Porting a legacy Multimedia Server from Erlang to Python
What is a media server
- Serving and storing Media & Derivatives
- Metadata Tasks:
- Extraction of XMP, IPTC, EXIF
- A whole lot of obsolete standards
- Analysis Tasks
- Guessing
- Text Extraction / OCR
- Conversion Tasks
- Zoomable FPX / Tiling
- Conversion between formats
- Generating Thumbnails and Derivatives
What is a media server (Cont)
- Viewer related tasks
- Custom Video Players
- FPX Viewers
- Cubic Viewers (Some browsers are dropping support for QTVR)
The Media
# Image formats
'png': ('img', ['png']),
'tif': ('img', ['tif', 'tiff']),
'jpg': ('img', ['jpg', 'jpeg']),
'psd': ('img', ['psd', 'psb']),
'jp2': ('img', ['jp2', 'j2k', 'j2c', ...]),
# Camera RAW formats
'crw': ('img', ['crw']),
'dng': ('img', ['dng']),
'cr2': ('img', ['cr2']),
'zvi': ('img', ['zvi']),
# Document formats
'pdf': ('doc', ['pdf', 'ai']),
'doc': ('doc', ['doc']),
'docx': ('doc', ['docx']),
'xls': ('doc', ['xls']),
'xlsx': ('doc', ['xlsx']),
'ppt': ('doc', ['ppt']),
'pptx': ('doc', ['pptx']),
# Video formats
'avi': ('vid', ['avi']),
'swf': ('vid', ['swf']),
'flv': ('vid', ['flv', 'f4v']),
'wmv': ('vid', ['wmv']),
'mpg': ('vid', ['mpg', 'mpeg']),
'asf': ('vid', ['asf', 'wmv', 'wma']),
'3gp': ('vid', ['3gp']),
'3g2': ('vid', ['3g2']),
'mkv': ('vid', ['mkv']),
'f4v': ('vid', ['f4v']),
'webm': ('vid', ['webm']
# Audio formats
'mp3': ('aud', ['mp3']),
'flac': ('aud', ['flac']),
'aif': ('aud', ['aif']),
'wma': ('aud', ['wma']),
The Client
Non profit operating in Cataloging & Media Management Systems for the Artwork industry with more than 1500 institutional partners.{Museums, Colleges, Universities, Libraries, etc }
The Legacy System
- Originally written by an academic
- Erlang is also the reason I joined the Company
- Infant product. Did not get a lot of load
- Aspired to be a mature product
- Replicated assets(included physical files) across data centers
- The logic was written by hand
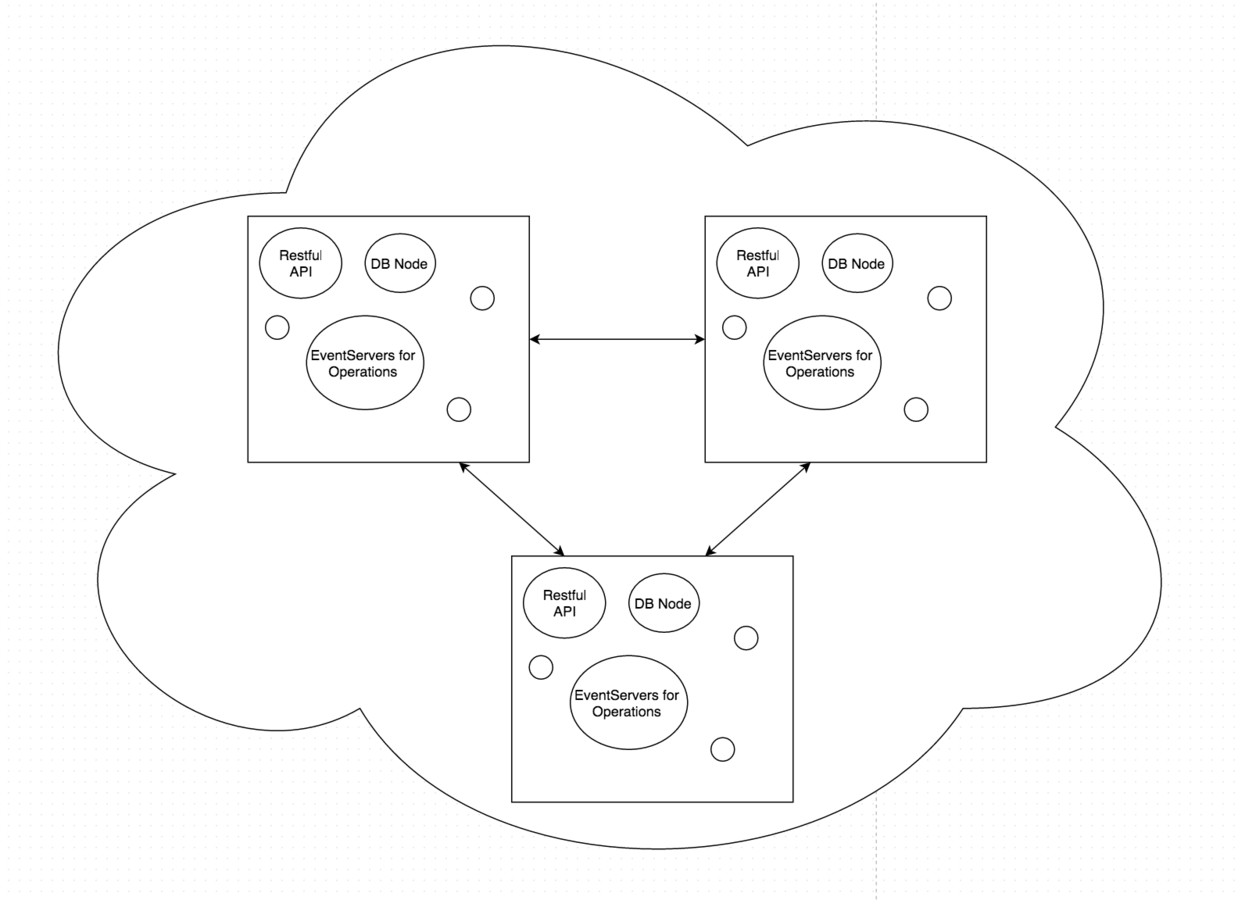
Erlang Runtime spanning across machines and across data centers
Erlang Facilities

Message Passing is at the core of the system

The code itself stays the same on a cluster
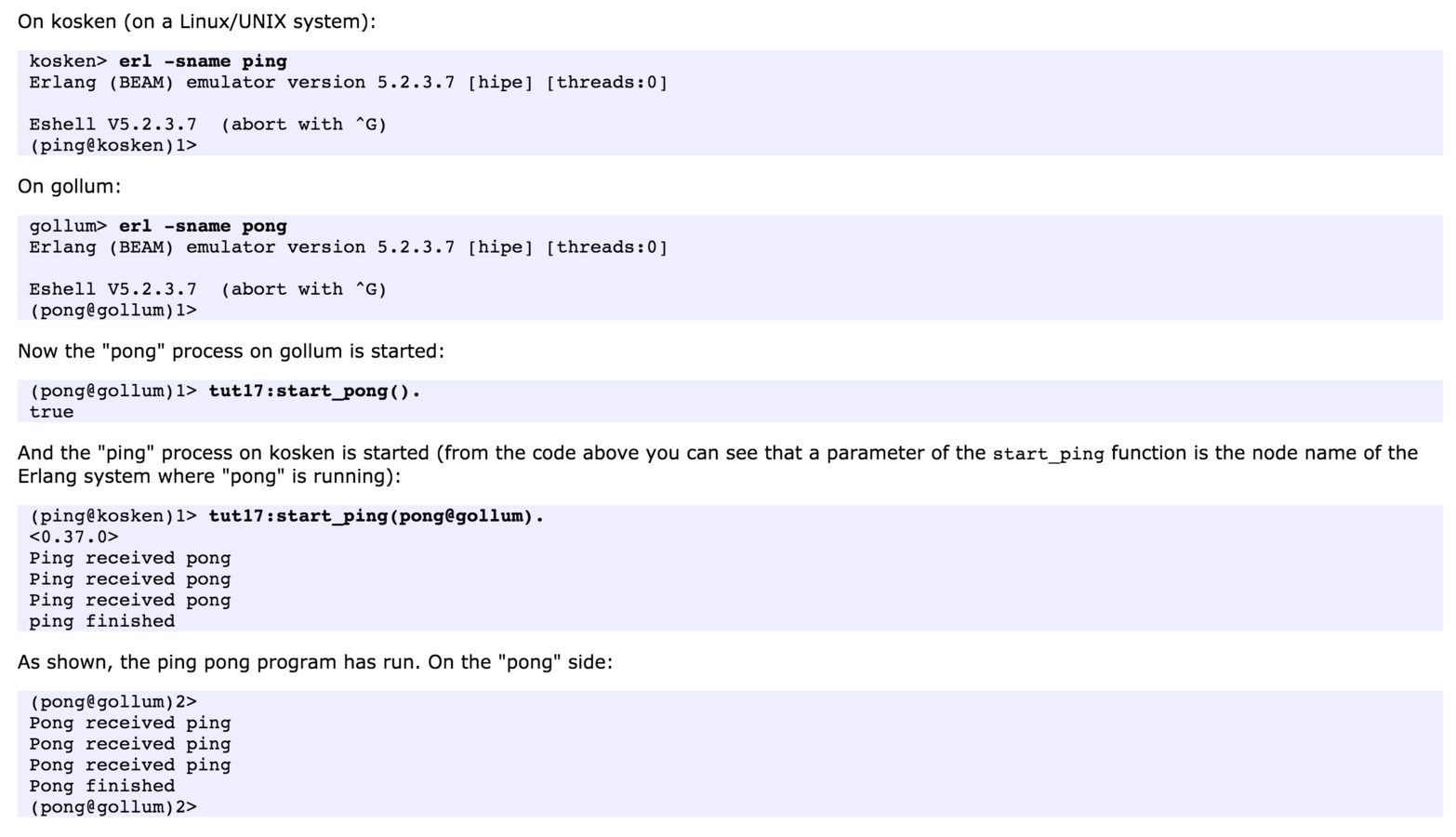
Thats the output
