A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning
ECE381V: Deep Reinforcement Learning (Spring 2026)

Presenter: Aadharsh Aadhithya A
Motivation and Problem Statement
ECE381V: Deep Reinforcement Learning (Spring 2026)
Motivation and Problem Statement
ECE381V: Deep Reinforcement Learning (Spring 2026)
Motivation and Problem Statement
ECE381V: Deep Reinforcement Learning (Spring 2026)
. .
)
. .
)
. .
)
Pursuit
Evade
P1
P2
\begin{bmatrix}
up \\
down\\
right\\
left \\
stay \\
\end{bmatrix}
\Pi = \begin{bmatrix}
\begin{bmatrix}
1 \\
0 \\
0 \\
0 \\
0
\end{bmatrix}
\cdots
\begin{bmatrix}
0 \\
0 \\
0 \\
0 \\
1
\end{bmatrix}
\end{bmatrix}
or
\Delta(\Pi)
Pure Stratergies
Mixed Stratergies
\Pi_i^* = \argmax_{\Delta(\Pi)} U_i(\Pi_i , \Pi_{\neg i}) \, \, \, \forall i
U is Utility for each joint policy permutations
Motivation and Problem Statement
ECE381V: Deep Reinforcement Learning (Spring 2026)
- Simplest form of MARL is Independent RL where each lerner is oblivious to other agents.
- This Makes the environement non-markovian & non stationary, convergence gaurentees vanish
- The work observes that Agents trained with InRL tend to overfit to the specific policies of the other agents, meaning their learned behaviors do not generalize well.
- Existing approaches are limited to classic 2-player zero-sum matrix games, with limited attempts to extend to sequential general (cooperative and competitive games)
Motivation and Problem Statement
ECE381V: Deep Reinforcement Learning (Spring 2026)
- Simplest form of MARL is Independent RL where each lerner is oblivious to other agents.
- This Makes the environement non-markovian & non stationary, convergence gaurentees vanish
- The work observes that Agents trained with InRL tend to overfit to the specific policies of the other agents, meaning their learned behaviors do not generalize well.
- Existing approaches are limited to classic 2-player zero-sum matrix games, with limited attempts to extend to sequential general (cooperative and competitive games)
At High Level
Double Oracle Algorithm Solves
Extensive form games, in general without exhaustive search
Oracle -> Costly step, approximate using Emperical Game theoritic Analysis and Deep RL.
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Normal form games & Nash Eq.
Normal Form Games generally has a pay-off matrix and players make moves simultaneusly to get a pay-off
Nash-Eq is a equilibrium concept, where each player does not have any incentive to deviate from their stratergy.
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Extensive Form Games
- Usually Sequential In nature
- Use Info-sets to specify partial-information settings
- Represented by a Game tree
Every Finite extensive-form game has an equivalent normal-form
0
1
2
3
. .
)
. .
)
. .
)
{Left , Right , Stay}
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
0
1
2
3
. .
)
. .
)
. .
)
{Left , Right , Stay}
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Double Oracle Algorithm
Consider this setup
P
E
\begin{array}{l|rrrrr}
