Dr James Cummings
Digital Editing:
text encoding, software,
and the risks of failure
James.Cummings@newcastle.ac.uk
@jamescummings

CC+BY (press space to cycle through slides)
Overview
- TEI: Text Encoding Initiative
- TEI Scope
- TEI Customisation
- Creating TEI files
- Publishing TEI files
- Risks of Failure: some problematic projects
- Lessons learned
TEI
(The Text Encoding Initiative: A markup vocabulary for digital texts)

The TEI (The Text Encoding Initiative) is:
- An international consortium of institutions, projects and individual members
- A community of users and volunteers
- A freely available manual of set of regularly maintained and updated recommendations: 'The Guidelines' with definitions, examples, and discussion of over 560 markup distinctions
- A mechanism for producing customized schemas for validating your project's digital texts
- A set of free and openly licensed, customizable tools and stylesheets for transformations to many formats (e.g. HTML, Word, PDF, Databases, RDF/LinkedData, Slides, ePub, etc.)
- A simple consensus-based way of organizing and structuring textual (and other) resources
- An archival, well-understood, format for long-term preservation of digital data and metadata
- Whatever you make it! It is a community-driven standard

Why use markup?
Markup is used in many different fields, for many different purposes: storing data, relating information, encoding understanding, preserving metadata
- Markup is a way of making our knowledge or understanding about a text explicit
- Markup makes strives to make explicit (to a machine) what is implicit (to a person)
- Markup assists us in facilitating re-use of the same material:
- in different formats
- in different contexts
- by different sorts of users
Descriptive Markup
- It is usually more useful to mark up what we think things represent (in a source text, in our understanding of the data, etc.) rather than what they look like.
- Using descriptive markup enables us to make explicit the distinctions we want to make when processing a string of characters
- It gives us a way of naming, characterising, and annotating textual data in a formalised way and recording this for re-use
- Also called 'Encoding' or 'Annotation'
Why do we use italic fonts?
Think about the uses for an italic font in any form of printed publication. Why might an author/publisher put some text into italics? What are they signalling about that text?
We can usually tell these types of things apart from context. If we want to use these categories, computers need to be told these things are different.
Some common uses include:
- titles
- emphasis
- foreign phrases
- technical terms
- editorial apparatus, captions, cross references
- quotations, speaker labels in drama
- speech and thought
... and many more
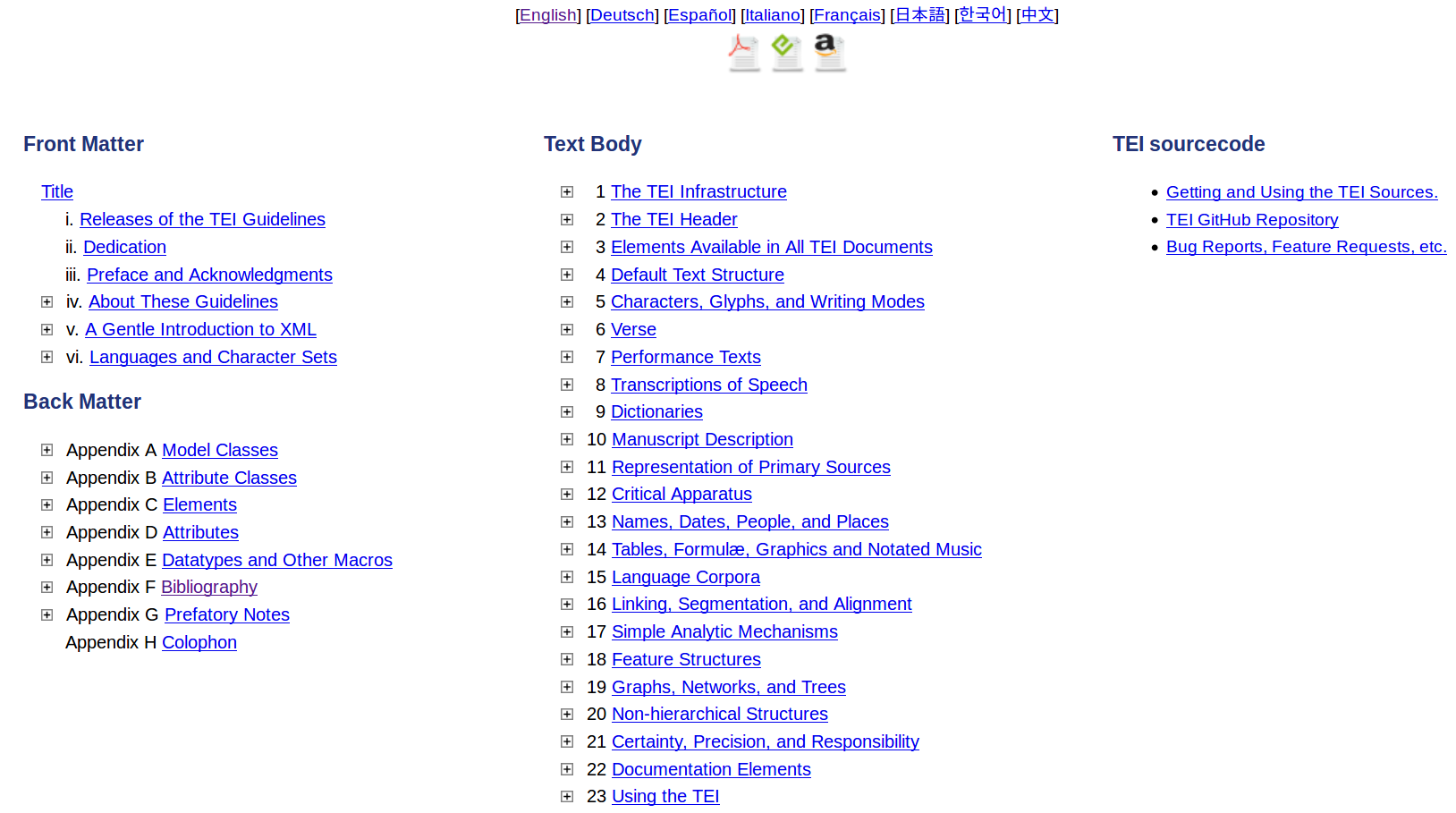
The TEI Guidelines

TEI Scope
(What kinds of texts is the TEI good for?)

