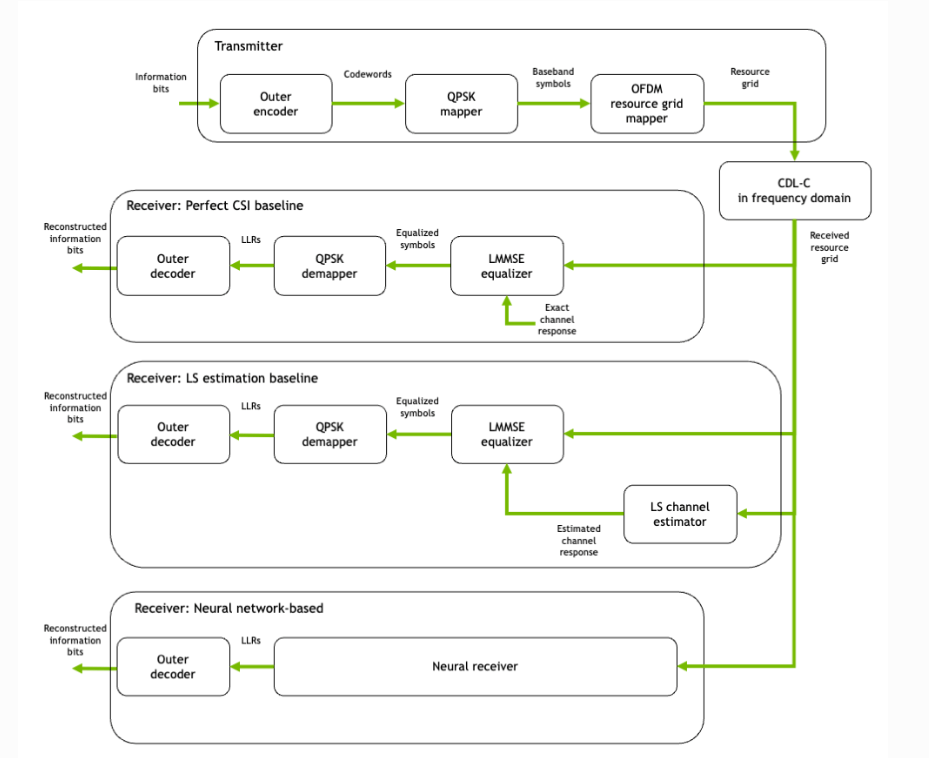
Adaptive Neural Comm. Systems
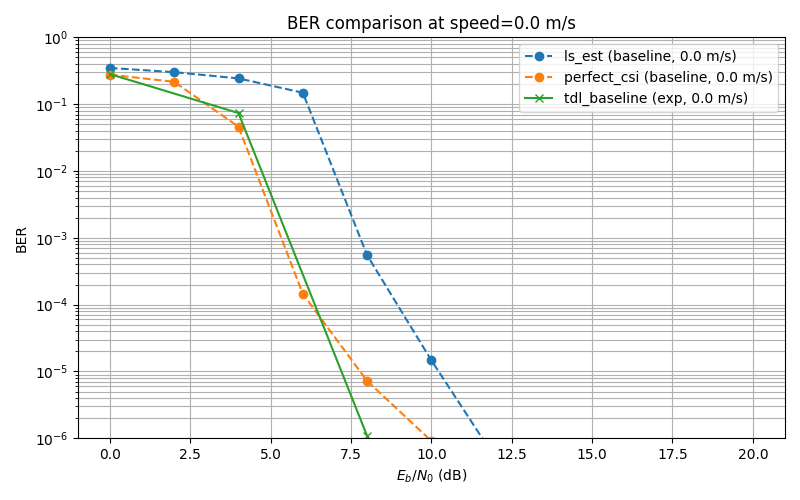
Baseline Exps
Baseline Exps
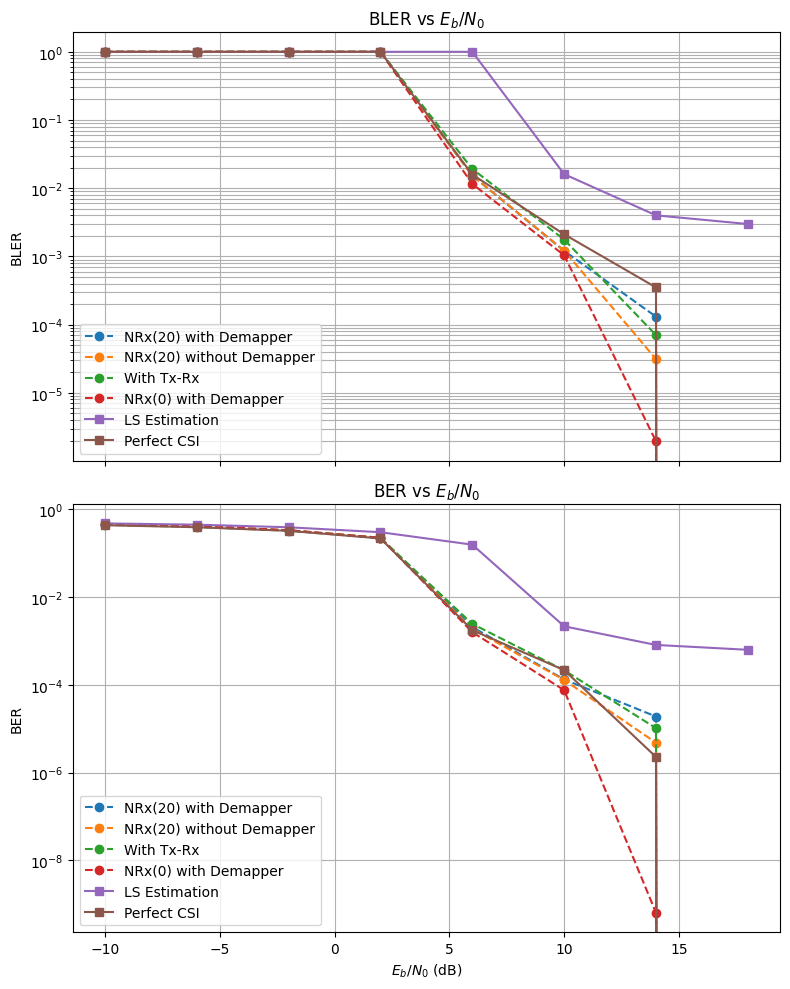
NRx(20) With Demapper:
- This is a configuration where we only have a trainable neural receiver, and the transmission pipeline is fixed, i.e, no trainable parameters, default conventional transmission pipeline. During training, the speed of the user is randomly sampled from 0-20 when getting the channel impulse response. The output of the Neural Receiver is then passed onto a Demapper to get the LLRs.
2) NRx(20) Without Demapper:
- This is an identical configuration as above, just without the demapper. The Nural receiver is expected to produce the LLRs directly.
3) Tx-Rx:
- A light-weight neural modulator is added to the transmitter side, which takes in a 14x128 Resource Grid and gives out another 14x128 modulated Grid. The Receiver side configuration is identical to (1): speed randomly sampled from 0-20, neural_Receiver -> Demapper-> LLRs.
Baselines: Baselines are Perfect CSI, where there is no estimation at the receiver's side, and perfect information is available, and LS Estimation, which is a baseline from Sionna's tutorial that deepOFDM work also uses.
After our last meeting, Nasim and I spoke and discussed that perhaps we should start with training the model with speed=0 and seeing what happens when we change speed at test time. That is our next configuration,
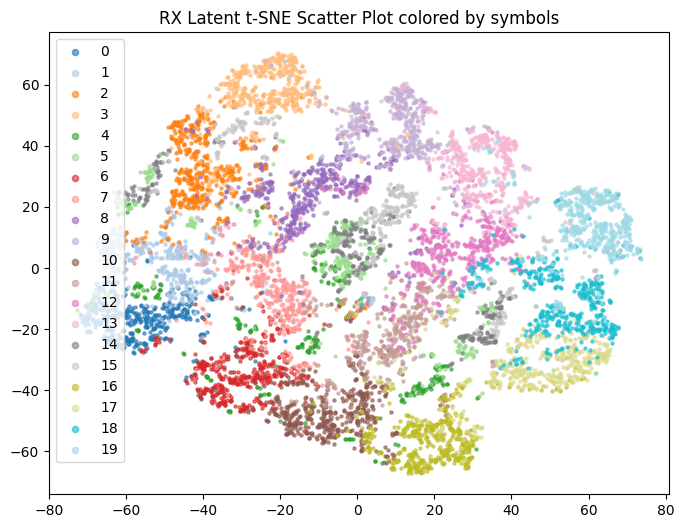
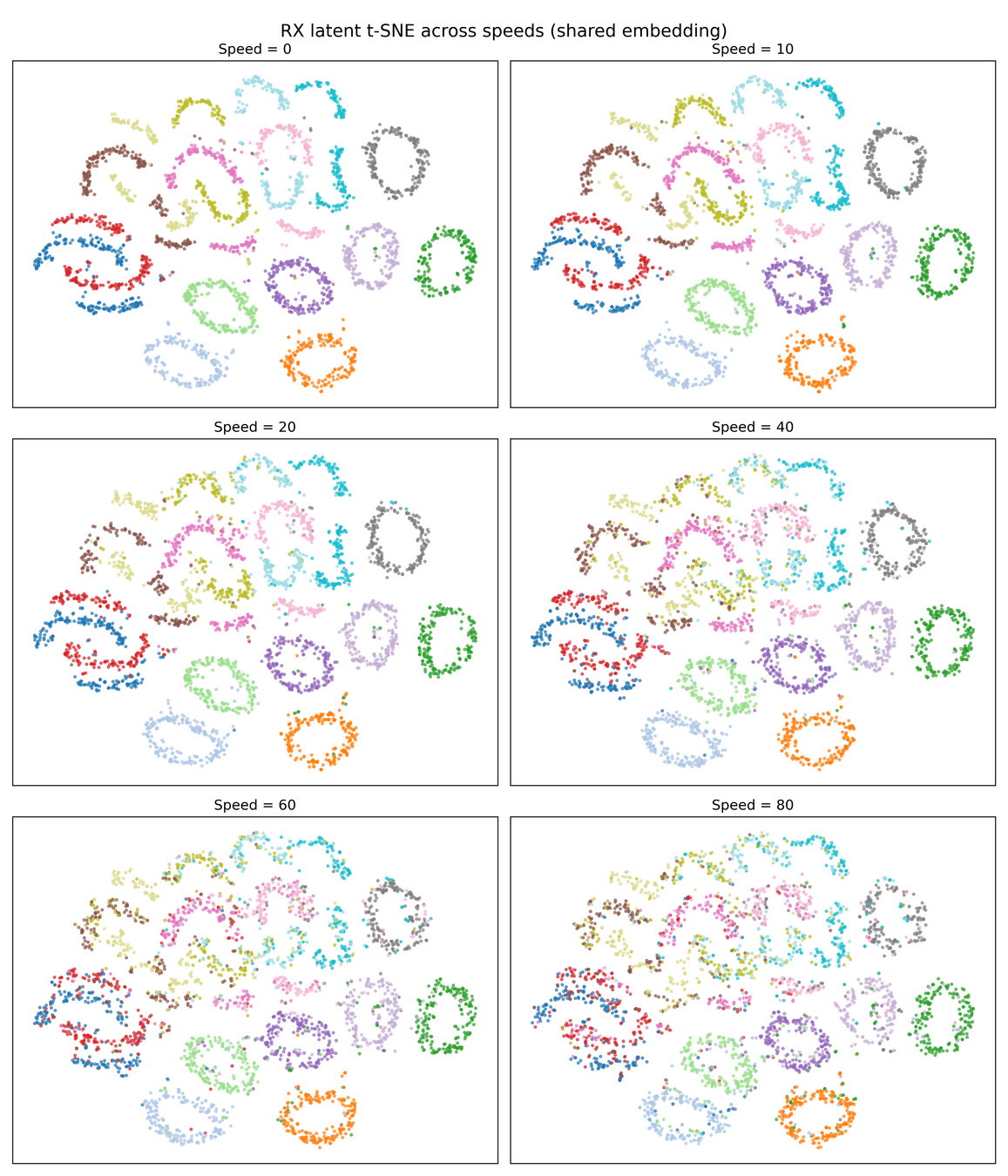
4) NRx(0) with Demapper: Identical configuration as (1), but during training, we only get channel impulse responses with the user speed being 0. Then, during test time, we change the channel model to have speeds of 10,20, etc, and see what happens to the clusters.
NRx(20) with demapper
Demapper
LLRs
NRx(20) wo demapper
LLRs
NRx(20)
Demapper
Baseline Exps
Baseline Exps
Quick Sanity Check
Baseline Exps
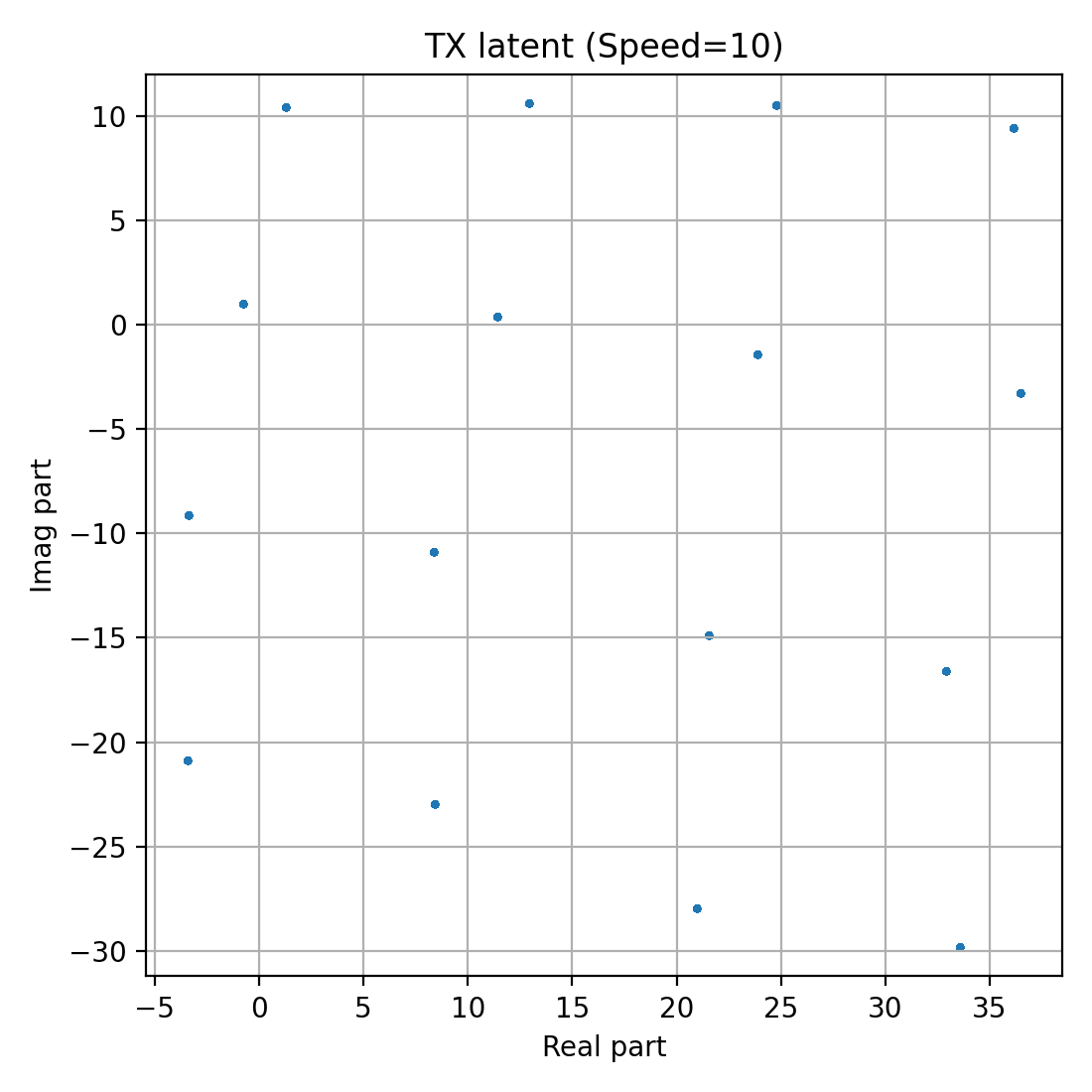
For Traning both Tx and Rx
TX
RX
Baseline Exps
NRX(0) setting
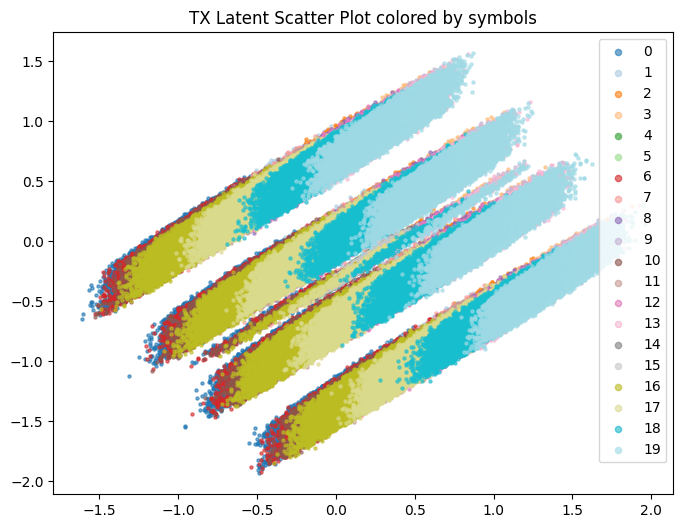
Latent from NRx

Baseline Exps
Next, we wanted to see what happens if we have "Trainable Mapper" in the NRX(0) setting
Baseline Exps
Next, we wanted to see what happens if we have "Trainable Mapper" in the NRX(0) setting
Learned Symbols
Baseline Exps
Next, we wanted to see what happens if we have "Trainable Mapper" in the NRX(0) setting
Baseline Exps
Next, we wanted to see what happens if we have "Trainable Mapper" in the NRX(0) setting
Also when we have mapper = trainable, loss curve appears to be lot smoother
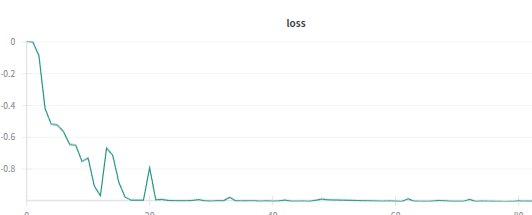
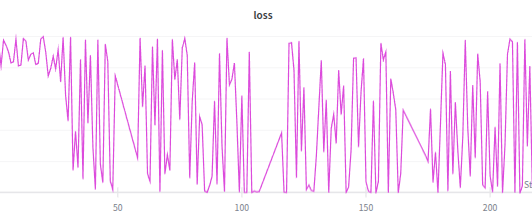
With Trainable Mapper
NRx(0) setting
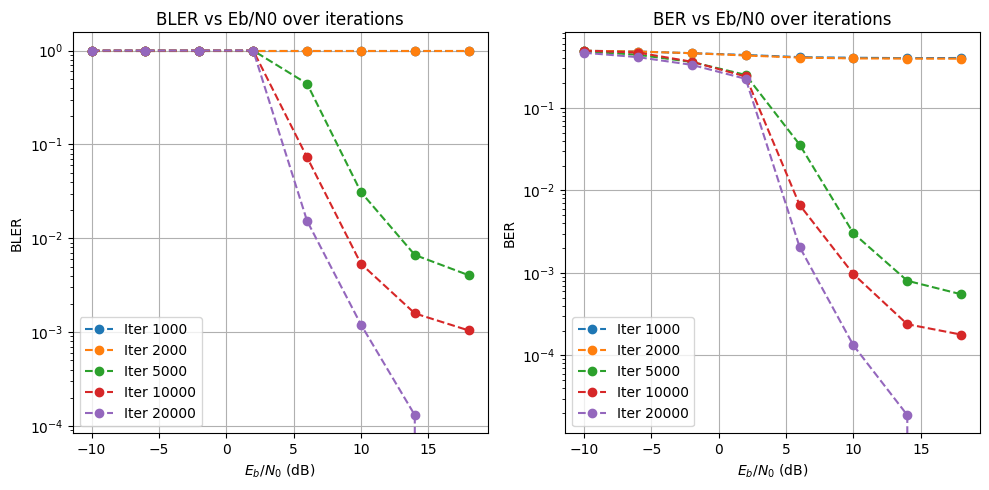
Also, when running the eval loop, the eval stopped at ebno=-10, because it satisfied the low error rate threshold, which was met for other configs only at ebno=10-14
Experiments
Experiments
Trained for 20k steps with normal loss
No trainable component in TX
Neural Receiver
Experiments
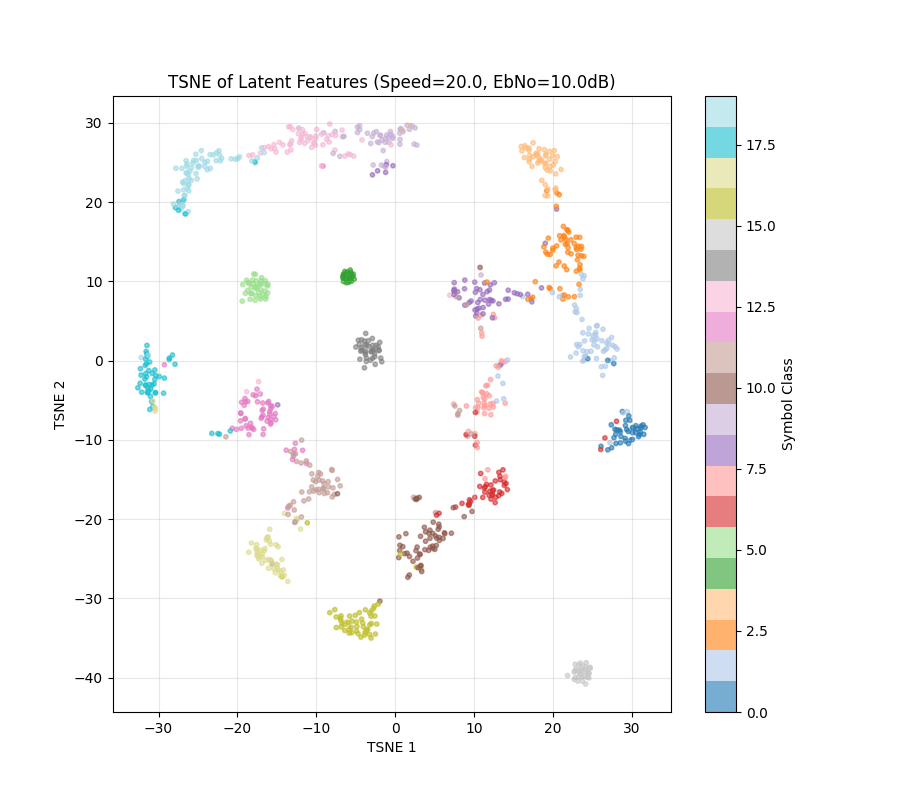
Note: This TSNE might not have one to one Correspondence. Randomness comes from input data being generated
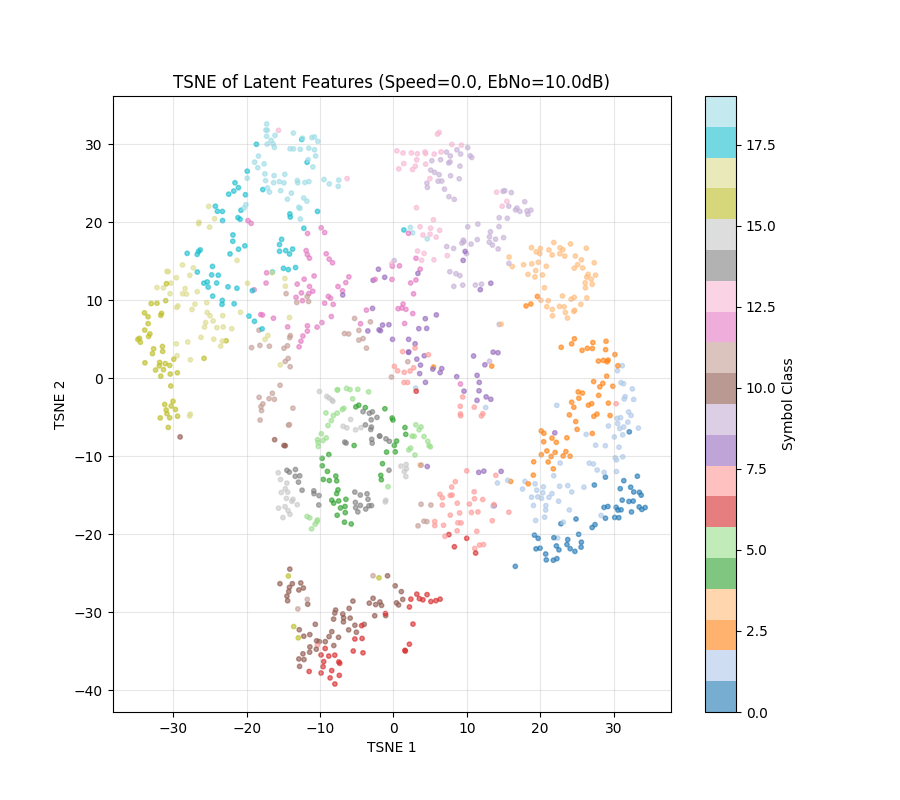
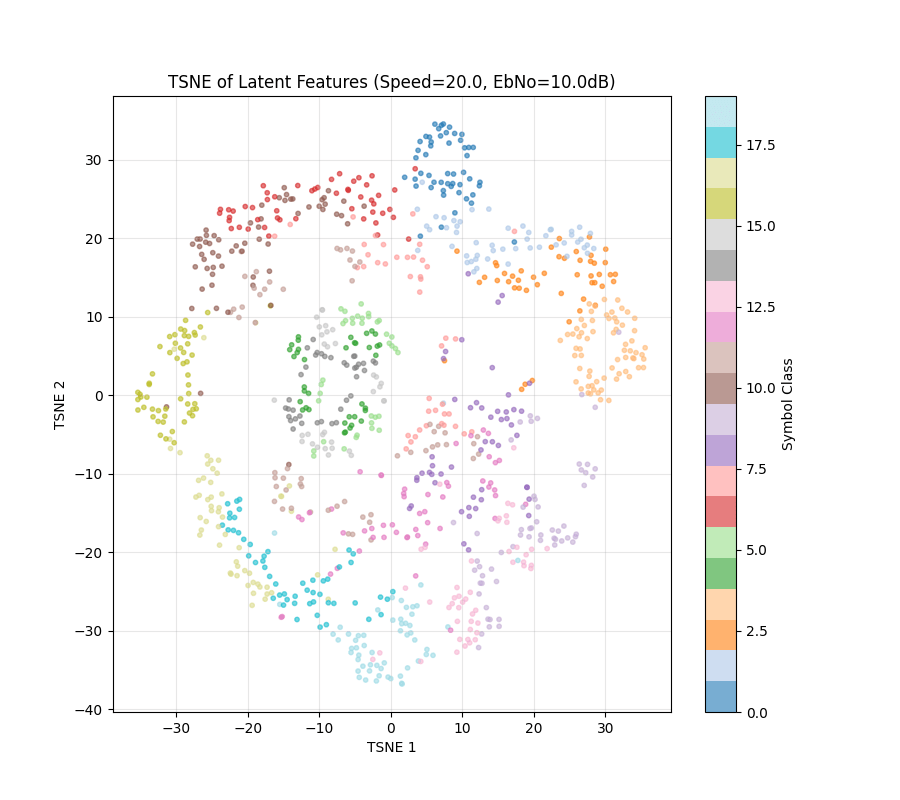
Experiments
To Make the clusters more coherent