We observe that the time taken to create an Erlang process is constant 1µs up to 2,500 processes; thereafter it increases to about 3µs for up to 30,000 processes. The performance of Java and C# is shown at the top of the figure. For a small number of processes it takes about 300µs to create a process. Creating more than two thousand processes is impossible.
We see that for up to 30,000 processes the time to send a message between two Erlang processes is about 0.8µs. For C# it takes about 50µs per message, up to the maximum number of processes (which was about 1800 processes). Java was even worse, for up to 100 process it took about 50µs per message thereafter it increased rapidly to 10ms per message when there were about 1000 Java processes.
And more
- Hot code loading
- Immutability for better code
- Used by the telecom industry / Ericsson to ensure nine nines (99.9999999 % uptime)
So
- Erlang makes writing distributed code easier
But
- Distributed code writing is not easy to begin with
- Repos are very difficult
- And we are writing a framework where we should be writing media processing systems.
What frustrations looked like
- Map reduce syntax assumed the machine was infinite
- No native database library that could talk to postgres. Hackish nature relying on alpha python libraries
- qtvr_nailer and exif_thumbnailer
A lot of the code written assumed the machine was infinite
And there was a lot of code
Pids = lists:map(fun(El) ->
spawn(fun() -> execute(S, Function, El) end)
end,
List),
gather(Pids).
No Native DB Library Implementation
- Python Processes had to be managed externally that could connect to the Erlang Runtime
- These were built using an Alpha Python
- So there was external orchestration needed to ensure uptime in case of failure
- Perl scripts were also integrated in a similar fashion for some metadata operations
IO related tooling Was not the best for the Web
- We had to support websockets by writing them from scratch
- The same went for handling cors, customizing request parsers, etc
- Made adding new functionality very difficult
Uncoupling the system
- Centralized Databases:
- Postgres with PGPOOL
- Centralized File systems:
- Fork1: ZFS Storage
- Fork2: MogileFS

We had a basic Scalable System
- No mechanisms to control incoming load
- No such thing as deferred or asynchronous operations
- Still towards the monolithic Side
- Still difficult to develop code for: No batteries included, and not a very big community for this kind of stuff.
- Difficulty on-boarding more talent
One has to ...