What Kinds of Documents Can The TEI Cope With?
The TEI takes a generalistic approach to overall text structure and this means it should be able to cope with texts of any size, language, date, complexity, writing system, or media.
This could be in any form: books, journals, manuscripts, postcards, letters, rolls of papyrus, clay tablets, web pages, gravestones, etc. and contain any type of text.

Holinshed's Chronicles: columns, marginal notes, woodcuts
Medieval Drama: (York Cycle, Noah & Flood): Dramatic texts, speeches, rhyme schemes, editorial corrections, etc.

Medieval Manuscripts: full description, translations, stylistic rendering, variants, critical apparatus, editorial commentary, etc.


First Folio:
forme-work, catchwords, decorative initials, etc.


Wilfred Owen: manuscripts, corrections, multiple versions


Wilfred Owen: Letters, codewords

George Herbert: Graphic text layout, poetry

William Godwin's Diary: diary structure, abbreviated texts
Modern Manuscripts: Genetic editing, many hands, text (re)use, location/orientation on page


Print and Digital Dictionaries: entries, sense, etymologies, quotations, etc.

Epigraphical Texts: partial letters, supplied text, physical description


WW1 Propaganda: font, colour, glyph substitution, image classification and metadata


Various writing systems: Unicode/non-Unicode characters, right-to-left, reversing lines, etc.
A Mental Exercise We Often Give Students
Thinking about this material, and indeed your own, what do you think are the things you would like to mark up?
- Make a list of textual phenomena and metadata that are important to capture
- How likely is it that you can mark these up reliably and consistently?
- Could any of these potentially be marked up automatically by a cleverly crafted bit of software you had someone build?
Pretend an authoritarian anti-intellectual government has come to power and, through a series of bad decisions, has to slash your project funding by 50%. What do you do?
- Do you do half the amount of material in the same depth?
- Markup less?
- Invest in more semi-automatic markup?
- Something else?
Repeat the exercise.
TEI Customisation
(But I don't need everything the TEI provides, or want something it doesn't give me)

Possibilities of the
TEI Framework
Project B
Project A
New Elements




- The ability to interchange many documents improves significantly with a common interchange format
- Customisation can document the differences in a machine processable format so tools can compare different corpora
- @louburnard
Creating TEI Files
(Do I have to see the XML markup?)

Creating TEI
- How do people create TEI Files?
- hand encoding
- as individuals, through a variety of editors
- through an interface
- whether various forms, tags-off views in editors, or bespoke content management systems
- up-conversion
- of materials created in other formats, such as docx, xlsx, etc., by a programmer
- hand encoding

