







He Wang PRO
Knowledge increases by sharing but not by saving.
He Wang (王赫)
[hewang@mail.bnu.edu.cn]
Department of Physics, Beijing Normal University
In collaboration with Zhou-Jian Cao
July 16th, 2019
Topological data analysis and deep learning: theory and signal applications - Part 4 ICIAM 2019
A trigger generator \(\rightarrow\) Efficiency+ Completeness + Informative
Background
Related works
Past attempts on stimulated noise
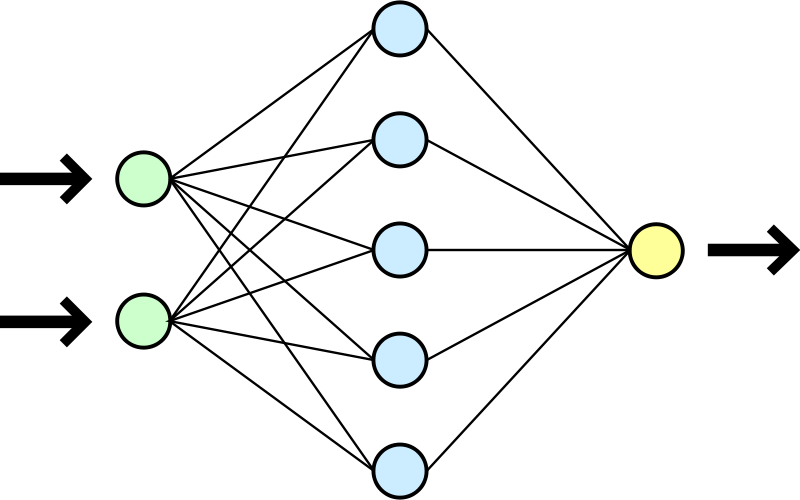
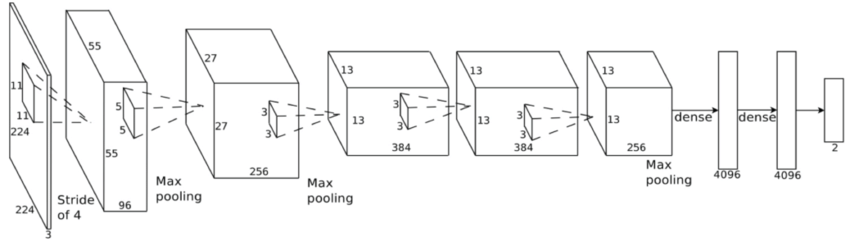
Convolutional neural network (ConvNet or CNN)
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012)
Feature extraction
Merge part
Convolutional neural network (ConvNet or CNN)
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012)
Classification
Visualization for the high-dimensional feature maps of learned network in layers for bi-class using t-SNE.
Past attempts on stimulated noise
Marginal!
Feature extraction
Convolutional neural network (ConvNet or CNN)
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012)
Classification
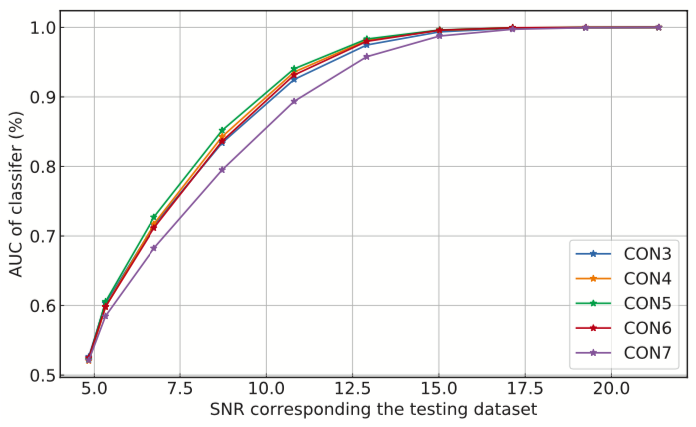
Effect of the number of the convolutional layers on signal recognizing accuracy.
Past attempts on stimulated noise
Feature extraction
Convolutional neural network (ConvNet or CNN)
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012)
Classification
Marginal!