\text{Pursuer} \setminus \text{Evader} & \text{Up} & \text{Down} & \text{Left} & \text{Right} & \text{Stay} \\
\hline
\text{Up} & -0.5 & -1.0 & -1.0 & 0.5 & -0.5 \\
\text{Down} & -1.0 & -0.5 & -1.0 & -0.5 & -0.5 \\
\text{Left} & -1.0 & -1.0 & -0.5 & 1.0 & 0.5 \\
\text{Right} & 0.5 & -0.5 & 1.0 & -0.5 & 0.5 \\
\text{Stay} & -0.5 & -0.5 & 0.5 & -0.5 & 0.0 \\
\end{array}
Restricted Game Matrix
Stay
Stay
0
P\E
G_1
NE:
The Pursuer looks at the columns and
picks the highest number
Evader looks at rows and picks lowest number
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Double Oracle Algorithm
Consider this setup
P
E
\begin{array}{l|rrrrr}
\text{Pursuer} \setminus \text{Evader} & \text{Up} & \text{Down} & \text{Left} & \text{Right} & \text{Stay} \\
\hline
\text{Up} & -0.5 & -1.0 & -1.0 & 0.5 & -0.5 \\
\text{Down} & -1.0 & -0.5 & -1.0 & -0.5 & -0.5 \\
\text{Left} & -1.0 & -1.0 & -0.5 & 1.0 & 0.5 \\
\text{Right} & 0.5 & -0.5 & 1.0 & -0.5 & 0.5 \\
\text{Stay} & -0.5 & -0.5 & 0.5 & -0.5 & 0.0 \\
\end{array}
Restricted Game Matrix
Stay
Stay
0
BR(\sigma^{*,1}_E)
-0.5
P\E
G_1
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Double Oracle Algorithm
Consider this setup
P
E
\begin{array}{l|rrrrr}
\text{Pursuer} \setminus \text{Evader} & \text{Up} & \text{Down} & \text{Left} & \text{Right} & \text{Stay} \\
\hline
\text{Up} & -0.5 & -1.0 & -1.0 & 0.5 & -0.5 \\
\text{Down} & -1.0 & -0.5 & -1.0 & -0.5 & -0.5 \\
\text{Left} & -1.0 & -1.0 & -0.5 & 1.0 & 0.5 \\
\text{Right} & 0.5 & -0.5 & 1.0 & -0.5 & 0.5 \\
\text{Stay} & -0.5 & -0.5 & 0.5 & -0.5 & 0.0 \\
\end{array}
Restricted Game Matrix
Stay
Stay
0
BR(\sigma^{*,1}_E)
-0.5
BR(\sigma^{*,1}_P)
0.5
P\E
G_1
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Double Oracle Algorithm
Consider this setup
P
E
\begin{array}{l|rrrrr}
\text{Pursuer} \setminus \text{Evader} & \text{Up} & \text{Down} & \text{Left} & \text{Right} & \text{Stay} \\
\hline
\text{Up} & -0.5 & -1.0 & -1.0 & 0.5 & -0.5 \\
\text{Down} & -1.0 & -0.5 & -1.0 & -0.5 & -0.5 \\
\text{Left} & -1.0 & -1.0 & -0.5 & 1.0 & 0.5 \\
\text{Right} & 0.5 & -0.5 & 1.0 & -0.5 & 0.5 \\
\text{Stay} & -0.5 & -0.5 & 0.5 & -0.5 & 0.0 \\
\end{array}
Restricted Game Matrix
Stay
Stay
0
BR(\sigma^{*,1}_E)
-0.5,Up
BR(\sigma^{*,1}_P)
0.5,Right
Left
Up
0.5
-0.5
-1
P\E
G_2
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Double Oracle Algorithm
Consider this setup
P
E
\begin{array}{l|rrrrr}
\text{Pursuer} \setminus \text{Evader} & \text{Up} & \text{Down} & \text{Left} & \text{Right} & \text{Stay} \\
\hline
\text{Up} & -0.5 & -1.0 & -1.0 & 0.5 & -0.5 \\
\text{Down} & -1.0 & -0.5 & -1.0 & -0.5 & -0.5 \\
\text{Left} & -1.0 & -1.0 & -0.5 & 1.0 & 0.5 \\
\text{Right} & 0.5 & -0.5 & 1.0 & -0.5 & 0.5 \\
\text{Stay} & -0.5 & -0.5 & 0.5 & -0.5 & 0.0 \\
\end{array}
Restricted Game Matrix
Stay
Stay
0
BR(\sigma^{*,1}_E)
-0.5,Down
BR(\sigma^{*,1}_P)
0.5,Right
Left
Up
0.5
-0.5
-1
P\E
G_3
Right
0.5
0.5
0.5
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Double Oracle Algorithm
Consider this setup
P
E
\begin{array}{l|rrrrr}
