Introduction to Data Management with iRODS
Jason Coposky
@jason_coposky
Executive Director, iRODS Consortium
Introduction to Data Management with iRODS

Rm 3211, Engineering II
NC State University
Raleigh, North Carolina
Motivation
- Many petabytes of data is being constantly generated by every type of organization around the world
- Infrastructure is constantly changing
- Science is increasingly driven by data and software
- Reproducible scientific results is critical to progress
- Collaboration within and across organizational boundaries accelerates discovery
- Necessary to demonstrate compliance to security standards
What is the system and model to solve these problems in an automated way?

Motivation
A Definition of Data Management
"The development, execution and supervision of plans, policies, programs and practices that control, protect, deliver and enhance the value of data and information assets."
Organizations need a future-proof solution to managing data and its surrounding infrastructure
What is iRODS
Distributed - runs on a laptop, a cluster, on premises or geographically distributed
Open Source - BSD-3 Licensed, install it today and try before you buy
Metadata Driven & Data Centric - Insulate both your users and your data from your infrastructure
iRODS as the Integration Layer
Creating the Machine
What are the necessary components to build such a system?
- Where do we maintain state?
- How do we handle command and control?
- How do we manage data movement?
- What guarantees can be made regarding semantics?
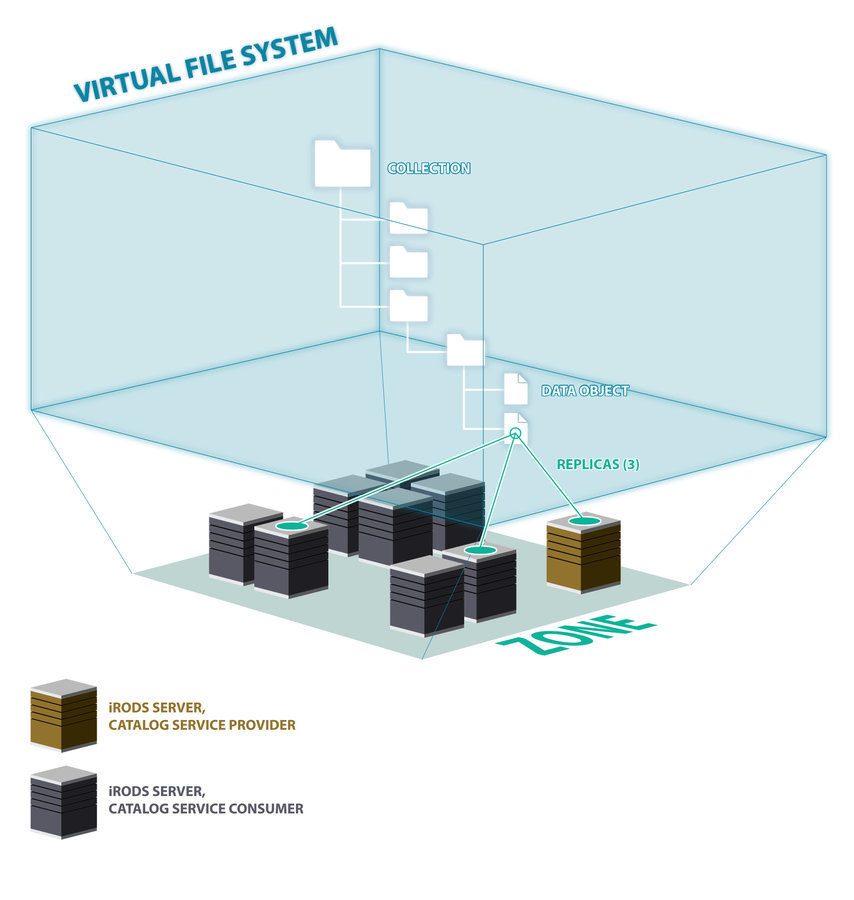
iRODS Architecture
- Metadata Catalog - where we write everything down
- Catalog Service Provider - provides access to the Catalog
- Catalog Service Consumer - distributed nodes to provide access to storage and other resources
iRODS is ultimately a Catalog and an RPC API
Catalog Service Consumers
Servers which provide access to storage resources
-
Connect to the Catalog Service Provider for
- resource configuration
- authentication
- system metadata
- user assigned metadata
- Provide scalable access to iRODS services
- May be geographically distributed
- May have an arbitrary number of resources attached
Catalog Service Provider
Same capabilities as the Consumer with the addition of a database plugin
- May serve storage capabilities
- Provides access to the metadata catalog
- May be placed in a High Availability configuration for failover and load balancing
Metadata Catalog
-
Relational Database
- Postgres, MySql, Oracle, Cockroach DB
-
Single source of truth for the Zone
- Holds users, groups, resources, system metadata, user metadata
- Co-resident with iRODS or a clustered server farm
- Referenced by a database plugin implemented with odbc
What are some limitations of this design?
Limitations of System Design
- Catalog Service Provider represents a single point of failure
- The Catalog may be corrupted or fail entirely
- Data may be made unavailable by a server failure
- Storage may be corrupted or fail entirely
Addressing System Limitations
- Catalog Service Provider represents a single point of failure
- Cluster behind a Proxy
- The Catalog may be corrupted or fail entirely
- Cluster with replication or multi-master
- Data may be made unavailable by a server failure
- Provide replication of data for durability
- Storage may be corrupted or fail entirely
- Replication and Backup strategies
What to consider in an iRODS deployment
Things to consider
- Number of users and expected simultaneous connections
- Expected ingest rate
- Sizes of files
- many small
- Partial read / write vs whole file usage
- Replication for durability
- Replication for locality of reference
- Load balancing vs High Availability
iRODS will run on a laptop or a rack of servers
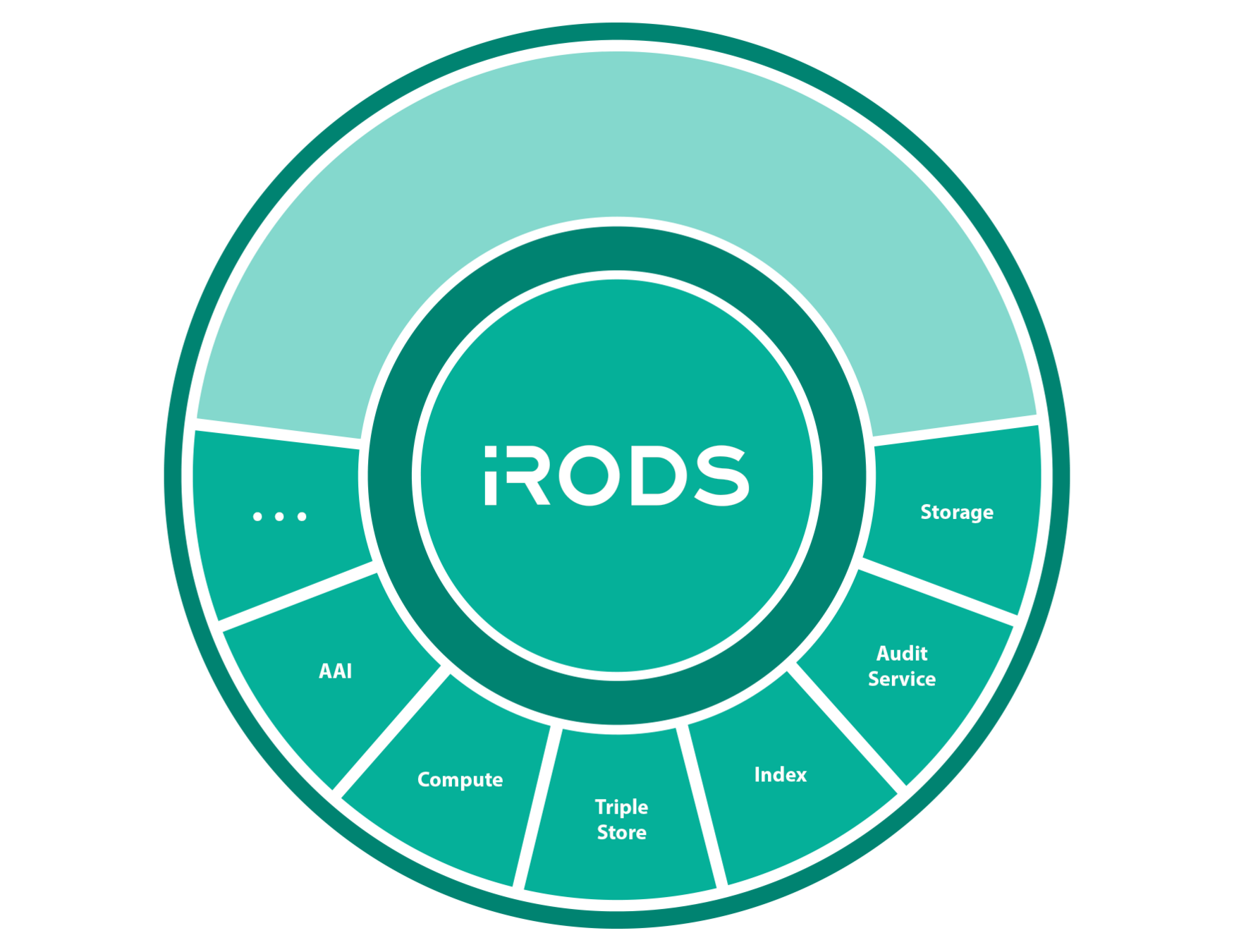
iRODS Core Competencies
The underlying technology categorized into four areas




