













He Wang PRO
Knowledge increases by sharing but not by saving.
第 3 部分 机器学习基础
主讲老师:王赫
2023/12/24
ICTP-AP, UCAS
机器学习算法之应用进阶
# Response
# GW: ML
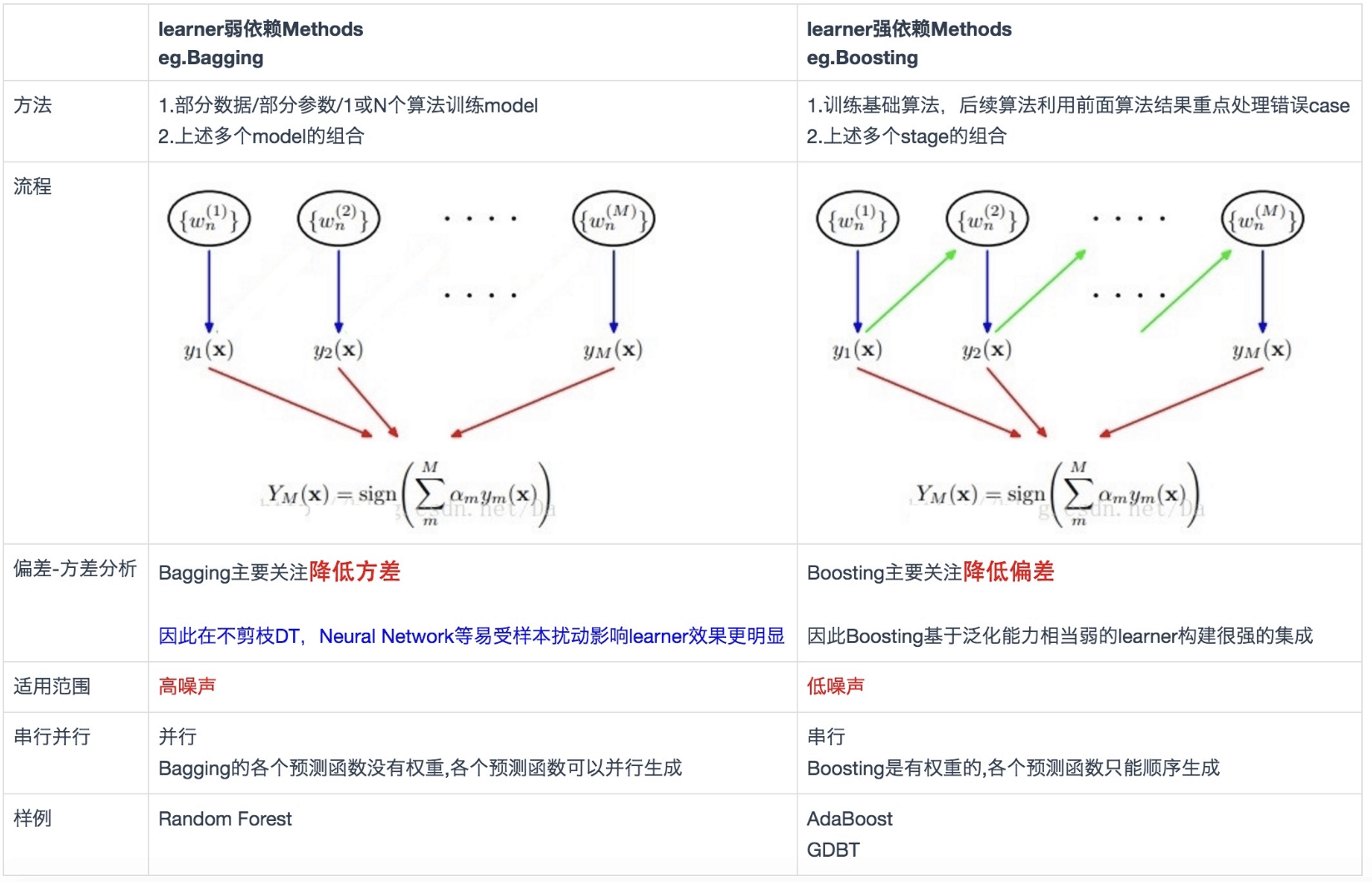
模型融合(Model Ensemble)是一种机器学习策略,它结合了多个模型的预测结果,以获得比单个模型更好的预测性能。模型融合的基本思想是通过集成学习(Ensemble Learning)的方式,利用一组模型的多样性,减少模型的偏差(Bias)和方差(Variance),从而提高模型的泛化能力。
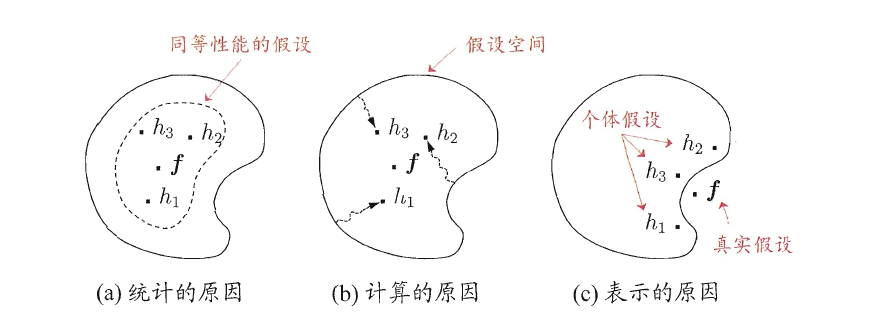
从统计方面看,由于学习任务的假设空间往往很大,可能有多个假设在训练集上达到同样性能,此时若使用单学习器可能因误选而导致泛化性能不佳,结合多个学习器则会减小这一风险
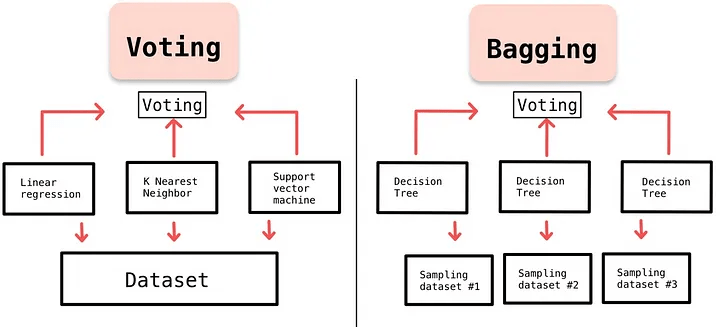