Loss = Information Rate - 0.1*(Intra-class variance)
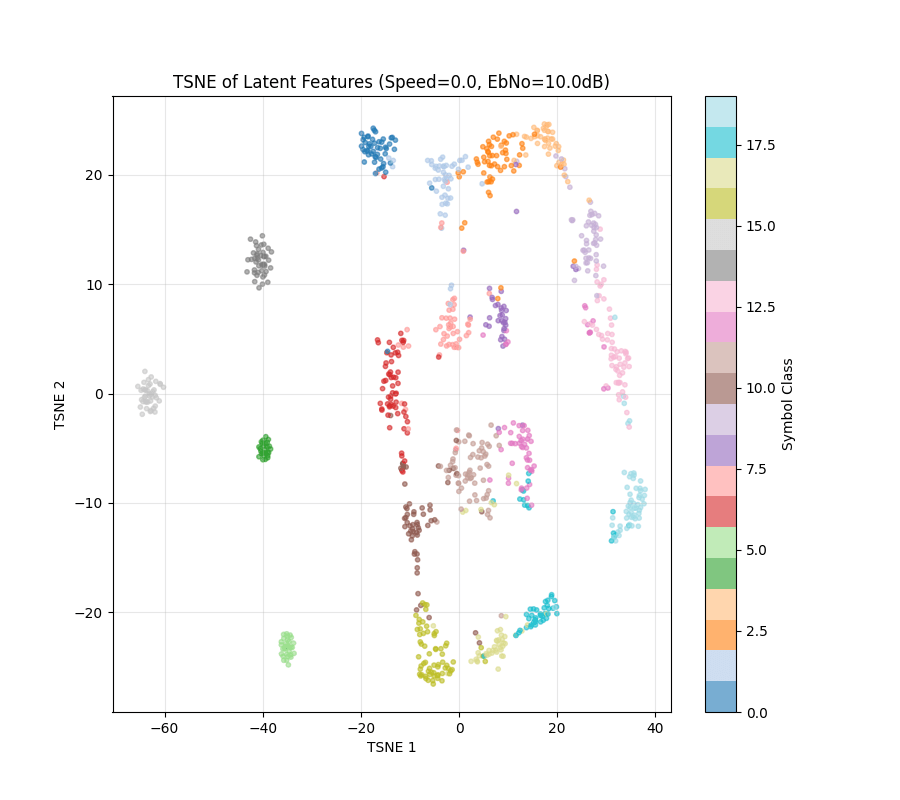
Experiments
Experiments
Metric to measure cluster similarity
Assume Clustered as Gaussians with
\mathcal{N} (\mu_A , \Sigma_A)
\mathcal{N} (\mu_B , \Sigma_B)
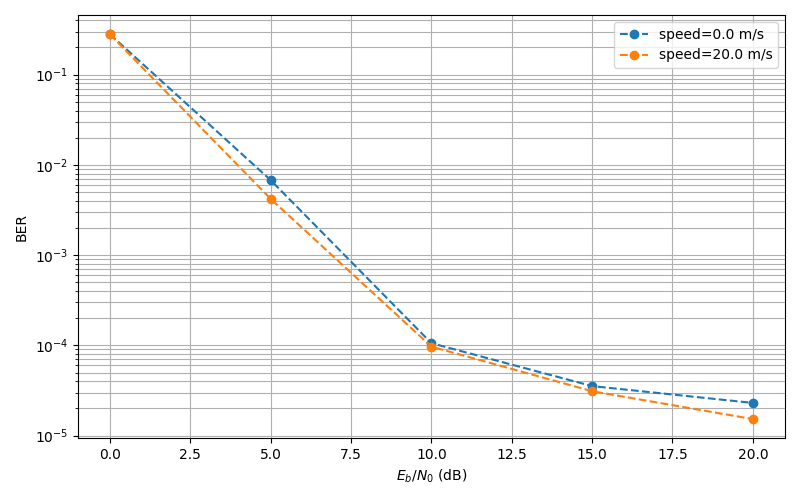
Centroid movement
ch. 0m/s
ch. 20m/s
\|\mu_A - \mu_B\|^2
Change in spread
\text{Tr}\left(\Sigma_A + \Sigma_B - 2(\Sigma_A \Sigma_B)^{1/2}\right)
Total
\|\mu_A - \mu_B\|^2
\text{Tr}\left(\Sigma_A + \Sigma_B - 2(\Sigma_A \Sigma_B)^{1/2}\right)
+
Experiments
Metric to measure cluster similarity
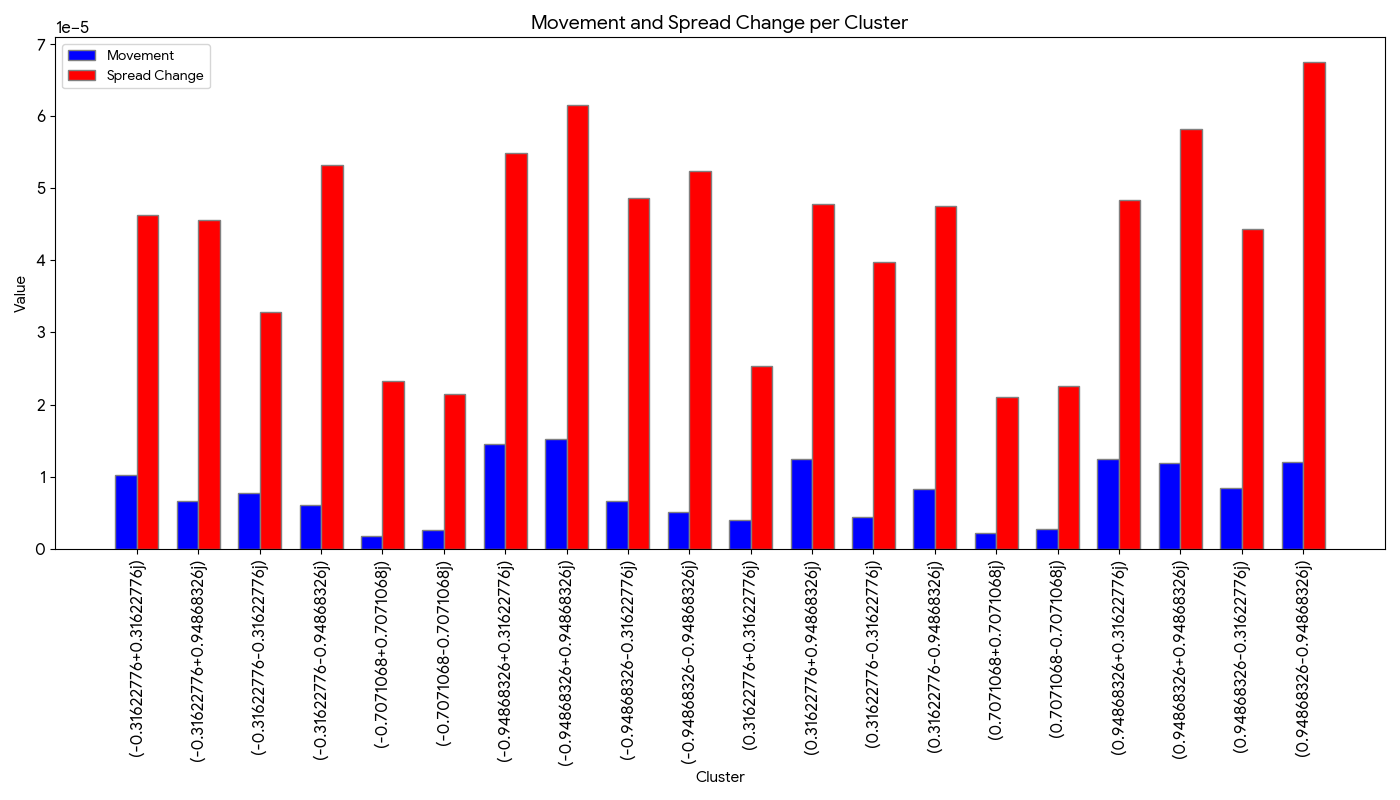
Experiments
Metric to measure cluster similarity
Tried on speed 80m/s
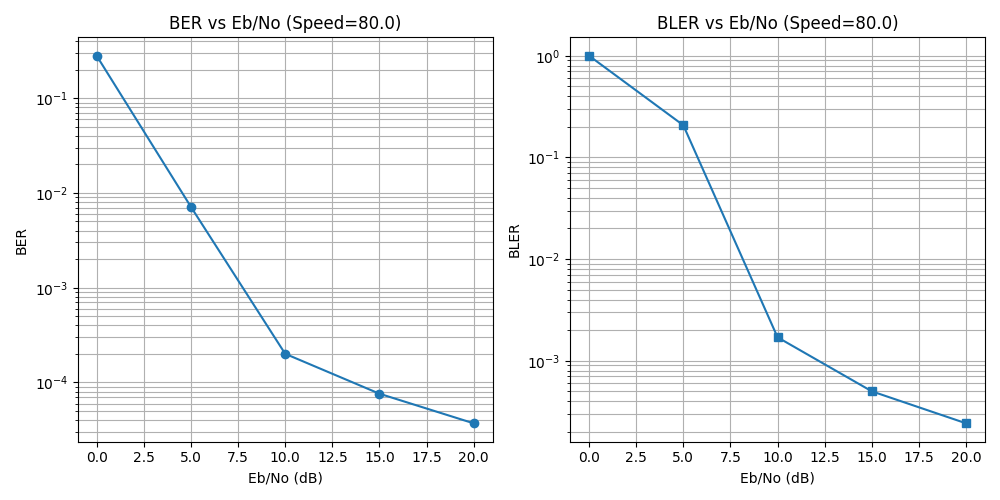
Experiments
Metric to measure cluster similarity
Tried on speed 80m/s
Experiments
What other parameters of the channel should be changed for us to observe a more drastic difference in performance?
Self-Supervised Learning Experiment
Self-Supervised Learning Experiment
Setting
Sp. 0
Cluster Centers mu_0
Cluster loss: L_ref
Self-Supervised Learning Experiment
Setting
Sp. 10
Cluster Centers mu_0
Cluster loss: L_ref
Sp. 0
Self-Supervised Learning Experiment
Setting
Sp. 10
Cluster Centers mu_0
Cluster loss: L_ref
Every N steps:
- Assign each point to its nearest
center
- Recompute cluster centeres
Self-Supervised Learning Experiment
Setting
Sp. 10
Cluster Centers mu_0
Cluster loss: L_ref
Every N steps:
- Assign each point to its nearest
center
- Recompute cluster centeres
Every step, update the following loss
\frac{1}{B} \sum_{i=1}^B ||z_i - \mu_{k_i}||^2 + \lambda \cdot \frac{1}{K(K-1)} \sum_{j \neq l} \frac{1}{|| \mu_j - \mu_l ||^2 + \epsilon}
Self-Supervised Learning Experiment
Setting
Sp. 10
Cluster Centers mu_0
Cluster loss: L_ref
Every N steps:
- Assign each point to its nearest
center
- Recompute cluster centeres
Every step, update the following loss
\frac{1}{B} \sum_{i=1}^B ||z_i - \mu_{k_i}||^2 + \lambda \cdot \frac{1}{K(K-1)} \sum_{j \neq l} \frac{1}{|| \mu_j - \mu_l ||^2 + \epsilon}
Note: Rate is NOT in the loss function; it is only measured
Self-Supervised Learning Experiment
Setting
Sp. 10
Cluster Centers mu_0
Cluster loss: L_ref
Every N steps:
- Assign each point to its nearest
center
- Recompute cluster centeres
Every step, update the following loss
\frac{1}{B} \sum_{i=1}^B ||z_i - \mu_{k_i}||^2 + \lambda \cdot \frac{1}{K(K-1)} \sum_{j \neq l} \frac{1}{|| \mu_j - \mu_l ||^2 + \epsilon}
Note: Rate is NOT in the loss function; it is only measured
Self-Supervised Learning Experiment
Setting
Sp. 10
Cluster Centers mu_0
Cluster loss: L_ref
Every N steps:
- Assign each point to its nearest
center
- Recompute cluster centeres
Every step, update the following loss
\frac{1}{B} \sum_{i=1}^B ||z_i - \mu_{k_i}||^2 + \lambda \cdot \frac{1}{K(K-1)} \sum_{j \neq l} \frac{1}{|| \mu_j - \mu_l ||^2 + \epsilon}
Stop iff:
L_{cont} \leq L_{ref} + \epsilon_{loss}
Self-Supervised Learning Experiment
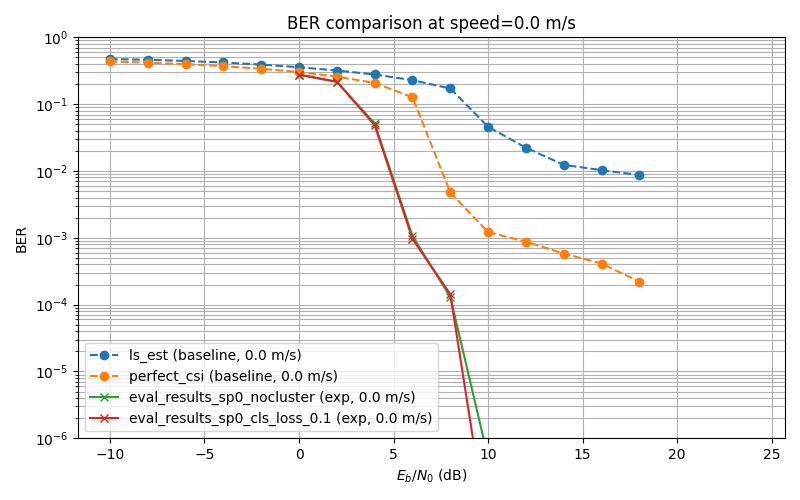
Self-Supervised Learning Experiment
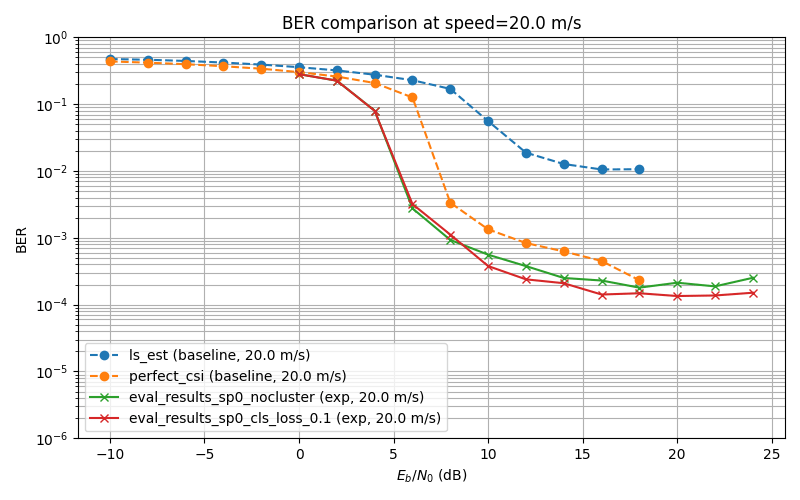
Self-Supervised Learning Experiment
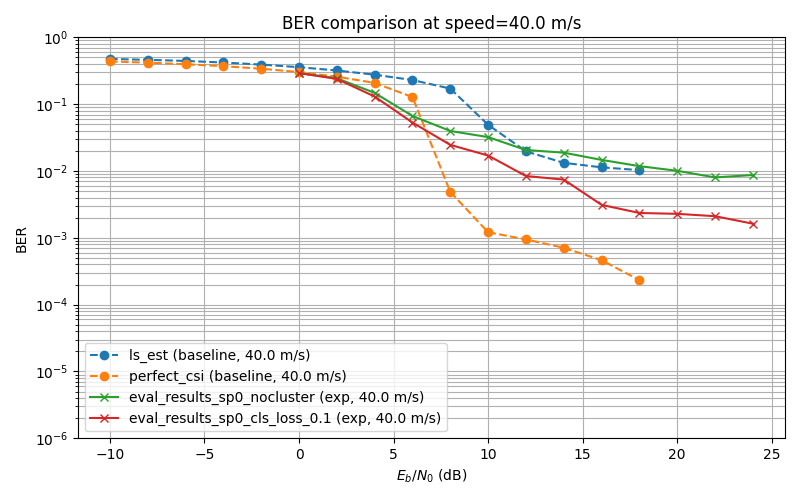
Self-Supervised Learning Experiment
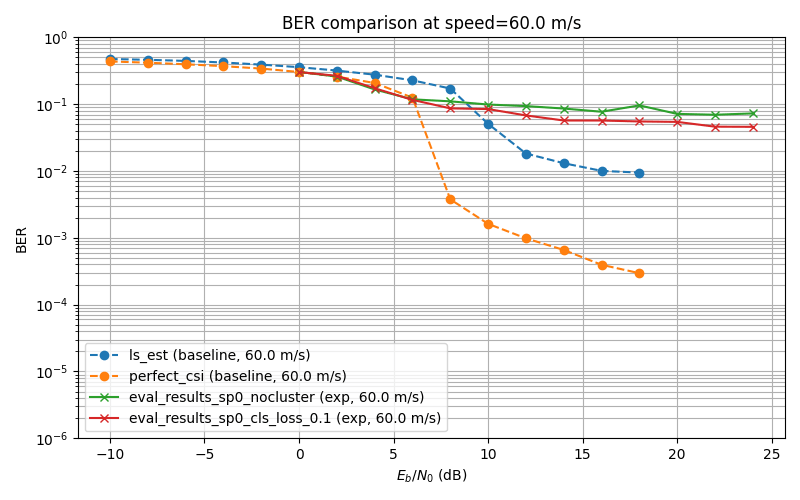
Self-Supervised Learning Experiment
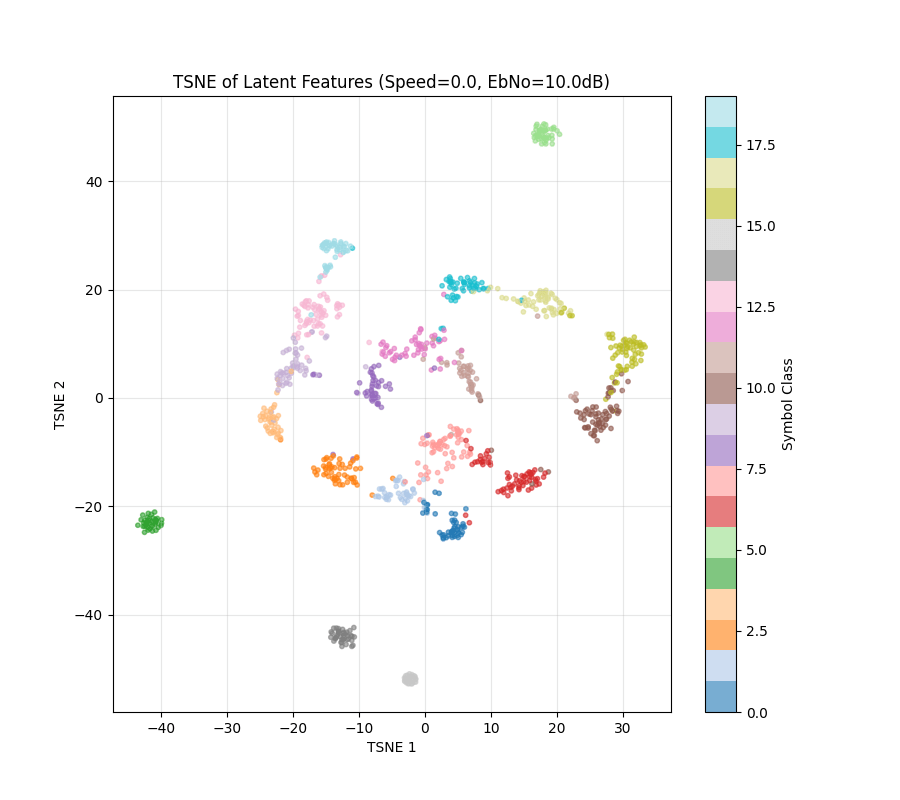
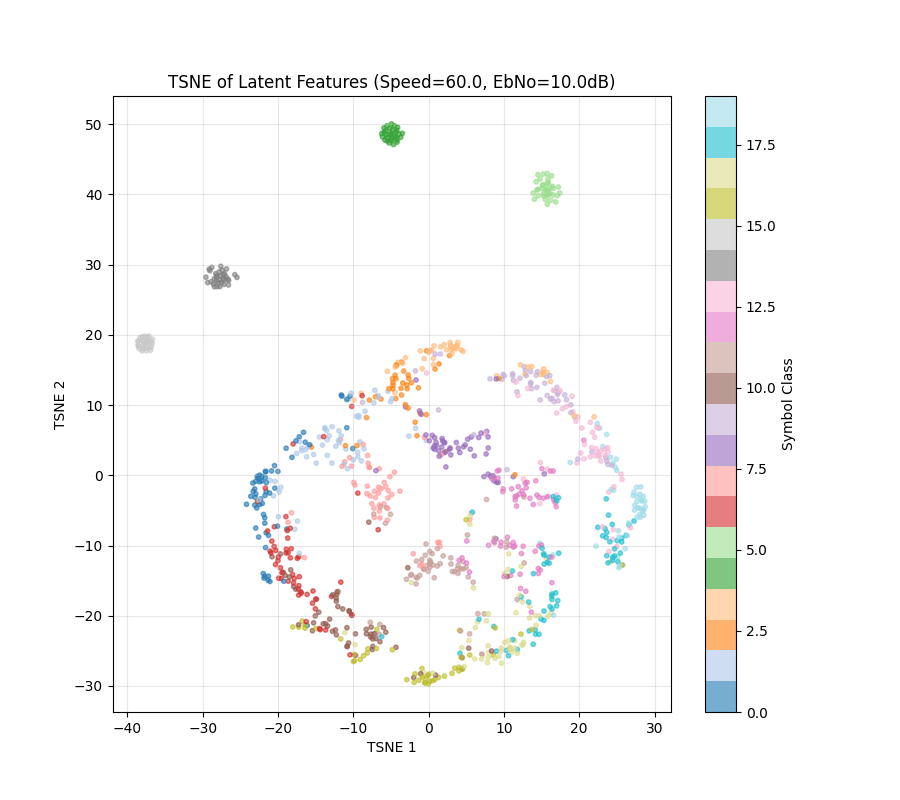
Now run SSL....