Data Virtualization
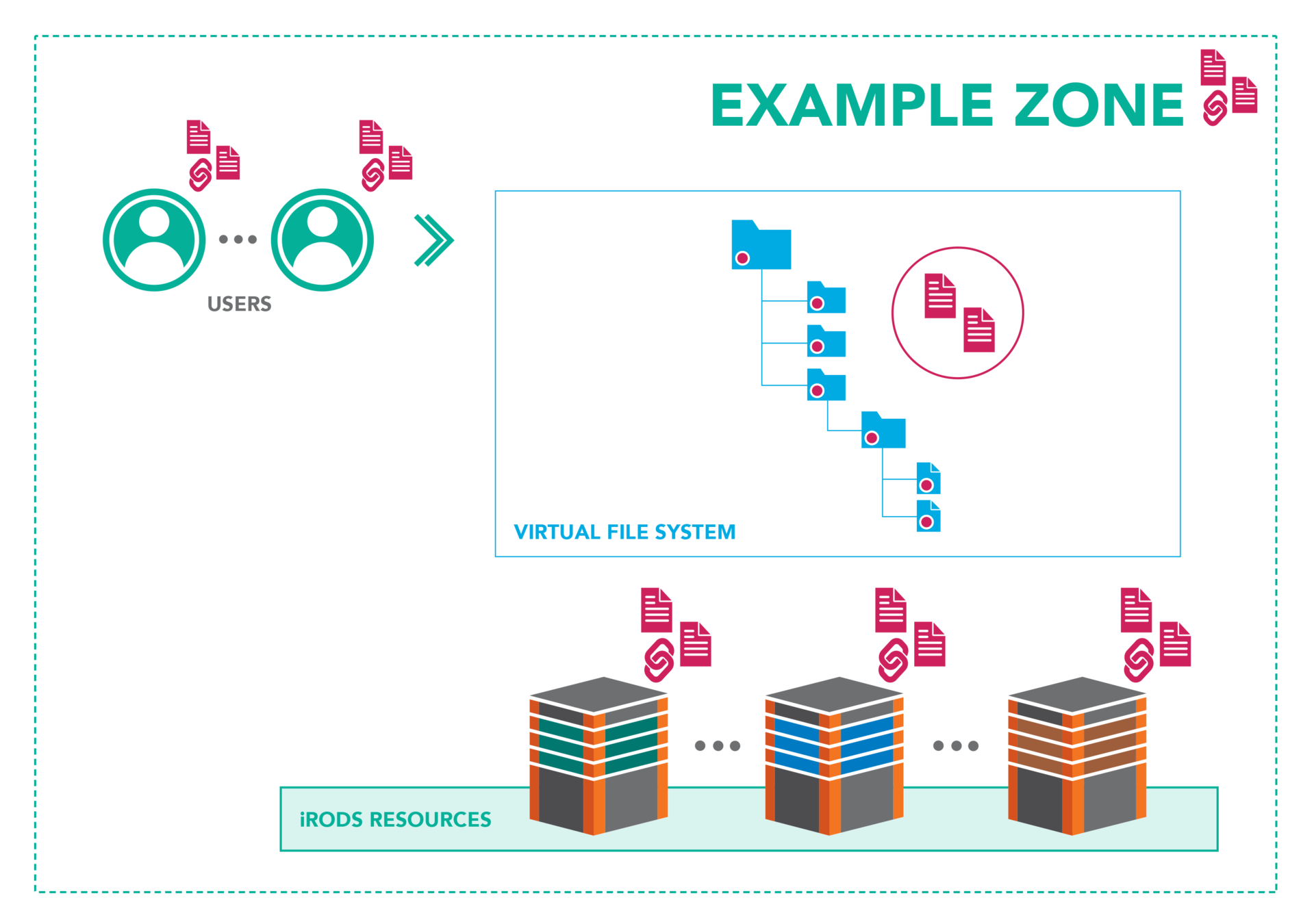
Combine various distributed storage technologies into a Unified Namespace
- Existing file systems
- Cloud storage
- On premises object storage
- Archival storage systems
iRODS provides a logical view into the complex physical representation of your data, distributed geographically, and at scale.
Projection of the Physical into the Logical
Logical Path
Physical Path(s)
Data Discovery
Attach metadata to any first class entity within the iRODS Zone
- Data Objects
- Collections
- Users
- Storage Resources
- The Namespace
iRODS provides automated and user-provided metadata which makes your data and infrastructure more discoverable, operational and valuable.