模型融合中的模型可以是同质的,也可以是异质的:
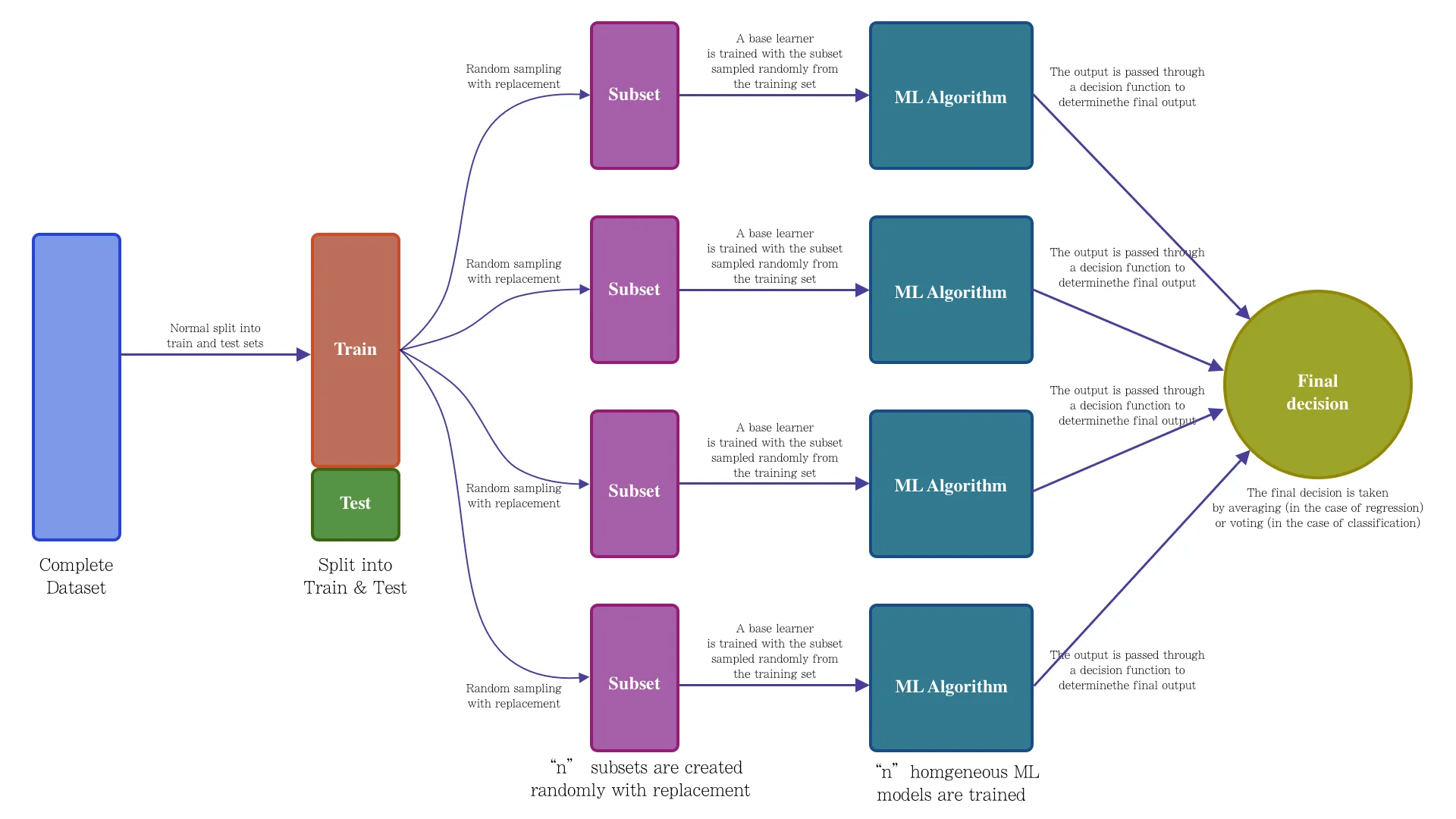
同质模型(Base Learner):这些模型都是同一类型的,例如都是决策树或者都是神经网络。同质模型通常通过引入随机性来增加多样性,例如在随机森林中,我们通过自助采样(Bootstrap Sampling)和随机特征选择来生成多个不同的决策树
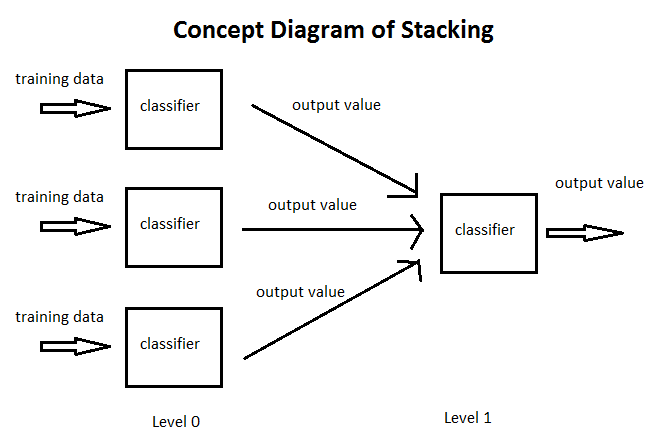
异质模型(Component Learner):这些模型是不同类型的,例如一部分是决策树,一部分是神经网络。异质模型通常通过结合不同类型模型的优点来增加多样性,例如在堆叠泛化(Stacking)中,我们可以使用不同类型的模型作为基模型,然后使用另一个模型(元模型)来结合这些基模型的预测结果。
# GW: ML
简单说来,我们信奉几个信条:
群众的力量是伟大的,集体智慧是惊人的
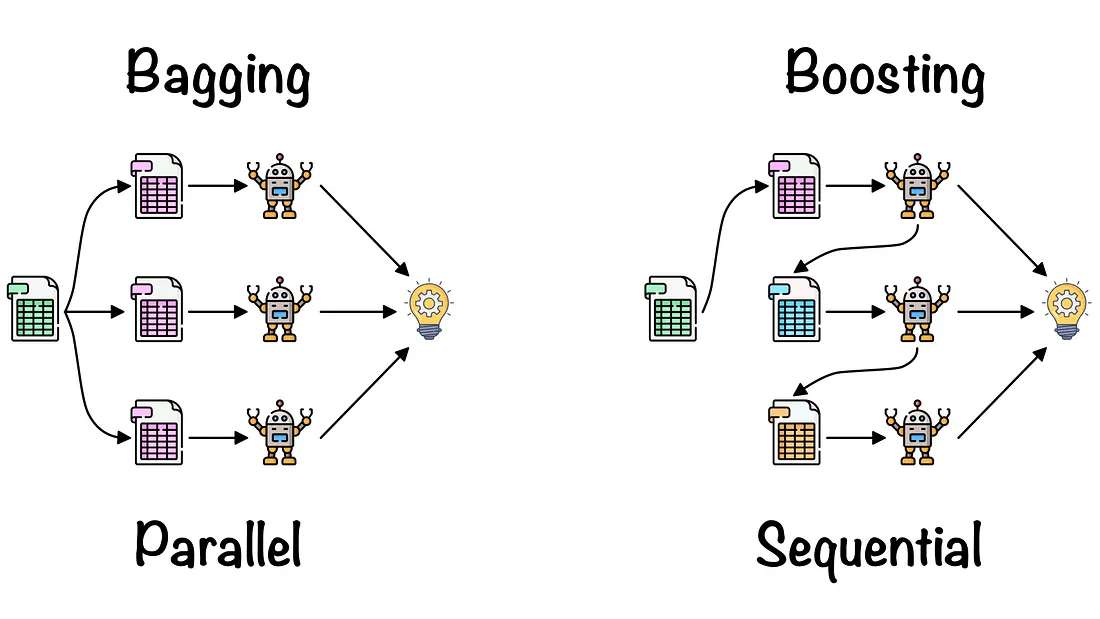
投票(Voting)
装袋(Bagging)
随机森林(Random forest)
