








































































He Wang PRO
Knowledge increases by sharing but not by saving.
第 4 部分 深度学习基础
主讲老师:王赫
2023/12/27
ICTP-AP, UCAS
深度学习技术概述与神经网络基础
# GW: DL
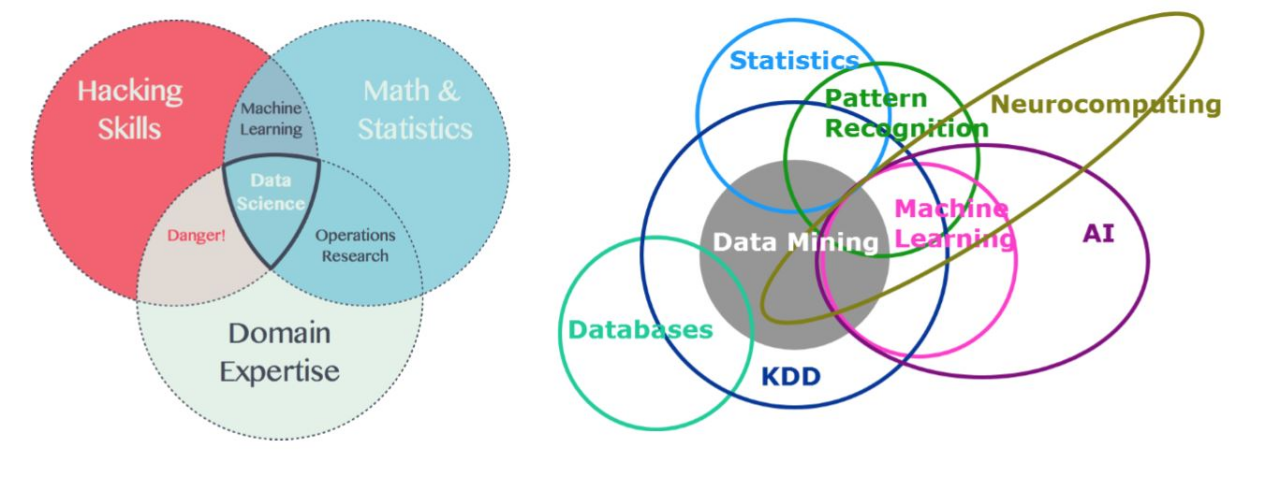
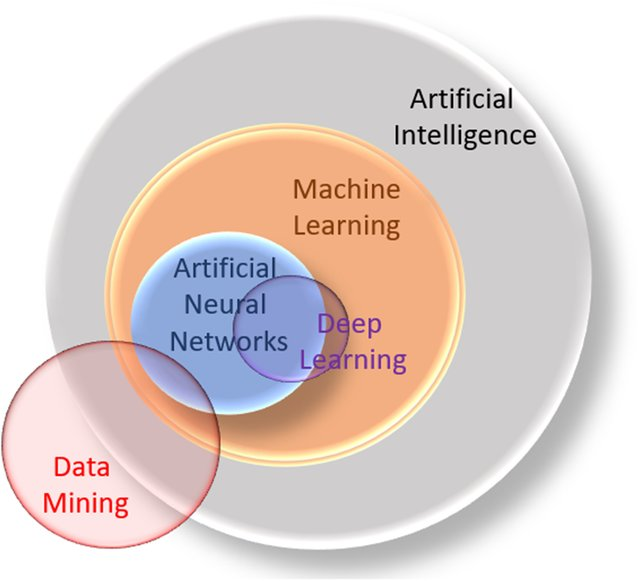
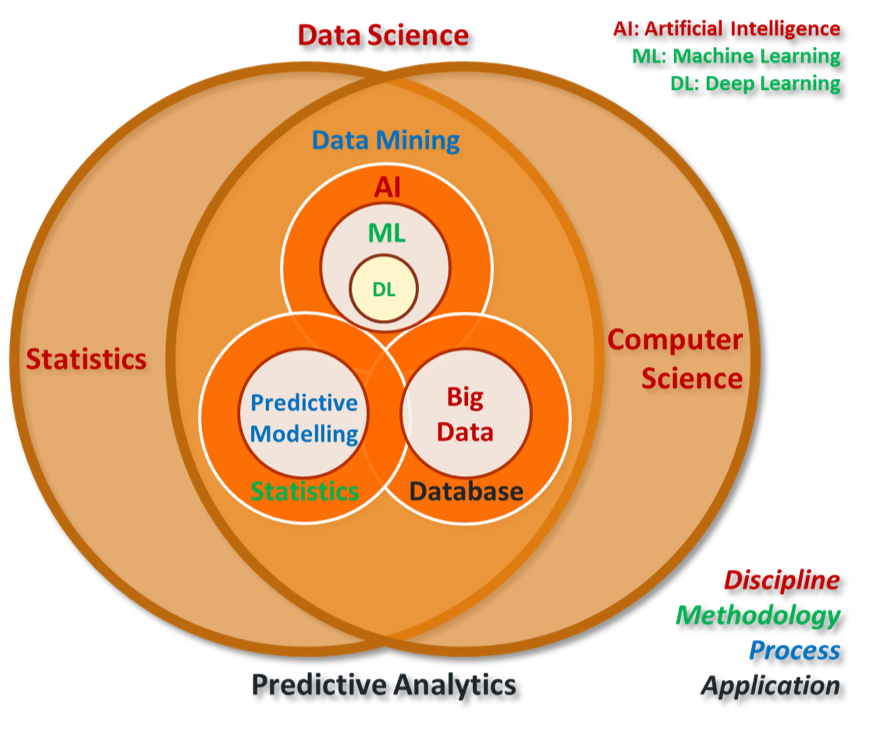
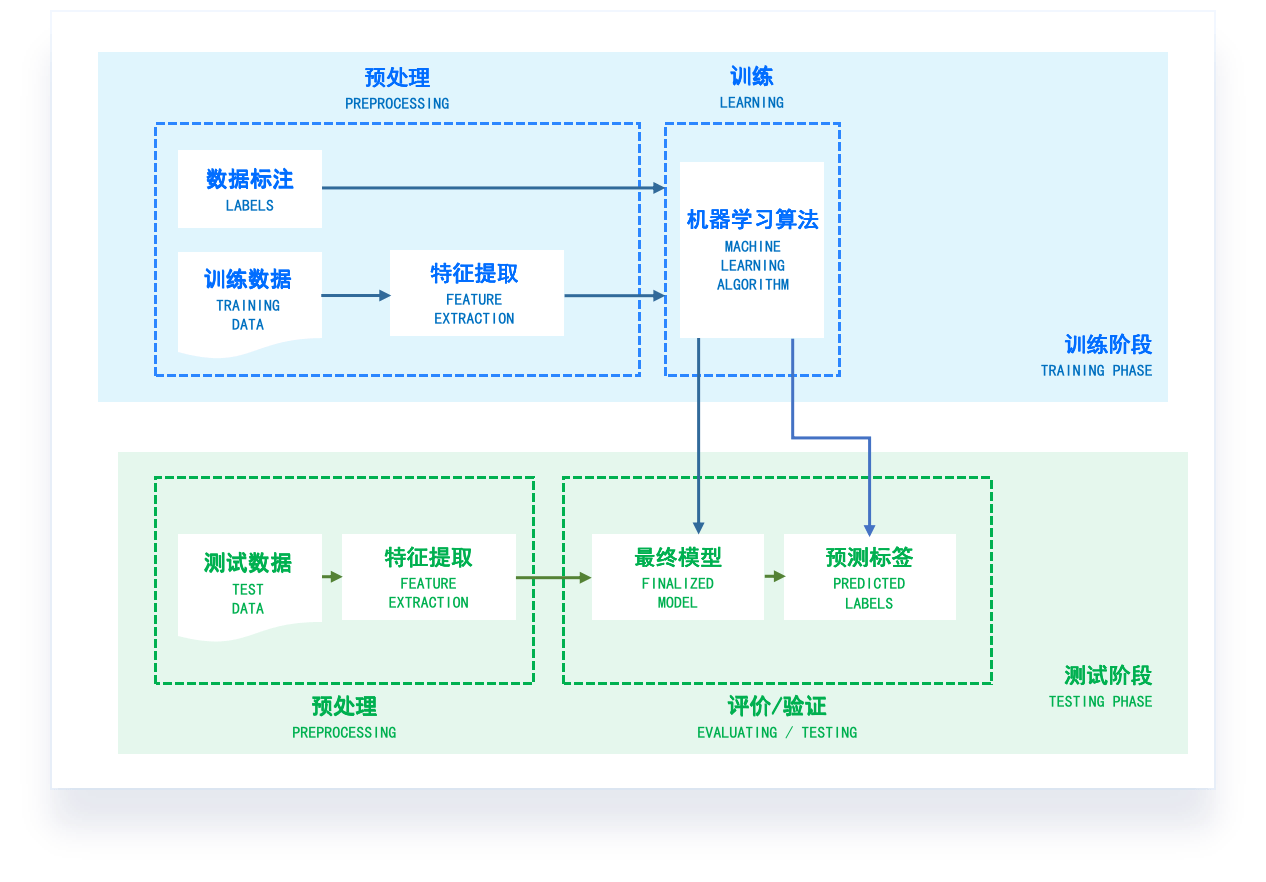
Knowledge Discovery in Database, KDD
# GW: DL
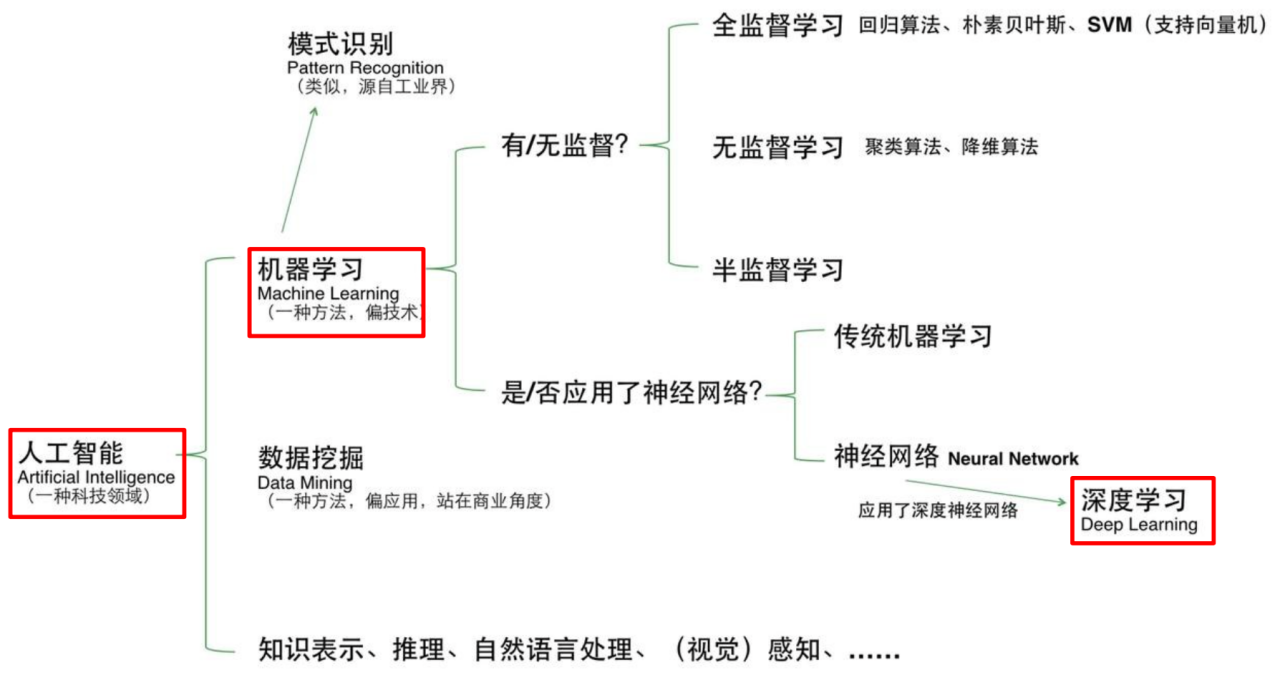
人工智能(Artificial Intelligence) 使一部机器像人一样进行感知、认知、决策、执行的人工程序或系统。
# GW: DL
# GW: DL
# GW: DL
# GW: DL
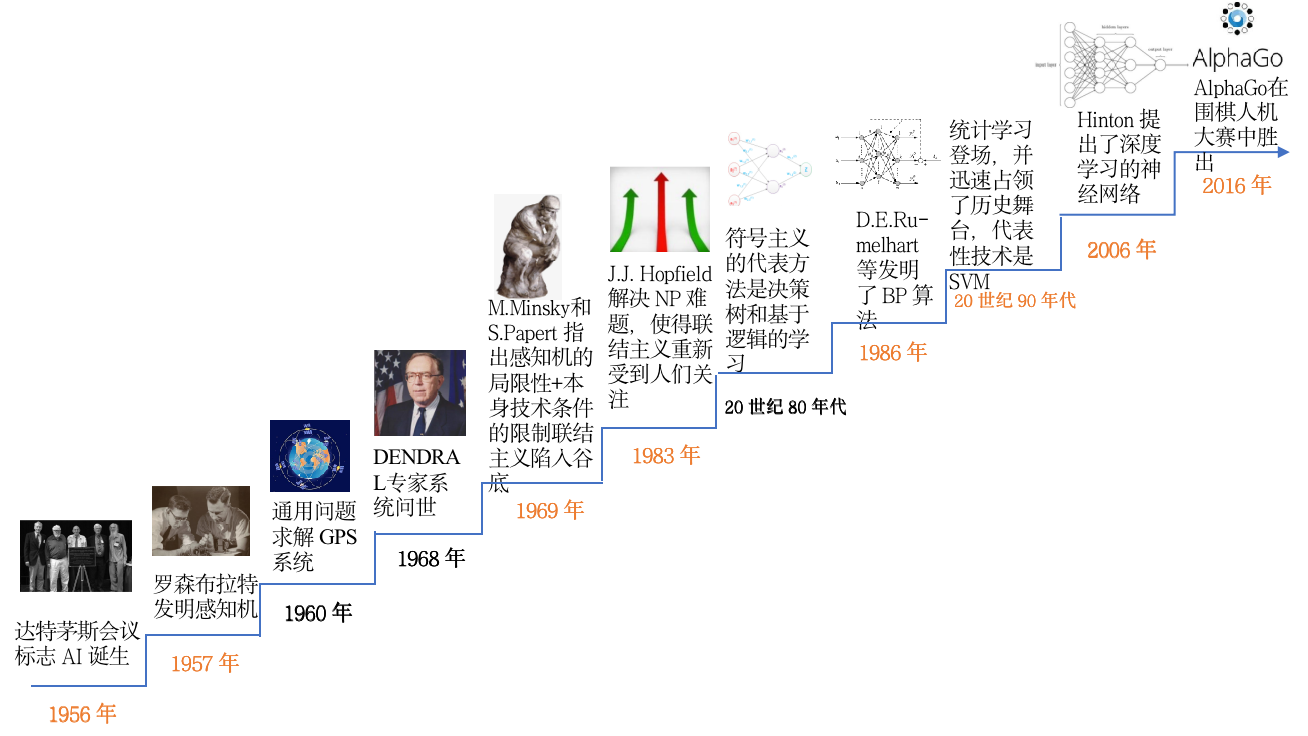
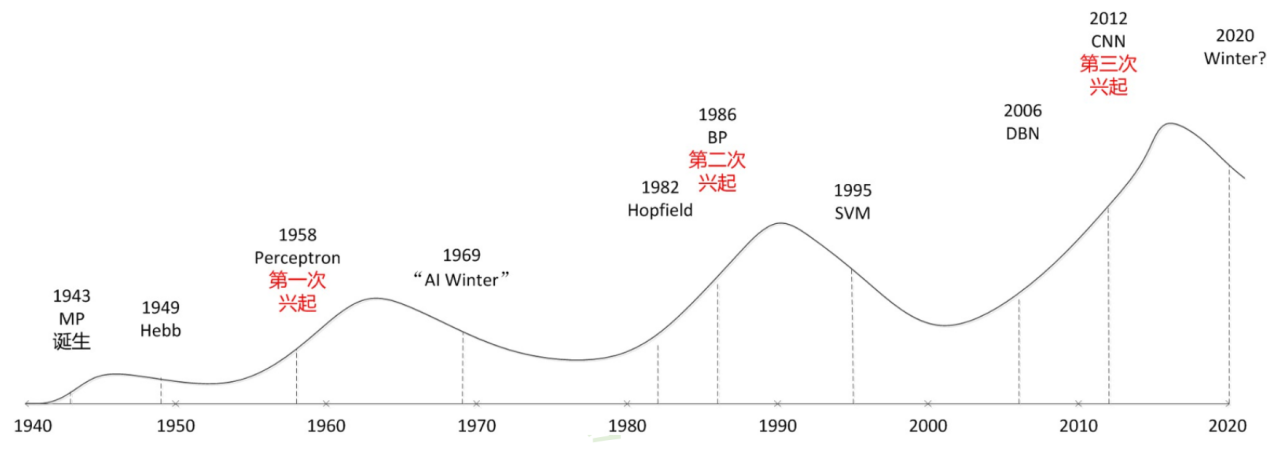
1949年,心理学家提出了突触联系强度可变的设想。
# GW: DL
# GW: DL
# GW: DL
# GW: DL
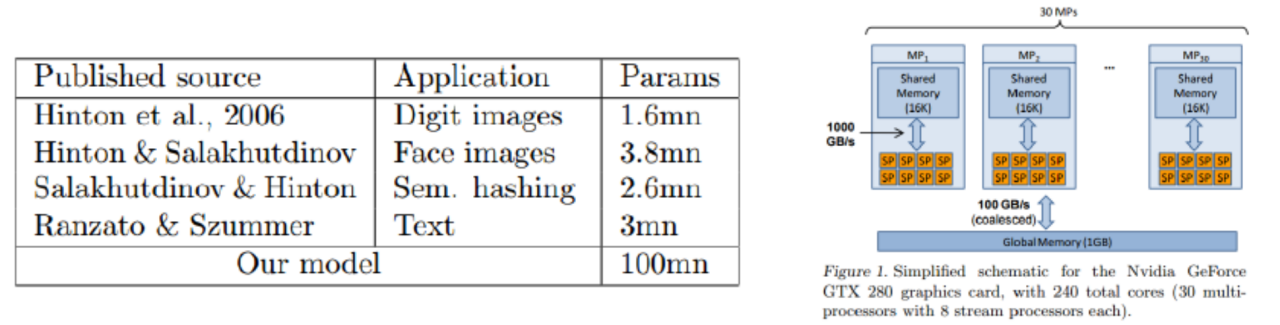
