2020 U.S.
Presidential
Election Analysis
Final project
CAP6307: Text Mining
by
Dharitrikumari Rathod
Lamia Alshahrani
Yuh Haur Chen
Introduction:
- Analysis of 2020 Presidential debates and townhall meetings
-
Comparison of 2020 Presidential debates and 2016 presidential debates
| Research questions: | Method |
|---|---|
| 1. What were the most prominent words said by each candidate during the different stages of debate during the 2020 and 2016 presidential debates? | Word cloud Bigram |
| 2. Which candidate was most talkative during the debate? | Statistics |
| 3. How many times did they get interrupted by others? | Heatmap |
| 4. What were the positive and negative sentiments of the 2020 debate? | Sentiment analysis |
| 5. Which topics were discussed during the 2020 Presidential debates? | TF-IDF, Cosine similarity |
| 6. How does the similarity of the candidate’s speech compare to the other candidate on the same topic? | TF-IDF, LDA model |
| 7. How does the similarity between President Trump's speech during 2020 and 2016? | TF-IDF, LDA model |
Related work:
Data source
Knowledge

Presidential debate 2016 Presidential debate 2020
Rev.com
David M. Blei
LDA
- Sentiment analysis was done for presidential candidates( Indonesia) based on Twitter data using the Naive Bayes algorithm
- TF-IDF algorithm was used for the news document to find the frequency of word/term (TF)and to find the frequency of the term in other documents (IDF)
Data Processing:
- Normalization
- Tokenization
- Stopwords
- custom stopwords
- Lemmatization
Libraries & Packages & Data cleaning:
Tools: Python 3.8.2, Jupyter notebook
| Methods | Libraries & Packages |
|---|---|
| Word cloud | NLTK, Pandas, Word-cloud |
| Bi-grams | NLTK,Pandas |
| Heatmaps | Mathplotlib, Pandas |
| Sentiment analysis | Sentiment Intesity Analyzer, |
| TF-IDF model | Scikitlearn, Pandas, NLTK |
| LDA-BoW Model | Gensim, NLTK, Pandas, Spacy, pyLDAvis |