站在巨人的肩膀上,能看得更远
堆叠(Stacking)
Blending
一万小时定律
Boosting
模型融合的常见方法包括投票(Voting)、装袋(Bagging)、提升(Boosting)和堆叠(Stacking)。这些方法都有各自的优点和适用场景,例如投票和装袋可以减少模型的方差,提升可以减少模型的偏差,堆叠泛化可以结合多个模型的优点。
总的来说,模型融合是一种强大的机器学习策略,它可以有效地提高模型的预测性能,特别是在处理复杂的非线性问题时。
模型融合若想取得较好的效果,需要个体学习器“好而不同”。
“好”指的是个体学习器需要有一定的准确性,“不同”指的是学习器间具有差异。模型的不同可以体现在:
不同训练数据:数据集使用比例(e.g. bootstrap、不同特征)、预处理方法(缺失值填补、特征工程)
不同模型结构:RF、XGBoost、LightGBM、CNN、LSTM等
不同超参数:随机种子数、权重初始化、收敛相关参数(如学习率、batch size、epoch、early stop)、损失函数、子采样比例等
下图中西瓜书中的实例对该问题进行了说明,采用简单投票的方法确定融合模型的结果,图(a)子模型满足“好”和“不同”两个条件,图(b)中子模型不满足“不同”的条件,图(c)子模型不满足“好”的条件。
# GW: ML
简单说来,我们信奉几个信条:
群众的力量是伟大的,集体智慧是惊人的
投票(Voting)
装袋(Bagging)
随机森林(Random forest)
站在巨人的肩膀上,能看得更远
堆叠(Stacking)
Blending
一万小时定律
Boosting
bootstrapped
Voting: 单个模型很难控制过拟合。
Bagging:模型效果不好的原因是过拟合?
# GW: ML
简单说来,我们信奉几个信条:
群众的力量是伟大的,集体智慧是惊人的
投票(Voting)
装袋(Bagging)
随机森林(Random forest)
站在巨人的肩膀上,能看得更远
堆叠(Stacking)
Blending
一万小时定律
Boosting
# GW: ML
简单说来,我们信奉几个信条:
群众的力量是伟大的,集体智慧是惊人的
投票(Voting)
装袋(Bagging)
随机森林(Random forest)
站在巨人的肩膀上,能看得更远
堆叠(Stacking)