Self-Supervised Learning Experiment
Now run SSL....
Speed 0 to 20
Self-Supervised Learning Experiment
Now run SSL....
Speed 0 to 20
Before SSL
After SSL
Self-Supervised Learning Experiment
Now run SSL....
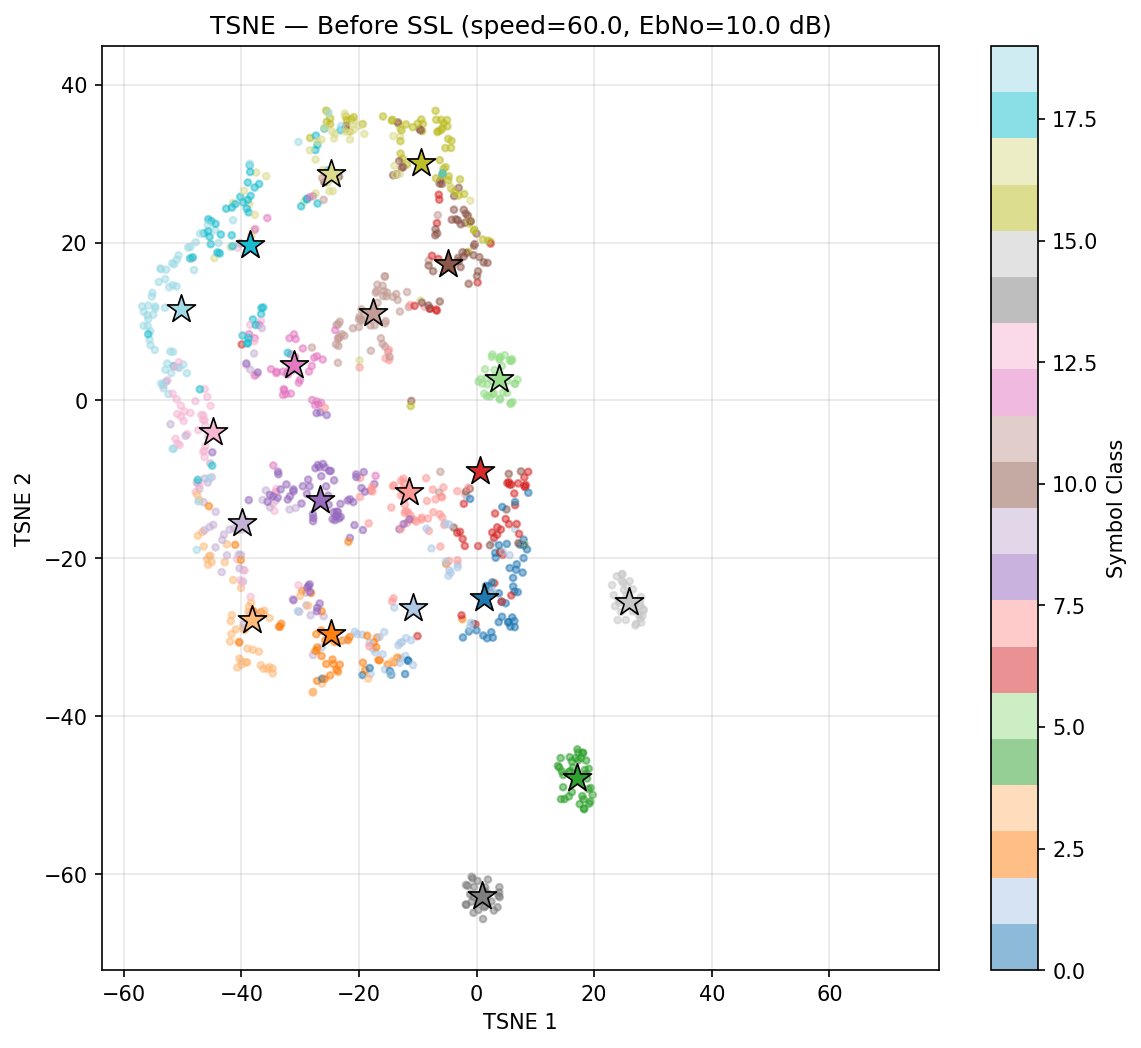
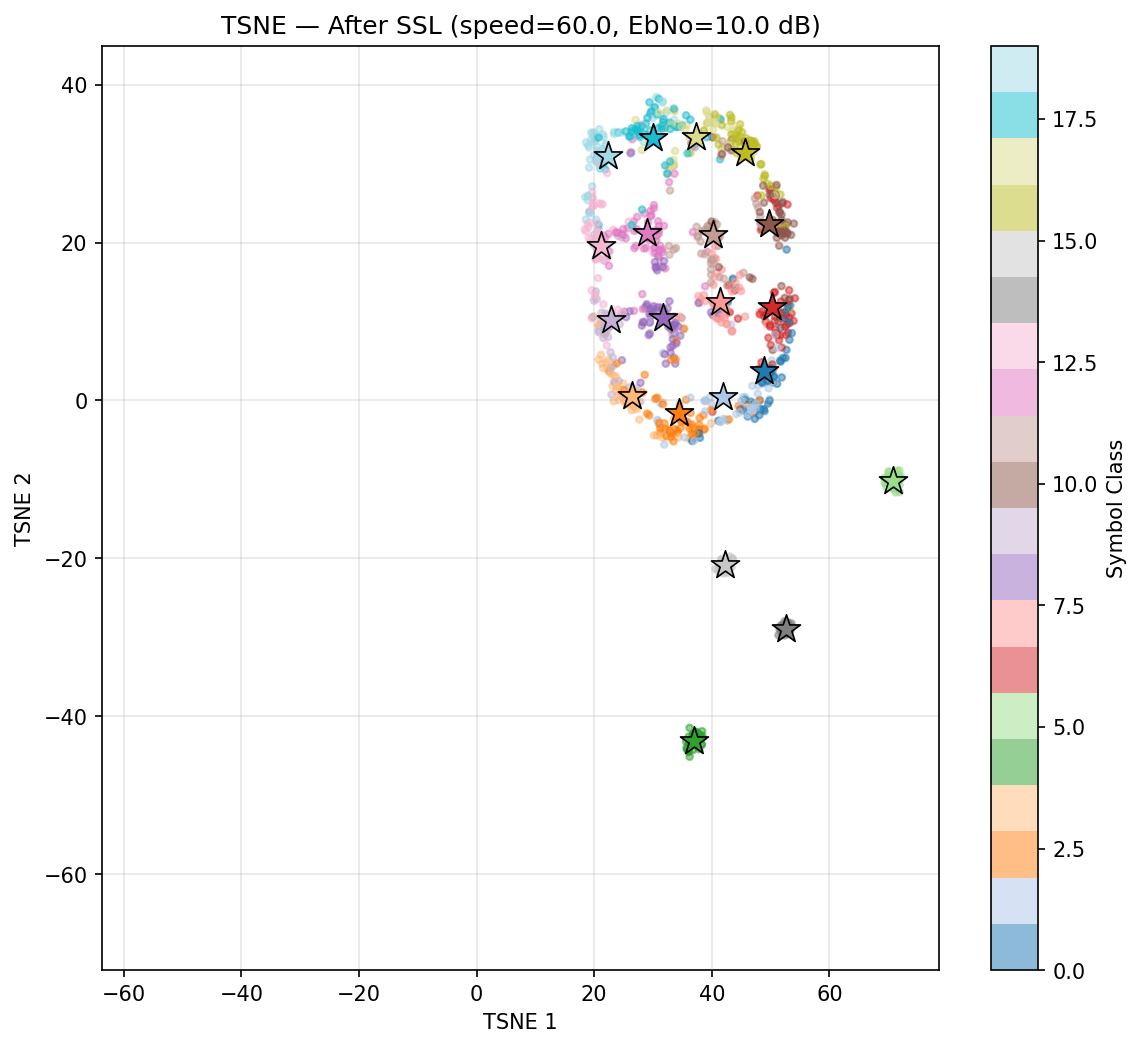
Speed 0 to 60
Before SSL
After SSL
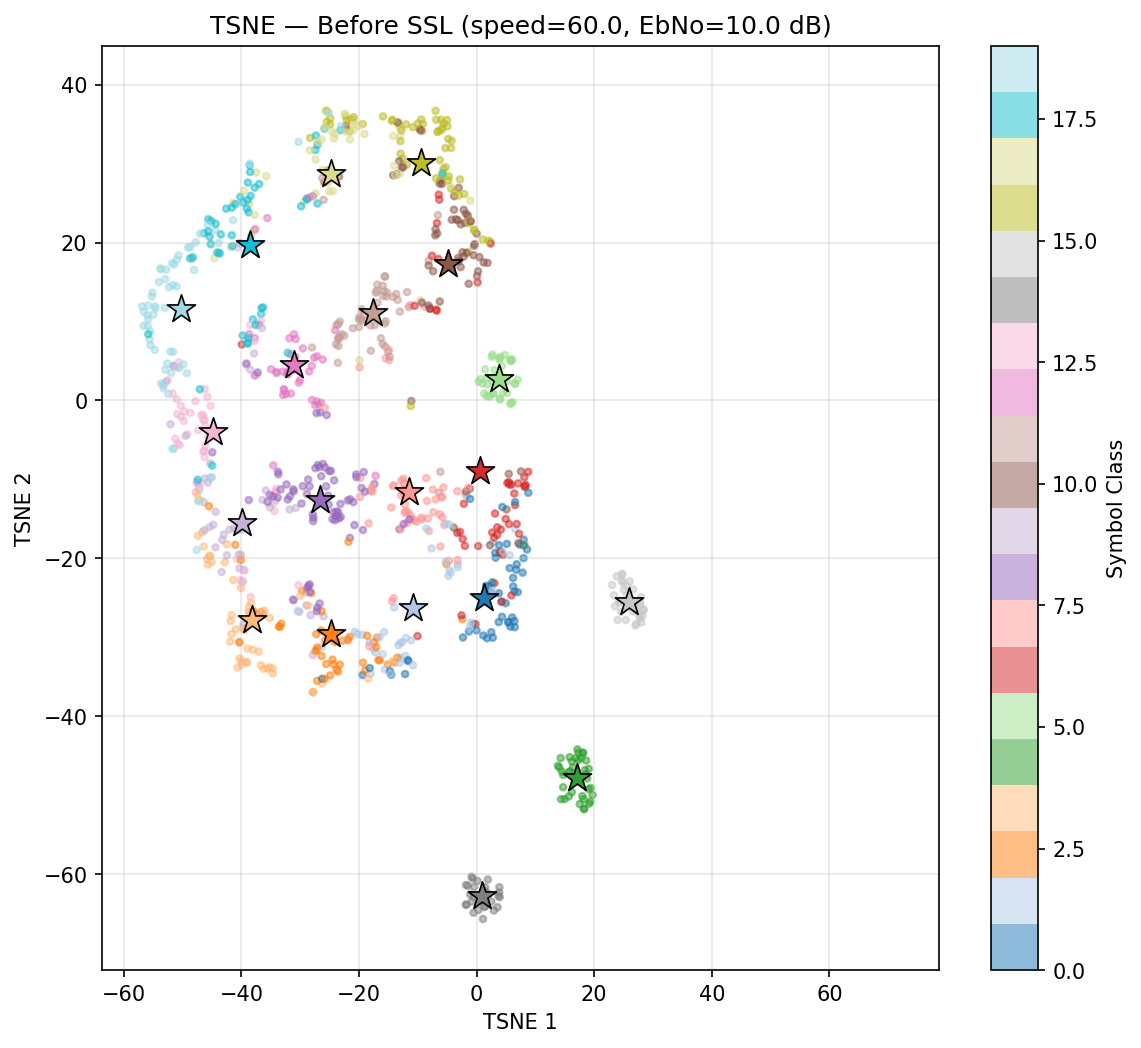
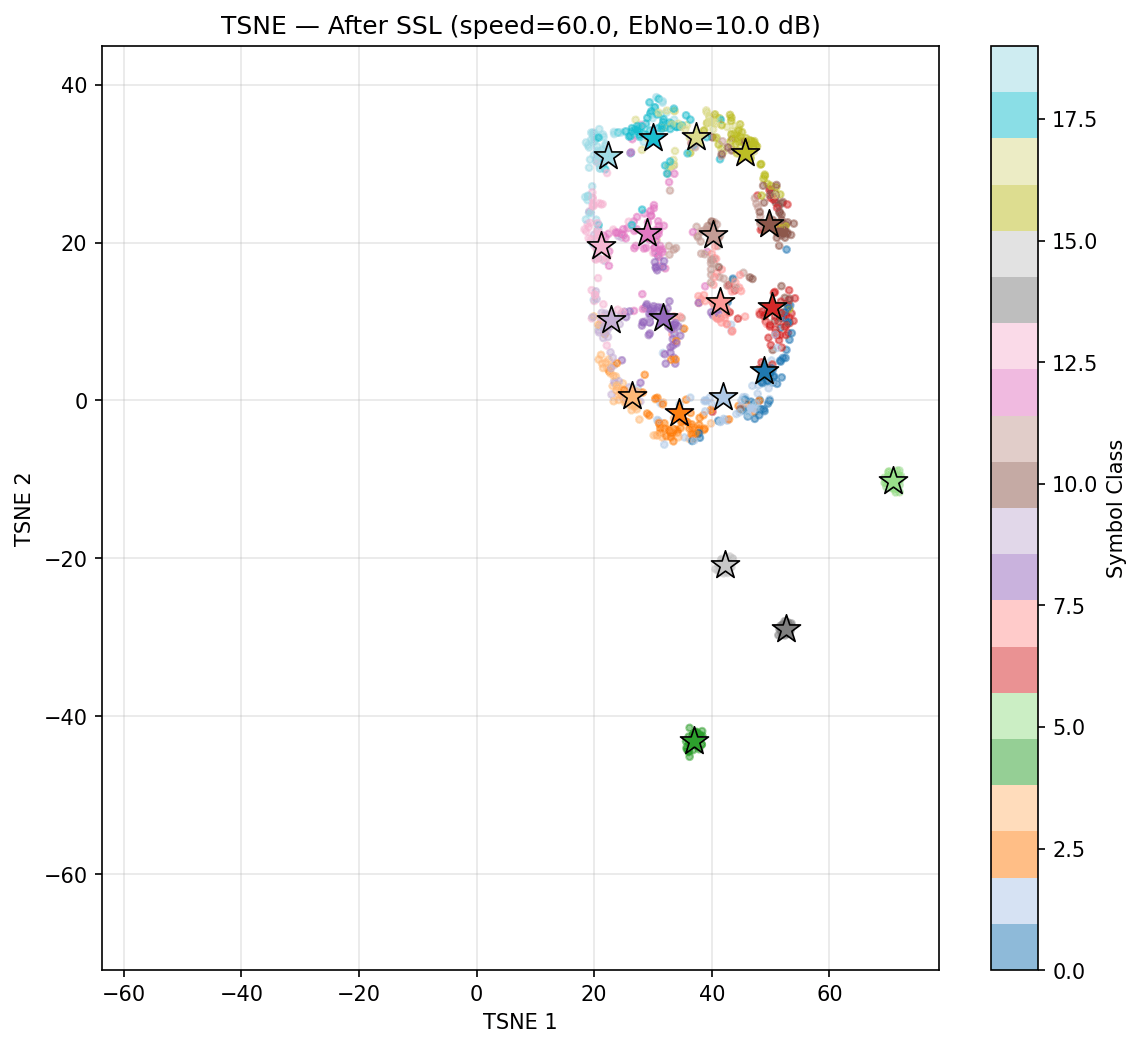
Self-Supervised Learning Experiment
Now run SSL....
However, the Bit Error Rate is not improving before and after SSL
Self-Supervised Learning Experiment
Now run SSL....
However, the Bit Error Rate is not improving before and after SSL
Thoughts:
1. Should we "pin" the cluster centers to the original cluster centers, as the model's decision boundary had no incentive to change?
2. "Few-shot" updates to the model after SSL? Any advantages over standard supervised learning approaches?