2003 年,Yann LeCun 等人在 NEC 实验室的使用CNN进行人脸检测。
# GW: DL
在90年代,人工神经网络缺少严格的数学理论支撑,统计学习大发展。 Vapnik提出支持向量机(SVM),改进了感知器的一些缺陷(例如创建灵活的特征而不是手编的非适应的特征)。它同样解决了线性不可分问题,但是对比神经网络有全方位优势:
SVM (support vector machines)
# GW: DL
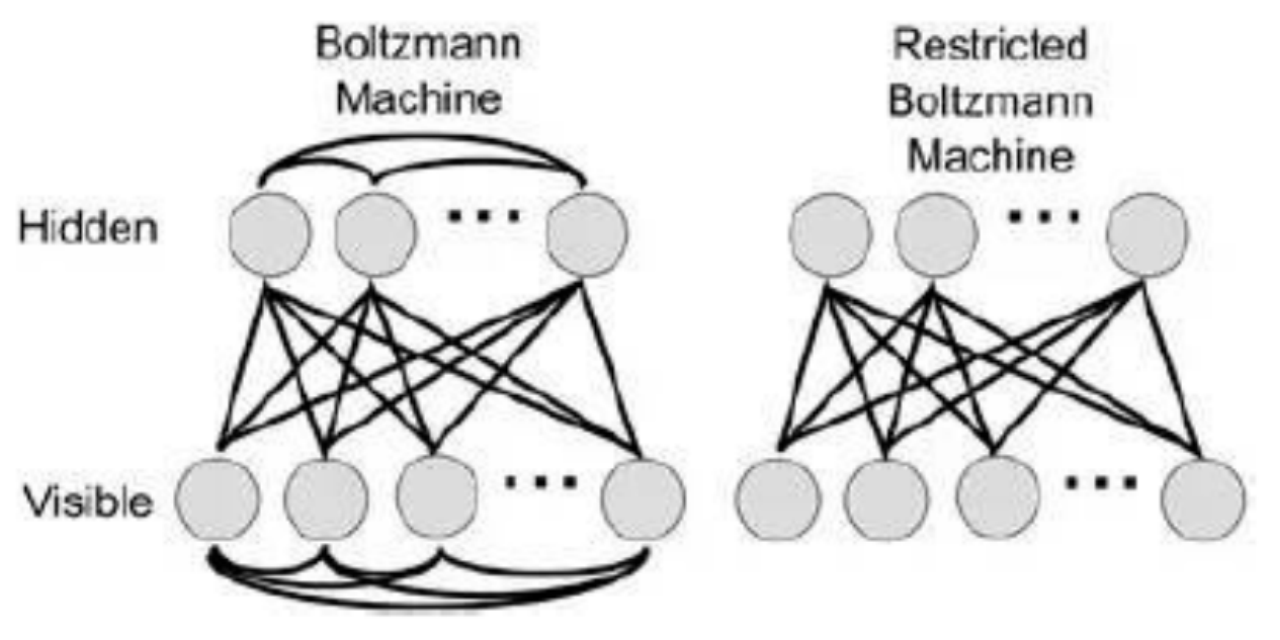
被 Hinton 首次定义为深度学习过程
# GW: DL
# GW: DL
# GW: DL
# GW: DL
# GW: DL
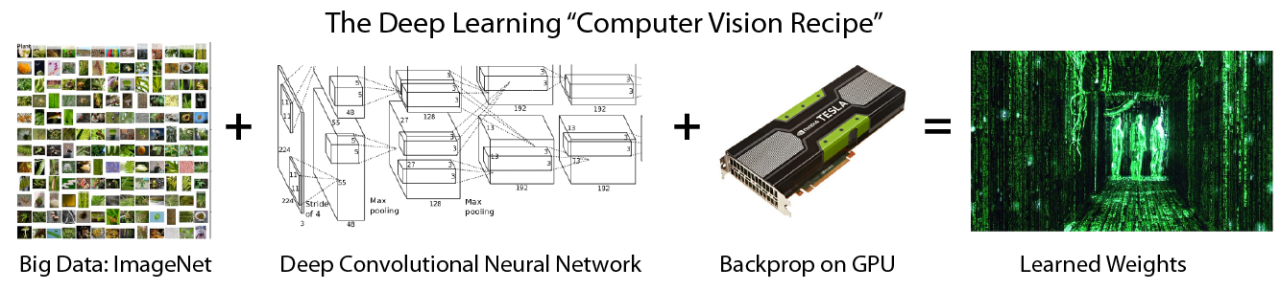
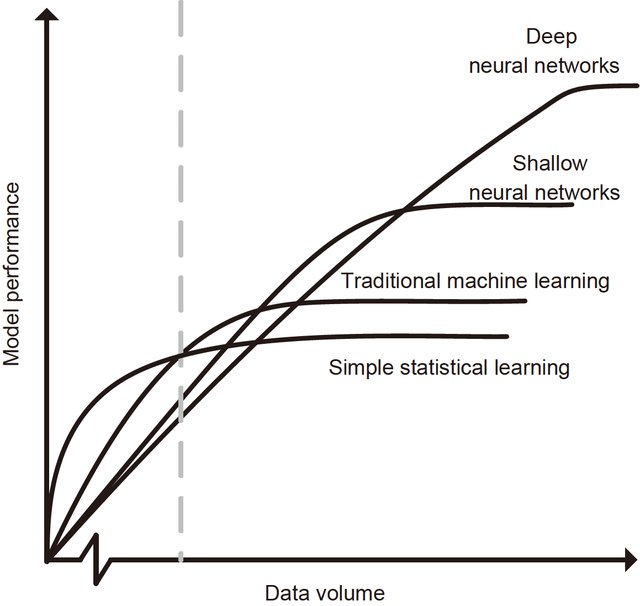
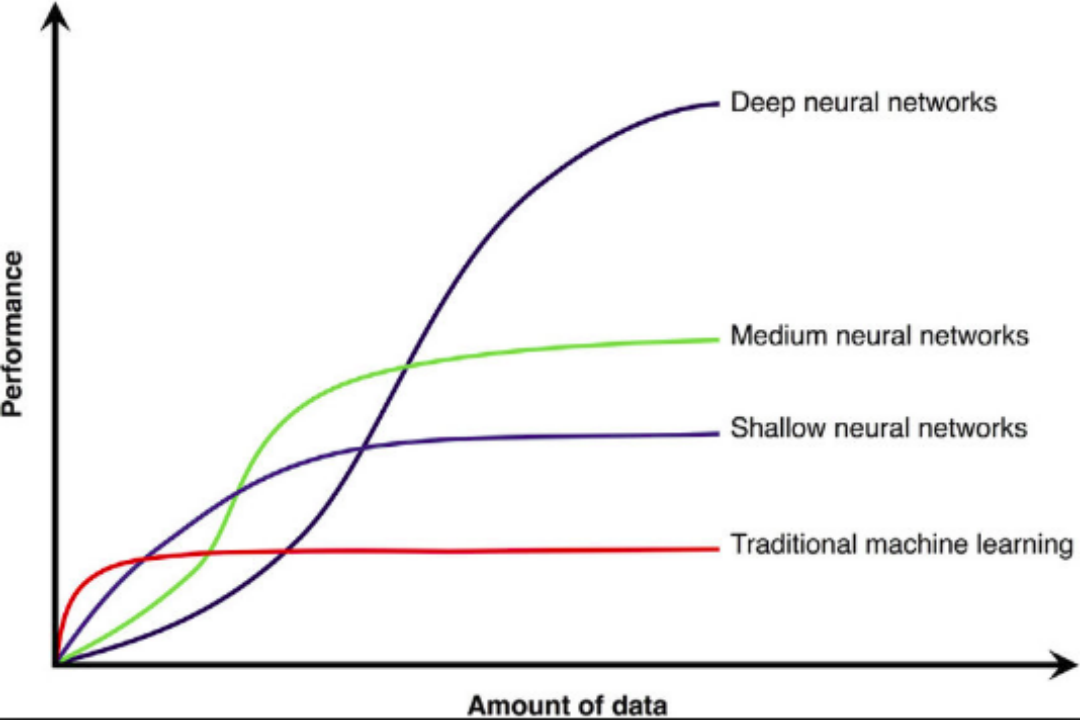
大数据(海量)
算法(神经网络)
计算力(GPU硬件)
算法(神经网络)
人工智能
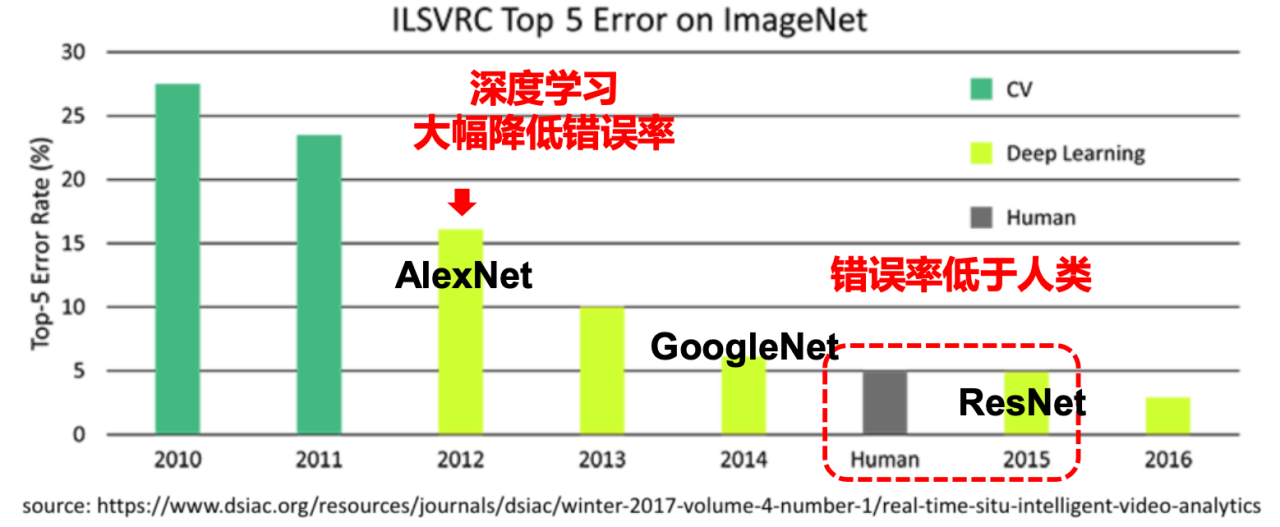
LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. “Deep Learning.” Nature 521, no. 7553 (May 1, 2015): 436–44. https://doi.org/10.1038/nature14539.
