









































































He Wang PRO
Knowledge increases by sharing but not by saving.
2023 Summer School on GW @TianQin
He Wang (王赫)
2023/08/22
ICTP-AP, UCAS
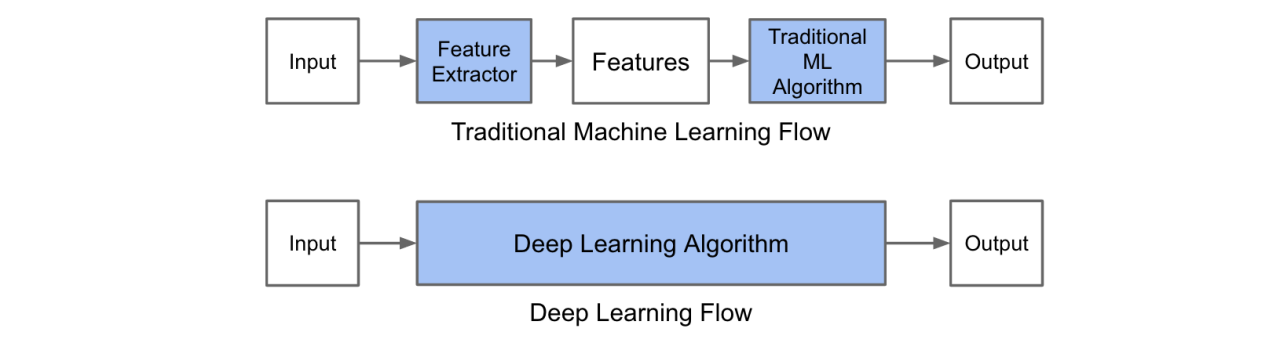
# DL: Intro
深度学习技术:概述
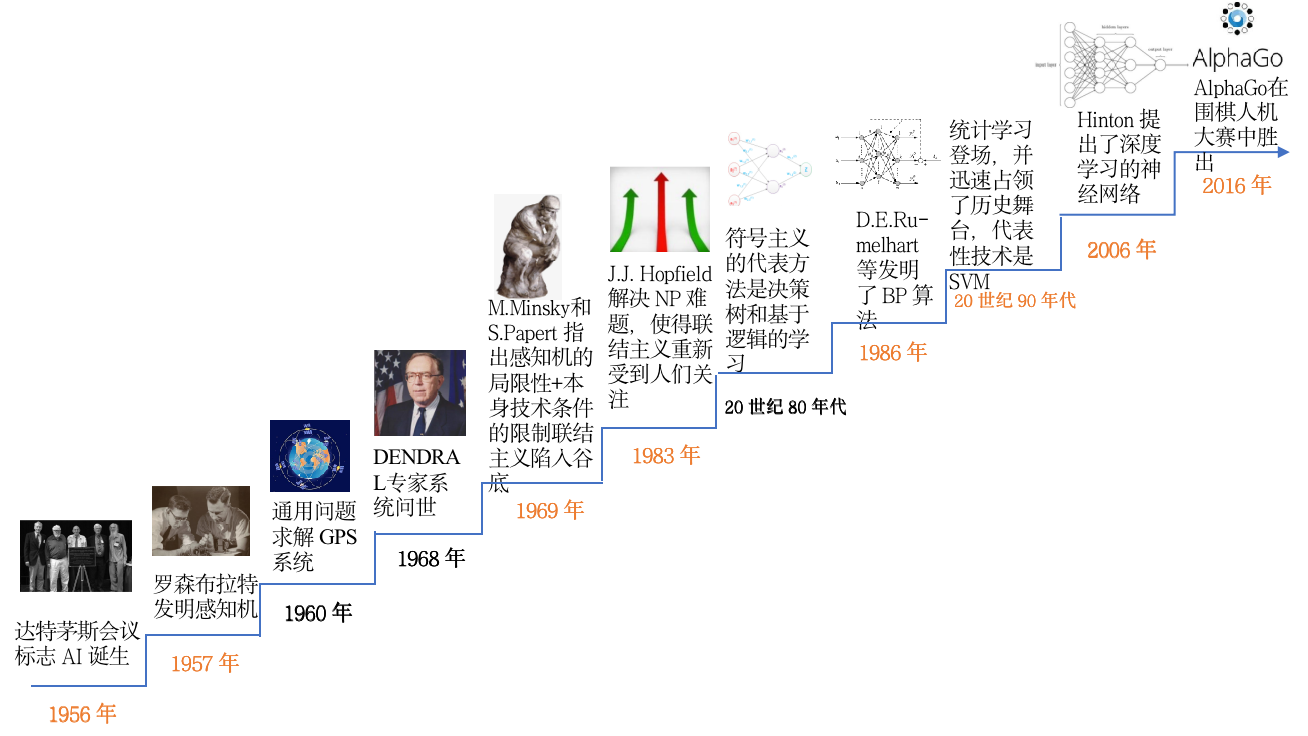
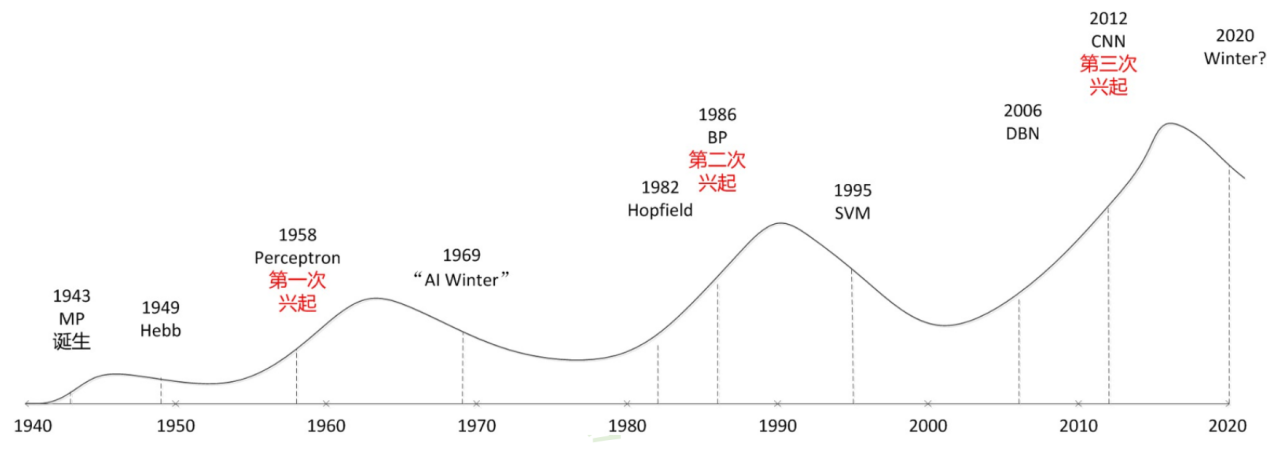
深度学习技术的起源
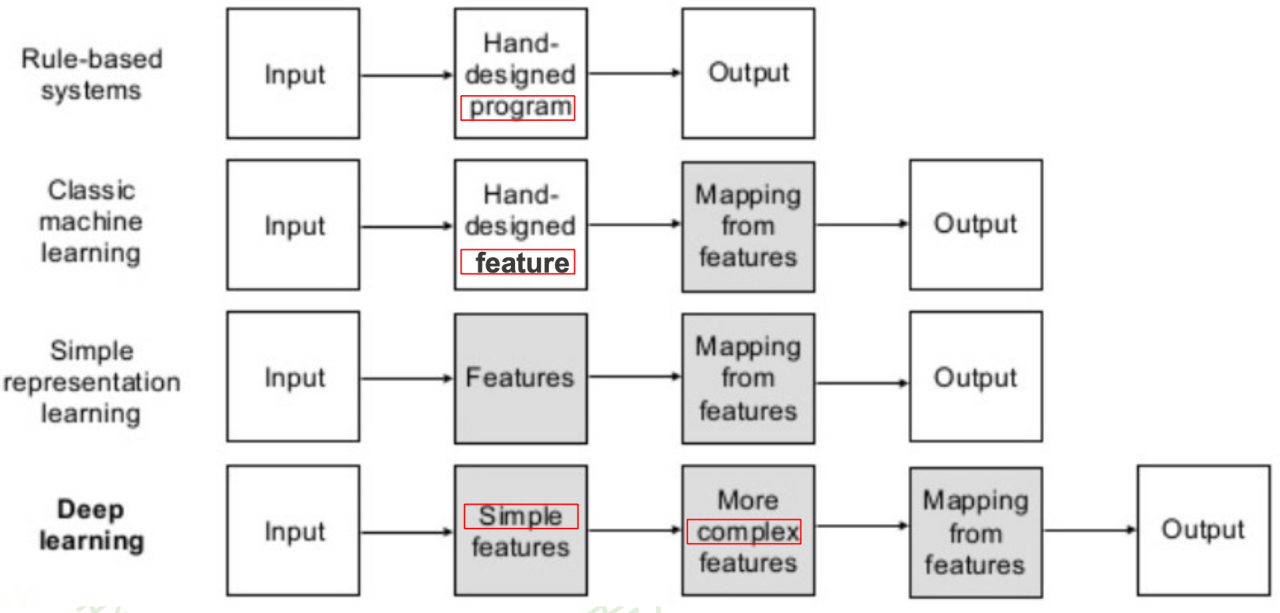
# DL: Intro
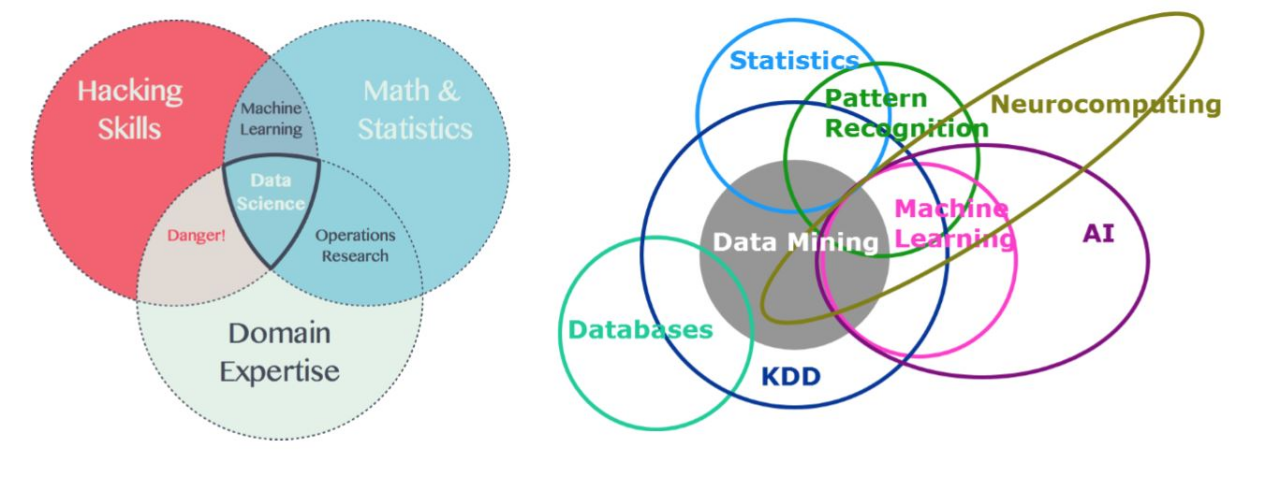
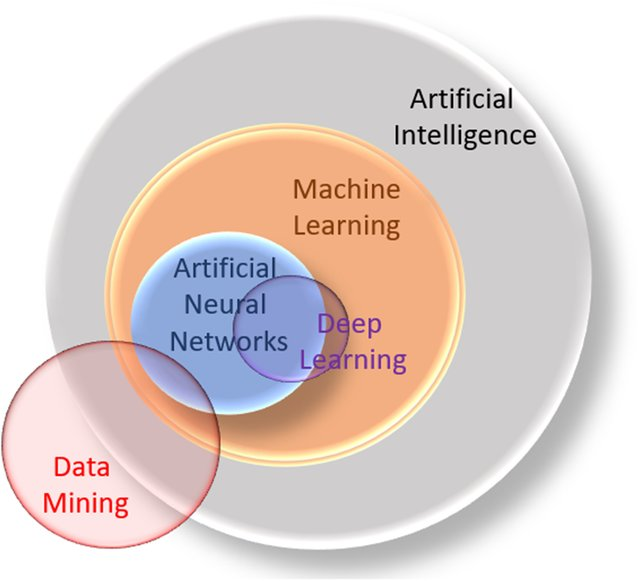
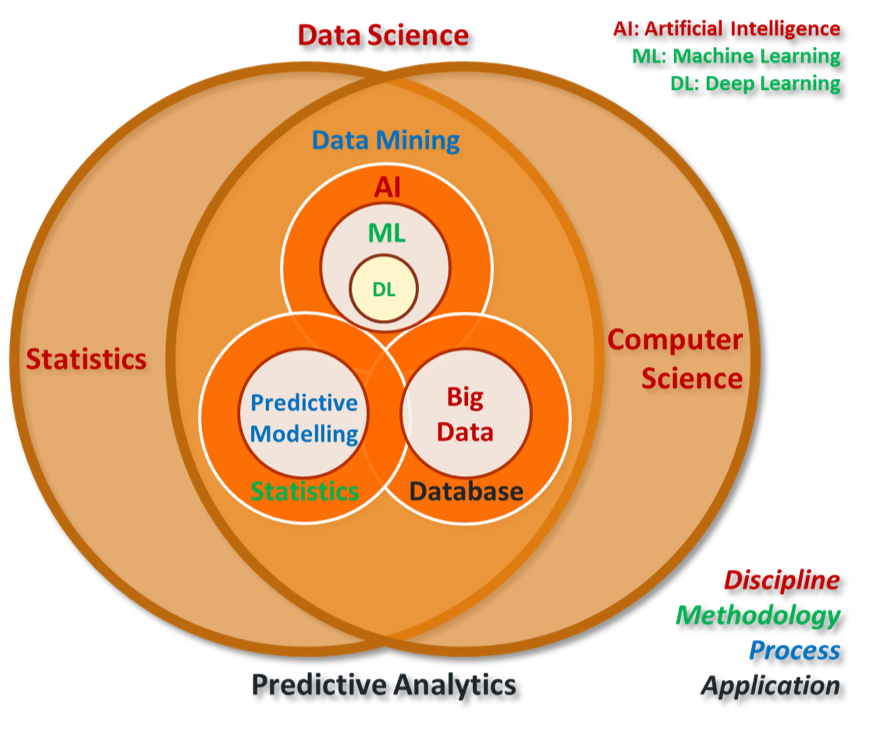
Knowledge Discovery in Database, KDD
深度学习技术的起源
人工智能(Artificial Intelligence) 使一部机器像人一样进行感知、认知、决策、执行的人工程序或系统。
# DL: Intro
深度学习技术的起源
# DL: Intro
深度学习技术的起源
# DL: Intro
深度学习技术的起源
# DL: Intro
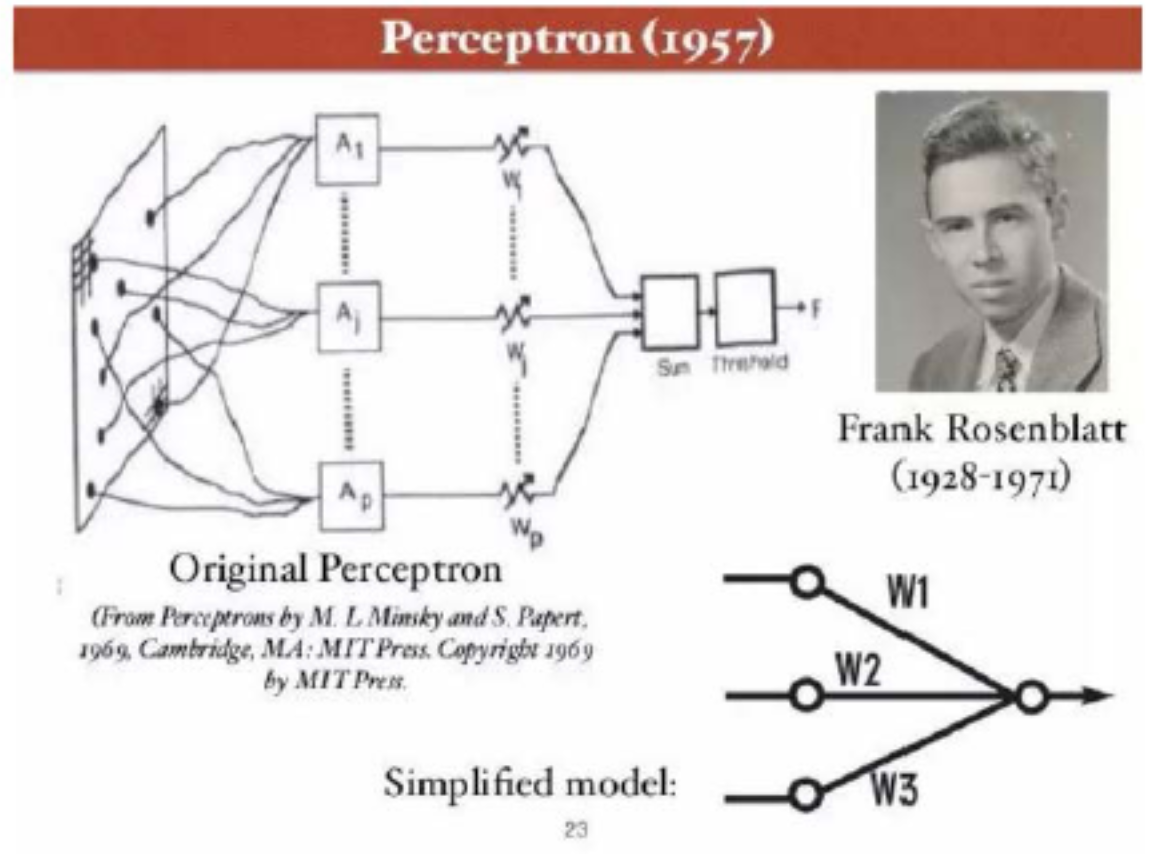
一切的开始:感知器
# DL: Intro
一切的开始:感知器
# DL: Intro
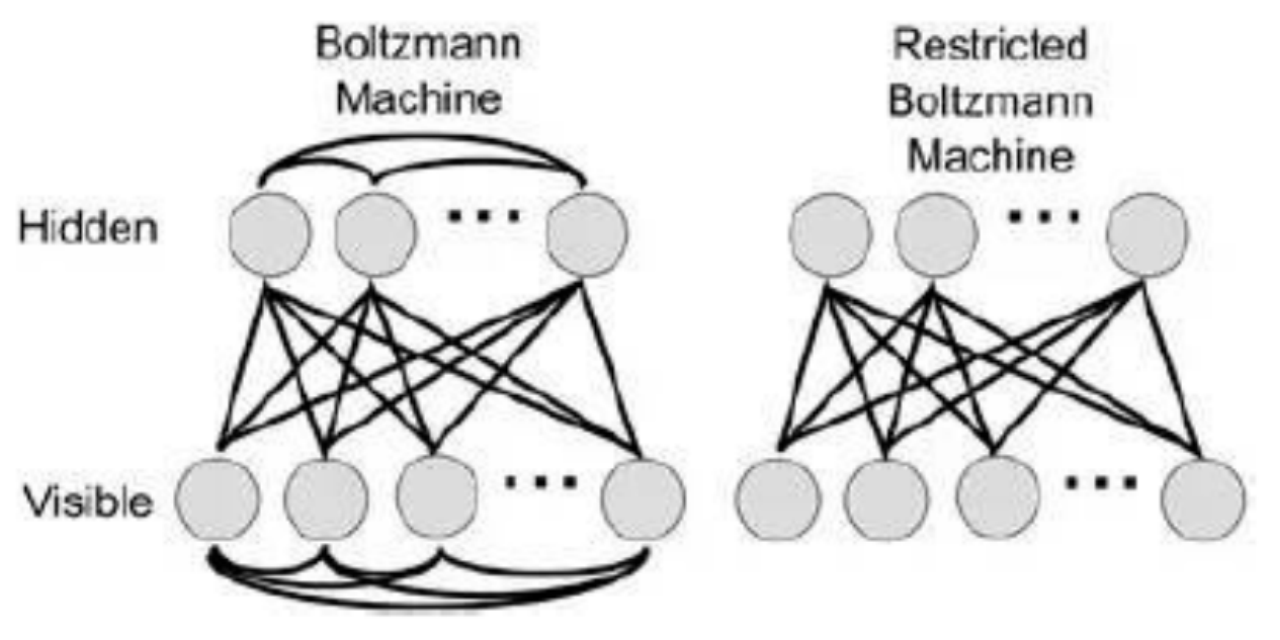
深度学习技术的发展
# DL: Intro
深度学习技术的发展
# DL: Intro
深度学习技术的发展
2003 年,Yann LeCun 等人在 NEC 实验室的使用CNN进行人脸检测。
# DL: Intro
深度学习技术的发展
SVM (support vector machines)
# DL: Intro
深度学习技术的发展
# DL: Intro
深度学习技术的发展
# DL: Intro
深度学习技术的发展
# DL: Intro
深度学习技术的发展
# DL: Intro
深度学习技术的发展
# DL: Intro
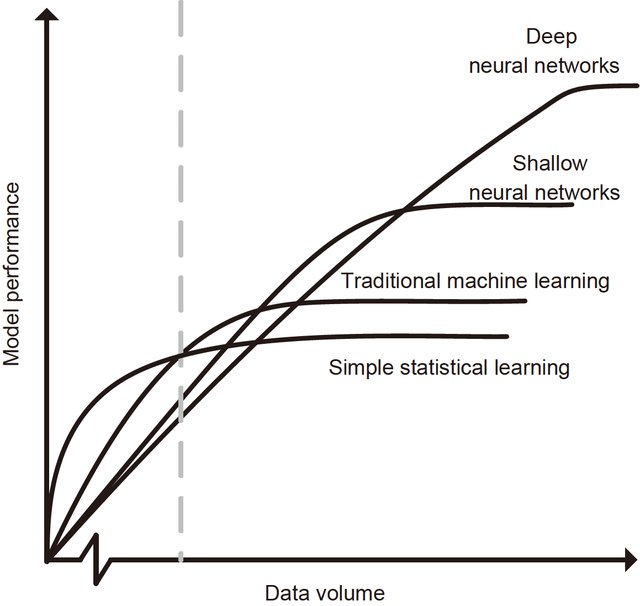
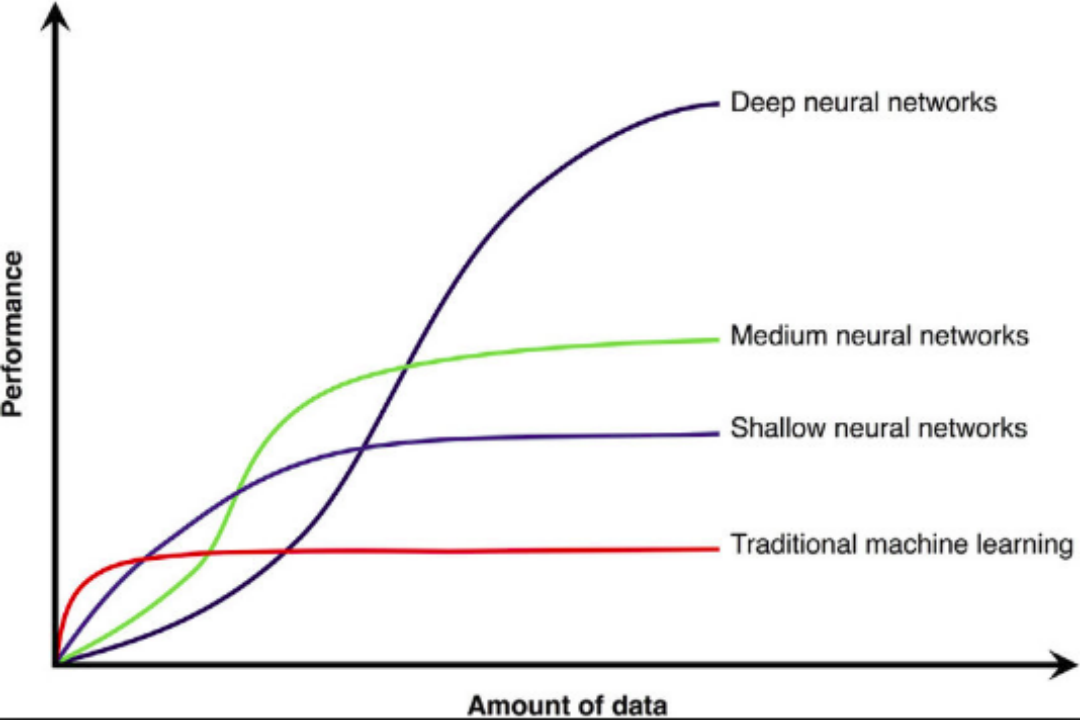
深度学习技术的应用
大数据(海量)
算法(神经网络)
计算力(GPU硬件)
算法(神经网络)
人工智能
LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. “Deep Learning.” Nature 521, no. 7553 (May 1, 2015): 436–44. https://doi.org/10.1038/nature14539.
# DL: Intro
深度学习技术的特点
# DL: Intro
深度学习技术的特点
# DL: Intro
深度学习技术的特点
# DL: Intro
深度学习:工程技术 or 科学研究 ?
# DL: Intro
机器学习与深度学习技术的学习材料
书中例子多而形象,适合当做工具书
模型+策略+算法
(从概率角度)
机器学习
(公理化角度)
讲理论,不讲推导
经典,缺前沿
神书(从贝叶斯角度)
2k 多页,难啃,概率模型的角度出发
花书:DL 圣经
科普,培养直觉
# DL: Intro
机器学习与深度学习技术的学习材料
工程角度,无需高等
数学背景
参数非参数
+频率贝叶
斯角度
统计角度
统计方法集大成的书
讲理论,
不会讲推导
贝叶斯角度
DL 应用角度
贝叶斯角度完整介绍
大量数学推导
# DL: Intro
机器学习与深度学习技术的学习材料
优秀课程资源:
# DL: Intro
值得关注的公众号:
机器之心(顶流)
量子位(顶流)
新智元(顶流)
专知(偏学术)
微软亚洲研究院
将门创投
旷视研究院
DeepTech 深科技(麻省理工科技评论)
极市平台(技术分享)
爱可可-爱生活(微博、公众号、知乎、b站...)
陈光老师,北京邮电大学PRIS模式识别实验室
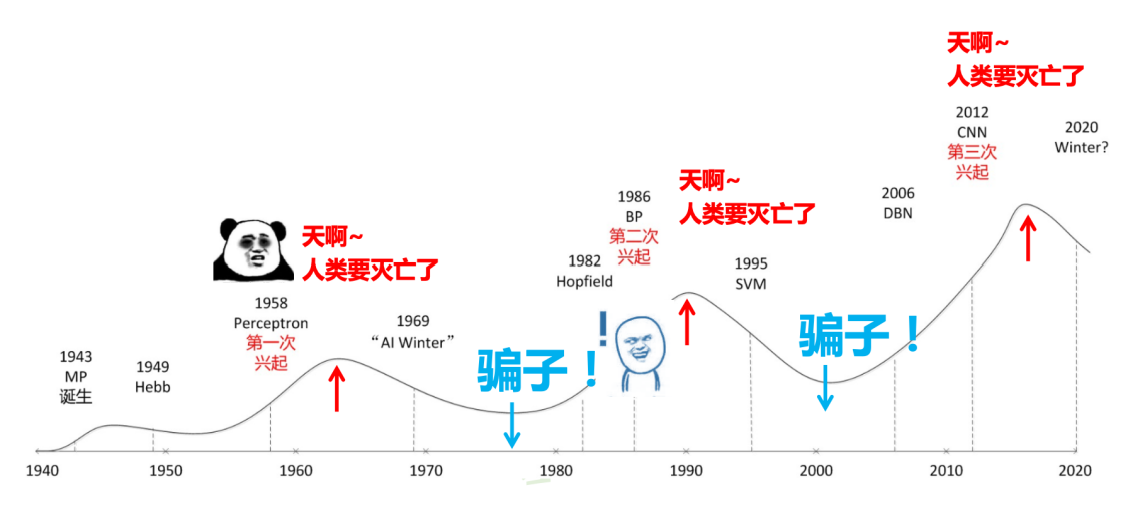
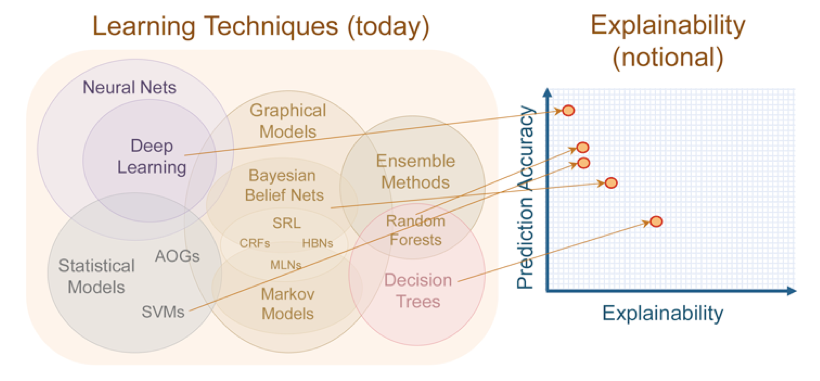
深度学习技术的“不能”
# DL: Intro
深度学习技术的“不能”
Despite all of the problems I have sketched, I don't think that we need to abandon deep learning... Rather, we need to reconceptualize it: not as a universal solvent, but simply as one tool among many
# DL: Intro
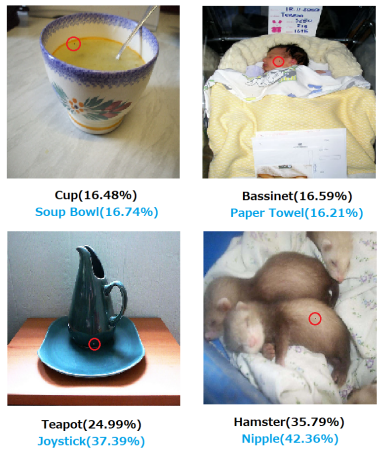
深度学习技术的“不能” (1/n)
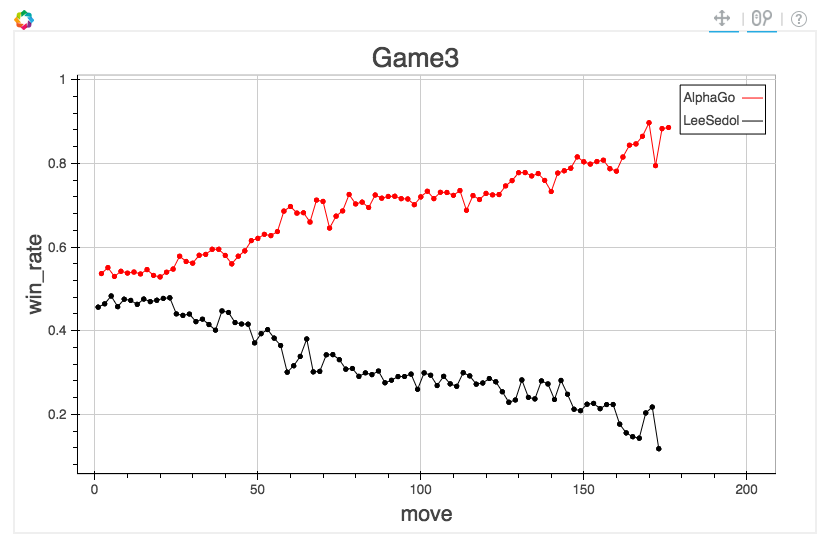
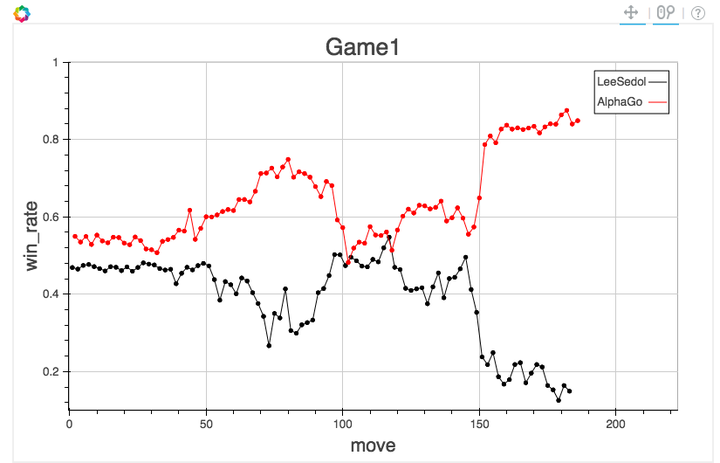
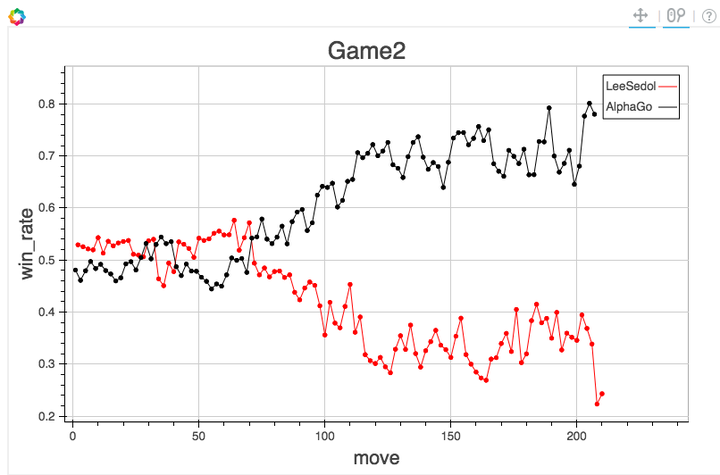
Su J, Vargas D V, Sakurai K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. (2019)
arXiv:1312.6199
vs
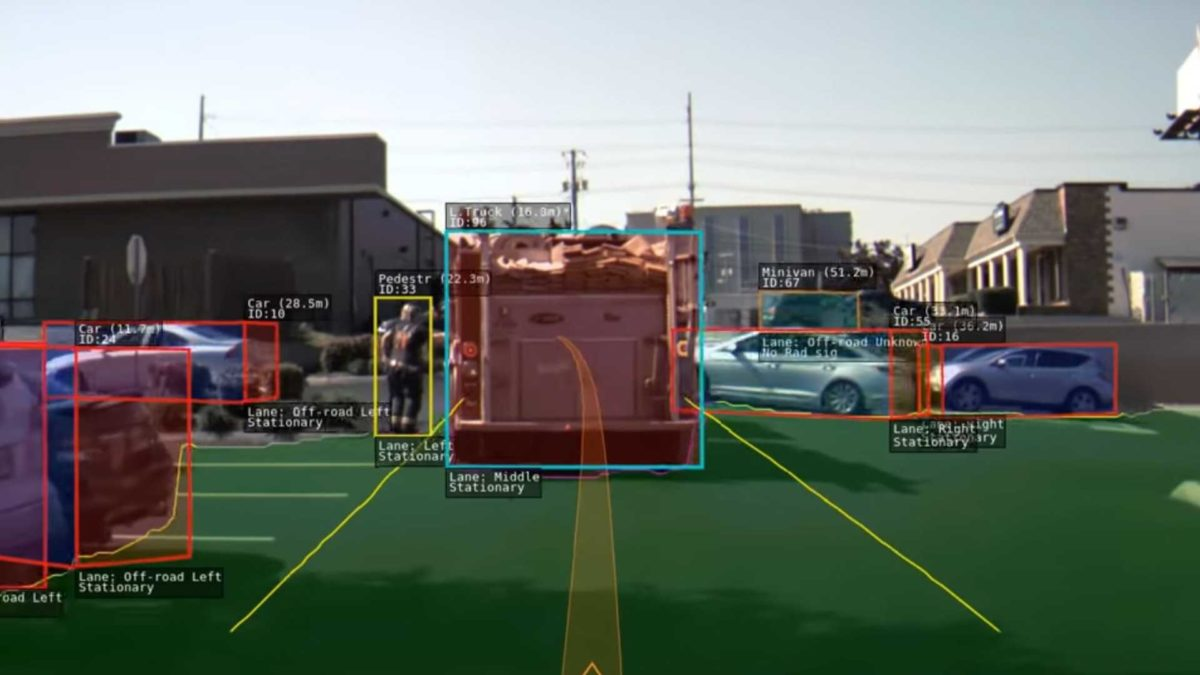