SSL Some more experiments
SSL Some more experiments
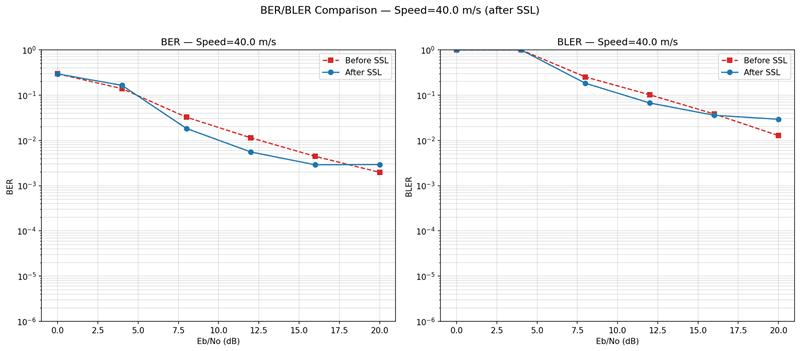
Corrected baseline plots
Reason for discrepancy in previous plots: The model's ber and baselines ber were evaluated with different step,s and the plotting function did not take into account that. Now I have updated the plotting function and am running all evaluations from a single config file, so that evaluations all share the same parameters
SSL Some more experiments
Corrected baseline plots
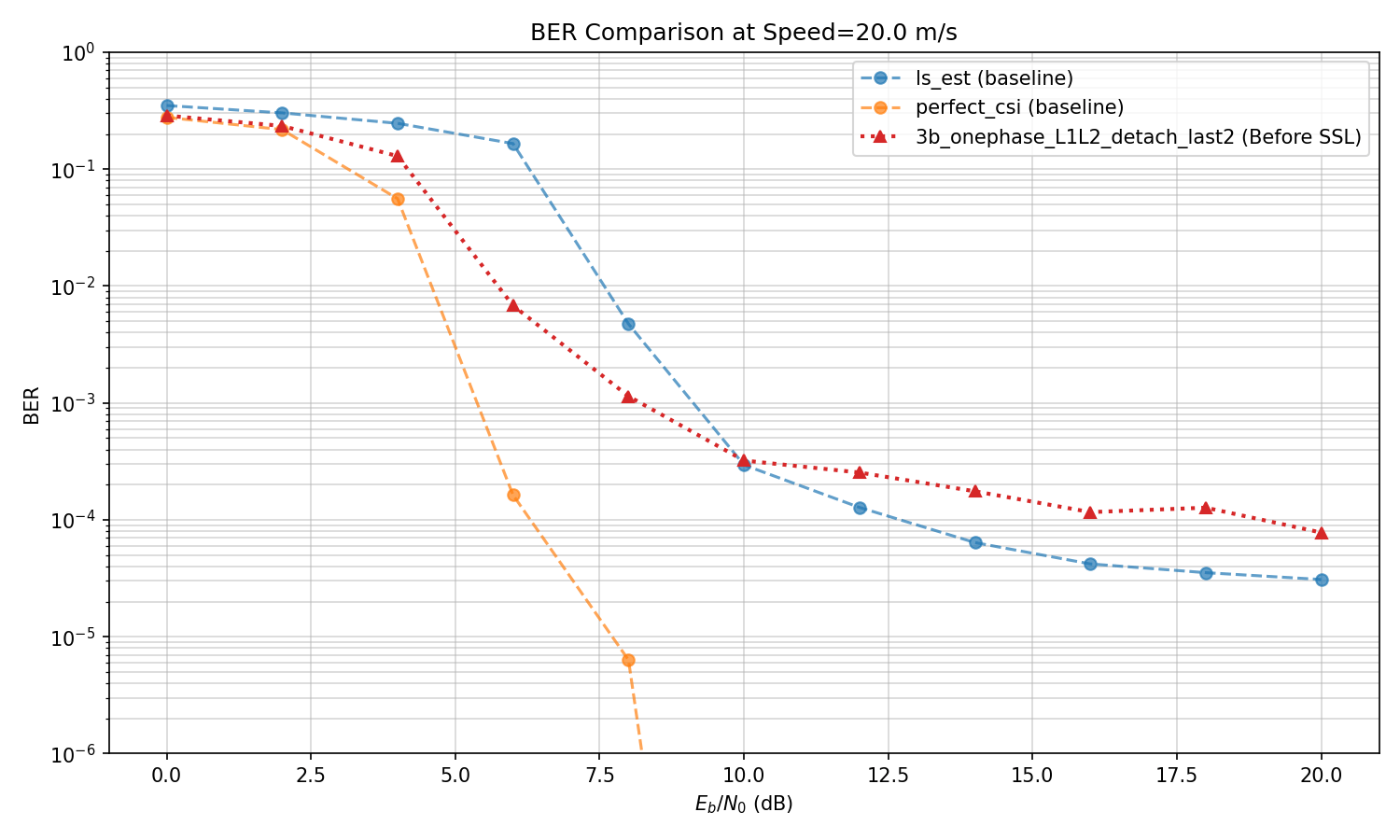
SSL Some more experiments
Corrected baseline plots
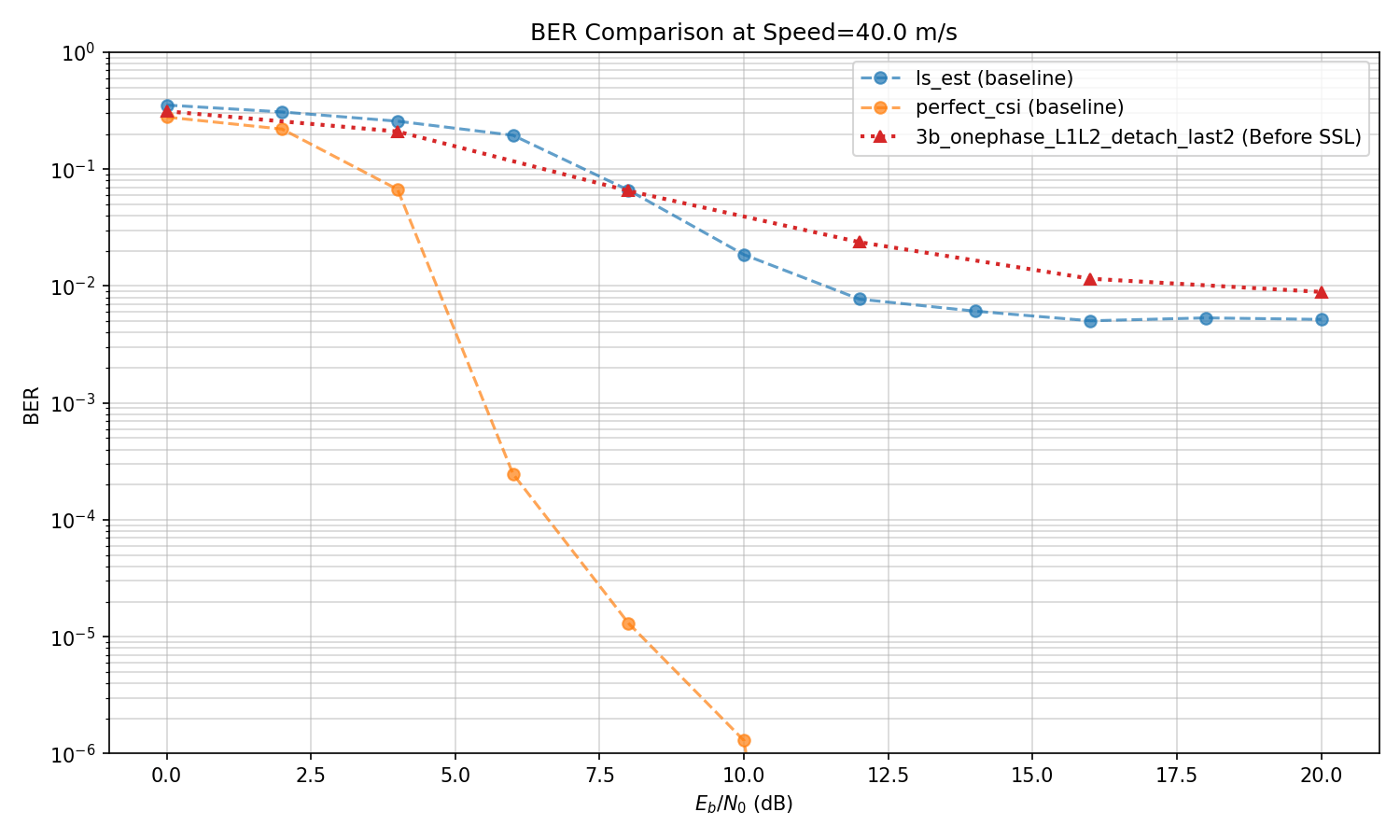
SSL Some more experiments
Corrected baseline plots
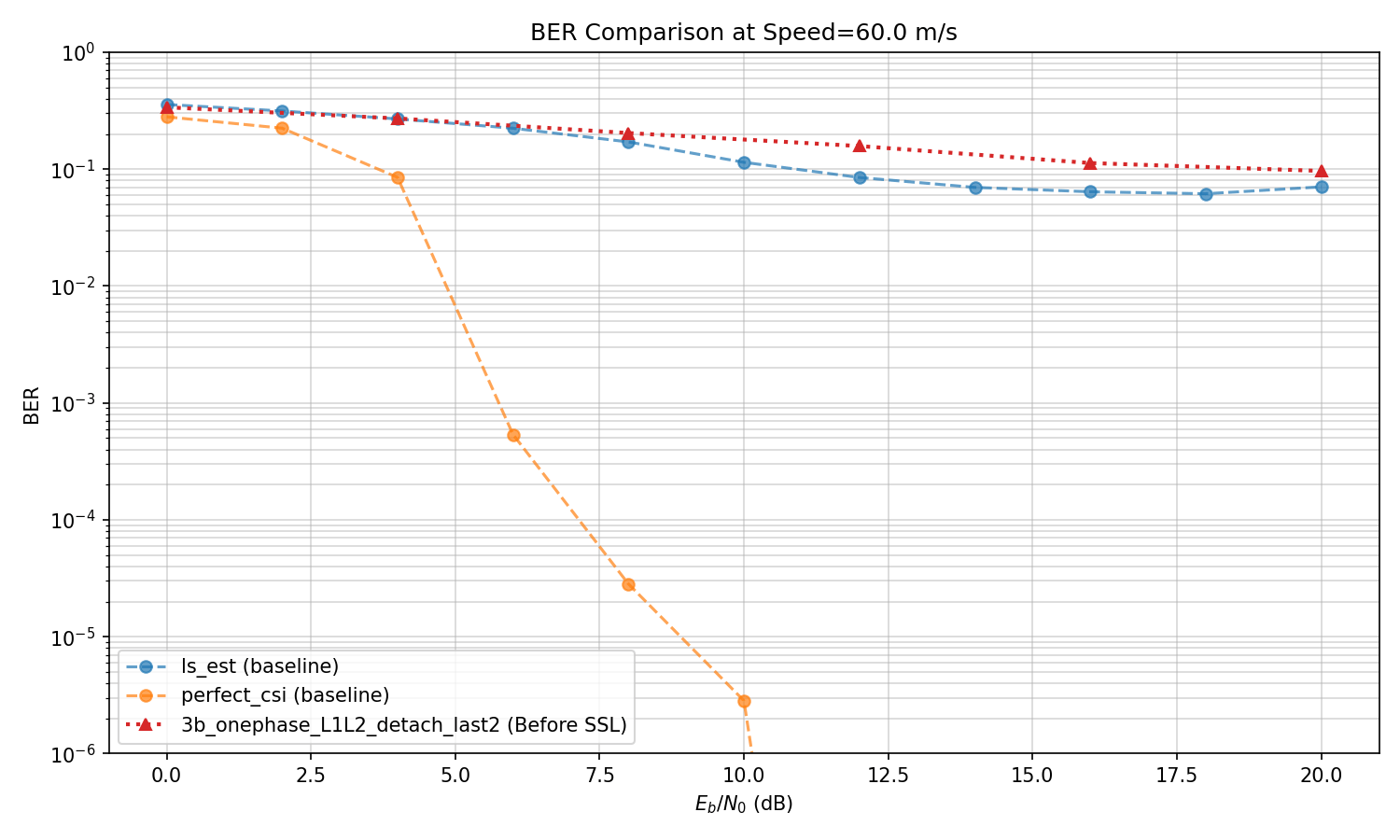
SSL Some more experiments
SSL Some more experiments
1: Baseline
Loss: Cluster + P-label
centroids updated through kmeans every 2 steps
LLRs
z
L1: Cluster-Loss
L2: Plabel Loss
SSL Some more experiments
SSL Some more experiments
1: Baseline
Loss: Cluster + P-label
centroids updated through kmeans every 2 steps
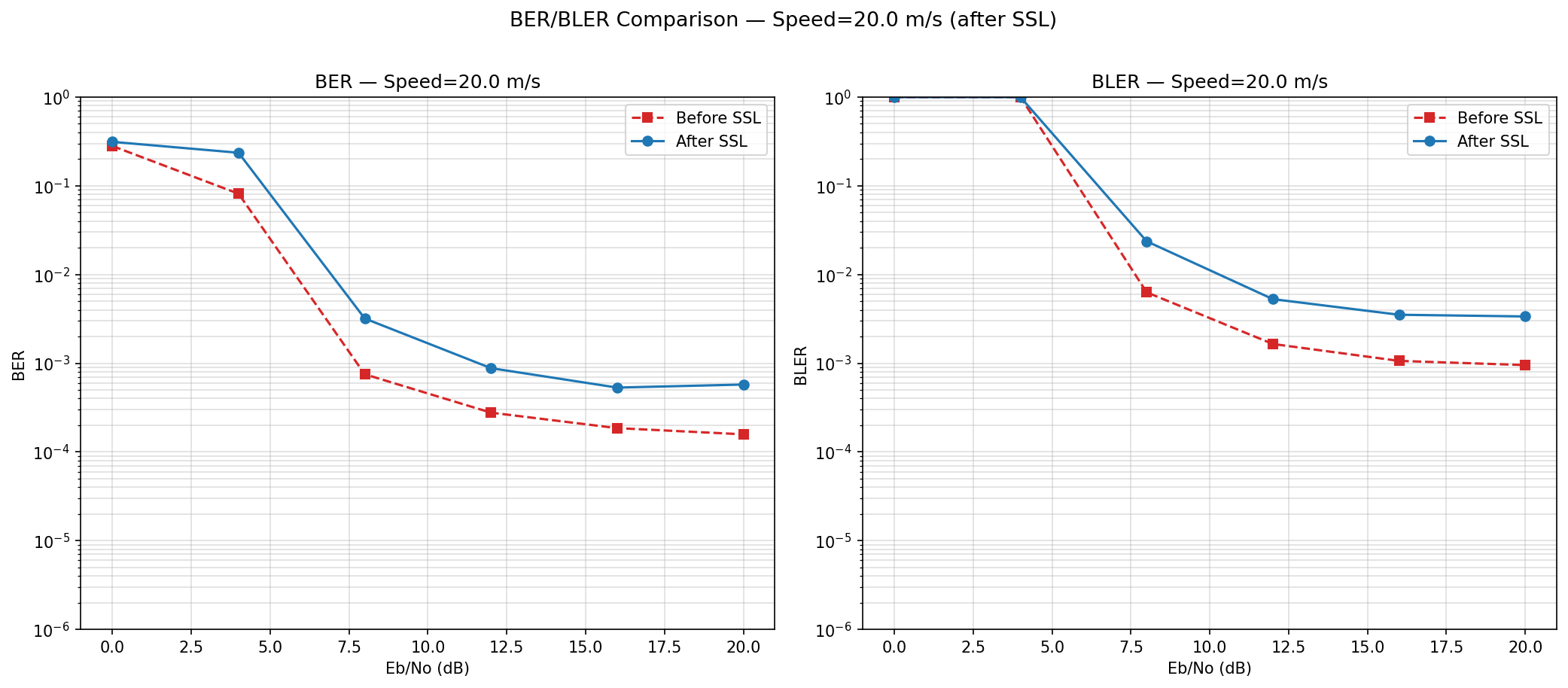
BER became slightly worse after training
SSL Some more experiments
SSL Some more experiments
1: Baseline
Loss: Cluster + P-label
centroids updated through kmeans every 2 steps
BER became slightly worse after training
Hypothesis: backbone updates shifted the clusters -> pseudo-labels became wrong -> training on wrong labels corrupted the backbone further.
SSL Some more experiments
SSL Some more experiments
1: Baseline
Loss: Cluster + P-label
BER became slightly worse after training
Hypothesis: backbone updates shifted the clusters -> pseudo-labels became wrong -> training on wrong labels corrupted the backbone further.
Soln: Break the feedback loop by detaching L2 gradients from the backbone, so L2 only updates the final classifier layer.
LLRs
z
L1: Cluster-Loss
L2: Plabel Loss
\nabla L_2
\nabla L_1
Stop gradient
SSL Some more experiments
SSL Some more experiments
3a: L1 + L2 (detach)
Loss: Cluster + P-label
BER became slightly worse after training
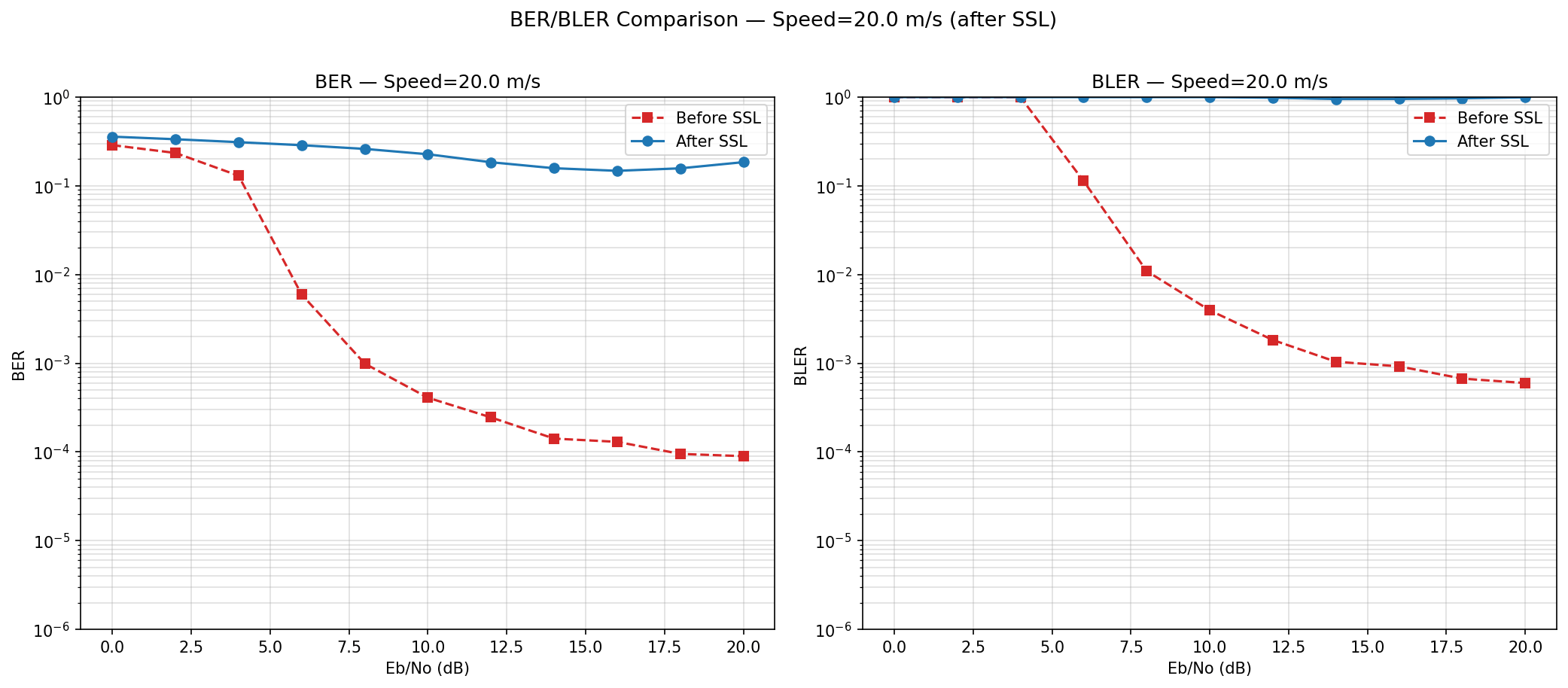
Inference still degrades
L1 might affect abstract features already learnt when we update the full backbone. Update only the latter layers
SSL Some more experiments
SSL Some more experiments
3b: L1 (update only last layers) + L2 (detach)
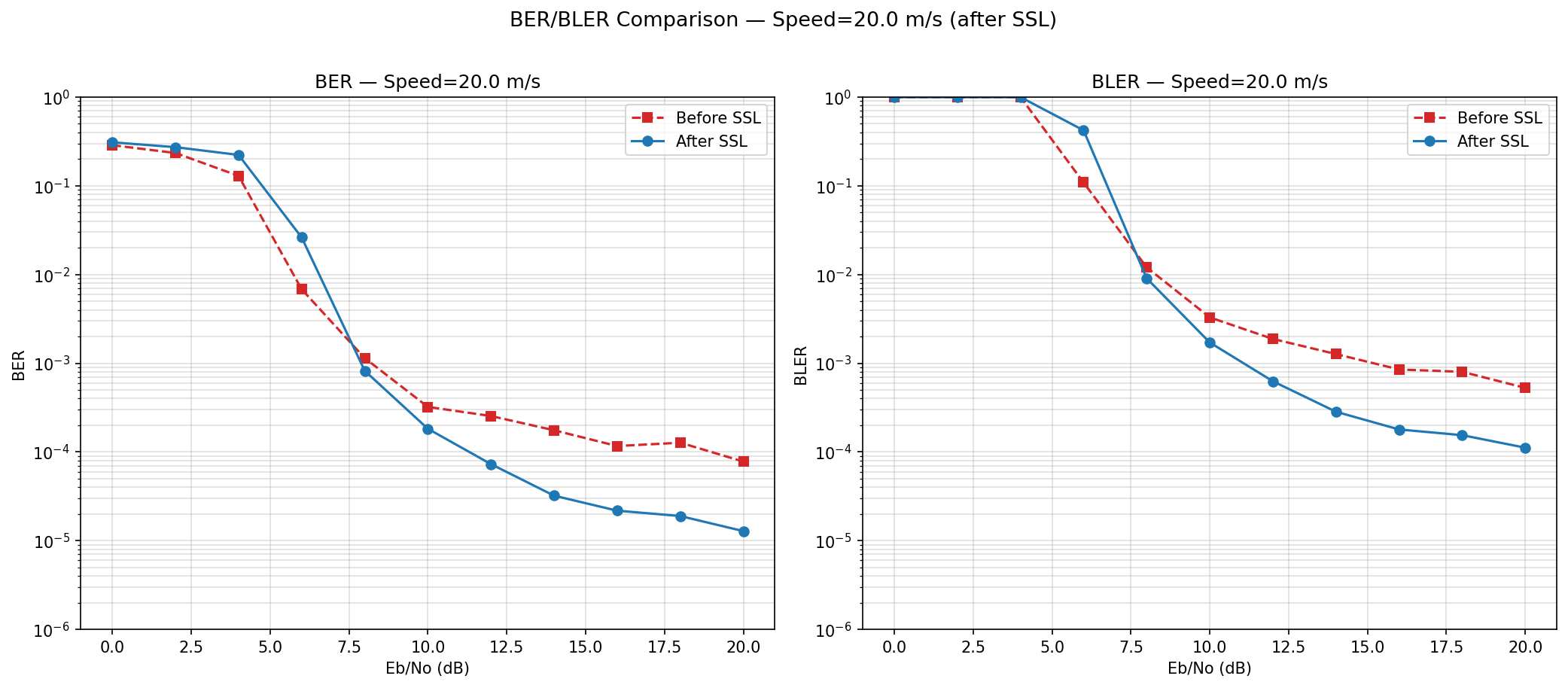
loss that modifies the full backbone based on clustering (L1) tends to be harmful.