Metadata Everywhere
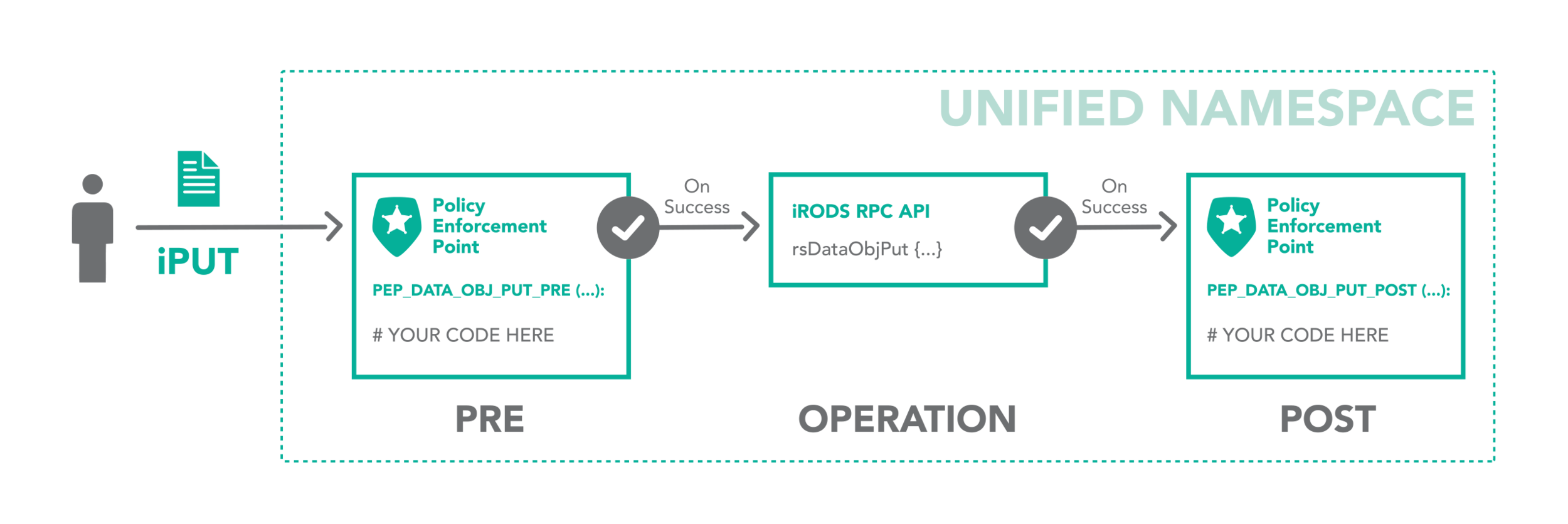
Workflow Automation
Integrated scripting language which is triggered by any operation within the framework
- Authentication
- Storage Access
- Database Interaction
- Network Activity
- Extensible RPC API
The iRODS rule engine provides the ability to capture real world policy as computer actionable rules which may allow, deny, or add context to operations within the system.
Dynamic Policy Enforcement
- restrict access
- log for audit and reporting
- provide additional context
- send a notification
The iRODS rule may:
Dynamic Policy Enforcement
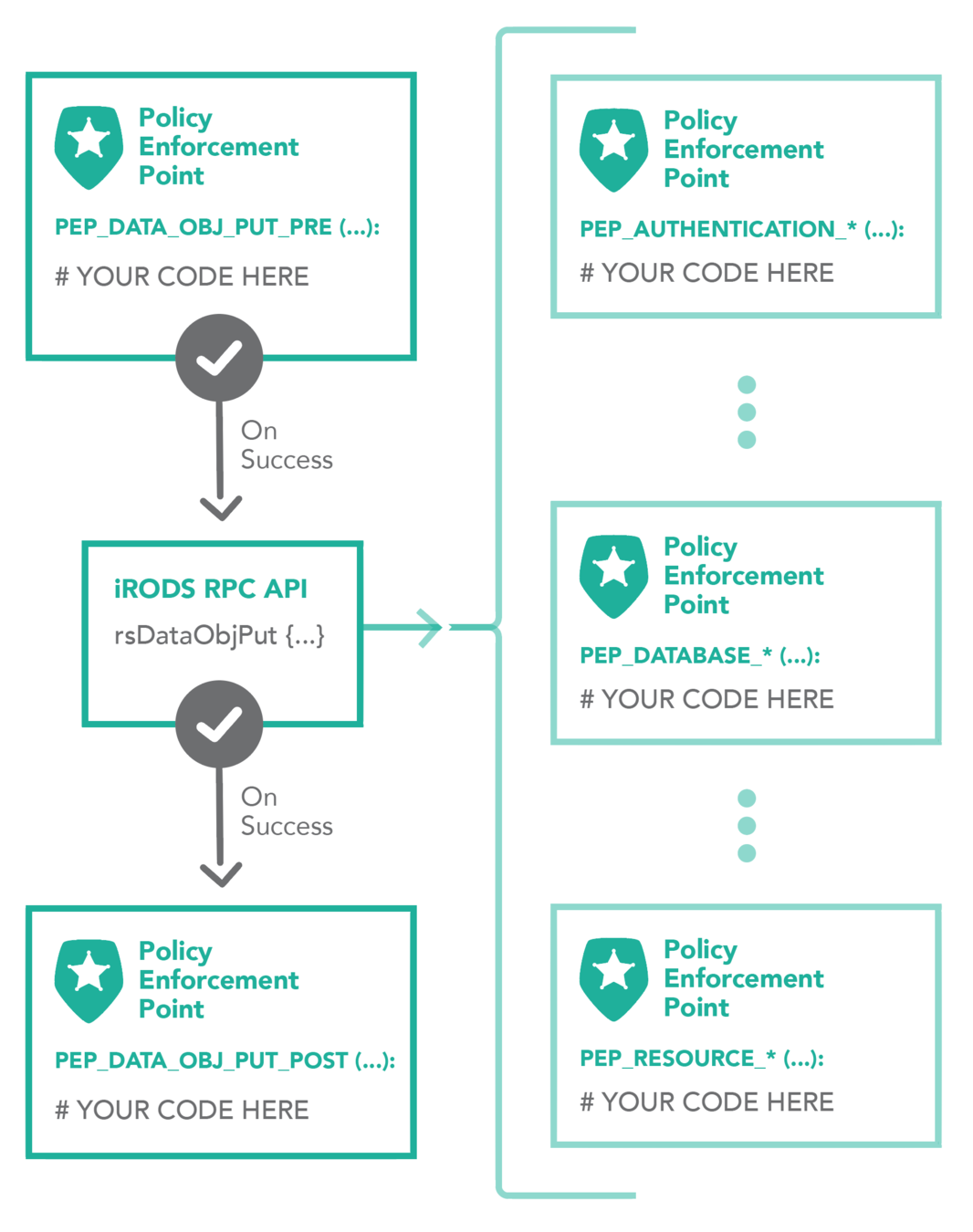
A single API call expands to many plugin operations all of which may invoke policy enforcement
