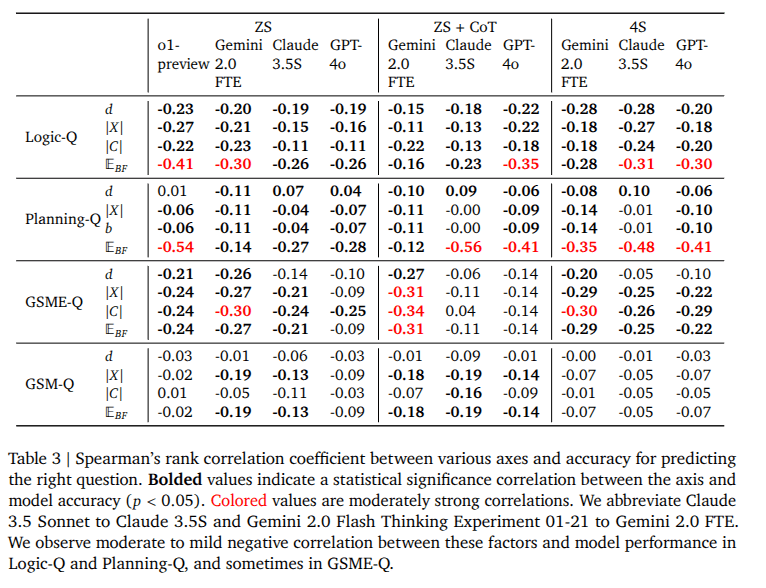
Observe mostly negative correlation
Results
Is asking the right question harder than solving the problem?
- Filter well-sepecified CSPs where model correctly answered
Results
Is asking the right question harder than solving the problem?
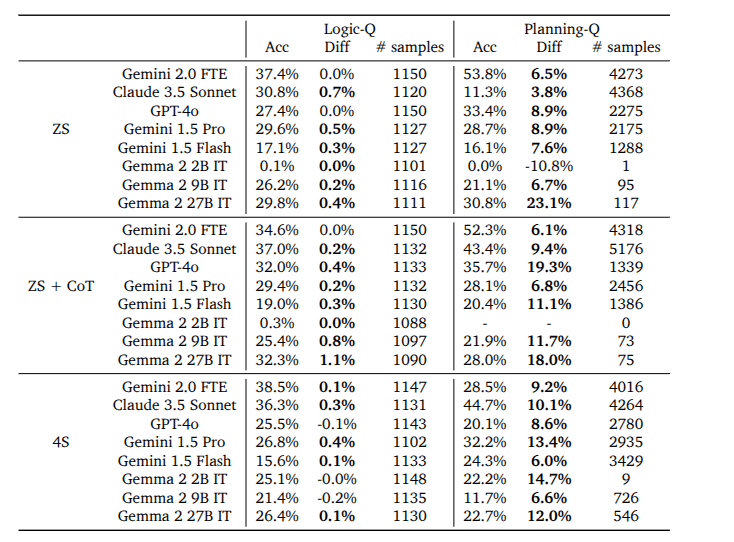
- question-asking accuracy increased slightly in Planning-Q after filtering, but remained effectively unchanged in Logic-Q
Results
Is asking the right question harder than solving the problem?
- GSM-Q and
GSME-Q domains, the question-asking accuracy for some models increased by up to 39% but for some others, it decreased by about 10%. - These results suggest that while reasoning ability for well-specified problems may be a necessary component of effective question-asking, it may not be sufficient for
identifying what information is missing.
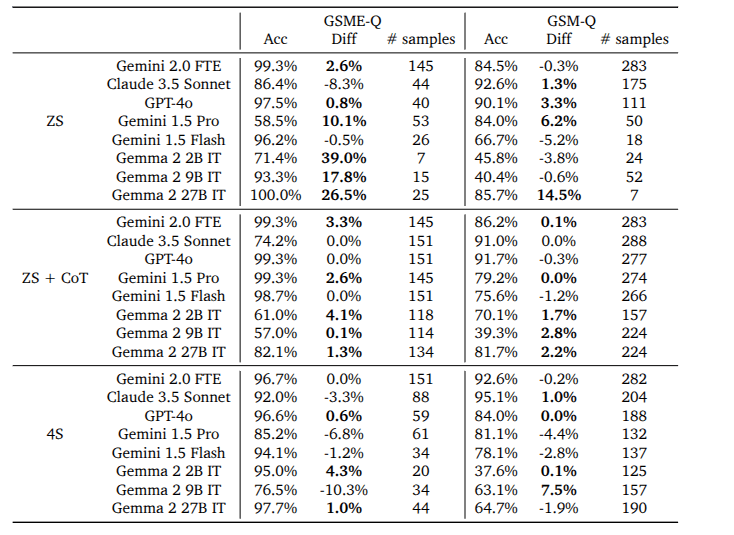
Results
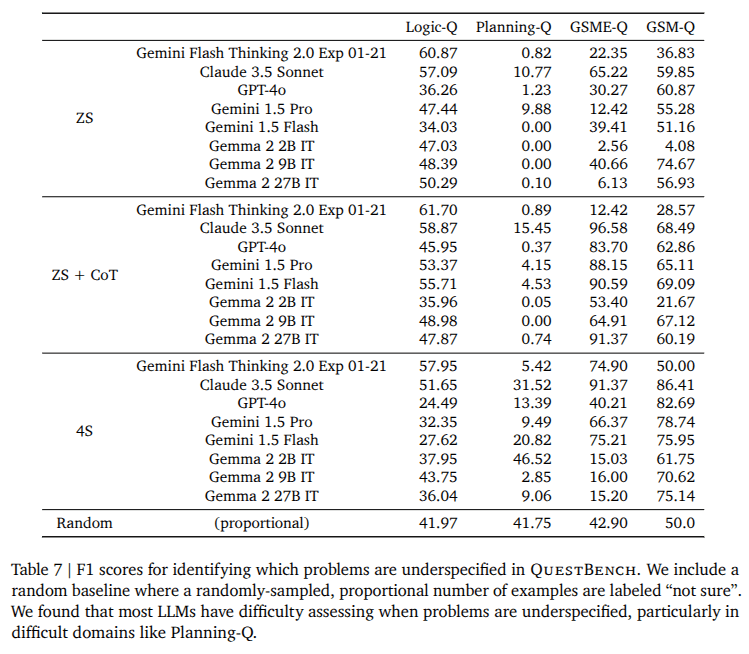
Can LLMs detect underspecification?
- Create a mix of Well specified and 1-CSP problems
- For each problem, let the llm decide if it is well specified or not
- If it is well specified, determine target variable value
- If not, Say not sure.
Results
Can LLMs detect underspecification?
- performance did not always improve substantially with model size (Particularly in the Planning Q domain)
- They say that Planning-Q problems are sufficiently difficult that models
cannot recognize uncertainty, and thus opt to guess randomly instead of answering truthfully
Questions?
Thank you!
🫡
Information SeekingAadharsh Aadhithya A
By Incredeble us



