





















He Wang PRO
Knowledge increases by sharing but not by saving.
第 2 部分 基于 Python 的数据分析基础
主讲老师:王赫
2023/12/03
ICTP-AP, UCAS
数据分析实训之 Pandas
# Response
# Pandas
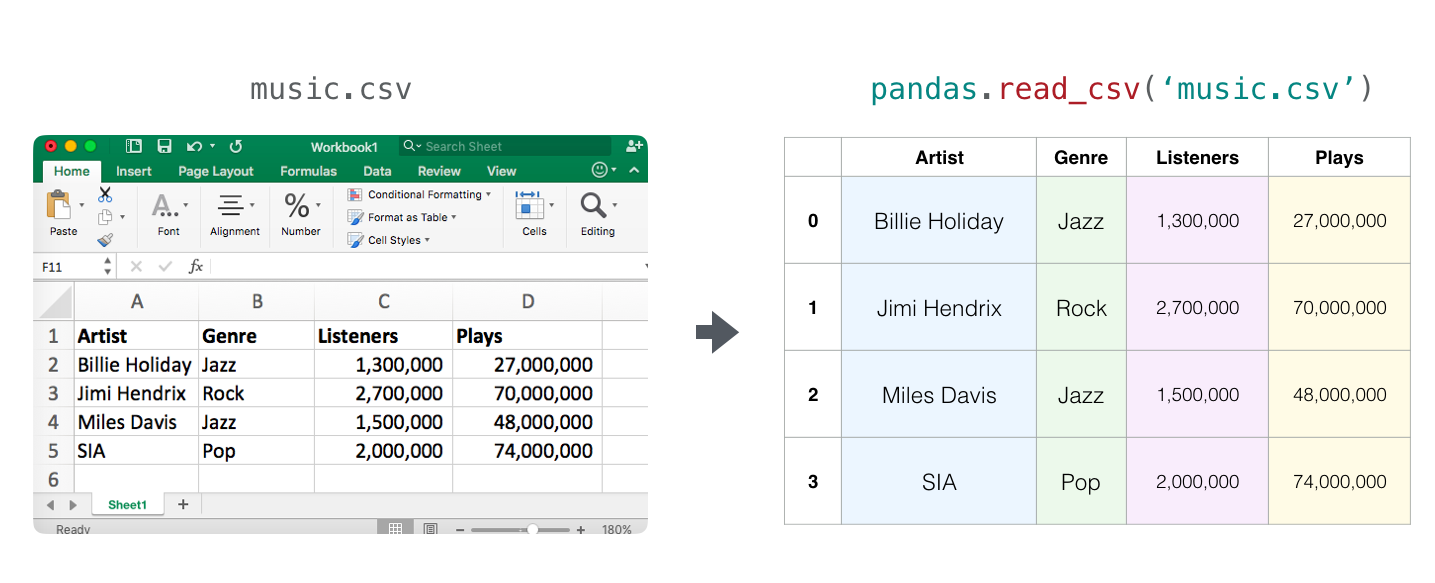
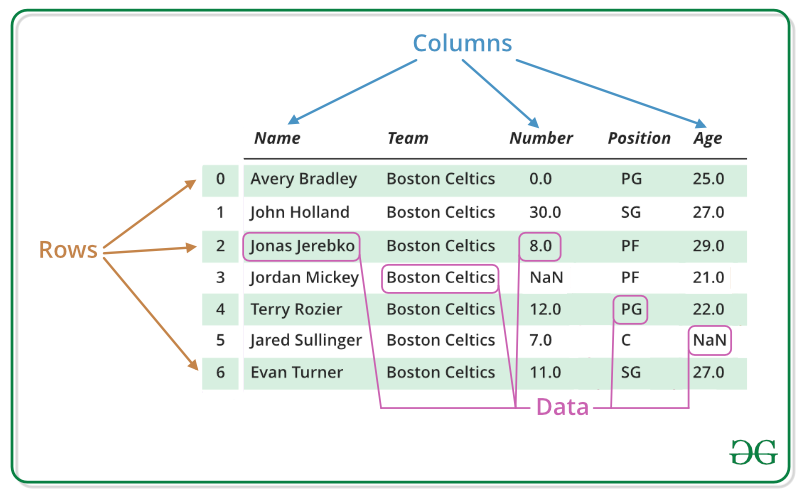
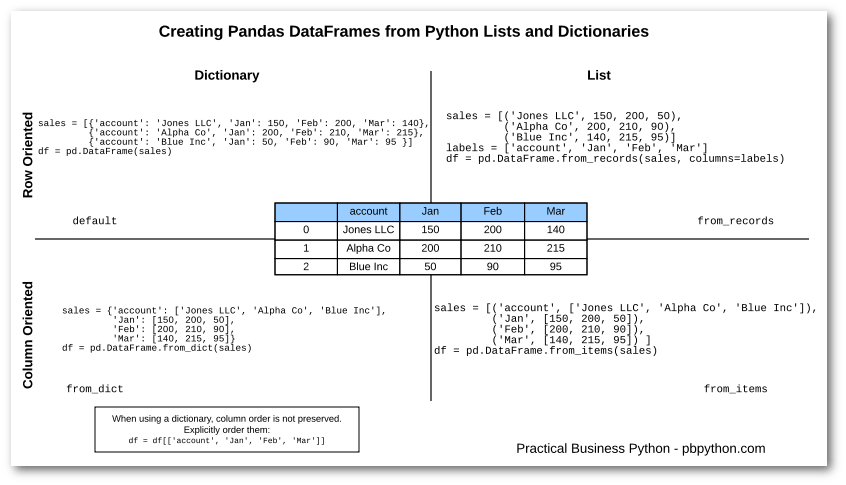
从 Numpy 的 Ndarray 到 Pandas 的 Series / DataFrame
(Numpy) 1-dimensional array \(\Leftrightarrow\) Series (Pandas)