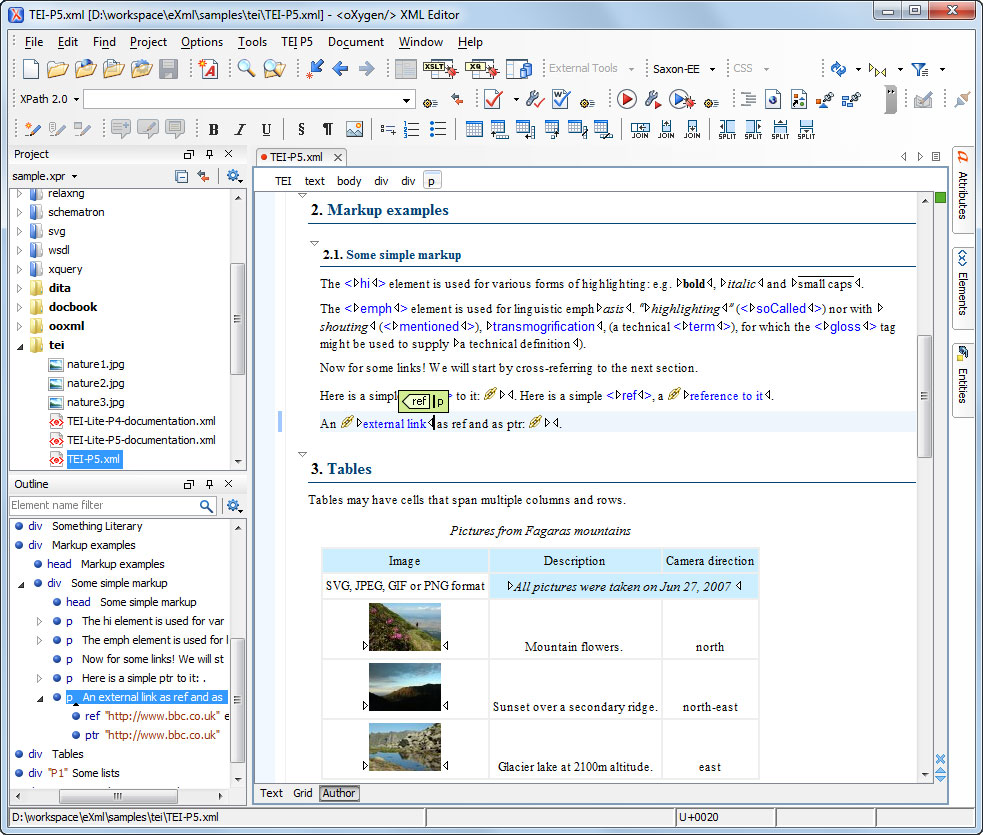
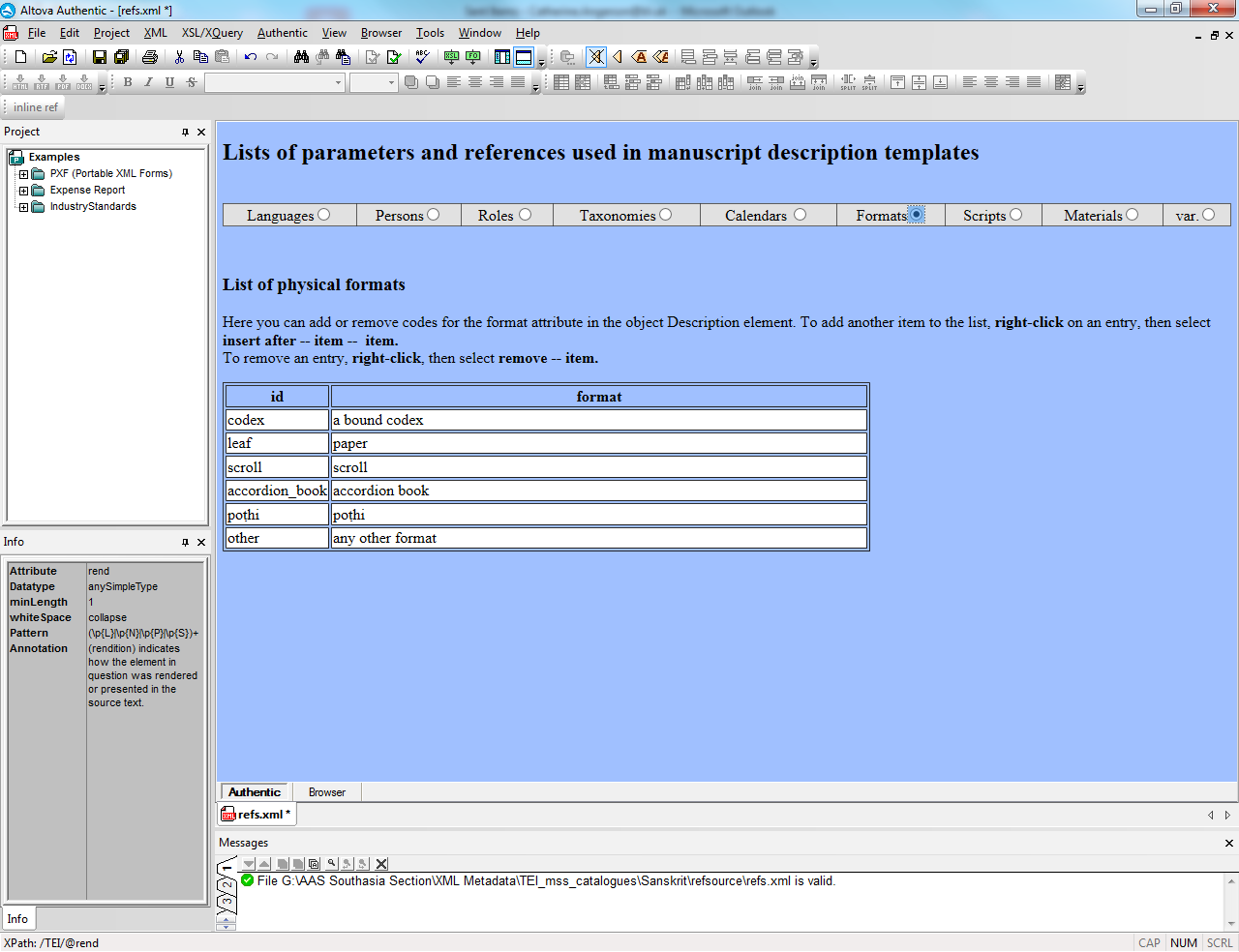
Up-conversion
- Often people will create editions through other forms such as MS Word (docx)
- Using the docxtotei conversion that TEI-C freely provides this can be transformed to TEI
- Limited to presentational markup (based on Word formatting styles)
- If you use special word phase-level styles in the form of tei_elementName it tries to convert these to that element (e.g. tei_name to <name>)
- Second phase of conversion work can often provide more detailed markup depending on how granular the original format preserves distinctions
In the end the best method to use is that which enables you actually to create your rich digital texts
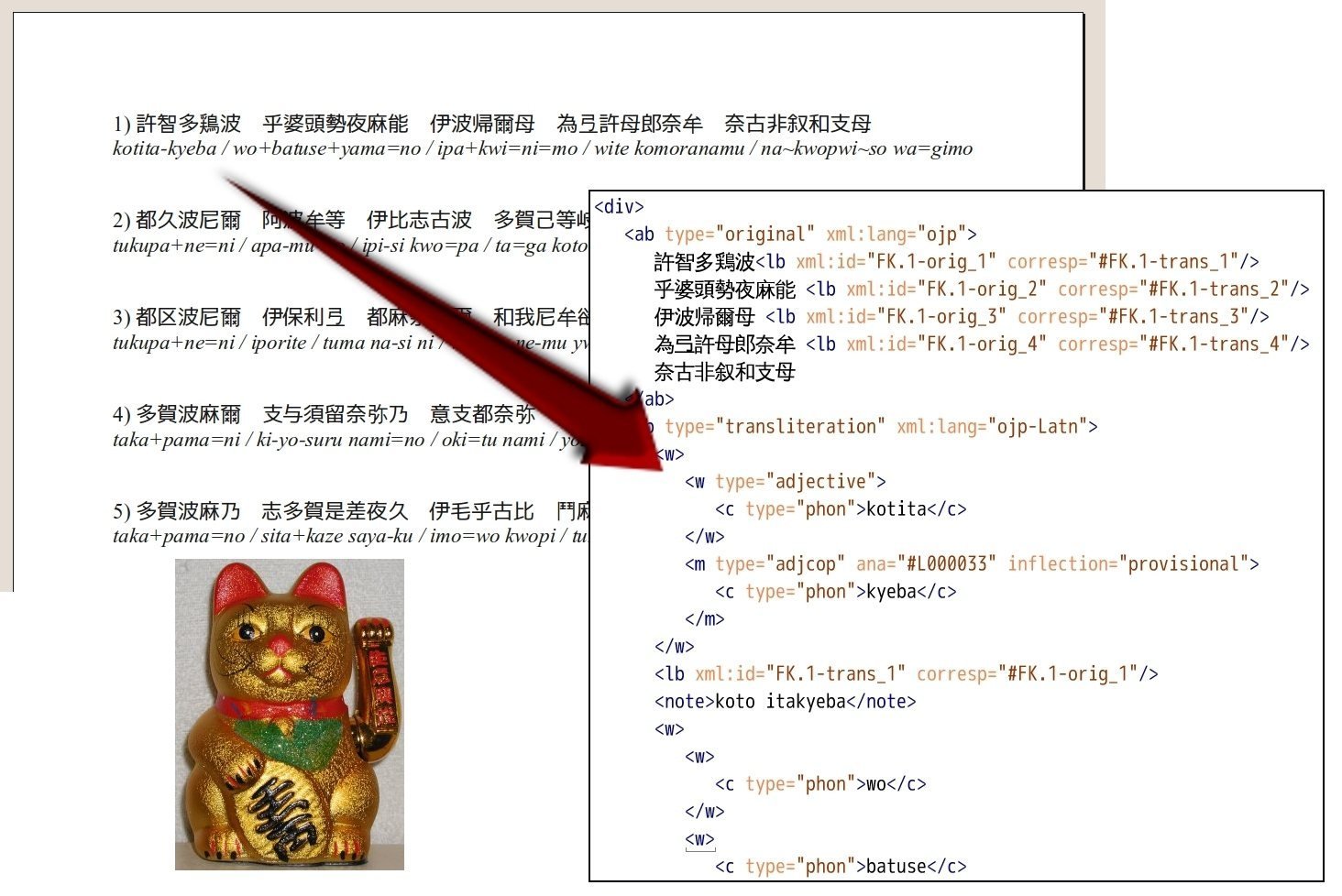
Publishing TEI Files
(How can I publish these TEI files?)