| LDA-TF-IDF Model | Gensim, NLTK, Pandas, Spacy, pyLDAvis |
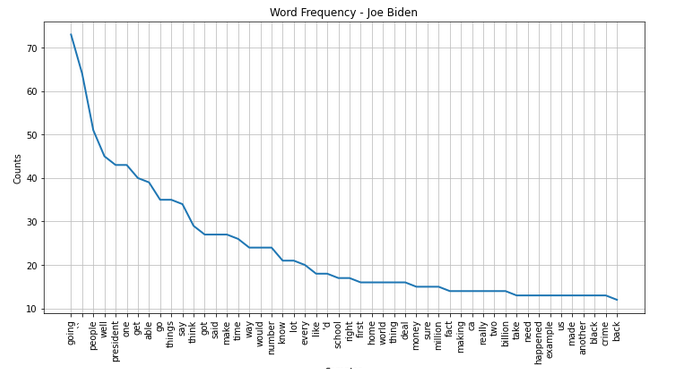
#1 Most prominent words
- Word Cloud
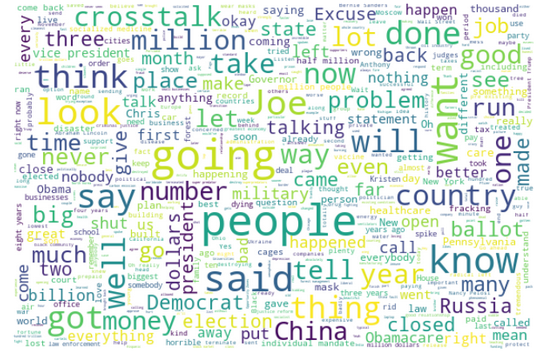
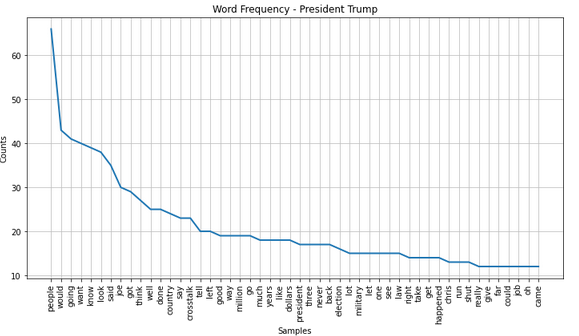
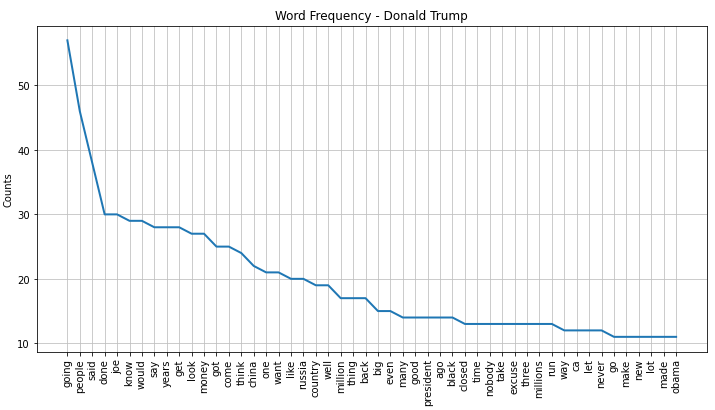
Most prominent words: 2020
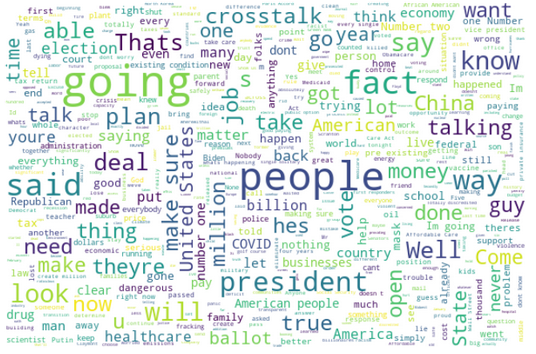
Biden 2020
Trump 2020
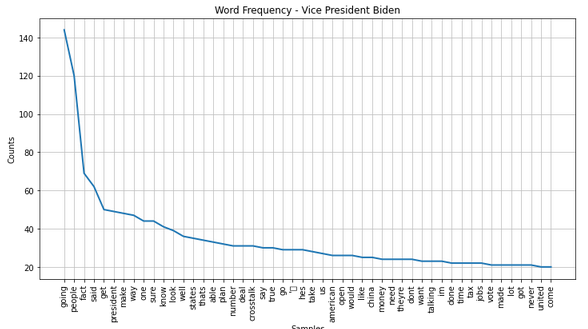
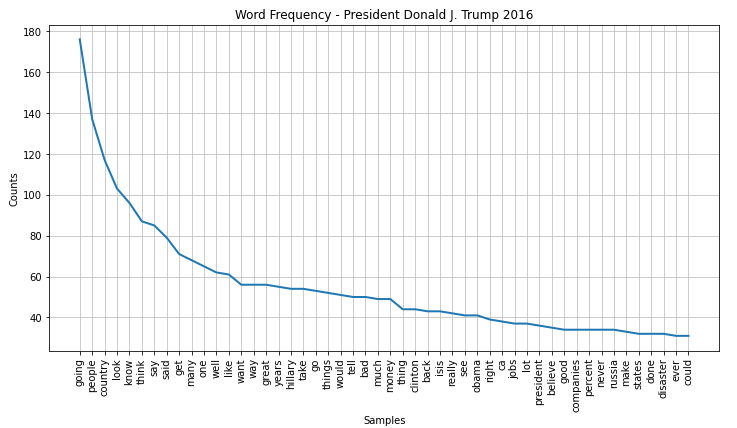
Most prominent words: 2016
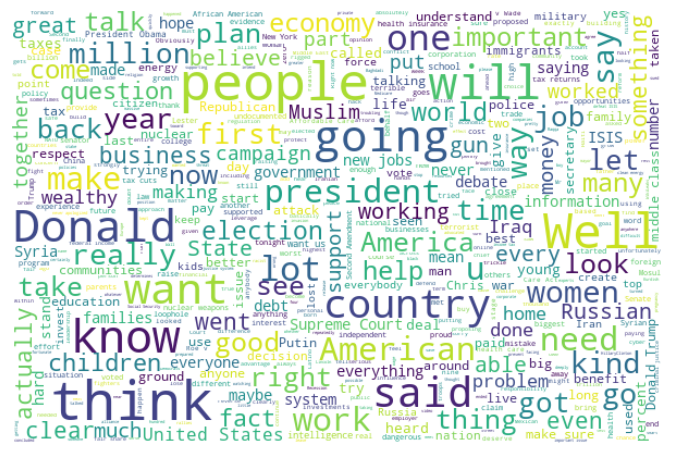
Clinton 2016
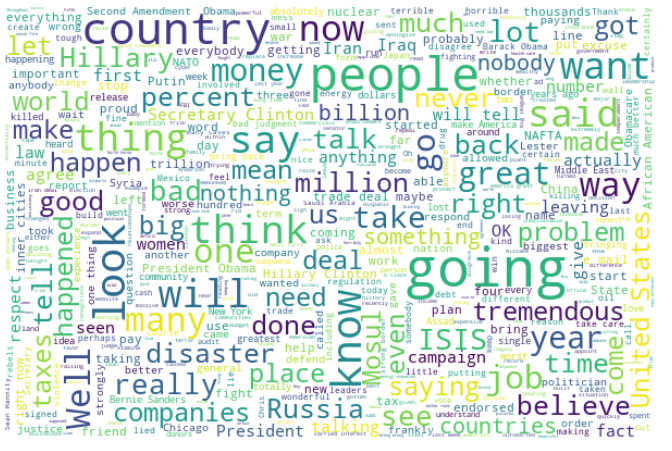
Trump 2016
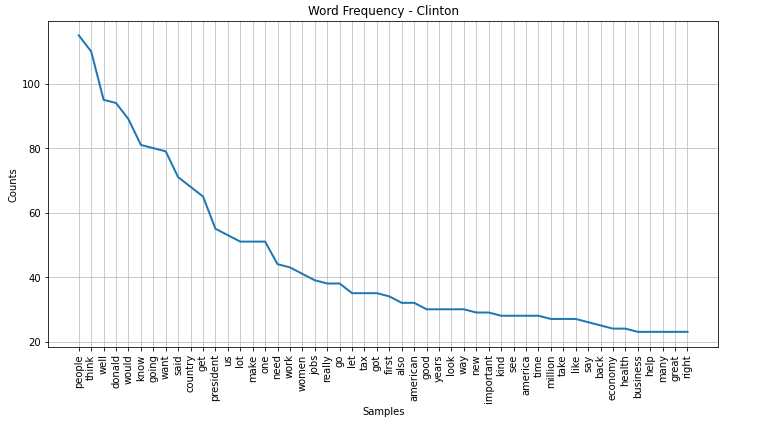
Most prominent words During First Debate 2020
Biden 1st debate
Trump 1st debate
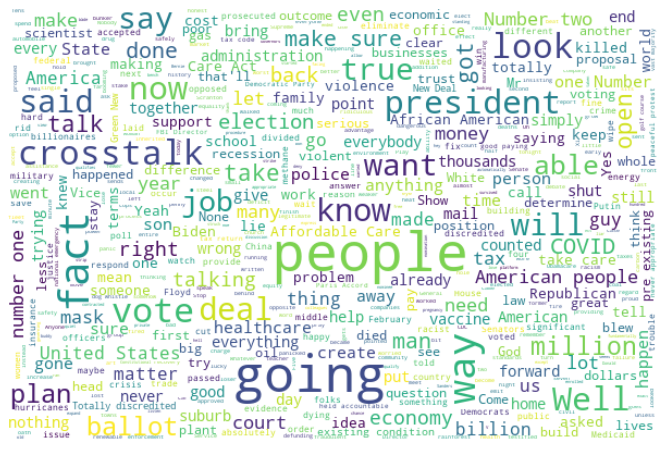
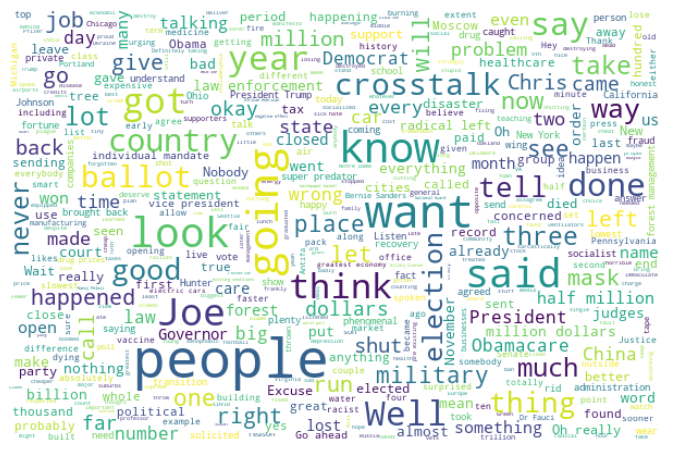
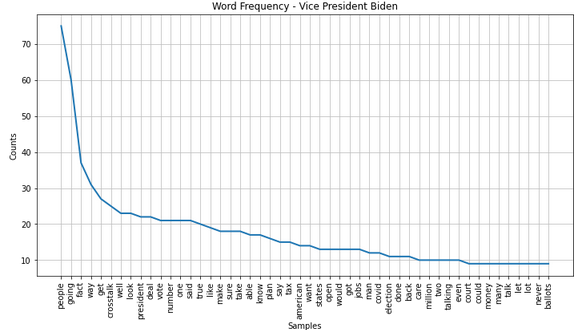
Most prominent words During Second Debate 2020
Biden 2nd debate
Trump 2nd debate
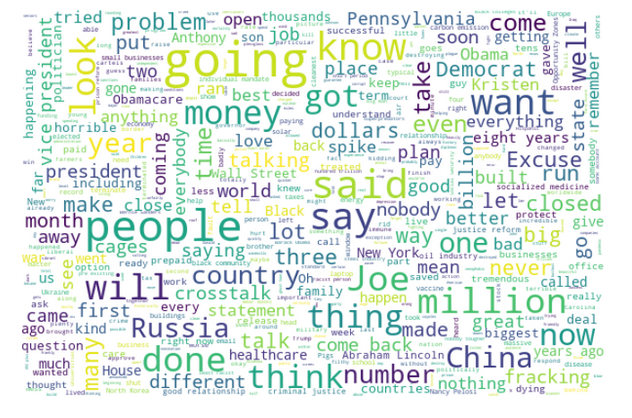
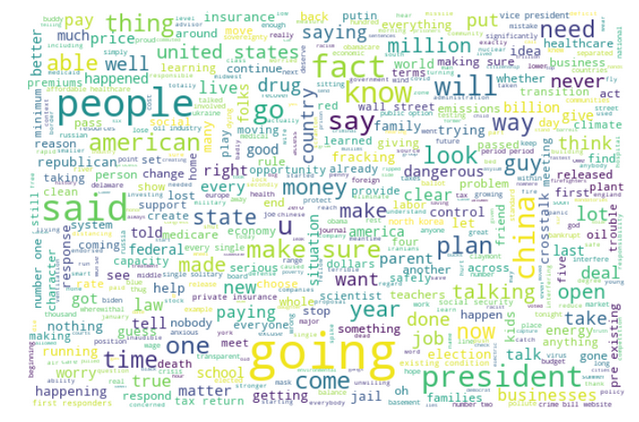