- Authentication
- Database
- Storage
- Network
- Rule Engine
- Microservice
- RPC API
Plugin Interfaces:
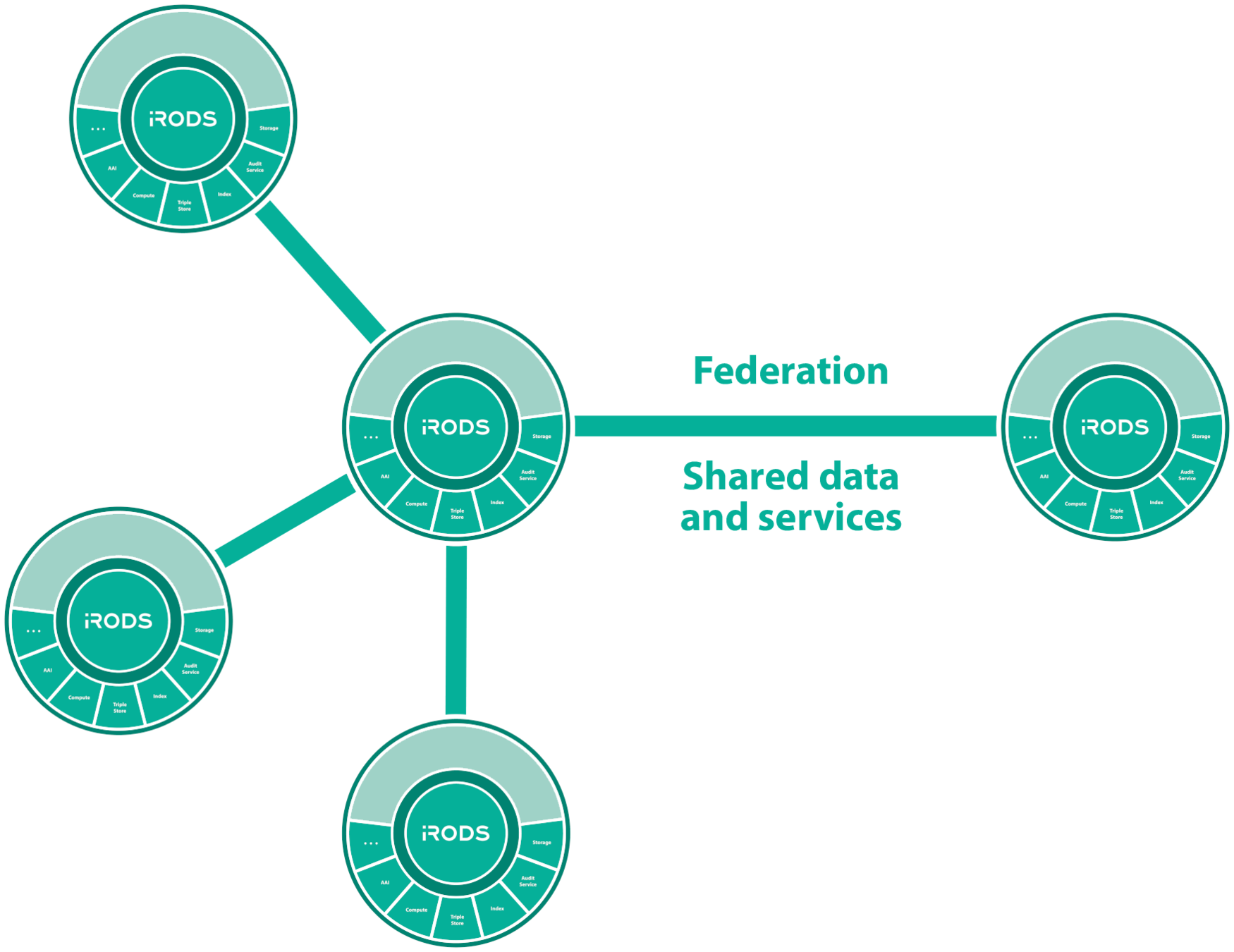
Secure Collaboration
iRODS allows for collaboration across administrative boundaries after deployment
- No need for common infrastructure
- No need for shared funding
- Affords temporary collaborations
iRODS provides the ability to federate namespaces across organizations without pre-coordinated funding or effort.
iRODS as a Service Interface
Federation - Shared Data and Services
Ingest to Institutional repository
As data matures and reaches a broader community, data management policy must also evolve to meet these additional requirements.
iRODS Capabilities