- Maintain the legacy Erlang System
- Get Frustrated enough with the System
- While adding new features(in 2 forks)
- Port the System

We want more features I dont care about system stability at this point
- Overtime project
- Secret team
Najam Ahmed
https://pk.linkedin.com/in/nansari89
Hashim Muqtadir
https://github.com/hashimmm
Architectural Requirements
- Rolling Restarts
- Ability to add throughput with zero down
- Redundancy
- Separation of Concern
- Monitoring
- Centralised Logging & Analytics
- Maintenance Operations
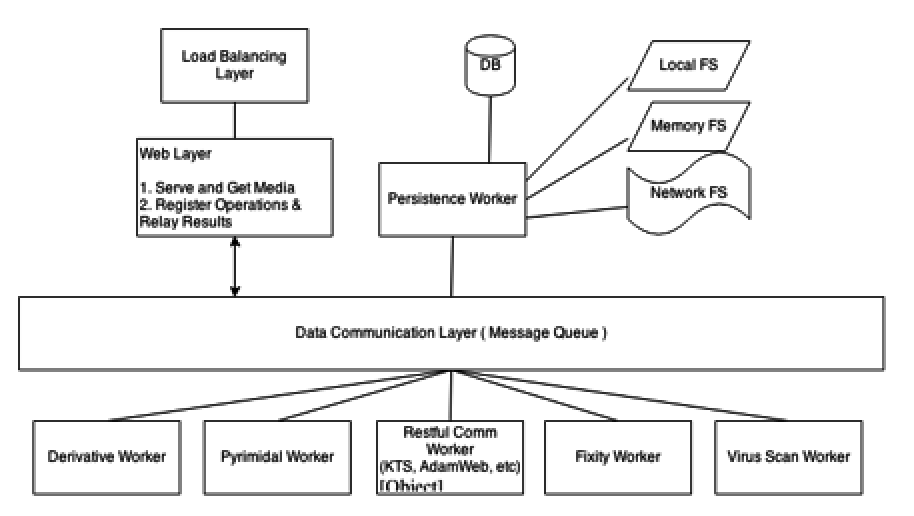
2 weeks of Reserch later
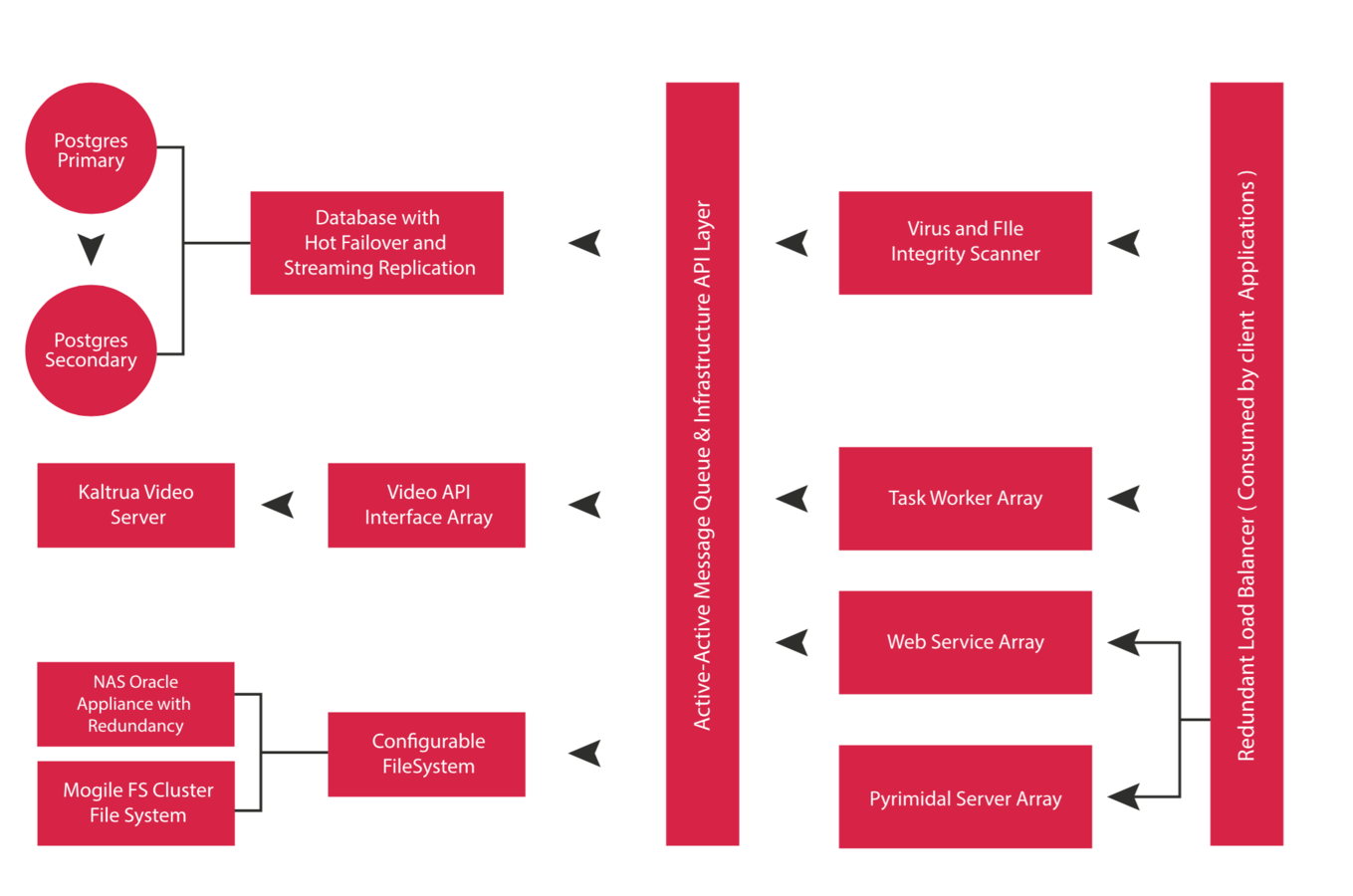
Nginx / LB & Front End
- Load Balancing Layer
- Front End Server
- File IO In handled by nginx server
- And also more advanced stuff like checksum computation through plugins
- File IO also handled by nginx server directives issued by the back end web servers
Flask / Gunicorn - Web Back end
def register_blueprints(app):
app.register_blueprint(dastor_web, url_prefix='')
app.register_blueprint(dastor_task_api, url_prefix='/tasks')
app.register_blueprint(iiif.dastor_iiif, url_prefix='')
app.register_blueprint(editor, url_prefix='')
Organized using blue prints
@dastor_web.route('/stor/', methods=['POST'])
@dastor_web.route('/stor', methods=['POST'])
@decorators.require_token()
def ingest_asset():
"""Defines the POST request for ingesting assets into STOR.
:return: str -- JSON string containing the metadata of the asset
"""
ingest_tag = '/stor'
log(logger, 'info', "Initiating ingest request", tags=[ingest_tag,
'INGEST-START'])
asset_instance = _ingest_asset(ingest_tag)
return serve_metadata(asset_instance.uuid)def _ingest_asset(ingest_tag):
asset_info = _extract_asset_info_from_request(ingest_tag=ingest_tag)
allow_any = request.form.get("ignore_unsupported", '0') or \
request.args.get("ignore_unsupported", '0')
allow_any = distutils.strtobool(allow_any)
asset_instance = asset.create(from_path=asset_info['file_path'],
filename=asset_info['file_name'],
filesize=asset_info['file_size'],
md5=asset_info['file_md5'],
project_id=asset_info['project_id'],
raise_on_unknown=not allow_any)
asset_instance.execute_tasks(transaction_id=g.get('transaction_id', ''))
return asset_instanceAsynchronous Ingestion
def serve_path(path, through_frontend=True, buffering=False,
expiry_time=False, throttling=False, download=False,
download_filename=None, temp=False, original_filename=None,
response = make_response((path, 200, []))
path = path.replace(root, "")
path = path.lstrip("/")
response.headers['X-Accel-Redirect'] = os.path.join(redirect_uri, path)
if not original_filename:
extension = os.path.splitext(path)[-1]
else:
extension = os.path.splitext(original_filename.lower())[-1]
if buffering:
response.headers['X-Accel-Buffering'] = "yes"
if expiry_time:
response.headers['X-Accel-Expires'] = str(expiry_time)
if throttling:
response.headers['X-Accel-Limit-Rate'] = str(throttling)
response.headers["Content-Type"] = quick_mime(extension)
if download:
disposition = "attachment" if not download_filename else\
'attachment; filename="%s"' % download_filename
response.headers["Content-Disposition"] = disposition
if temp:
response.headers['Cache-Control'] = 'no-cache'
response.headers['Pragma'] = 'no-cache'
response.headers["Refresh"] = 30Serving Static Files
def serve_path(path, through_frontend=True, buffering=False,
expiry_time=False, throttling=False, download=False,
download_filename=None, temp=False, original_filename=None,
response = make_response((path, 200, []))
path = path.replace(root, "")
path = path.lstrip("/")
response.headers['X-Accel-Redirect'] = os.path.join(redirect_uri, path)
if not original_filename:
extension = os.path.splitext(path)[-1]
else:
extension = os.path.splitext(original_filename.lower())[-1]
if buffering:
response.headers['X-Accel-Buffering'] = "yes"
if expiry_time:
response.headers['X-Accel-Expires'] = str(expiry_time)
if throttling:
response.headers['X-Accel-Limit-Rate'] = str(throttling)
response.headers["Content-Type"] = quick_mime(extension)
if download:
disposition = "attachment" if not download_filename else\
'attachment; filename="%s"' % download_filename
response.headers["Content-Disposition"] = disposition
if temp:
response.headers['Cache-Control'] = 'no-cache'
response.headers['Pragma'] = 'no-cache'
response.headers["Refresh"] = 30Serving Static Files
Tests: Lettuce
Feature: Asset Ingestion
Scenario: Ingest a simple jpeg Asset
Given we have a sample JPEG from our test asset location called test_jpg_img.jpg
when we ingest it into stor
then we get a valid json response containing a valid uuid
and we get a valid json response containing a valid filesize
and we get a valid json response containing a valid filetype@given(
u'we have a sample JPEG from our test asset location called {image_name}')
def set_asset_in_world(context, image_name):
path = os.path.join(BASEPATH, image_name)
context.inputfile = {"path": path, "size": file_size(path)}Celery / RabbitMQ
class TaskInterface(object):
"""Interface for the Task"""
"""Interface for the Stor's tasks."""