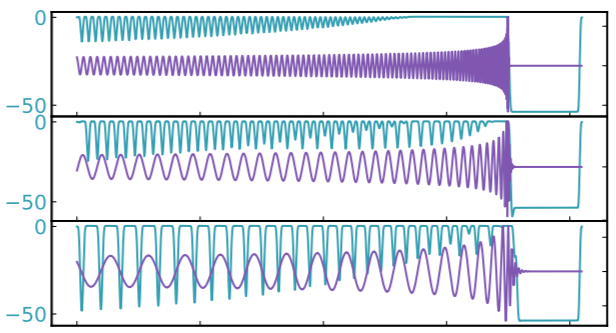
Visualization of the top activation on average at the \(n\)th layer projected back to time domain using the deconvolutional network approach
Past attempts on stimulated noise
Feature extraction
Peak of GW
Convolutional neural network (ConvNet or CNN)
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012)
Classification
Marginal!
Occlusion Sensitivity
Past attempts on stimulated noise
Feature extraction
Convolutional neural network (ConvNet or CNN)
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012)
A specific design of the architecture is needed.
[as Timothy D. Gebhard et al. (2019)]
Classification
Marginal!
Peak of GW
Past attempts on stimulated noise
Motivation
Matched-filtering in time domain
Matched-filtering ConvNet
(In preprint)
