Fantastic Recommendations and Where to Find Them
Julián Bayardo

Notebook: bit.ly/pydata-cordoba-2018-ipy
Slides & Qs: bit.ly/pydata-cordoba-2018-slides
Could anyone tell me what MeLi is?
Easy:
E-Commerce Platform
Objective
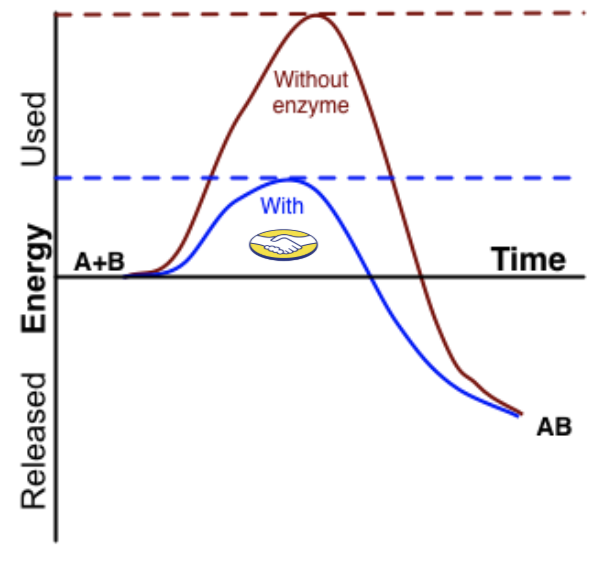
Democratize E-Commerce
Help users purchase faster, effortlessly
Why Recommendations
Experience
Exploration
Sales
Amazon
35% of Revenue
Taobao
20% Conversion
Netflix
80% of Views
YouTube
70% of Views
The Data
Items
- Multiple items for the same product
- May be sold by different sellers
- We don't hide this from users
- 184M active items across all sites.
Products
- Identifier for sets of items
- Algorithm-generated
- Interesting properties:
- ~65% of the revenue-generating items
- 5% to 15% of all items, varies per country
- >20% of total prints have product_id
- Usually very accurate
- 600k across all sites




Product ID for PS4
Categories
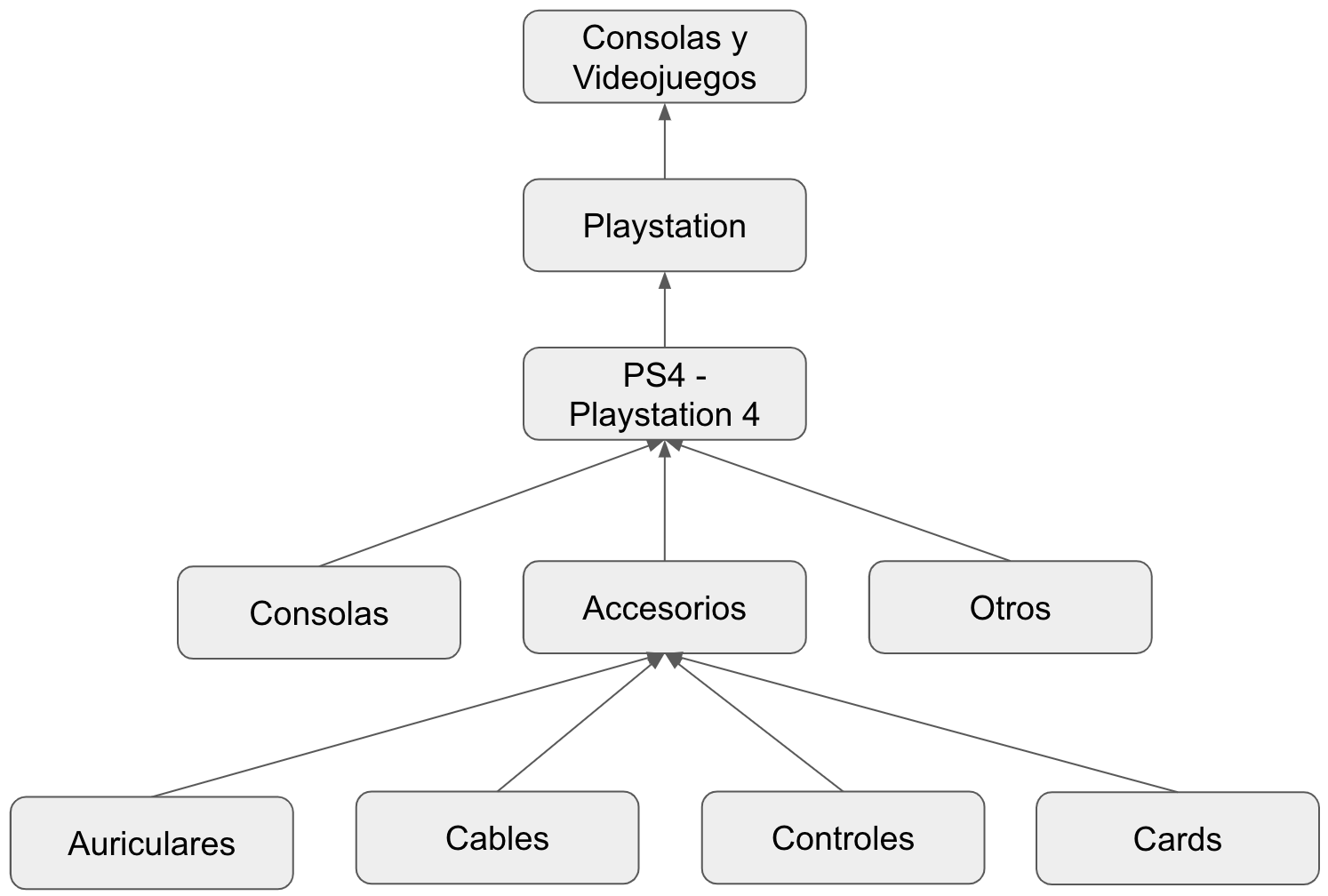
Attributes
Primary
Secondary
Views and Purchases



