Kamon for Distributed Tracing
Presented by Ivan Topolnjak (@ivantopo)
Kamon
A set of libraries providing metrics collection, context propagation and
distributed tracing for applications on
the JVM
- Almost 5 years of efforts
- Open Source
- Initially focused on the Scala ecosystem
- Used in production since early days
- 1.0.0 Released January 2018
- "Vendor Neutral"

Motivations
Traditional Threading
Servlets
"Reactive" Threading
Akka, Futures, RxJava
We had to have some AkKA MONitoring :P
Kamon at a Glance
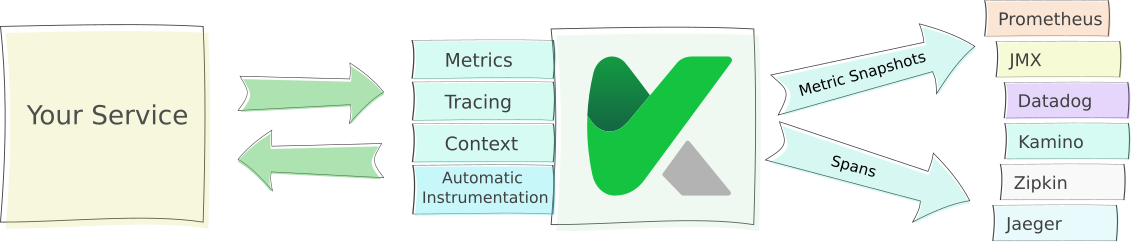
Metrics API
- Dimensional Data Model
- Data flush on a defined interval
- Write and Read sides are separate
- 4 base instruments
- Counters
- Gauges
- Histograms
- Range Samplers
- HDR Histogram Underneath
// Creating Instruments
val histogram = Kamon.histogram("span.processing-time")
.refine("operation", "GET /users")
histogram.record(1000349L)
// Creating a Metrics Reporter
trait MetricReporter {
def start(): Unit
def stop(): Unit
def reconfigure(config: Config): Unit
def reportPeriodSnapshot(snapshot: PeriodSnapshot): Unit
}
// Adding Reporters in Runtime
Kamon.addReporter(new PrometheusReporter())
Kamon.addReporter(new KaminoReporter())We love distributions and percentiles
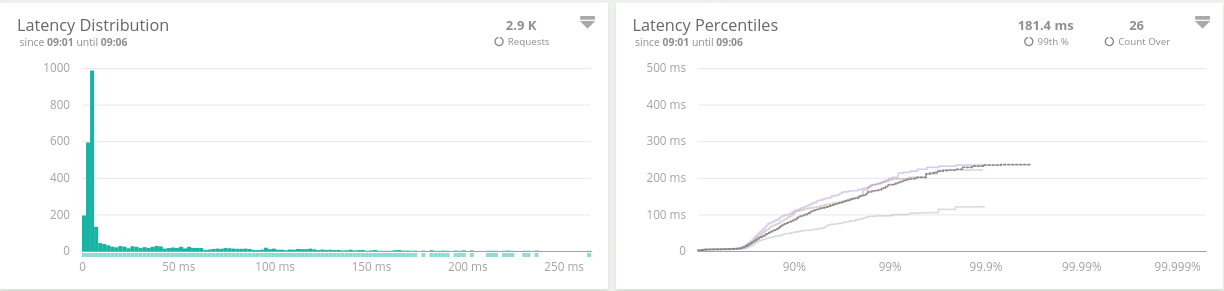
The Distribution snapshots contain a compact versions of all the HDR Histogram data.
Range Sampler What??
Tracks behavior rather than point-in-time values
Tracing API
- Heavily Influenced by Brave and OpenTracing
- Spans flushed in batches at a fixed interval
- Write and Read sides are separate
- Pluggable Identity Providers
- Small API additions for metrics
- Propagation is built on Kamon's Context
// Creating a Metrics Reporter
trait MetricReporter {
def start(): Unit
def stop(): Unit
def reconfigure(config: Config): Unit
def reportSpans(spans: Seq[Span.FinishedSpan]): Unit
}
// Adding Reporters in Runtime
Kamon.addReporter(new ZipkinReporter())
Kamon.addReporter(new JaegerReporter())
Kamon.addReporter(new KaminoReporter())Using a Span
- No Baggage
- No notion of Context
- Spans generate metrics with default tags:
- operation
- error
- parentOperation
val span = Kamon.buildSpan("find-users")
.withTag("string-tag", "hello")
.withTag("number-tag", 42)
.withTag("boolean-tag", true)
.withMetricTag("early-tag", "value")
.start()
span
.tag("other-string-tag", "bye")
.tag("other-number-tag", 24)
.tag("other-boolean-tag", false)
span
.mark("message.dequeued")
.mark(at = Instant.now(), "This could be free text")
span
.tagMetric("tag", "value")
.disableMetrics()
.enableMetrics()
span.finish()Context API
- Immutable key/value store
- Two propagation scopes:
- local
- broadcast
- Two propagation mediums:
- HTTP Headers
- Binary
- Built-in B3 and String codecs
- Pluggable Codecs
// Propagated in-process only
val UserID = Key.local[String]("userID", "undefined")
// Propagated in-process and across processes.