Jadhav et al. 2306.11797
# DL: Intro
深度学习技术的“不能” (2/n)
大众眼中的我们
工程师眼中的我们
数学家眼中的我们
我们眼中的自己
实际的我们
# DL: Intro
深度学习技术的“不能” (3/n)
from stackexchange
on the top activated
neurals
Conv-1
Conv-2
Conv-3
Dense-1
# DL: Intro
深度学习技术的“不能” (4/n)
# DL: Intro
深度学习技术的“不能” (5/n)
“鹦鹉”智能
“乌鸦”智能
# DL: Intro
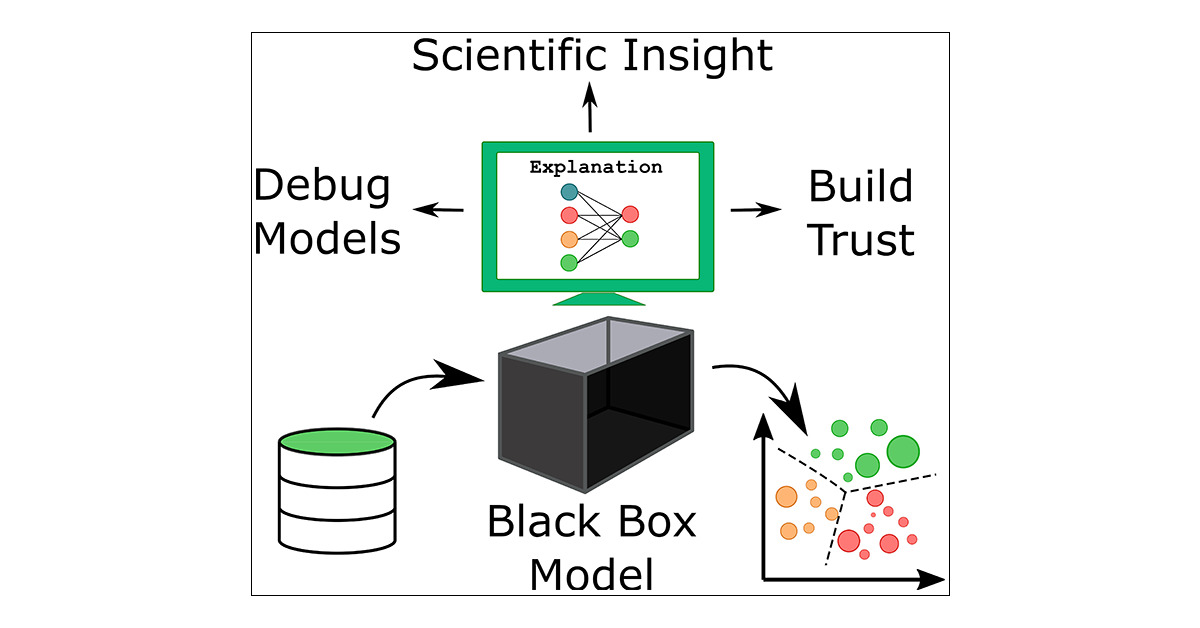
深度学习技术的“不能”与解释性
深度学习的“不能”
解释性的三个层次
“对症下药”(找得到)
知道那些特征输出有重要影响,出了问题准确快速纠错
不再“对牛弹琴”(看得懂)
双向:算法能被人的知识体系理解+利用和结合人类知识
稳定性低
可调试性差
参数不透明
机器偏见
增量性差
推理能力差
“站在巨人的肩膀上”(留得下)
知识得到有效存储、积累和复用
\(\rightarrow\) 越学越聪明
# DL: Intro
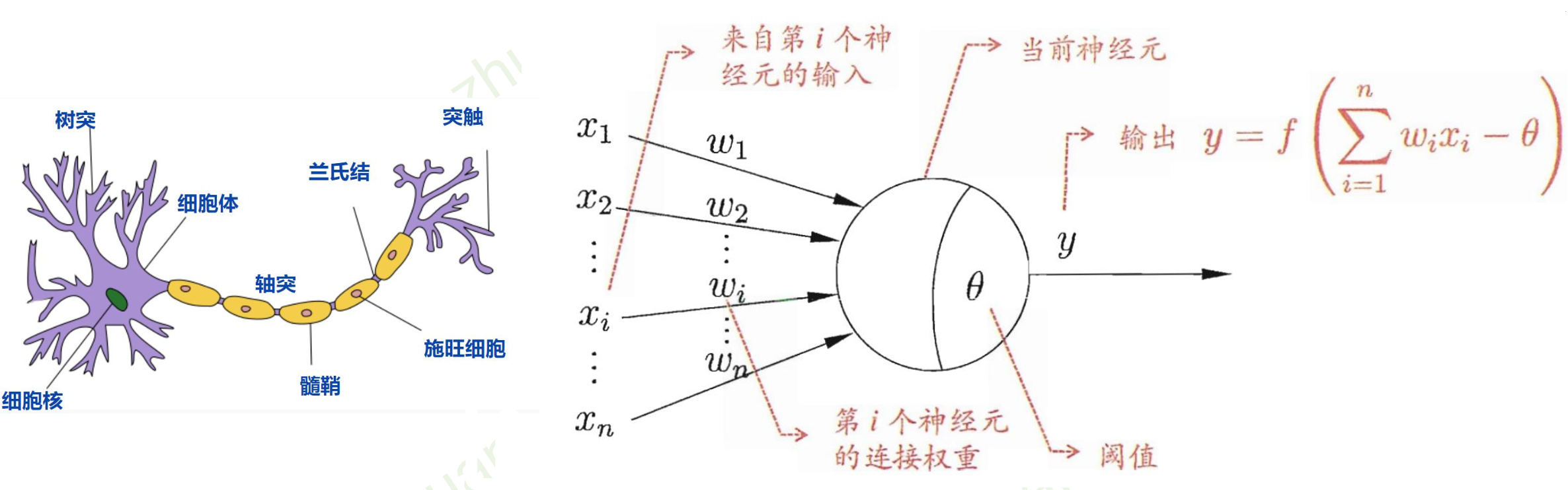
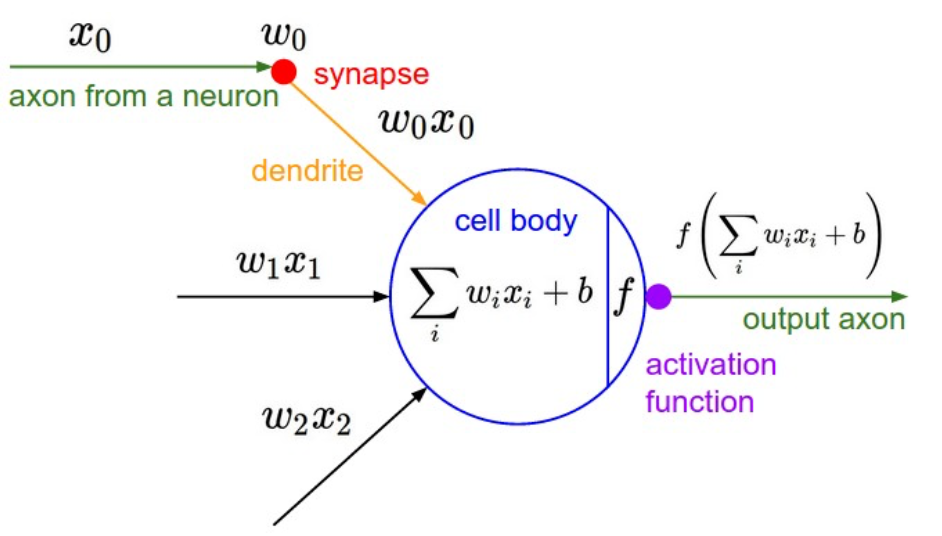
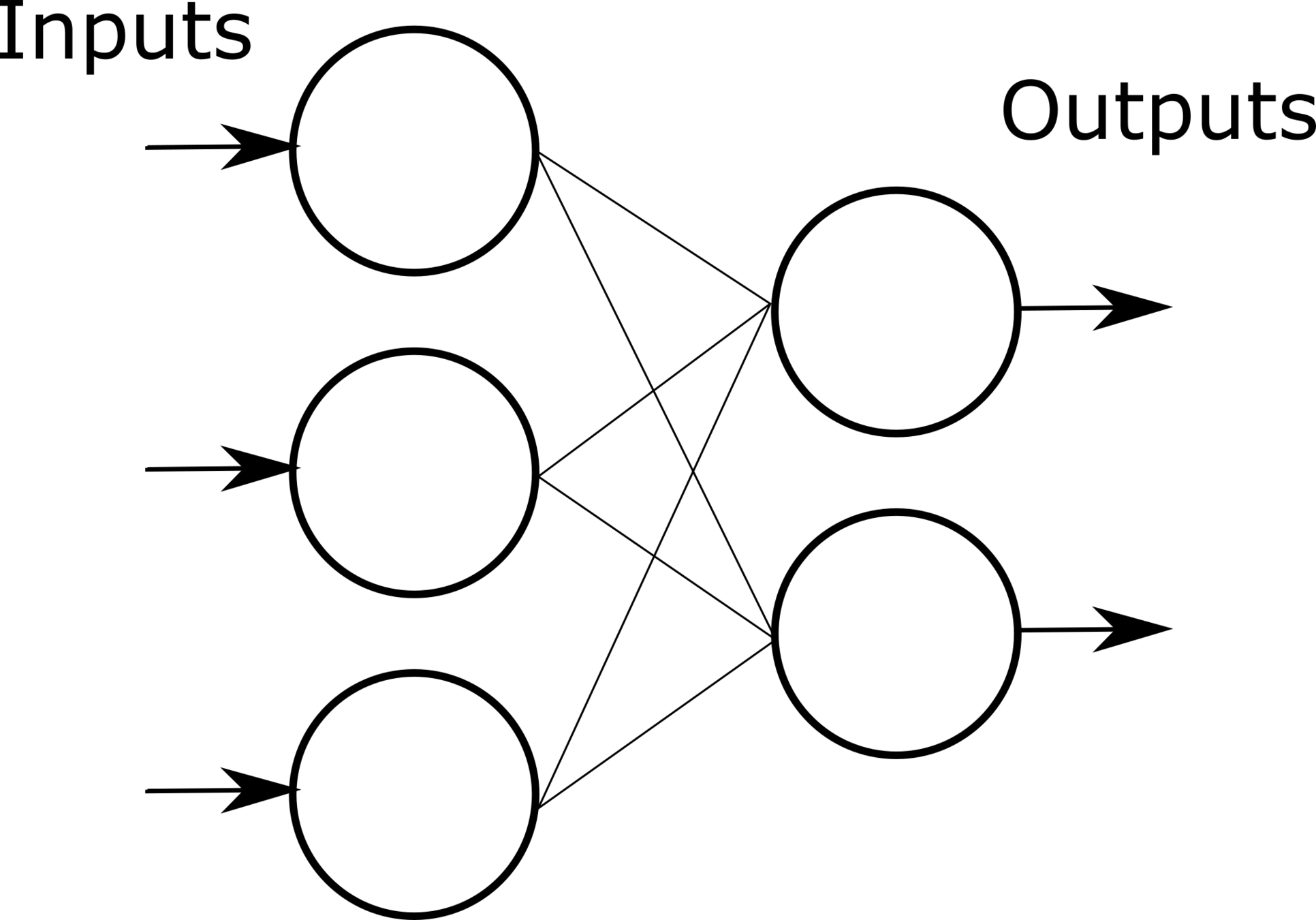
深度学习:神经网络基础
# DL: Intro
深度学习:神经网络基础
没有激活函数的话,
相当于一维矩阵相乘:
多层和一层一样
只能拟合线性函数
# DL: Intro
深度学习:神经网络基础
# DL: Intro
深度学习:神经网络基础
# DL: Intro
深度学习:神经网络基础
# DL: Intro
深度学习:神经网络基础
# DL: Intro
深度学习:神经网络基础
Seide F, Li G, Yu D. Conversational speech transcription using context-dependent deep neural networks[C] Interspeech. 2011.
# DL: Intro
深度学习:神经网络基础
# DL: Intro
深度学习:神经网络基础
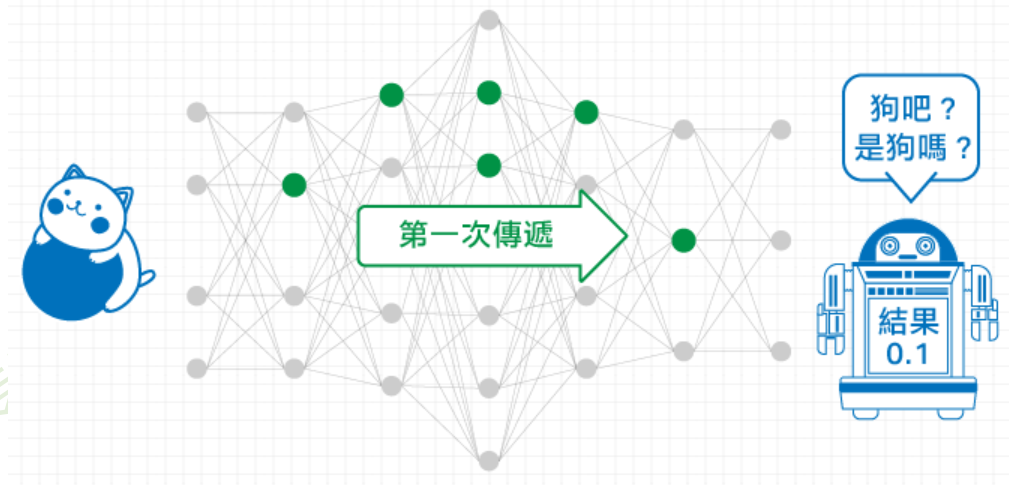
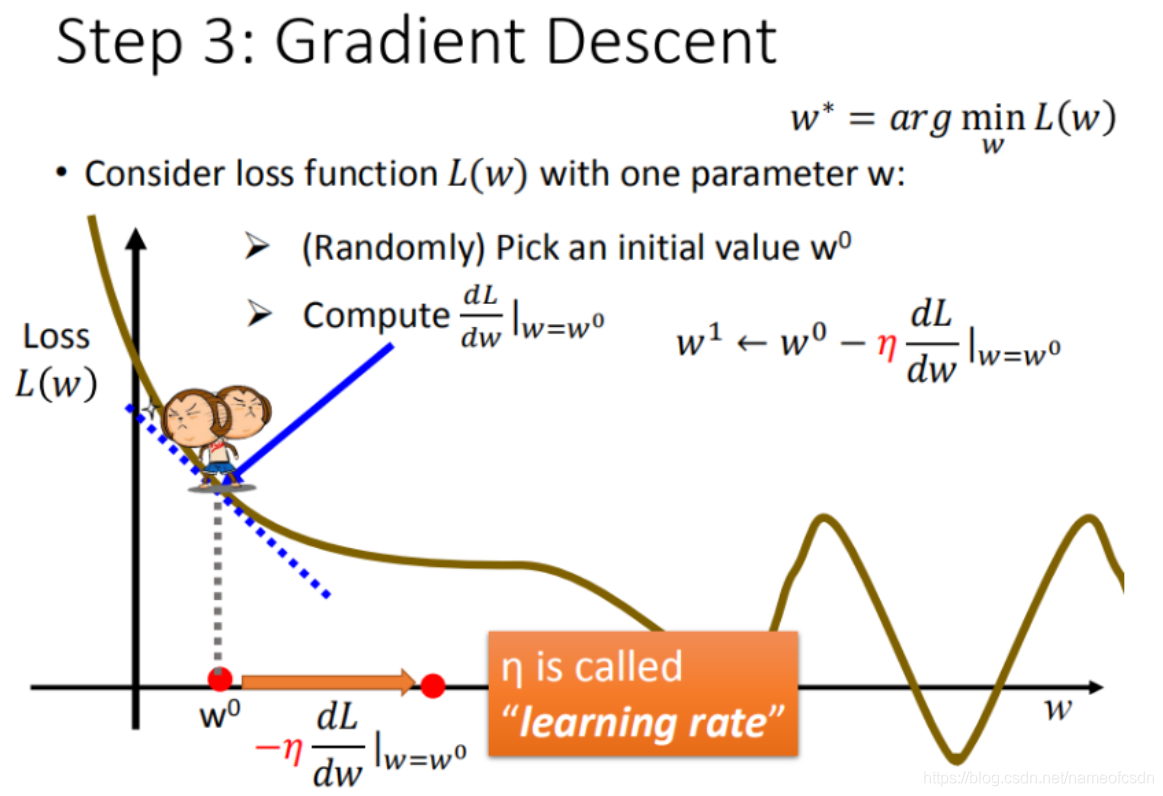
多层神经网络可看成是一个复合的非线性多元函数 \(\mathrm{F}(\cdot): X \rightarrow Y\)
给定训练数据 \(\left\{x^i, y^i\right\}_{i=1: N}\),希望损失 \(\sum_i \operatorname{loss}\left(F_w\left(x^i\right), y^i\right)\) 尽可能小.