Publishing TEI
- There are many tools available these are only some of the examples of different types of tools:
- Edition Visualization Technology
- TEI Boilerplate
- TEI Critical Edition Toolbox
- TEI-C Stylesheets
- OxGarage
- CETEIcean
- eXist-db / TEI Publisher
- TAPAS project
- The tools you use may affect the features you can display to those reading your research and you may have more or less ability to customise
Edition Visualization Technology
- Easy publication for multi-witness critical editions
- Critical Edition support: rich and expandable critical apparatus, variant heat map, witnesses collation and variant filtering
- Bookmark: direct reference to the current view of the web application, page and edition level, collated witnesses and selected apparatus entry
- High level of customization: the editor can customize both the user interface layout and the appearance of the graphical components
- https://visualizationtechnology.wordpress.com/

TEI Boilerplate
- TEI Boilerplate gives in-browser conversion of TEI P5 XML using a simple XSL Stylesheet processing instruction
- It transforms elements to HTML necessary for display of images, making links clickable, etc
- Works in all major browsers
- Works well for small, simple, individual web pages
- Uses standard customisable CSS but also pays attention to CSS in TEI <rendition> elements
- Viewing the web page source gives access to your TEI
- http://teiboilerplate.org/

TEI Critical Apparatus Toolbox
- Based on TEI Boilerplate
- The toolbox lets you:
- Check your encoding: offers facilities to display your edition while it is still in the making, and check the consistency of your encoding
- Display parallel versions: choose the sigla of the witnesses, and the different versions of the text, following each chosen witness, will be displayed in parallel columns.
- http://ciham-digital.huma-num.fr/teitoolbox/


TEI-C Stylesheets
- Freely available, generalised XSLT stylesheets
- Transformations to and/or from around 40 formats such as:
- BibTeX, COCOA, CSV, DocBook, DocX (MS Word), DTD, EPub, XSL-FO, HTML, JSON, LaTeX, Markdown, NLM, ODT, PDF, RDF, RelaxNG, RNC, Schematron, Slides, TEI Lite, TEI ODD, TEI P4, TEI simplePrint, TCP, Text, Wordpress, XLSX (MS Excel), XSD
- Customisable through importing and overwriting templates; Stylesheets repository allows for local 'profiles'
- TEI-C offers services such as OxGarage which enable pipelined conversion to/from many more formats
- https://github.com/TEIC/Stylesheets



CETEIcean
- CETEIcean is a Javascript (ES6) library that enables TEI P5 XML to be displayed in a web browser without transforming them to HTML
- Instead it registers them with the browser as Custom Elements
- Because the elements are treated as HTML, the HTML it produces is valid, and there are not element name collisions (like HTML <p> vs. TEI <p>)
- http://github.com/TEIC/CETEIcean



Your Edition or Web Page Template
Embedded divisions of custom HTML elements
CETEIcean
JavaScript
eXist-db TEI Publisher
- The "instant publishing toolbox" based on eXist-db XML database
- Provides easy browsing and search of TEI XML documents initially built for TEI simplePrint
- Default display is clean and sophisticated page-by-page display
- Control of element display is by editing the processing model documentation embedded in the TEI ODD (the TEI customisation format)
- http://www.teipublisher.com/


TAPAS Project
- The TAPAS project: TEI Archiving, Publishing, and Access Service hosted by Northeastern University Library's Digital Scholarship Group
- A free account can contribute to projects and collections in TAPAS to archive, publish, discover or share their TEI files
- Built in very basic XSLT transformations
- TEI Members (or paid TAPAS membership) can create collections and projects
- 1GB of XML file storage for TEI files, TEI ODD Customisations
- http://tapasproject.org/

The Risks of Failure
(What could possibly go wrong?)

Some Problematic Projects
- Case studies of (otherwise excellent) projects with some challenges to overcome:
- CURSUS: An Online Resource of Medieval Liturgical Texts
- William Godwin’s Diary
- LEAP: Livingstone Online Enhancement and Access Project
CURSUS:
An Online Resource of Medieval Liturgical Texts
Original URL:
http://www.cursus.uea.ac.uk/
Working URL:
http://www.cursus.org.uk/
About the Cursus Project
- AHRB-funded project (2000-2003) at University of East Anglia to produce resource of medieval liturgical texts and explore XML publication possibilities
- Principal Investigator Professor David Chadd and Dr James Cummings produced editions of 12 medieval manuscripts
- Desire of research project to investigate and compare order of antiphons, responds, and prayers in these manuscripts which detail order of service in different places in England
- Project produced full copy of Corpus Antiphonalium Officii, Vulgate Bible, and other supplementary information