# GW: DL
# GW: DL
# GW: DL
# GW: DL
# GW: DL
局部边缘特征
面部细节特征
面部全局特征
# GW: DL
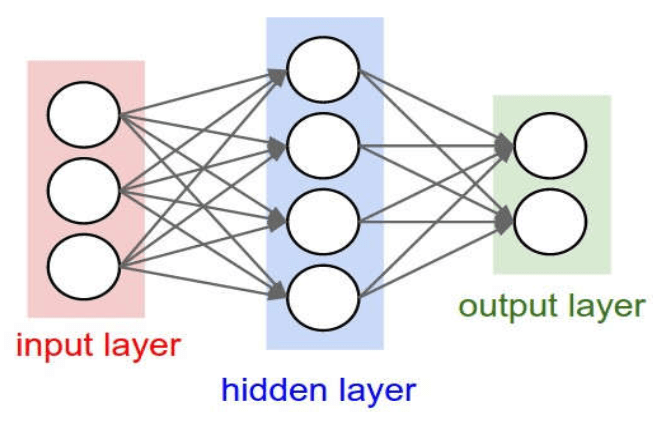
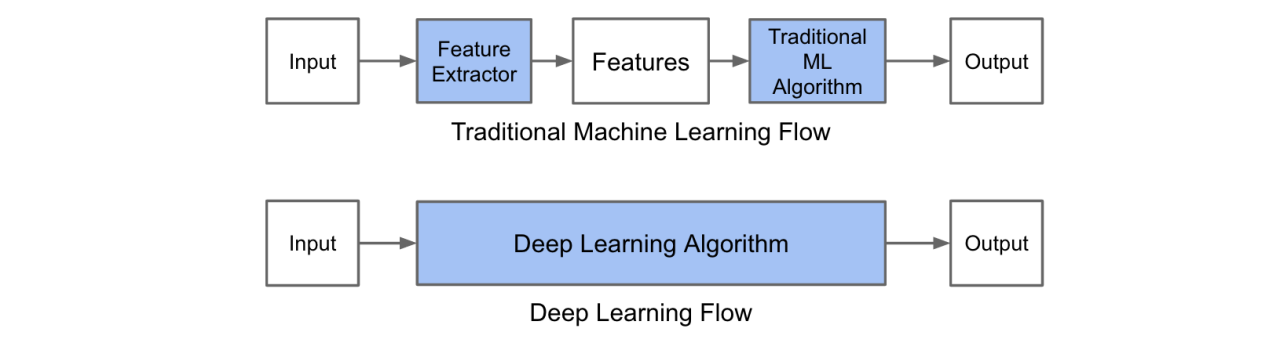
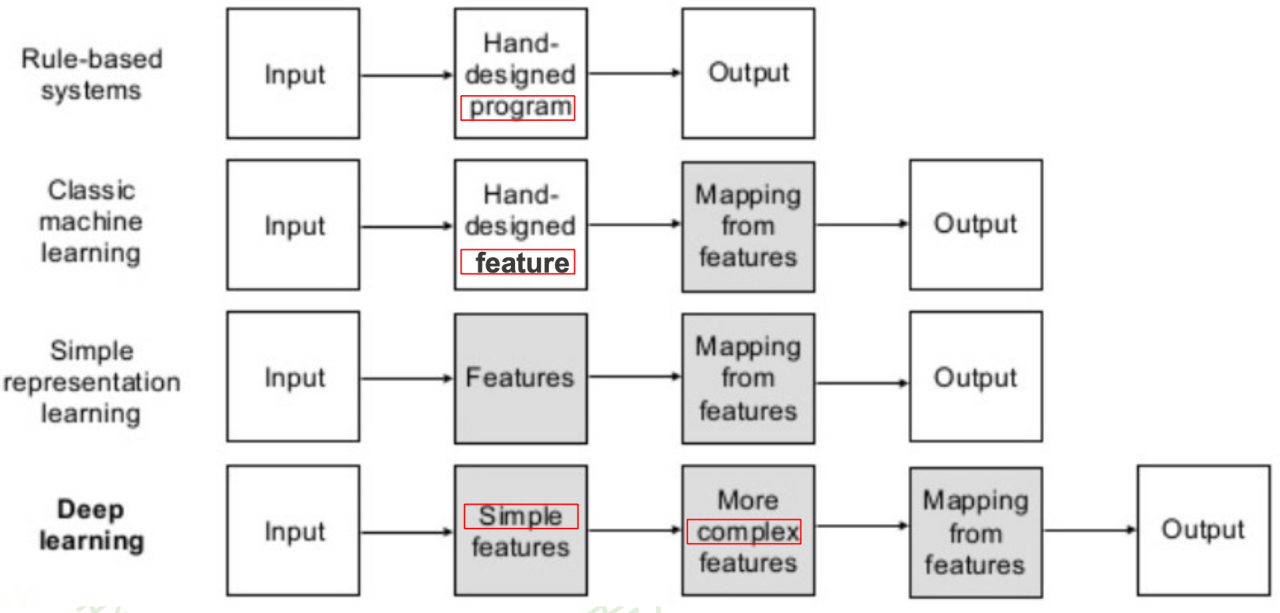
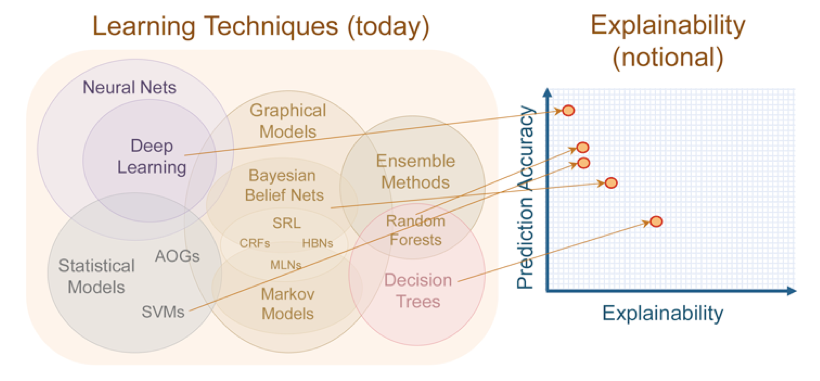
本质:通过构建多隐层的模型和海量训练数据(可为无标签数据),来学习更有用的特征,从而最终提升分类或预测的准确性。 “深度模型”是手段,“特征学习”是目的。
与浅层学习区别:
强调了模型结构的深度,通常有5-10多层的隐层节点;
明确突出了特征学习的重要性,通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,从而使分类或预测更加容易。与人工规则构造特征的方法相比,利用大数据来学习特征,更能够刻画数据的丰富内在信息。
# GW: DL
# GW: DL
书中例子多而形象,适合当做工具书
模型+策略+算法
(从概率角度)
机器学习
(公理化角度)
讲理论,不讲推导
经典,缺前沿
神书(从贝叶斯角度)
2k 多页,难啃,概率模型的角度出发
花书:DL 圣经
科普,培养直觉
# GW: DL
工程角度,无需高等
数学背景
参数非参数
+频率贝叶
斯角度
统计角度
统计方法集大成的书
讲理论,
不会讲推导
贝叶斯角度
DL 应用角度
贝叶斯角度完整介绍
大量数学推导
# GW: DL
优秀课程资源:
值得关注的公众号:
机器之心(顶流)
量子位(顶流)
新智元(顶流)
专知(偏学术)
微软亚洲研究院
将门创投
旷视研究院
DeepTech 深科技(麻省理工科技评论)
极市平台(技术分享)
爱可可-爱生活(微博、公众号、知乎、b站...)
陈光老师,北京邮电大学PRIS模式识别实验室
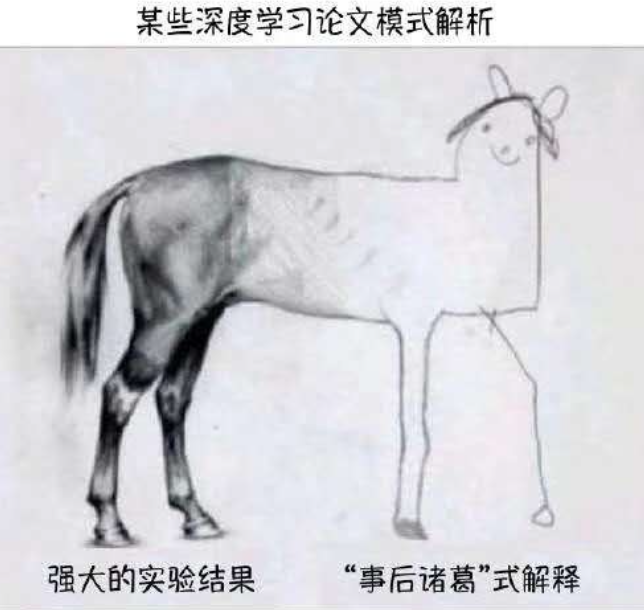
Despite all of the problems I have sketched, I don't think that we need to abandon deep learning... Rather, we need to reconceptualize it: not as a universal solvent, but simply as one tool among many
# GW: DL
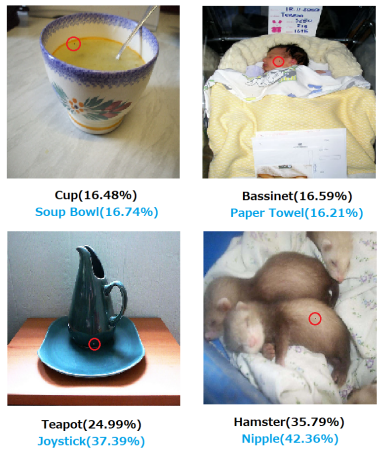
Su J, Vargas D V, Sakurai K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. (2019)