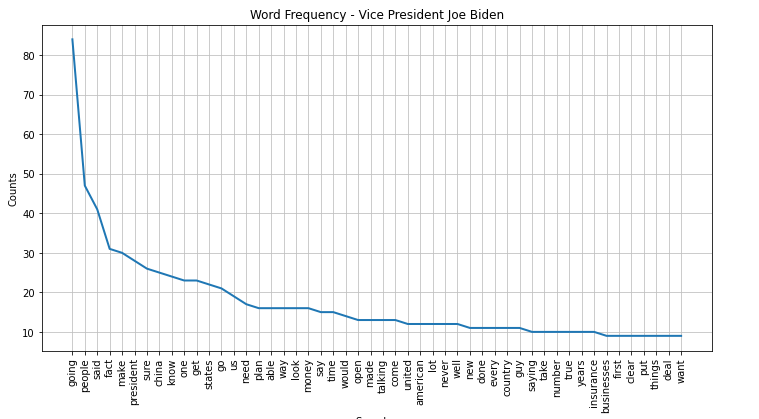
Most prominent words During TownHall Debate 2020
Biden TownHall
Trump TownHall
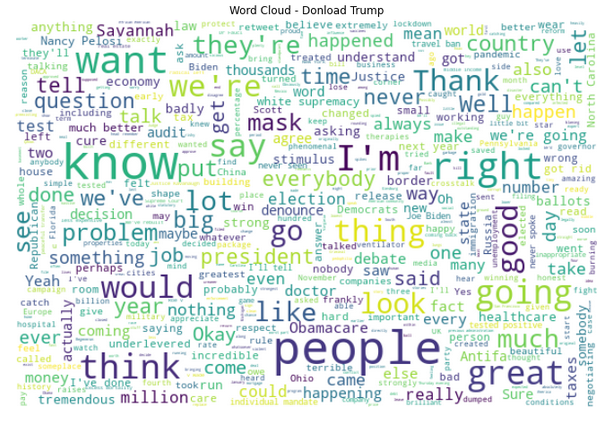
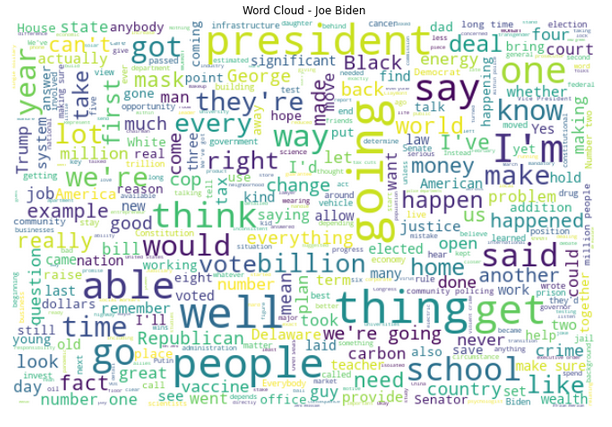
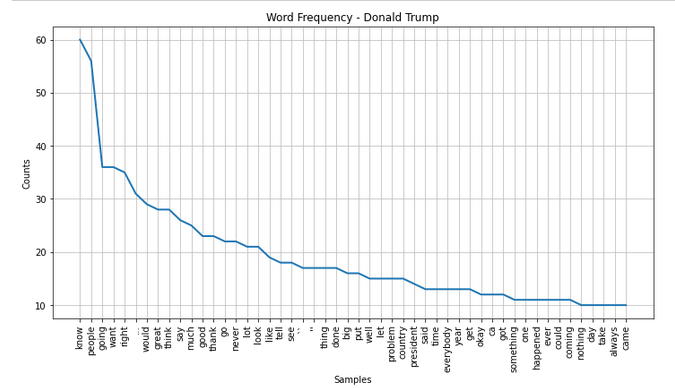
#1 Most prominent words
- Bigram
Most Prominant topics: 2020
Bigram: Joe Biden
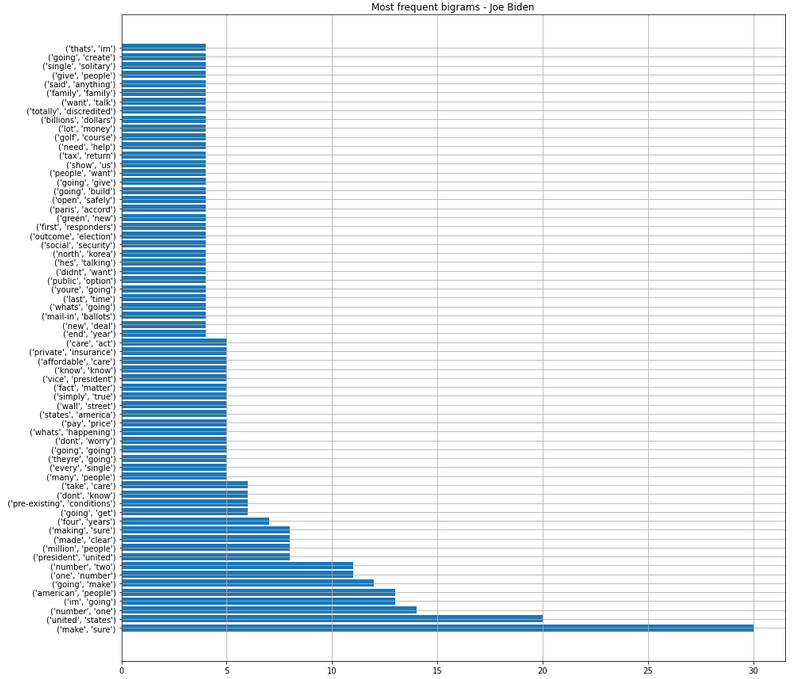
| Topics |
|---|
| Green infrastructure |
| Social security |
| Mail in ballot |
| Health insurance/ Affordable care act |
| First responders |
| Tax plans |
Most Prominant topics:
Bigram: Donald Trump
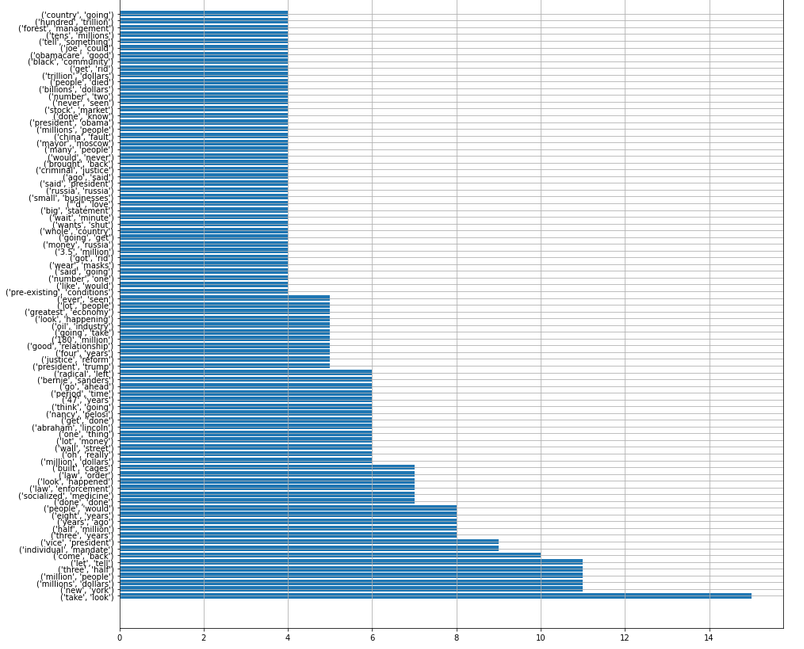
| Extracted Topics |
|---|
| New york |
| Individual mandate |
| Law enforcement |
| Stock market |
| Justice reform |
| Economy |
| Small businesses |
| Oil industry |
| Forest Management |
| Obamacare/Health Insuran |
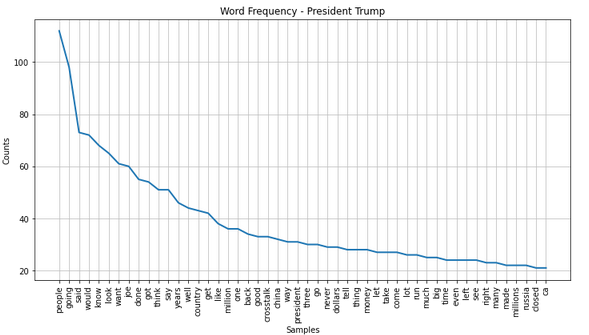
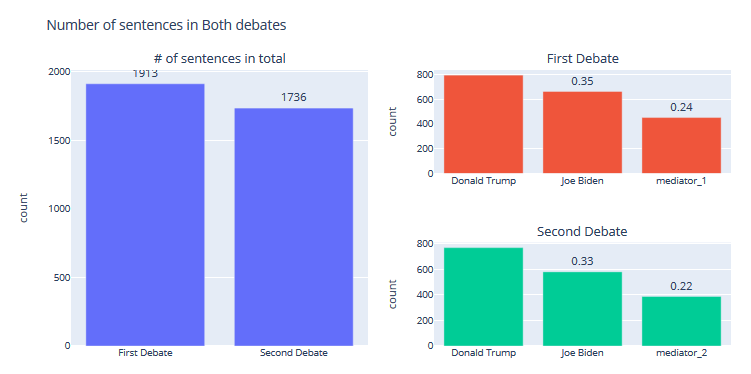
#2 Most talkative in 2020:
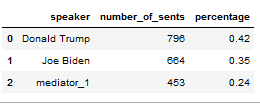