guid = NotImplemented
"""A unique identifier for the task (mainly used for logging)"""
friendly_name = NotImplemented
"""A user-friendly name for the task, to identify it in apis."""
def __init__(self, *args, **kwargs):
"""Initializer method
:param args: the arguments to be passed to the task methods
:param kwargs: the arguments to be passed to the task methods
:return: None
"""
raise NotImplementedError()
def execute(self):
""" The method that actually does stuff.
:return: some value meaningful for the next task (if applicable.)
"""
raise NotImplementedError()class StorCeleryTask(PausableTask):
abstract = True
autoregister = True
serializer = 'json'
def __init__(self):
deferred = settings.get("stor", "deferred_ingestion", boolean=True)
if not deferred:
self.is_paused = lambda: False
@staticmethod
def to_wrap():
"""Override this to return the Stor Task to celery-fy."""
raise NotImplementedError()
def __call__(self, *args, **kwargs):
self.run = self.runner
return super(StorCeleryTask, self).__call__(*args, **kwargs)
def after_return(self, status, retval, task_id, args, kwargs, einfo):
db.Session.remove()(Cont)
def runner(self, transaction_id='', *args, **kwargs):
_to_wrap = self.to_wrap()
log(logger, "debug",
"Inside wrapper object for class: {}".format(_to_wrap))
patcher = patch('stor.logs.LogContext',
CustomLogContext(transaction_id))
patcher.start()
start_time = time.time()
task = _to_wrap(*args, **kwargs)
task_guid = task.guid
try:
log(logger, "debug", "Running tasks for : {}".format(task))
task_return_value = task.execute()
except exception.TaskFailedException as e:
log(logger, 'exception', e.message, tags=[task_guid])
task_return_value = None
time_taken = time.time() - start_time
msg = "Task %s took time %s" % (task_guid, time_taken)
log(logger, 'info', msg, task=task_guid,
time_taken=time_taken, tags=[task_guid])
patcher.stop()
return task_return_value
Load based Scaling
MAX_MEMORY = 1073741824L
MAX_CPU = 90.0
logger = logging.getLogger('stor.smartscaler')
class Smartscaler(Autoscaler):
...
def _maybe_scale(self, req=None):
procs = self.processes
cur = min(self.qty, self.max_concurrency)
cpu_util = psutil.cpu_percent()
available_mem = psutil.virtual_memory()[1]
allow_workers = (cpu_util < MAX_CPU and available_mem > MAX_MEMORY)
if cur > procs and allow_workers:
worker_delta = cur - procs
msg = """Current workers: {cur}, current CPU: {cpu},
current RAM: {ram}. Spawning additional workers"""
log(logger, "INFO", msg.format(cur=cur, cpu=cpu_util,
ram=available_mem),
worker_delta=worker_delta, tags=['WORKER-BEAT'])
self.scale_up(worker_delta)
return True
elif cur < procs and not allow_workers:
worker_delta = (procs - cur) - self.min_concurrency
msg = """Current workers: {cur}, current CPU: {cpu},
current RAM: {ram}. Killing some workers"""
log(logger, "INFO", msg.format(cur=cur, cpu=cpu_util,
ram=available_mem),
worker_delta=-worker_delta, tags=['WORKER-BEAT'])