图片取自李宏毅老师《机器学习》课程
# DL: Intro
深度学习:神经网络基础
多层神经网络可看成是一个复合的非线性多元函数 \(\mathrm{F}(\cdot): X \rightarrow Y\)
给定训练数据 \(\left\{x^i, y^i\right\}_{i=1: N}\),希望损失 \(\sum_i \operatorname{loss}\left(F_w\left(x^i\right), y^i\right)\) 尽可能小
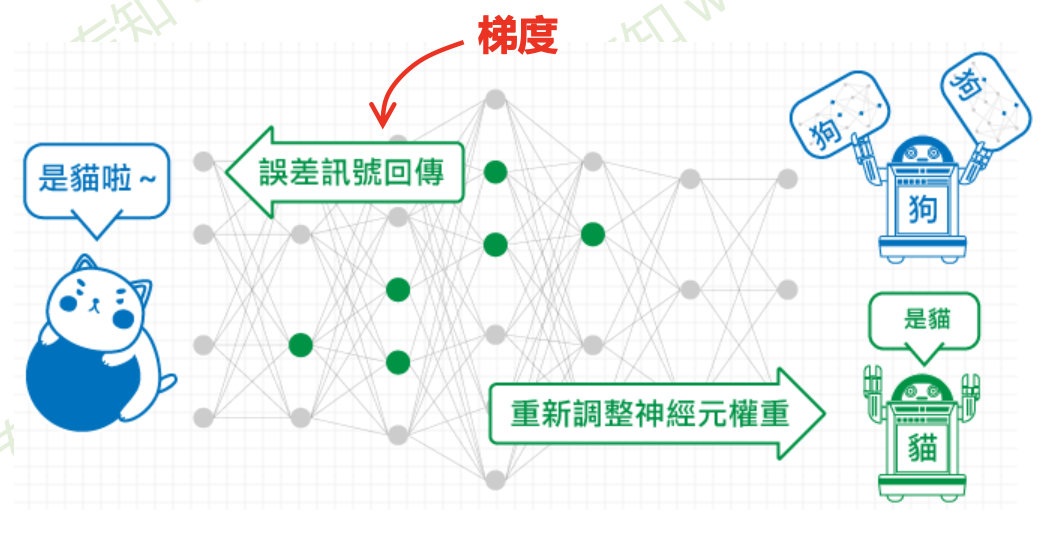
反向传播算法 (BP) 的目标是找损失函数关于神经网络中可学习参数 (\(w\)) 的偏导数(证明略)
# DL: Intro
深度学习:神经网络基础
多层神经网络可看成是一个复合的非线性多元函数 \(\mathrm{F}(\cdot): X \rightarrow Y\)
给定训练数据 \(\left\{x^i, y^i\right\}_{i=1: N}\),希望损失 \(\sum_i \operatorname{loss}\left(F_w\left(x^i\right), y^i\right)\) 尽可能小
反向传播算法 (BP) 的目标是找损失函数关于神经网络中可学习参数 (\(w\)) 的偏导数(证明略)
# DL: Intro
Credit: Cameron R. Wolfe
From here
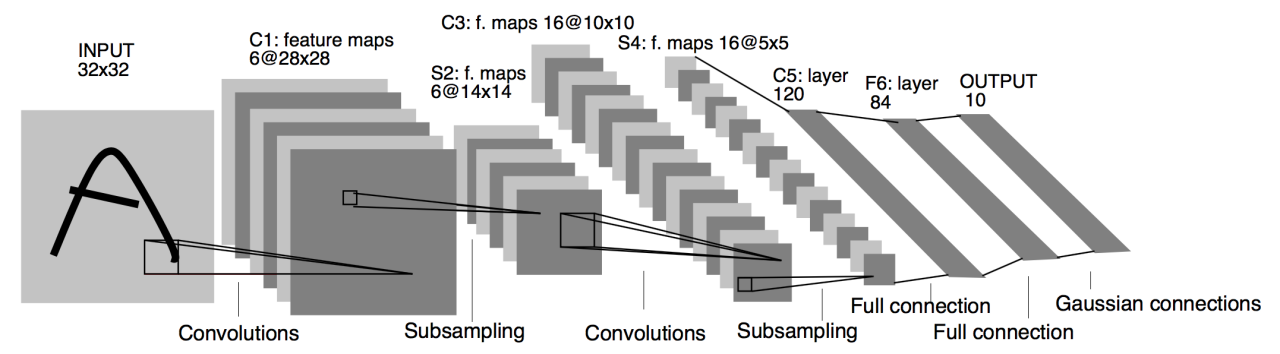
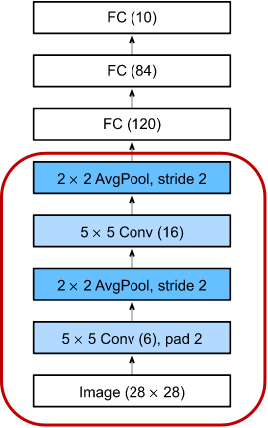
深度学习:卷积神经网络
# DL: Intro
深度学习:卷积神经网络
Gebru et al. ICCV (2017)
Zhou et al. CVPR (2018)
Shen et al. CVPR (2018)
Image courtesy of Tesla (2020)
# DL: Intro
深度学习:卷积神经网络
# DL: Intro
深度学习:卷积神经网络
# DL: Intro
深度学习:卷积神经网络
# DL: Intro
深度学习:卷积神经网络
# DL: Intro
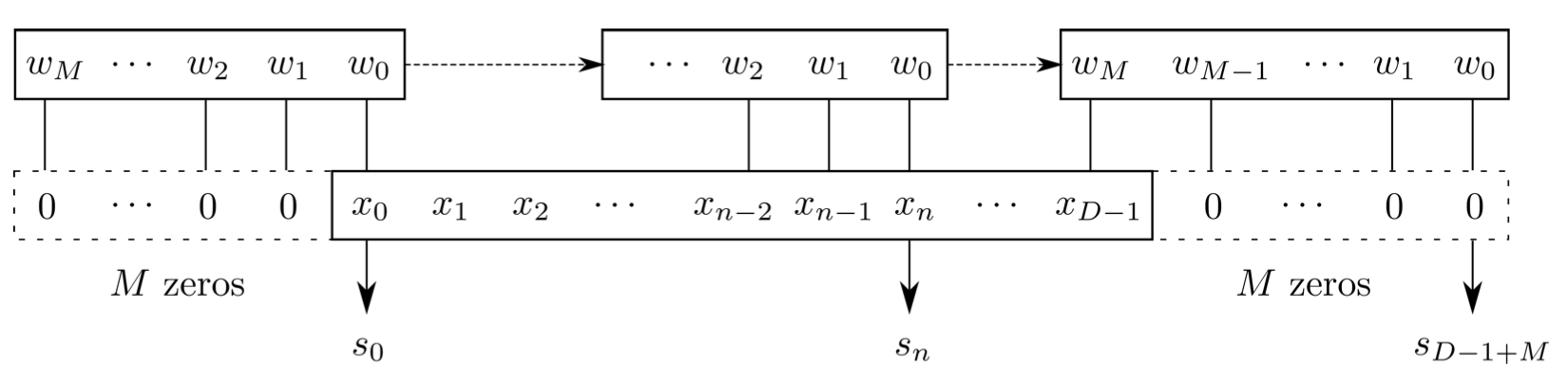
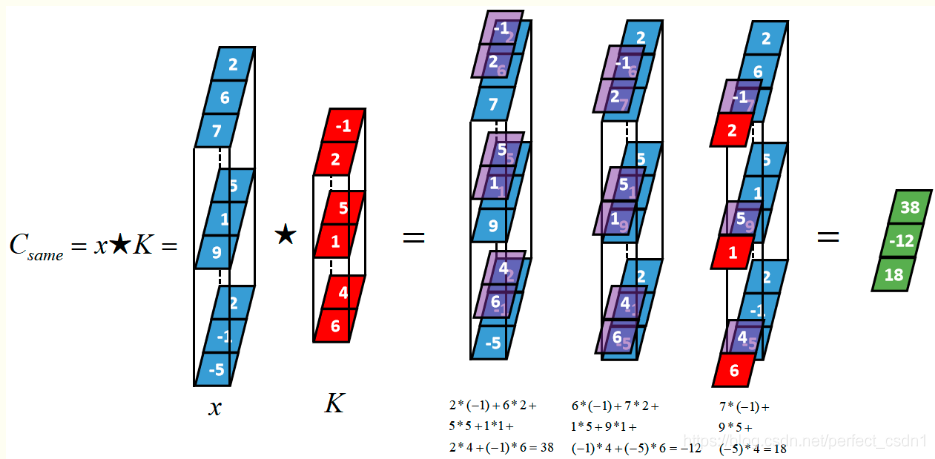
[1,1,3] \(\star\) [1,1,3] \(\rightarrow\) [1,1,3/5/7]
样本个数
“深度”维度
卷积核个数
深度学习:卷积神经网络
# DL: Intro
[1,1,3] \(\star\) [1,1,3] \(\rightarrow\) [1,1,3/5/7]
样本个数
“深度”维度
卷积核个数
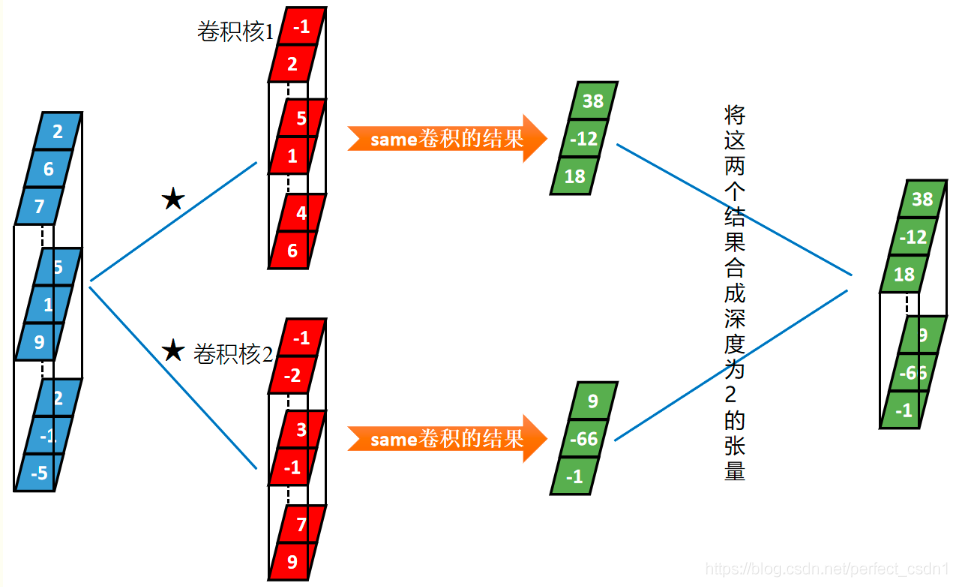
[1,3,3] \(\star\) [1,3,2] \(\rightarrow\) [1,1,3]
“深度”维度
深度学习:卷积神经网络
# DL: Intro
[1,3,3] \(\star\) [1,3,2] \(\rightarrow\) [1,1,3]
“深度”维度
[1,3,3] \(\star\) [2,3,2] \(\rightarrow\) [1,2,3]
“深度”维度
样本个数
卷积核个数
深度学习:卷积神经网络
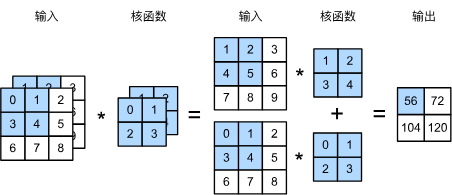
[1,2,3,3] \(\star\) [1,2,2,2] \(\rightarrow\) [1,1,2,2]
样本个数
channel
卷积核个数
长和宽
# DL: Intro
深度学习:卷积神经网络
[1,3,3,3] \(\star\) [2,3,1,1] \(\rightarrow\) [1,2,3,3]
样本个数
channel
卷积核个数
长和宽
# DL: Intro
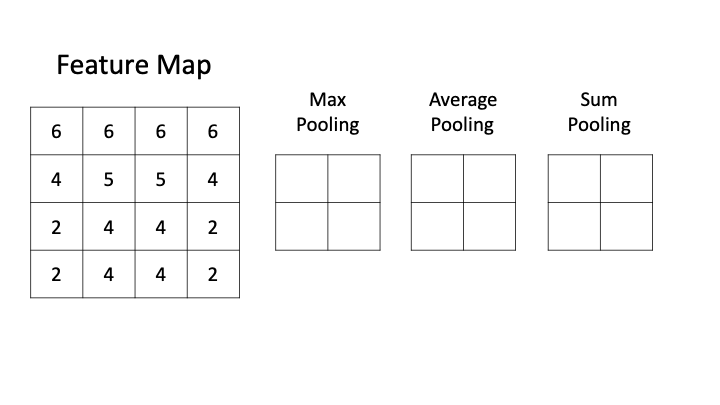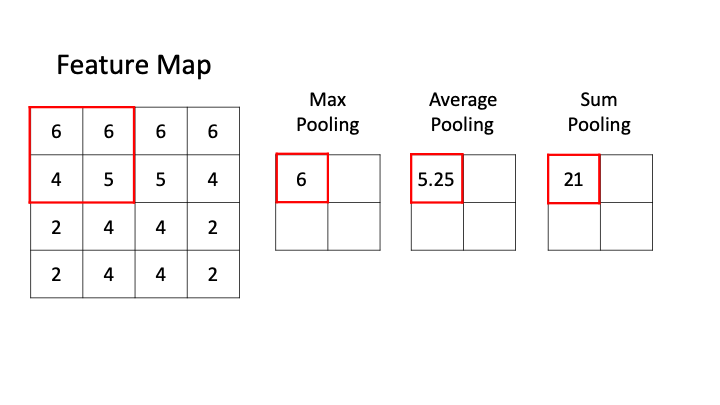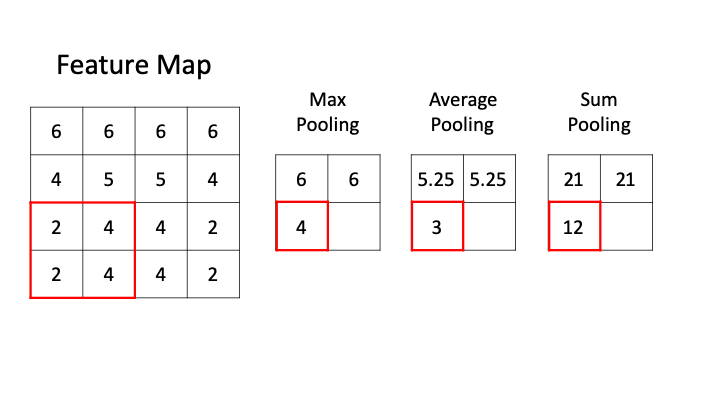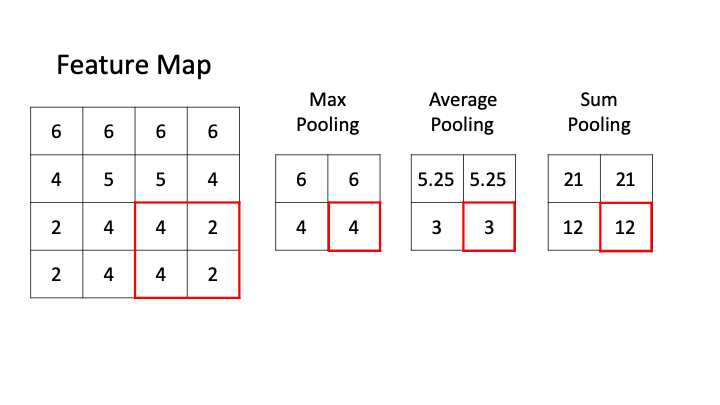
深度学习:卷积神经网络
# DL: Intro
深度学习:卷积神经网络
# DL: Intro
深度学习:卷积神经网络
# DL: Intro
深度学习:卷积神经网络
# DL: Intro
深度学习:卷积神经网络
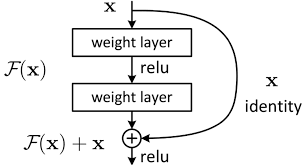
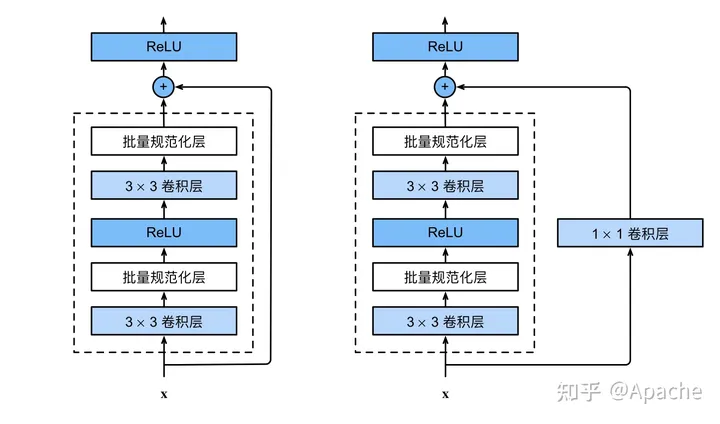
残差的思想: 去掉相同的主体部分,从而突出微小的变化。
可以被用来训练非常深的网络
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. CVPR (2016)
# DL: Intro
深度学习:卷积神经网络
# DL: Intro
# GWDA: DL
引力波数据分析与深度学习
引力波信号搜寻
# GWDA: DL
See also:
D. George and E.A. Huerta Phys. Lett. B 778 64–70 (2018)
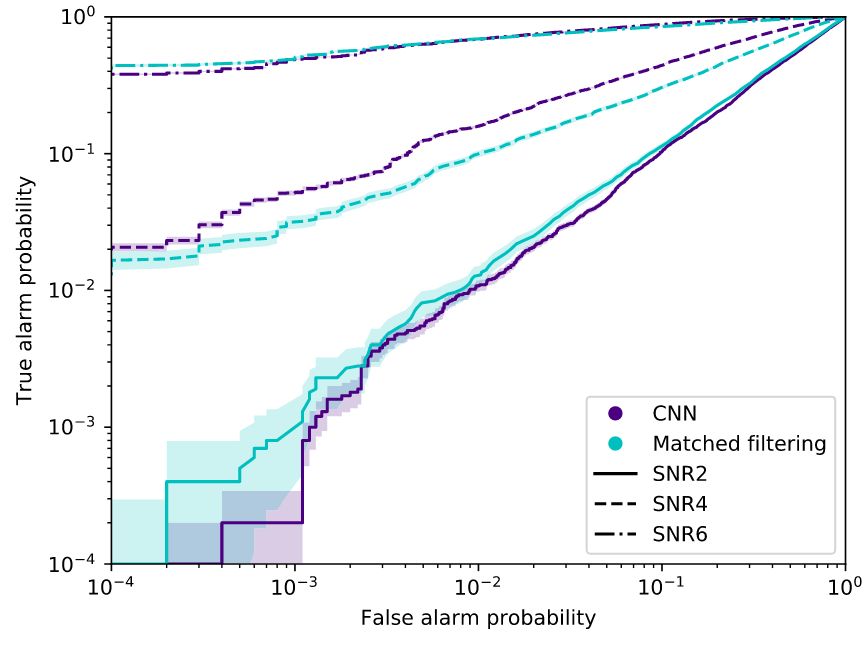
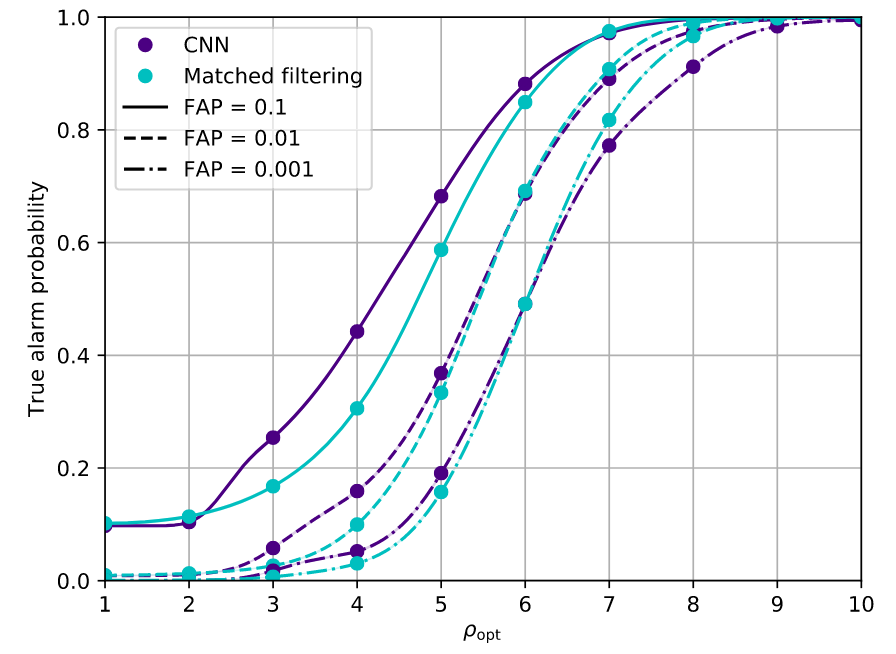
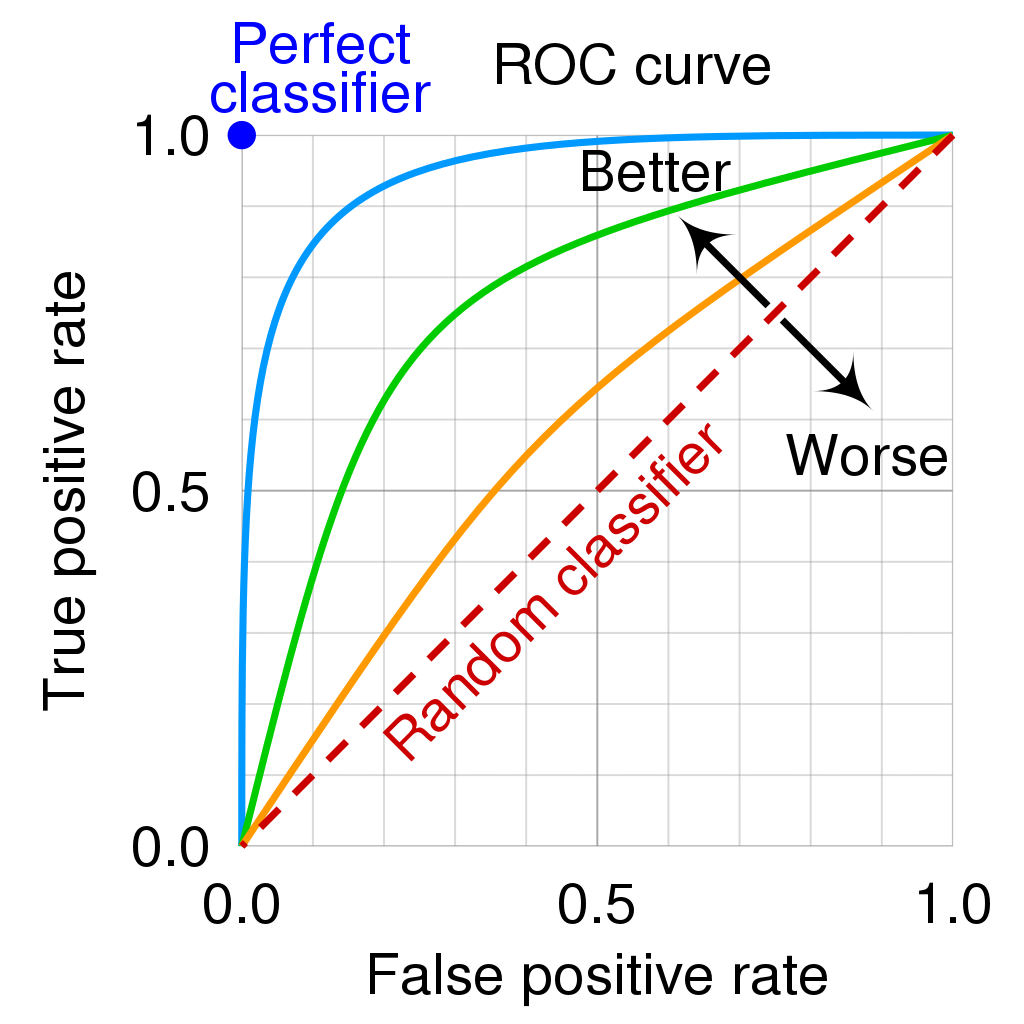
What is ROC?