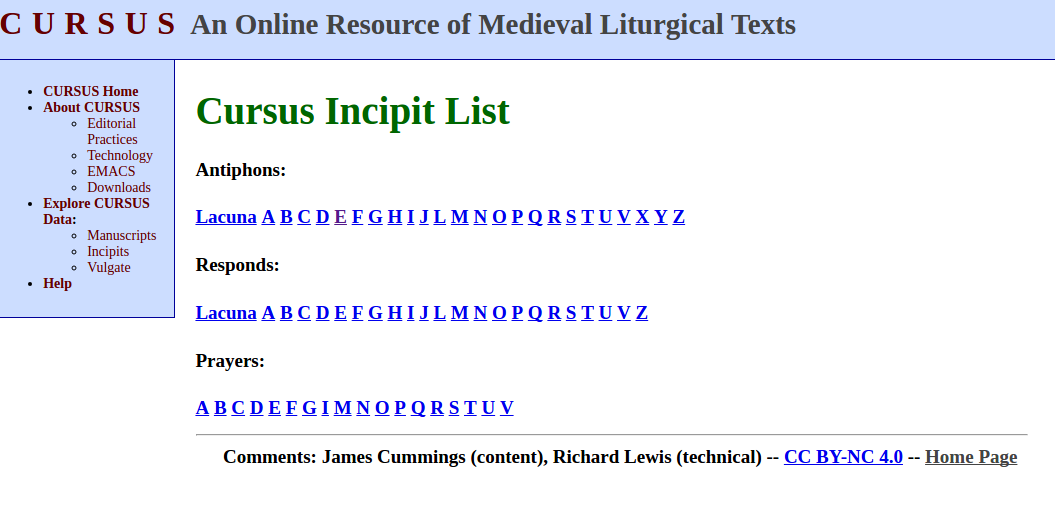
Cursus Project Challenges
- 2000-3 – Main Cursus project completed
- 2003 – I moved Oxford, project continues with Richard Lewis taking over technical development for 3 years
- 2006 – Sadly, in November 2006 the Principal Investigator Professor David Chadd died
- 2009 – ‘Climategate’ (hacking of emails relating to climate change data) caused UEA to close all off-campus access
- 2010 – Richard and I unable to access server when it went down, later server replaced, website gone.
- 2016 – After 6 years of negotiation I get confirmation of CC+BY+NC license of data, allowing Richard and I to put it up elsewhere
- TEI P4 XML data was safe but (until 2016) not stored in open repository, although freely available on original site it had not been explicitly licensed
William
Godwin’s
Diary
About the Godwin's Diary Project
- Godwin was a political philosopher and writer, Mary Wollstonecraft’s husband and Mary Shelley’s father
- University of Oxford project (2007-2010) to create digital edition of William Godwin’s Diary with funding for project from Leverhulme Trust
- Diaries purchased with Abinger Collection based on National Heritage Memorial Fund and donations
- 48 years of diaries in 32 octavo notebooks, written in highly abbreviated daily entries
- People’s names often given as initials
- little detail of substance of meetings
- networks of relationships with people, and aggregate lists of information able to extracted from richly encoded TEI