\text{Pursuer} \setminus \text{Evader} & \text{Up} & \text{Down} & \text{Left} & \text{Right} & \text{Stay} \\
\hline
\text{Up} & -0.5 & -1.0 & -1.0 & 0.5 & -0.5 \\
\text{Down} & -1.0 & -0.5 & -1.0 & -0.5 & -0.5 \\
\text{Left} & -1.0 & -1.0 & -0.5 & 1.0 & 0.5 \\
\text{Right} & 0.5 & -0.5 & 1.0 & -0.5 & 0.5 \\
\text{Stay} & -0.5 & -0.5 & 0.5 & -0.5 & 0.0 \\
\end{array}
Restricted Game Matrix
Stay
Stay
0
BR(\sigma^{*,1}_E)
-0.5,Up
BR(\sigma^{*,1}_P)
-0.5,Down
Left
Up
0.5
-0.5
-1
P\E
G_4
Right
0.5
0.5
0.5
Down
-0.5
-0.5
-1
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Double Oracle Algorithm
Consider this setup
P
E
\begin{array}{l|rrrrr}
\text{Pursuer} \setminus \text{Evader} & \text{Up} & \text{Down} & \text{Left} & \text{Right} & \text{Stay} \\
\hline
\text{Up} & -0.5 & -1.0 & -1.0 & 0.5 & -0.5 \\
\text{Down} & -1.0 & -0.5 & -1.0 & -0.5 & -0.5 \\
\text{Left} & -1.0 & -1.0 & -0.5 & 1.0 & 0.5 \\
\text{Right} & 0.5 & -0.5 & 1.0 & -0.5 & 0.5 \\
\text{Stay} & -0.5 & -0.5 & 0.5 & -0.5 & 0.0 \\
\end{array}
Restricted Game Matrix
Stay
Stay
0
BR(\sigma^{*,1}_E)
-0.5,Up
BR(\sigma^{*,1}_P)
-0.5,Down
Left
Up
0.5
-0.5
-1
P\E
G_4
Right
0.5
0.5
0.5
Down
-0.5
-0.5
-1
Down
-0.5
-1
-0.5
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Double Oracle Algorithm
Consider this setup
P
E
\begin{array}{l|rrrrr}
\text{Pursuer} \setminus \text{Evader} & \text{Up} & \text{Down} & \text{Left} & \text{Right} & \text{Stay} \\
\hline
\text{Up} & -0.5 & -1.0 & -1.0 & 0.5 & -0.5 \\
\text{Down} & -1.0 & -0.5 & -1.0 & -0.5 & -0.5 \\
\text{Left} & -1.0 & -1.0 & -0.5 & 1.0 & 0.5 \\
\text{Right} & 0.5 & -0.5 & 1.0 & -0.5 & 0.5 \\
\text{Stay} & -0.5 & -0.5 & 0.5 & -0.5 & 0.0 \\
\end{array}
Restricted Game Matrix
Stay
Stay
0
BR(\sigma^{*,1}_E)
-0.5,Up
BR(\sigma^{*,1}_P)
-0.5,Down
Left
Up
0.5
-0.5
-1
P\E
G_4
Right
0.5
0.5
0.5
Down
-0.5
-0.5
-1
Down
-0.5
-1
-0.5
No New best responses
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Double Oracle Algorithm
Consider this setup
P
E
\begin{array}{l|rrrrr}
\text{Pursuer} \setminus \text{Evader} & \text{Up} & \text{Down} & \text{Left} & \text{Right} & \text{Stay} \\
\hline
\text{Up} & -0.5 & -1.0 & -1.0 & 0.5 & -0.5 \\
\text{Down} & -1.0 & -0.5 & -1.0 & -0.5 & -0.5 \\
\text{Left} & -1.0 & -1.0 & -0.5 & 1.0 & 0.5 \\
\text{Right} & 0.5 & -0.5 & 1.0 & -0.5 & 0.5 \\
\text{Stay} & -0.5 & -0.5 & 0.5 & -0.5 & 0.0 \\
\end{array}
Restricted Game Matrix
Stay
Stay
0
BR(\sigma^{*,1}_E)
-0.5,Up
BR(\sigma^{*,1}_P)
-0.5,Down
Left
Up
0.5
-0.5
-1
P\E
G_4
Right
0.5
0.5
0.5
Down
-0.5
-0.5
-1
Down
-0.5
-1
-0.5
No New best responses
Converged
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Double Oracle Algorithm
Consider this setup
P
E
Restricted Game Matrix
Stay
Stay
0
Left
Up
0.5
-0.5
-1
P\E
G_4
Right
0.5
0.5
0.5
Down
-0.5
-0.5
-1
Down
-0.5
-1
-0.5
No New best responses
Converged
Note, converged in 4x3 submatrix , instead
of full 5x5 game solver
Worst case, Might have to enumerate full stratergy space
However, the authors claim that there is evidence that support sizes shrink for many games as a function of episode length and information structure.