val SessionID = Key.broadcast[Option[Int]]("sessionID", None)
val RequestID = Key.broadcastString("requestID")
// Creating a Context with two keys
val context = Context()
.withKey(UserID, "1234")
.withKey(SessionID, Some(42))
// Reading values from a Context
val userID: String = context.get(UserID)
val sessionID: Option[Int] = context.get(SessionID)
// The default value is returned for non-existent keys
val requestID: Option[String] = context.get(RequestID)
Context Scoping
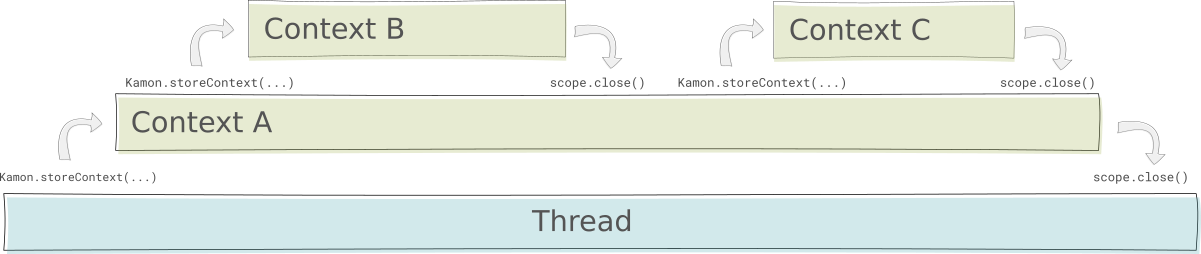
A Context could be stored in any Storage implementation although only a ThreadLocal-based Storage is shipped with Kamon
Creating a Codec
- Per-key implementations
- Resolved at runtime via configuration
- Free usage of headers
// Propagated in-process only
trait ForEntry[T] {
def encode(context: Context): T
def decode(carrier: T, context: Context): Context
}
// Where T can be:
// - TextMap for HTTP Headers
// - ByteBuffer for BinaryUse case:
Propagate Sidecar Headers
// Add to the configuration file:
kamon.context.codecs {
string-keys {
l5d-ctx-dtab = "l5d-ctx-dtab"
l5d-ctx-deadline = "l5d-ctx-deadline"
l5d-ctx-trace = "l5d-ctx-trace"
}
}Use case:
Switch to TraceContext Propagation
// Add to the configuration file:
kamon.context.codecs.http-headers-keys {
span = "kamon.trace.W3CTraceParentCodec"
tracestate = "kamon.trace.W3CTraceStateCodec"
}Codec available at https://github.com/kamon-io/kamon-tracecontext-codec
Instrumentation
- Akka Actors, Routers, Dispatchers. Local and Remote
- Scala Futures
- JDBC and Hikari CP
- Akka HTTP
- Play Framework
- HTTP4S
- Logback (AsyncAppender)
- Executors
- System and JVM Metrics
Reporters
- Prometheus
- InfluxDB
- StatsD
- Zipkin
- Jaeger
- Datadog (only metrics)
- Sematext SPM
- Kamino
Planned:
- Stackdriver
- Amazon Cloudwatch + X-ray
Our near Future:
- Standarize HTTP instrumentation (like HttpTracing)
- Improve reporters startup and configuration process
- Formalize Context tags
- Microbenchmarks and continuous performance monitoring
- Stackdriver + Amazon reporters
- Nicer out of the box experience
And after that:
- Goodbye AspectJ, Hello Kanela
- APM-like experience from the very beginning
More detailed writeup: http://kamon.io/teamblog/2018/04/27/kamon-forecast-april-2018/
Kamon for Distributed Tracing
By Ivan Topolnjak
Kamon for Distributed Tracing
Distributed Tracing Workshop - Solingen - May 2018