arXiv:1312.6199
vs
Jadhav et al. 2306.11797
# GW: DL
大众眼中的我们
工程师眼中的我们
数学家眼中的我们
我们眼中的自己
实际的我们
# GW: DL
from stackexchange
on the top activated
neurals
Conv-1
Conv-2
Conv-3
Dense-1
# GW: DL
# GW: DL
“鹦鹉”智能
“乌鸦”智能
# GW: DL
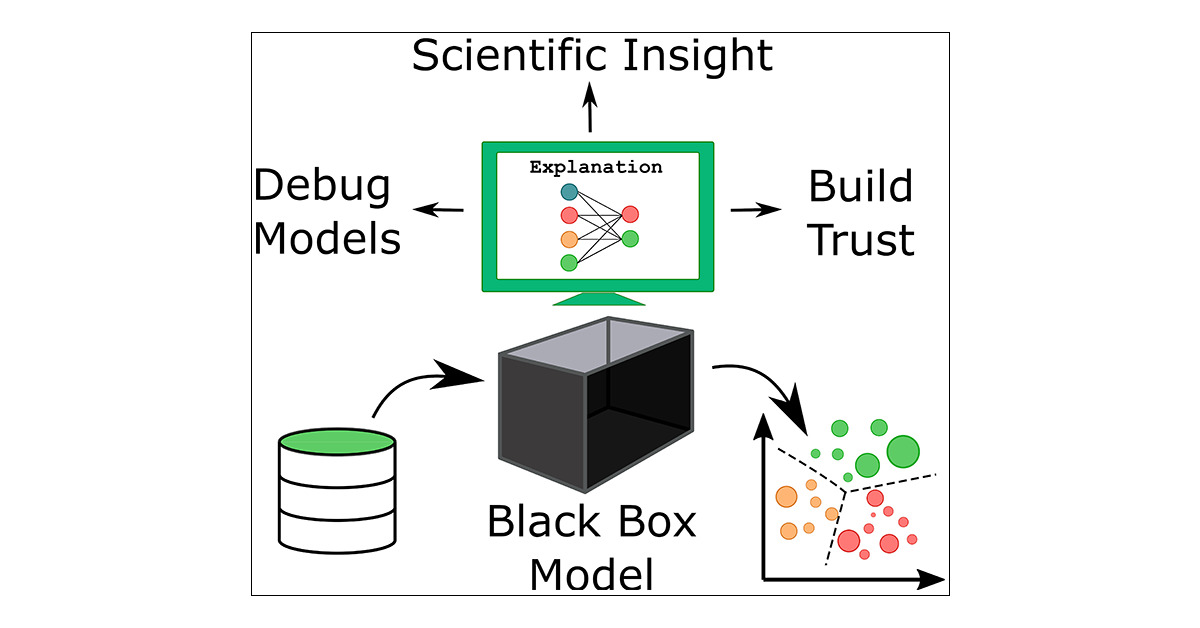
深度学习的“不能”
解释性的三个层次
“对症下药”(找得到)
知道那些特征输出有重要影响,出了问题准确快速纠错
不再“对牛弹琴”(看得懂)
双向:算法能被人的知识体系理解+利用和结合人类知识
稳定性低
可调试性差
参数不透明
机器偏见
增量性差
推理能力差
“站在巨人的肩膀上”(留得下)
知识得到有效存储、积累和复用
\(\rightarrow\) 越学越聪明
# GW: DL
# GW: DL
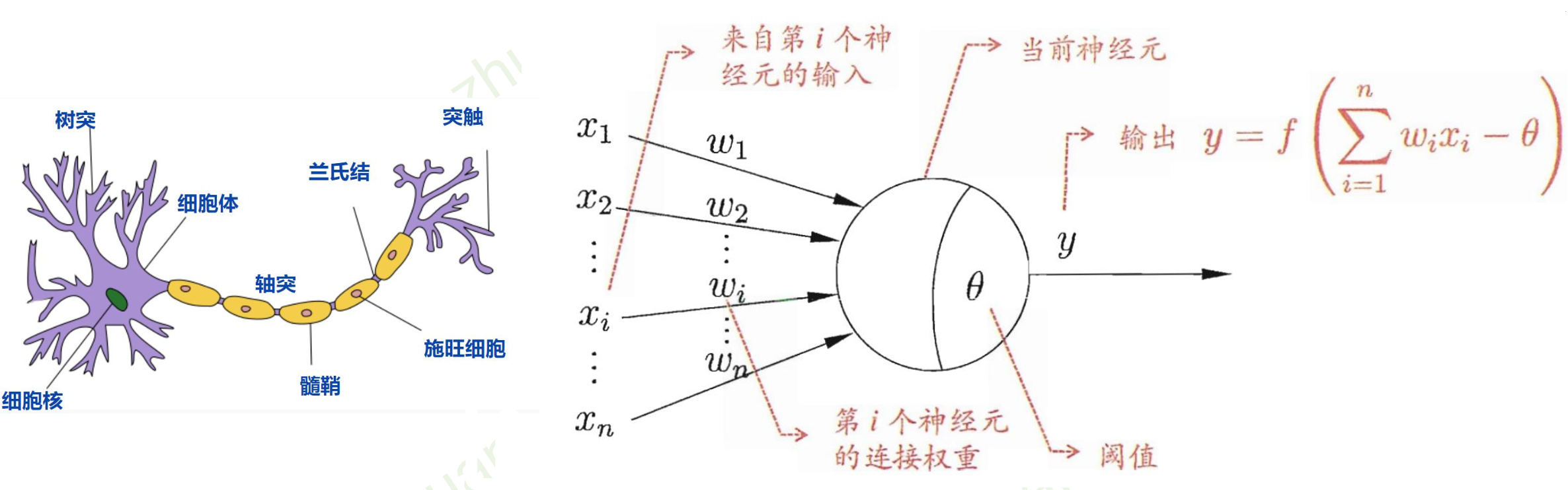
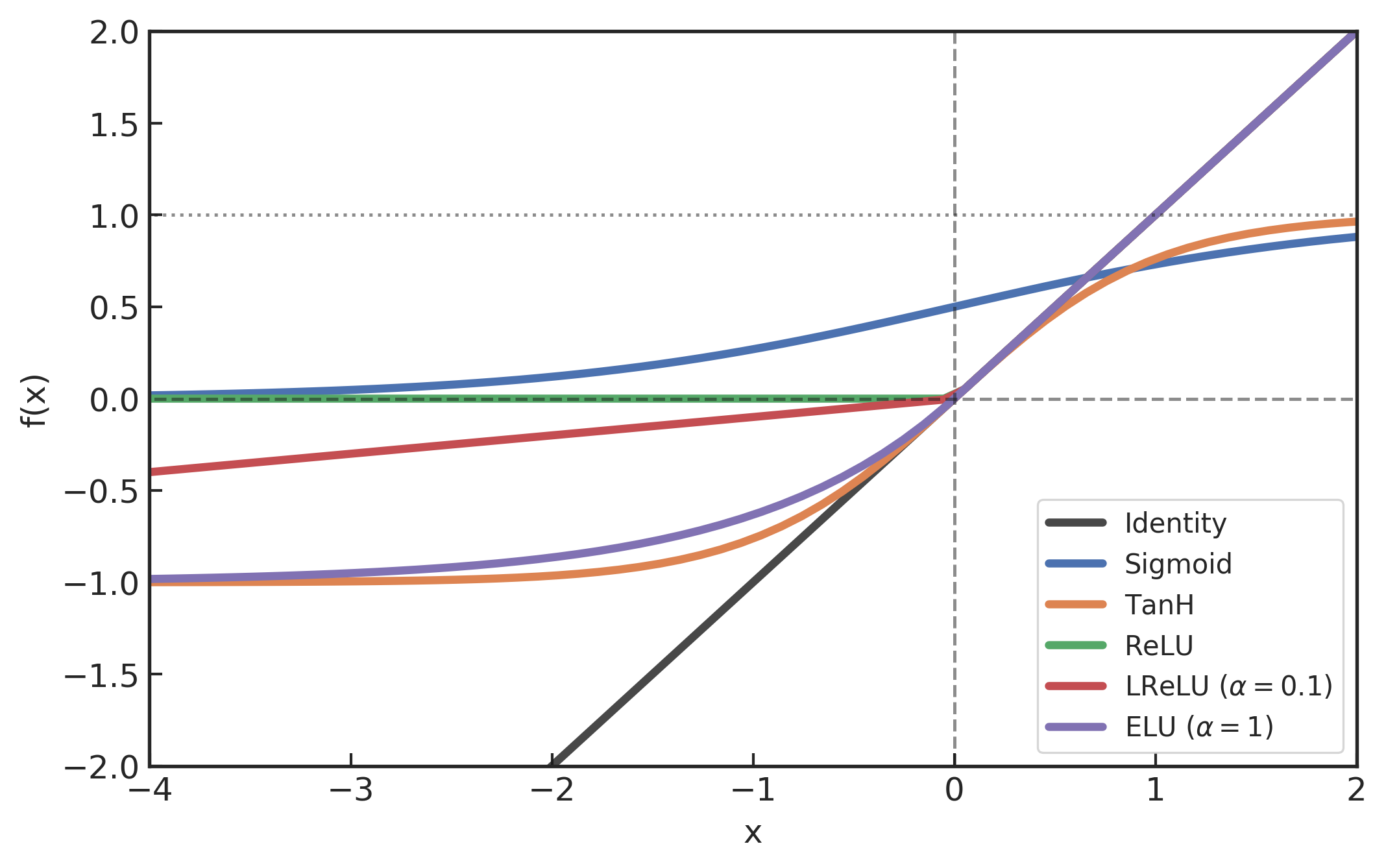
没有激活函数的话,
相当于一维矩阵相乘:
多层和一层一样
只能拟合线性函数
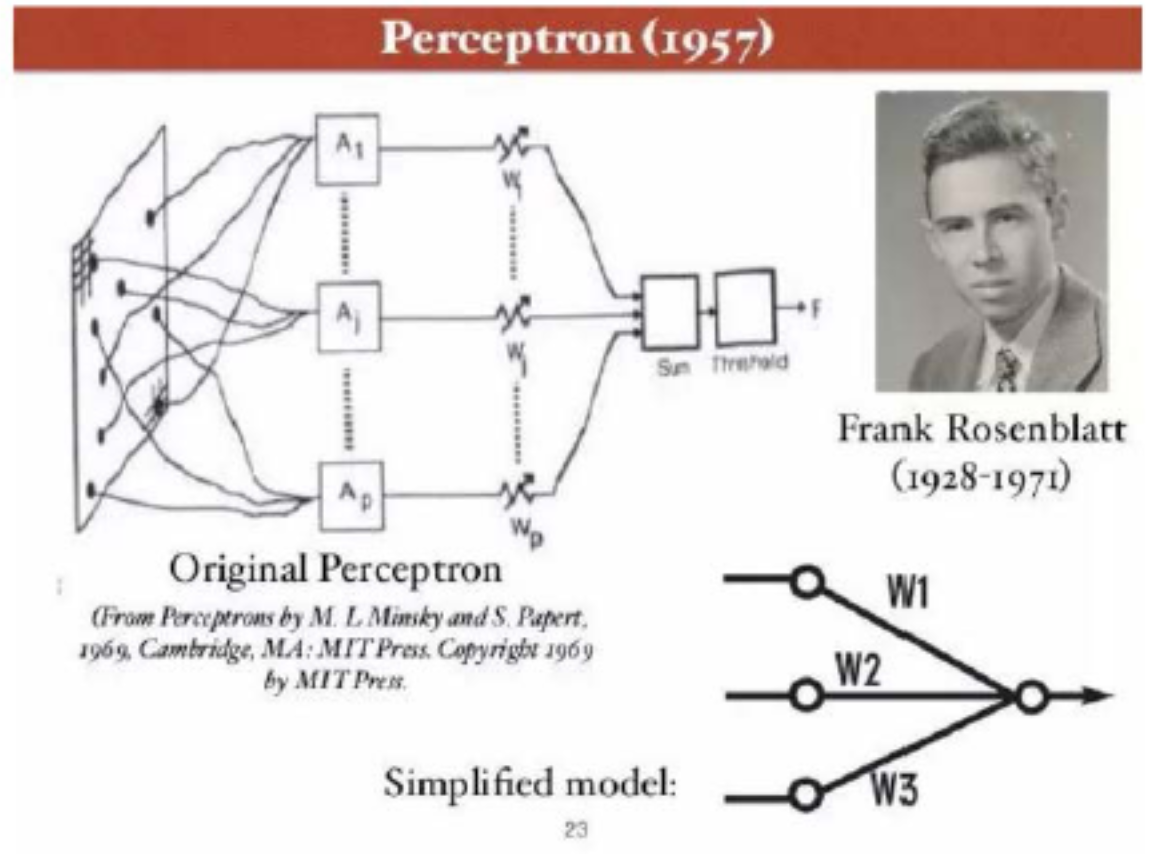
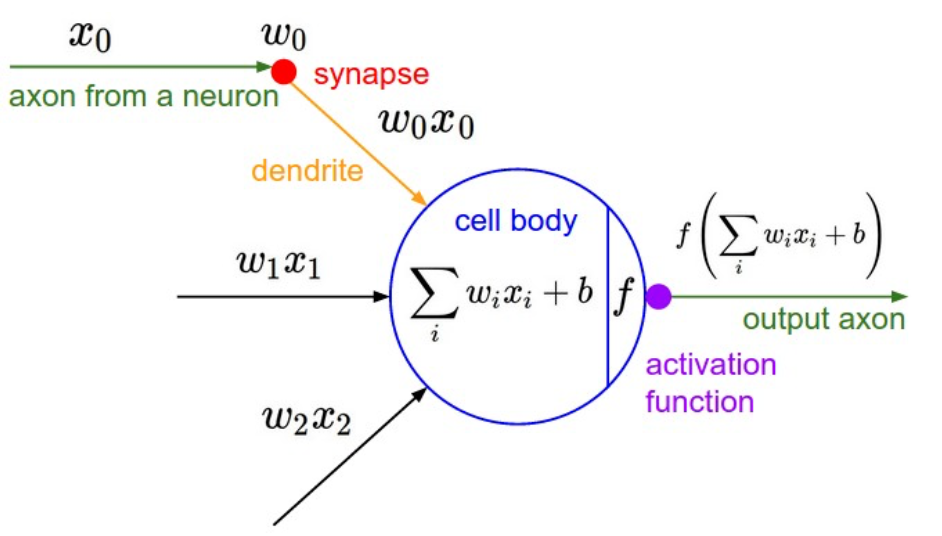
M-P神经元模型 [McCulloch and Pitts, 1943]
# GW: DL
# GW: DL
# GW: DL
# GW: DL
[Hornik et al., 1989]
# GW: DL
Seide F, Li G, Yu D. Conversational speech transcription using context-dependent deep neural networks[C] Interspeech. 2011.
# GW: DL
# GW: DL
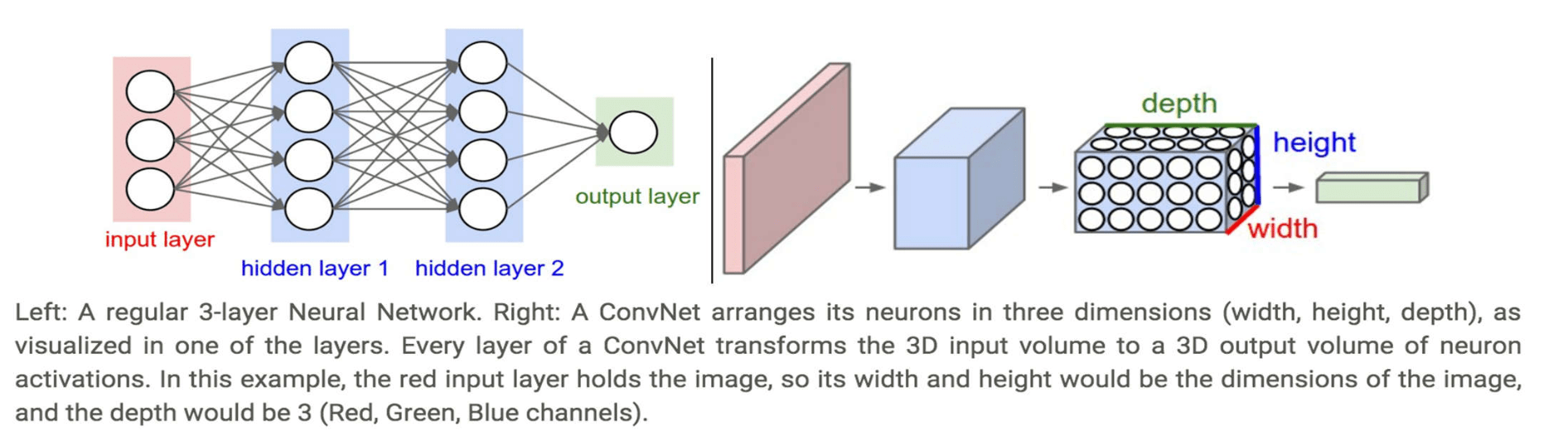
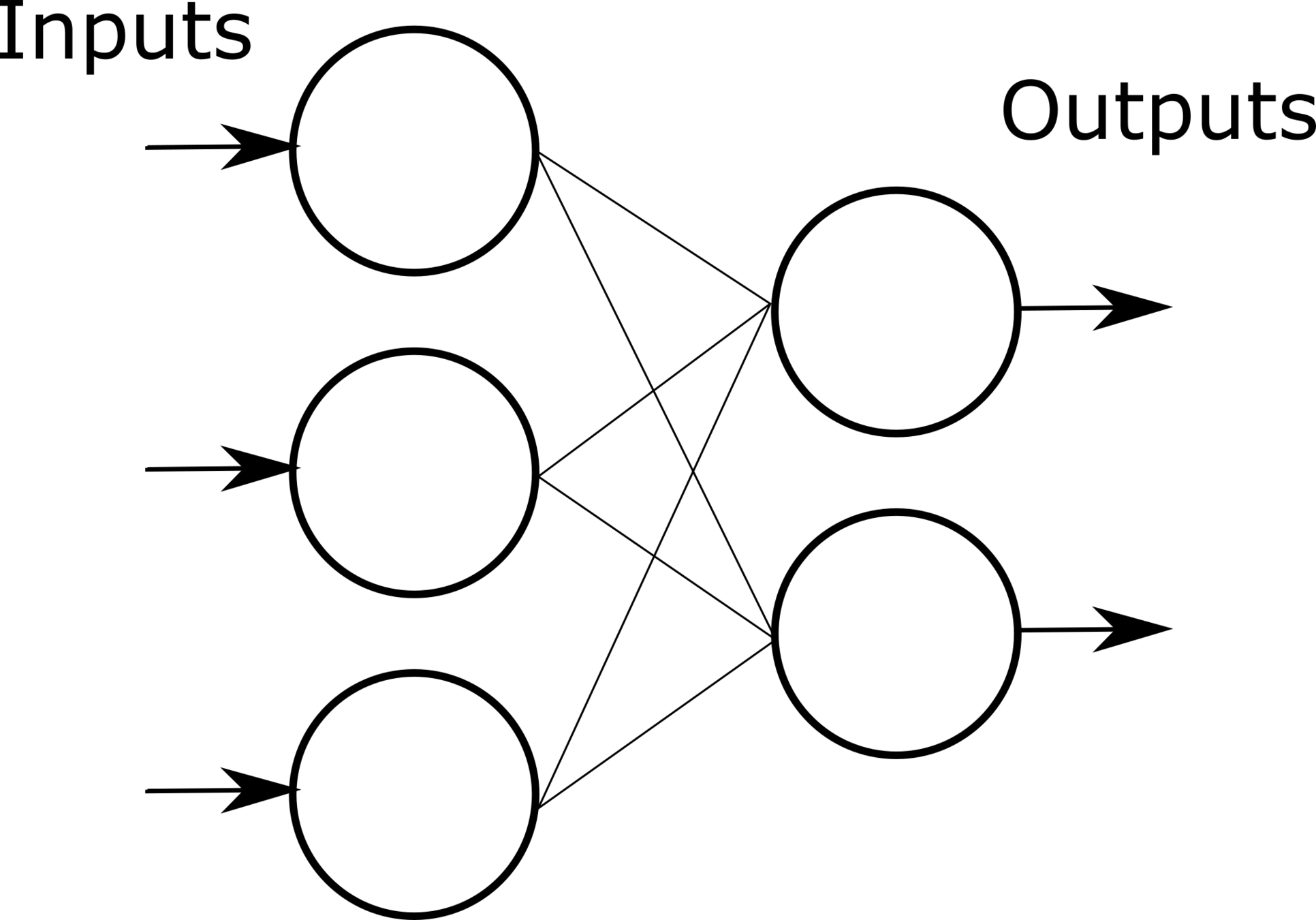
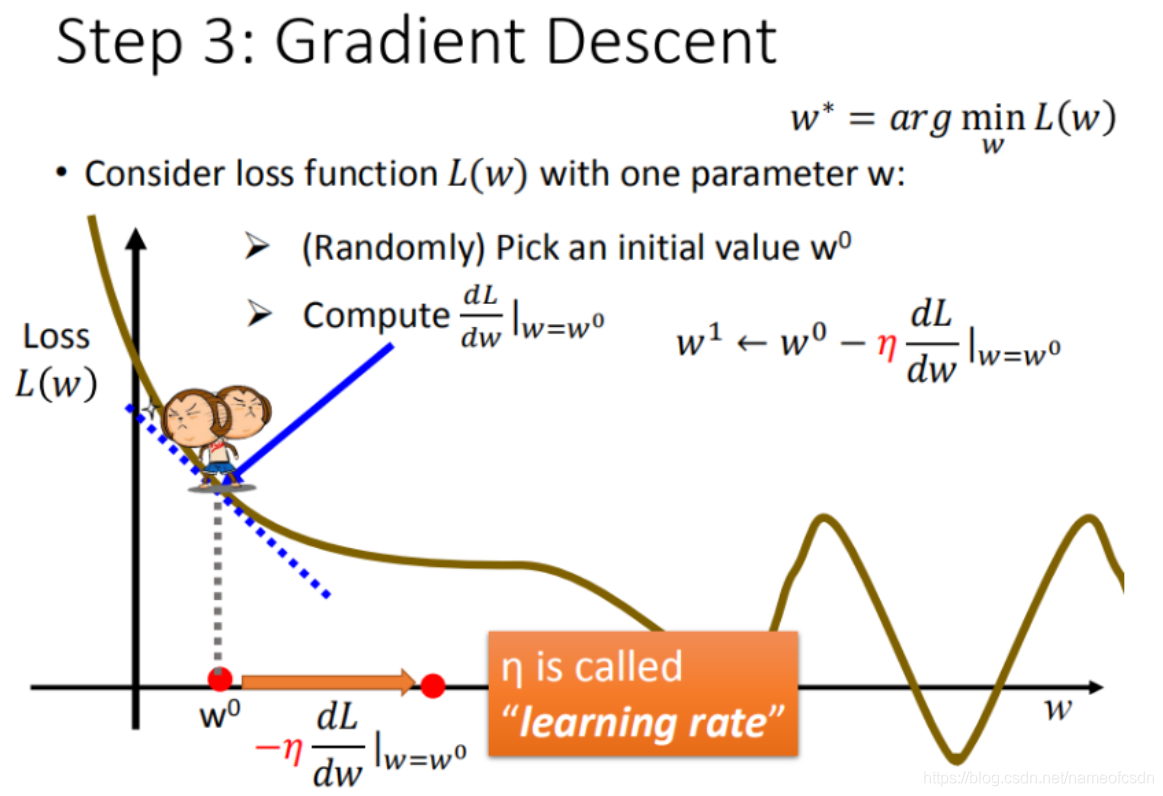
多层神经网络可看成是一个复合的非线性多元函数 \(\mathrm{F}(\cdot): X \rightarrow Y\)
给定训练数据 \(\left\{x^i, y^i\right\}_{i=1: N}\),希望损失 \(\sum_i \operatorname{loss}\left(F_w\left(x^i\right), y^i\right)\) 尽可能小.