(Numpy) 2-dimensional array \(\Leftrightarrow\) DataFrame (Pandas)
# Pandas
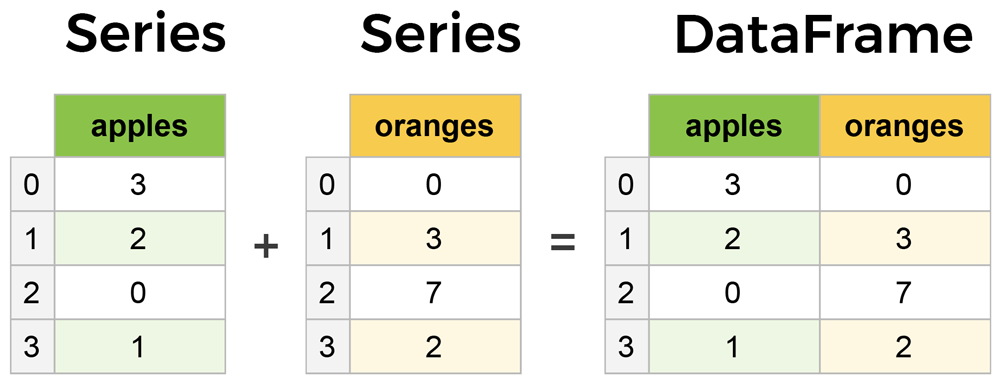
Series 是一种类似于一维数组的对象,是由一组数据 (各种 NumPy 数据类型) 以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的 Series 对象。
# Pandas
Series 是一种类似于一维数组的对象,是由一组数据 (各种 NumPy 数据类型) 以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的 Series 对象。
# Pandas
# Pandas
# Pandas
\(\Rightarrow\) Series
\(\Rightarrow\) DataFrame
Just like ndarray ...