引力波信号搜寻
# GWDA: DL
引力波信号搜寻
# GWDA: DL
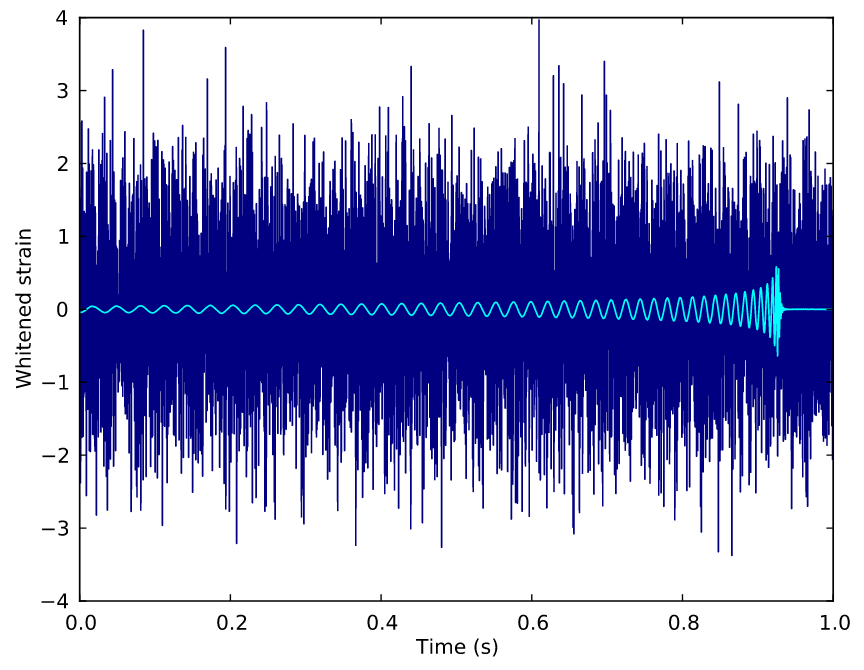
0.99
0.05
期望达到的效果(Evaluation):
H1
L1
CNN
引力波信号搜寻
# GWDA: DL
训练的过程(Train):
1
0
H1
L1
Labels
CNN
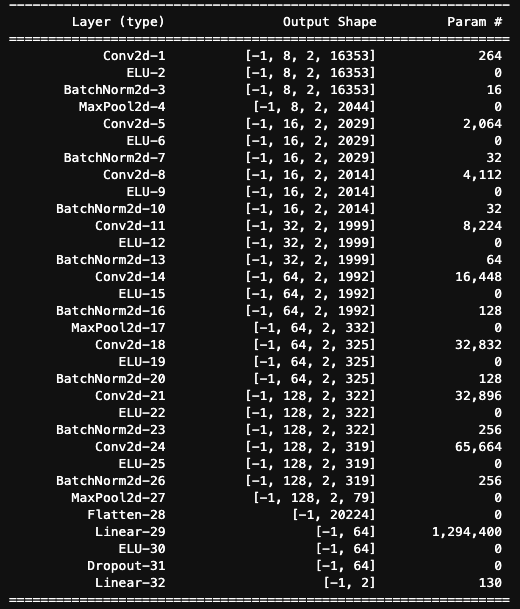
[6,2,16384][6,2]1
1
0
0
引力波信号搜寻
# GWDA: DL
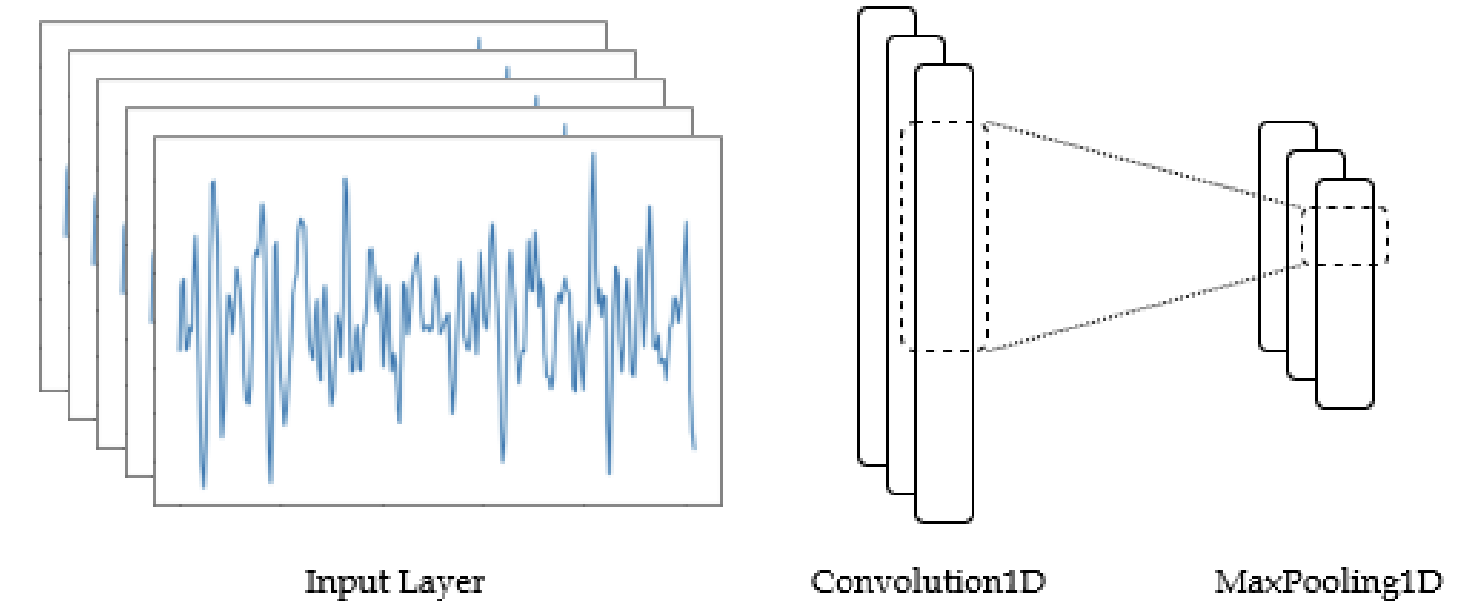
CNN
[6,2,16384] -> Reshape your input data:
[6,1,2,16384]样本个数
channel
长和宽
引力波信号搜寻
# GWDA: DL
CNN
[6,2,16384] -> Reshape your input data:
[6,1,2,16384]样本个数
in channel
长和宽
Conv2D:
Conv2d(1, 8, kernel_size=(1, 32), stride=(1, 1))[8,1,1,32][6,8,2,16353]卷积核个数 / out channel
in channel
out channel
引力波信号搜寻
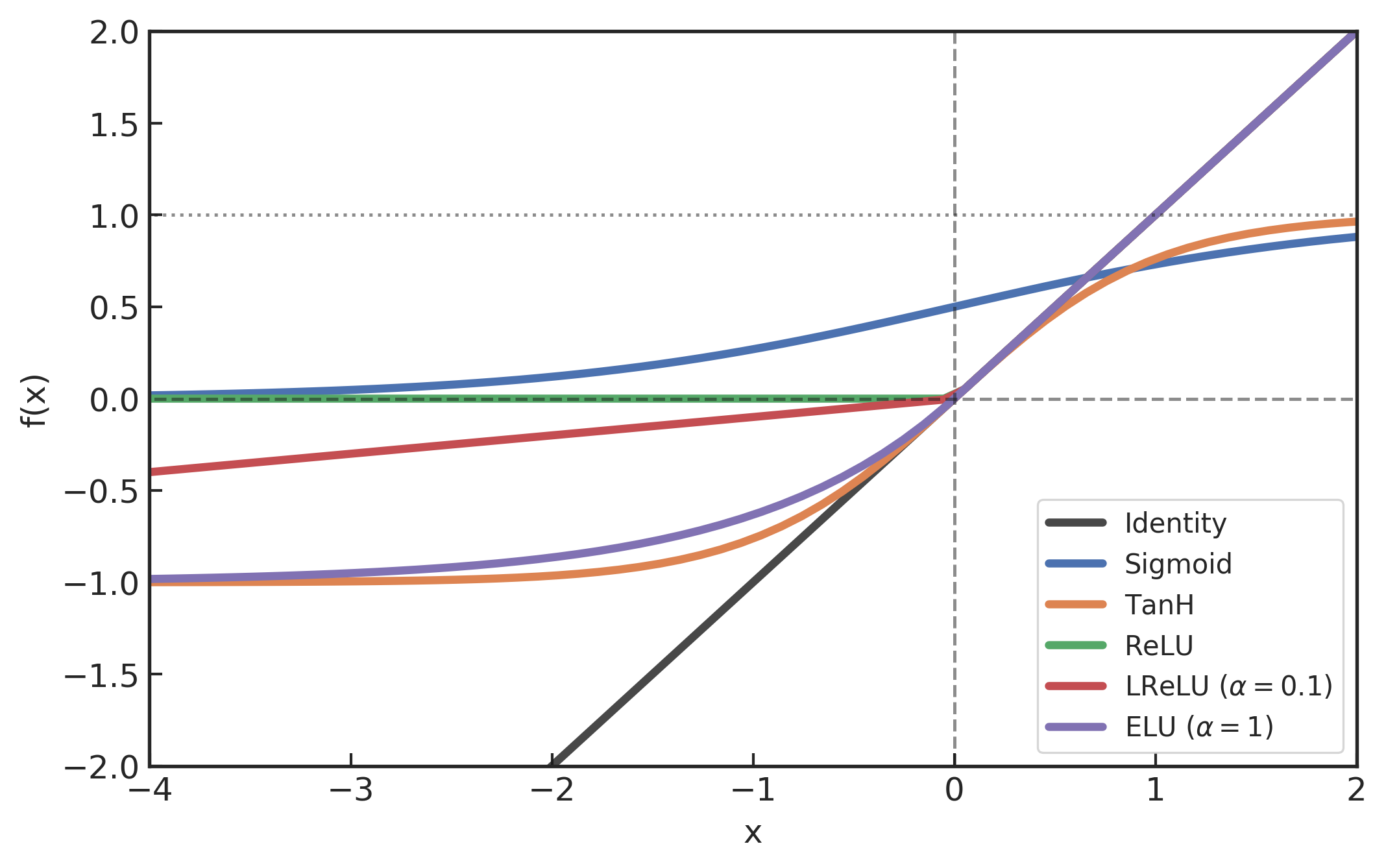
# GWDA: DL
CNN
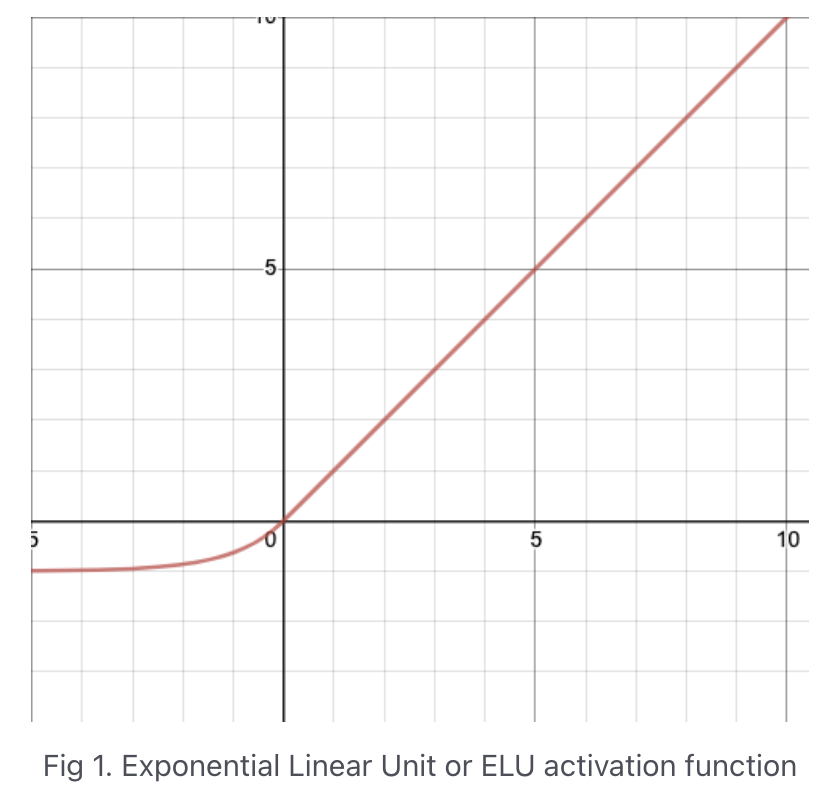
ELU activation
[6,8,2,16353][6,8,2,16353]ELU(alpha=0.01)引力波信号搜寻
# GWDA: DL
CNN
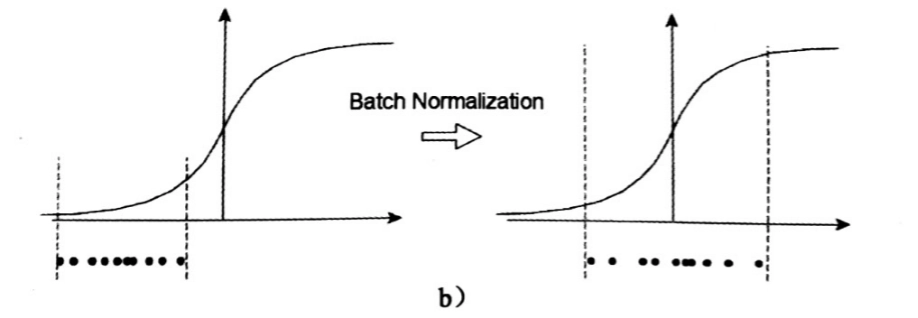
Batch Normalization
[6,8,2,16353][6,8,2,16353]BatchNorm2d(8, eps=1e-05, momentum=0.1)in channel
引力波信号搜寻
# GWDA: DL
CNN
Max Pooling
[6,8,2,16353][6,8,2,2044]MaxPool2d(kernel_size=[1, 8],
stride=[1, 8],
padding=0)引力波信号搜寻
# GWDA: DL
CNN
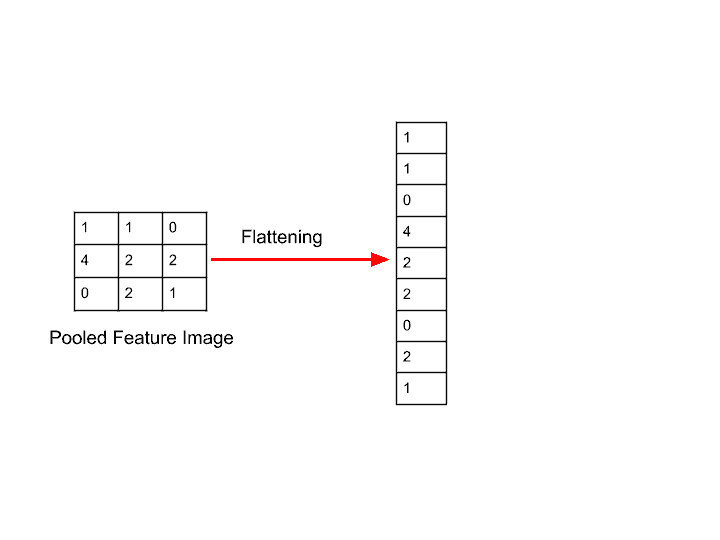
Flatten
[6,128,2,79][6,20224]Linear
[6,20224][6,64][6,64][20224,64][64,2][6,2]引力波信号搜寻
# GWDA: DL
CNN
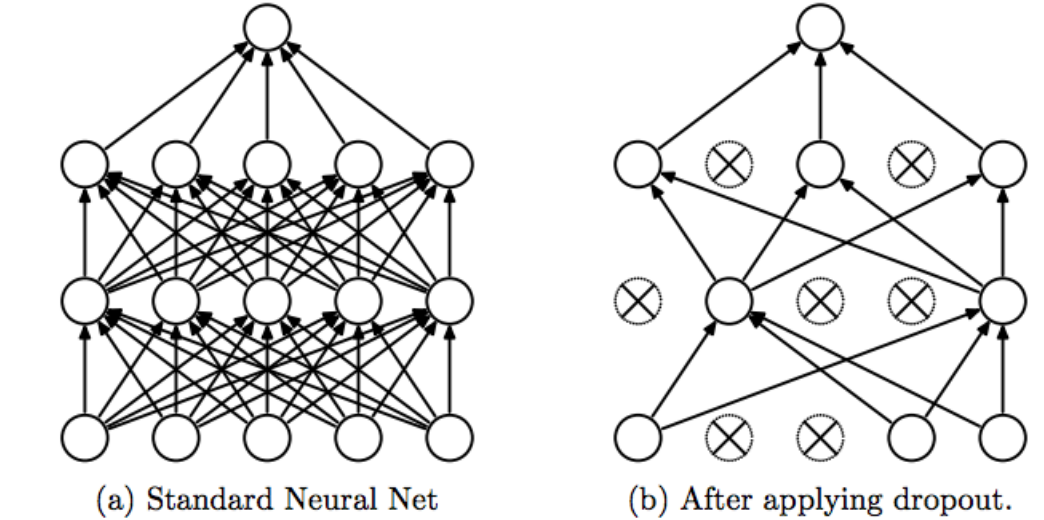
Dropout
[6,20224][6,64][20224,64]Dropout(p=0.5)引力波信号搜寻
# GWDA: DL
训练的过程(Train):
1
0
H1
L1
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]引力波信号搜寻
# GWDA: DL
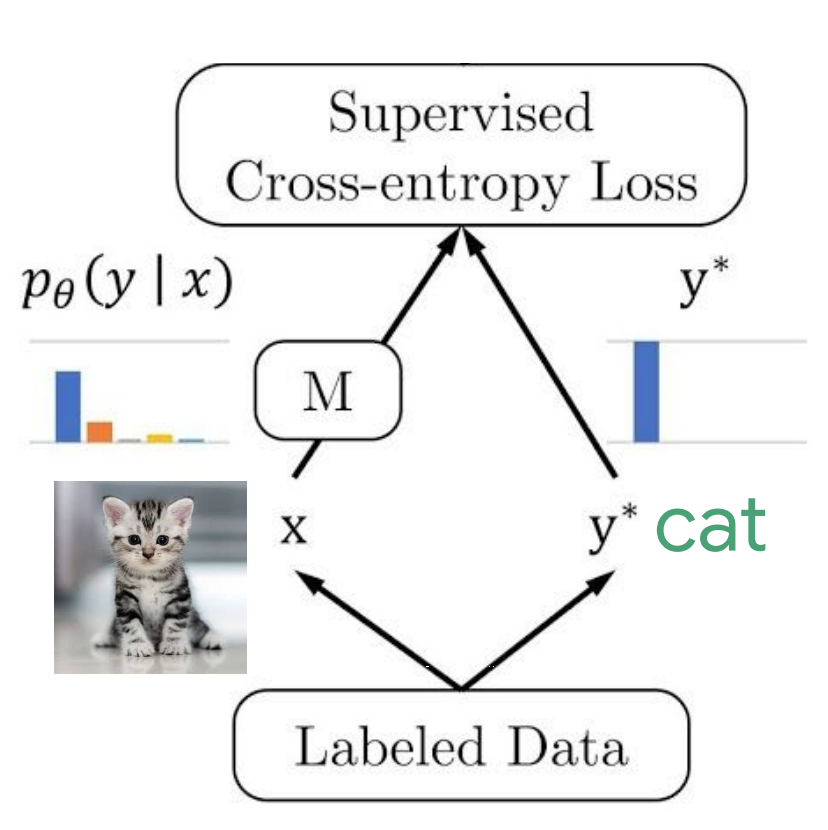
Dataset containing \(N\) examples sampling from true but unknown data generating distribution \(p_{\text {data }}(\mathbf{x})\):
with coressponding ground-truth labels:
Machine learning model is nothing but a map \(f\) from samples to labels:
where \(\mathbb{\Theta}\) is parameters of the model and the outputs are predicted labels:
described by \(p_{\text {model }}(\mathbf{y}|\mathbf{x} ; \boldsymbol{\Theta})\), a parametric family of probability distributions over the same space indexed by \(\Theta\).
