Harnessing Character-level Dynamics and Word-level Semantics: A New Perspective on Twitter Sentiment Analysis
about the dataset
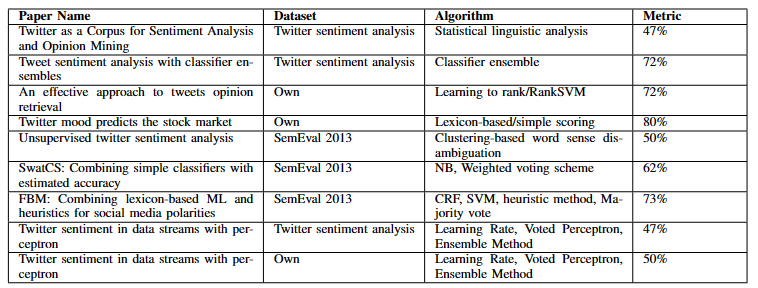
Existing works
Existing works
Experiment 1
Use DMD Embeddings to classify based on ML
Use DMD Embeddings to classify based on ML
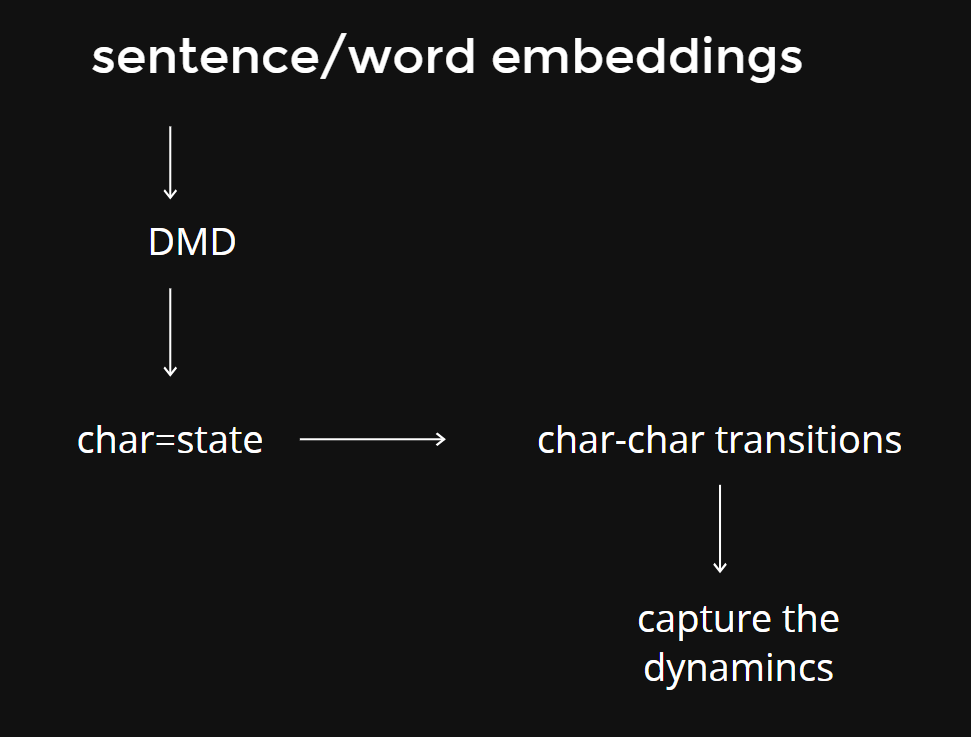
DMD in Word Embeddinsg
The dynamics captured by the Dynamic Mode Decomposition (DMD) correspond to the semantic relationships between characters within sentences. By analyzing the transitions from one character to another, DMD identifies and represents the underlying dynamics that convey meaning and semantic connections. These dynamics encapsulate the relationships between characters and contribute to the overall semantic understanding of the sentence.