Blending
一万小时定律
Boosting
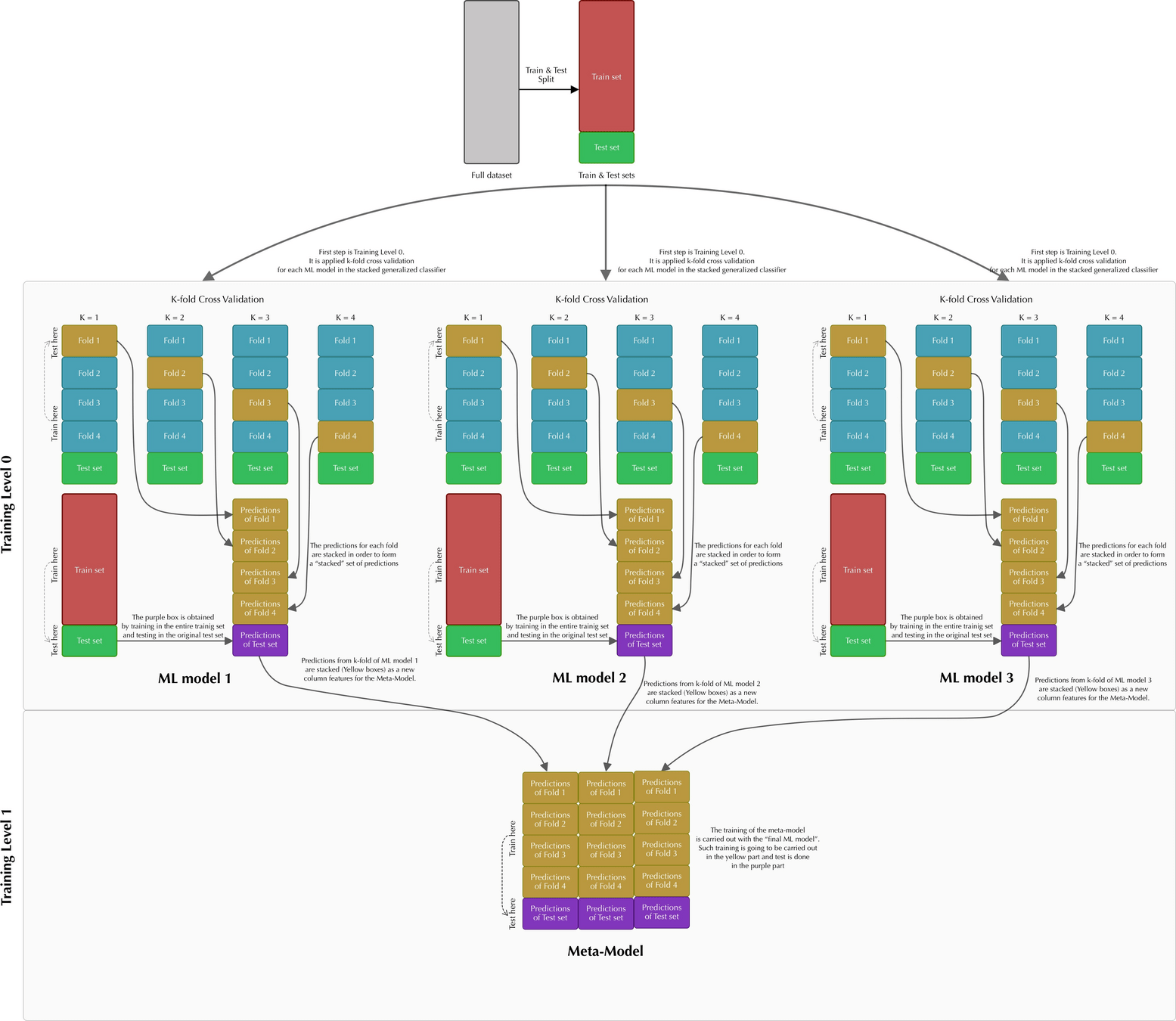
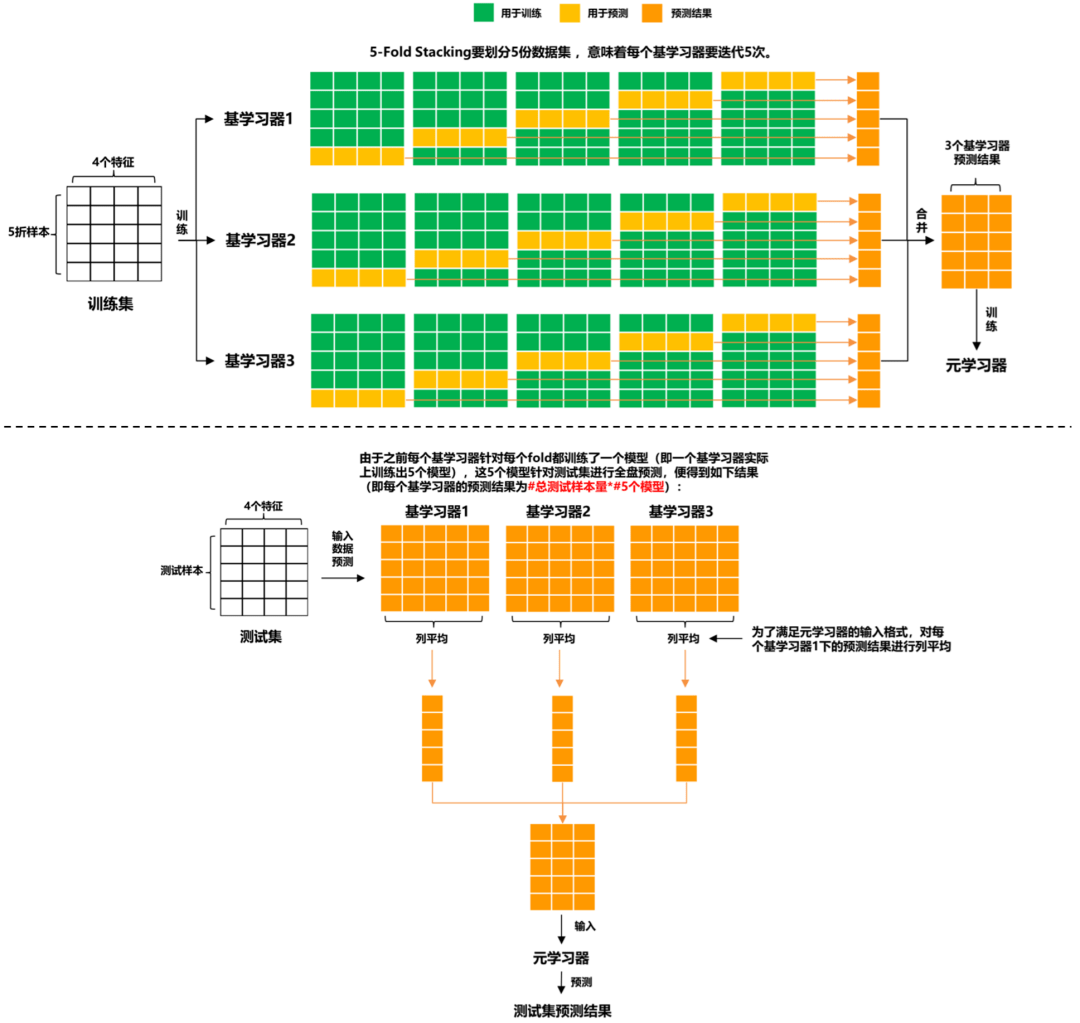
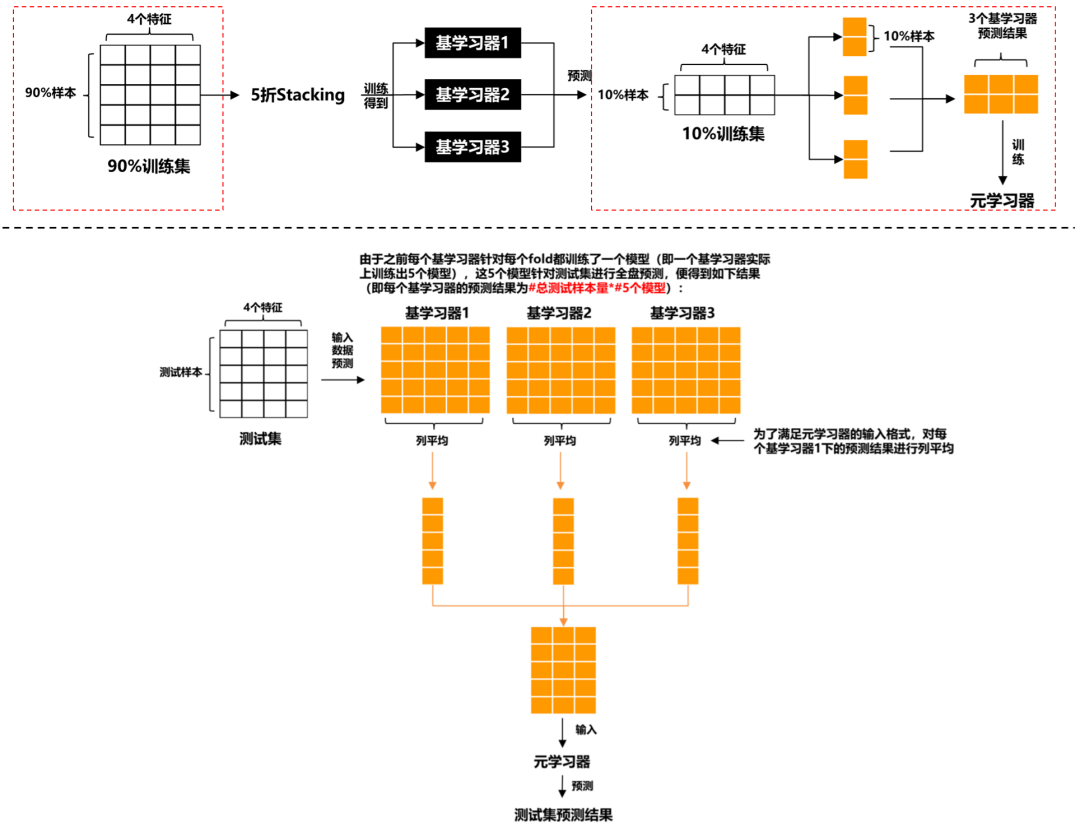
Stacking
# GW: ML
简单说来,我们信奉几个信条:
群众的力量是伟大的,集体智慧是惊人的
投票(Voting)
装袋(Bagging)
随机森林(Random forest)
站在巨人的肩膀上,能看得更远
堆叠(Stacking)
Blending
一万小时定律
Boosting
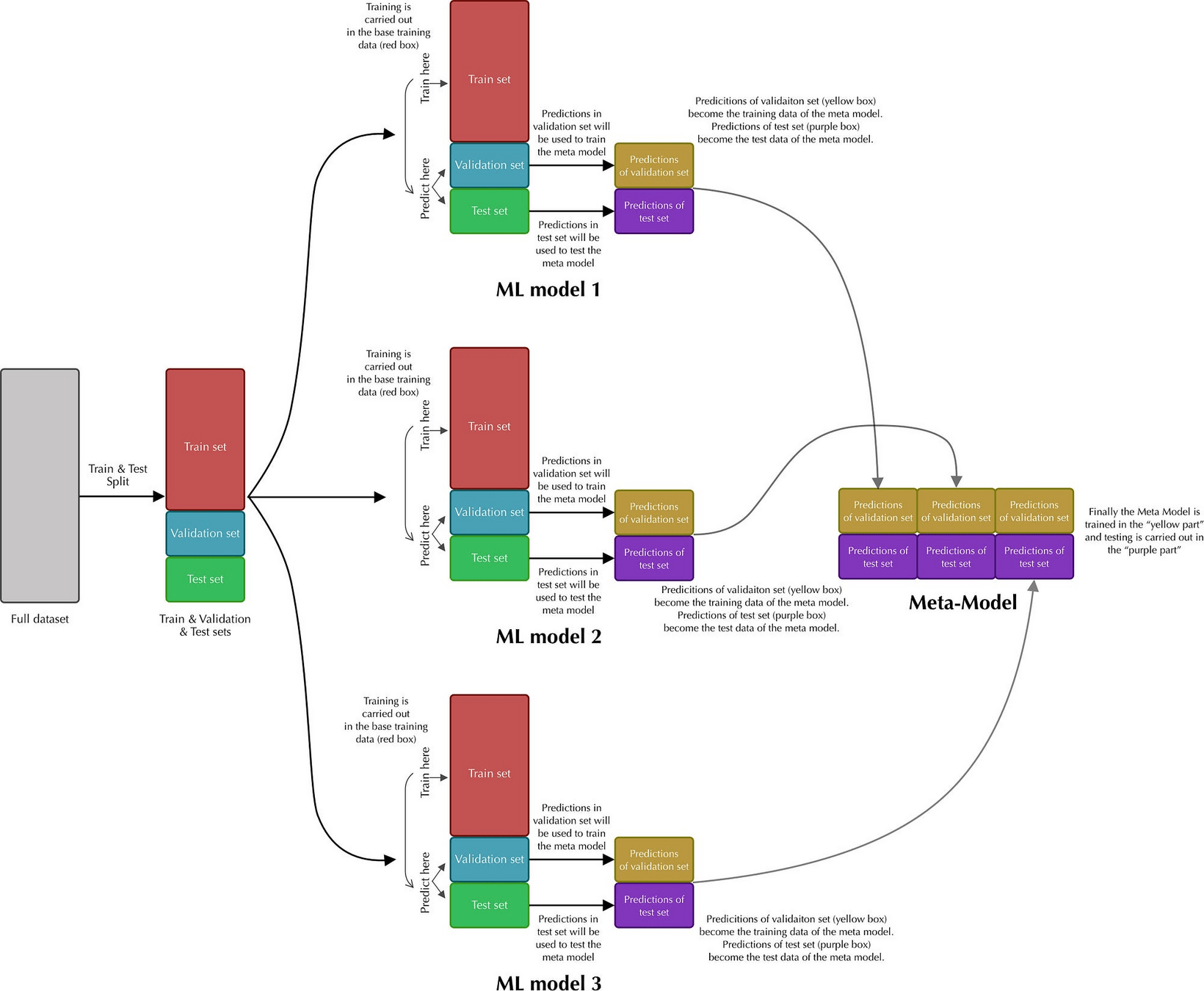
Blending
# GW: ML
简单说来,我们信奉几个信条:
群众的力量是伟大的,集体智慧是惊人的
投票(Voting)
装袋(Bagging)
随机森林(Random forest)
站在巨人的肩膀上,能看得更远
堆叠(Stacking)
Blending
一万小时定律
Boosting
Blending
考得不好的原因是什么?