self.scale_down(worker_delta)
return True├── __init__.py
├── celery.py
├── celery_scheduler.py
├── celerybackends
│ ├── __init__.py
│ └── database
│ ├── __init__.py
│ └── session.py
├── celeryconfig.py
├── corruption_detector.py
├── dastor_web
│ ├── __init__.py
│ ├── decorators.py
│ ├── forms.py
│ ├── templates
│ │ ├── ...
│ ├── tests
│ │ └── features
│ │ ├── ingest_asset.feature
│ │ └── steps
│ │ └── asset_steps.py
│ └── views.py
├── dastor_web_task_api
│ ├── __init__.py
│ ├── task_api_views.py
│ └── templates├── database
│ ├── __init__.py
│ ├── access_rules.py
│ ├── asset.py
│ ├── celery_models.py
│ ├── document_page.py
│ ├── exifdata.py
│ ├── fixityrecord.py
│ ├── scanrecord.py
│ ├── tags.py
│ ├── task_groups.py
│ ├── tokens.py
│ └── user.py
├── exception.py
├── exiftool.py
├── filetype.py
├── logs
│ ├── __init__.py
│ └── contexts.py
├── scanner
│ ├── __init__.py
│ ├── bluprnt.py
│ └── scanutils.py
├── settings.py
├── smartscaler.py
├── stor-test.cfg
├── stor.cfg
├── thumbnail.py
└── util.pyNow we're here
├── controller
│ ├── __init__.py
│ ├── asset
│ │ ├── __init__.py
│ │ ├── asset.py
│ │ ├── assetgroup.py
│ │ ├── audio
│ │ │ ├── __init__.py
│ │ │ └── audio.py
│ │ ├── document
│ │ │ ├── __init__.py
│ │ │ ├── document.py
│ │ │ └── document_office.py
│ │ ├── image
│ │ │ ├── __init__.py
│ │ │ ├── image.py
│ │ │ ├── image_jpeg.py
│ │ │ └── image_tiff.py
│ │ ├── video
│ │ │ ├── __init__.py
│ │ │ └── video.py
│ │ └── virtual
│ │ ├── __init__.py