t_0
t_1
t_2
t_3
Purchase!
- Noisy. Users go back and forth.
-
Heuristics get this dataset to be more reasonable.
- This includes manipulation attempts :)
- 6k searches/s. 9 purchases/s
A Brief Introduction to Recommendations
Seller Items
View2Purch
Purch2Purch
- Alternatives
- Same seller
- Alternatives
- Any seller
- Complementaries
- Any seller

Bug Report
Where's the soda?
Trigger Item
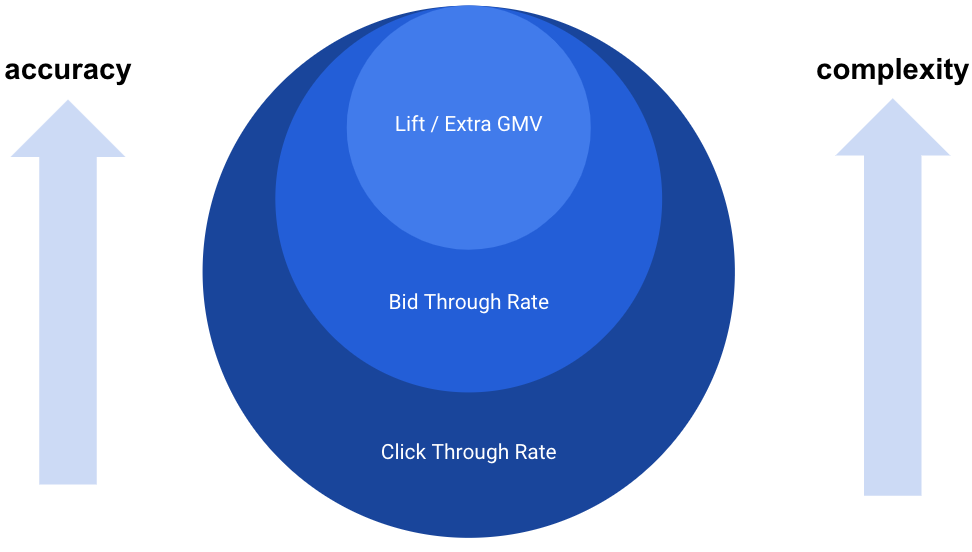
Key Performance Indicators
- Ultimately:
- User Lifetime Value
- Differential Gross Merchandise Volume (GMV)
- Hard to measure, so we use online proxies:
- Bid Through Rate (BTR)
- Click Through Rate (CTR)
- These we can measure through A/B testing
Offline Metrics
- CTR and BTR are online metrics, we need a deployed model.
- Develop using traditional metrics:
- Coverage@k
- Items that have k-length carrousels
- Recall@k
- Exact item purchases captured until position k
- Coverage@k
- Careful!
- Dependent on view sample taken
- Volatile
- Not nailing offline metrics is very bad.
- Quick to compute for development use, is all.
What makes a good recommendation?
- A lot to factor in:
- User's intent.
- Domain knowledge.
- You know it when you see it. Hard to put into a formula.
- Qualitative evaluation is paramount
- First take hundreds of examples, then look at metrics.
- Easy to achieve a high recall and coverage, with low quality recommendations (i.e. popular items).
First Iteration
f :: Item -> [Item]
f trigger = ...
f :: Item -> User -> [Item]
f trigger user = ...
f :: Item -> Navigation -> [Item]
f trigger history = ...
f :: Item -> User -> Navigation -> [Item]
f trigger user history = ...You are here
C-C-C-Co Counts!
- Occurrences between:
- Item (View|Purchase) vs Item (View|Purchase)
- Causality notice due!
- User vs Item (View|Purchase)
- ...
- Item (View|Purchase) vs Item (View|Purchase)
M_{ij} = \text{\#occurrences(i, j)}
Item2Item for View2Purch
- Empirical probability of purchase, given the trigger item.
- Recommend the top K.
- ????
- Profit!