What if we used only L2? How much effect does only using L2 have?
SSL Some more experiments
SSL Some more experiments
4a: Backbone frozen L2 (detach)
Before and After SSL curves are identical
Inference: We *MUST* update the backbone for gains, however too much cluster shift is causing us harms
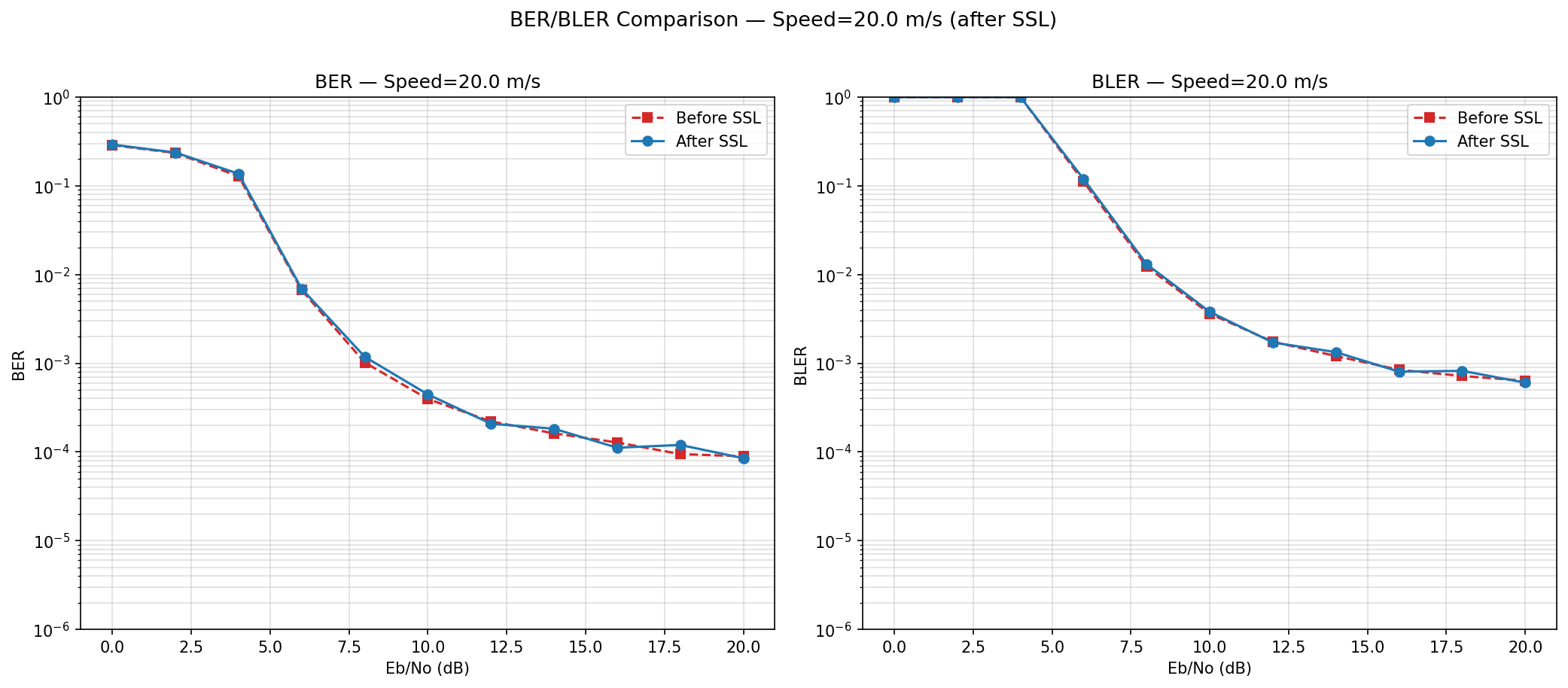
SSL Some more experiments
SSL Some more experiments
5a: Alternative Loss, using entropy (Minimized the entropy of predictions)
Before and After SSL curves are identical
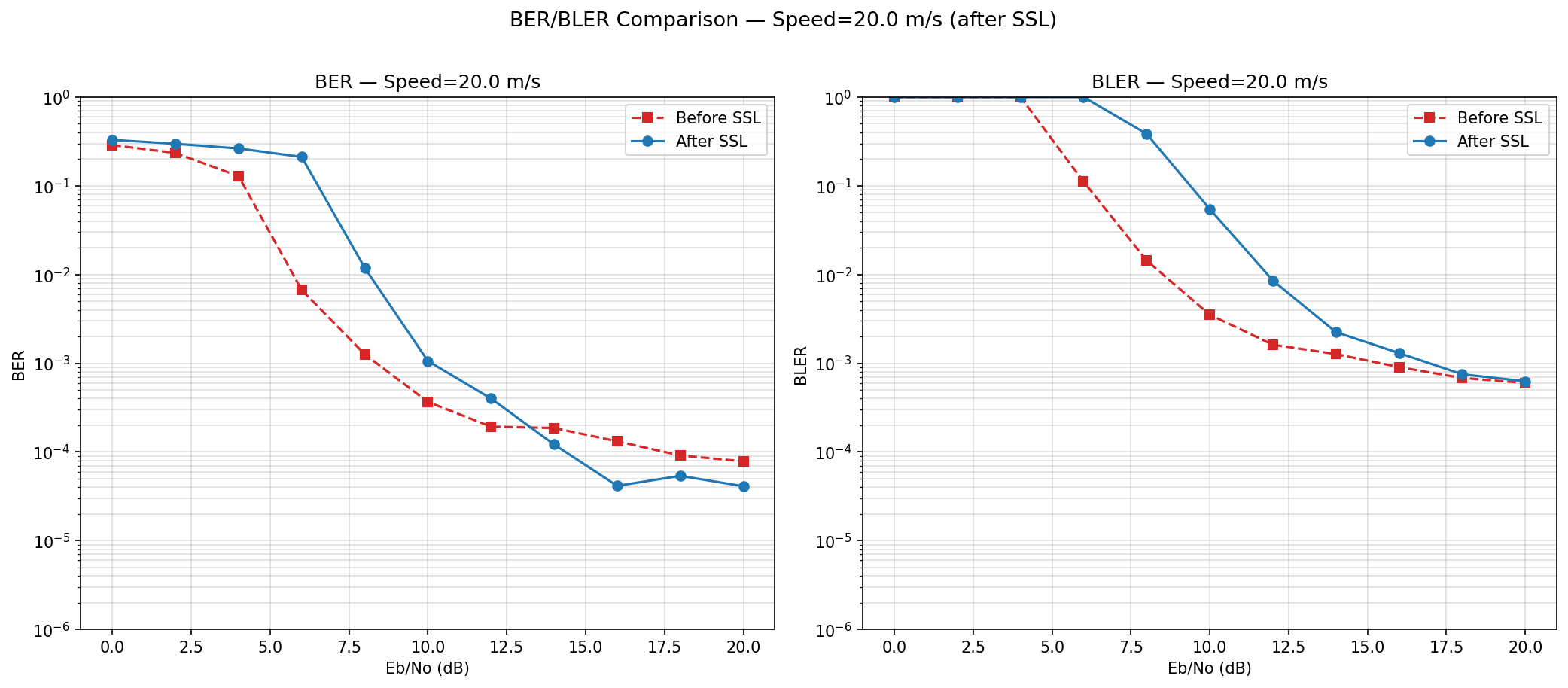
Motivation: Saw some papers that used Entropy as a common objective for test time adaptation
SSL Some more experiments
SSL Some more experiments
Based on the experiments, best improvement till now:
3b: L1 (update only last layers) + L2 (detach)
However, How does it compare to baselilnes?
SSL Some more experiments
SSL Some more experiments
Based on the experiments, best improvement till now:
3b: L1 (update only last layers) + L2 (detach)
However, How does it compare to baselilnes?
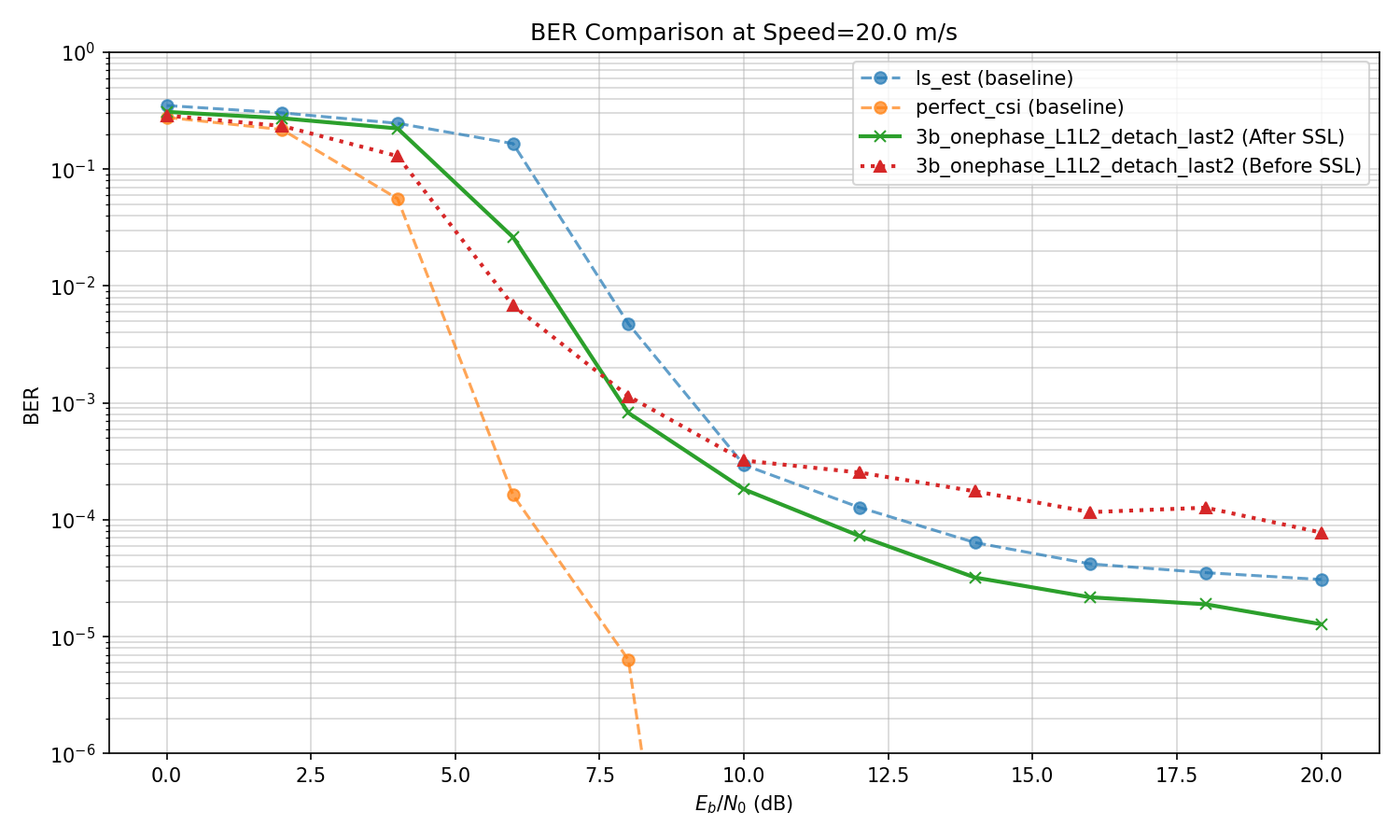
SSL Some more experiments
SSL Some more experiments
Miss classification rate (Before SSL) [sp. 20]
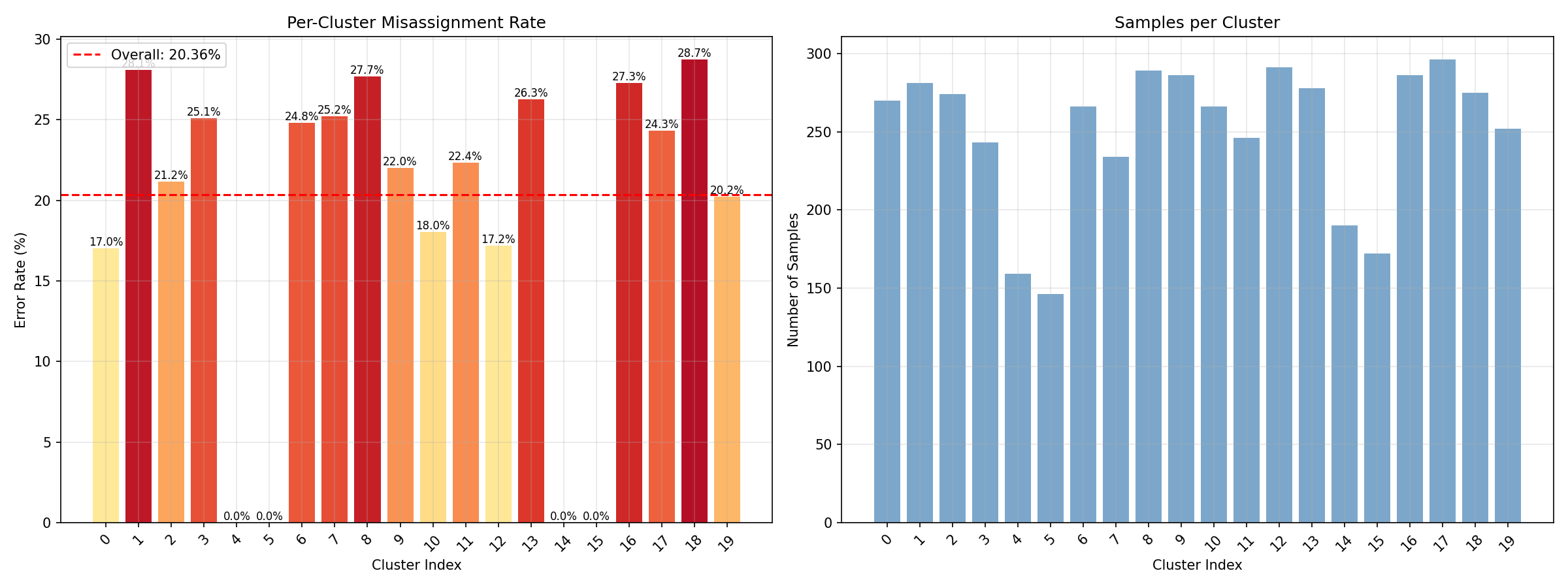
SSL Some more experiments
SSL Some more experiments
Miss classification rate (Before SSL) [sp. 20]
SSL Some more experiments
SSL Some more experiments
Miss classification rate (Before SSL) [sp. 40]
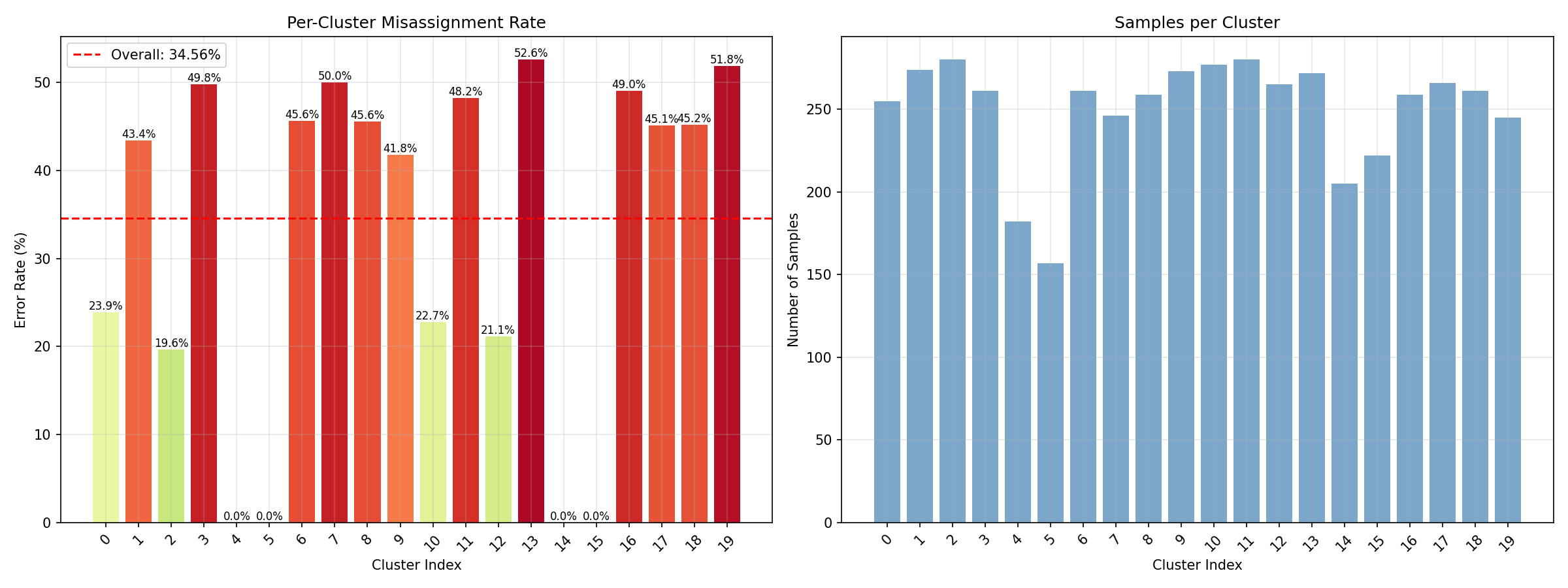
SSL Some more experiments
SSL Some more experiments
Miss classification rate (Before SSL) [sp. 60]
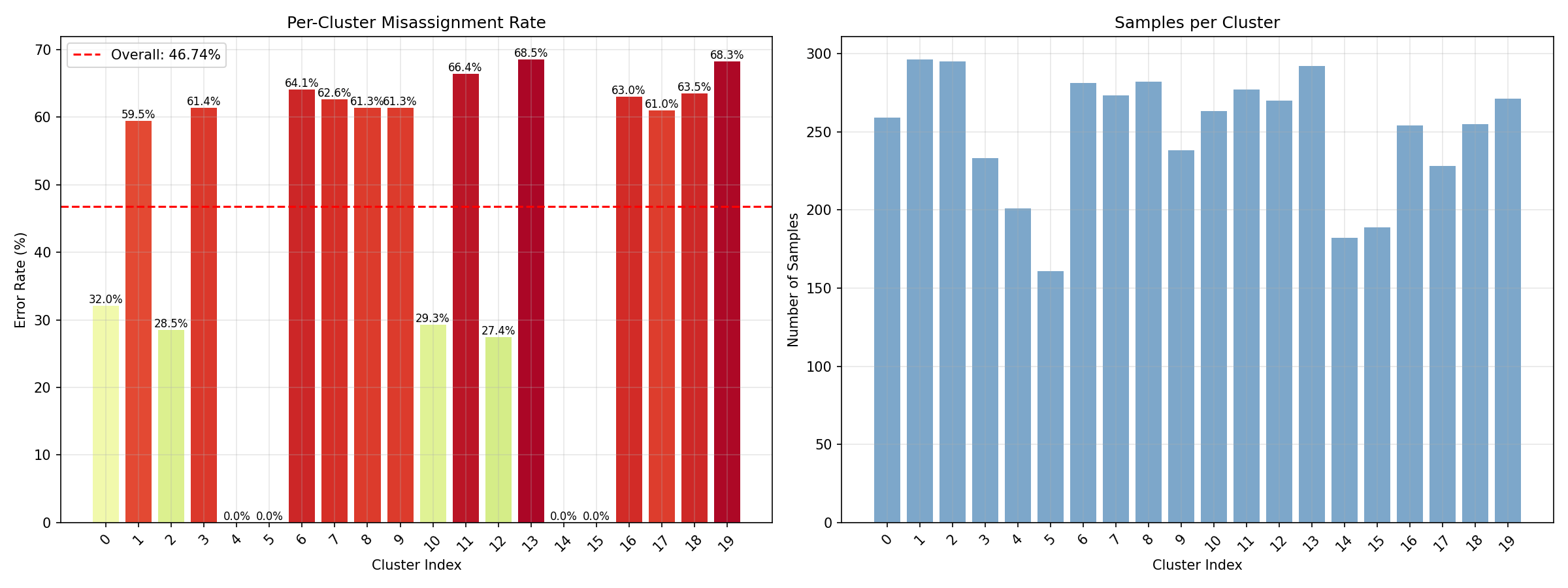
SSL Some more experiments
SSL Some more experiments
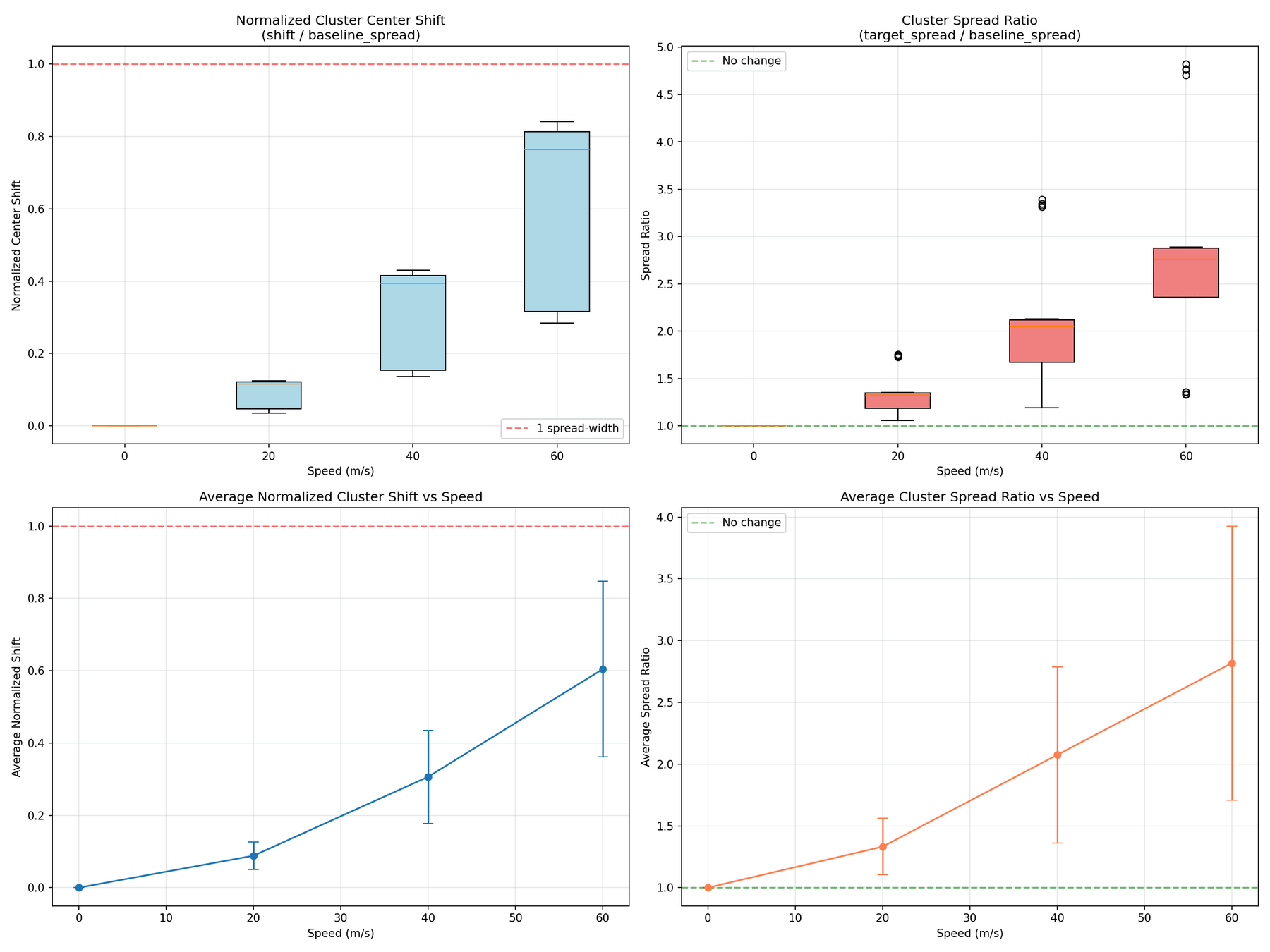
Cluster Shifts (Average)
Text
SSL Some more experiments
SSL Some more experiments
Cluster Shifts (Average)
Speed 20.0 m/s (relative to speed=0):
Average normalized shift: 0.088 (spread-widths)
Average spread ratio: 1.332
→ Clusters expanded by 33.2%
Speed 40.0 m/s (relative to speed=0):
Average normalized shift: 0.307 (spread-widths)
Average spread ratio: 2.075
→ Clusters expanded by 107.5%
Speed 60.0 m/s (relative to speed=0):
Average normalized shift: 0.604 (spread-widths)
Average spread ratio: 2.818
→ Clusters expanded by 181.8%
SSL Some more experiments
SSL Some more experiments
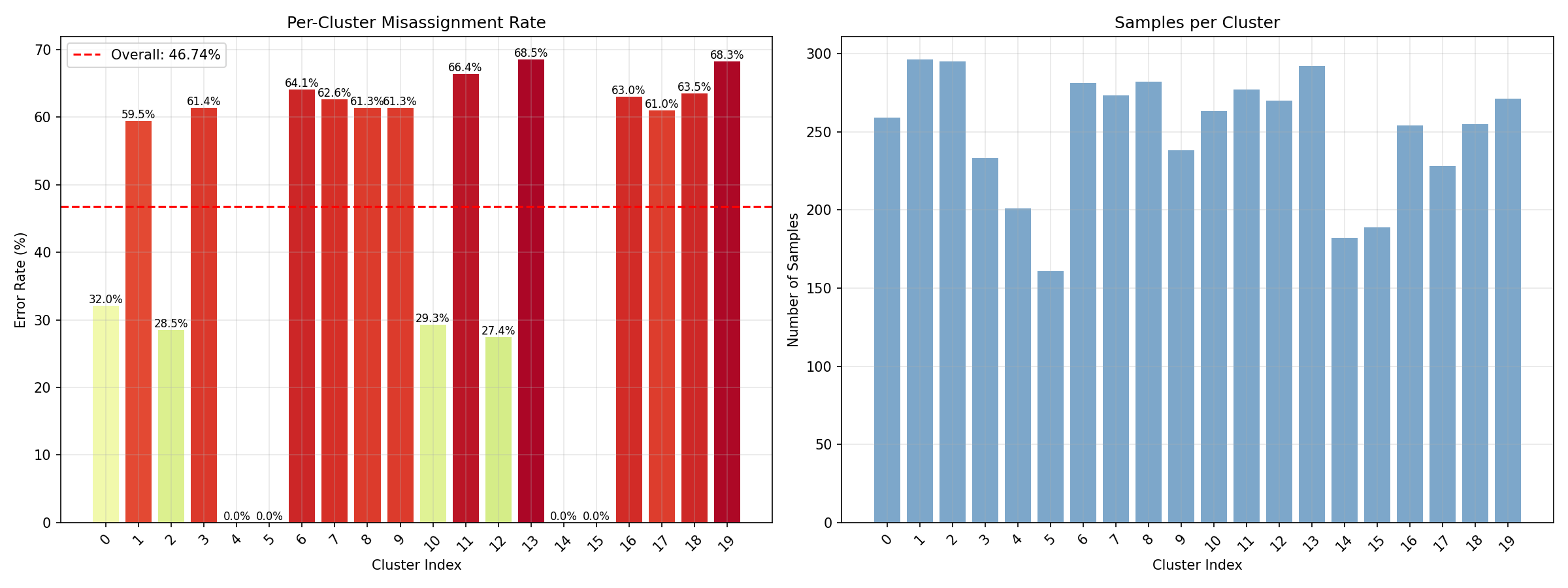
Miss classification rate (Before SSL) [sp. 40]
SSL Some more experiments
SSL Some more experiments
Miss classification rate (Before SSL)
Varying Channels
Varying Channels
TDL-D channel,
test on various values of delay spread
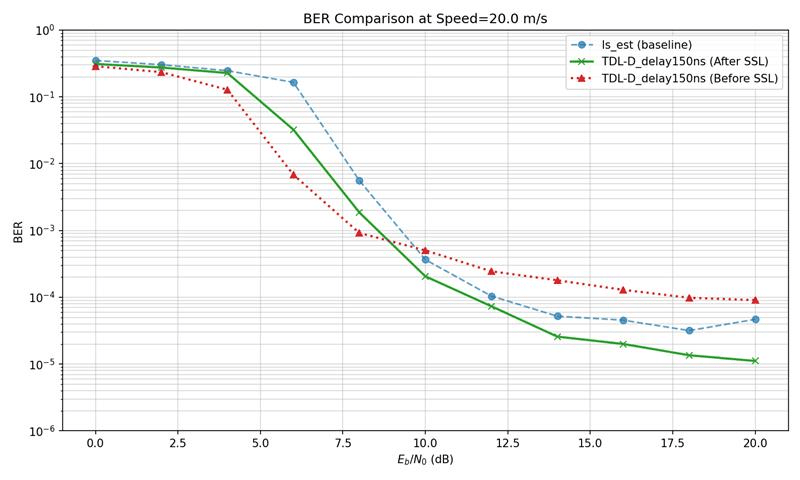
Delay spread : 150ns
Speed: 0->20
Varying Channels
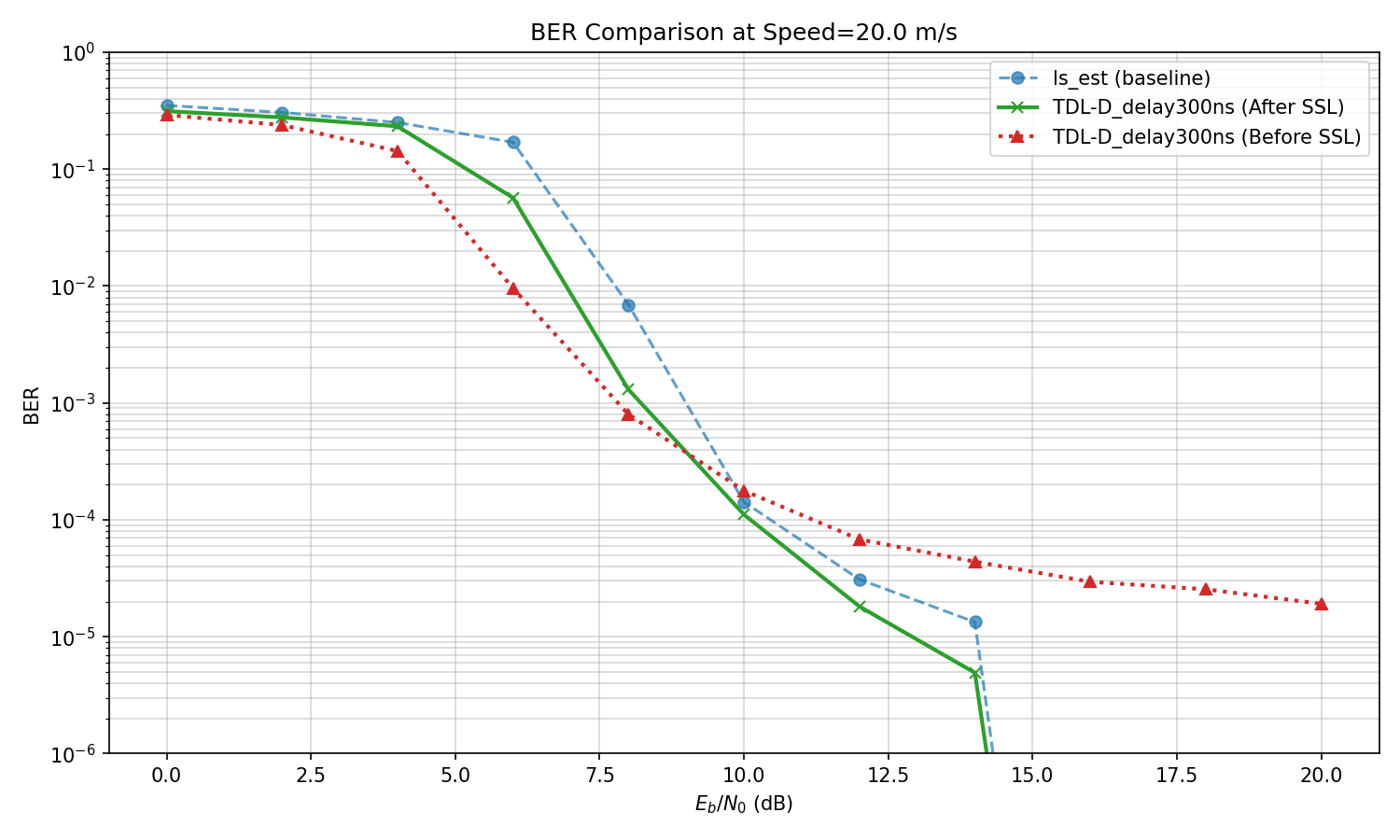
TDL-D channel,
test on various values of delay spread
Delay spread : 300ns
Speed: 0->20
Varying Channels
TDL-D channel,