Debate_1
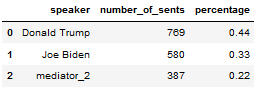
Debate_2
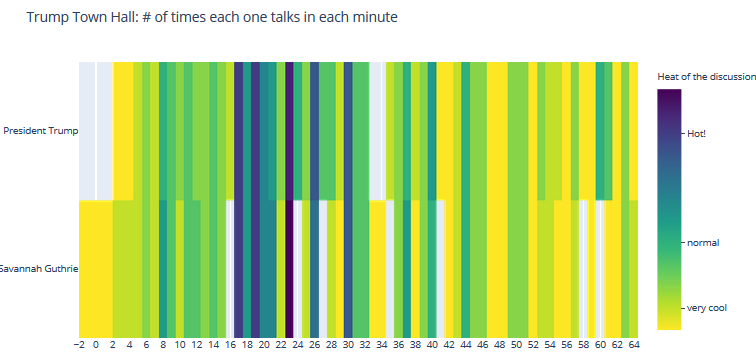
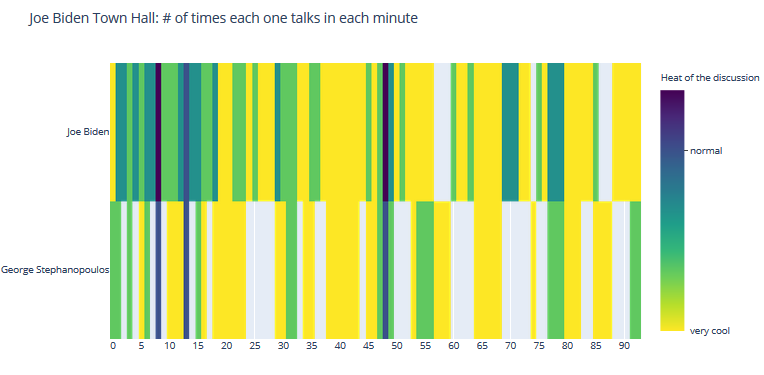
#3 Crosstalks
- Heatmap
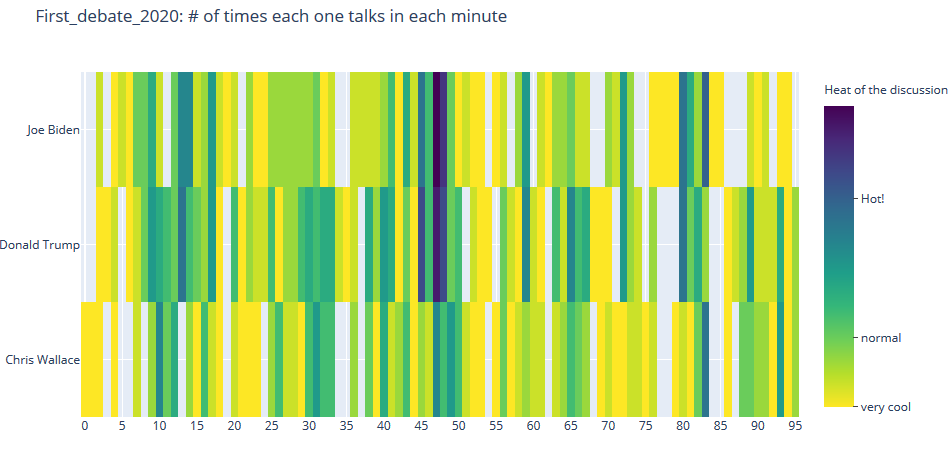
Crosstalk/Heat moment
Town Hall Crosstalks
#4 Sentiment analysis
Sentiment Analysis:
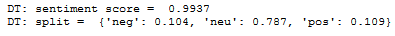
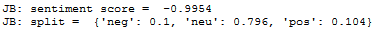
1st_debate

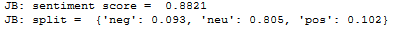
Overall 2020
2nd_debate
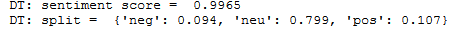
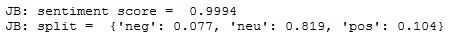
#5&6 Topic similarity
- TF-IDF
TF-IDF vectorizer
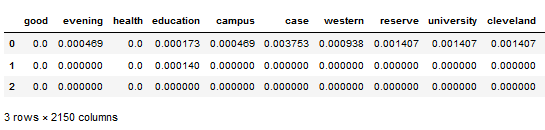
TF-IDF 1st debate
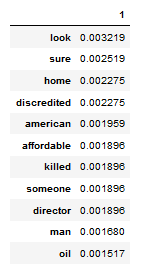
Biden
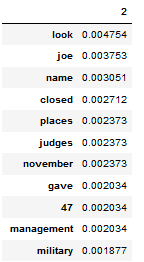
Trump
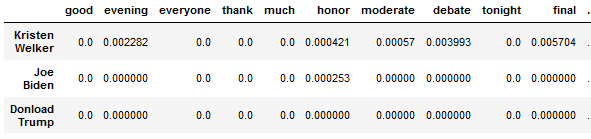
TF-IDF 2nd debate
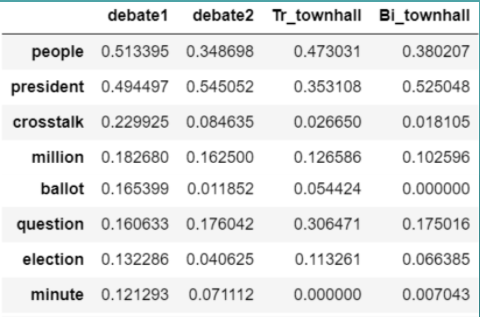
TF-IDF Topics
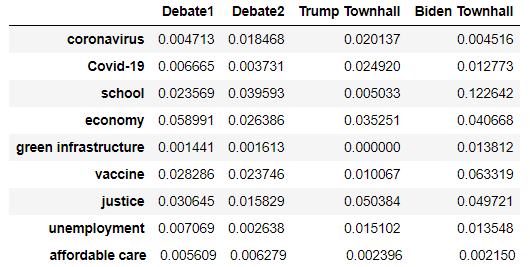
TFIDF and Cosine similarities