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Emperical Game theoretic analysis
Simulate much smaller game
Emperical Payoff matrix
Discover new stratergies & Reason
Pre-reqs
ECE381V: Deep Reinforcement Learning (Spring 2026)
Emperical Game theoretic analysis
Simulate much smaller game
Emperical Payoff matrix
Discover new stratergies & Reason
Instead of exact best response, use RL for approximate best response
Use simulations for emperical pay-offs
Policy-Space Response Oracles
ECE381V: Deep Reinforcement Learning (Spring 2026)
Policy-Space Response Oracles
ECE381V: Deep Reinforcement Learning (Spring 2026)
\begin{array}{l|rrrrr}
\text{Pursuer} \setminus \text{Evader} & \text{Up} & \text{Down} & \text{Left} & \text{Right} & \text{Stay} \\
\hline
\text{Up} & -0.5 & -1.0 & -1.0 & 0.5 & -0.5 \\
\text{Down} & -1.0 & -0.5 & -1.0 & -0.5 & -0.5 \\
\text{Left} & -1.0 & -1.0 & -0.5 & 1.0 & 0.5 \\
\text{Right} & 0.5 & -0.5 & 1.0 & -0.5 & 0.5 \\
\text{Stay} & -0.5 & -0.5 & 0.5 & -0.5 & 0.0 \\
\end{array}
Restricted Game Matrix
Uniform random
BR(\sigma^{*,1}_P)
0.5
BR(\sigma^{*,1}_P)
-0.5
P\E
G_1
\pi_1^e
\pi_1^p
Policy-Space Response Oracles
ECE381V: Deep Reinforcement Learning (Spring 2026)
Restricted Game Matrix
Uniform random
\pi_2^p \leftarrow BR(\sigma^{*,1}_P) \leftarrow RL \, Loop
\pi_2^e\leftarrow BR(\sigma^{*,1}_E) \leftarrow RL \, Loop
P\E
G_1
\pi_1^e
\pi_1^p
In partially observable multiagent environments, when the other players are fixed the envirionment becomes markovian and computing best responses reduces to MDP , thus any RL algo. can be used
Policy-Space Response Oracles
ECE381V: Deep Reinforcement Learning (Spring 2026)
Restricted Game Matrix
U11
\pi_2^p \leftarrow BR(\sigma^{*,1}_P) \leftarrow RL \, Loop
\pi_2^e\leftarrow BR(\sigma^{*,1}_E) \leftarrow RL \, Loop
P\E
G_1
\pi_1^e
\pi_1^p
\pi_2^e
\pi_2^p
U12
U21
U22
U11
U12
U21
U22
Obtained through simulation
of respective joint policies
Policy-Space Response Oracles
ECE381V: Deep Reinforcement Learning (Spring 2026)
Restricted Game Matrix
U11
\pi_2^p \leftarrow BR(\sigma^{*,1}_P) \leftarrow RL \, Loop
\pi_2^e\leftarrow BR(\sigma^{*,1}_E) \leftarrow RL \, Loop
P\E
G_1
\pi_1^e
\pi_1^p
\pi_2^e
\pi_2^p
U12
U21
U22
U11
U12
U21
U22
Obtained through simulation
of respective joint policies
U11
U12
U21
U22
Meta-solver
\sigma_i's
Metasolver gives the mixture over
policies found through the oracle (RL)
Policy-Space Response Oracles
ECE381V: Deep Reinforcement Learning (Spring 2026)
Text
U11
\pi_2^p \leftarrow BR(\sigma^{*,1}_P) \leftarrow RL \, Loop
\pi_2^e\leftarrow BR(\sigma^{*,1}_E) \leftarrow RL \, Loop
P\E
\pi_1^e
\pi_1^p
\pi_2^e
\pi_2^p
U12
U21
U22
U11
U12
U21
U22
Obtained through simulation
of respective joint policies
U11
U12
U21
U22
Meta-solver
\sigma_i's
Metasolver gives the mixture over
policies found through the oracle (RL)
Policy-Space Response Oracles
ECE381V: Deep Reinforcement Learning (Spring 2026)
Text
U11
\pi_2^p \leftarrow BR(\sigma^{*,1}_P) \leftarrow RL \, Loop
\pi_2^e\leftarrow BR(\sigma^{*,1}_E) \leftarrow RL \, Loop
P\E
\pi_1^e
\pi_1^p
\pi_2^e
\pi_2^p
U12
U21
U22
U11
U12
U21
U22
Obtained through simulation
of respective joint policies
U11
U12
U21
U22
Meta-solver
\sigma_i's
Meta-solver
Policy-Space Response Oracles
ECE381V: Deep Reinforcement Learning (Spring 2026)
Text
U11
\pi_2^p \leftarrow BR(\sigma^{*,1}_P) \leftarrow RL \, Loop
\pi_2^e\leftarrow BR(\sigma^{*,1}_E) \leftarrow RL \, Loop
P\E
\pi_1^e
\pi_1^p
\pi_2^e
\pi_2^p
U12
U21
U22
U11
U12
U21
U22
Obtained through simulation
of respective joint policies
U11
U12
U21
U22
Meta-solver
\sigma_i's
Meta-solver
Regret matching
Hedge
Projected Replicated dyn.