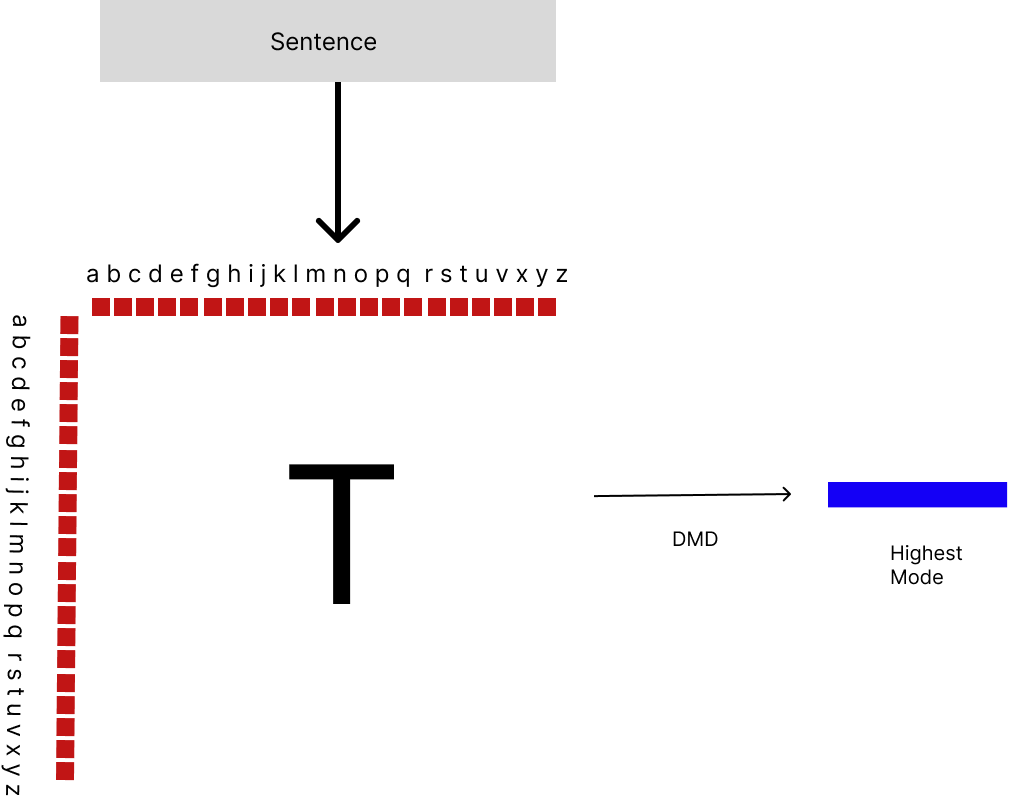
Simple Graph Construction
Nodes are Characters
Edges are based on Character Co-occurance
Update the edge weight if Co-ocurance already exists else add edge
Fit the Co-Occurrence matrix to get the DMD Modes
Take the highest mode
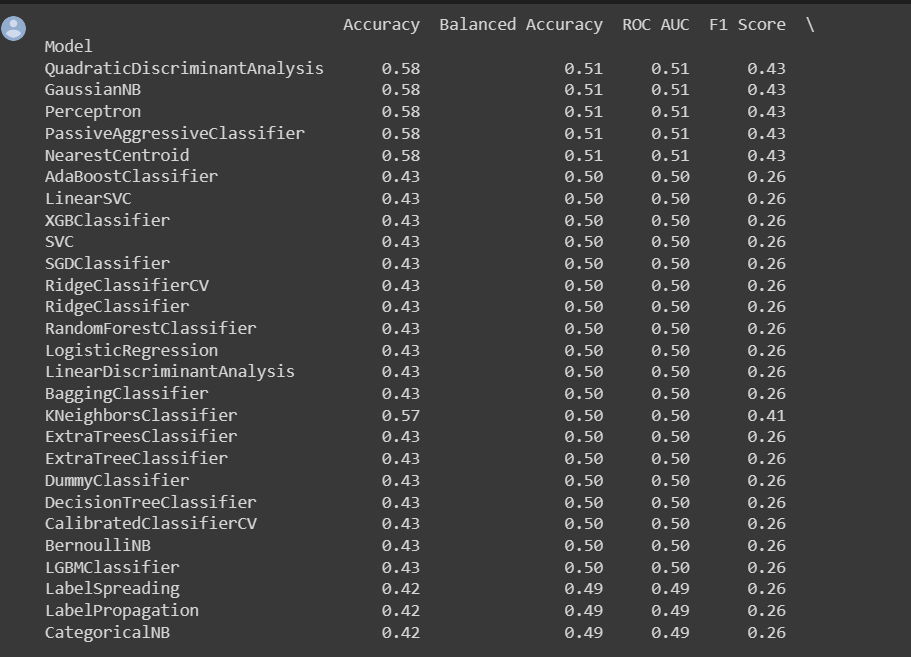
Results
Experiment 2
Message Passing
Intiution
Spike a Graph and Edges denote the way the signal can transfer through the graph
How the signal Spreads through the graph is the Message passing
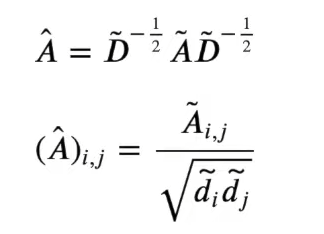
A is Adjacency Matrix
D is Degree Of Connections
Pass to GCN
Experiment 3
From Characters to words
AFFIN
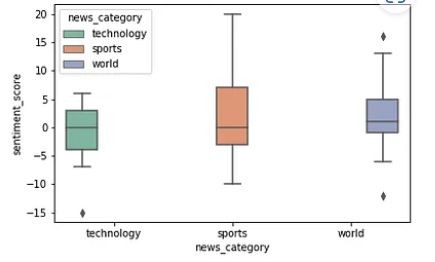
example
Lexicon-based approach for text scoring
The AFINN lexicon, consists of over 3,300 English words or phrases, each assigned a sentiment score ranging from -5 to +5. The sentiment score indicates the degree of positive or negative sentiment associated with a particular word or phrase.
Words with positive sentiment Positive Score
VADER
Valence Aware Dictionary and sentiment Reasoner
Valence Aware Dictionary and sEntiment Reasoner
rule-based sentiment analysis tool
Comes with a pre-trained model that includes a lexicon of words and their associated sentiment scores.
VADER assigns sentiment scores to individual words based on their position in the lexicon and their contextual usage. These scores are then combined to calculate an overall sentiment score for a given text
-1 (extremely negative) to +1 (extremely positive)
GLOVE
Glove model combines word-word co-occurrence counts and window based approaches
pre-trained model with 6 billion english words from stanford
Glove
Objective Function
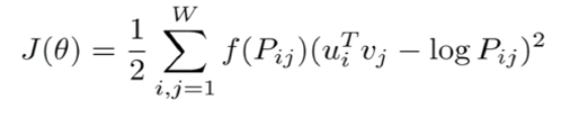
Pij=The observed co-occurrence count between word i and word j in the corpus.
For each pair of words that can co-occur, minimize the distance between the inner product of two words and the log count of two words
Squared distance value is weighted using f(Pij) which will assign lower weights to the pair having high count
If two words frequently co-occur in similar contexts, their inner product should be high. On the other hand, if their co-occurrence count is high, their logarithm should also be high. By minimizing the difference between the two, GloVe effectively learns word vectors that accurately capture the relationships between words based on their co-occurrence patterns.