引力波信号搜寻
# GWDA: DL
Dataset containing \(N\) examples sampling from true but unknown data generating distribution \(p_{\text {data }}(\mathbf{x})\):
with coressponding ground-truth labels:
Machine learning model is nothing but a map \(f\) from samples to labels:
where \(\mathbb{\Theta}\) is parameters of the model and the outputs are predicted labels:
described by \(p_{\text {model }}(\mathbf{y}|\mathbf{x} ; \boldsymbol{\Theta})\), a parametric family of probability distributions over the same space indexed by \(\Theta\).
Objective:
引力波信号搜寻
# GWDA: DL
Objective:
to construct cost function \(J(\Theta)\) (also called loss func. or error func.)
For classification problem, we always use maximum likelihood estimator for \(\Theta\)
引力波信号搜寻
# GWDA: DL
Objective:
在信息论中,可以通过某概率分布函数 \(p(x),x\in X\) 作为变量,定义一个关于 \(p(x)\) 的单调函数 \(h(x)\),称其为概率分布 \(p(x)\) 的信息量(measure of information): \(h(x) \equiv -\log p(x)\)
定义所有信息量的期望为随机变量 \(x\) 的 熵 (entropy):
若同一个随机变量 \(x\) 有两个独立的概率分布 \(p(x)\) 和 \(q(x)\),则可以定义这两个分布的相对熵 (relative entropy),也常称为 KL 散度 (Kullback-Leibler divergence),来衡量两个分布之间的差异:
可见 KL 越小,表示 \(p(x)\) 和 \(q(x)\) 两个分布越接近。上式中,我们已经定义了交叉熵 (cross entropy) 为
引力波信号搜寻
# GWDA: DL
Objective:
当对应到机器学习中最大似然估计方法时,训练集上的经验分布 \(\hat{p}_ \text{data}\) 和模型分布之间的差异程度可以用 KL 散度度量为:
由上式可知,等号右边第一项仅涉及数据的生成过程,和机器学习模型无关。这意味着当我们训练机器学习模型最小化 KL 散度时,我们只需要等价优化地最小化等号右边的第二项,即有
Recall:
由此可知,对于任何一个由负对数似然组成的代价函数都是定义在训练集上的经验分布和定义在模型上的概率分布之间的交叉熵。
引力波信号搜寻
# GWDA: DL
训练的过程(Train):
1
0
H1
L1
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]引力波信号搜寻
# GWDA: DL
训练的过程(Train):
1
0
H1
L1
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]引力波信号搜寻
# GWDA: DL
基于分类问题的网络模型里,我们都是用 softmax 函数作为模型最终输出数据时的非线性计算单元,其函数形式为:
1
0
Labels
1
1
0
0
[6,2]由于该函数的输出元素都介于 0 和 1 之间,且向量之和为 1,这使得其可以作为一个有效的“概率分布” \(p_\text{model}(y=k|\mathbf{x}^{(i)})\)。