Policy-Space Response Oracles
ECE381V: Deep Reinforcement Learning (Spring 2026)
Deep Cognitive Hierarchies
ECE381V: Deep Reinforcement Learning (Spring 2026)
- RL Step can take a long time to converge to a good response
- Basic behaviours might have to be relearned when starting from scratch
K \leftarrow num \, levels
\cdots
\cdots
\cdots
\cdots
\cdots
\cdots
\cdots
Deep Cognitive Hierarchies
ECE381V: Deep Reinforcement Learning (Spring 2026)
- RL Step can take a long time to converge to a good response
- Basic behaviours might have to be relearned when starting from scratch
K \leftarrow num \, levels
\cdots
\cdots
\cdots
\cdots
\cdots
\cdots
\cdots
N
K
N \leftarrow num \, players
Start N*K procs in
Parallel
Uniform Random
Deep Cognitive Hierarchies
ECE381V: Deep Reinforcement Learning (Spring 2026)
- RL Step can take a long time to converge to a good response
- Basic behaviours might have to be relearned when starting from scratch
K \leftarrow num \, levels
\cdots
\cdots
\cdots
\cdots
\cdots
\cdots
\cdots
N
K
N \leftarrow num \, players
Start N*K procs in
Parallel
Uniform Random
\text{Train } \pi_{i,k} \text{and get } \sigma_{i,k}
Cache to central disk
Deep Cognitive Hierarchies
ECE381V: Deep Reinforcement Learning (Spring 2026)
- RL Step can take a long time to converge to a good response
- Basic behaviours might have to be relearned when starting from scratch
K \leftarrow num \, levels
\cdots
\cdots
\cdots
\cdots
\cdots
\cdots
\cdots
N
K
N \leftarrow num \, players
Start N*K procs in
Parallel
Uniform Random
\text{Train } \pi_{i,k} \text{and get } \sigma_{i,k}
Cache to central disk
Since Each procs, uses
Slightly outdated copies,
its a approximation of
PSRO
Deep Cognitive Hierarchies
ECE381V: Deep Reinforcement Learning (Spring 2026)
Experiments
ECE381V: Deep Reinforcement Learning (Spring 2026)
Experiments
ECE381V: Deep Reinforcement Learning (Spring 2026)
- Uses Reactor for Learning SoTA in Atari game playing during the release of the paper
Experiments Setup
ECE381V: Deep Reinforcement Learning (Spring 2026)
- First person Grid world games
17
10
10
2
21x20x3 pixels as obs
- Laser Tag
- Random spawning, if agent is tagged twice, then it is teleported to spawn point, and source agent is given reward of +1
- Gathering
- No tagging; gather apples, 1 pt for 1 apple, refresh at fixed rate
- Pathfind
- 1pt reward when both reach their respective destinations
Experiments Setup
ECE381V: Deep Reinforcement Learning (Spring 2026)
- First person Grid world games
17
10
10
2
21x20x3 pixels as obs
- Laser Tag
- Random spawning, if agent is tagged twice, then it is teleported to spawn point, and source agent is given reward of +1
- Gathering
- No tagging; gather apples, 1 pt for 1 apple, refresh at fixed rate
- Pathfind
- 1pt reward when both reach their respective destinations
- Leduc Poker
- Measure Performance using two metrics
- Performance against fixed players:
- Random
- Counterfactual regret minimization (CFR) after 500 iterations (cfr500)
- Purified version of CFR that chooses action with highest prob.
- NashConv
- Canbe interpreted as a value that denotes distance from the Nash equilibrium
- Performance against fixed players:
Results
ECE381V: Deep Reinforcement Learning (Spring 2026)
Joint Policy Correlation Matrix
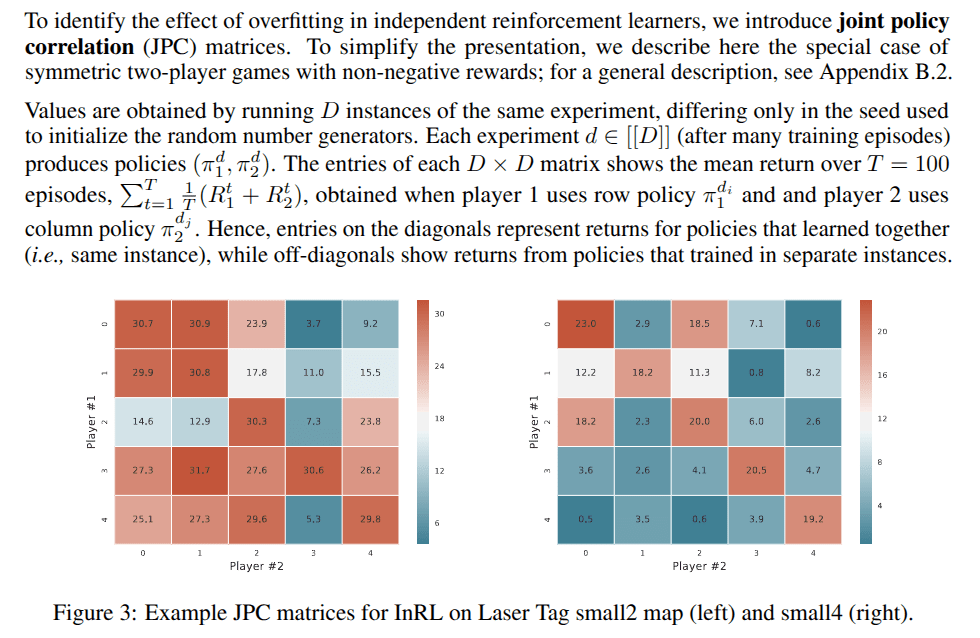
Average Propotional Loss
\frac{\bar{D} - \bar{O}}{ \bar{D}}
\text{mean value of Diagonals} \leftarrow \bar{D}
\text{mean value of off-Diagonals} \leftarrow \bar{O}
-
bar{D} (Mean of Diagonals): This represents the average score when agents play with the exact partners they trained with. Because they trained together, they have usually figured out how to coordinate well, resulting in a high score.