图片取自李宏毅老师《机器学习》课程
# GW: DL
多层神经网络可看成是一个复合的非线性多元函数 \(\mathrm{F}(\cdot): X \rightarrow Y\)
给定训练数据 \(\left\{x^i, y^i\right\}_{i=1: N}\),希望损失 \(\sum_i \operatorname{loss}\left(F_w\left(x^i\right), y^i\right)\) 尽可能小
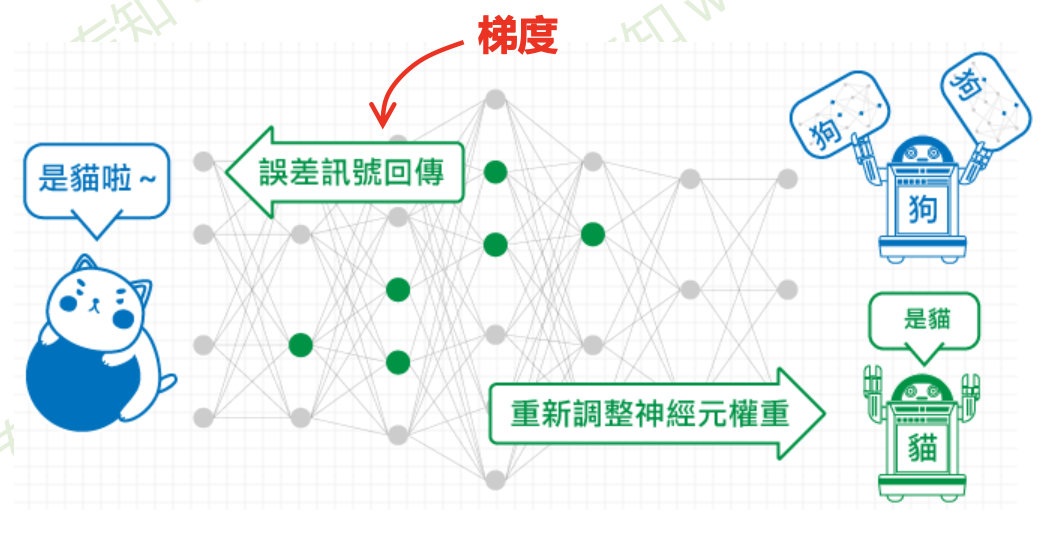
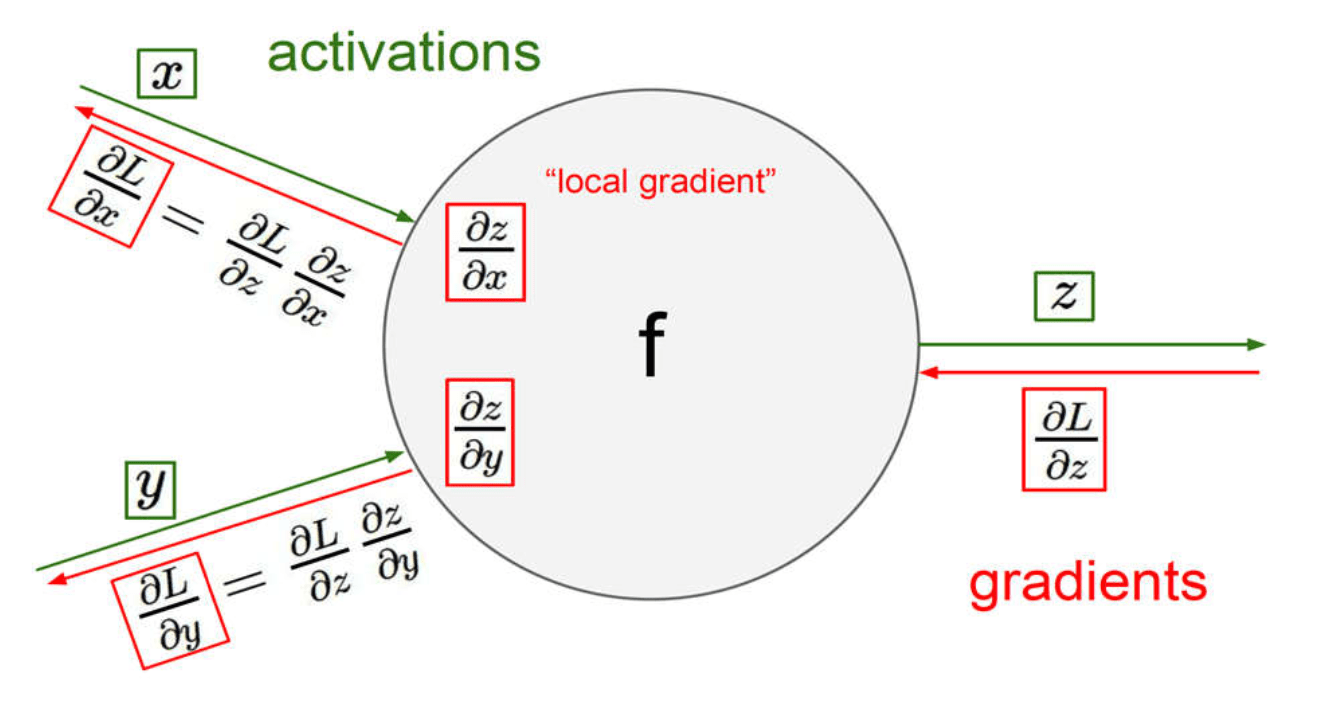
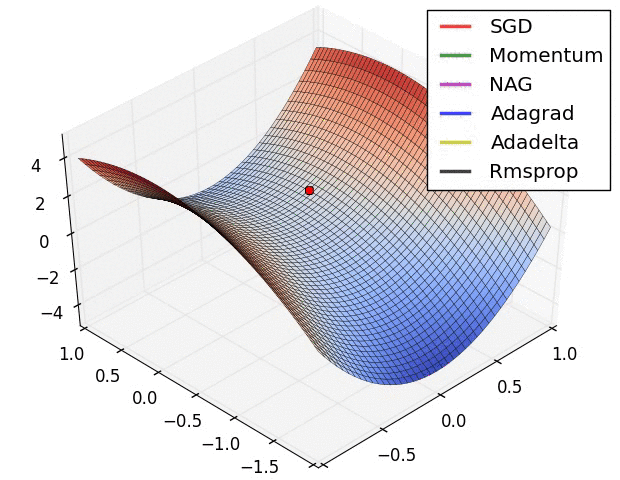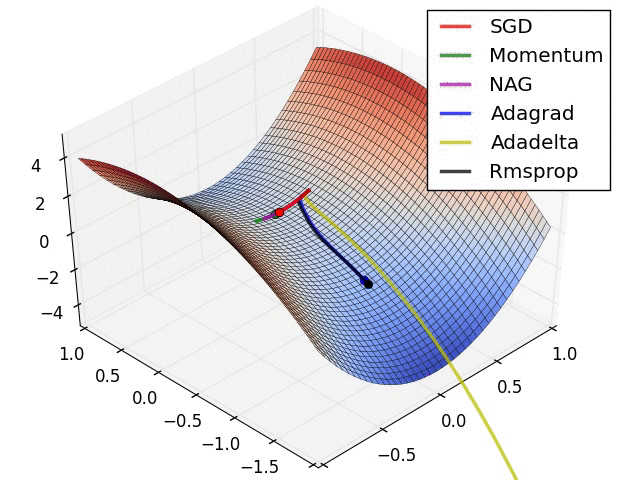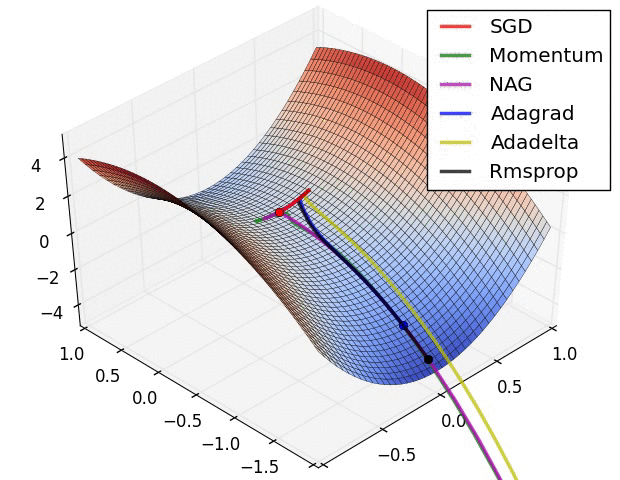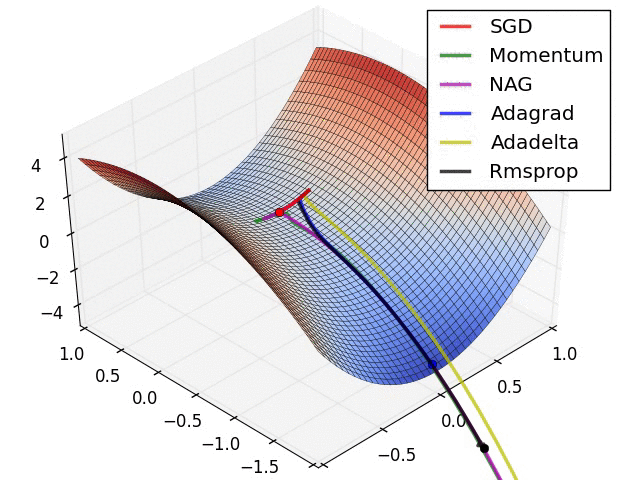
反向传播算法 (BP) 的目标是找损失函数关于神经网络中可学习参数 (\(w\)) 的偏导数(证明略)
# GW: DL
多层神经网络可看成是一个复合的非线性多元函数 \(\mathrm{F}(\cdot): X \rightarrow Y\)
给定训练数据 \(\left\{x^i, y^i\right\}_{i=1: N}\),希望损失 \(\sum_i \operatorname{loss}\left(F_w\left(x^i\right), y^i\right)\) 尽可能小
