Machine Learning
程式碼集中營
-
人工智慧?
-
機器學習?
-
神經網路?
人工智慧:人類的目標
我們希望電腦可以和人類一樣,解決一些需要智慧的問題!
e.g. 影像辨識、聊天機器人、下圍棋...
如何定義問題?
影像辨識:

: " 貓 "

: " 軟軟 "
人工智慧:一個函數
相信大家都知道函數是什麼(?
我們希望人工智慧是這麼一個函數,當我們丟給它一些輸入,能夠輸出我們想要看到的結果!
這樣,我們就能稱呼它為"有智慧"!
f(
) = ``貓"
f(
) = ``軟軟"
函數怎麼找?
人類告訴他函數應該長什麼樣子?
- 問題可能過於複雜,無法考慮到所有情況
- 停留在人類的智慧,代表機器不可能超越人
讓機器自己找到這個函數!
機器學習。
機器學習:達成目標的方法
我們希望讓機器自己找到這個函數!
藉由告訴機器輸入與期望的輸出,期待它可以融會貫通(?
當看到新的東西時可以判斷得出來!
當機器看過一堆照片
再塞給他一張他沒看過的

希望它辨認的出來

它是軟軟


機器學習:達成目標的方法
如何學習?
大致分為三步驟。
定義函數的集合
評估函數的好壞
找到最好的函數
就好像把大象放進冰箱...

機器學習:達成目標的方法
達成這三個步驟的方法有很多種:
- 線性迴歸
- k-nearest neighbor
- 支持向量機
- 神經網路
今天主要介紹人工神經網路,同時也是現今最主流、變化最多的方式。
人工神經網路
人工神經網路?
大腦裡有許多神經元,連接在一起形成神經網路。
人工神經網路,顧名思義,就是人建出一個類似人腦的結構,想要電腦模擬人類大腦的運作。
想一想:大腦是如何運作的?

訊息接收
訊息處理
訊息輸出
基本單位:神經元
對人工神經網路來說,神經元就是一個將輸入進行線性組合再輸出的東東(?
output=\sigma(\sum{w_{i}x_{i}}+b)
w:權重(weight):這個輸入分量有多重要
b:偏值(bias):整個輸出分量有多重要
:激活函數
\sigma
舉例
output=\sigma(\sum{w_{i}x_{i}}+b)
x_1=2
x_2=-1
x_3=3
w_1=0.7
w_2=0.1
w_3=-0.2
0.9
b=0.2
通過激活函數後輸出
激活函數
可以弄出非線性的組合。

其中ReLU是最常使用的激活函數。
據說是因為它和生物的神經元運作概念類似(?
當你將許多神經元串在一塊...
x_1=2
x_2=-1
x_3=3
0.7
0.1
-0.2
0.9
0.2
\sigma(x)
每一個神經元都有自己的權重和偏值......
0.2
-0.3
0.5
0.2
-2
\sigma(x)
當你將許多神經元串在一塊...
人工神經網路!
又稱為全連結神經網路、神經網路。