由此,我们使用最大化条件对数似然输出某样本的目标分类 \(y\) 时,即等价于对下式最大化,
上式中的第一项表示模型的直接输出结果 \(\hat{y}_k\),对优化目标有着直接的贡献。在最大化对数似然时,当然是第一项越大越好,而第二项是鼓励越小越好。根据 \(\log\sum^N_j\exp(\hat{y}_ j)\sim\max_j\hat{y}_ j\) 近似关系,可以发现负对数似然代价函数总是强烈的想要惩罚最活跃的不正确预测。如果某样本的正确 label 对应了 softmax 的最大输入,那么 \(-{y}_k\) 项和 \(\log \sum_j^N \exp \left({y}_j\right)\sim\max_jy_j=y_j\) 项将大致抵消。
引力波信号搜寻
# GWDA: DL
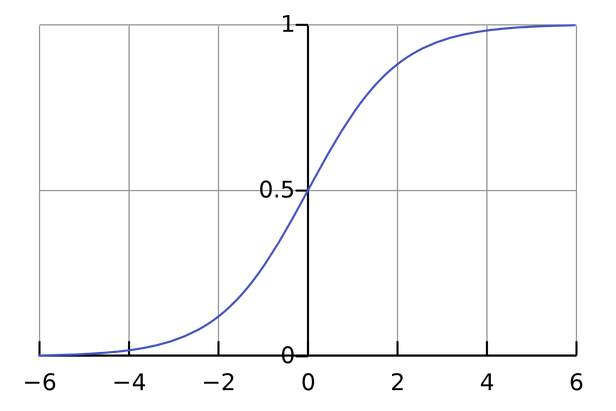
对于二值型的分类学习任务,softmax 函数会退化到 sigmoid 函数:
1
0
Labels
1
1
0
0
[6,2]由此可以证明,cost funcion 可以表示为
引力波信号搜寻
# GWDA: DL
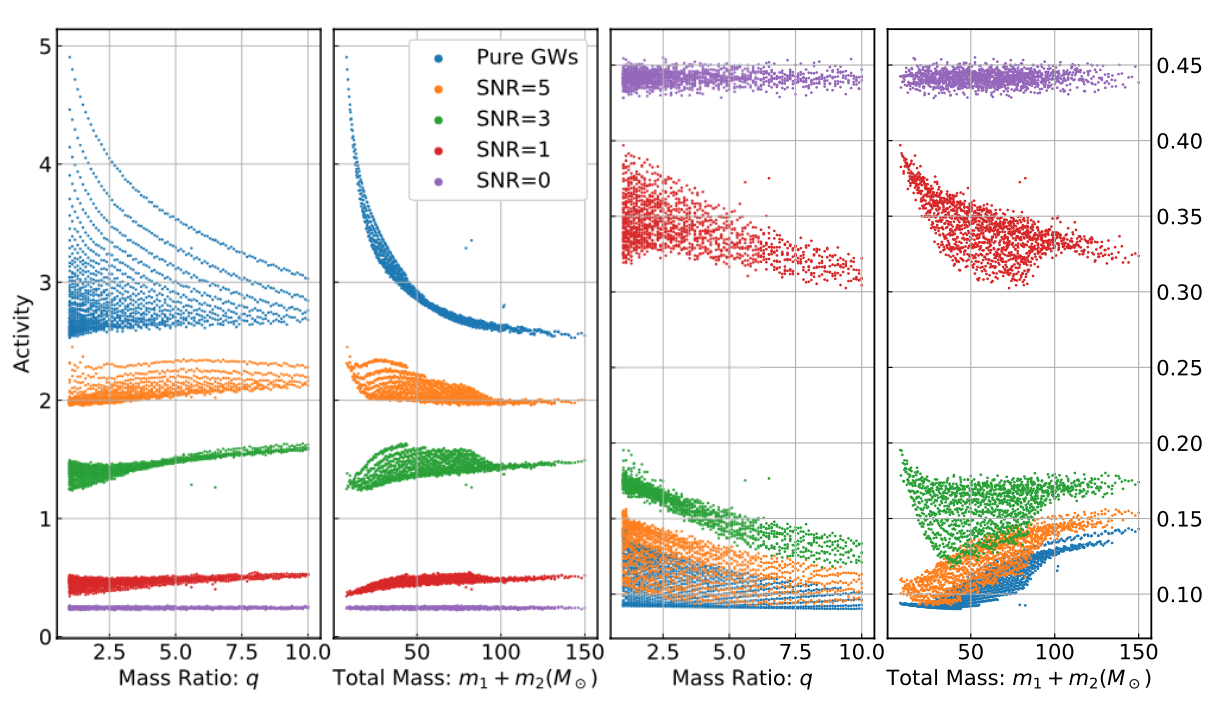
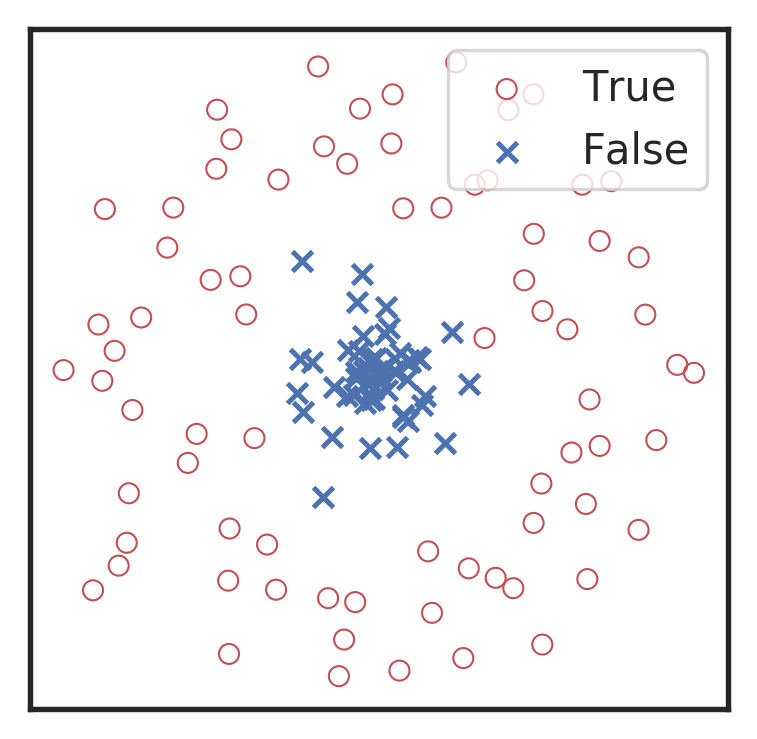
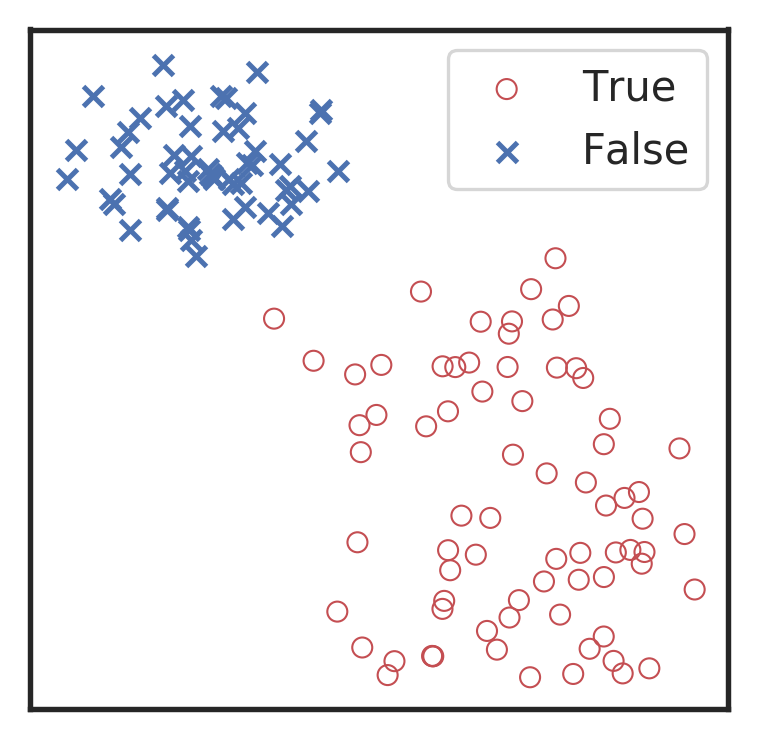
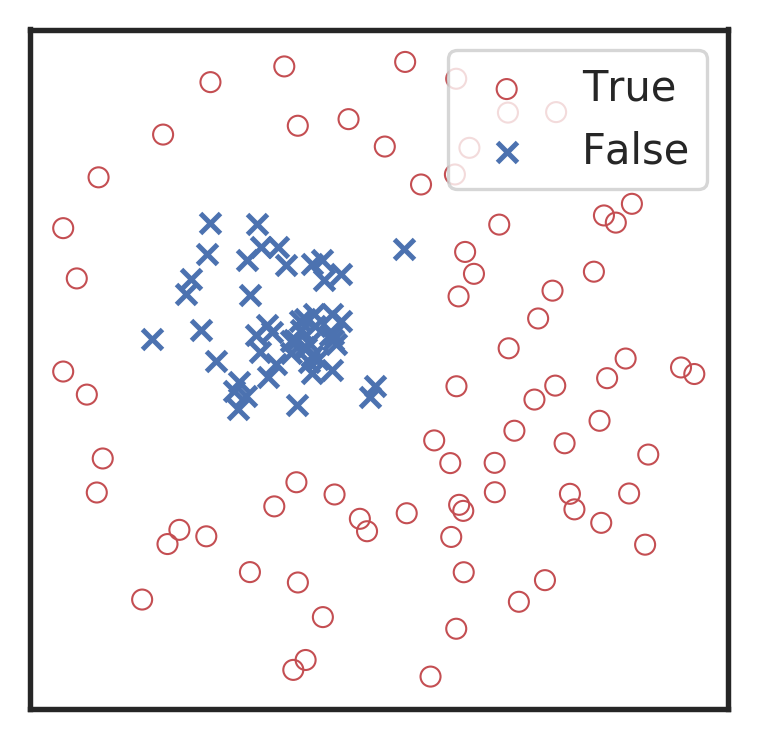
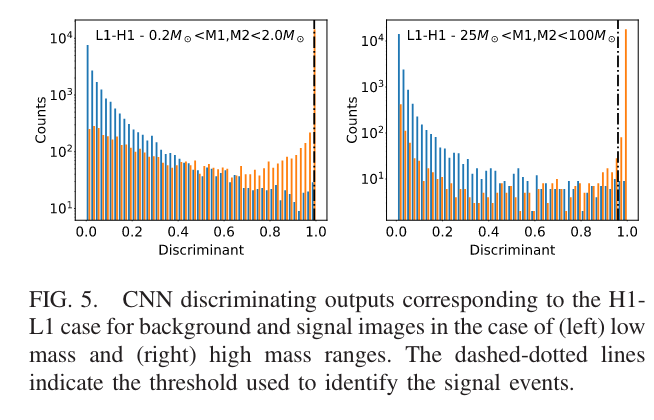
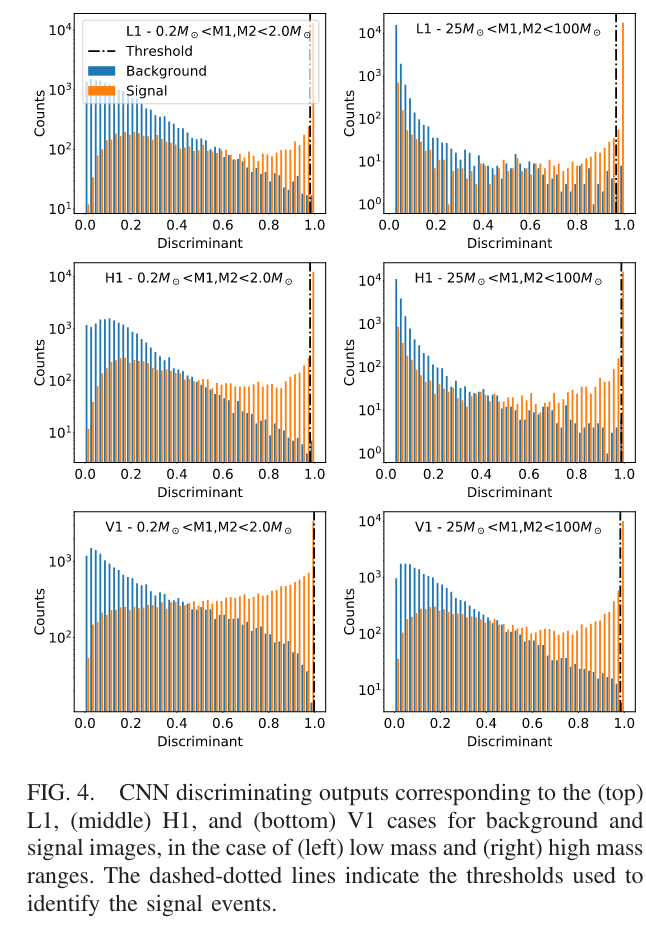
Menéndez-Vázquez A, et al.PRD 2021
arXiv: 2307.09268
引力波信号搜寻
# GWDA: DL
训练的过程(Train):
1
0
H1
L1
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]引力波信号搜寻
# GWDA: DL
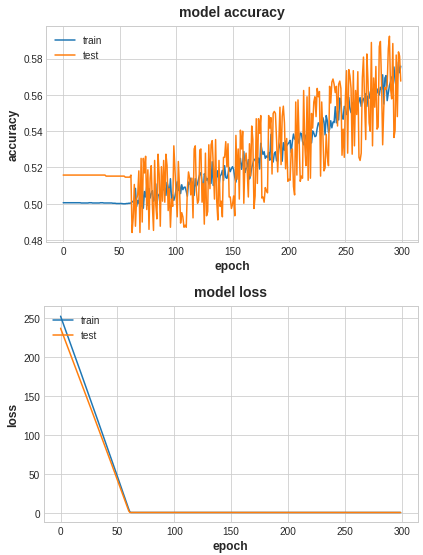
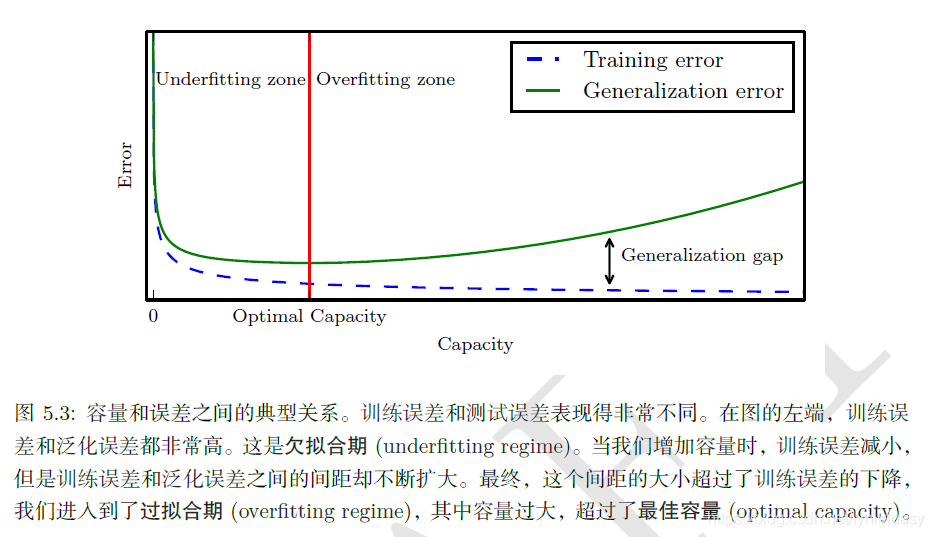
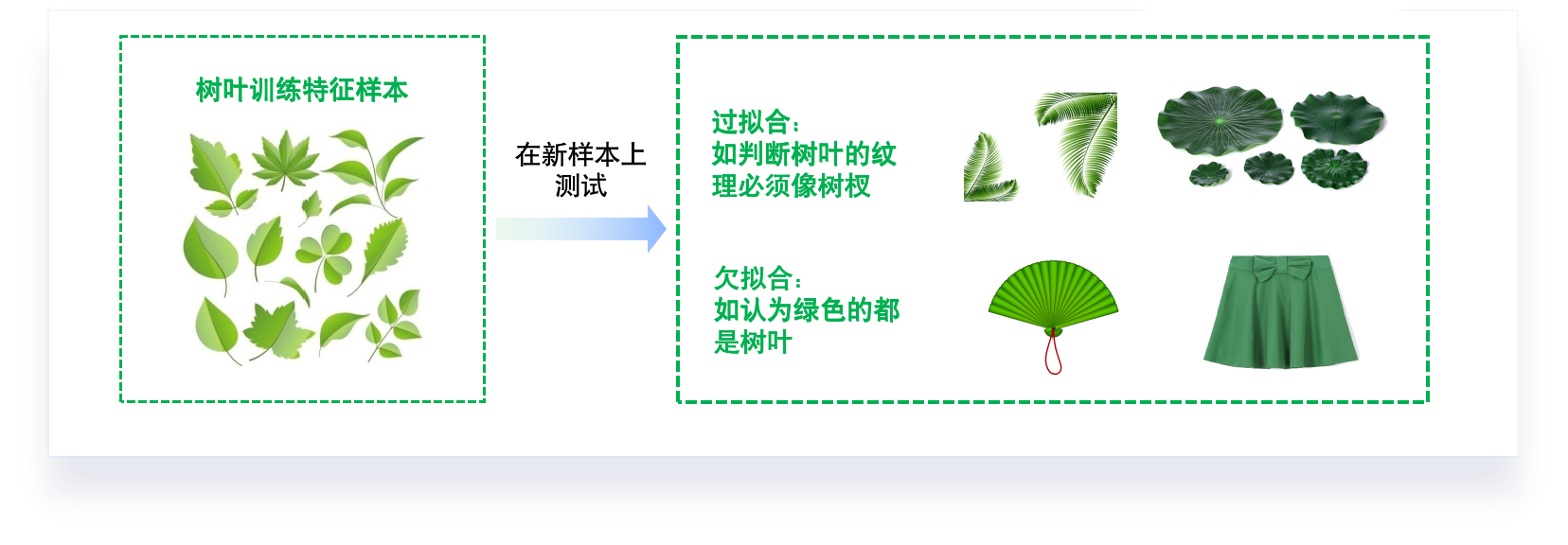
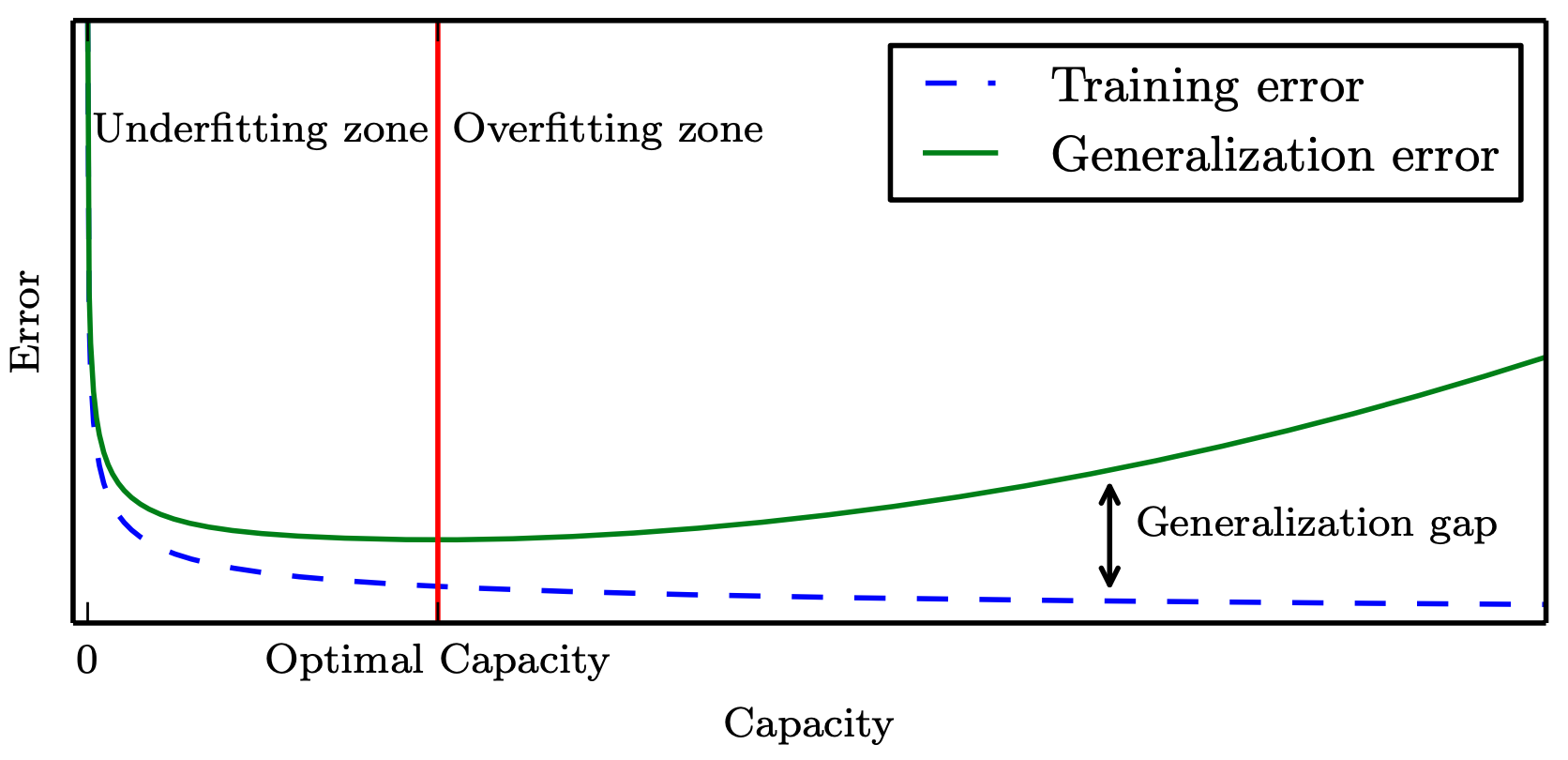
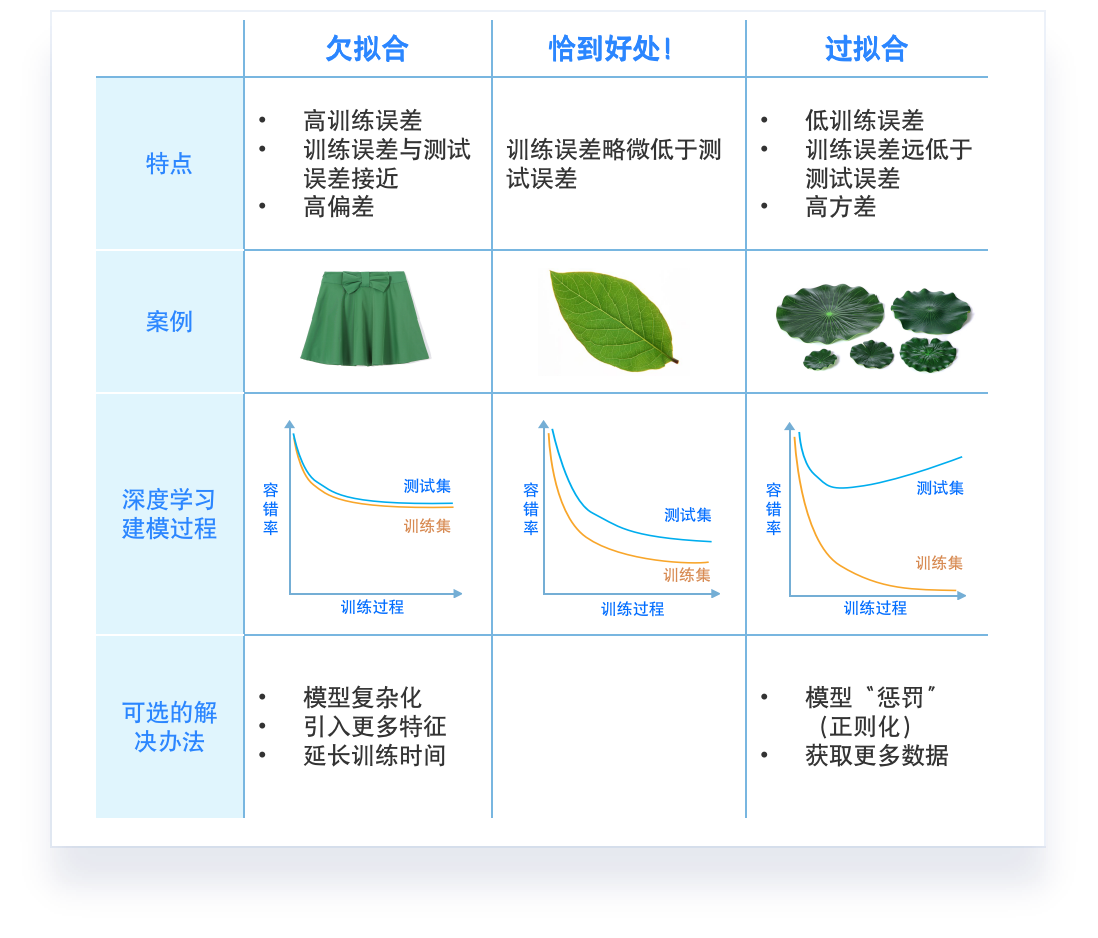
“最合适”的模型:机器学习从有限的观测数据中学习出规律 [训练误差 (training error)],
并将总结的规律推广应用到未观测样本上 \(\rightarrow\) 追求泛化性能 [泛化误差 (generalization error)]。
所以,我们认定机器学习算法效果是否很好,两个学习目标:
降低训练误差。
缩小训练误差和测试误差的差距。
这两个目标分别对应了机器学习的两个重要挑战:
欠拟合 (underfitting):模型不能在训练集上获得足够低的误差。
过拟合 (overfitting):训练误差与测试误差之间的差距过大。
引力波信号搜寻
# GWDA: DL
“最合适”的模型:机器学习从有限的观测数据中学习出规律 [训练误差 (training error)],
并将总结的规律推广应用到未观测样本上 \(\rightarrow\) 追求泛化性能 [泛化误差 (generalization error)]。
所以,我们认定机器学习算法效果是否很好,两个学习目标:
降低训练误差。
缩小训练误差和测试误差的差距。
这两个目标分别对应了机器学习的两个重要挑战:
欠拟合 (underfitting):模型不能在训练集上获得足够低的误差。
过拟合 (overfitting):训练误差与测试误差之间的差距过大。
泛化性能 是由
学习算法的能力、
数据的充分性以及
学习任务本身的难度共同决定。
模型的容量 Capacity 是指其拟合各种函数的能力,一般也可以代表模型的复杂程度。(“计算学习理论”)
奥卡姆剃刀原理:
惩罚大模型复杂度
训练集的一般性质尚未被
学习器学好
学习器把训练集特点当做样本的 一般特点.