-
bar{O} (Mean of Off-diagonals): This represents the average score when an agent is forced to play with a "stranger," an agent that was trained in an identical environment, but in a separate training run (with a different random seed).
Even in a simple domain with almost full observability (small2), an independently-learned policy could expect to lose 34.2% of its reward when playing with another independently-learned policy even though it was trained under identical circumstances
Results
ECE381V: Deep Reinforcement Learning (Spring 2026)
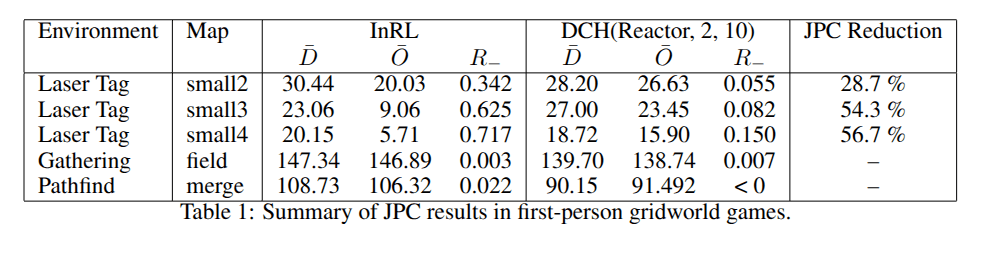
{
No JPC problem because tasks are largley independent?
Results
ECE381V: Deep Reinforcement Learning (Spring 2026)
Meta-strategies help bringing R_ down
R_ for just level-10 policies (without mixing) is 0.147,0.27 and 0.118 for small2-4 respectively
With Meta-stratergies is shown in table above
Results
ECE381V: Deep Reinforcement Learning (Spring 2026)
Diminishing Returns on num levels
-
Level 3: Helps decently. It reduces the overfitting penalty by 44%.
-
Level 5: Helps a lot. It reduces the overfitting penalty by 56.1%
-
Level 10: Barely helps more than Level 5. It reduces the penalty by 56.7%.
Results
ECE381V: Deep Reinforcement Learning (Spring 2026)
Results on Leduc Poker
Effect of the various meta-strategies and exploration parameters
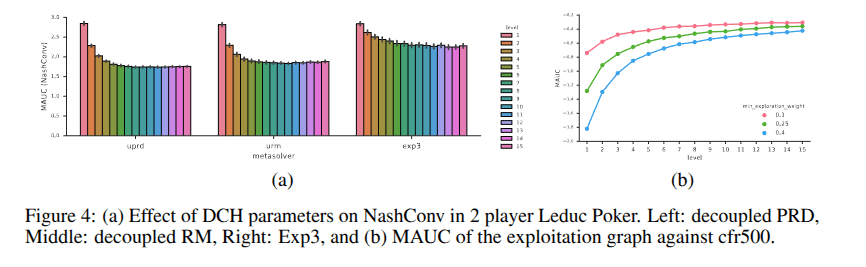
Metric Used: Performance was measured using the Mean Area-Under-Curve (MAUC) of the final 32 NashConv values. (Lower better)
-
Optimal Exploration Rate: Setting gamma =0.4 proved most effective for minimizing NashConv.
-
Meta-Solver Performance Ranking: 1. Decoupled Replicator Dynamics (Best)
2. Decoupled Regret-Matching
3. Exp3
-
Level Scaling: Higher training levels consistently reduce NashConv, but exhibit diminishing returns (improvements plateau at higher levels).
Results
ECE381V: Deep Reinforcement Learning (Spring 2026)
Comparison to Neural Fictitious Self play
-
DCH & PSRO converge faster than NFSP at the beginning of training.
-
This early speed advantage is likely due to their use of superior meta-strategies compared to the uniform random strategy used in NFSP's fictitious play.