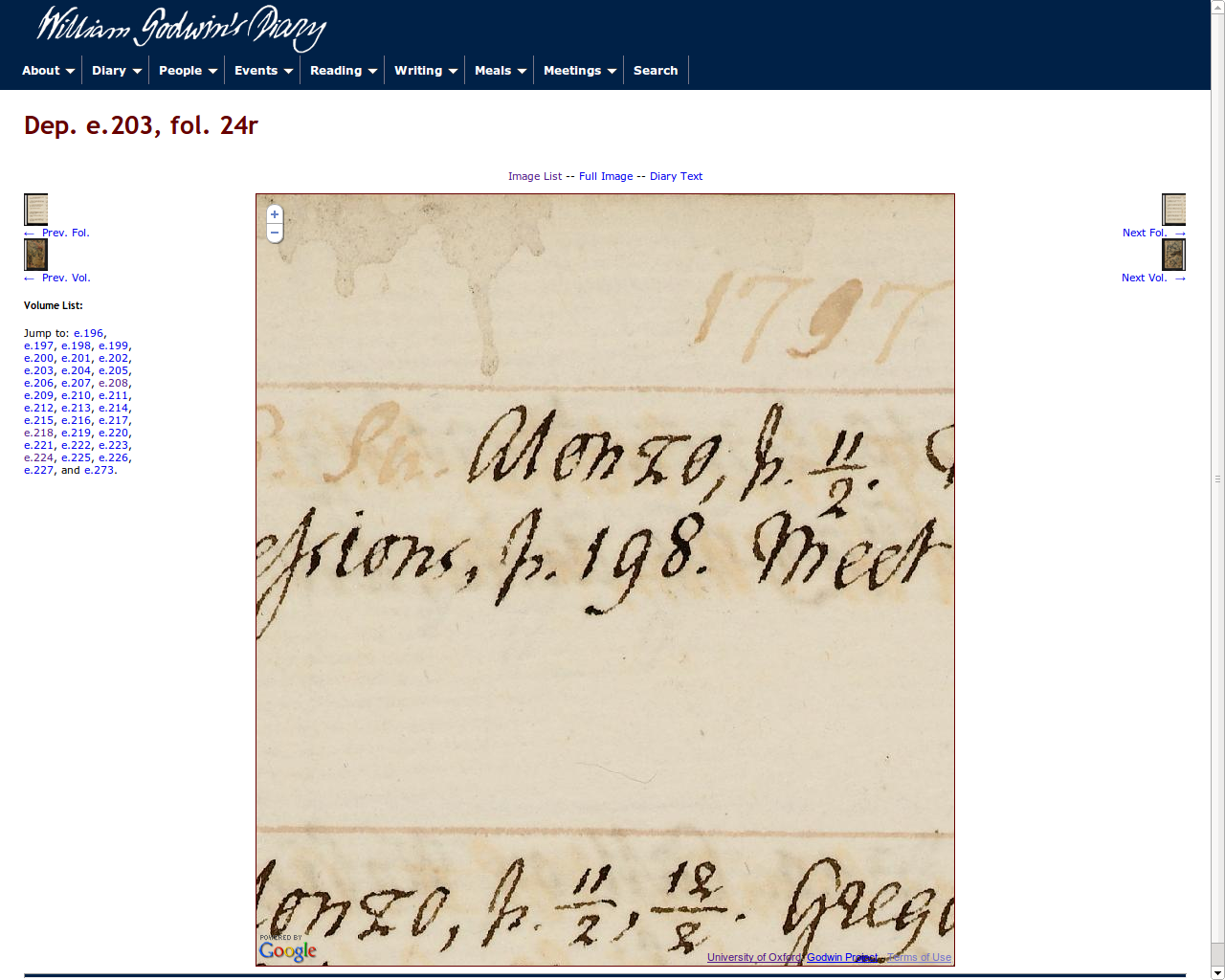





Godwin Diary Project Challenges
- No funding direct to library to support / host, only funding/donations to purchase Abinger Collection
- Not adopted into Bodleian project infrastructure during project development (even though requested)
- Single developer (me) who continued to support on best-effort basis after project ended in 2010
- Developer, PI, Research Associates, etc. all now at other institutions
- Hosted on old virtual machine infrastructure, software needs occasional restart
- Did not use IIIF (or related standards) for image serving and created bespoke pan/zoom image browser using dated Google Maps API
- XML and images available from site, but website code is not in an open repository
LEAP:
Livingstone Online Enhancement
and Access Project