Automated Ingest - Landing Zone
Automated Ingest - Filesystem Scanning
Storage Tiering
Indexing
Publication
Provenance
Deployment Patterns

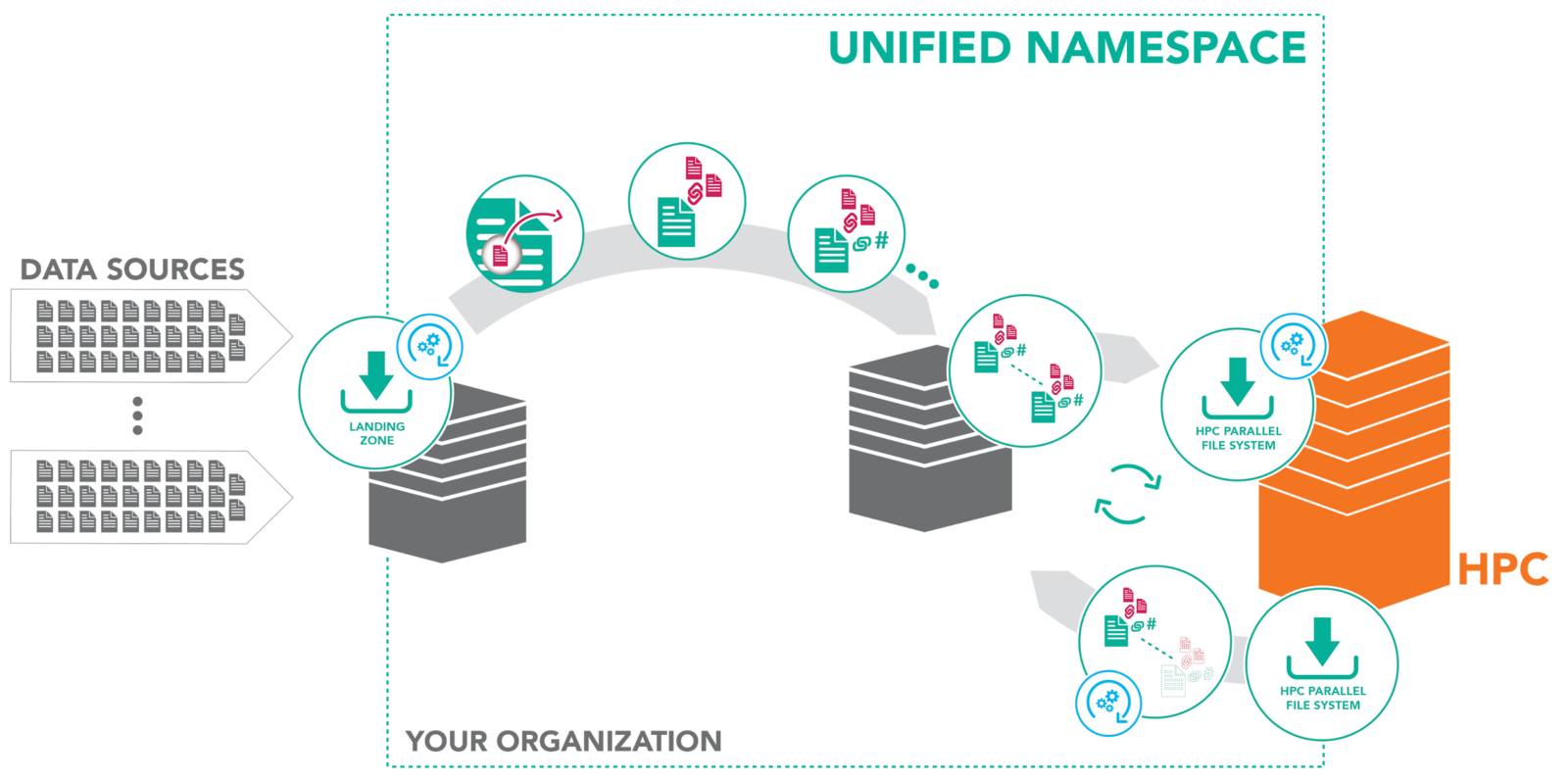
Data to Compute
Compute to Data
Filesystem Synchronization
Data Transfer Node
Filesystem Synchronization
Data to Compute
Compute to Data
Data Transfer Node
The Data Management Model