Graph Construction
"I am having headache"
I
am
having
headache
k=1
Graph Construction
"I am having headache"
I
am
having
headache
k=1
Each word will be connected to "k-nearest words"
GCN
Embedding
Pooling
Text
Logits
Results

import re
import string
import pandas as pd
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from afinn import Afinn
from nltk.sentiment import SentimentIntensityAnalyzer
from gensim.models import Word2Vec
from torch_geometric.data import Data
from torch_geometric.nn import GCNConv
import torch
import torch.nn.functional as F
# Load the data
df = pd.read_csv("/content/twitter_validation.csv", usecols=[2, 3], names=['emotion', 'tweet'], header=0)
# Lowercase the tweets
df['tweet'] = df['tweet'].str.lower()
# Remove URLs
df['tweet'] = df['tweet'].apply(lambda x: re.sub(r'https?:\/\/\S+', '', x))
# Remove the punctuation
df['tweet'] = df['tweet'].apply(lambda x: x.translate(str.maketrans('', '', string.punctuation)))
# Remove stopwords and keep words with length > 3
stop = stopwords.words('english')
df['tweet'] = df['tweet'].apply(lambda x: ' '.join([word for word in x.split() if word not in stop and len(word) > 3]))
from sklearn.preprocessing import LabelEncoder
# Convert emotion labels to numerical labels
label_encoder = LabelEncoder()
df['label'] = label_encoder.fit_transform(df['emotion'])
# Get the unique numerical labels
unique_labels = df['label'].unique()
# Instantiate sentiment intensity analyzer
sia = SentimentIntensityAnalyzer()
# Instantiate AFINN-111
afinn = Afinn()
# Train Word2Vec model
sentences = [word_tokenize(tweet) for tweet in df['tweet']]
# Train Word2Vec model
word2vec_model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# Define a function to get sentiment scores using AFFINN
def get_affinn_sentiment(word):
return afinn.score(word)
# Define a function to get sentiment scores using VADER
def get_vader_sentiment(word):
sentiment = sia.polarity_scores(word)
return sentiment['compound']
# Define a function to get Word2Vec embeddings
def get_word2vec_embedding(word):
if word in word2vec_model.wv:
return torch.from_numpy(word2vec_model.wv[word])
else:
return torch.zeros(word2vec_model.vector_size)
# Prepare the data
df['tweet'] = df['tweet'].apply(lambda x: word_tokenize(x))
df['affinn_sentiment'] = df['tweet'].apply(lambda x: [get_affinn_sentiment(word) for word in x])
df['vader_sentiment'] = df['tweet'].apply(lambda x: [get_vader_sentiment(word) for word in x])
df['word2vec_embedding'] = df['tweet'].apply(lambda x: [get_word2vec_embedding(word) for word in x])
Code
def create_graph(tweet, node_embeddings, label, k=2):
# Convert node_embeddings and label to tensors
if len(node_embeddings)!=0:
x = torch.stack(node_embeddings, dim=0)
y = torch.tensor([label], dtype=torch.long)
# Prepare edge_index
edge_index = []
for i in range(len(tweet)):
for j in range(i+1, min(i + k + 1, len(tweet))):
edge_index.append((i, j))
edge_index = torch.tensor(edge_index, dtype=torch.long).t().contiguous()
# Check if the graph is empty
if len(x) <= 1 or len(edge_index) <= 1:
return None
# Construct a PyG Data object
data = Data(x=x, edge_index=edge_index, y=y)
return data
graph_data_list = []
for i, row in df.iterrows():
tweet = row['tweet']
affinn_sentiment = row['affinn_sentiment']
vader_sentiment = row['vader_sentiment']
word2vec_embedding = row['word2vec_embedding']
label = row['label']
graph_data = create_graph(tweet, word2vec_embedding, label)
# Add the graph data object to the list
if graph_data is not None:
graph_data_list.append(graph_data)
from sklearn.model_selection import train_test_split
train_data, test_data = train_test_split(graph_data_list, test_size=0.2, random_state=42)
import torch.nn.functional as F
def train(model, graph_data_list, criterion, optimizer):
model.train()
for data in graph_data_list:
try:
optimizer.zero_grad() # Clear gradients
# Forward propagation
outputs = model(data.x, data.edge_index)
# Convert data.y to one-hot vector
y_onehot = F.one_hot(data.y, num_classes=4).float()
# Compute loss
loss = criterion(outputs.squeeze(), y_onehot.squeeze())
# Backward propagation
loss.backward()
# Update weights
optimizer.step()
# Update weights
except Exception as e:
raise e
def test(model, graph_data_list):
model.eval()
correct = 0
total = 0
for data in graph_data_list:
try:
outputs = model(data.x,data.edge_index)
predicted = outputs.argmax(dim=1)
correct += (predicted == data.y).sum().item()
total += len(data.y)
except Exception as e:
raise e
accuracy = correct / total
return accuracy
for epoch in range(10): # Number of epochs
train(model, train_data, criterion, optimizer)
test_acc = test(model, test_data)
print(f"Epoch {epoch+1}, Test Accuracy: {test_acc}")
Code
Overview
By Incredeble us



