High performance MySQL (draft)
By James Harvey
Database performance is an issue that creeps up on you
Early-stage startup problems
- Finding customers
- Rapid feature development
- Iterating to find product-market fit
- Fixing bugs and bad product decisions
Scaling startup problems
- All that stuff from before
- Heaps of customers
- A bunch of really big customers
- Even bigger customers coming down the pipeline
- Your database servers go to 100% CPU randomly
- You start getting weird errors from the database
How did this emerge for us?
Errors, slow queries and app performance


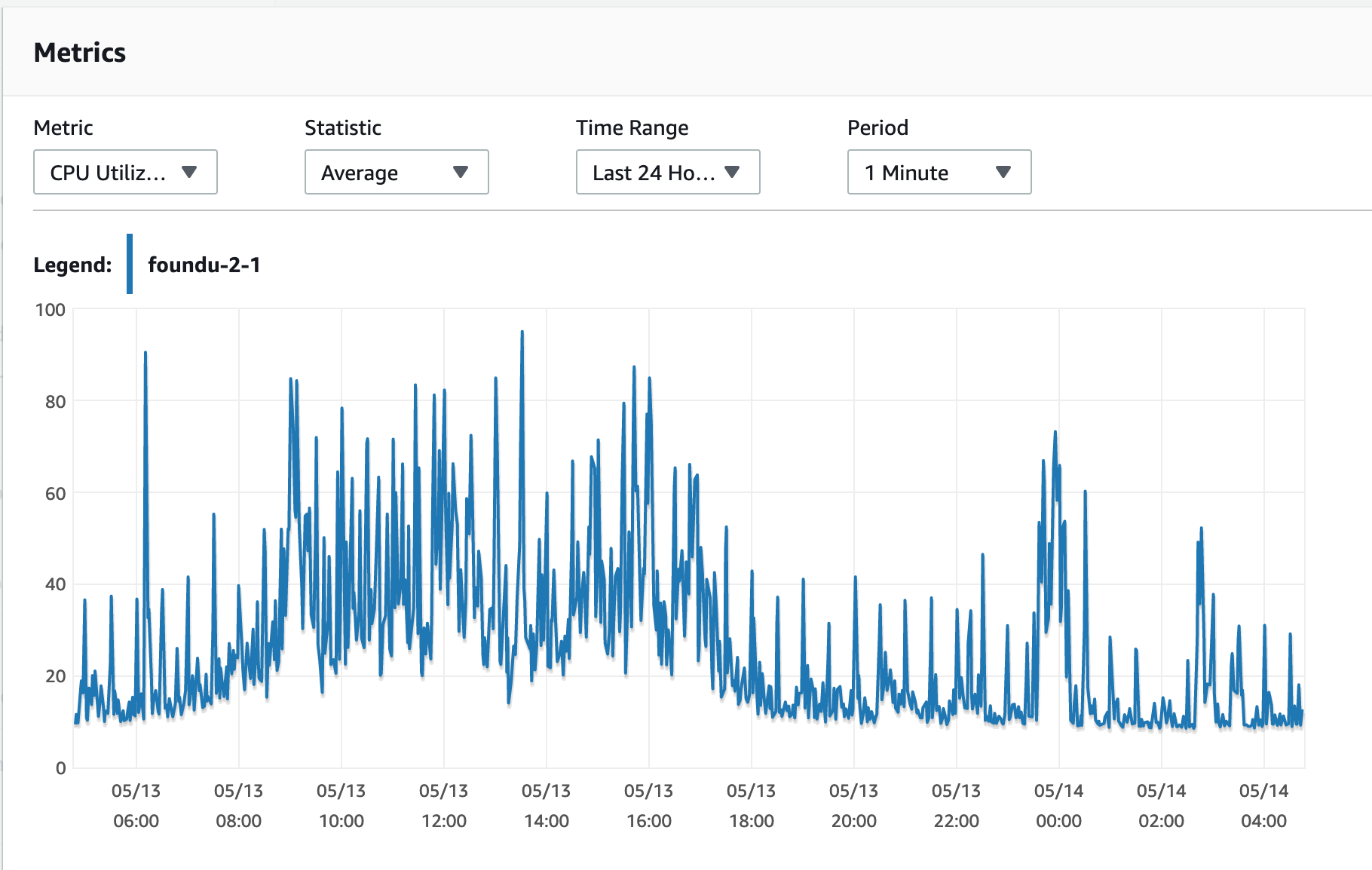







And helpful informative bug reports
Okay let's take a step back
You will make mistakes in your database design
You will think you know how MySQL will behave at scale and you will be wrong
It is a good thing when you start hitting scaling issues in your app because it means people are actually using it!
Back to basics
- Optimization vs scaling
- Database design
- How indexes work
- How transactions work
- F***ing deadlocks
- Explain
Optimization
Making maximum use of each MySQL node
- Fast queries
- Quick transactions
- No f***ing deadlocks
- Avoiding N+1 queries
Scaling
Adding more MySQL nodes
- Adding read replicas
- Splitting out databases across clusters
- Sharding
Database design - Integers
| Column | Bytes | Signed | Unsigned |
|---|---|---|---|
| TINYINT | 1 | -128 to 128 | 0 to 256 |
| SMALLINT | 2 | -32,768 to 32,767 | 0 to 65,535 |
| MEDIUMINT | 3 | -8,388,608 to 8,388,607 | 0 to 16,777,215 |
| INT | 4 | -2,147,483,648 to 2,147,483,647 | 0 to 4,294,967,295 |
| BIGINT | 8 | REALLY BIG | REALLY BIG |
- Unsign if you don't need negative numbers
- Don't use char/var_char for numbers if you can use an integer
- Pick the smallest size that makes sense but give yourself some headroom if you think you need it
- Int(11) is for MySQL tooling, it does not affect storage or performance
Database design - Floats and Decimal
TODO
Database design -
Varchar vs Char
TODO
Database design -
Text and Blobs
TODO
Database design -
Bits and Flags
TODO
Database design -
Ideas to try
- Smaller is usually better
- Move text fields to alternative storage (eg. AWS S3)
- JSON storage is likely an anti-pattern
- Move out optional data into sub tables to reduce storage waste
- Checksum data as a key
- Keep the maximum joins in queries under ~15
Indexes and Keys
Clustered Indexes
- A clustered index is how the data is stored on disk
- MySQL/InnoDB uses clustered indexes for primary keys
- If a primary key does not exist, MySQL will create one behind the scenes
- Never make a primary key nullable
- InnoDB uses a B+ Tree not a B Tree
- It is best to use ordered data as PK
Disk Blocks
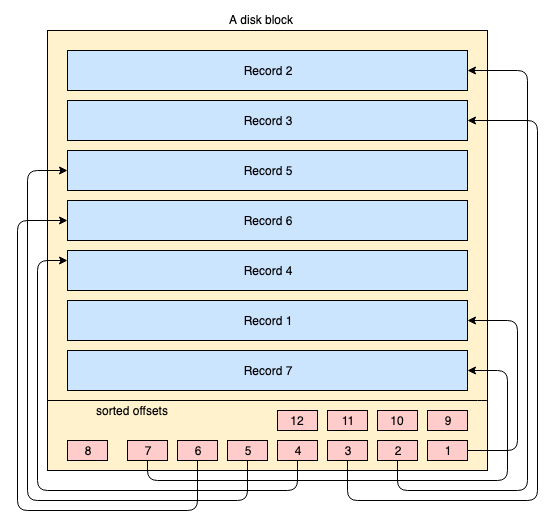