Use Cases
iRODS
The Wellcome Sanger Institute

Sanger - Replication
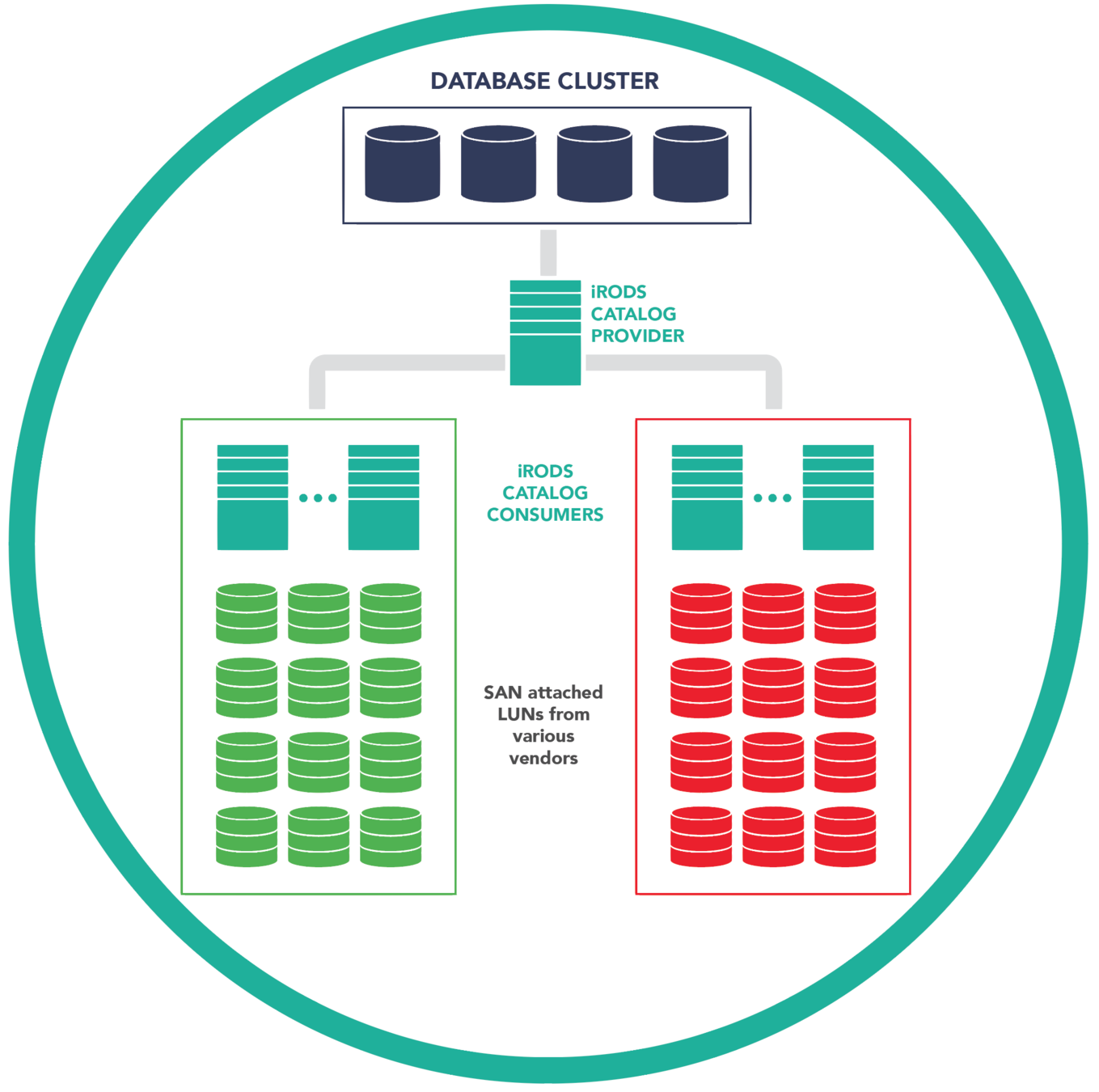
- Data preferentially placed on resource servers in the green data center (fallback to red)
- Data replicated to the other room.
- Checksums applied
- Green and red centers both used for read access.
Sanger - Metadata
attribute: library
attribute: total_reads
attribute: type
attribute: lane
attribute: is_paired_read
attribute: study_accession_number
attribute: library_id
attribute: sample_accession_number
attribute: sample_public_name
attribute: manual_qc
attribute: tag
attribute: sample_common_name
attribute: md5
attribute: tag_index
attribute: study_title
attribute: study_id
attribute: reference
attribute: sample
attribute: target
attribute: sample_id
attribute: id_run
attribute: study
attribute: alignment
- Example metadata attributes
- Users query and access data from local compute clusters
- Users access iRODS locally via the command line interface
Sanger - Federation