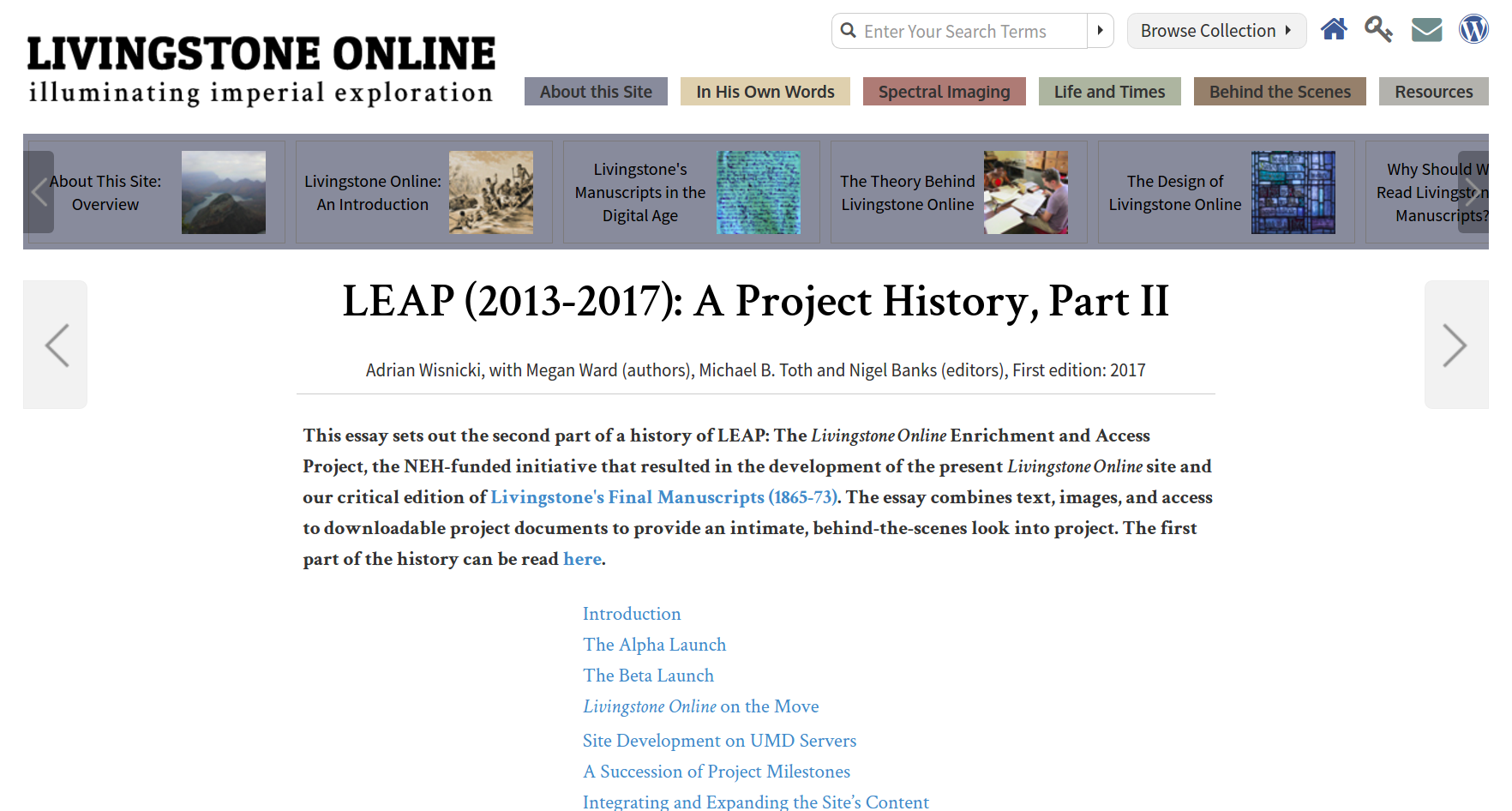
About the LEAP Project
- Project, led by Dr Adrian Wisnicki (UNL), 2013-2017 to:
- re-develop the Livingstone Online website,
- update all underlying materials to TEI P5 XML under a single TEI customization, and
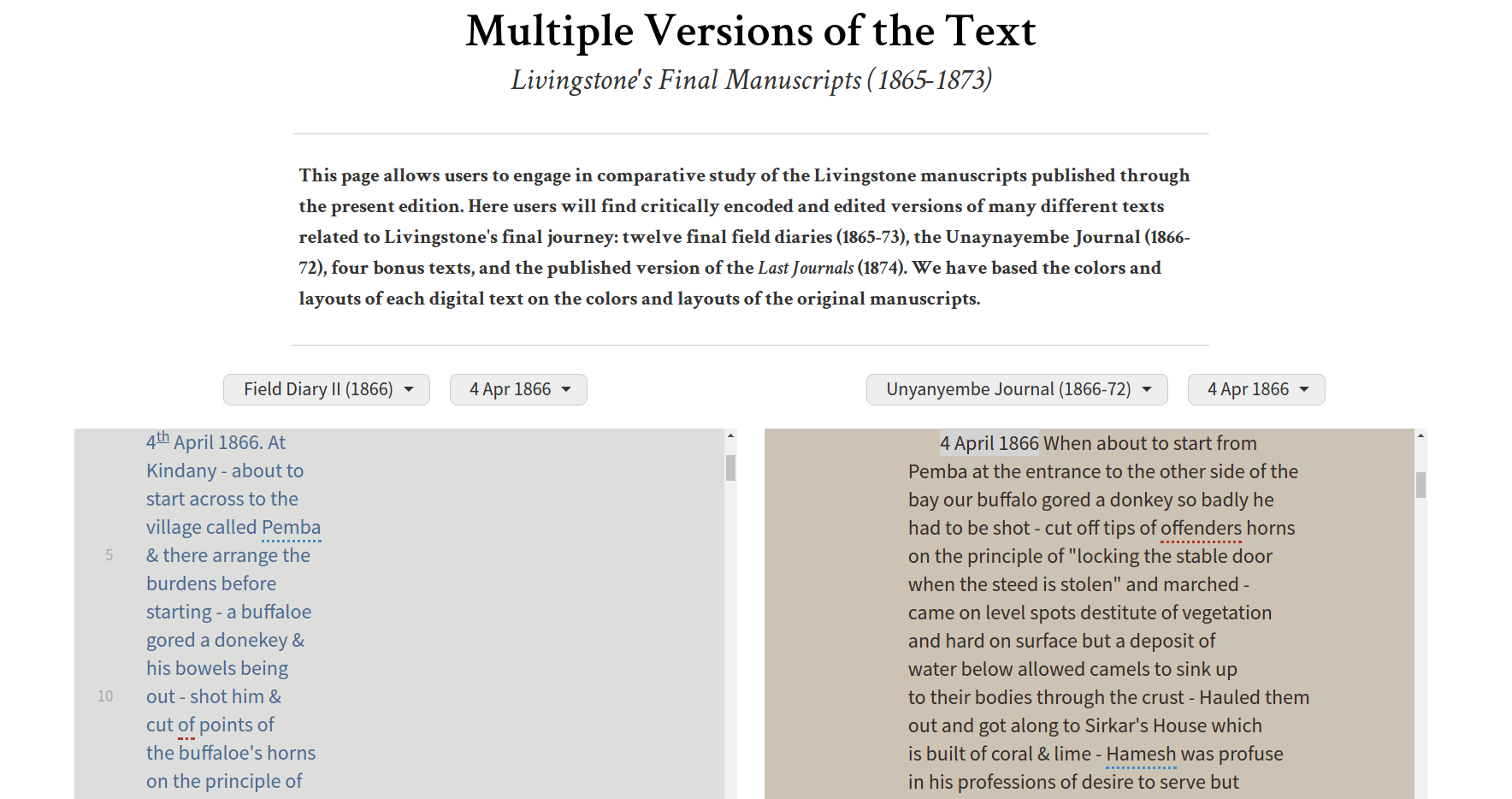
- produce critical edition of David Livingstone’s final manuscripts (1865-73), including multi-witness texts
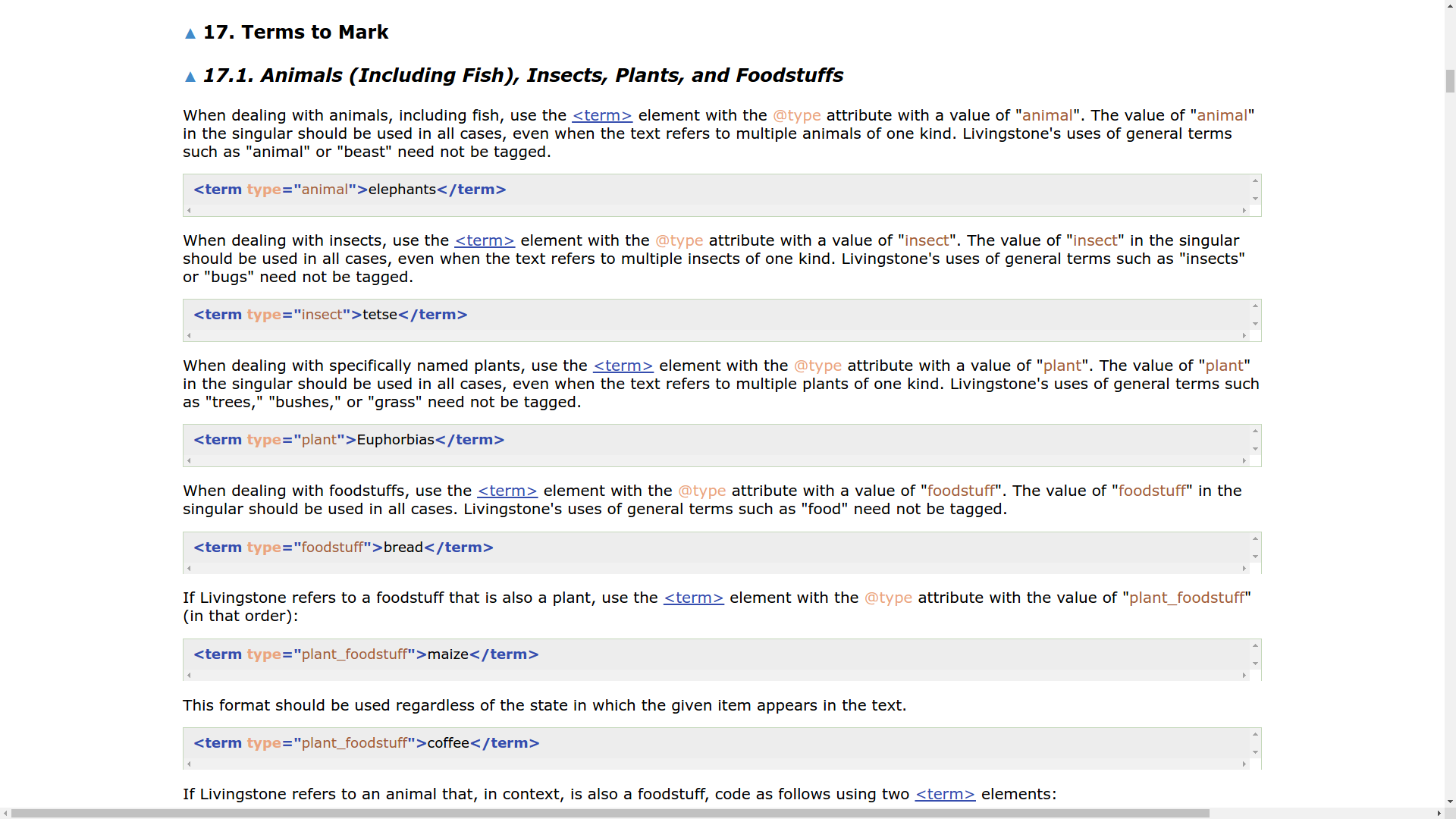
- created detailed project documentation, including full TEI P5 ODD customization, information about funding, including project difficulties and lessons learned
- Multi-spectral imaging of difficult to read texts
- All materials released openly, more than just a digital edition, but an archive of all related material including project materials and reports
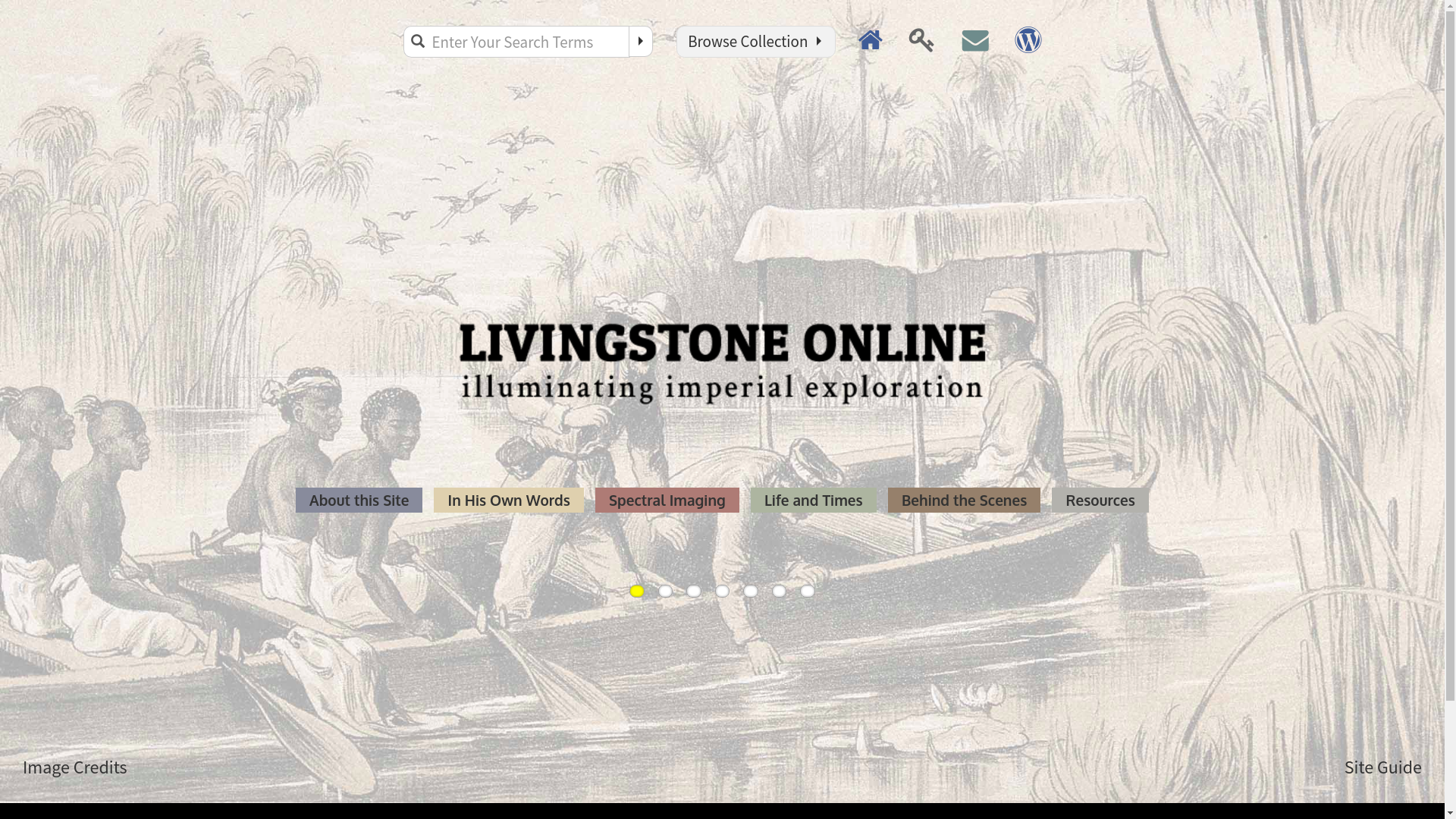