Built the TF-IDF Model to check if the given topic was discussed in the 2020 election or not. Also, compared the topic using cosine similarity at each stage of the Presidential election 2020.
Extracted Topics TFIDF
#5,6,7 Topic similarity
- LDA model
-
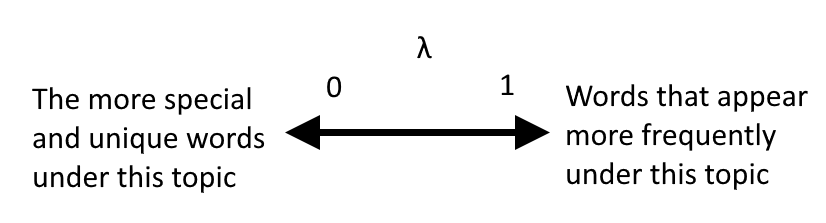
Each document is composed of several "Topic"
-
Each topic can be described by several important "words", and the same word can appear between different topics at the same time.
atent
irichlet
llocation
L
D
A

| Dictionary | Corpus |
|---|---|
| corpora.Dictionary() | Dictionary.doc2bow() models.TfidfModel() |
Dictionary
Corpus
First debate
Combined debate
Second debate
BoW
LDA model 1~3
TF-IDF
LDA model 1~3
Debate1-BoW
Debate1-tfidf
Debate2-BoW
Debate2-tfidf
Debate1+2-BoW
Debate1+2-tfidf
Dictionary
Dictionary
+
+
BoW corpus
tfidf corpus
Bag of words
TF-IDF
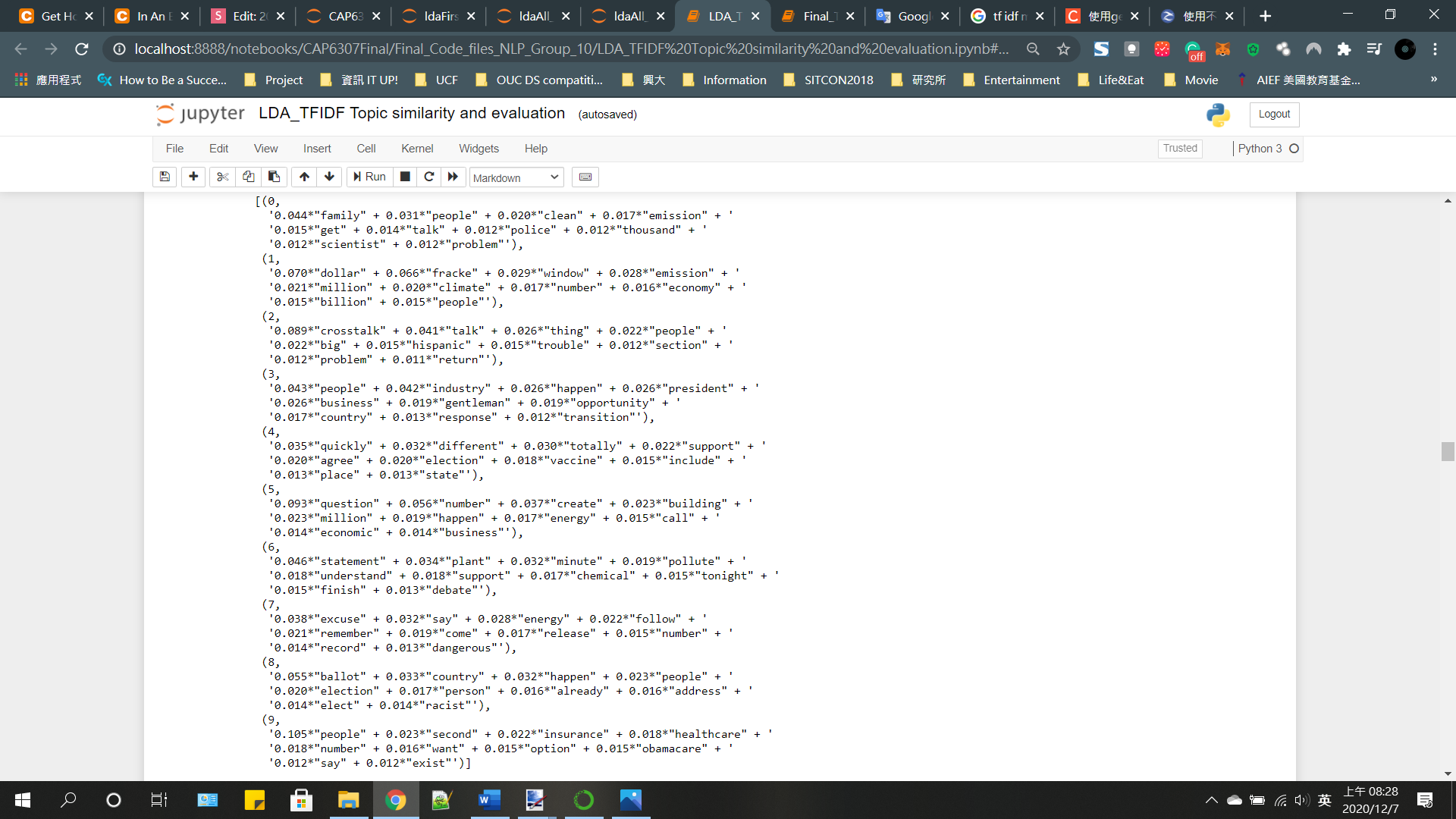
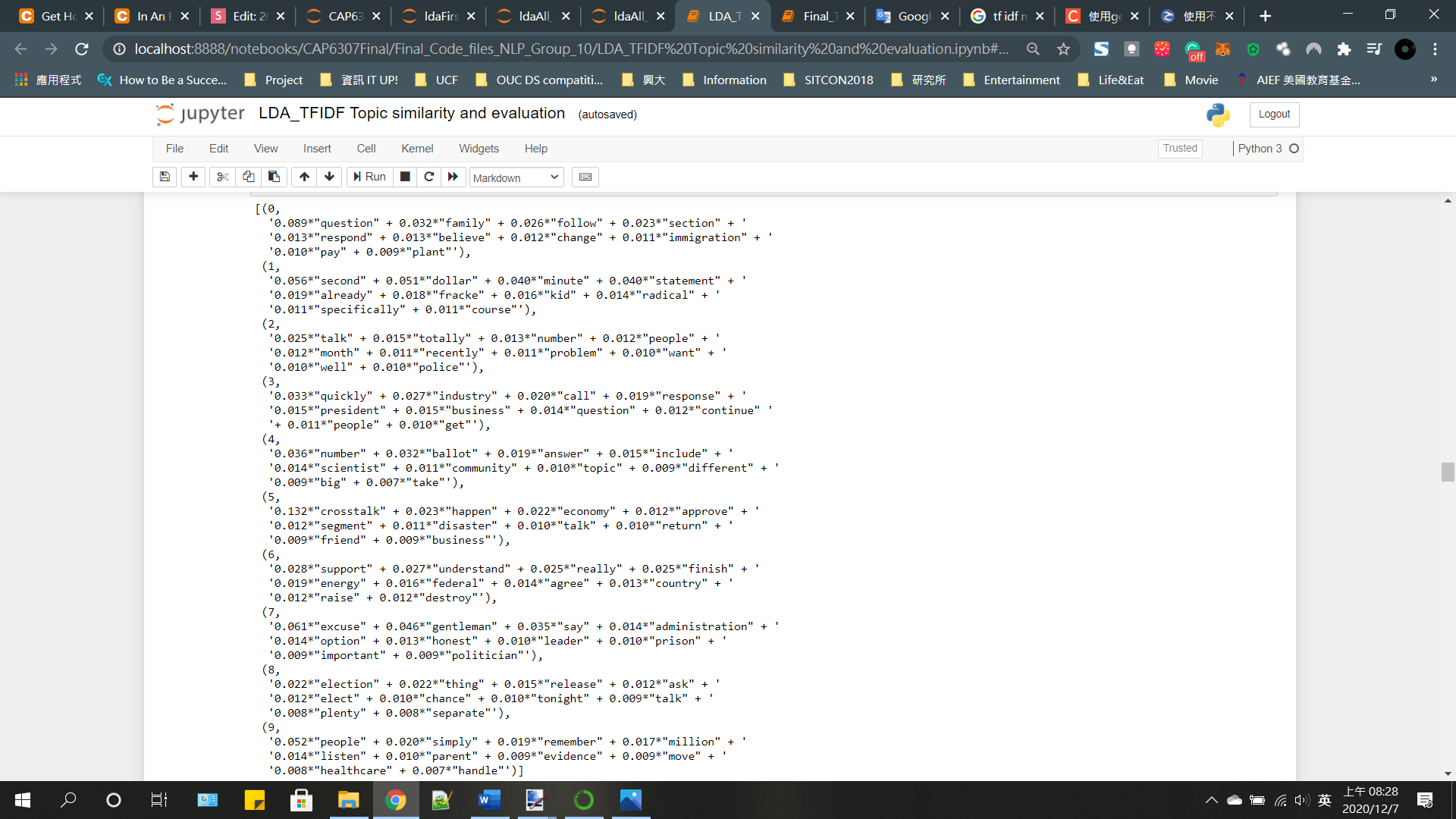
Topic extract
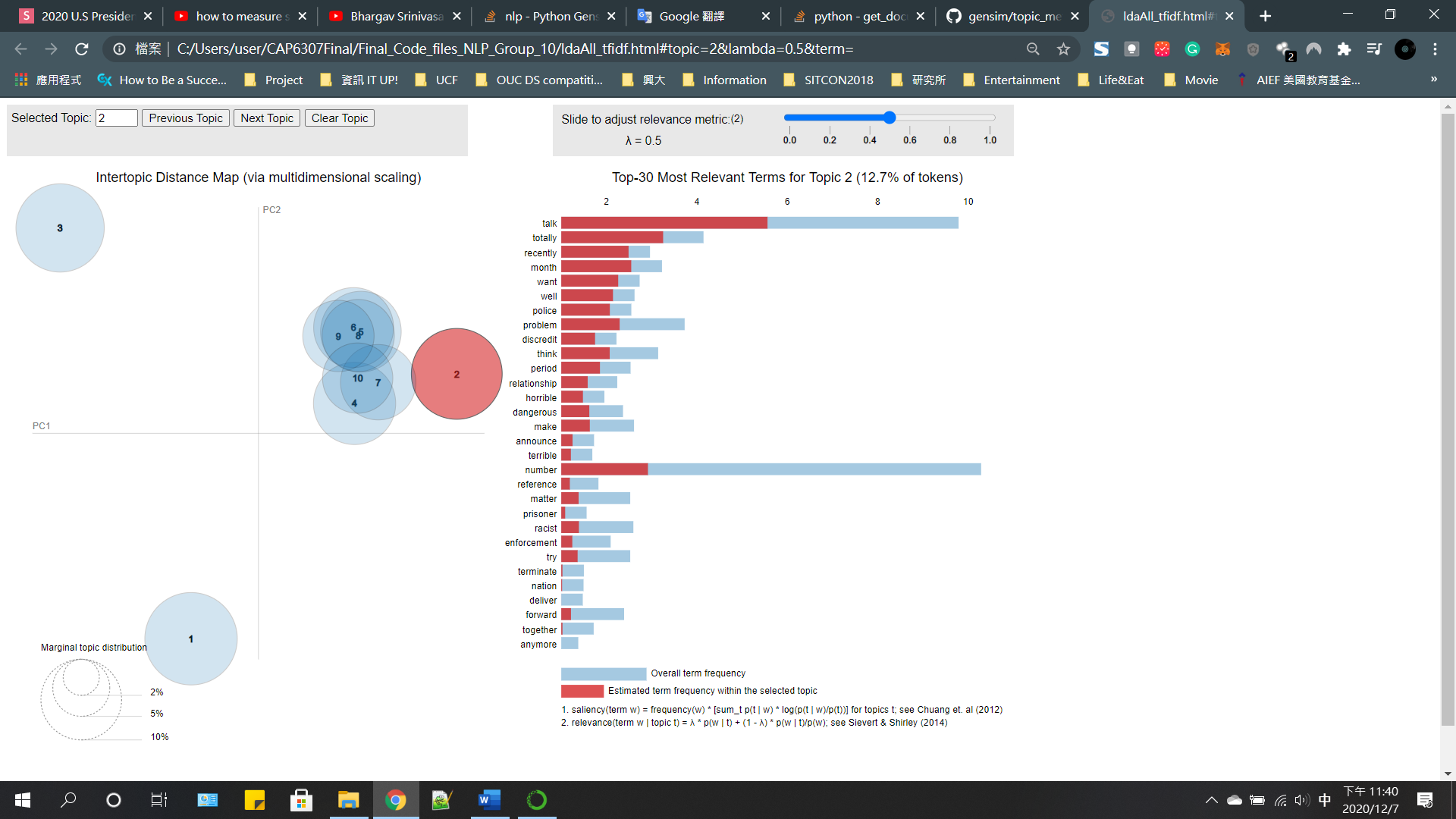
pyLDAvis
pyLDAvis
What topics?