深度神經網路?
很深的神經網路。
要多深其實沒有統一的定義,通常隱藏層有三層或以上就可以稱為深度神經網路。
為什麼深會比較好?
輸入層
原始像素
隱藏層一
直線、條紋
隱藏層二
一些特徵
隱藏層三
一張人臉
輸出層
軟軟
| 0 | 0.1 | 0.7 |
| 0.6 | 0.4 | 0.5 |
| 0.2 | 0.3 | 0.9 |
想像成某種分工的模式(?
回到剛剛的問題
剛剛不是有提到,機器學習大致分為三步驟嗎?
定義函數的集合
評估函數的好壞
找到最好的函數
使用人工神經網路,要如何做到這三步驟?
Step 1:定義函數的集合
當我們把神經網路的架構建好後,所有的權重與偏值都可以自由調整!
也就是說,每一組權重與偏值都代表著一個函數,所有可能的權重與偏值的組合,就是函數的集合。
可以表示的函數種類非常的多:
- 成千上萬個參數
- 並沒有對原輸入進行太多的假設或預處理
(例如圖像辨識的輸入即是原像素)
Step 2:評估函數的好壞
好壞用什麼標準評估?
- 當然是跑出來的正確率囉!
- 損失函數(Loss function)
如: mean_square error, cross entropy
L(x)=\frac{1}{n} \sum (f(x)_i-y_i)^2
L(x)=-\sum y_i\, ln(f(x)_i)
0
1
2
3
4
0
0.1
0.2
0
0.7
0
0
0
0
1
Step 3:找到最好的函數
不過只知道正確率還不夠,我們還需要知道如何調整參數(權重和偏值),函數才能表現得更好!
梯度下降(Gradient descent)。
梯度下降
假如我們把其中一個參數對損失函數的影響作圖,可能會得到以下的圖形:
(記住:其實我們是看不到完整的圖形是長什麼樣子的。)
Loss
w
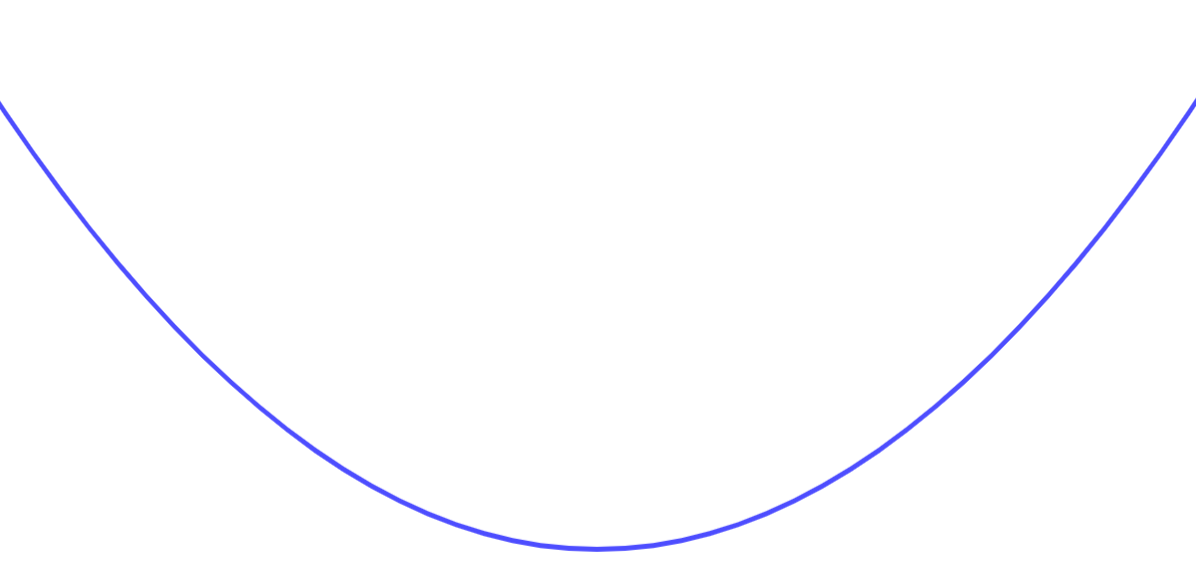
梯度下降
在開始時,我們隨機選一個位置為起始,記為
接下來,我想要往比較低的方向走......
Loss
w
w_0
w_0
梯度下降
因此,我們計算此函數圖形在 時的斜率。
(計算斜率需要用到微積分,詳細做法先略過不談)
Loss
w
w_0
w=w_0
梯度下降
然後我們將此斜率加負號,再乘上一個常數 (稱為學習率)
得出的值,就是我們這一步所需走的距離!
Loss
w
w_0
\eta
w_1
w_{1}=w_{0}-\eta{}\frac{\partial L}{\partial w}
梯度下降
重複以上步驟許多次,就可以找到此函數的區域最小值
(不一定是全域最小值)。
Loss
w
w_0
w_1
...
Local Minimum
如果後面還有更小的值是找不到的
...
當我們考慮所有的參數
當我們把千萬個參數一個一個挑出來,算出當下的斜率與修改幅度後......
就可以寫出一個"梯度"。
由於是沿著梯度變化而往低處走,稱為"梯度下降"。
可以如右式將所有參數疊在一起,
進行一些類似矩陣運算的東東。
因為GPU支援矩陣運算的平行操作,
所以才說使用GPU可以加速(?
\Delta L=
\left[
\begin{matrix}
\Delta \theta_1 \\
\Delta \theta_2 \\
\cdot \\
\cdot \\
\cdot \\
\Delta \theta_n \\
\end{matrix}
\right]
反向傳播
參數是由後面的層往前調的,稱為反向傳播
會有什麼問題?
找到的結果不一定是全域最小值
學習率太小->學得太慢
學習率太大->會跳過頭
不同參數的值域不同,無法共用同一個學習率
......
不用擔心
經過機器學習專家與數學家們的努力,開發出了許多不同的算法,以解決上述的問題。
常規化(Normalization):解決值域差異
隨機梯度下降(SGD):加速訓練
AdaGrad:遞減的學習率有助於更快接近最小值
Momentum:有機會脫離區域最小值,找到全域最小值。
如果想延伸學習的話,歡迎詢問講師(?
找到最好的函數後...
當我們找到在測試資料集中,表現得最好的那組參數時,我們的人工神經網路就訓練完畢了!
當我們使用這個人工神經網路做事時,他理當會得出我們想要的結果...嗎?
當神經網路看完訓練資料,也訓練完了
再塞給他沒看過的測試資料
他能辨認的出來嗎?
它是......