LEAP Project Challenges
- Planned alpha launch (March 2015) plagued with problems (UCLA developers difficulties in implementing in their chosen solution of Islandora in conjunction with Fedora backend)
- Other project partners did additional work before beta launch, development proceeded in halting fashion, lots of missed deadlines, failure of agreed specification
- After beta launch LEAP team made hard decision to ask UCLA to leave the project, negotiated departure over end of 2015
- LEAP reached agreement for hosting with MITH (Maryland Institute for Technology in the Humanities) at University of Maryland and additional developers
- Transfer of project in 2016 only possible because of detailed documentation of materials, project specifications, and project reports mentioning these problems
Some Lessons
(What is the use of failure
if we don't learn something?)

Lessons: Documentation
You never know who will leave/retire/die, create documentation for their replacement:
- Create detailed internal project documentation and share this openly and publicly including documenting all project working practices and assumptions, desired technical specifications, agendas/minutes of meetings
- Always have memorandum of understanding with institutions and other partners (such as developers) with clear milestones and responsibilities on both sides
- Document use of international technical standards and variation from them (e.g. TEI ODD Customization), technical frameworks, software dependencies or anything else a technical replacement might need
Lessons: Working In The Light
Projects tend to hide away their work, not wanting to show work-in-progress until it is finished. It is better in the long run if they work in the light, work openly making as many internal project materials available openly to the greater community. Where feasible minimal requirements should be:
- Always give access to the underlying data
- Pre-license all outputs with open licenses (e.g Creative Commons)
- Provide data and website code in open repositories (e.g. GitHub, GitLab, etc.)
- Work in inter-institutional collaborative manner, not relying on single institution’s policies but joint enforceable agreements
- Give a method for community to provide feedback, improvements, or make derivative works
Lessons: Technical Infrastructure
- Ensure technical decisions use open international standards and popular community supported open source software
- Base development on open documented API (application program interface)
- Avoid implementing quick workarounds (or if you must, document them in detail)
- Have multiple technical partners overseeing / validating each others work through review of pull-requests, regular reporting
- Integrate into institutional (or multi-institutional) infrastructural support so servers will go on running, be updated, for many years
- If feasible, research software developers should be partners in project, not just solution providers
Dr James Cummings
Digital Editing:
text encoding, software,
and the risks of failure
James.Cummings@newcastle.ac.uk
@jamescummings
CC+BY (press space to cycle through slides)
ATNU:
Animating Text
Newcastle University
(A new inter-disciplinary project hoping to learn from some of these challenges)
About the ATNU Project
- ATNU is a new project that has just started at Newcastle University trying to learn from some of these mistakes
- It is exploring new frontiers at the cross-roads between traditional scholarly textual editing, digital editing, digital humanities and computer science
- It is involving computer scientists from the very beginning as full partners in the project, not just solution providers.
- It is running several pilot projects across multiple departments and is just as interested in solutions and methodologies that do not work as those which do work.

ATNU Pilots
- Manuscript and Print:
- Digital Edition of the Sarum Hymnal
- Visualization over time of a MS notebook (Shelley)
- Performance:
- ‘Polyphonic Player’
- Early Modern Ballot, with interactive animation
- Text to speech for Early Modern texts
- Translation:
- Differences between Early Modern translations
- Social translation research
- Translation networks



Digital Editing: text encoding, software, and the risks of failure
By James Cummings
Digital Editing: text encoding, software, and the risks of failure
"Digital Editing: text encoding, software, and the risks of failure" A talk for the Brontë Editing Colloquium, Durham University, 12-14 June 2018; given 14 June 2018.