还不够努力,练习题要多次学习
重复迭代和训练
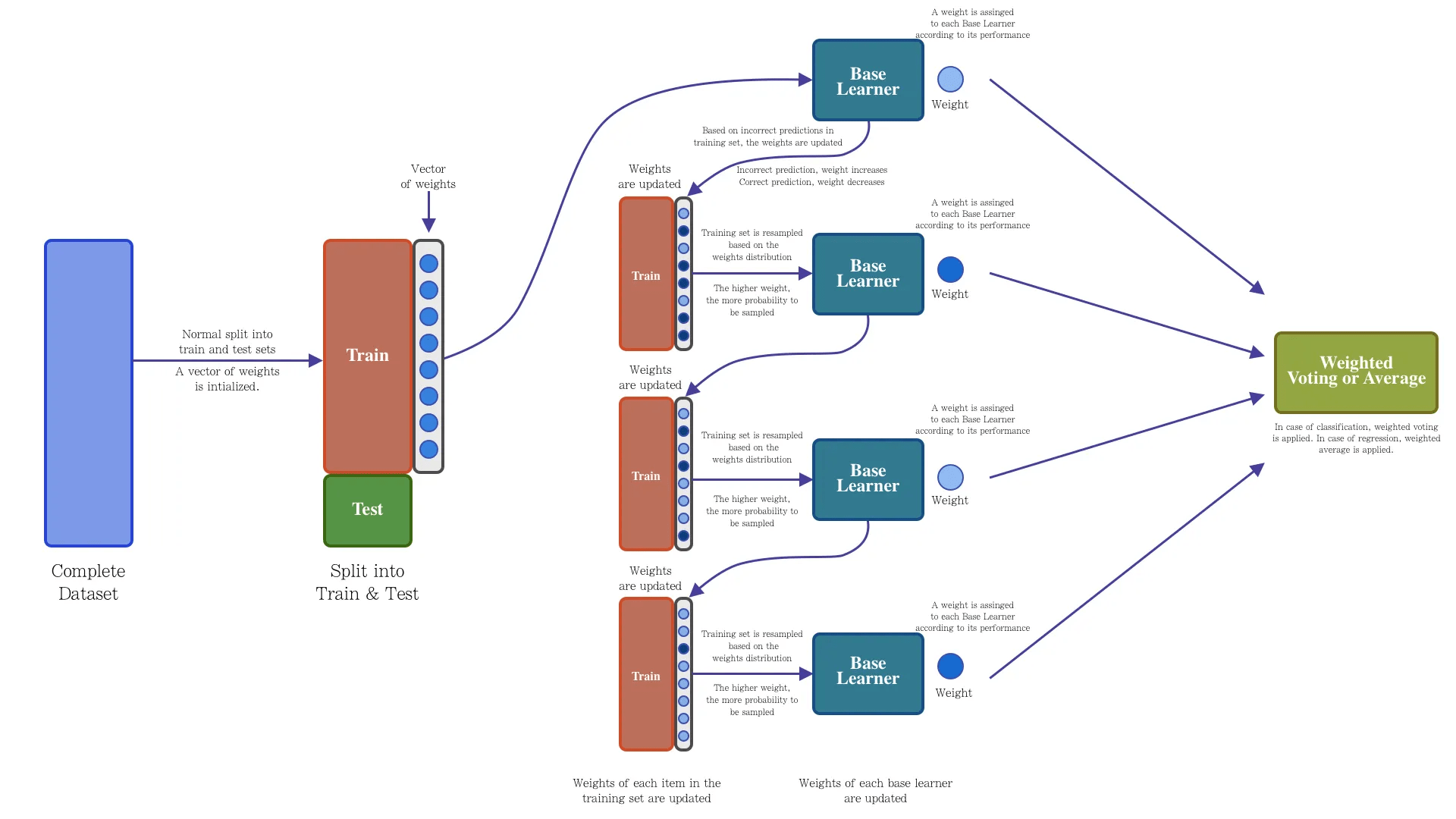
时间分配要合理,要多练习之前做错的题
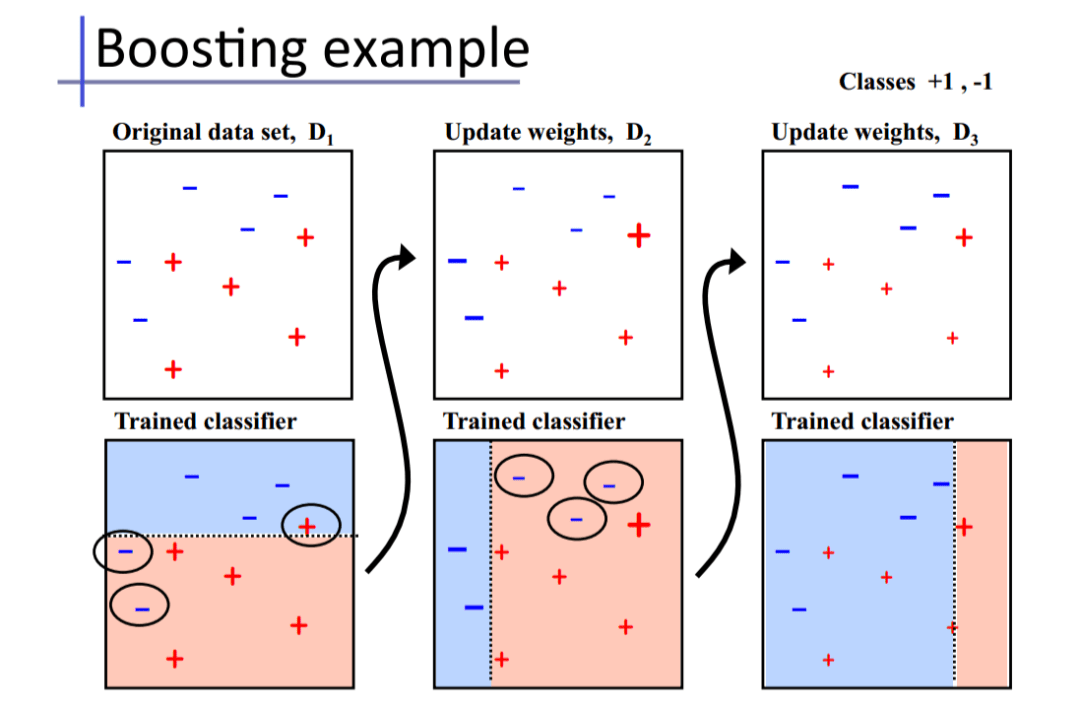
每次分配给预测错的样本更高的权重
我不聪明,但是脚踏实地,用最简单的知识不断积累,称为专家
最简单的分类器的叠加
# GW: ML
简单说来,我们信奉几个信条:
群众的力量是伟大的,集体智慧是惊人的
投票(Voting)
装袋(Bagging)
随机森林(Random forest)
站在巨人的肩膀上,能看得更远
堆叠(Stacking)
Blending
一万小时定律
Boosting
Blending
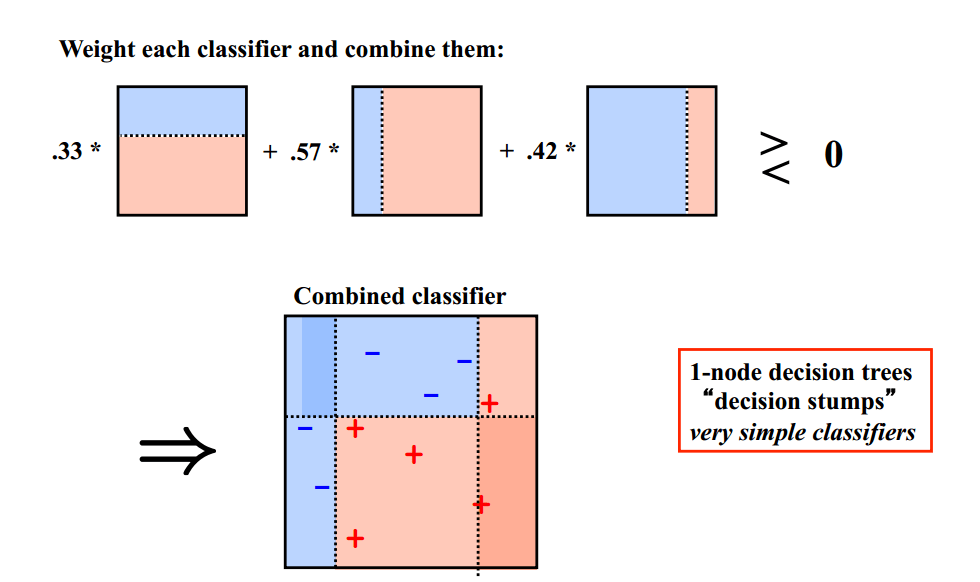
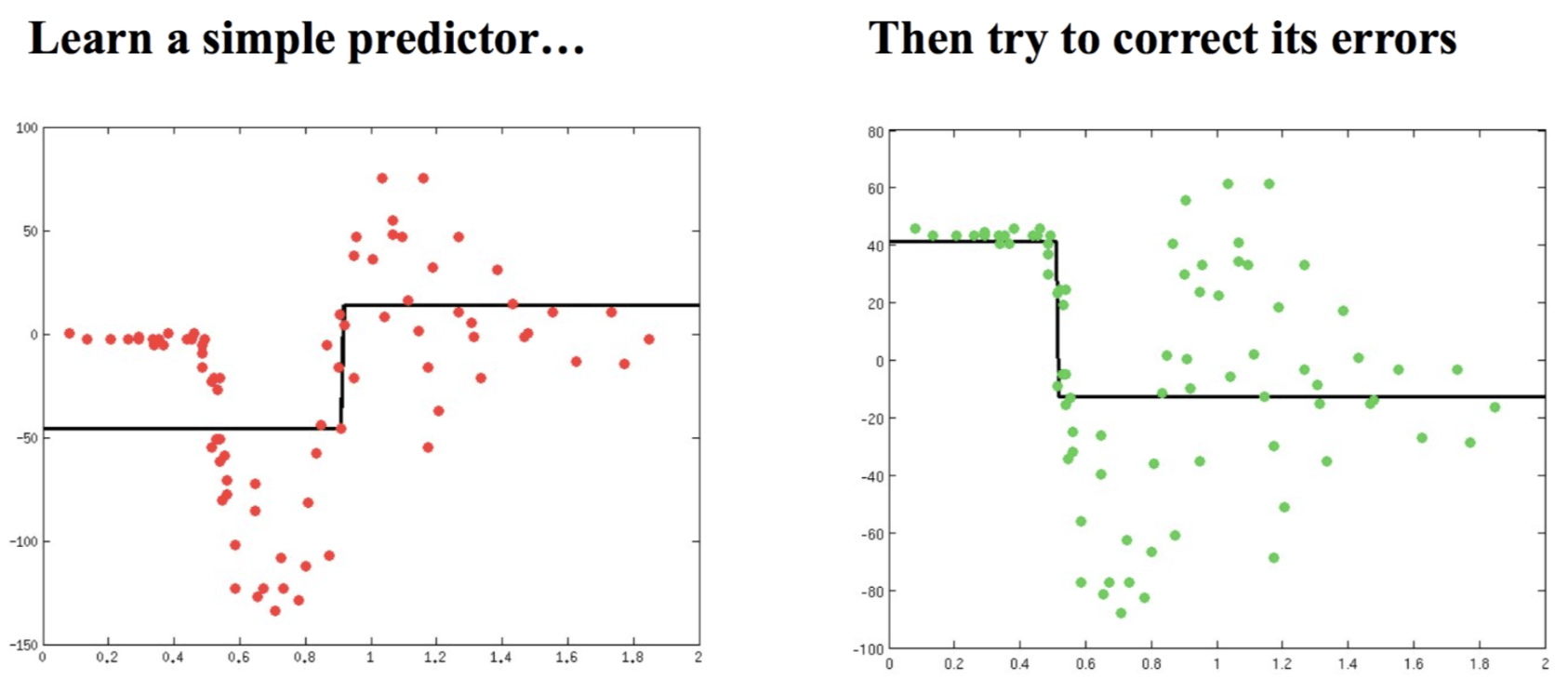