照理說會。
但不一定。
有可能你Train爛了
這種情況下,在訓練資料時就會跑得很差。
修改一下神經網路的架構、調整學習率,或者使用前面的一些優化方法,或許有幫助(?
當你在訓練集上得到足夠好的正確率,在測試集上就會有好的正確率...嗎?
過度擬合(OverFitting)
可以想像成,你的神經網路嘗試去背考古題的答案(?
因為我們沒有對輸入進行過多預處理,神經網路要找什麼樣的feature進行判別是隨自己高興,所以有可能選到一個沒有幫助的feature(?
所有的向左箭頭是綠色的
所有的向右箭頭是藍色的
當你丟給它一個綠色向右箭頭可能就會出錯
過度擬合(OverFitting)
以圖像化來說長成下面這個樣子(?
可以看見對訓練集來說,誤差是好的,不過套用到測試集就爛掉了。

解決辦法
夠多的訓練資料
Cross Validation:抽出一些訓練資料作為驗證集
正規化(Regularization):讓最後訓練出來的函數可以"平滑"一些,減少出大偏差的機會。
Dropout:在訓練期間隨機拔掉一些神經元,使他停止工作,於是其他神經元便需要學會在缺乏隊友時完成工作(?
注意:只有在測試集得到的正確率遠低於訓練集得到的正確率時,才需要套用這些方法。
Q&A
實作Part.1
實作目標


MNIST手寫數字
實作目標
60000張訓練圖片
10000張測試圖片
達到90%的測試圖片準確率
Chapter 0 引入資料庫
import keras
import matplotlib.pyplot as plt


Chapter 1 資料處理
(train_x,train_y),(test_x,test_y) = keras.datasets.mnist.load_data()
train_image = train_x / 255
test_image = test_x / 255
train_label = keras.utils.to_categorical(train_y, 10)
test_label = keras.utils.to_categorical(test_y, 10)x:[0,255,105,...,0]
\rightarrow
[0,1,0.4,...,0]
y:3
\rightarrow[0,0,0,1,0,0,0,0,0,0]
Chapter 2 建造模型
net = keras.models.Sequential()
net.add(keras.layers.Flatten(input_shape = (28,28)))
net.add(keras.layers.Dense(50,activation = 'relu'))
net.add(keras.layers.Dense(10,activation = 'softmax'))
Chapter 2 建造模型
keras.layers.Flatten
1
2
3
4
5
6
7
8
9
1
2
3
4
5
6
7
8
9
\rightarrow
Chapter 2 建造模型
keras.layers.Dense
compile
net.compile(
loss = keras.losses.mean_squared_error,
optimizer = keras.optimizers.SGD(learning_rate = 0.1),
metrics = ['accuracy']
)Chapter 2 建造模型
Chapter 3 訓練
net.fit(
train_image,
train_label,
batch_size = 100,
epochs = 10,
validation_data = (test_image,test_label)
)卷積神經網路