test on various values of delay spread
Delay spread : 700ns
Speed: 0->20
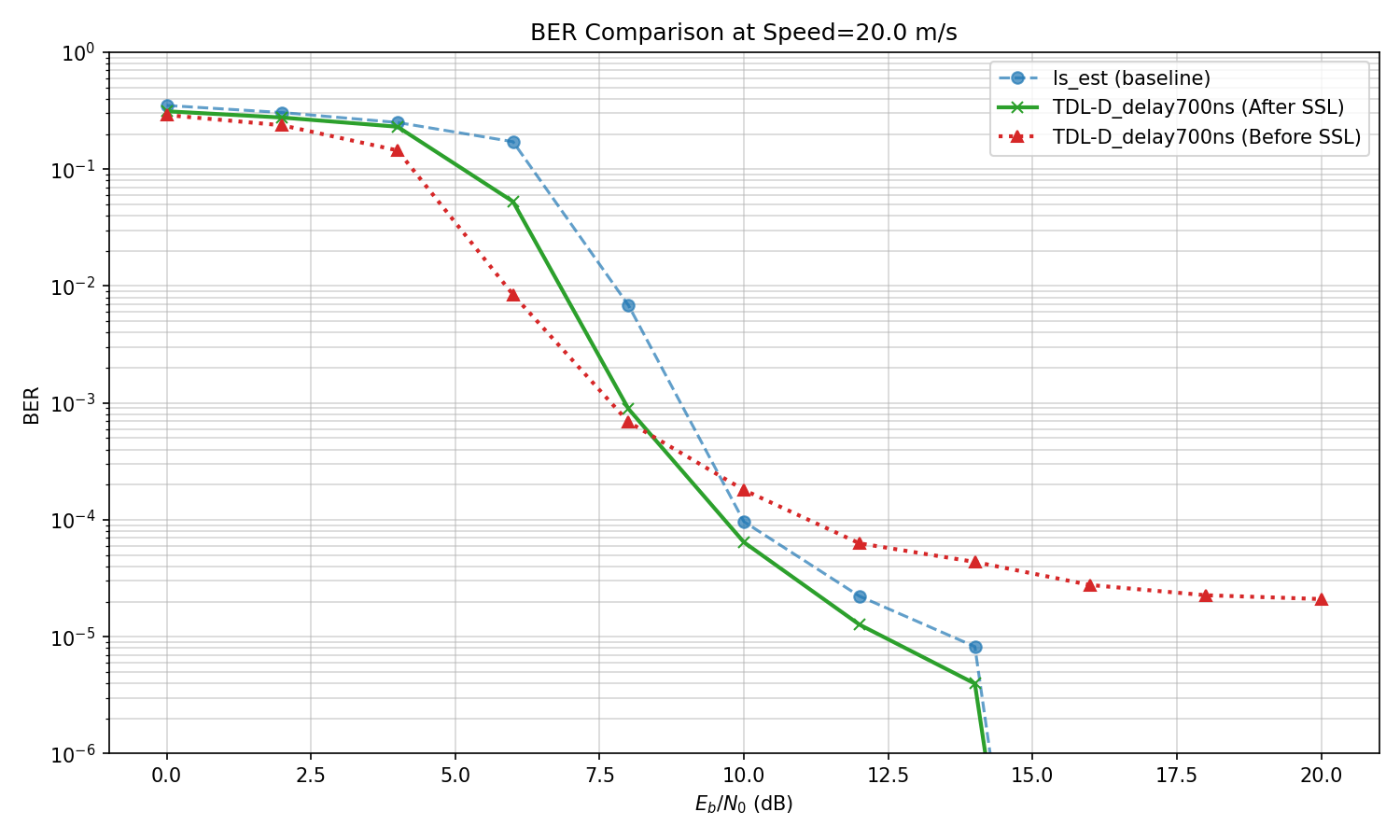
Varying Channels
TDL-D channel,
test on various values of delay spread
If I change channel type to D->A,
Everything breaks and SSL does not help
Speed: 0->20
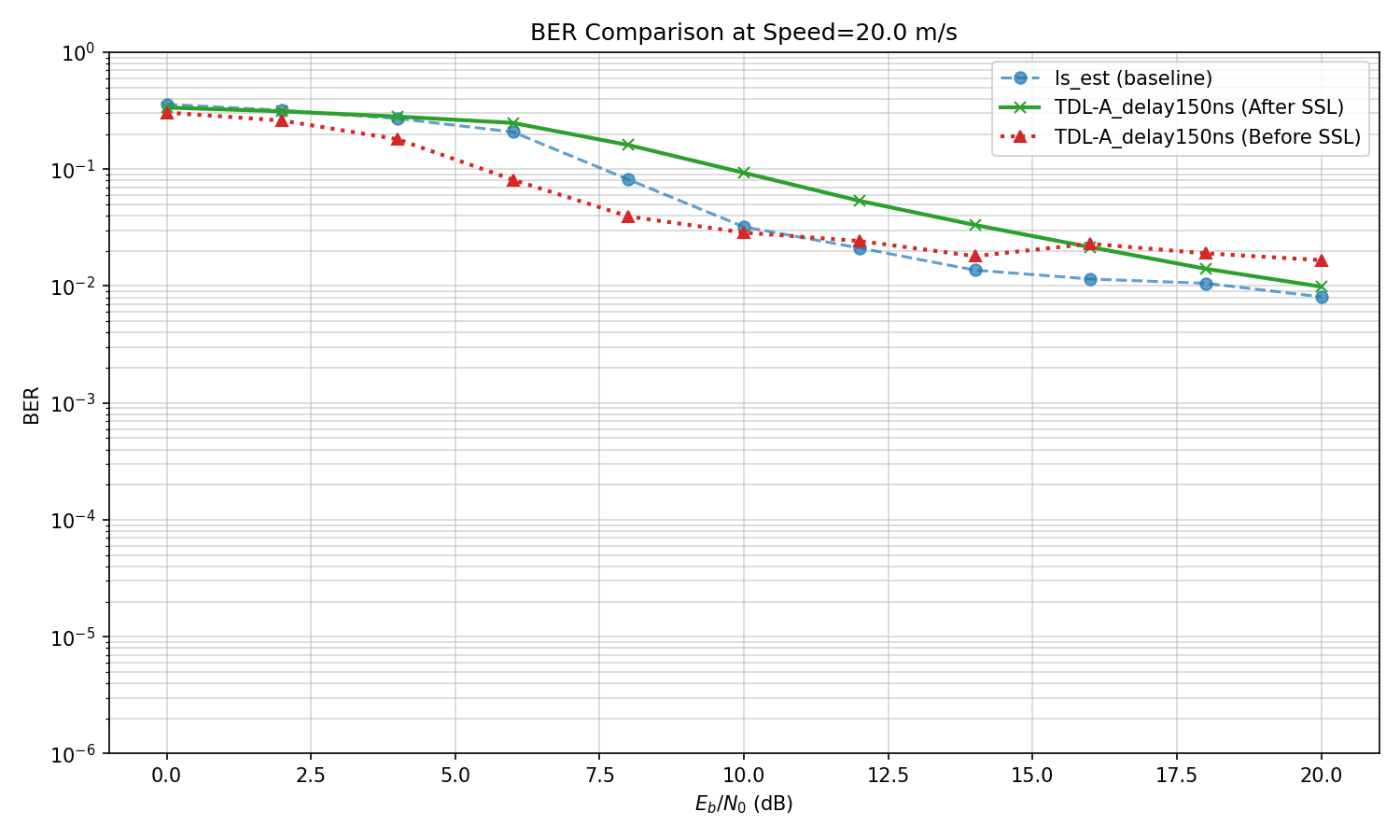
Varying Channels
TDL-D channel,
test on various values of delay spread
Next step:
- Understand when SSL works?
- Run an array of experiments by varying
1. Speed
2. Delay spread
3. Channel type
Independently
- Look at misclassification rate and relative cluster movement to see if we can say if SSL can fix or not
Varying Channels
Next step:
- Understand when SSL works?
- Run an array of experiments by varying
1. Speed
2. Delay spread
3. Channel type
Varying Channels
Next step:
- Understand when SSL works?
- Run an array of experiments by varying
1. Speed
2. Delay spread
3. Channel type
- Most of the times when the model type changes, the SSL Fails
Varying Channels
- Most of the times when the model type changes, the SSL Fails
- Looked at Gain: BER at highest ebno before SSL/After SSL, If the SSL is working we can expect it to be above 1
Before
After
Varying Channels
- Most of the times when the model type changes, the SSL Fails
- Looked at Gain: BER at highest ebno before SSL/After SSL, If the SSL is working we can expect it to be above 1
Base Channel is trained on channel configuration :
(TDL-D,150ns delay spread, speed 0)
- if just the channel type changes from D->A,B,C even with speed 0 same delay spread, we get gains of 0.96, 0.86 and 1.04 respectively, which says before and after ssl there is not much of a difference in BER
- however, When channel changes from D-> A, B, C with the speed changing to 20, with same delay spread, we get gains of 1.76,1.48 ad 2.01
Varying Channels
Base Channel is trained on channel configuration :
(TDL-D,150ns delay spread, speed 0)
Within the same channel type (D->D), the performance is satisfactory
| Model | Delay sp | speed | gain |
|---|---|---|---|
| D | 150 | 0 | 0.00 |
| D | 300 | 0 | 0.00 |
| D | 1000 | 0 | 0.00 |
| D | 150 | 20 | 3.45 |
| D | 300 | 20 | 4.23 |
| D | 1000 | 20 | 3.18 |
| D | 150 | 60 | 3.13 |
| D | 300 | 60 | 2.39 |
| D | 1000 | 60 | 2.34 |
Varying Channels
Base Channel is trained on channel configuration :
(TDL-D,150ns delay spread, speed 0)
Within the same channel type (D->D), the performance is satisfactory
- Works well when the channel type does not change
- If the channel type changes, struggles in general.
- Across all channels, struggles with high mobility settings
Varying Channels
Experiments with Linear Mode Connectivity
Linear Mode Connectivity
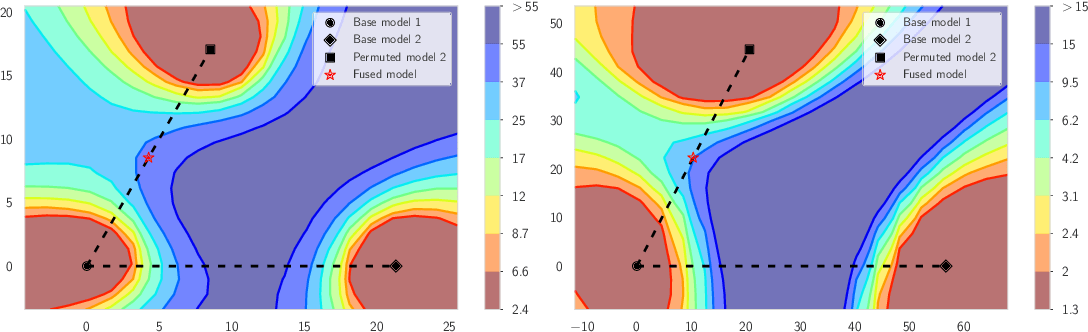
Varying Channels
Experiments with Linear Mode Connectivity
Goal: To empirically see if LMC hypothesis holds.