反向传播算法 (BP) 的目标是找损失函数关于神经网络中可学习参数 (\(w\)) 的偏导数(证明略)
Credit: Cameron R. Wolfe
From here
# GW: DL
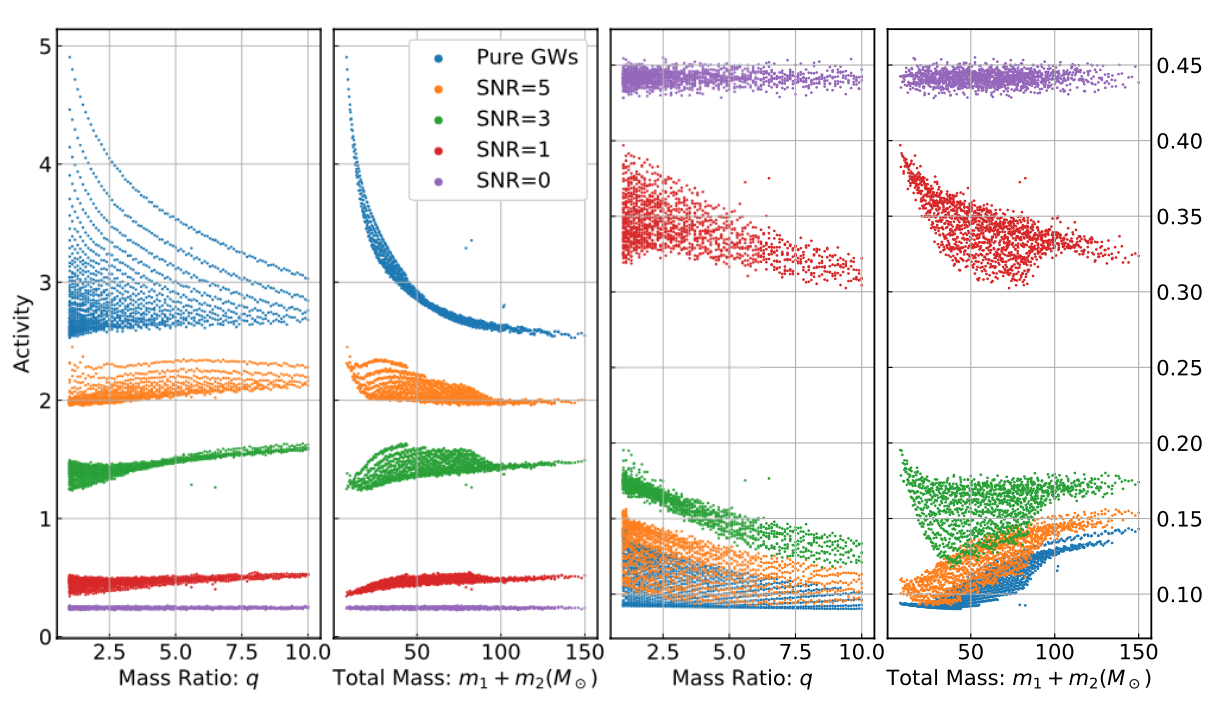
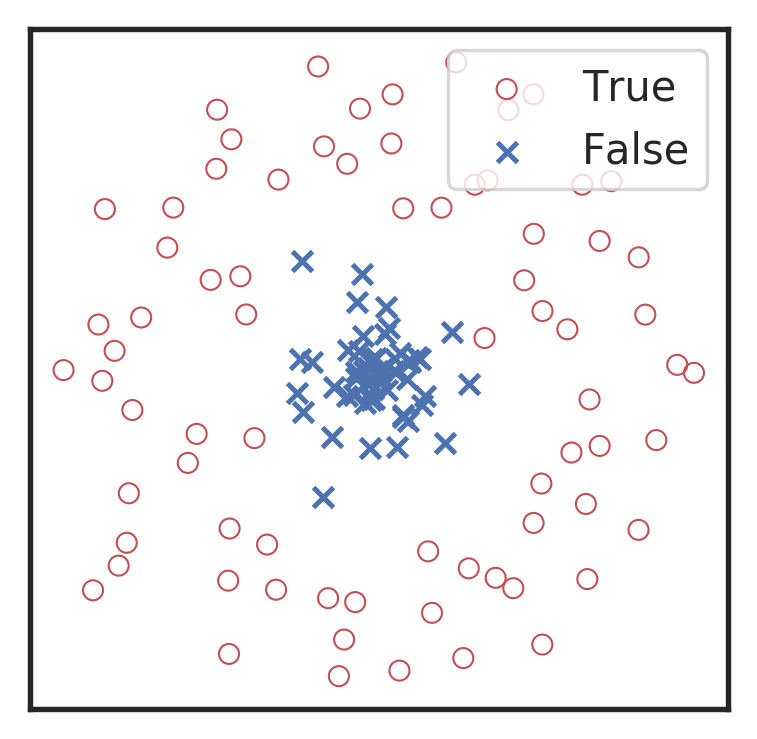
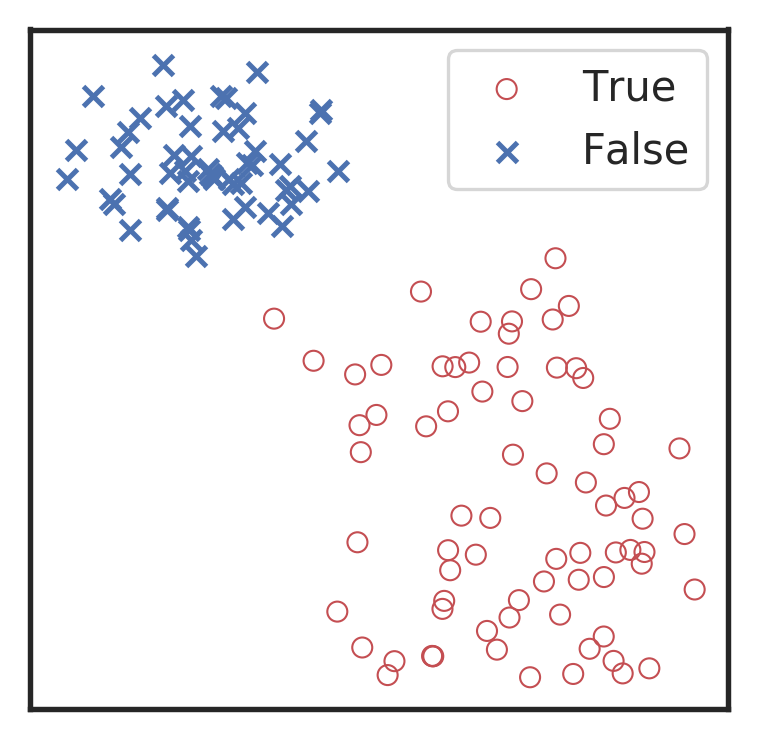
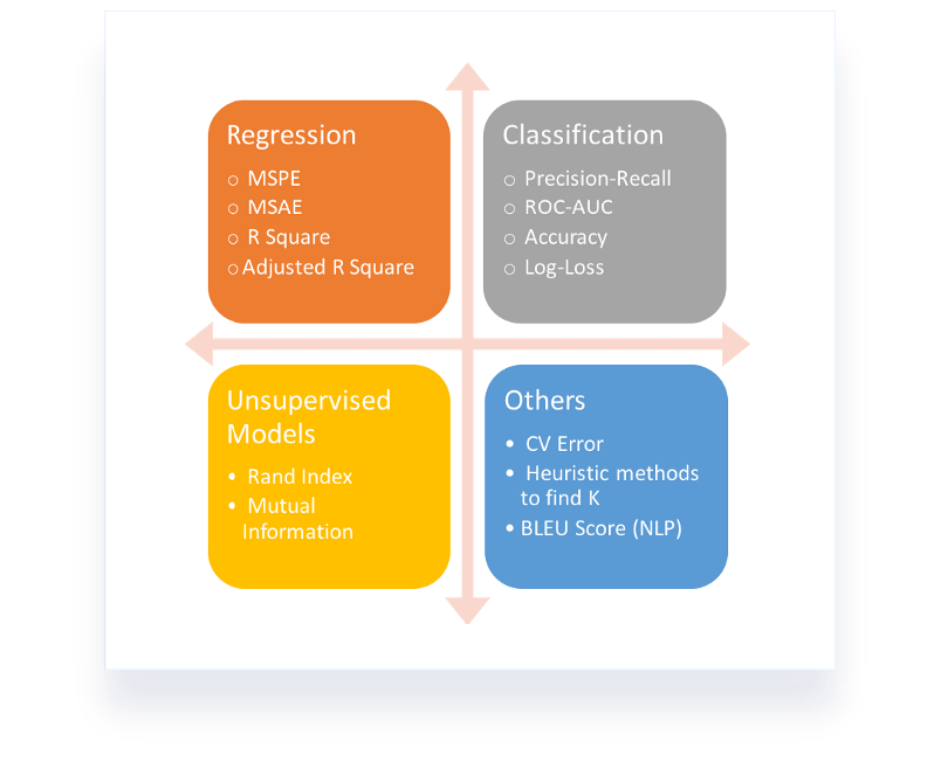
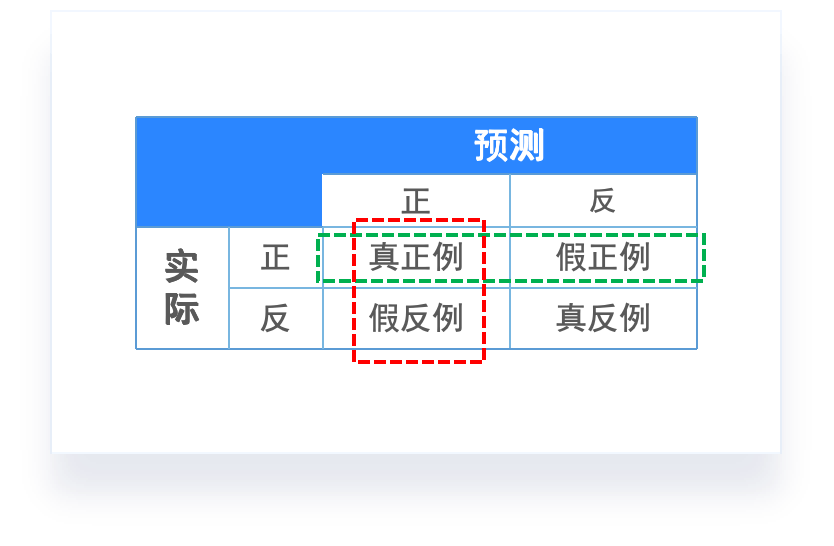
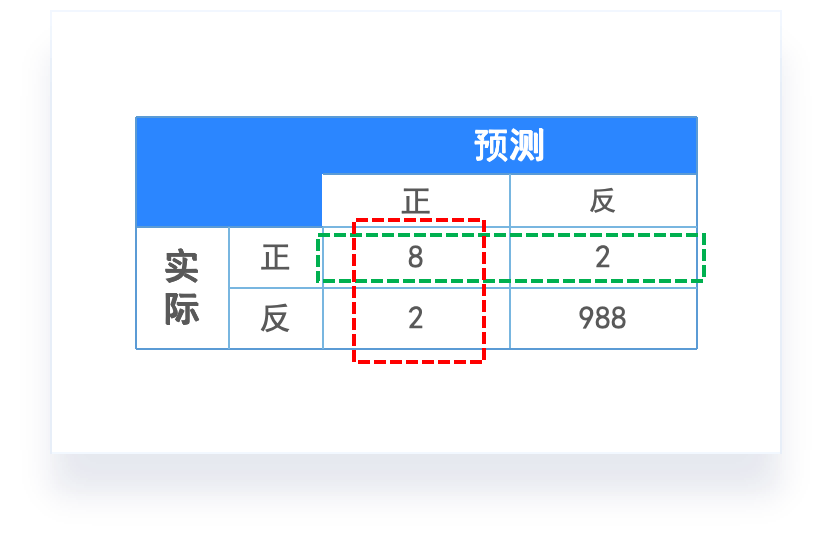
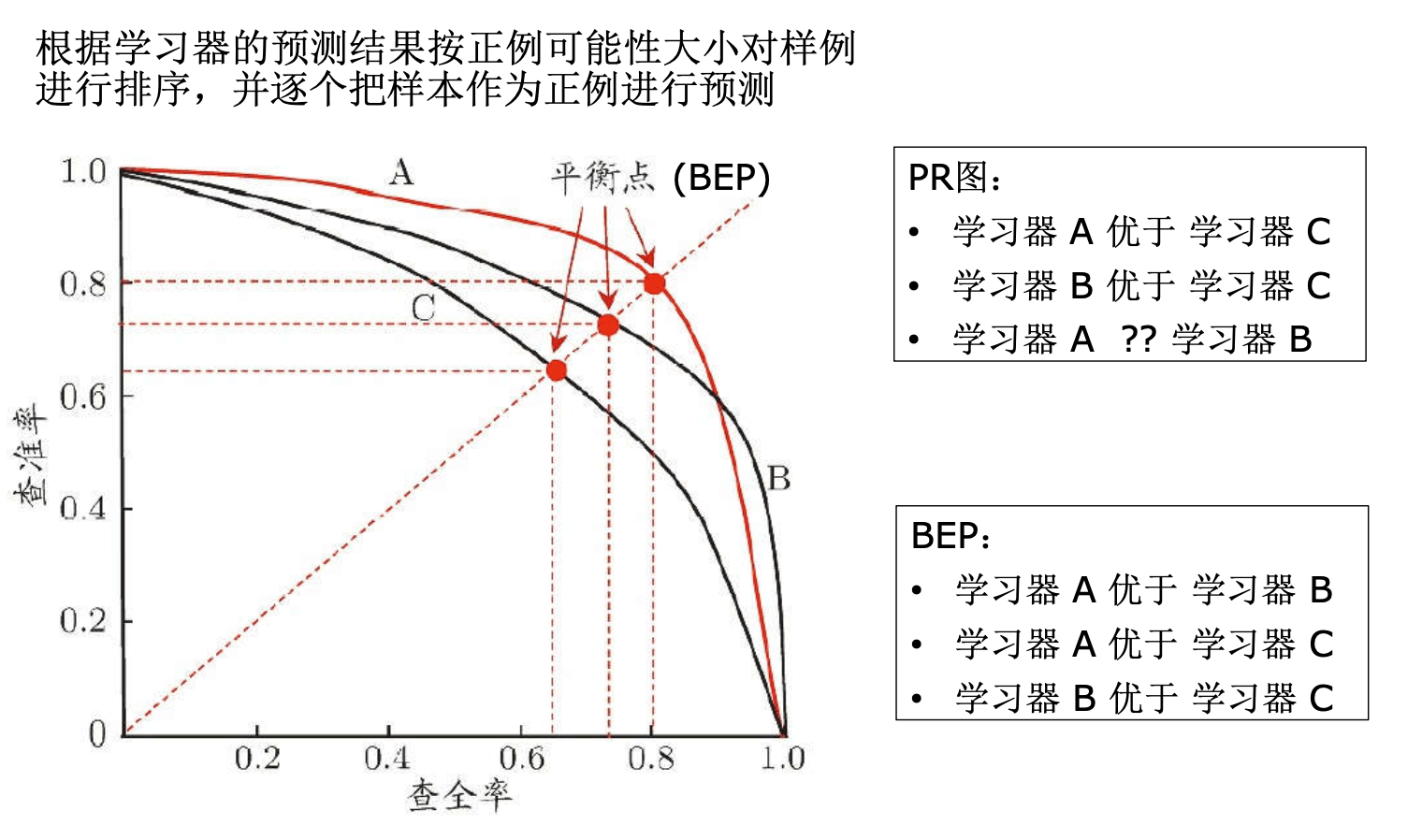
分类任务的评价指标
# GW: DL
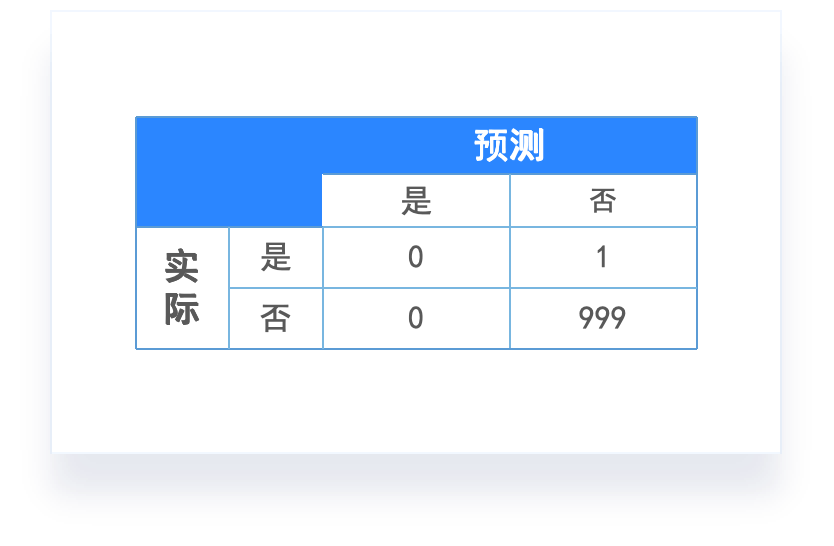
分类任务的评价指标
混淆矩阵
# GW: DL
分类任务的评价指标
混淆矩阵
# GW: DL
分类任务的评价指标
混淆矩阵
# GW: DL
分类任务的评价指标
混淆矩阵
# GW: DL
分类任务的评价指标
# GW: DL
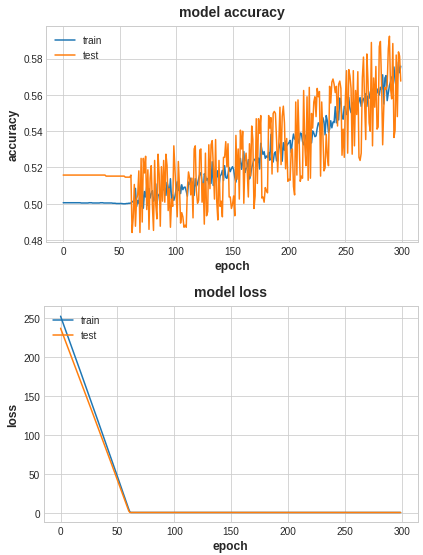
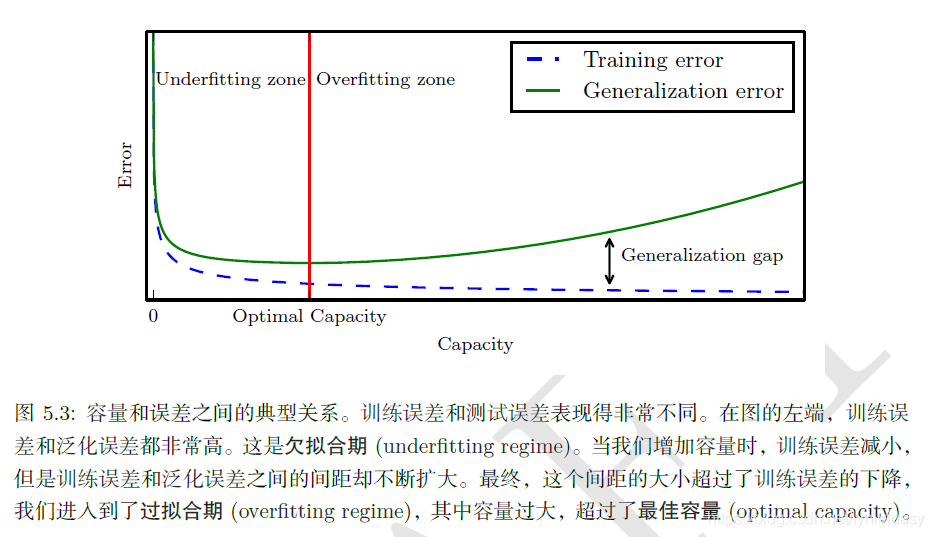