- Disk Blocks are the Leaf Nodes of the B+ Tree
- Data records are stored in any order
- A small list of pointers are maintained
- If an update is too big, a new record is added and the pointer is updated
- Storage is mostly handled by the Operating System
Secondary Indexes
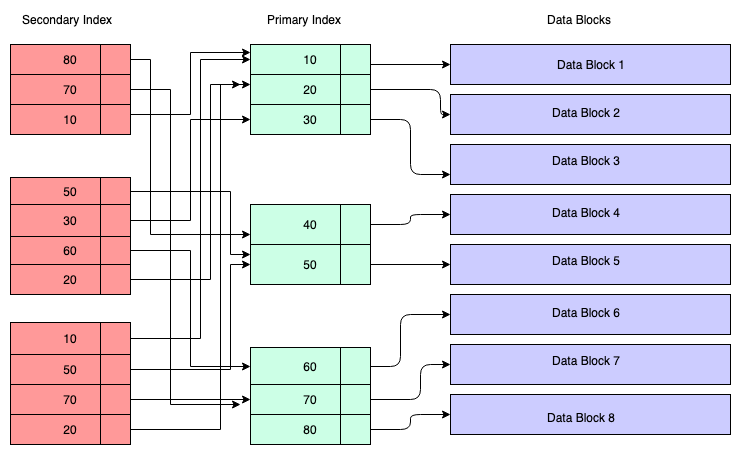
Secondary Indexes
- Secondary indexes reference the primary index
- If the data exists in the secondary index MySQL doesn't need to fetch data from the data block
- The bigger the primary key, the bigger the index size
- Data modifications will update the indexes as well
Multiple Secondary Indexes
- Index fields are concatenated together to form the index value
- Order of the indexed fields is important
- Part of the index can be used depending on the order
MySQL Explain

| Field | Meaning |
|---|---|
| type | Worst to best - ALL, index, range, ref, eq_ref, const, system |
| possible keys | The keys that could be used |
| key | The key that was used |
| rows | Number of rows that had to scanned |
| extra | More info |
Query optimisation tips
- Select only the data you need. If it's all in the index, MySQL does not need to go to the Disk Block
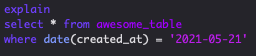
- Avoid function calls in queries on indexed columns. Eg. use date_field > 'date time'
instead of date(date_field) > 'date' - When performing joins, identify the best entry table that filters the most data
- Be considered when adding indexes, they are easy to add and hard to take away
- Continuously check the slow query log for new queries that have become problems
Transactions and Deadlocks
- Used to ensure a change completely works or completely fails
- All inserts, updates and deletes use transactions
- InnoDB has a solid transaction system
- Table locking and row locking
ACID compliance
-
Atomicity - A single logical unit of work
-
Consistency - DB moves from one consistent state to the next
-
Isolation - The results of a transaction are usually invisible to other transactions until the transaction is complete
-
Durability - Once committed, a transaction’s changes are permanent
Isolation Levels
- Read uncommitted - Bad
- Read committed - Non-repeatable read
- Repeatable Read - Can have phantom reads. (InnoDB uses this but tries to avoid phantom reads)
- Serializable - The highest level of isolation, locks reads though
How transactions work
- TODO
Lock timeouts
- A transaction was held open too long
F***ing deadlocks
- Two transactions competed for changes where InnoDB cannot resolve them both

Tips
- Keep transactions as fast as possible
- Ensure update/delete queries are optimized
- Don't mix storage engines and transactions
N+1 Queries
- TODO
References
(Draftt) High performance MySQL
By James Harvey