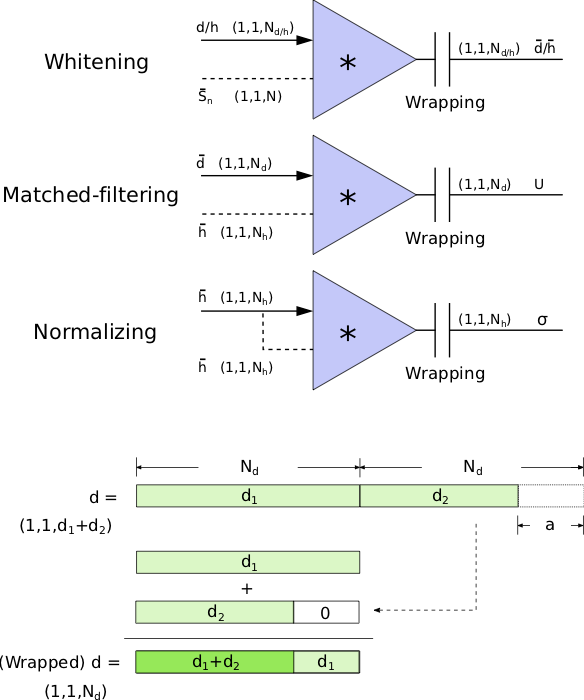
Motivation
Matched-filtering (cross-correlation with the templates) can be regarded as a convolutional layer with a set of predefined kernels.
Matched-filtering (cross-correlation with the templates) can be regarded as a convolutional layer with a set of predefined kernels.
Is it matched-filtering?
Motivation
The square of matched-filtering SNR for a given data \(d(t) = n(t)+h(t)\):
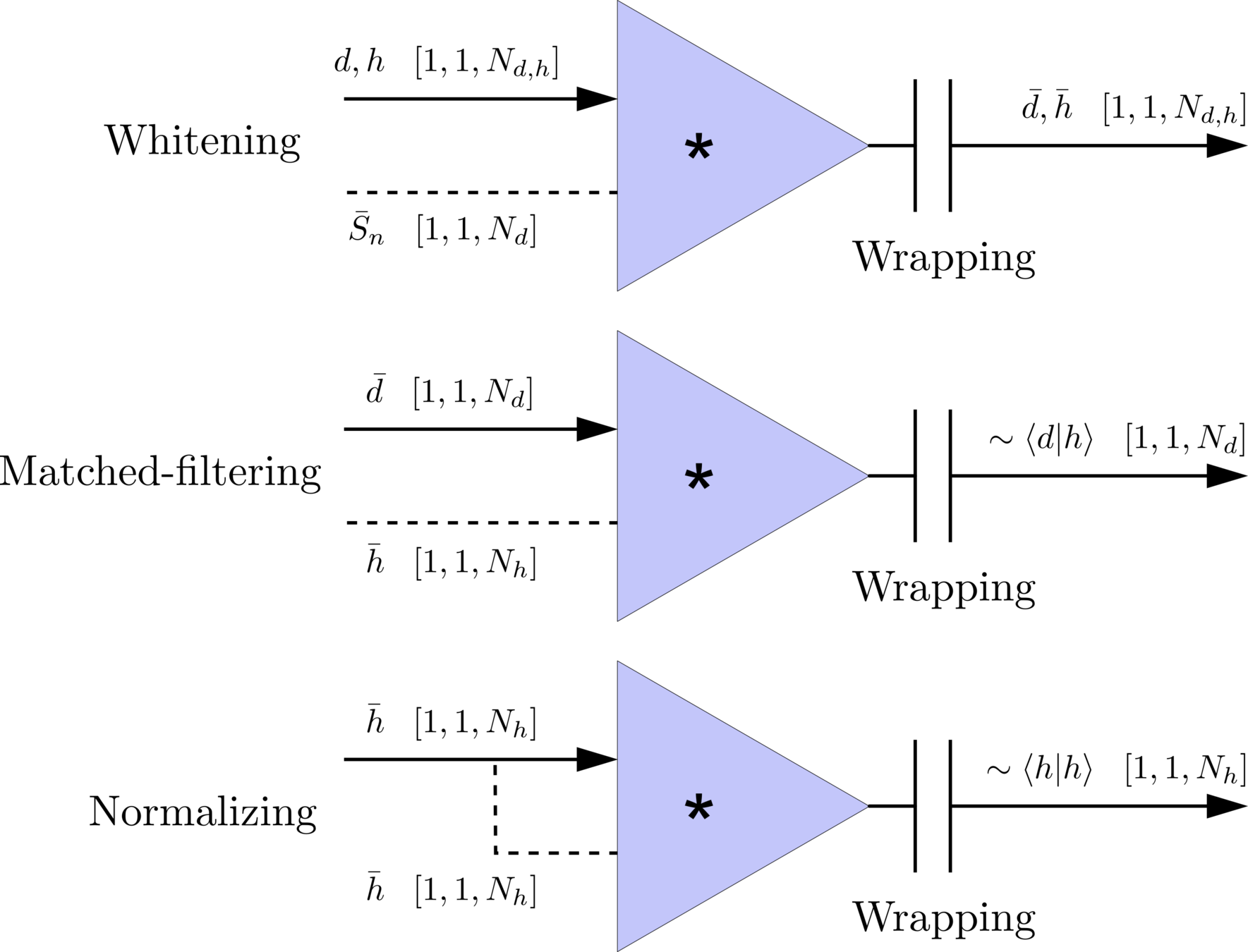
Matched-filtering in time domain
Frequency domain
(matched-filtering)
(normalizing)
Frequency domain
Time domain
where
(whitening)
\(S_n(|f|)\) is the one-sided average PSD of \(d(t)\)
Matched-filtering in time domain
The square of matched-filtering SNR for a given data \(d(t) = n(t)+h(t)\):
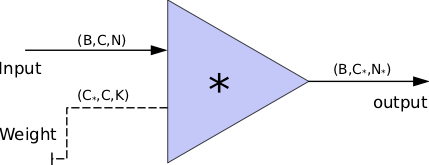