│ │ └── virtual.py
│ ├── ingestors.py
│ ├── interface
│ │ ├── __init__.py
│ │ ├── externalasset.py
│ │ ├── externalkalturaasset.py
│ │ ├── task.py
│ │ └── thumbnail.py
│ ├── kaltura_asset.py
│ ├── tags.py│ ├── tasks
│ │ ├── __init__.py
│ │ ├── bulk
│ │ │ └── __init__.py
│ │ ├── bulkpyrimidal.py
│ │ ├── extractor.py
│ │ ├── fixity.py
│ │ ├── kaltura.py
│ │ ├── panorama.py
│ │ ├── pyrimidal.py
│ │ ├── reingest.py
│ │ ├── scanner.py
│ │ ├── taskutils.py
│ │ └── thumbnail.py
│ └── thumbnail
│ ├── __init__.py
│ ├── thumbnail.py
│ ├── thumbnail_canonraw.py
│ ├── thumbnail_generic.py
│ ├── thumbnail_imagemagick.py
│ ├── thumbnail_jpeg2000.py
│ ├── thumbnail_office.py
│ ├── thumbnail_pdf.py
│ ├── thumbnail_png.py
│ ├── thumbnail_tiff_multipage.py
│ ├── thumbnail_tiff_ycbcr.py
│ └── thumbnail_vr.pyFrom Here
├── Makefile
├── airmail.erl
├── archive.erl
├── archive.hrl
├── archivist.erl
├── asset.erl
├── asset.erl.erlydb
├── asset.erl.psycop
├── copies.erl
├── copies.erl.erlydb
├── copies.erl.psycop
├── dastor.app
├── dastor.erl
├── dastor.hrl
├── dastor_app.erl
├── dastor_deps.erl
├── dastor_sup.erl
├── dastor_web.E
├── dastor_web.erl
├── util.erl
├── uuid.erl
└── vips.erl├── db_common.erl
├── db_coord.erl
├── errors.erl
├── errors.erl.erlydb
├── errors.erl.psycop
├── exif.erl
├── extern.erl
├── filetype.erl
├── logging.hrl
├── md5sum.erl
├── media.erl
├── mochiweb_mime.erl
├── morph.erl
├── plists.erl
├── procrastinator.erl
├── psql.app