小小複習
神經網路的問題
神經網路的問題
9
9
9
解決方法
卷積!!
卷積
卷積=重複的乘積
重複的乘積
1
3
4
3
2
2
1
2
1
-1
2
重複的乘積
1
3
4
3
2
2
1
4
2
1
-1
2
重複的乘積
1
3
4
3
2
2
1
4
8
2
1
-1
2
重複的乘積
1
3
4
3
2
2
1
4
8 \,
8
2
1
-1
2
重複的乘積
1
3
4
3
2
2
1
4
8
8
2
6
1
-1
2
圖片卷積
0.0
0.0
0.0
1.0
0.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.5
0.5
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.0
0.0
0.0
-0.1
-0.1
-0.1
0.2
0.2
0.2
-0.1
-0.1
-0.1
0.4
0.0
0.0
0.0
1.0
0.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.5
0.5
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.0
0.0
0.0
-0.1
-0.1
-0.1
0.2
0.2
0.2
-0.1
-0.1
-0.1
0.4
0.55
0.0
0.0
0.0
1.0
0.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.5
0.5
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.0
0.0
0.0
-0.1
-0.1
-0.1
0.2
0.2
0.2
-0.1
-0.1
-0.1
0.4
0.55
0.35
0.0
0.0
0.0
1.0
0.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.5
0.5
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.0
0.0
0.0
-0.1
-0.1
-0.1
0.2
0.2
0.2
-0.1
-0.1
-0.1
0.4
0.55
0.35
-.25
0.0
0.0
0.0
1.0
0.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.5
0.5
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.0
0.0
0.0
-0.1
-0.1
-0.1
0.2
0.2
0.2
-0.1
-0.1
-0.1
0.4
0.55
0.35
-.25
-.25
0.0
0.0
0.0
1.0
0.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.5
0.5
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.0
0.0
0.0
-0.1
-0.1
-0.1
0.2
0.2
0.2
-0.1
-0.1
-0.1
0.4
0.55
0.35
-.25
-.25
-.15
0.0
0.0
0.0
1.0
0.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.5
0.5
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.0
0.0
0.0
-0.1
-0.1
-0.1
0.2
0.2
0.2
-0.1
-0.1
-0.1
0.4
0.55
0.35
-.25
-.25
-.15
0.05
0.0
0.0
0.0
1.0
0.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.5
0.5
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.0
0.0
0.0
-0.1
-0.1
-0.1
0.2
0.2
0.2
-0.1
-0.1
-0.1
0.4
0.55
0.35
-.25
-.25
-.15
0.05
0.0
0.0
0.0
0.0
1.0
0.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.5
0.5
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.0
0.0
0.0
-0.1
-0.1
-0.1
0.2
0.2
0.2
-0.1
-0.1
-0.1
0.4
0.55
0.35
-.25
-.25
-.15
0.05
0.0
0.05
\circledast
=
卷積核Kernel
卷積
卷積能幹嘛
在歪掉的圖看出特徵
找複雜特徵
0.0
0.0
0.0
1.0
0.0
0.0
1.0
1.0
0.0
0.0
0.0
0.0
0.0
0.5
0.5
0.0
0.0
0.5
0.0
0.0
0.0
0.0
0.0
0.0
0.0
-0.1
-0.1
-0.1
0.2
0.2
0.2
-0.1
-0.1
-0.1
0.4
0.55
0.35
-.25
-.25
-.15
0.05
0.0
0.05
0.0
0.0
0.1
0.0
0.1
0.0
0.1
0.0
0.0
0.1
0.1
0.1
0.1
0.1
0.1
0.0
0.15
0.0
0.1
0.1
0.1
-0.1
-0.1
0.1
-0.1
0.1
-0.1
0.0
-.05
-.15
0.2
0.4
0.1
0.1
-.05
0.05
0.4
0.55
0.35
-.25
-.25
-.15
0.05
0.0
0.05
0.1
0.1
0.1
0.1
0.1
0.1
0.0
0.15
0.0
0.0
-.05
-.15
0.2
0.4
0.1
0.1
-.05
0.05
0.4
0.55
0.35
-.25
-.25
-.15
0.05
0.0
0.05
0.1
0.1
0.1
0.1
0.1
0.1
0.0
0.15
0.0
0.0
-.05
-.15
0.2
0.4
0.1
0.1
-.05
0.05
0.4
0.55
0.35
-.25
-.25
-.15
0.05
0.0
0.05
0.1
0.1
0.1
0.1
0.1
0.1
0.0
0.15
0.0
0.0
-.05
-.15
0.2
0.4
0.1
0.1
-.05
0.05
0.4
0.55
0.35
-.25
-.25
-.15
0.05
0.0
0.05
0.1
0.1
0.1
0.1
0.1
0.1
0.0
0.15
0.0
0.0
-.05
-.15
0.2
0.4
0.1
0.1
-.05
0.05
\circledast
=
\circledast
=
\circledast
=
池化
池化
0.1
87
0.1
-0.1
-0.1
0.1
-0.1
0.3
-0.1
-0.1
0.1
-0.1
0.1
0.1
-0.1
-0.1
87
0.3
0.1
-0.1
-0.1
0.1
0.1
-0.1
0.1
-0.1
-0.1
-0.1
0.1
-10
0.1
-0.1
0.1
-0.1
0.1
-0.1
-0.1
0.1
-0.1
0.1
0.1
0.1
0.1
0.1
0.1
\rightarrow
為何要池化?
來看範例吧
1張圖\(\longrightarrow\)6張圖\(\longrightarrow\)6張圖\(\longrightarrow\)16張圖\(\longrightarrow\)16張圖\(\longrightarrow\)全連接
池化
卷積
卷積
池化
LeNet-5
卷積神經網路實作
實作目標
60000張訓練圖片
10000張測試圖片
達到97%的測試圖片準確率
卷積神經網路實作
keras.layers.Conv2D(3,3,
activation = 'relu')輸出3張圖片
卷積核大小3*3
卷積神經網路實作
keras.layers.MaxPooling2D(pool_size = 2)0.1
87
0.1
-0.1
-0.1
0.1
-0.1
0.1
-0.1
-0.1
0.1
-0.1
0.1
0.1
-0.1
-0.1
87
0.1
0.1
-0.1
來不及說的部份
activation = 'relu','sigmoid','tanh','softmax'
keras.optimizer.SGD
keras.optimizer.RMSprop
keras.optimizer.Adagrad
keras.optimizer.Adam懸賞
測試集正確率99.5%
想深入機器學習原理?
3Blue1Brown

謝謝大家
<eos>
Machine Learning
By jass921026