University College London
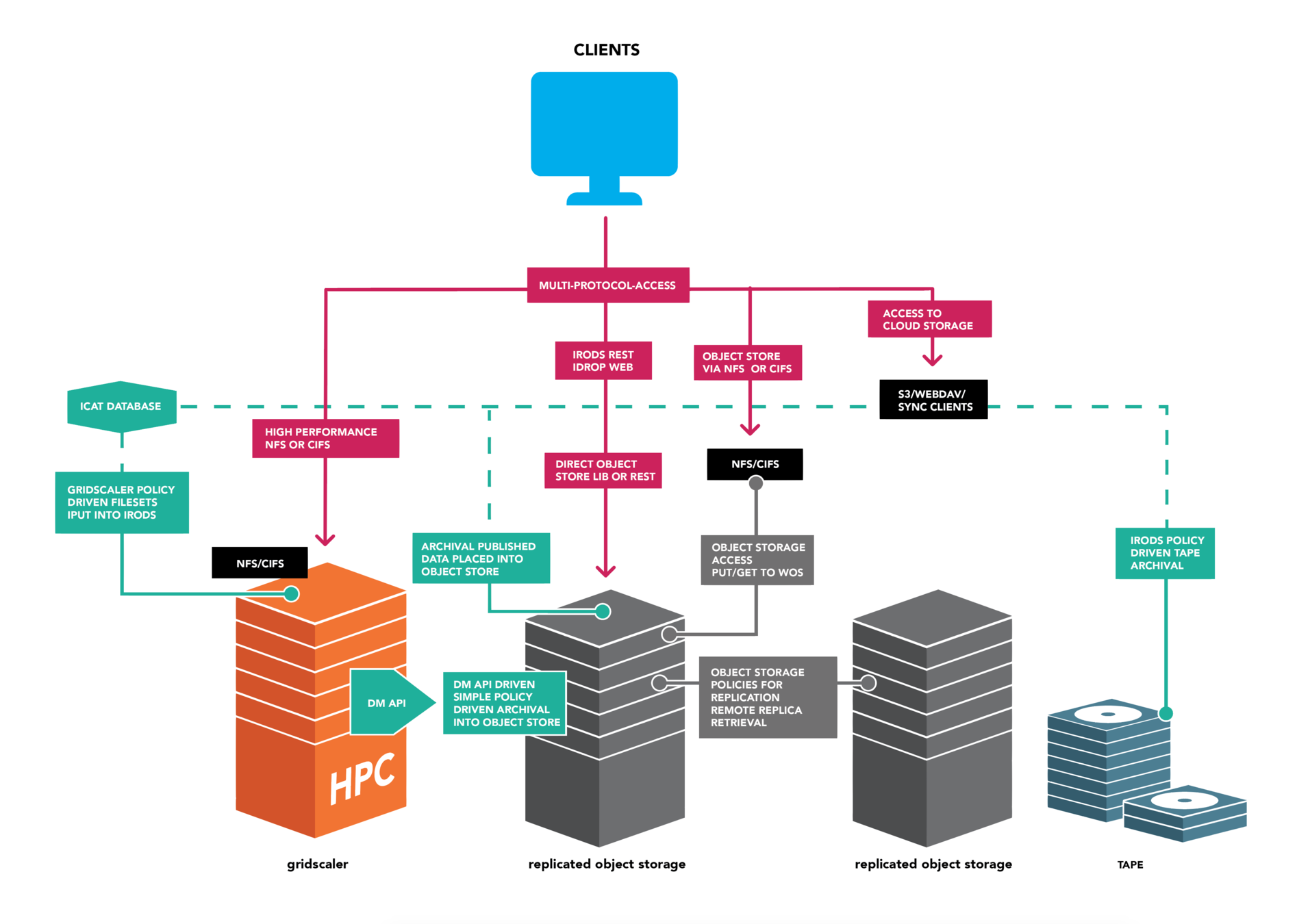
- UK sponsored research requirements: last date of access request plus 10 years
- iRODS tiers data across storage technologies
- Enables federated access from other centers
SURF Scale Out Pilot


University Zone
Catalog
University Zone
Catalog
Server Hosting Environment
Resource Server
Resource Server
Tape Archive
Disk Storage
Object Storage
SURF EUDAT CDI
External Community Zones
Catalog
Zone
Catalog
Local Storage
CXFS
Tape Library
EUDAT University Zone
Catalog
EUDAT University Zone
Catalog
B2SAFE iRODS Federation
EUDAT Centers
iRODS Federation
ARCHIVE
GridFTP Data Movement
Roadmap
iRODS Software
The Roadmap
- iRODS 4.3
- Packaged iRODS Capabilities
- Multipart Transfer
- Cacheless Object Storage
- Query Arrow
- Metadata Templates
- Filesystem Integration
The Roadmap - iRODS 4.3
- Hardening Release
- Logging
- iRODS Monitor
- Delegate Checksum to Storage Plugins
Multipart Transfer