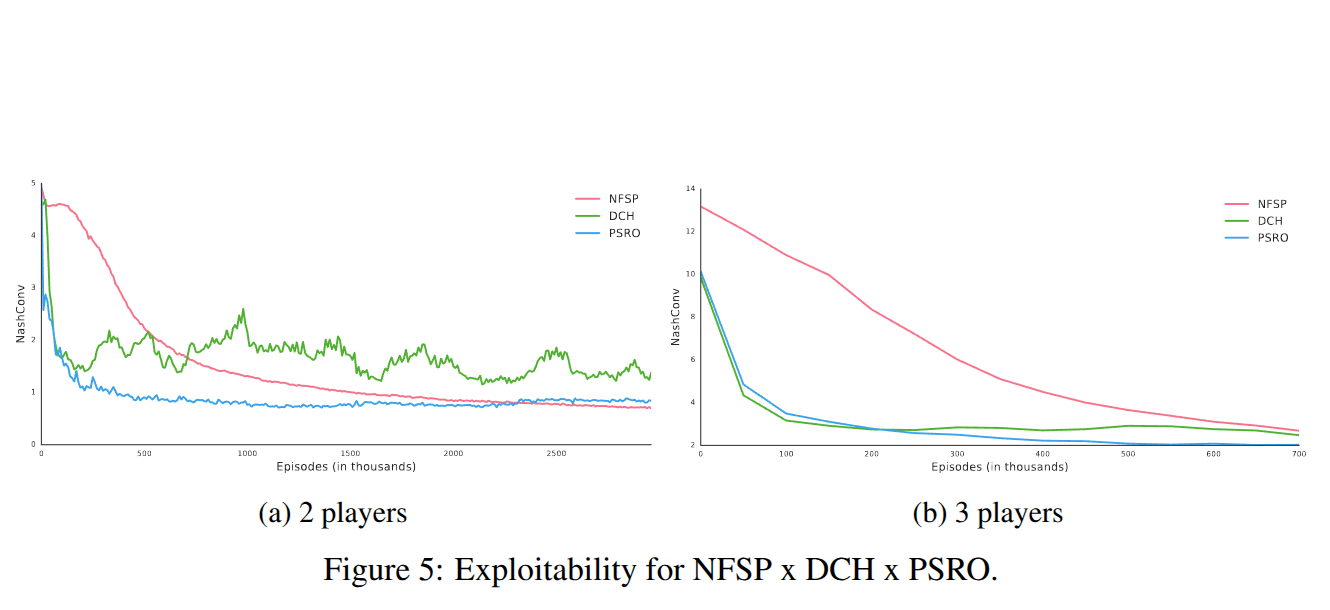
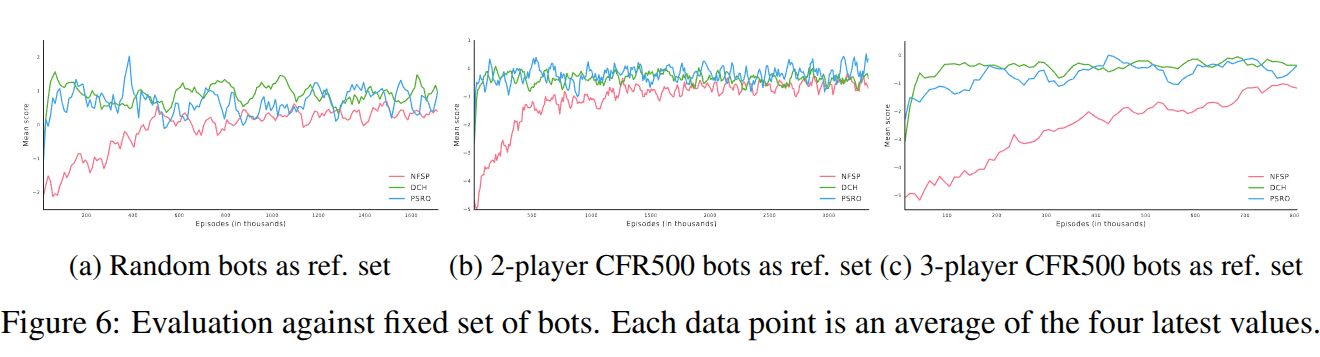
Results
ECE381V: Deep Reinforcement Learning (Spring 2026)
Comparison to Neural Fictitious Self play
-
DCH & PSRO converge faster than NFSP at the beginning of training.
-
This early speed advantage is likely due to their use of superior meta-strategies compared to the uniform random strategy used in NFSP's fictitious play.