In the 1-D convolution (\(*\)), given input data with shape [batch size, channel, length] :
FYI: \(N_\ast = \lfloor(N-K+2P)/S\rfloor+1\)
Time domain
(matched-filtering)
(normalizing)
where
(whitening)
Matched-filtering in time domain
The square of matched-filtering SNR for a given data \(d(t) = n(t)+h(t)\):
\(S_n(|f|)\) is the one-sided average PSD of \(d(t)\)
(A schematic illustration for a unit of convolution layer)
Time domain
(matched-filtering)
(normalizing)
where
(whitening)
Matched-filtering in time domain
The square of matched-filtering SNR for a given data \(d(t) = n(t)+h(t)\):
\(S_n(|f|)\) is the one-sided average PSD of \(d(t)\)
Wrapping (like the pooling layer)
Architechture
\(\bar{S_n}(t)\)
\(\bar{S_n}(t)\)
In the meanwhile, we can obtain the optimal time \(N_0\) (relative to the input) of feature response of matching by recording the location of the maxima value corresponding to the optimal template \(C_0\)
Architechture
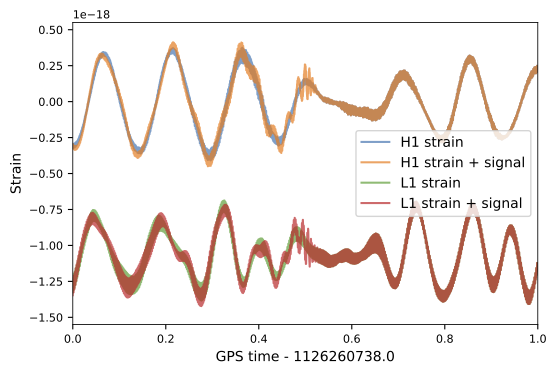
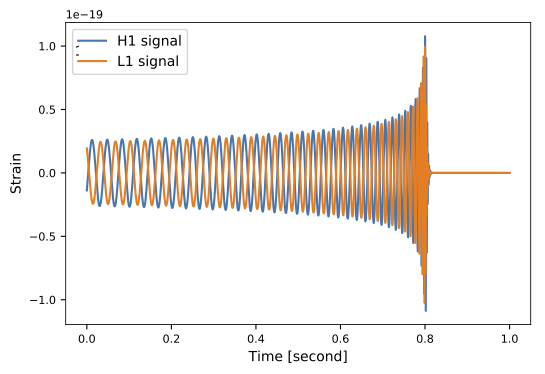
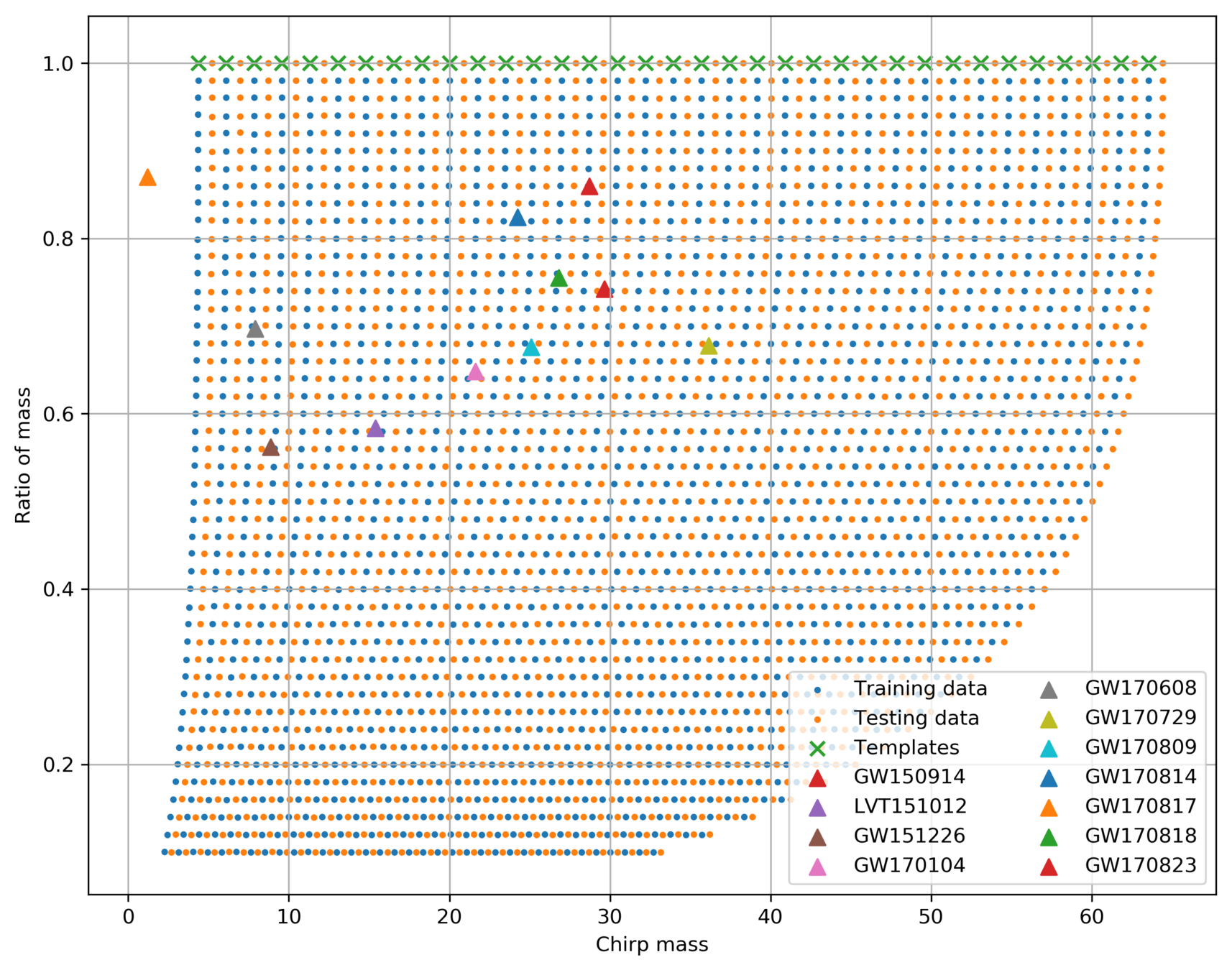
Dataset & Templates
| template | waveform (train/test) | |
|---|---|---|
| Number | 35 | 1610 |
| Length (s) | 1 | 5 |
| equal mass |
FYI: sampling rate = 4096Hz
(In preprint)
62.50M⊙ + 57.50M⊙ (\(\rho_{amp}=0.5\))
Dataset & Templates
(In preprint)
| template | waveform (train/test) | |
|---|---|---|
| Number | 35 | 1610 |
| Length (s) | 1 | 5 |
| equal mass |
FYI: sampling rate = 4096Hz
Training Strategy
Probability
(sigmoid function)
(In preprint)
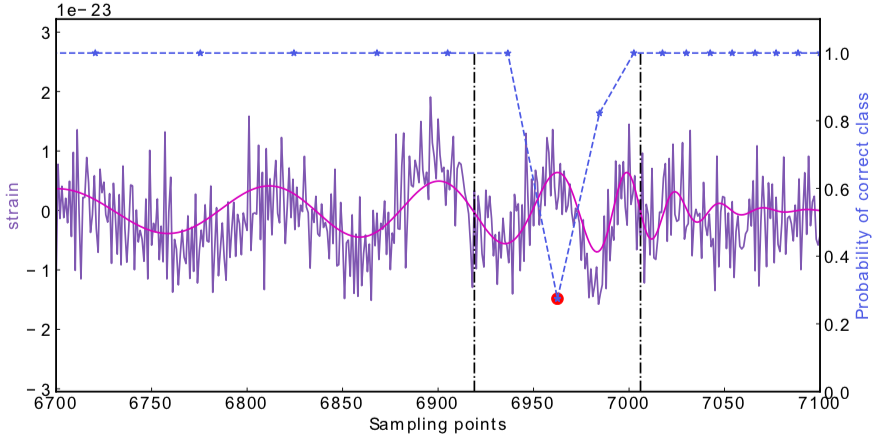
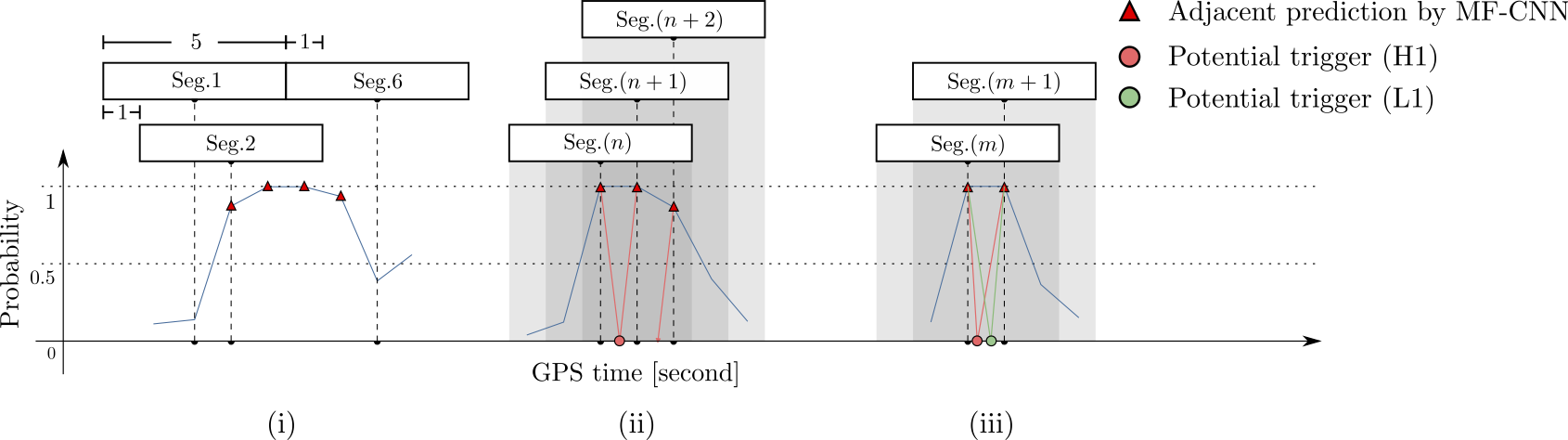
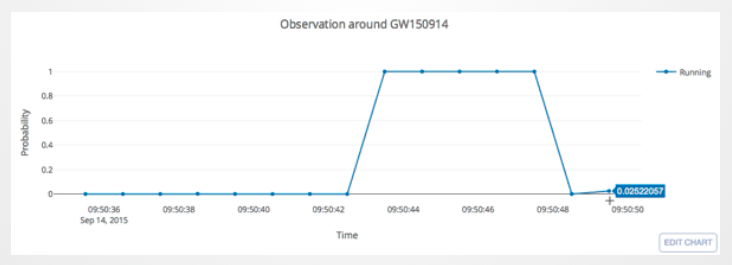