| BoW | TF-IDF |
|---|---|
| Second, insurance, healthcare, obamacare | Industry, child, website, reform, school, business |
| Industry, business, website, plague, enormous, nuclear, opportunity, | Talk, totally, month, well, police, discredit |
| Family, Clean, filthy, emission, police, scientist, pollutant, environmental, carbon | Family, immigration, political, protest, tremendous, democratic |
| Ballot, election, inaugural, racist, chance | People, million, evidence, healthcare, opposite, condition, fantastic, nuclear |
| Create, building, question, economic, energy, company | Election, chance, separate |
| Excuse, energy, subsidy, dangerous, federal, border, highway, ecnomically | Ballot, number, answer |
| Statement, plant, pollute, chemical, refinery, superpredator | Crosstalk, economy, segment, disaster, vaccine |
| Crosstalk, Hispanic, environment, global warming, gasoline, unemployment | Second, dollar, radical, deserve |
| Dollar, fracke, billion, emission, climate, market | Support, energy, federal, |
Evaluation LDA Models: BOW Vs. TF-IDF:
BoW
TF-IDF
Topic Similarity
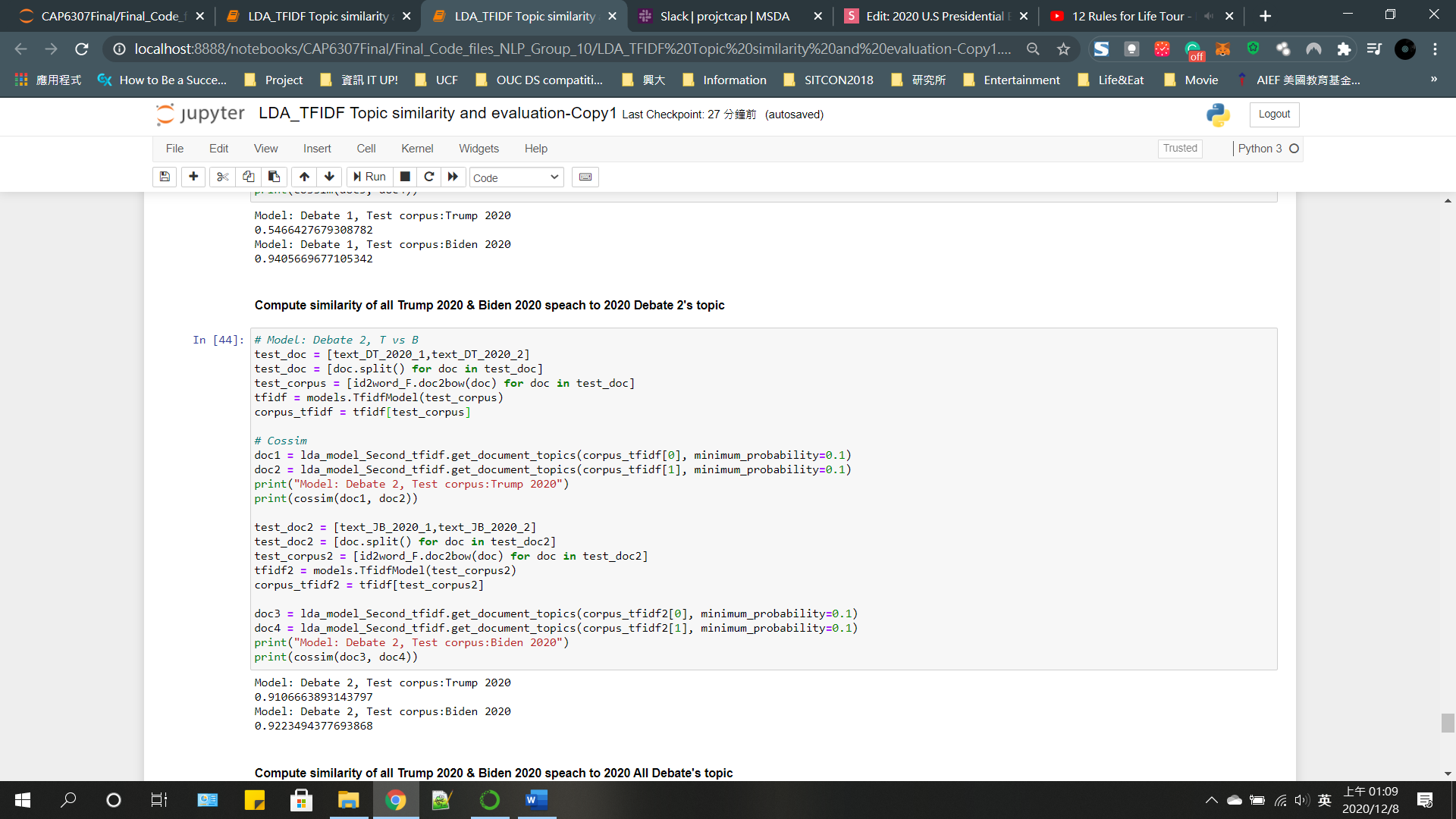
Topic Similarity
Trump
debate1
Trump
debate2
Test doc - Trump
Test doc - Biden
Biden
debate1
Biden
debate2
Test doc - Trump
Trump
2016-1
Trump
2016-2
LDA
Debate 1
LDA
Debate 2
LDA
Debate All
Result
| Questions | Answers |
|---|---|
| Word Cloud:The most prominant word in the Presidential debates | People, going, president, country, said, opponent |
| Compare the topics covered by each candidate at different stages | Money, China, insurance, businesses |
| TF-IDF: Prominant words with weights assigned to it -people, President, ballots | people president million, ballot, question, election |
| Bigrams: Extract more meaningful topics discussed: green infrastructure, forest management | Pandemic, Green infrastructure, Affordable care act, Stock market |
| Heatmap: Visualize the crosstalks during the debates: debate 1 | debate1: 13, debate 2: 7 |
| Word Analysis: Number of sentences spoken during each debates by whom and how many: President Trump, Debate | Debate 1, President Trump |
Sentiment Analysis: Based on the words used during the debates
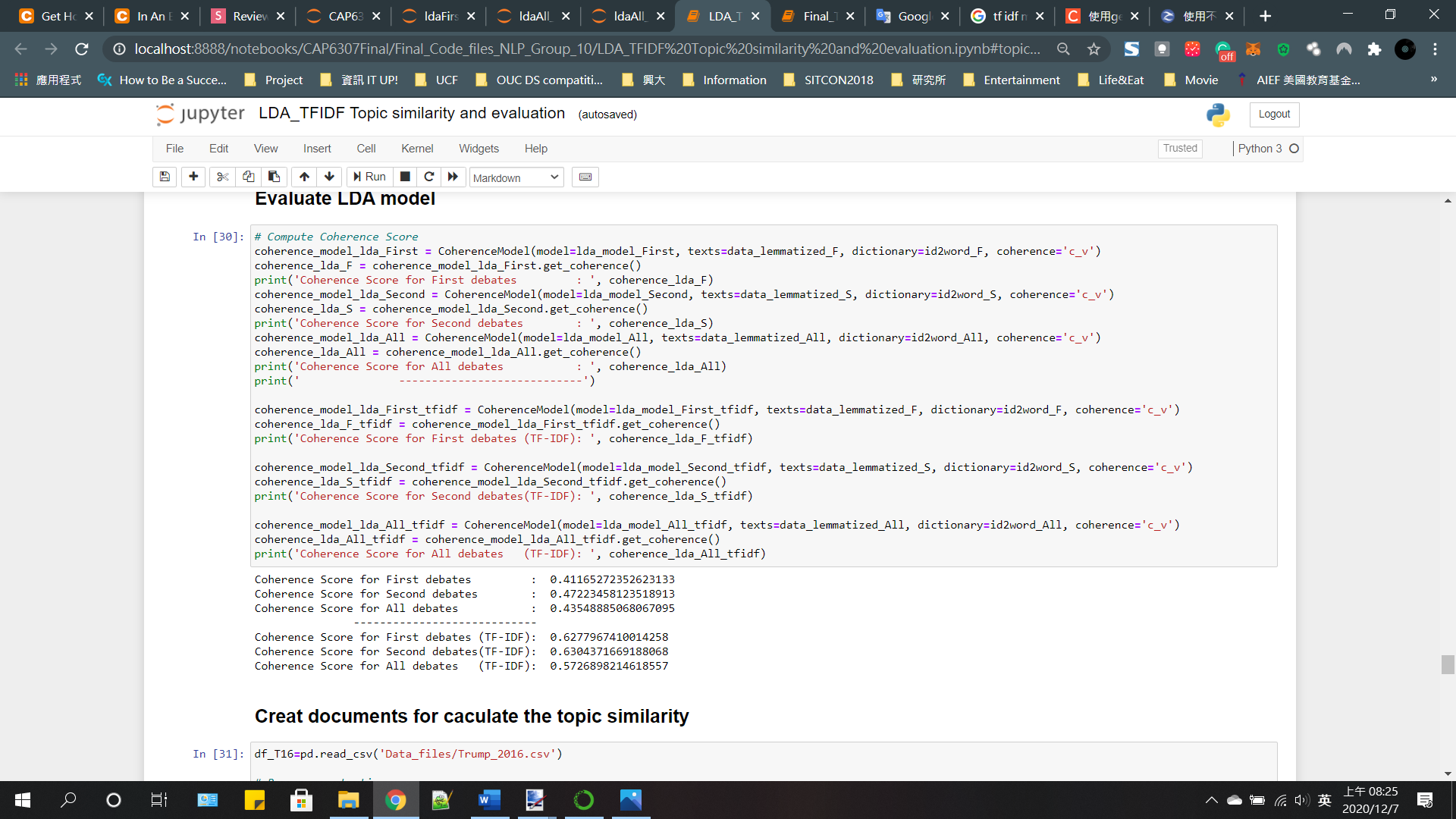
LDA Model: Trained LDA model based on BOW and TF-IDF and compared the scores. LDA model based on TFIDf does better topic modelling.


Future Work:
-
To enhance this work in the future, we may use some advanced Machine Learning algorithms to train our models in order to get a high score of accuracy
-
Regex can be used to remove more unnecessary words/ numbers
-
We can train the TF-IDF model to find the most prominent words in the document.
- Train LDA on Bigrams to get more accurate topic modeling
Text
| i me my myself we our ours ourselves themselves you you're you've you'll you'd your yours yourself yourselves against between himself she she's |