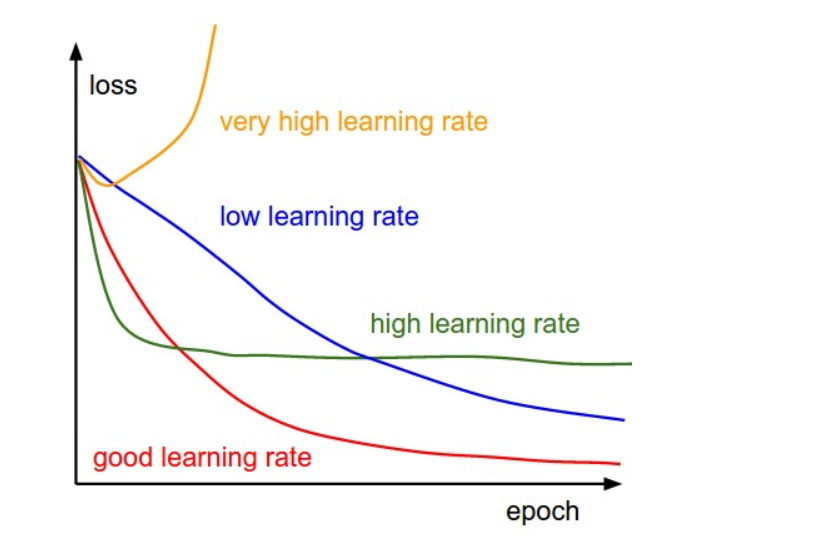
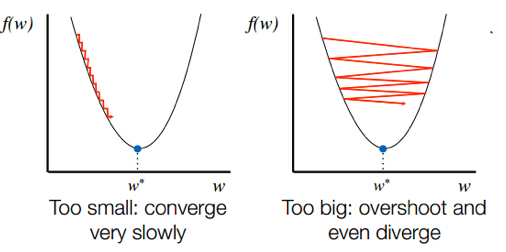
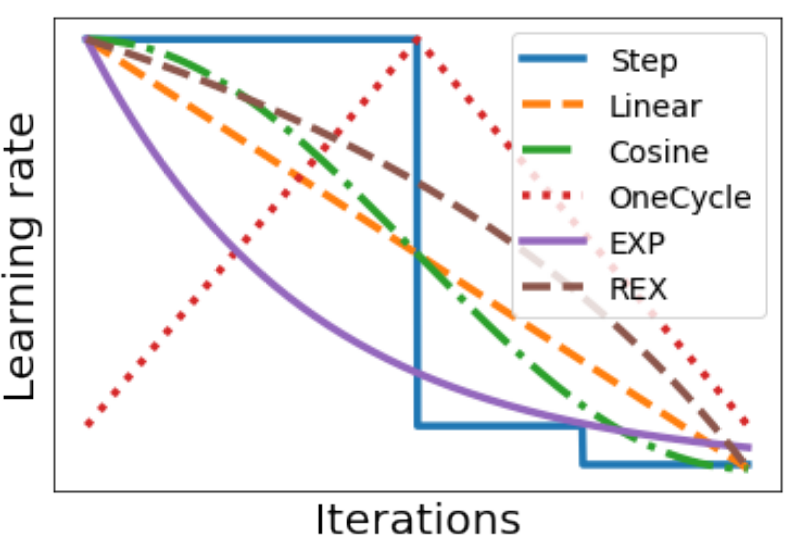
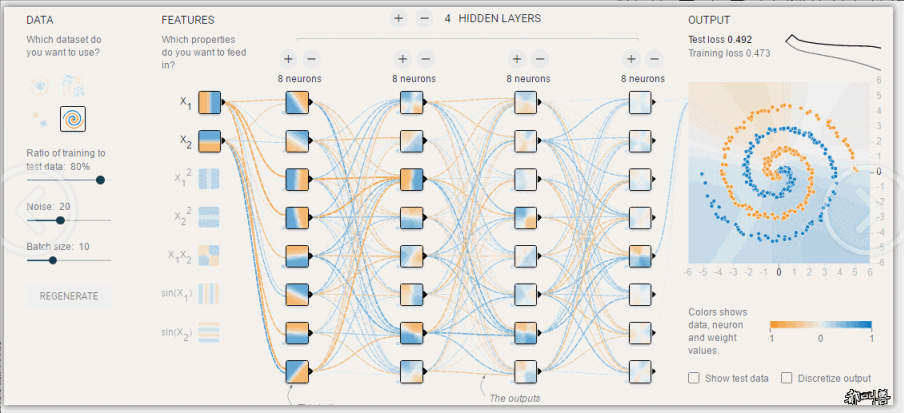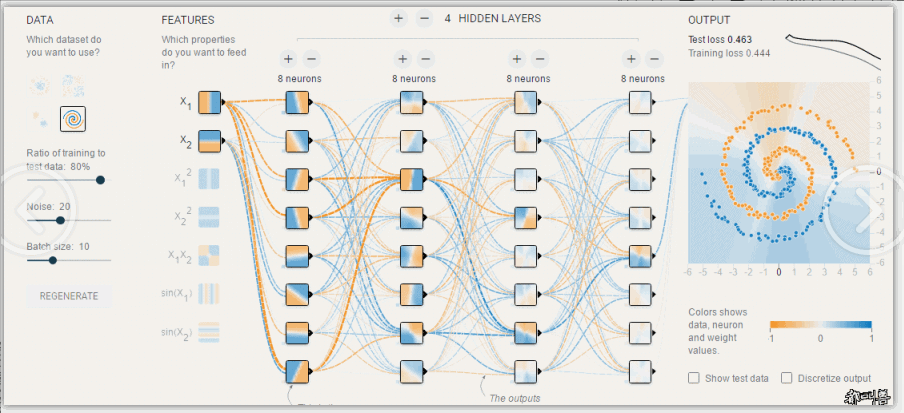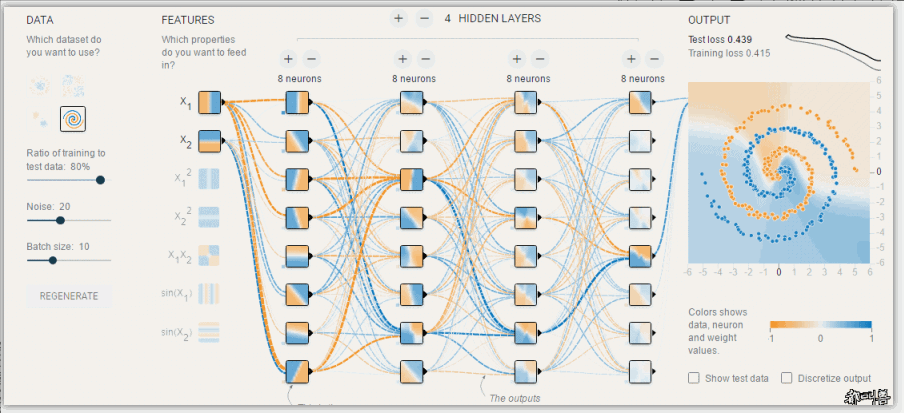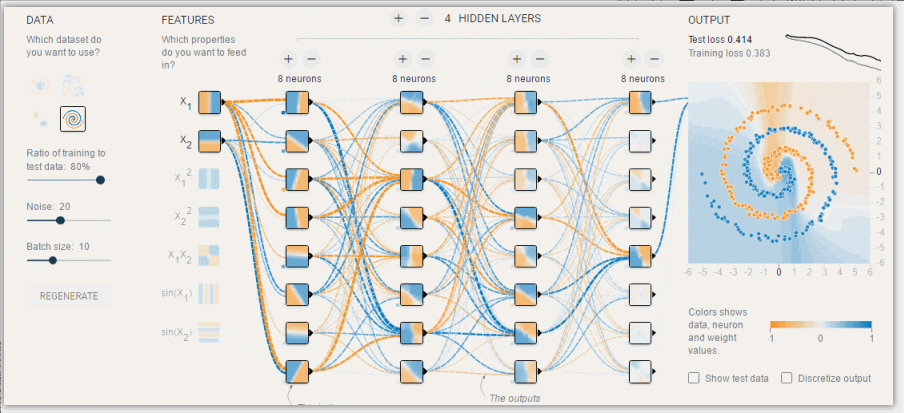
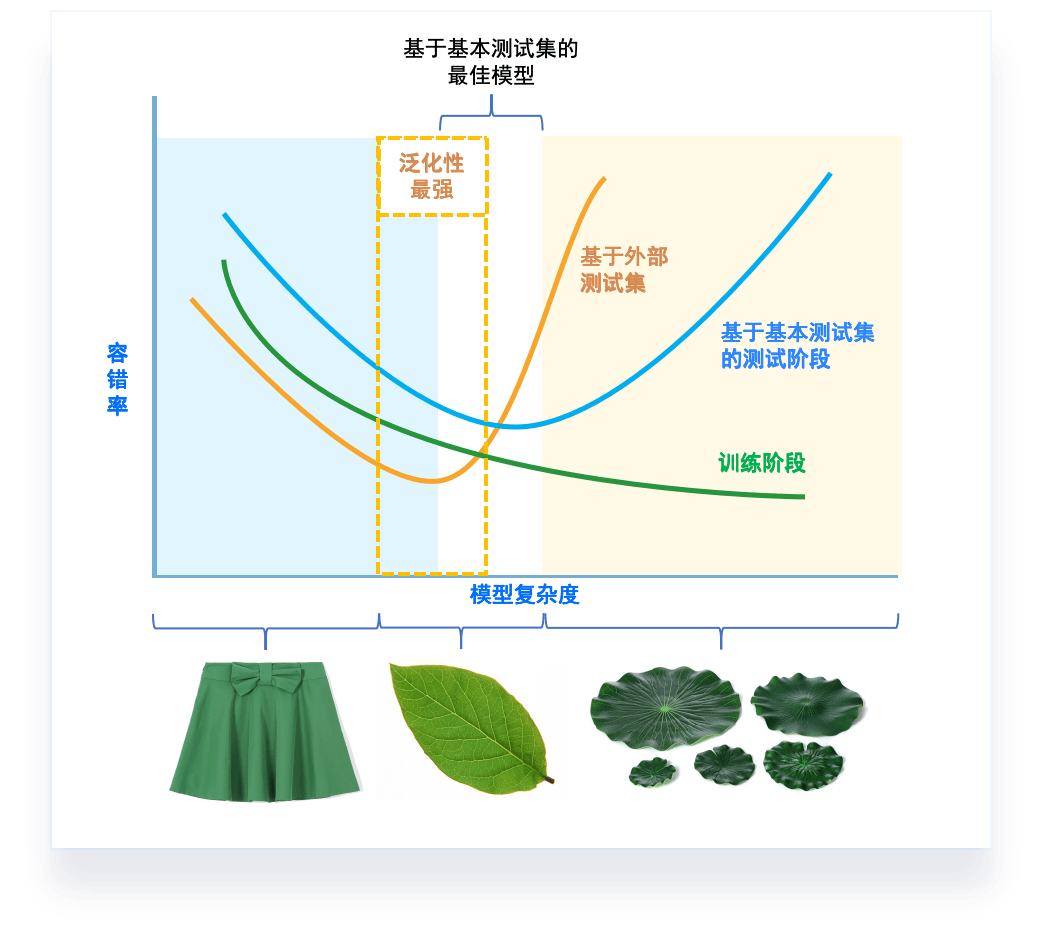
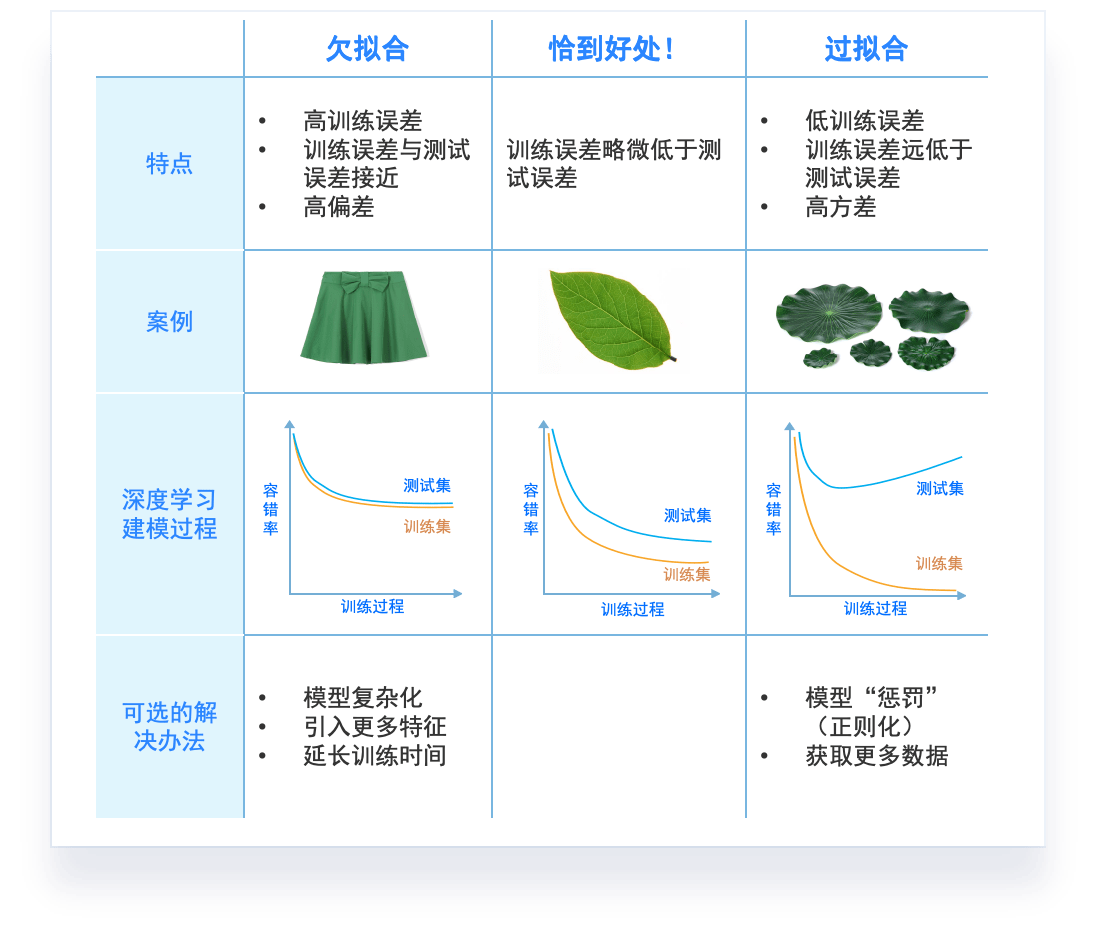
模型调优,过拟合与欠拟合
# GW: DL
模型调优,过拟合与欠拟合
# GW: DL
模型调优,过拟合与欠拟合
素材来源:DOI: 10.1177/2374289519873088
# GW: DL
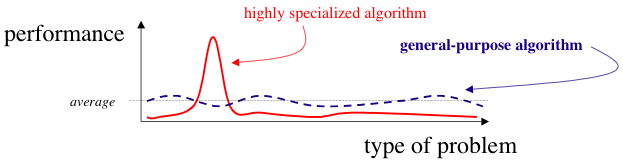
没有免费午餐定理(No free lunch theorem)
Wolpert D H. The lack of a priori distinctions between learning algorithms[J]. Neural computation, 1996, 8(7): 1341-1390.