LMC can be empirically verified by seeing if this is the case
(1-\alpha) Acc(\theta_1) + \alpha Acc(\theta_2) \leq Acc((1-\alpha) \theta_1 + \alpha \theta_2)
Example from: Kim B, Ahn C, Baddar WJ, Kim K, Lee H, Ahn S, Han S, Suh S, Yang E. Test-time ensemble via linear mode connectivity: A path to better adaptation. InThe Thirteenth International Conference on Learning Representations 2025.
Varying Channels
Experiments with Linear Mode Connectivity
Goal: To empirically see if LMC hypothesis holds.
In our setting
(1-\alpha) Rate(\theta_1) + \alpha Rate(\theta_2) \leq Rate((1-\alpha) \theta_1 + \alpha \theta_2)
\theta_1 \rightarrow \text{model trained on base\_channel\_config}
\theta_2 \rightarrow \text{model finetuned on changed\_channel\_config}
TDL-D, 150ns, speed 0
TDL-D, 150ns, speed 20
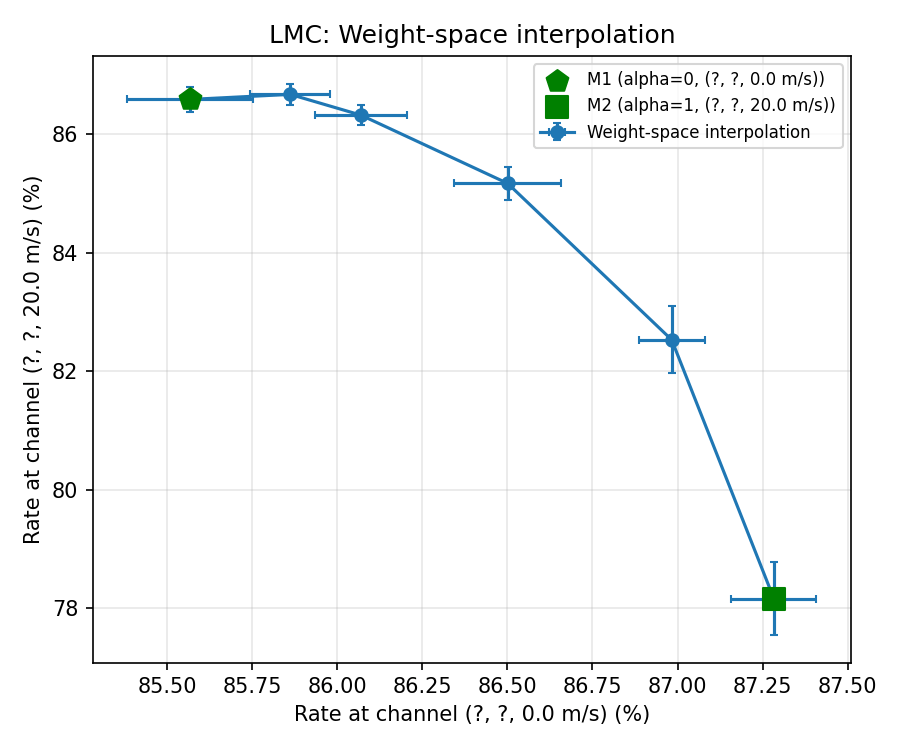
Varying Channels
Experiments with Linear Mode Connectivity
Goal: To empirically see if LMC hypothesis holds.
\theta_1 \rightarrow \text{model trained on base\_channel\_config}
\theta_2 \rightarrow \text{model finetuned on changed\_channel\_config}
TDL-D, 150ns, speed 0
TDL-D, 150ns, speed 20
LMC Holds
Varying Channels
Experiments with Linear Mode Connectivity
Goal: To empirically see if LMC hypothesis holds.
\theta_1 \rightarrow \text{model trained on base\_channel\_config}
\theta_2 \rightarrow \text{model finetuned on changed\_channel\_config}
TDL-D, 150ns, speed 0
TDL-D, 150ns, speed 60
LMC Holds
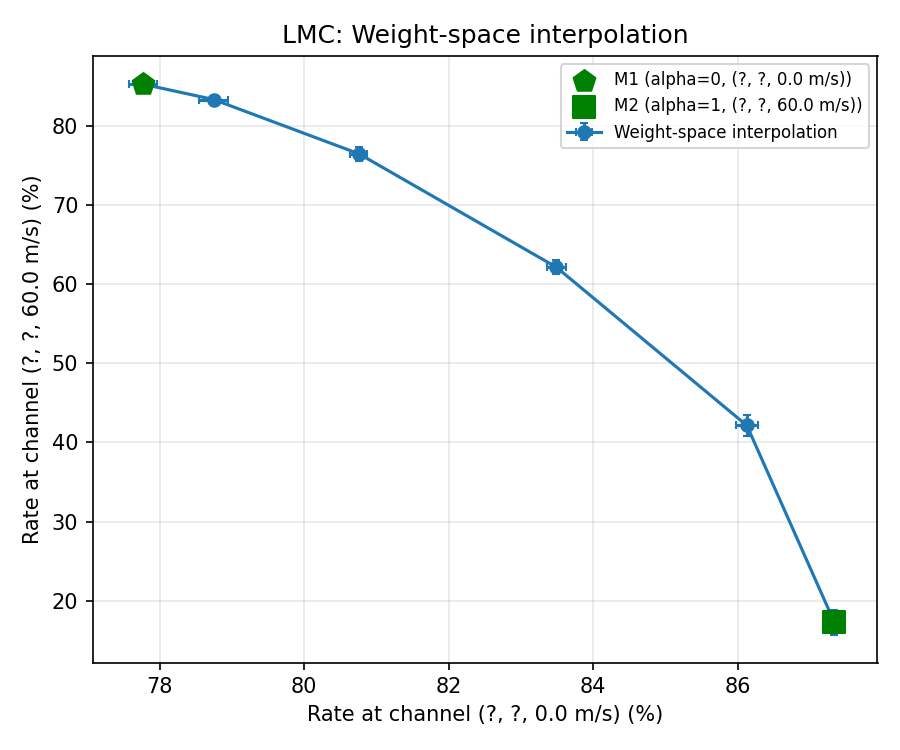
Varying Channels
Experiments with Linear Mode Connectivity
Goal: To empirically see if LMC hypothesis holds.
\theta_1 \rightarrow \text{model trained on base\_channel\_config}
\theta_2 \rightarrow \text{model finetuned on changed\_channel\_config}
TDL-D, 150ns, speed 0
TDL-A, 150ns, speed 60
Does it hold even when channel changes?
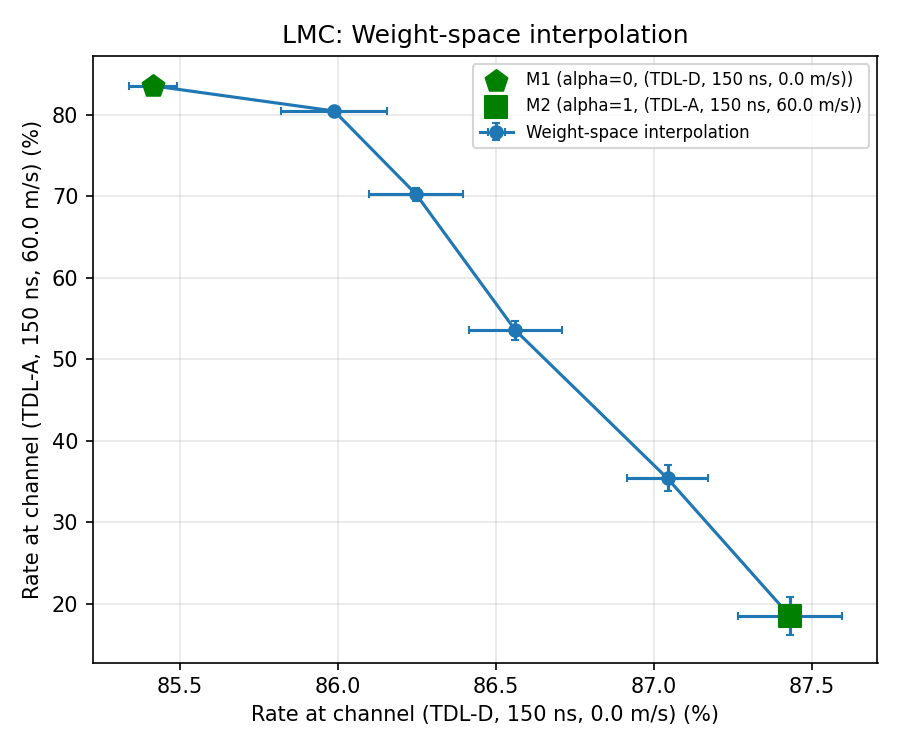
yes
Varying Channels
Experiments with Linear Mode Connectivity
Next steps:
See how to exploit LMC for test time adaptation?
Only one major prior work , published in ICLR 2025
Kim B, Ahn C, Baddar WJ, Kim K, Lee H, Ahn S, Han S, Suh S, Yang E. Test-time ensemble via linear mode connectivity: A path to better adaptation. InThe Thirteenth International Conference on Learning Representations 2025.
Only one major prior work , published in ICLR 2025

Varying Channels
Experiments with Linear Mode Connectivity
Next steps:
See how to exploit LMC for test time adaptation?
Initial Idea (Might change)
\Delta F
Hypernetwork
\hat{q} , \alpha
\hat{q} = \frac{\theta_2 - \theta_1}{|| \theta_2 - \theta_1||}
\hat{q} , \alpha
\hat{q}
\Delta_F \rightarrow \text{characteristic channel change captured by change in clusters }
Varying Channels
Catch: Cost of LMC \ finetuning
It is known that NNs loose their ability to "adapt" in nonstationary environments (plasticity)
How much is that cost?
I.E if we were to train a model from scratch on a new environment, how much better would we do?
Varying Channels
Catch: Cost of LMC \ finetuning
It is known that NNs loose their ability to "adapt" in nonstationary environments (plasticity)
How much is that cost?
I.E if we were to train a model from scratch on a new environment, how much better would we do?
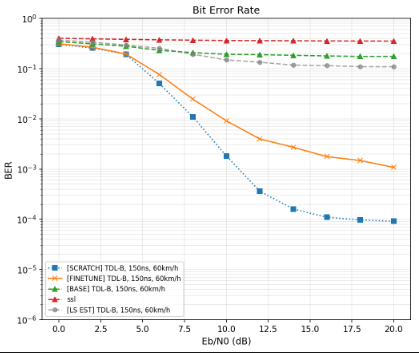
\}
Can we close the gap?
I Think yes. I feel this issue is because the
Network being "not" plastic enough.
There are some known tricks that will
improve plasticity
Varying Channels
Catch: Cost of LMC \ finetuning
It is known that NNs loose their ability to "adapt" in nonstationary environments (plasticity)
How much is that cost?
I.E if we were to train a model from scratch on a new environment, how much better would we do?
Can we close the gap?
I Think yes. I feel this issue is because the