├── pyrimidal.erl
├── qtvr.erl
├── rotating_logger.erl
├── stor.erl
├── thumbnail.erl
And some things we moved to their own projects and opensourced
https://github.com/hashimmm/KTS
But what about traceability
Structured Logfiles threaded through a transaction ID
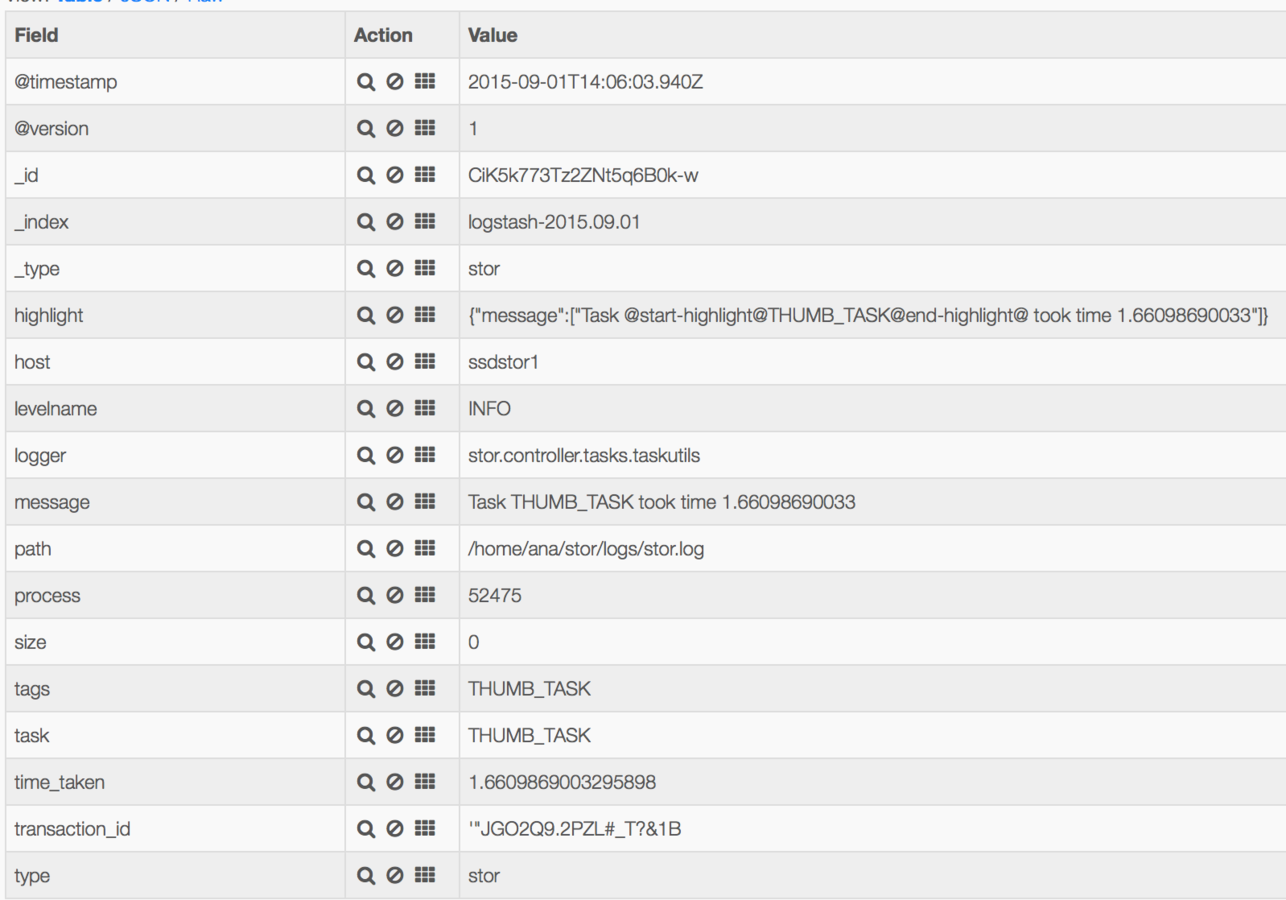
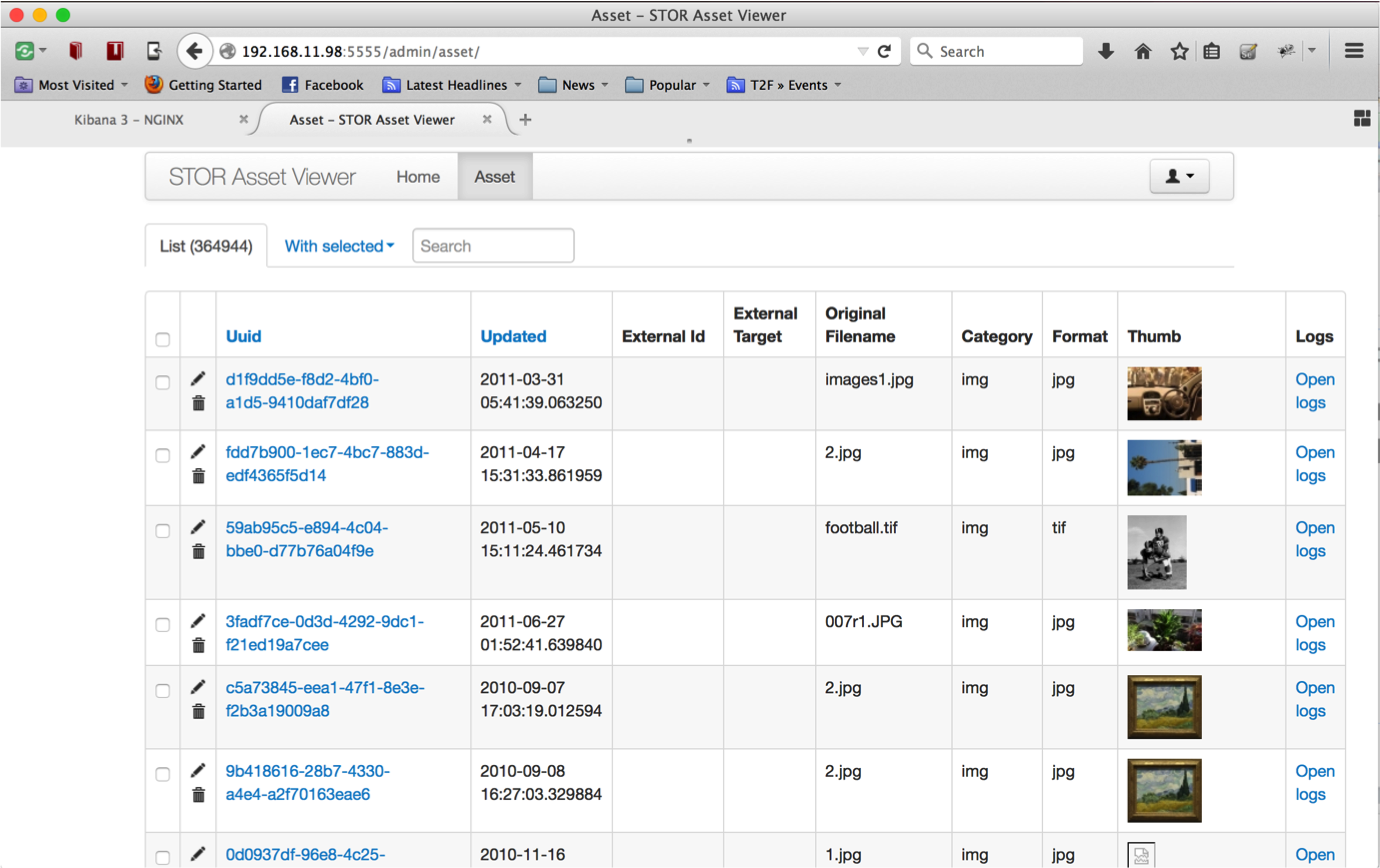
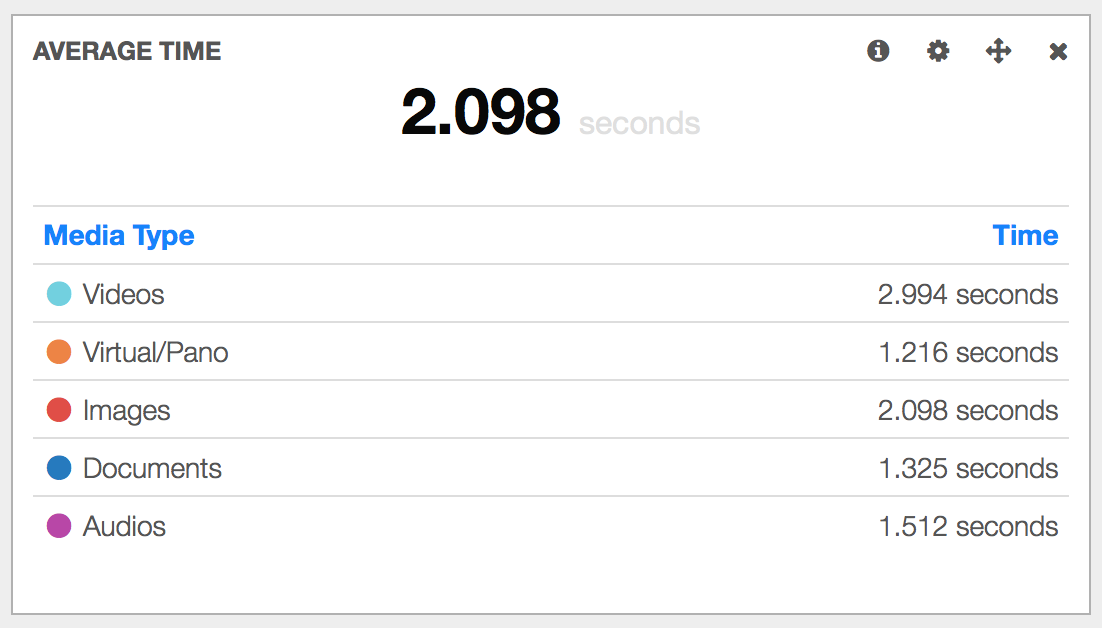
Everything can now be indexed by ELK and we can get the set of operations for any activity in the system
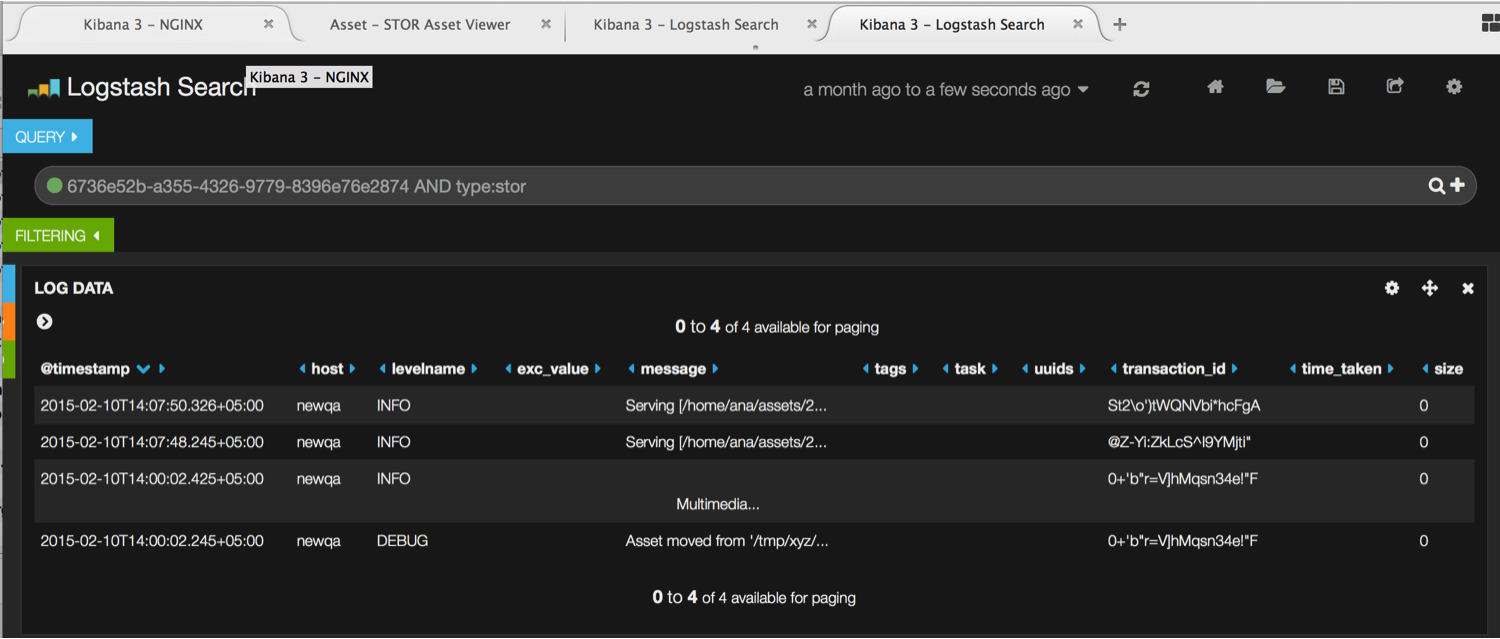
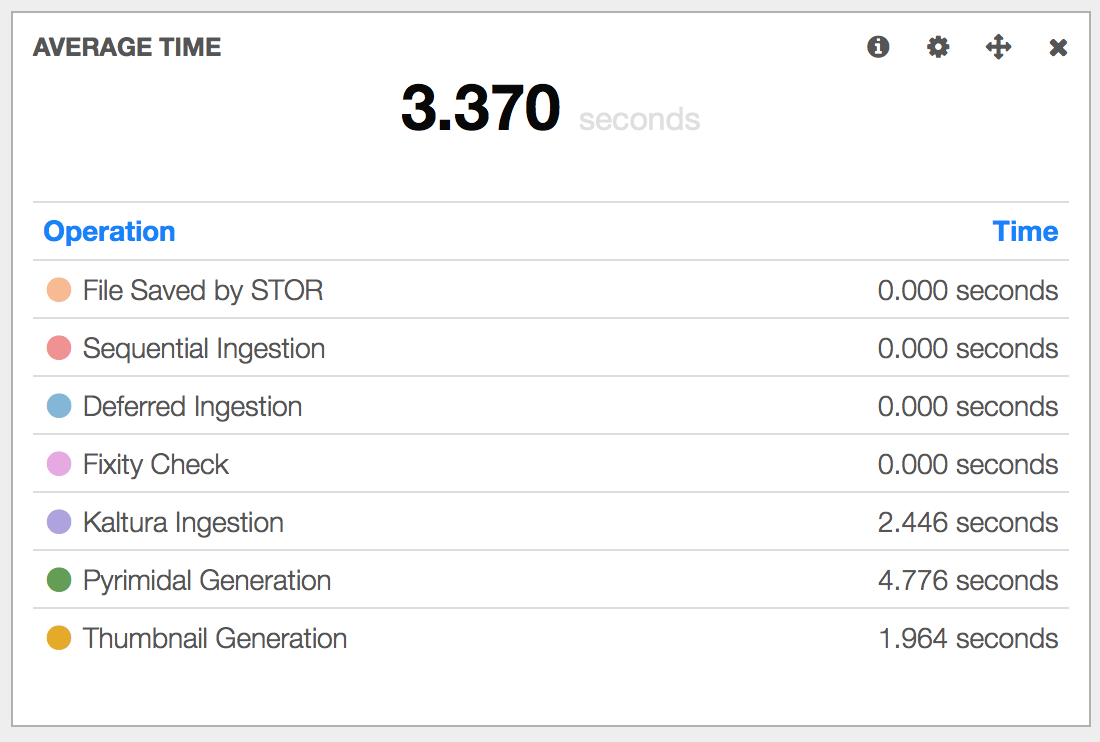
And using the mouse we can make it run aggregations to give us valuable data
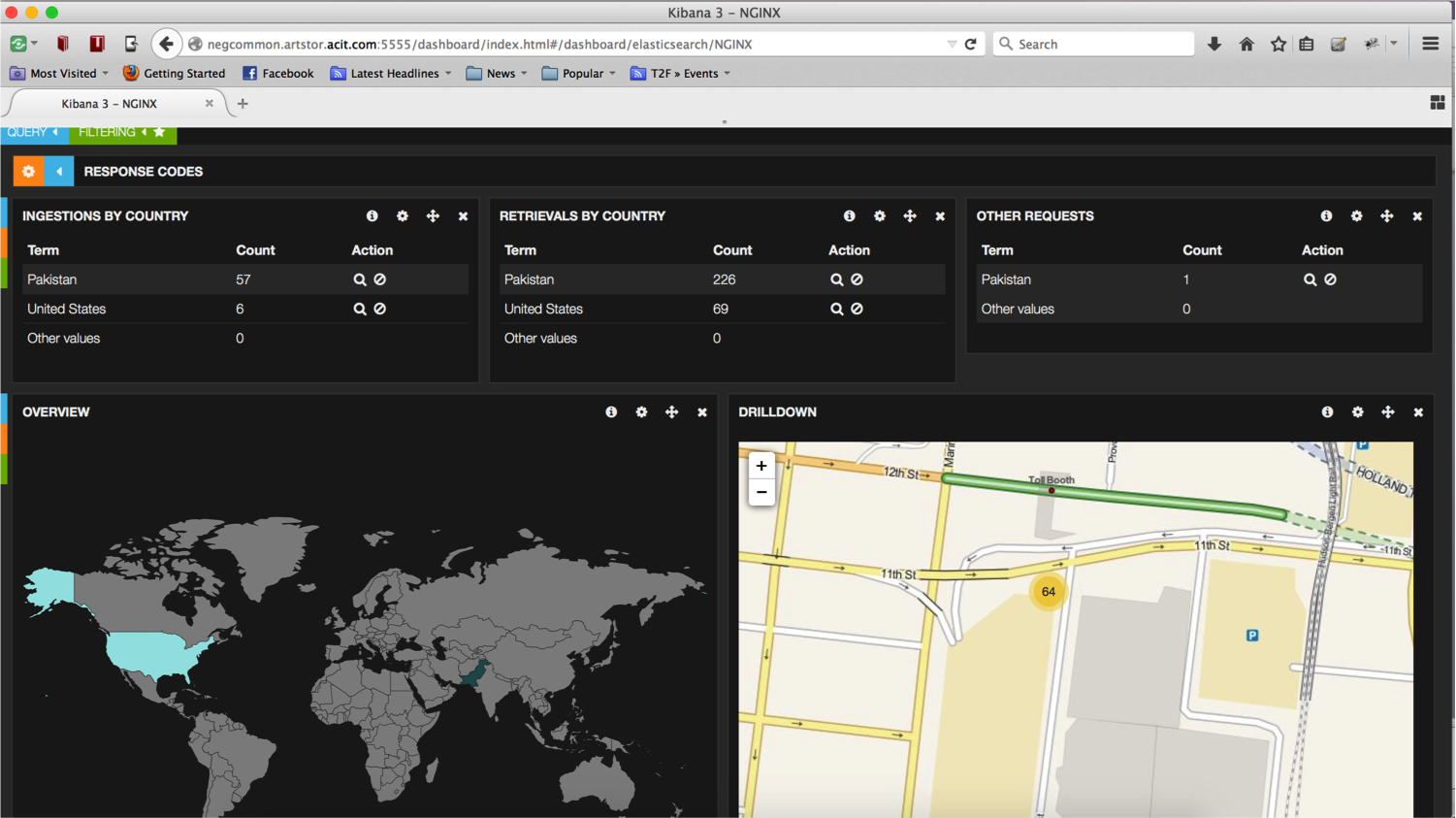
And we know where you are
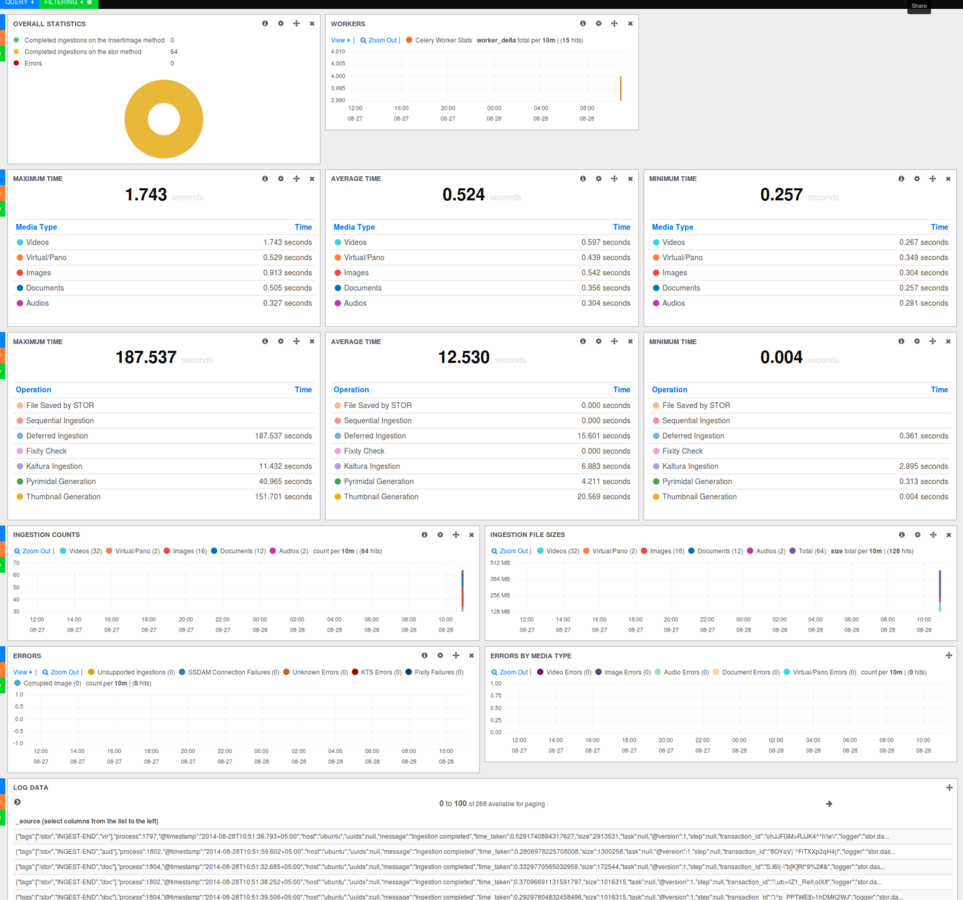
Finally
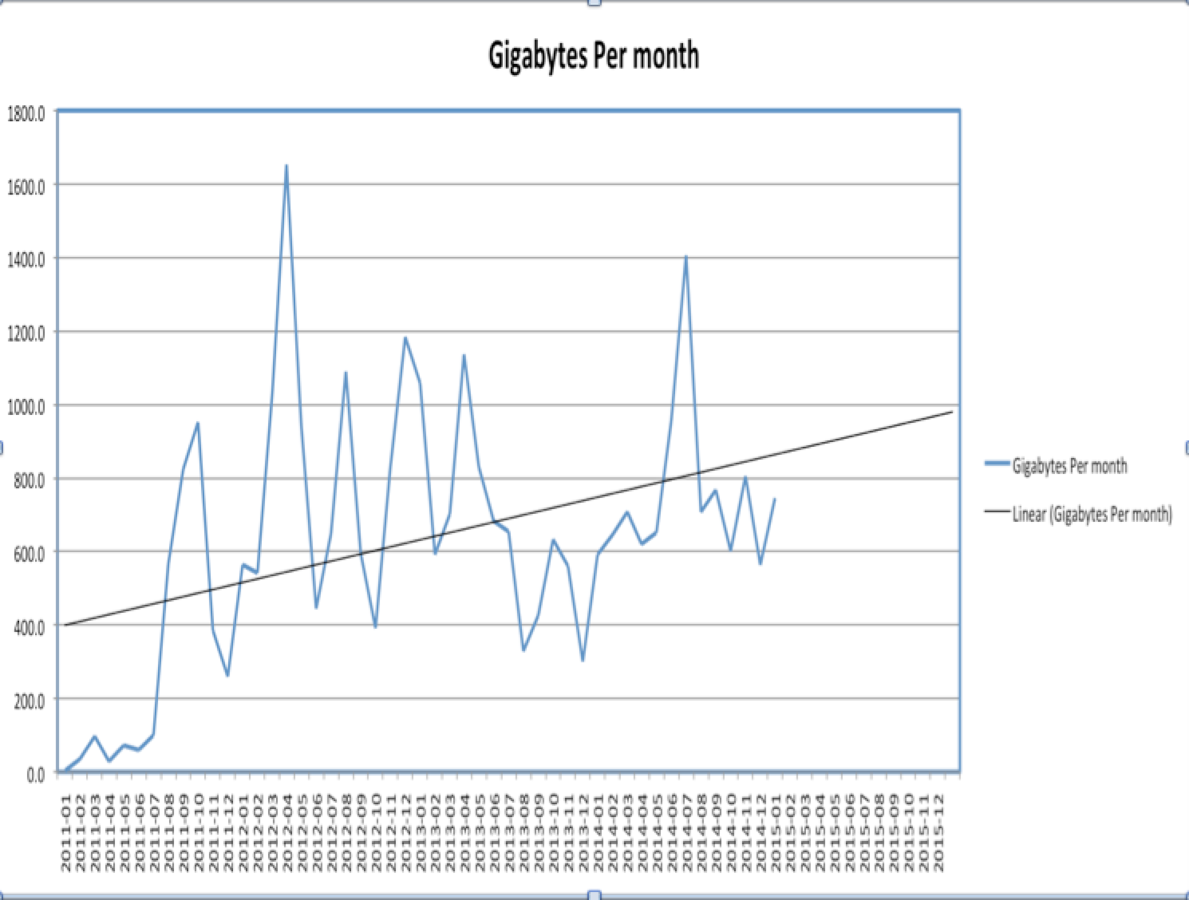
- Been live since Christmas Last year
- We are ingesting media files worth 0.1 TB a day double of what we had initially intended.
- And we've seen bursts of over a Gig a day
- We're 56.35% faster at getting things in.
- We have had around 10 system outages due to the ZFS appliance going down. It wasnt us :-)
Question(s)
About Me
CTO & Cofounder Patari[Pakistans largest Music Streaming Portal]
iqbal@patari.pk
CTO Active Capital IT[Software Consultancy working with Cataloging, Artwork & Telecom Sectors]
italaat@acit.com
https://twitter.com/iqqi84
https://au.linkedin.com/pub/iqbal-bhatti/14/63/493
Porting a legacy Multimedia
By Iqbal Talaat Bhatti