偏差-方差窘境(bias-variance dilemma)
引力波信号搜寻
# GWDA: DL
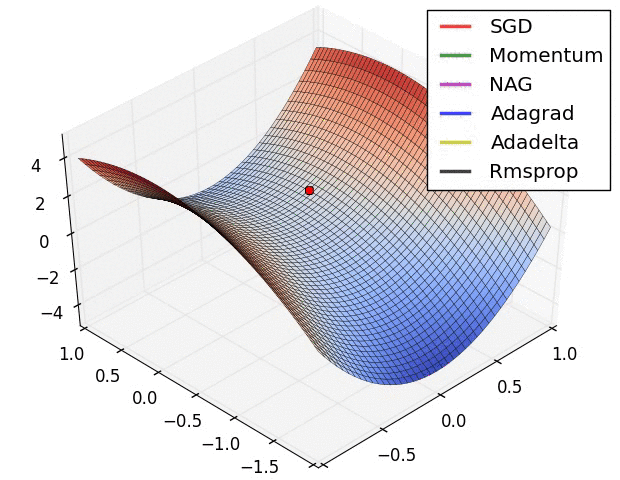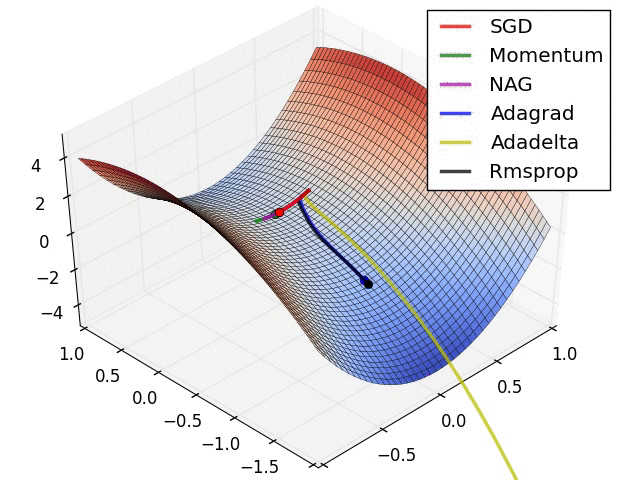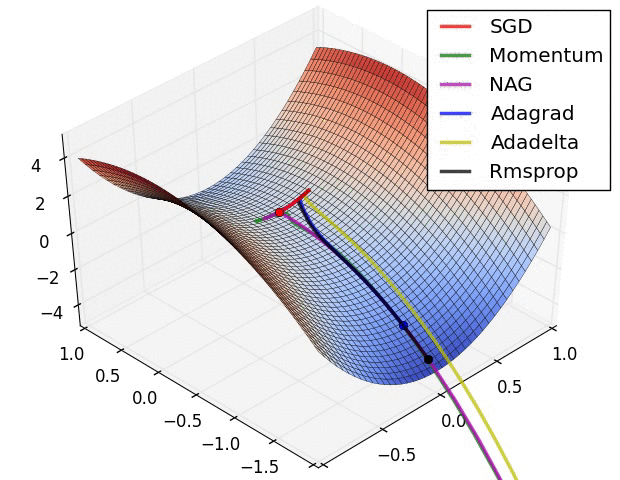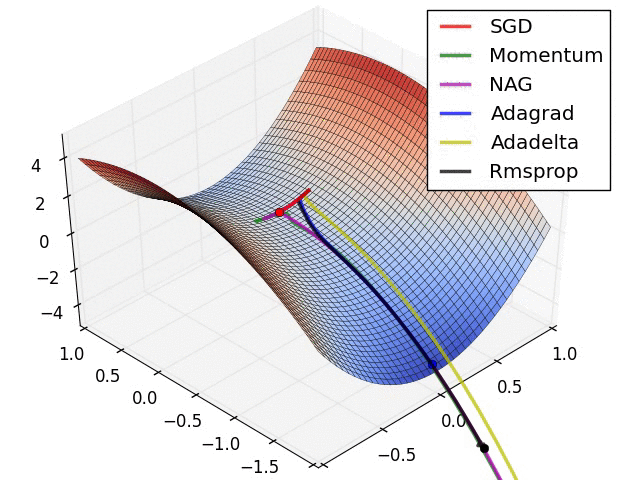
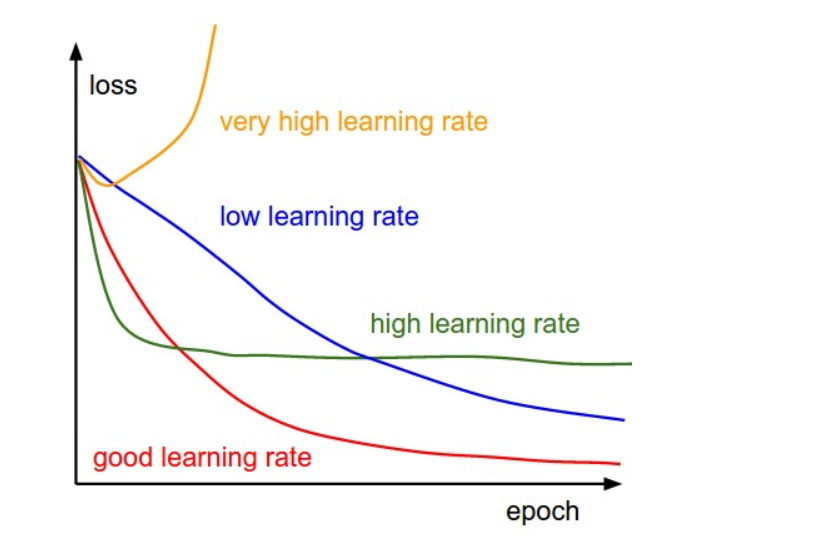
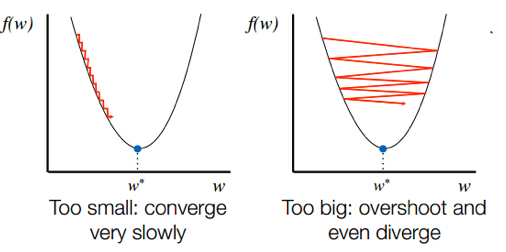
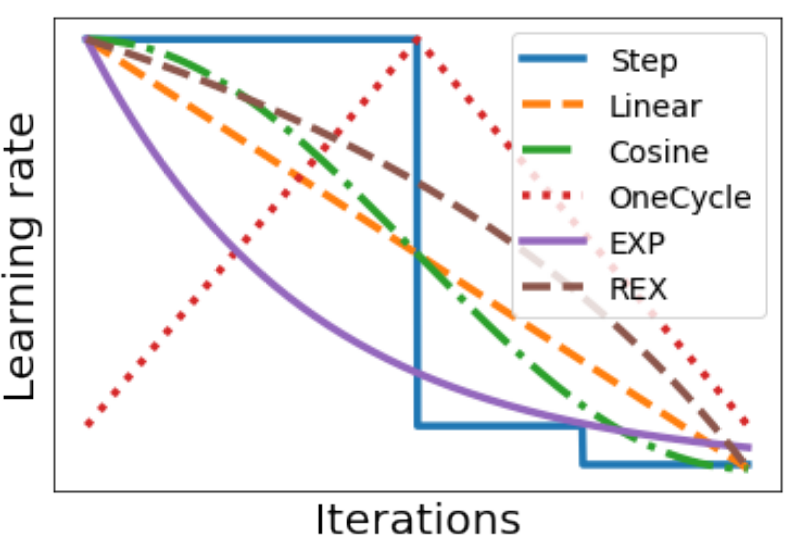
early stop、dropout
参数调得好不好,往往对最终性能有关键影响。
引力波信号搜寻
# GWDA: DL
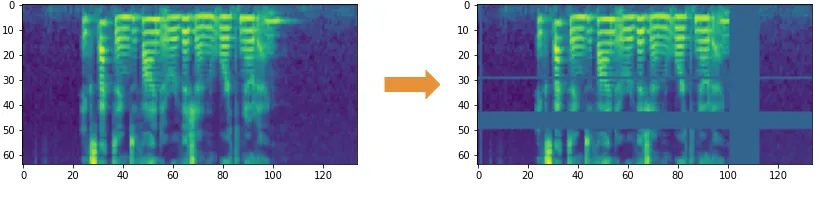
SpecAugment
引力波信号搜寻
# GWDA: DL
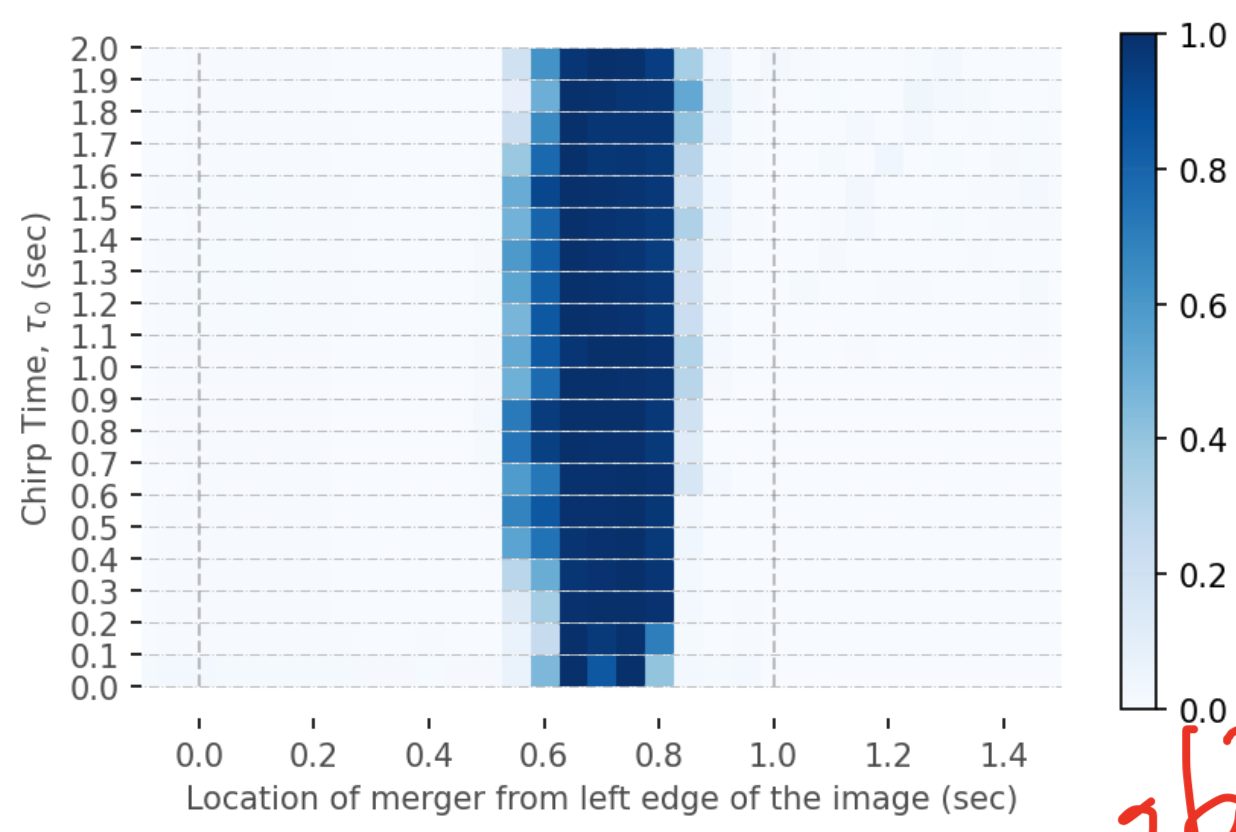
1.
Source: X
PSD
2.
noise instance
...
...
waveform
...
...
Jadhav et al. 2306.11797
merger location
...
...
引力波信号搜寻
# GWDA: DL
期望达到的效果(Evaluation):
H1
L1
CNN
0.99
0.05
引力波信号搜寻
# GWDA: DL
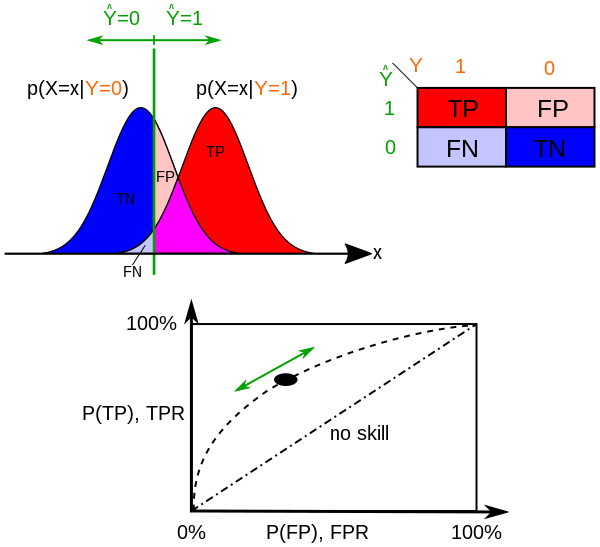
分类模型泛化性能评估:混淆矩阵/ROC/AUC
期望达到的效果(Evaluation):
H1
L1
CNN
0.54
有信号?无信号?
引力波信号搜寻
# GWDA: DL
CNN
0.54
有信号?无信号?
分类模型泛化性能评估:混淆矩阵/ROC/AUC
H1
L1
threshold = 0.5,这里有引力波信号!
threshold = 0.6,这里没有引力波信号!
引力波信号搜寻
# GWDA: DL
CNN
0.54
有信号?无信号?
分类模型泛化性能评估:混淆矩阵/ROC/AUC
H1
L1
threshold = 0.5,这里有引力波信号!
threshold = 0.6,这里没有引力波信号!
引力波信号搜寻
# GWDA: DL
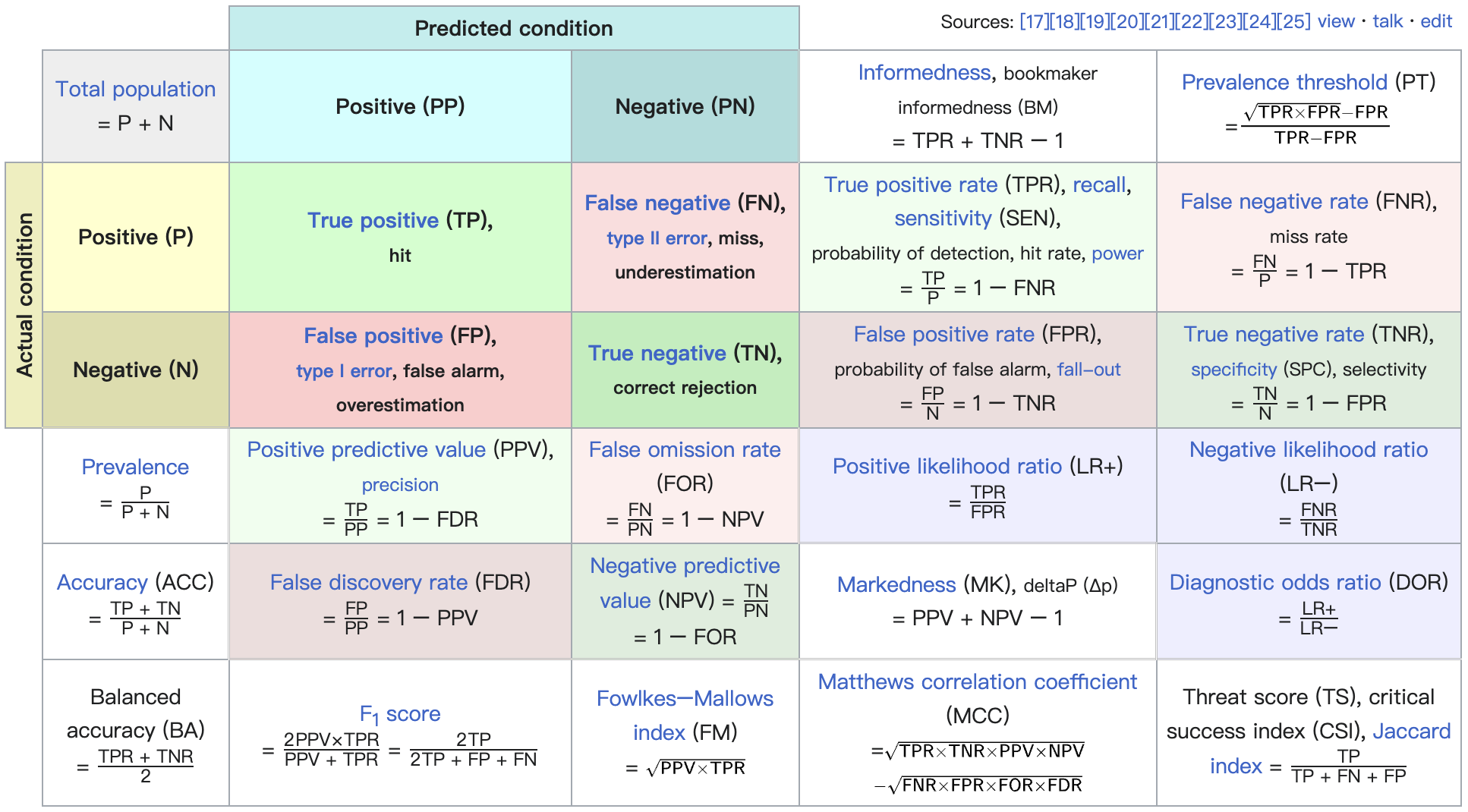
| 真实情况 | 正例(预测结果) | 反例(预测结果) |
|---|---|---|
| 正例 | TP (真正例) | FN (假反例) |
| 反例 | FP (假正例) | TN (真反例) |
arXiv: 2302.00666
引力波信号搜寻
# GWDA: DL
| 真实情况 | 正例(预测结果) | 反例(预测结果) |
|---|---|---|
| 正例 | TP (真正例) | FN (假反例) |
| 反例 | FP (假正例) | TN (真反例) |
arXiv: 2302.00666
Source: Wiki-en
引力波信号搜寻
# GWDA: DL
Source: Wiki-en
引力波信号搜寻
# GWDA: DL
Source: Wiki-en
引力波信号搜寻
# GWDA: DL
Source: Wiki-en
# GWDA: DL
很多其实很重要但没能讲到的内容:
Can you find the GW signals?
# Hackathon
数据科学挑战:引力波信号搜寻
# GWDA: DL
By He Wang
He Wang. (2023). Can you find the GW signals?. Kaggle. https://kaggle.com/competitions/can-you-find-the-gw-signalshttps://kaggle.com/competitions/can-you-find-the-gw-signals (引力波暑期学校 Summer School on Gravitational Waves) [Repo: https://github.com/iphysresearch/2023gwml4tianqinhttps://github.com/iphysresearch/2023gwml4tianqin