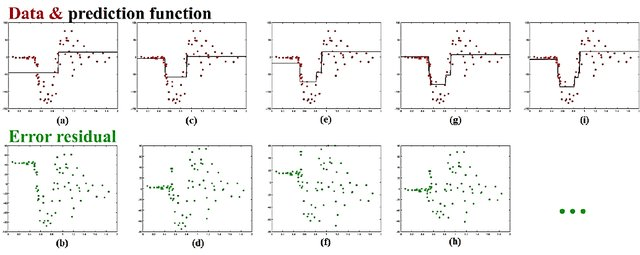
基础思想:Boosting是一种串行的工作机制,即个体学习器的训练存在依赖关系,必须一步一步序列化进行。Boosting是一个序列化的过程,后续模型会矫正之前模型的预测结果。也就是说,之后的模型依赖于之前的模型。
其基本思想是:增加前一个基学习器在训练训练过程中预测错误样本的权重,使得后续基学习器更加关注这些打标错误的训练样本,尽可能纠正这些错误,一直向下串行直至产生需要的T个基学习器,Boosting最终对这T个学习器进行加权结合,产生学习器委员会。
Adaboost
# GW: ML
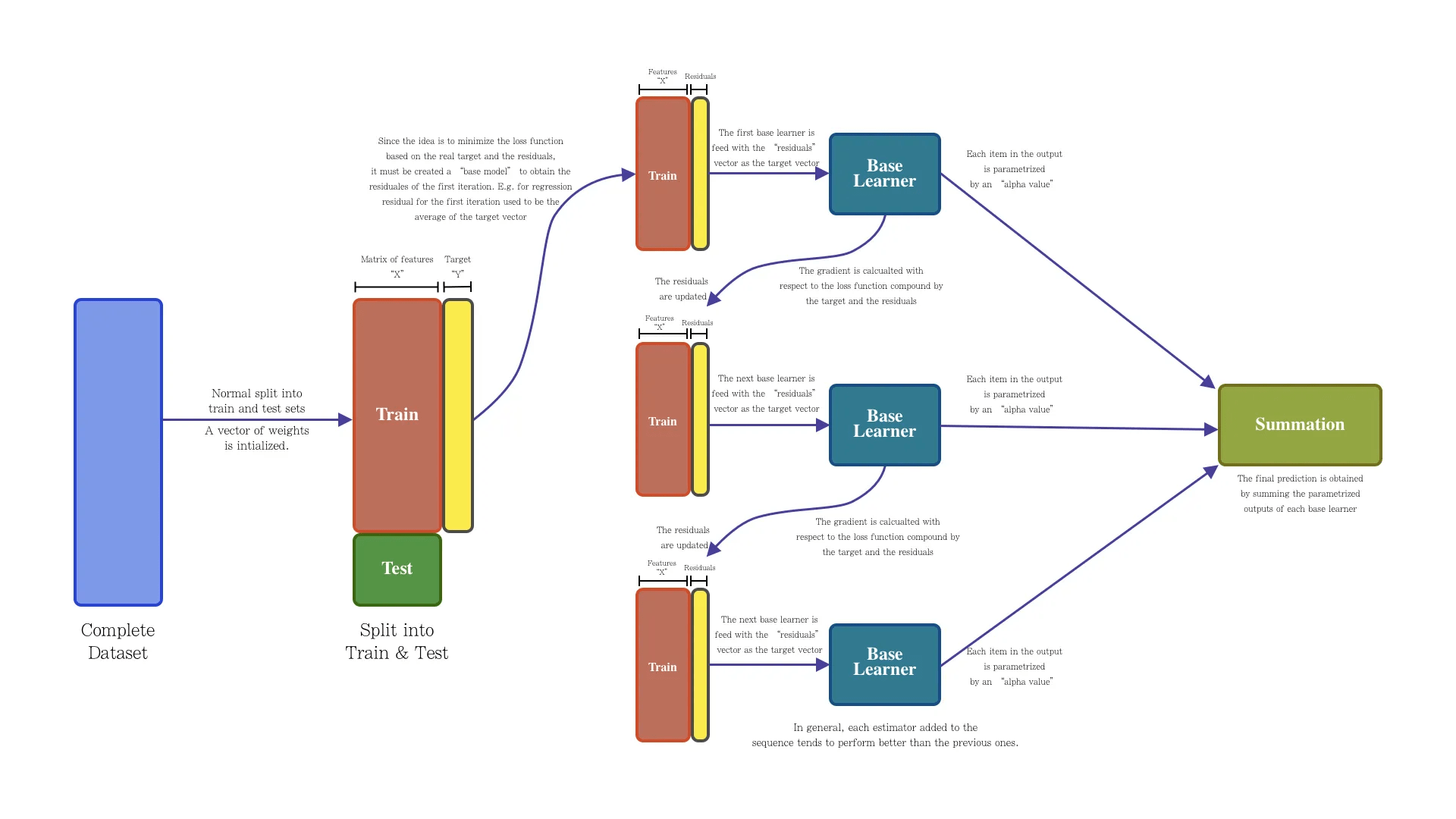
Gradient Boosting Tree
简单说来,我们信奉几个信条:
群众的力量是伟大的,集体智慧是惊人的
投票(Voting)
装袋(Bagging)
随机森林(Random forest)
站在巨人的肩膀上,能看得更远
堆叠(Stacking)
Blending
一万小时定律
Boosting
和 Adaboost 思路类似,解决回归问题
# GW: ML
Blending
Ensemble Methods: Foundations and Algorithms by Ralf Herbrich and Thore Graepel
# Homework
Repo of the course: https://github.com/iphysresearch/GWData-Bootcamp
通向自我实现之路:Kaggle
By He Wang
引力波数据探索:编程与分析实战训练营。课程网址:https://github.com/iphysresearch/GWData-Bootcamp