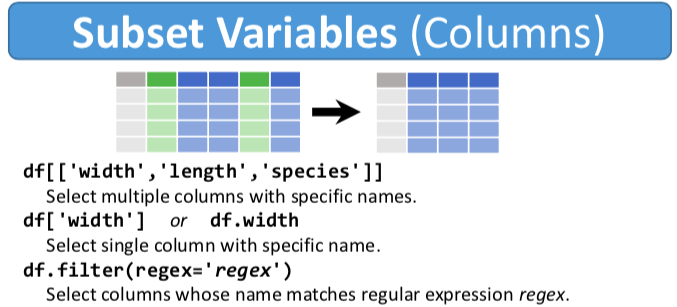
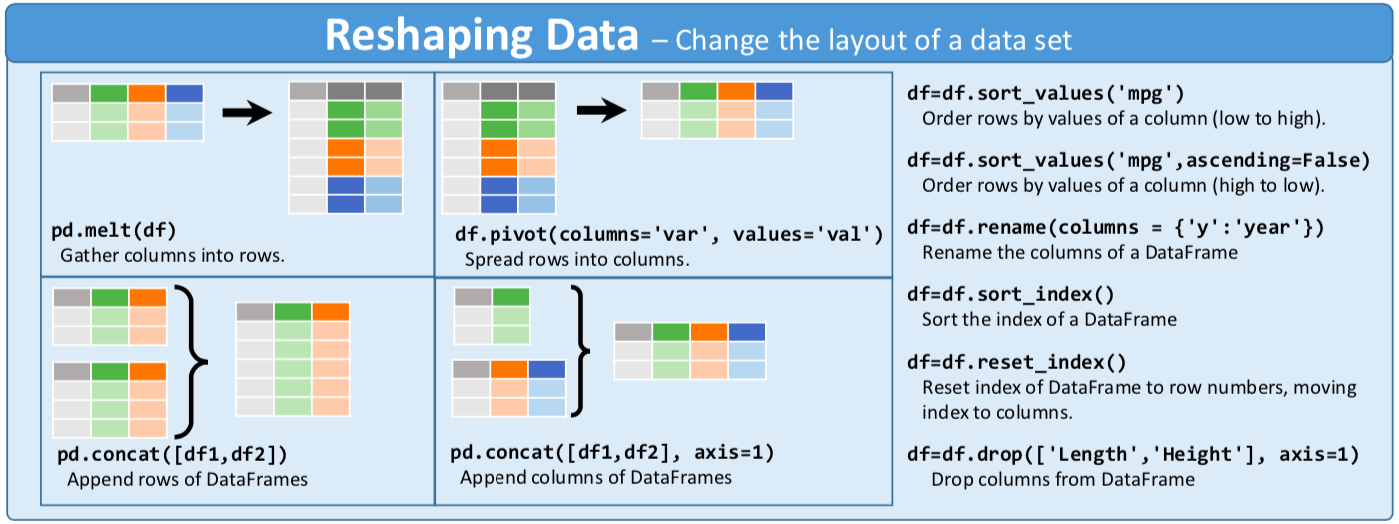
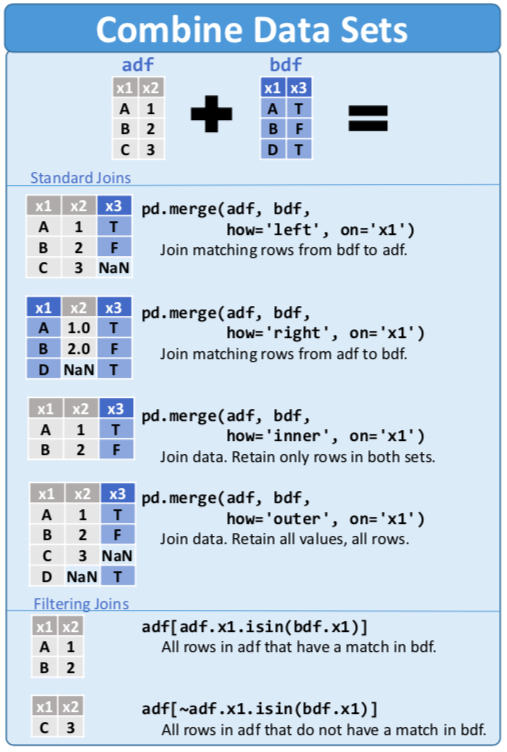
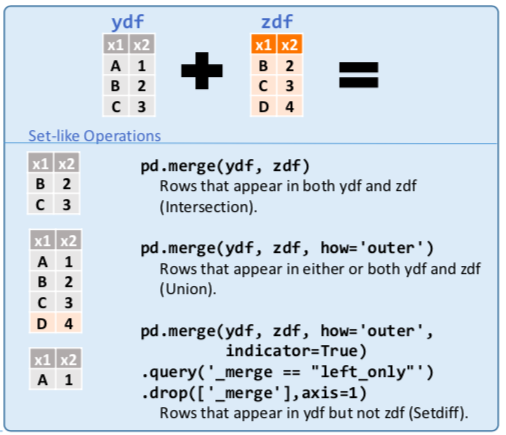
df.drop(['length','species'], axis=1)# Pandas
# Pandas
# Pandas
Series / DataFrame 常用的属性与方法
shape / size / index / dtype / astype() / ...
head() / tail() / describe() / values
max() / min() / mean() / median() / ...
to_*() / sort_index() / sort_values() / ...
apply() / drop() / drop_duplicates() / ...
isin() / isna() / isnull() / fillna() / ...