Provide reliable transfer with restart - object parts tracked in the catalog
Later versions will provide fast, first class access to object storage
iRODS 4.2 and Beyond - The Scatter

Next Generation Query Interface

iRODS 4.3 and Beyond - The Gather

Shared Data - Shared Infrastructure

Metadata Templates
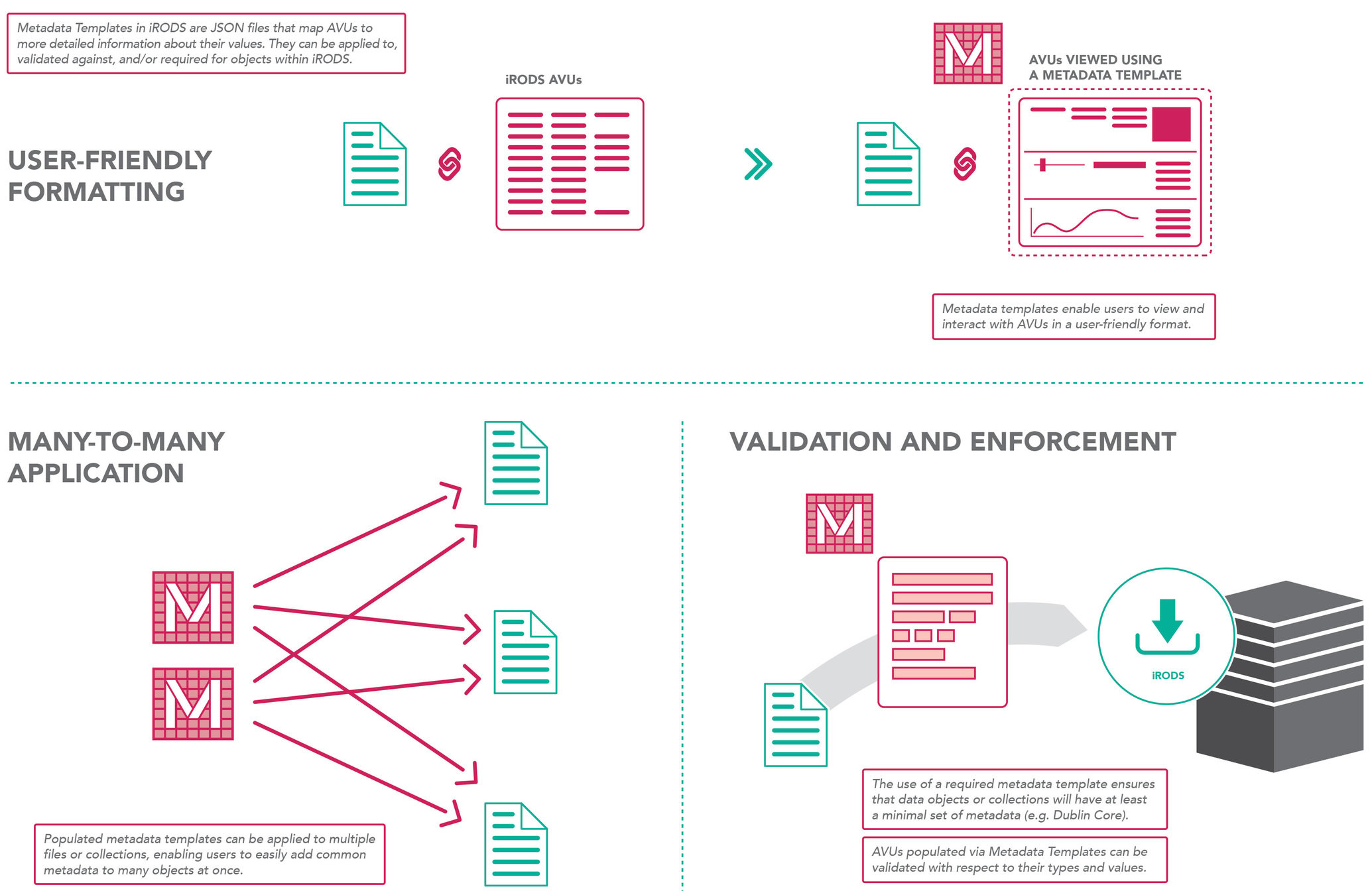
Business Model
iRODS Consortium
The iRODS Consortium
Our Mission
- Write Good Software
- Grow the Community
- Show Value to our Membership
Why Open Source
- Transparency
- Quality
- Persistence
- Vendor Neutrality
- Customization
- Community
- Try before you buy
Our Membership










Our Business Model
Consortium Membership
- Participate in roadmap development
- Participate in consortium governance
- Direct support from the team
- Tier 3 support agreements
- Discount for support agreements
Our Business Model
Service & Support Contracts
- Billed hourly
- Implement Proofs of Concept
- Custom rule and plugin development
- Expand to new use cases
- Discounted rate for consortium members
Membership Committees
Technology Working Group
- Monthly web conferences
- Build iRODS Roadmap
- Propose new technology direction
- Propose inclusion of new software
- Propose new working groups
Membership Committees
Planning Committee
- Monthly web conferences
- Discuss consortium policy and business practices
- Propose conferences and workshops
- Vote on inclusion of new software
- Vote on roadmap
Membership Committees
Executive Board
- Meets twice yearly
- Votes on consortium budget and bylaw changes
- Determines the thematic priorities of the consortium
Additional working groups are formed as required
Our Consortium Participation

Introduction to Data Management with iRODS
By jason coposky
Introduction to Data Management with iRODS
An overview of motivations for data management, iRODS, Patterns, and Use Cases