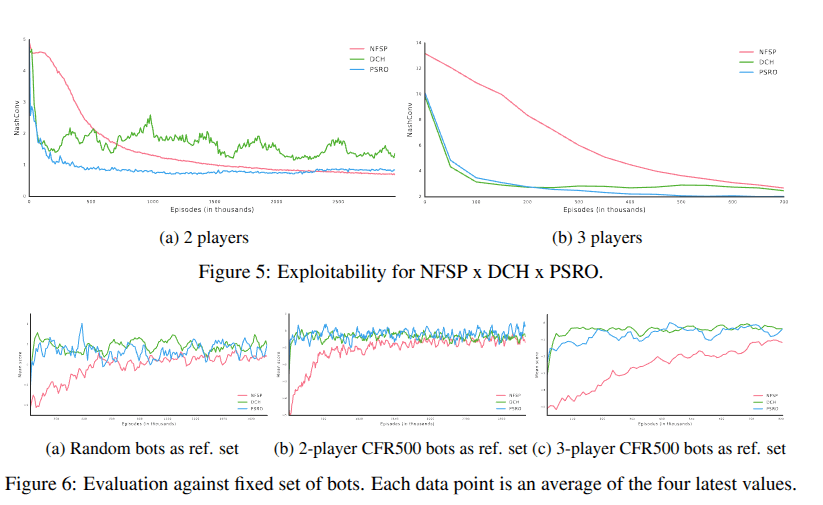
-
NFSP wins in the long run: It eventually reaches a lower exploitability than the others.
-
It Plateus: DCH and PSRO convergence curves plateau earlier (DCH is especially hindered by asynchronous updates). NFSP successfully mixes strategies deep down in the game tree (crucial for games like poker). DCH and PSRO only mix at the very top level over full, complete policies.
Results
ECE381V: Deep Reinforcement Learning (Spring 2026)
Comparison to Neural Fictitious Self play
-
DCH & PSRO converge faster than NFSP at the beginning of training.
-
This early speed advantage is likely due to their use of superior meta-strategies compared to the uniform random strategy used in NFSP's fictitious play.
- PSRO & DCH are able to achieve better performance against fixed players,
- Maybe because policies produced by PSRO and DCH are better able to recognize flaws in weaker opponents' policies
- NFSP is computing a safe equilibrium, while PSRO/DCH may be trading convergence precision for the ability to adapt to a range of different play observed during training.
Future Work & Limitations
ECE381V: Deep Reinforcement Learning (Spring 2026)
Future Work & Limitations
ECE381V: Deep Reinforcement Learning (Spring 2026)
- Consider Maintaining Diversity among oracles
- Generalized transferable oracles over similar opponent policies using successor features
- Fast online adaptation & ToM relationship
Future Work
Future Work & Limitations
ECE381V: Deep Reinforcement Learning (Spring 2026)
-
Evaluation and Results: The evaluation and results section lacks depth and could have been more comprehensive.
-
Methodology: The methodology mainly relies on Double Oracle combined with Reinforcement Learning (RL) and Empirical Game-Theoretic Analysis (EGTA), with limited methodological novelty.
-
Metric Limitation: The proposed metric is defined only for two-player games, limiting its general applicability.
-
Motivation vs Experiments: Although the paper claims to support both collaborative and competitive settings, no experiments demonstrate this capability.
-
Clarity and Related Work: The writing does not sufficiently explain related work or prerequisites, making the paper difficult to follow. In particular, the Double Oracle algorithm could have been explained in more detail.
-
Hyperparameter Sensitivity: The paper does not discuss sensitivity to hyperparameters or provide analysis on their impact.
Limitations
Extended Readings
ECE381V: Deep Reinforcement Learning (Spring 2026)
Extended Readings
ECE381V: Deep Reinforcement Learning (Spring 2026)

Extends to Multiplayer games
Extended Readings
ECE381V: Deep Reinforcement Learning (Spring 2026)
Fater Convergence, Mixing at every infostate

Extended Readings
ECE381V: Deep Reinforcement Learning (Spring 2026)
N Player general sum game, CE for metasolver

Summary
ECE381V: Deep Reinforcement Learning (Spring 2026)
Summary
ECE381V: Deep Reinforcement Learning (Spring 2026)
- Quantifies Joint Policy Correlation and quantifies the overfitting issue in InRL
- Proposes a Generalized MARL Algorithm that overcomes this, while performing in par with baselines.
- Uses Double-Oracle Paradigm (PSRO)
- RL for Approximate Best Response
- ETGA for estimating the payoff matrix
- DO Style Alg. eliminates the need to enumerate the full strategy space
- Proposes Parallized PSRO called Deep Cognitive Hierarchies that approximates PSRO
- Uses Double-Oracle Paradigm (PSRO)
- Empirically shows DCH reduces JPC significantly in First-person Grid world games
- Also Empirically shows:
- DCH and PSRO perform as well as baselines. Sometimes the async nature of PSRO is affecting convergence (Ex, 2 Player)
- Diminishing Returns on an increasing number of levels
- MetaStrategy helps reduce JPC
- Able to outperform Fixed Players, and perform as good as NFSP
Thank you
ECE381V: Deep Reinforcement Learning (Spring 2026)
deck
By Incredeble us