\(\Rightarrow\) ndarray (Numpy)
Series 的常用属性与方法
unique()
tolist()
value_counts()
map()
is_unique() / is_monotonic()
DataFrame 的常用属性与方法
columns
info()
stack()
insert()
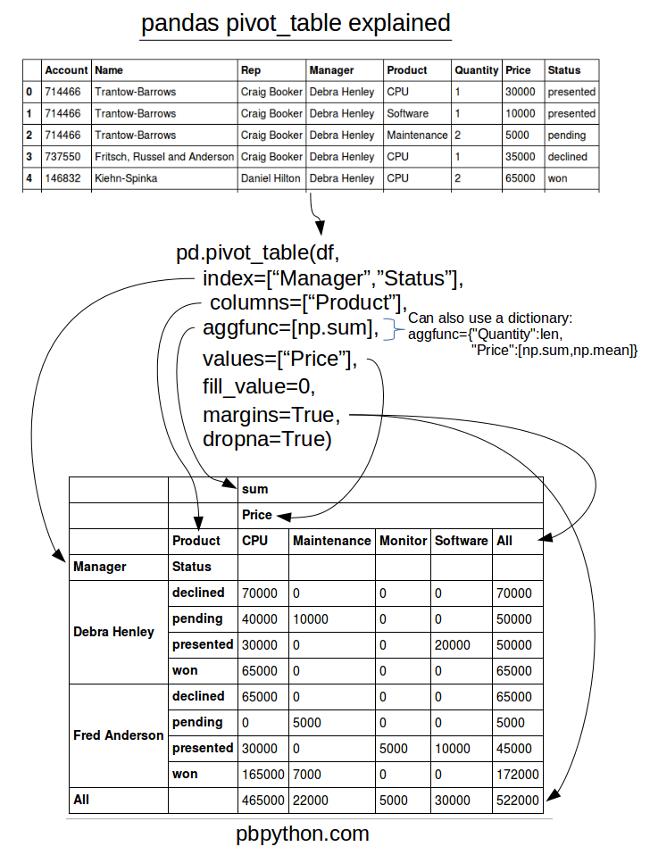
# Pandas
—— 数据高级统计分析
pivoted = pd.pivot_table(s4g, index=['Symbol', 'Year'],
values=['Open','Close'], aggfunc='mean',
columns=['Month'], fill_value = 0)\(\Leftrightarrow\)
table = s4g.groupby(['Symbol', 'Year', 'Month'])['Open', 'Close'].mean()
table = table.unstack('Month')
table = table.fillna(0)
# Homework
Repo of the course: https://github.com/iphysresearch/GWData-Bootcamp
Python、Numpy 和 Pandas 的基础作业题目(单选题)位于:
2023/python/homework-python.*
2023/python/homework-numpy.*
2023/python/homework-pandas.*
(分别有 ipynb, html, md 三种文档格式,以方便阅读)
将你完成的作业添加到你在上一步中创建的个人作业目录中。根据作业的类型,应将完成的作业分别命名为 python_submit.txt、numpy_submit.txt 和 pandas_submit.txt。其中每个 txt 文档的每行对应于 A,B,C,D,... 等选项当中的一个(注意:行号对应于题号)
在 homework 分支上把你完成的作业 push 到你自己的关于本课程的远程仓库中,即:$ git push origin homework ;最后,在GitHub上你的远程仓库中,在 homework 分支下发起 Pull Request (PR) 至本课程远程仓库的 homework 分支。
GitHub Actions 工作流将自动检查你的提交,并将 modified 的python_submit.txt、numpy_submit.txt 和 pandas_submit.txt 与 solution 进行比较。
不要修改其他学员的作业目录和作业内容!
# Homework
Repo of the course: https://github.com/iphysresearch/GWData-Bootcamp
扩展作业
Want more? see: Advent of Code
By He Wang
引力波数据探索:编程与分析实战训练营。课程网址:https://github.com/iphysresearch/GWData-Bootcamp