Network being "not" plastic enough.
There are some known tricks that will
improve plasticity
(for ex. see Lyle C, Zheng Z, Khetarpal K, Van Hasselt H, Pascanu R, Martens J, Dabney W. Disentangling the causes of plasticity loss in neural networks. arXiv preprint arXiv:2402.18762. 2024 Feb 29. )
Varying Channels
Catch: Cost of LMC \ finetuning
It is known that NNs loose their ability to "adapt" in nonstationary environments (plasticity)
How much is that cost?
I.E if we were to train a model from scratch on a new environment, how much better would we do?
Can we close the gap?
However, I am skeptical, as these works mention loss of plasticity is due to:
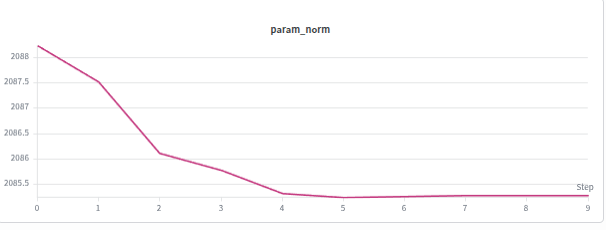
1. Growth in parameter norm, because of which the gradient norm is overshadowed
2. The preactivations shift to "non-linear" regions of the activations
3. Plus other factors
Varying Channels
Catch: Cost of LMC \ finetuning
It is known that NNs loose their ability to "adapt" in nonstationary environments (plasticity)
Can we close the gap?
However, I am skeptical, as these works mention loss of plasticity is due to:
1. Growth in parameter norm, because of which the gradient norm is overshadowed
2. The preactivations shift to "non-linear" regions of the activations
3. Plus other factors
We do not observe 1
Hypernetwork Arch
Hypernetwork Arch
C1
C2
Ck
\cdots
Model Bank
\theta_0 - \theta_k
Base
NRx
Adapted to Channel k
Hypernetwork Arch
C1
C2
Ck
\cdots
Model Bank
NRx
z_t
Hypernetwork
z_0 - z_t
\begin{bmatrix}
\alpha_1 \\
\vdots \\
\alpha_k
\end{bmatrix}
\sum_i \alpha_i \cdot c_i
Hypernetwork Arch
C1
C2
Ck
\cdots
Model Bank
NRx
z_t
Hypernetwork
z_0 - z_t
\begin{bmatrix}
\alpha_1 \\
\vdots \\
\alpha_k
\end{bmatrix}
\sum_i \alpha_i \cdot c_i
Because C1..Ck are LMC connected,
sum_i alpha_i c_i will always be better?
Online, no training at test time
Hypernetwork Arch
C1
C2
Cn
\cdots
All channel models
Results
Train
Test
80/20 split
Hypernetwork Arch
Results
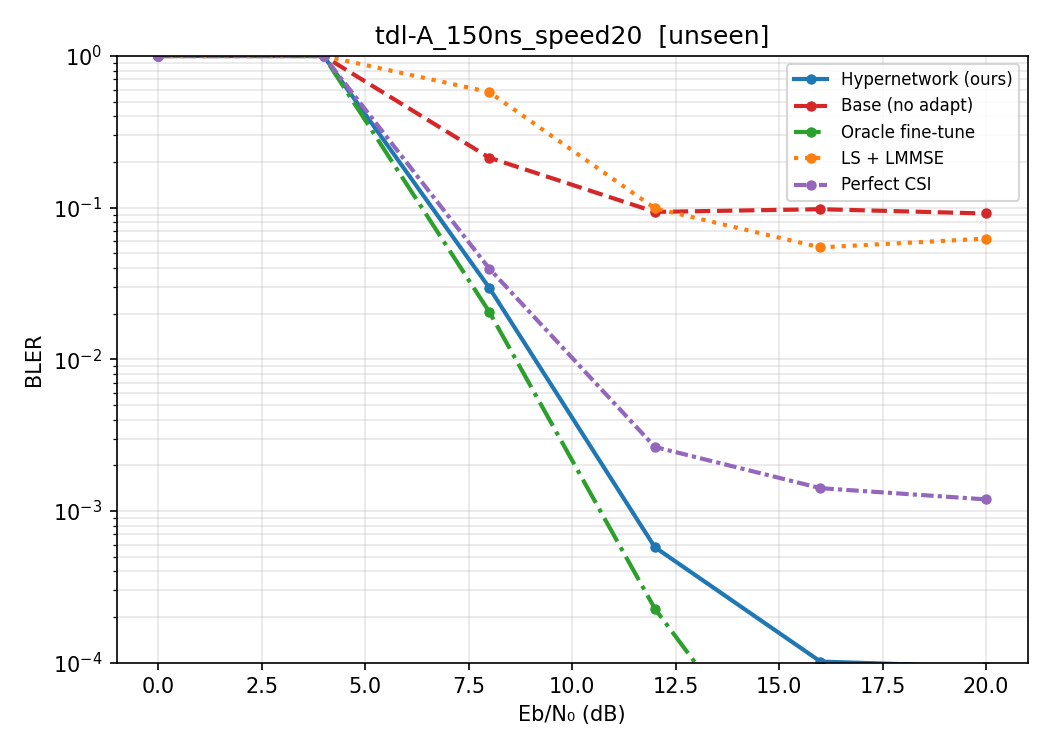
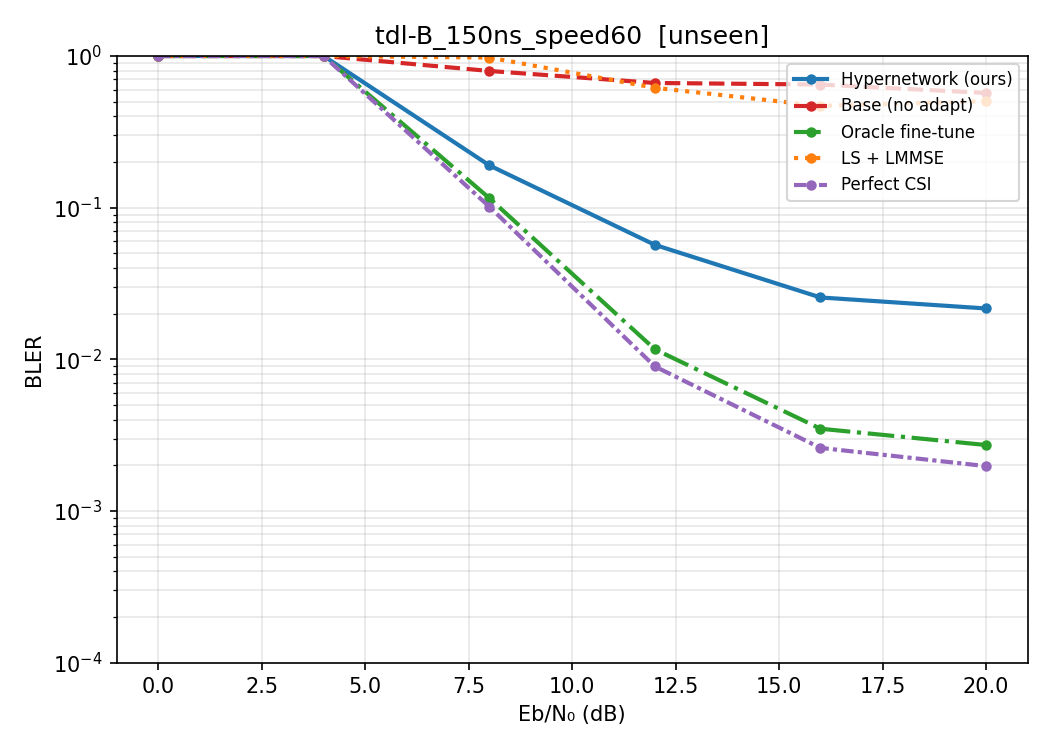
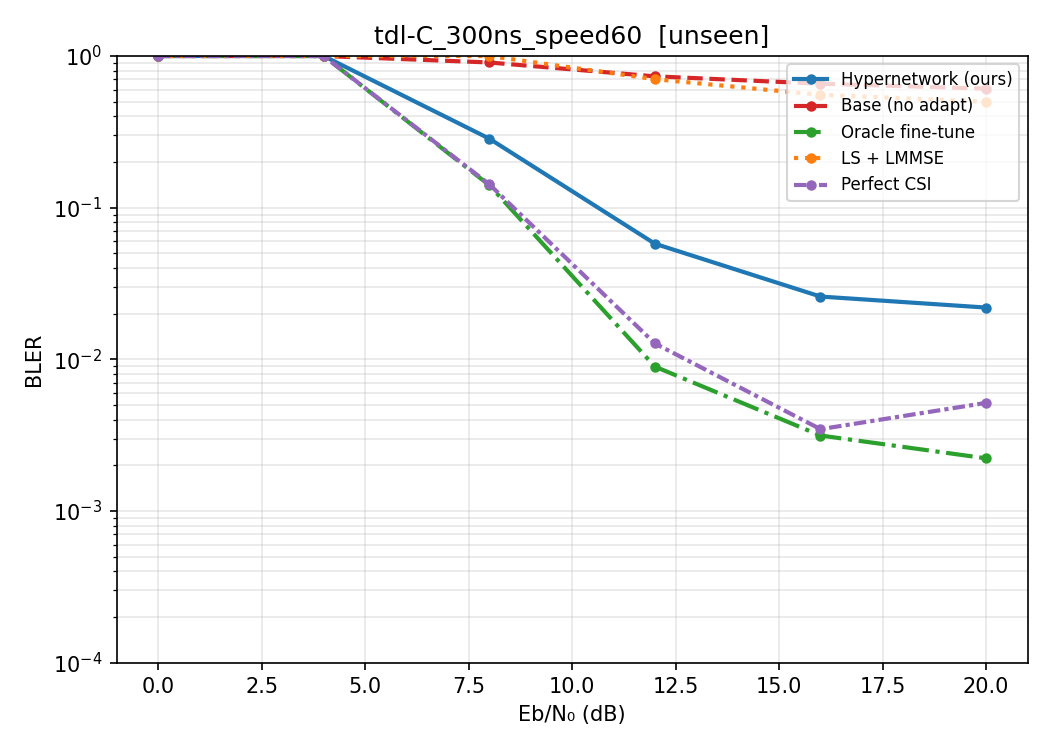
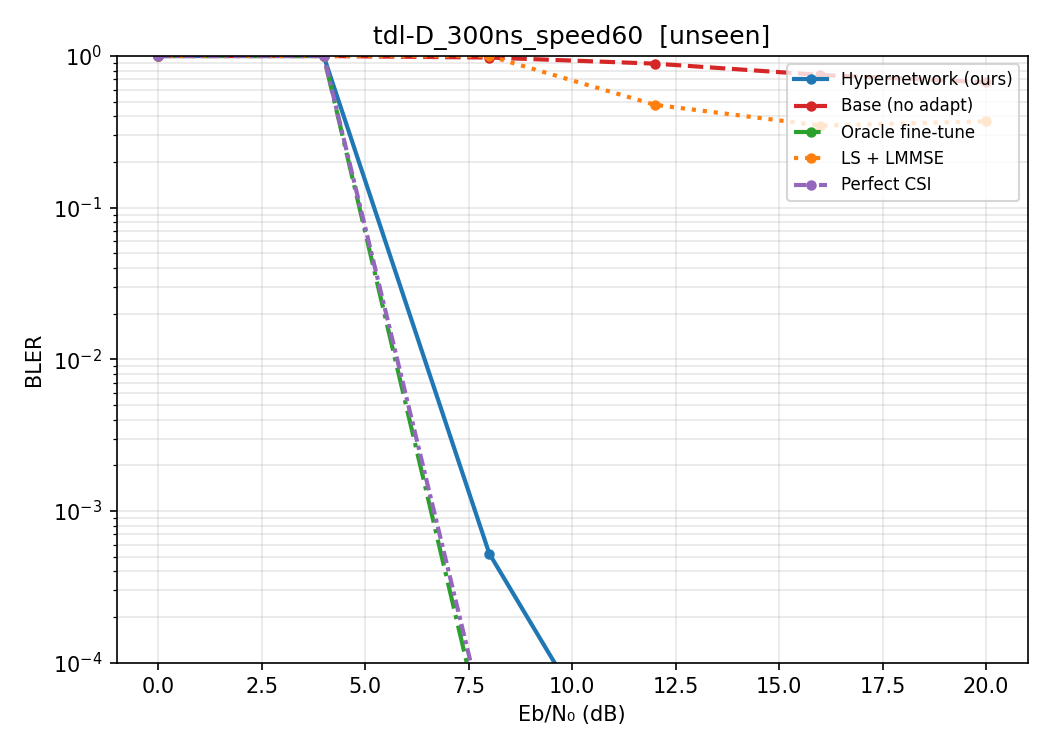
Hypernetwork Arch
Results
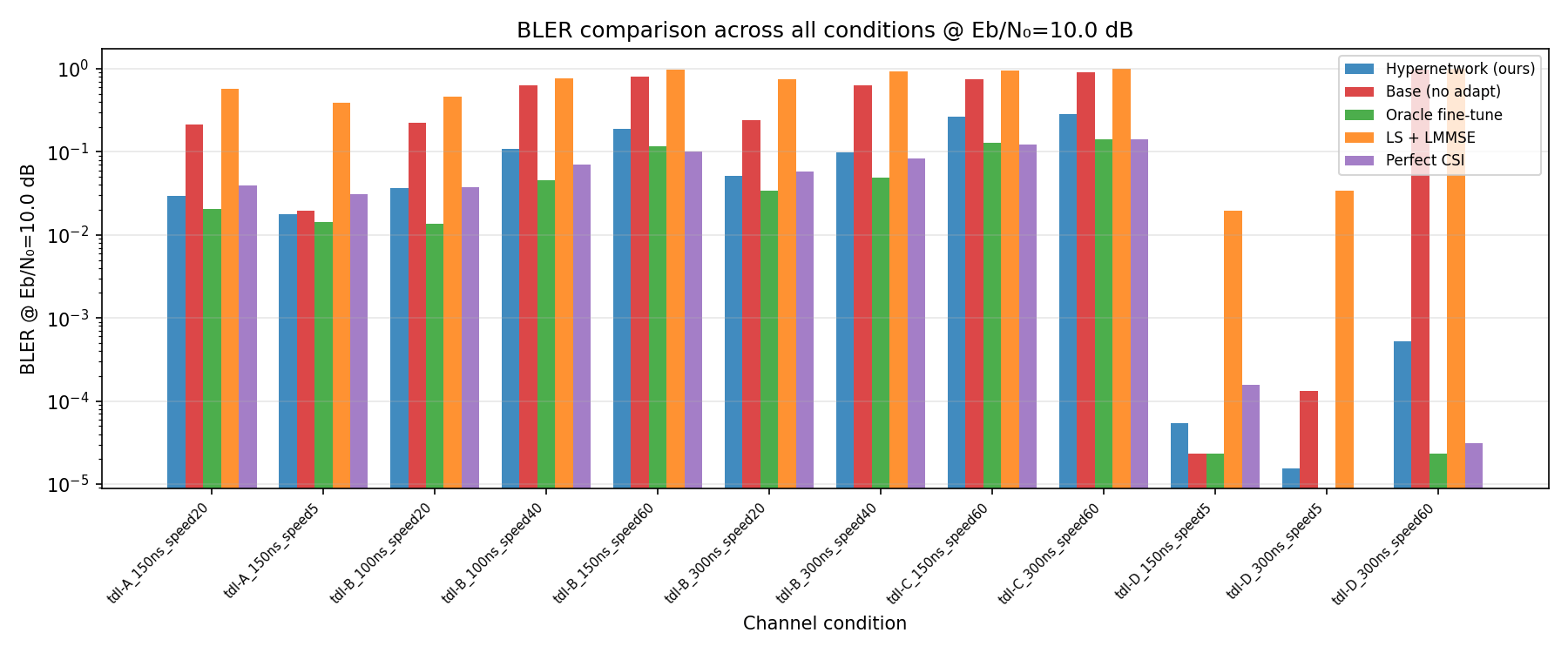
Hypernetwork Arch
Results
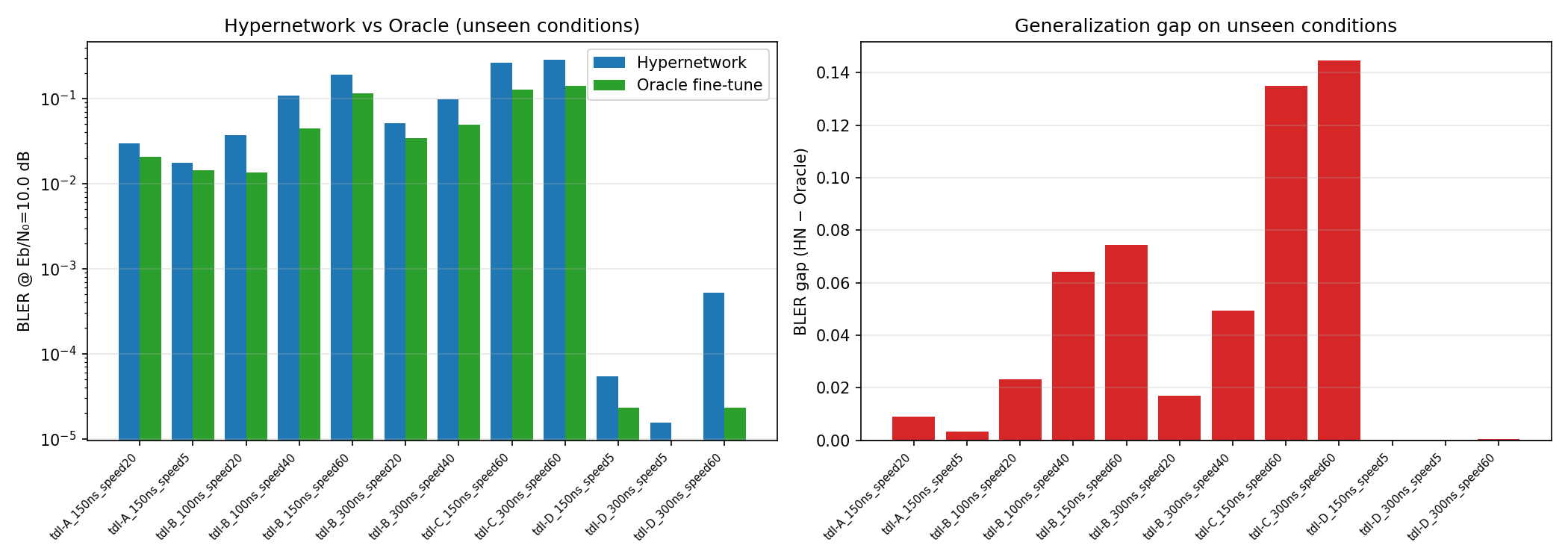
Hypernetwork Arch
Results
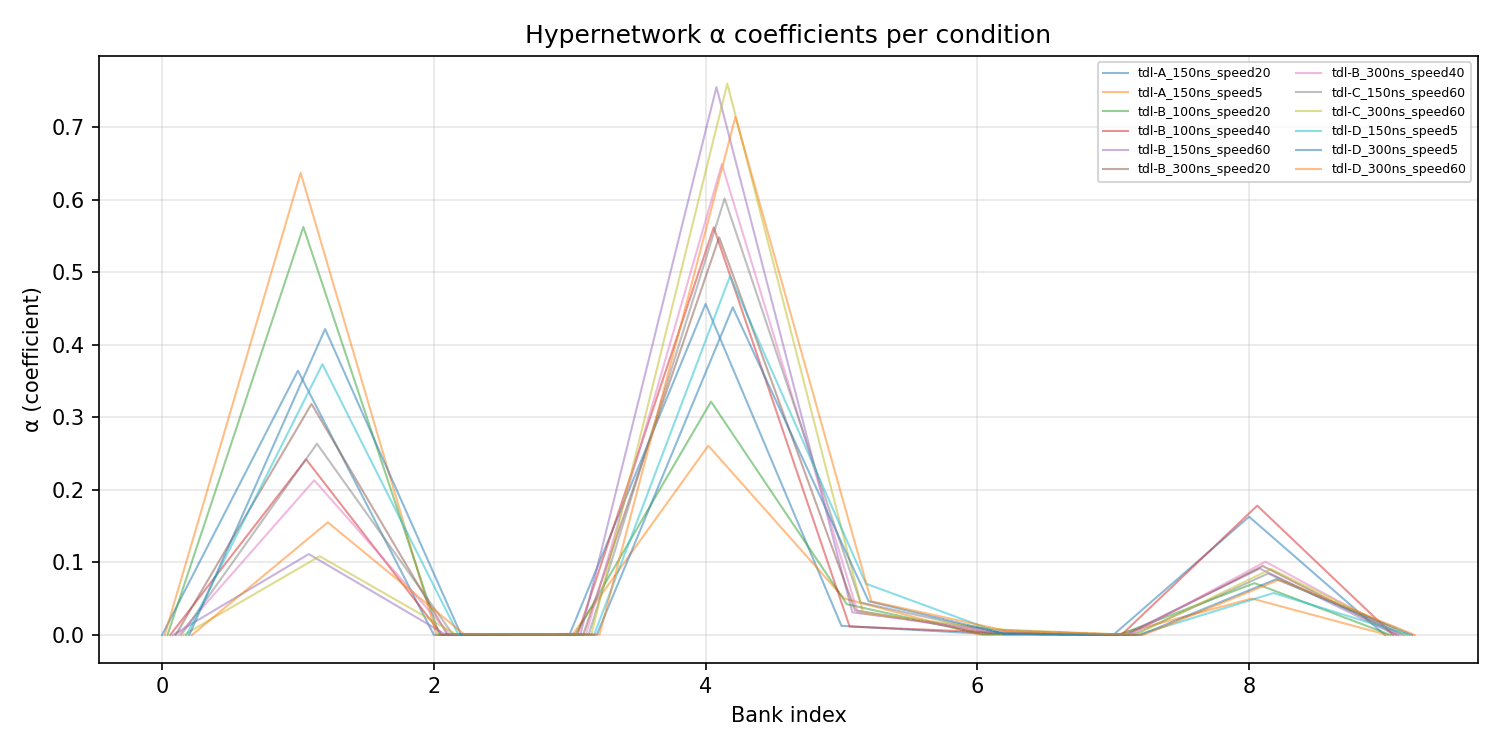
1: tdl-C_300ns_speed5,
4: tdl-B_100ns_speed10
8: tdl-C_300ns_speed20
Hypernetwork Arch
Results
C1
C2
Cn
\cdots
All channel models
Train on D, E (line of sight) and B (non line of sight)
Split
Speed: 10/20/40
Delay spread: 100ns
Test on other channel types
Speed: 60
Delay spread: 300ns/150ns
Hypernetwork Arch
Results
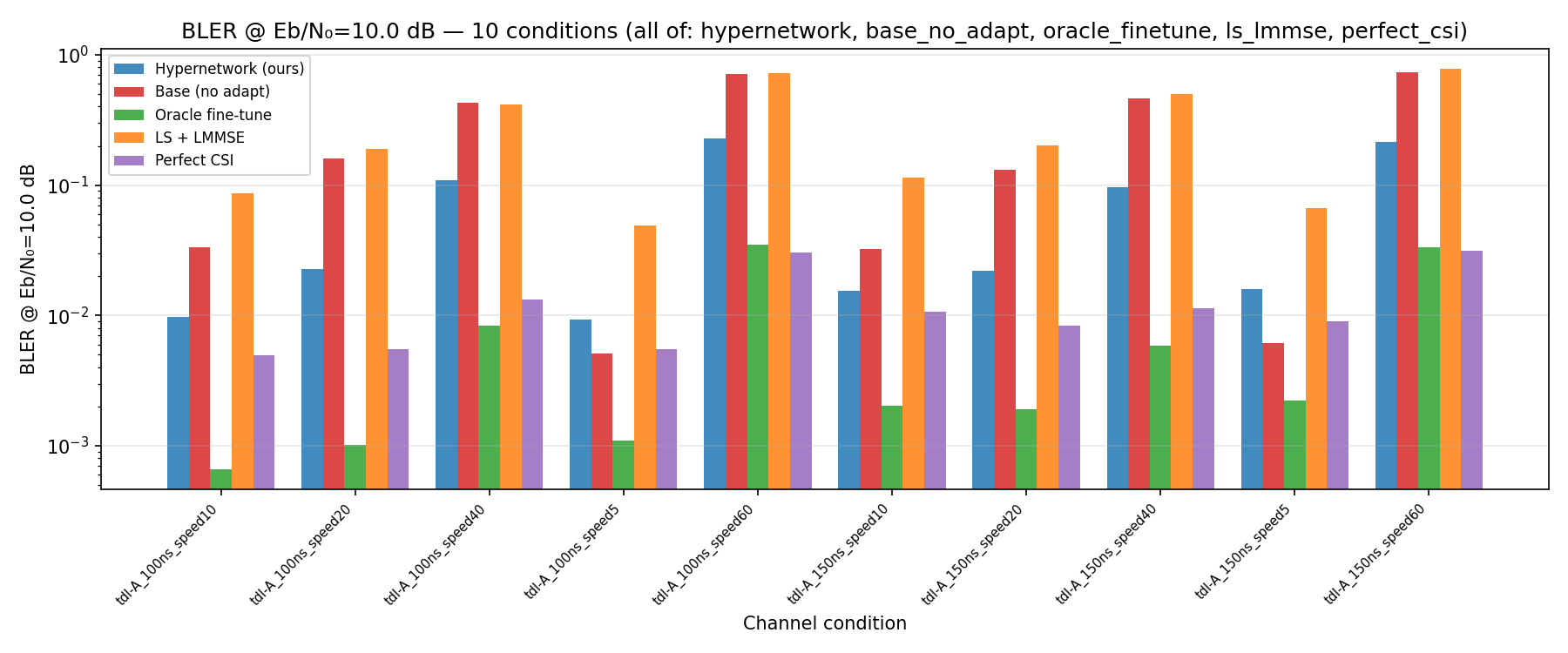
Hypernetwork Arch
Results
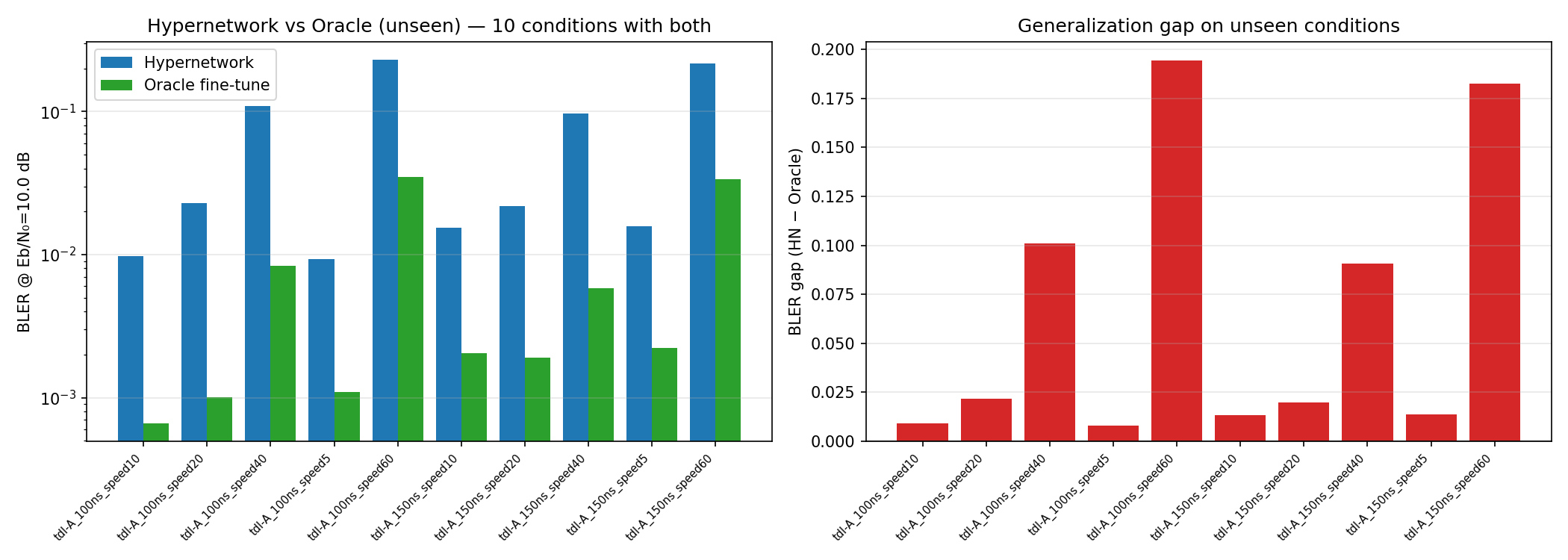
Hypernetwork Arch
Results

bank[1] (tdl-D,150ns,5m/s)
bank[3] (tdl-B,150ns,10m/s)
bank[8] (tdl-B,100ns,10m/s)
Hypernetwork Arch
Results
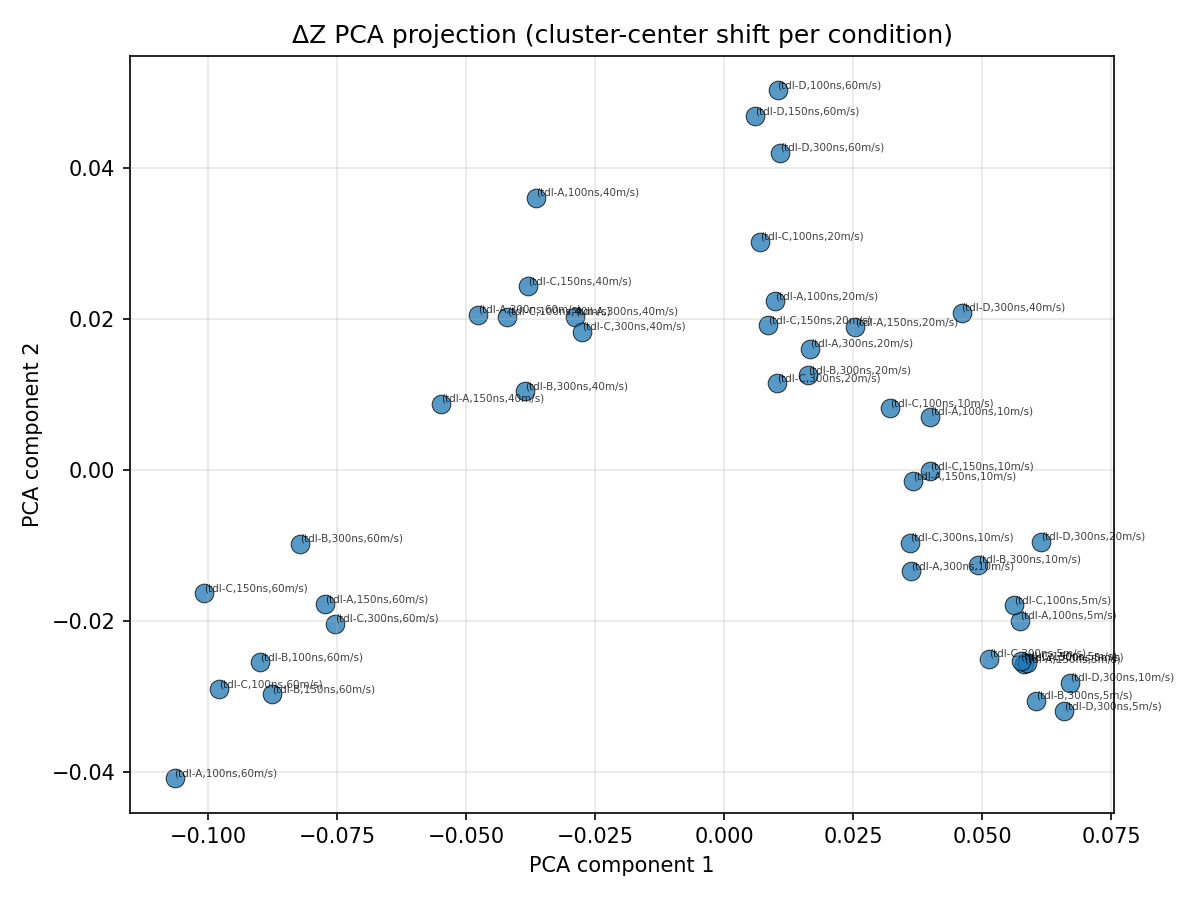
Hypernetwork Arch
C1
C2
Ck
\cdots
Model Bank
NRx
z_t
Hypernetwork
z_0 - z_t
\begin{bmatrix}
\alpha_1 \\
\vdots \\
\alpha_k
\end{bmatrix}


- I feel the paper has some elegant theory
- However, limited to the linear case.
- If we'd want to go this direction, we would probably want to look at non-linear objectives but take linear approximation
- Or problems that have linear structure to it?
- Also a related direction is barycentric/volumetric spanners

- I feel this is a very interesting direction.
- There is also recent evidence showing representations of different llms are connected by affine transformations.
- There is also a possibility for us to explore this direction.
- What are some examples of multimodal data that are of interest to us...?
deck
By Incredeble us