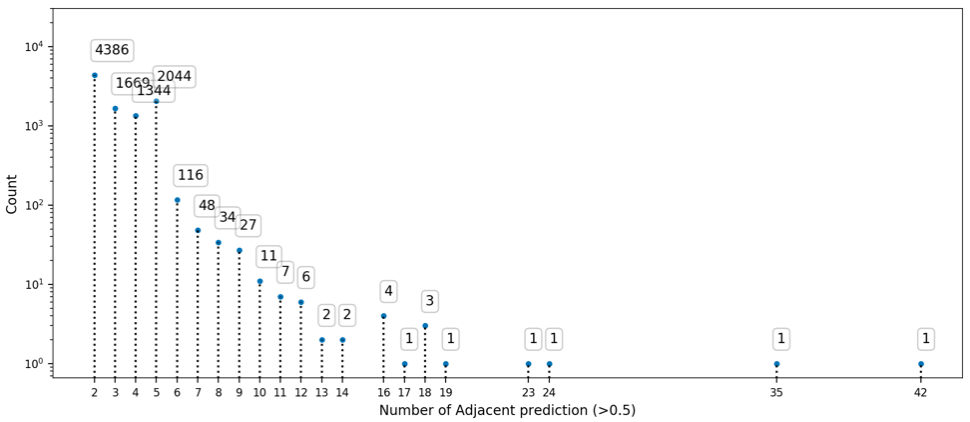
Search methodology
(In preprint)
(In preprint)
(In preprint)
(In preprint)
(In preprint)
(In progress)
Population property on O1
Detection ratio
Population property on O1
(In progress)
Population property on O1
(In progress)
Population property on O1
(In progress)
Interesting!
Some benefits from MF-CNN architechure
Simple configuration for GW data generation
Almost no data pre-processing
Easy parallel deployments, multiple detectors can be benefit a lot from this design
Thank you for your attention!
Some benefits from MF-CNN architechure
Simple configuration for GW data generation
Almost no data pre-processing
Easy parallel deployments, multiple detectors can be benefit a lot from this design
By He Wang
PDF version for ICIAM 2019 (July 16th, 2019)