没有免费午餐理论对于个人的指导
# GW: DL
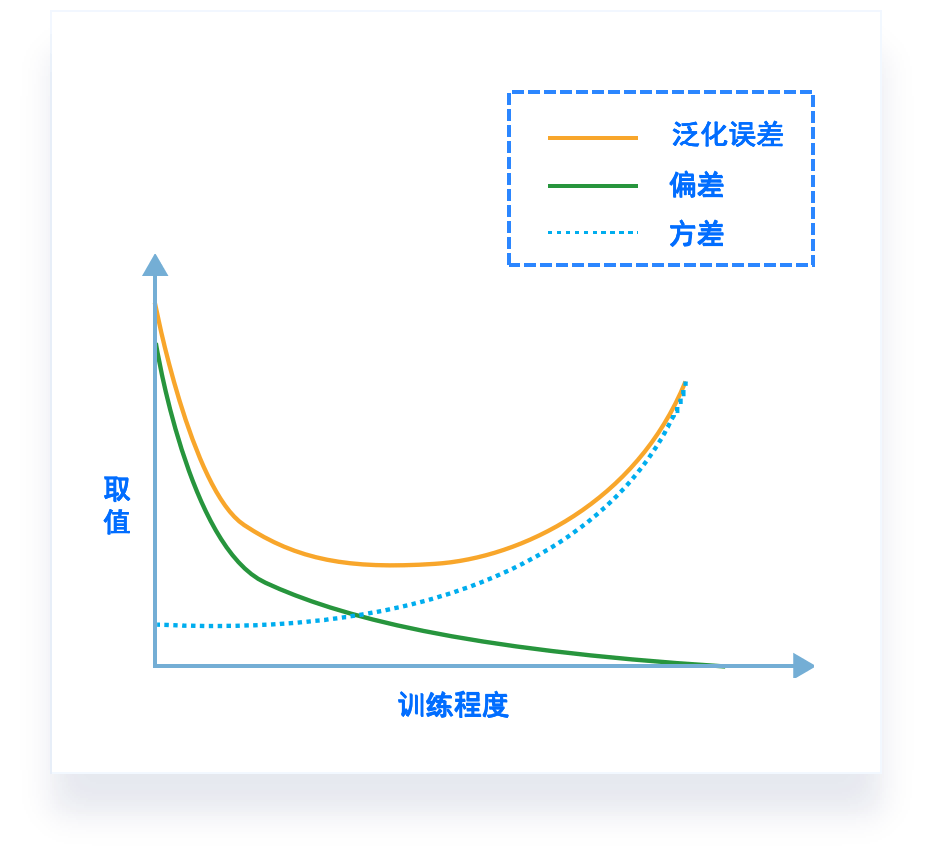
偏差-方差窘境(bias-variance dilemma)
泛化性能 是由学习算法的能力、数据的充分性以及学习任务本身的难度共同决定。
# GW: DL
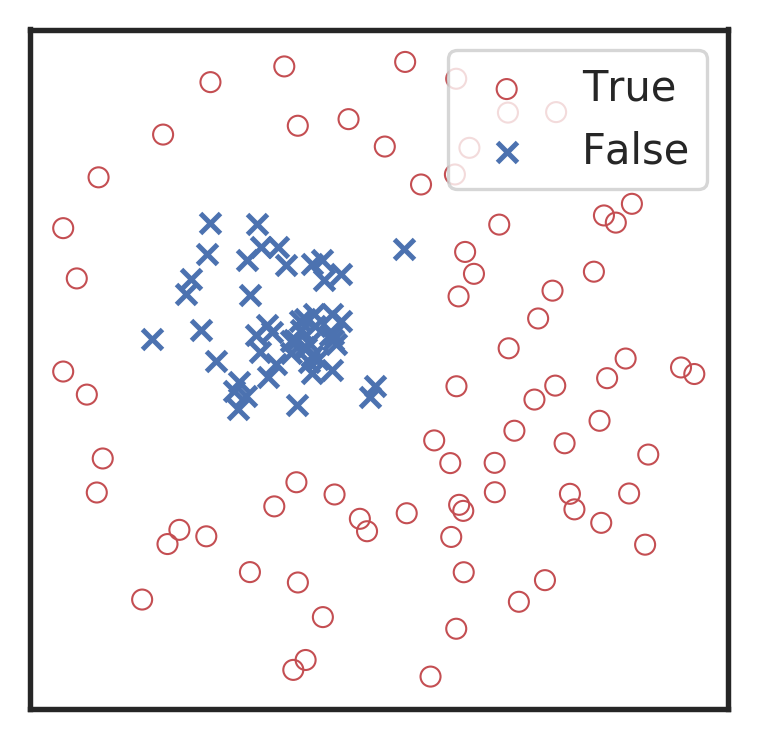
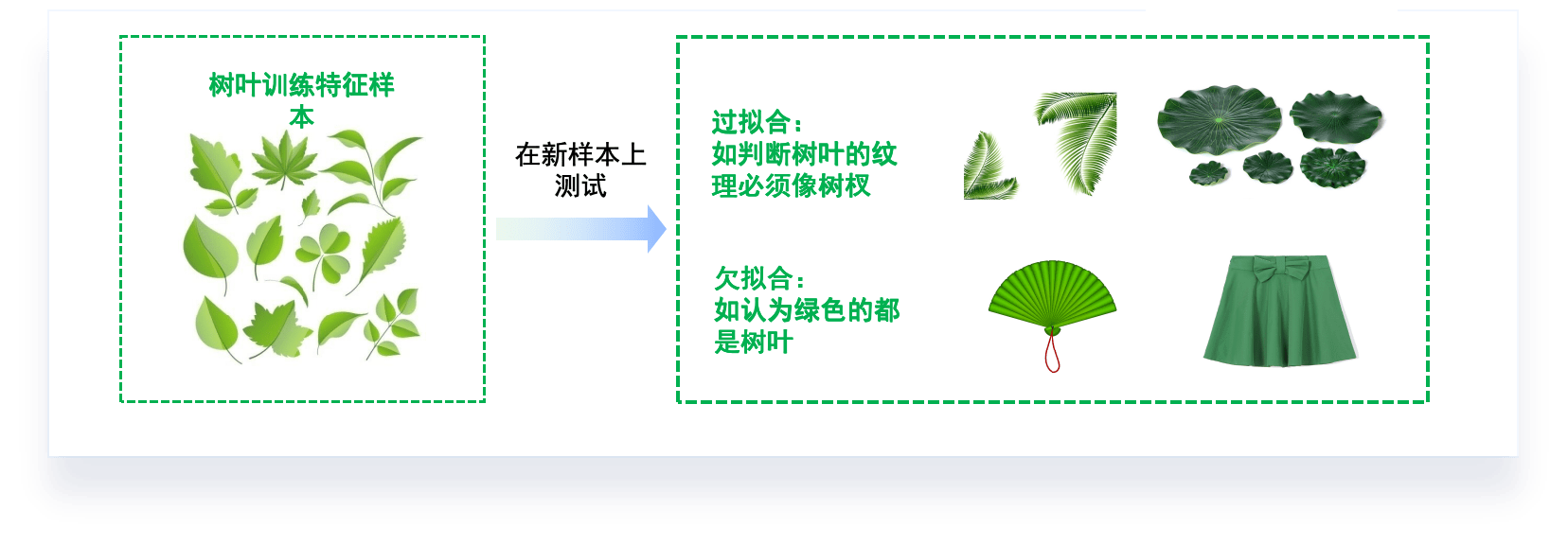
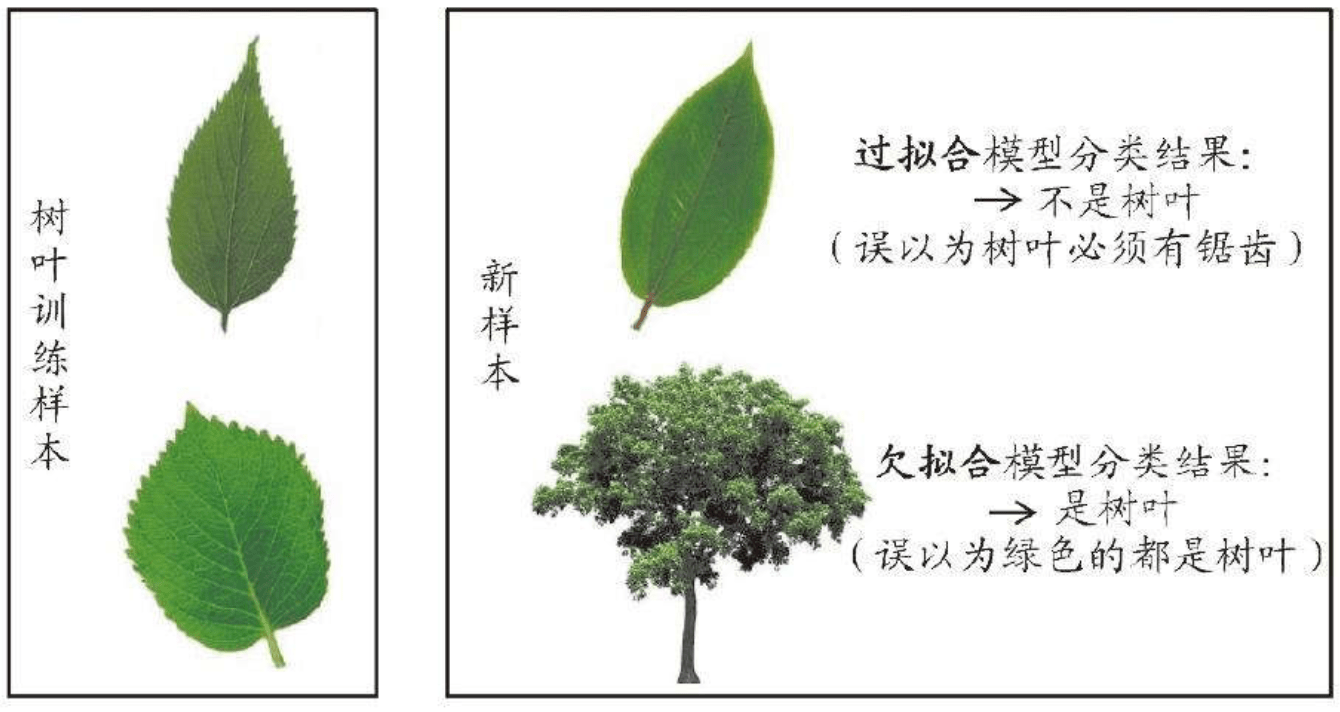
模型调优,过拟合与欠拟合
过拟合和欠拟合是机器学习中常见的两种问题。
# GW: DL
模型评估与选择
统计假设检验 (hypothesis test) 为学习器性能比较提供了重要依据【应需要有统计显著性作为评判依据】
两学习器比较
交叉验证 t 检验(基于成对 t 检验)
McNemar 检验(基于列联表、卡方检验)
多学习器比较
Kolmogorv-Smirnov Test (K-S检验)
Friedman 检验 (基于序值,F检验;判断“是否相同”)
Nemenyi 后续检验(基于序值,进一步判断两两差别)
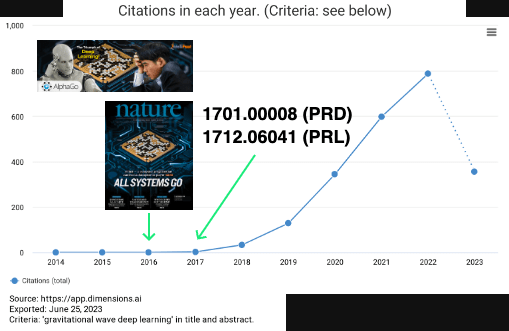
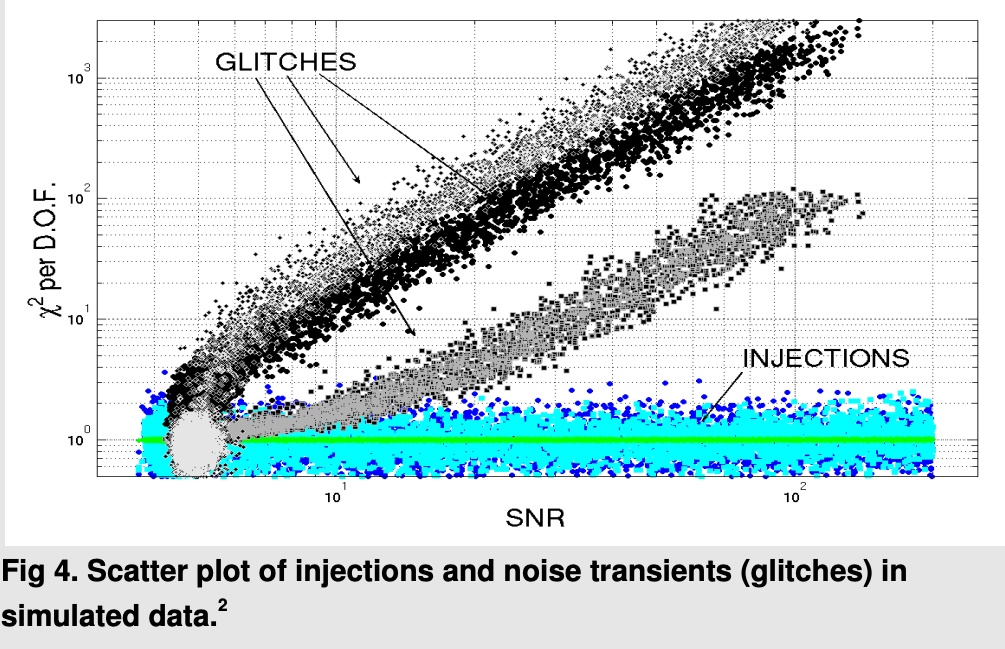
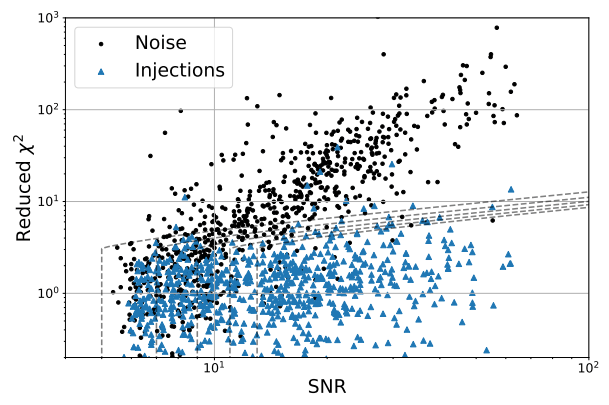
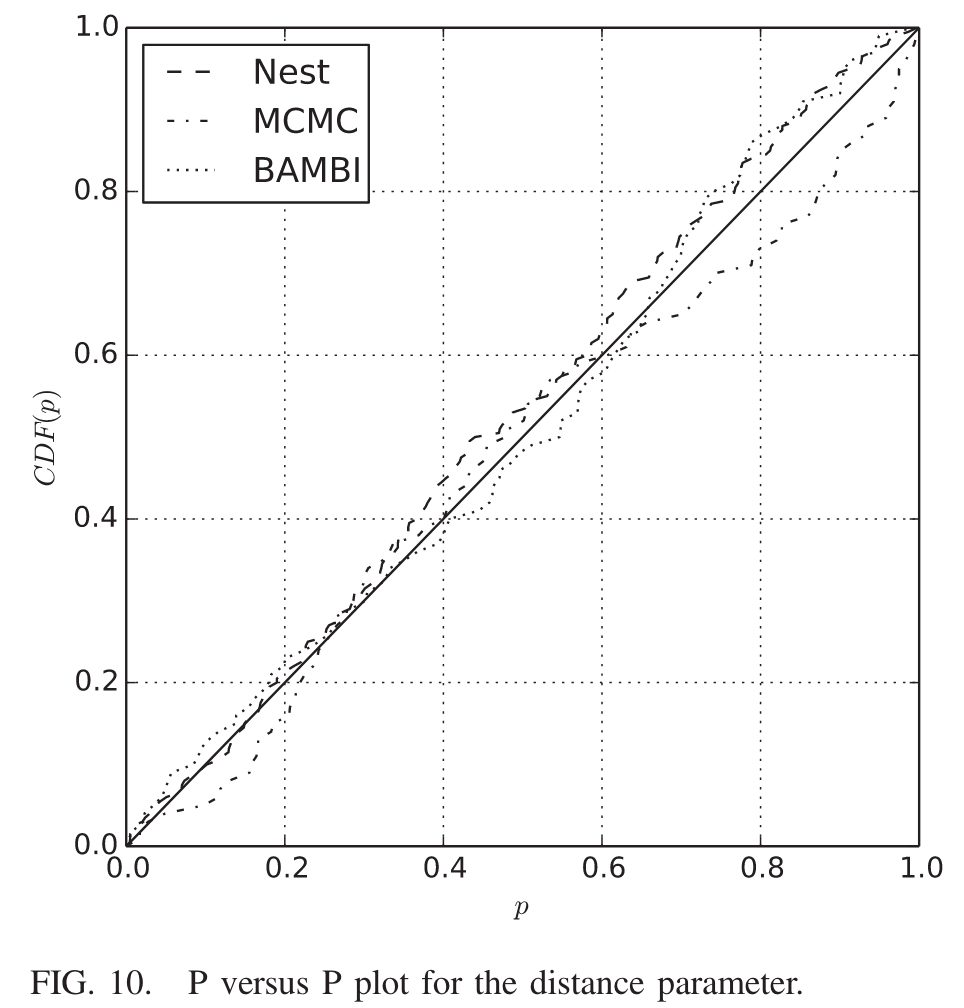
Veitch, J., et al. Physical Review D 91, no. 4 (February 2015): 042003. https://doi.org/10.1103/PhysRevD.91.042003.
# Homework
Repo of the course: https://github.com/iphysresearch/GWData-Bootcamp
通向自我实现之路:Kaggle
By He Wang
引力波数据探索:编程与分析实战训练营。课程网址:https://github.com/iphysresearch/GWData-Bootcamp