her hers herself it it's its itself they them he him his their theirs what which who whom this that that'll these those |
were be been being have has had having do does did doing a an the and but if or because am is are was |
as until while of at by for with about into through during before after above below to from up down in |
out on off over under again further then once here there when where why how all any both each few more most |
other some such no nor not only own same so than too very s t can will just don don't should should've |
now d ll m o re ve y ain aren aren't couldn couldn't didn didn't doesn doesn't hadn hadn't hasn hasn't haven haven't |
isn isn't ma mightn mightn't mustn mustn't needn needn't shan shan't shouldn shouldn't wasn wasn't weren weren't won won't wouldn wouldn't |
|---|
NLTK' Stopwords
Code Demo

LDA model
gensim.models.LdaMulticore(corpus=corpus_All_tfidf,
id2word=id2word_All,
num_topics=10,
random_state=100,
chunksize=100,
passes=10,
per_word_topics=True)# Model: Debate all, T vs B
test_doc = [text_DT_2020_1,text_DT_2020_2]
test_doc = [doc.split() for doc in test_doc]
test_corpus = [id2word_All.doc2bow(doc) for doc in test_doc]
tfidf = models.TfidfModel(test_corpus)
corpus_tfidf = tfidf[test_corpus]
# Cossim
doc1 = lda_model_All_tfidf.get_document_topics(corpus_tfidf[0], minimum_probability=0.1)
doc2 = lda_model_All_tfidf.get_document_topics(corpus_tfidf[1], minimum_probability=0.1)
print("Model: Debate all, Trump 2020")
print(cossim(doc1, doc2))
test_doc2 = [text_JB_2020_1,text_JB_2020_2]
test_doc2 = [doc.split() for doc in test_doc2]
test_corpus2 = [id2word_All.doc2bow(doc) for doc in test_doc2]
tfidf2 = models.TfidfModel(test_corpus2)
corpus_tfidf2 = tfidf[test_corpus2]
doc3 = lda_model_All_tfidf.get_document_topics(corpus_tfidf2[0], minimum_probability=0.1)
doc4 = lda_model_All_tfidf.get_document_topics(corpus_tfidf2[1], minimum_probability=0.1)
print("Model: Debate all, Biden 2020")
print(cossim(doc3, doc4))Topic similarity
References:
[1] Meg Risdal - Kaggle. 2016 US presidential debates(Link)
[2] Heads or Tails - Kaggle. US Election 2020 - Presidential Debates(Link)
[3] Ari Aulia Hakim, Alva Erwin, Kho I Eng, Maulahikmah Galinium, Wahyu Muliady. Oct. 2014. “Automated document classification for news articles in Bahasa Indonesia based on term frequency-inverse document frequency (TF-IDF) approach”(Link).
[4] Meylan Wongkar, Apriandy Angdresey. Oct. 2019. “Sentiment Analysis Using Naive Bayes Algorithm Of The Data Crawler: Twitter”(Link).
[5] Yonghe Lu, Yawen Zheng. Nov. 2018. “Subject Analysis of the Microblog About US Presidential Election Based on LDA”(Link).
[6] David M. Blei. Apr. 2012. Probabilistic Topic Models(Link).
Thank you!
2020 U.S Presidential Election Analysis - Team 10
By jackiechen08
2020 U.S Presidential Election Analysis - Team 10
CAP6307 - Textmining (UCF MSDA)