\mathbb{P}(\text{Purchase Item } j | \text{Seen Item } i) \approx \frac{M_{ij}}{\sum_{k = 1}^N M_{ik}}
Item2Item for View2Purch
- A tough and simple baseline
- Problems:
- 16% missing is a lot
- Cold start
- 82% of our listings are ephemeral.
- They disappear after being sold
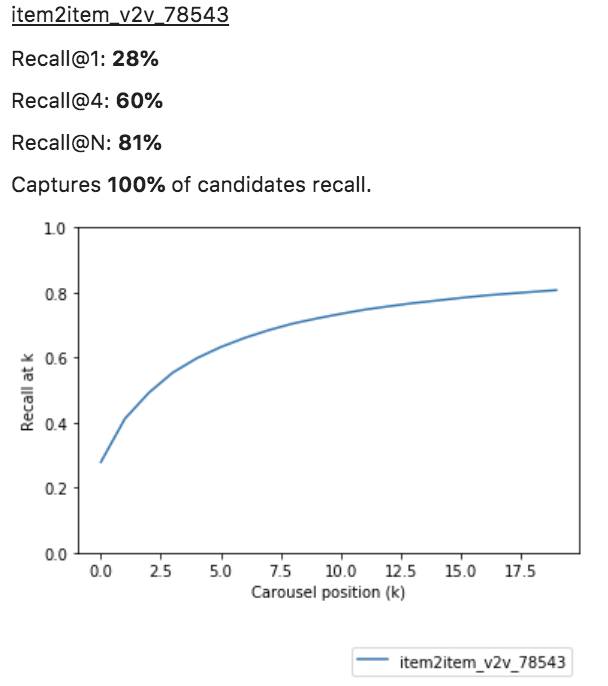
Coverage@20: 84%
At the end of the day...
- Keep a fallback sequence.
- Makes for an easy to implement and effective approach.
Item to Purchases
Item to Views
Current Iteration
f :: Item -> [Item]
f trigger = ...
f :: Item -> User -> [Item]
f trigger user = ...
f :: Item -> Navigation -> [Item]
f trigger history = ...
f :: Item -> User -> Navigation -> [Item]
f trigger user history = ...Still here
With some of
Candidates





Trigger

-
Huge set of items
- High Recall
- High Coverage
- Every carousel has a different need
- Seller Items
- Same seller alternatives
-
V2P
- Alternatives
- P2P
- Complimentary
- Seller Items
Candidates
Ranking
...
-
Items sorted by relevance
- Concentrated Recall
- Order matters
- Mobile: 2 - over 60% of traffic
- Desktop: 4/5
- ~50% of CTR without sliding
- Relevance = Conversion
If you have high recall and coverage, the game is in the ranking layer
Ranking
isn't
magic



In a world with bad candidates...

Trigger
Recommendation
Fernet
Hello Kitty Mate Set
Productization
What is it?
- Key Services:
- Similar items
- Item to item similarity
- Used for:
- Candidates
- Filtering
- Feature for ranking
- Boosting search results
- Imputing weight and measurements to items
- ... You get the drill...
- An improvement in productization impacts our entire stack.
B-b-b-but you had product_id!
Low coverage
No similarity measure
Distributional Hypothesis
"A man is known by the company he keeps"
Distributional Hypothesis
Applied to items



It just works!
Co-counts along a sliding window through views is gooooood
Trigger Item
Ad-hoc similarity measure
Not robust to noise
Suffers from cold start
...people have already dealt with this problem in NLP...

Word2Vec


Gist of it
- Have a vector representation for every word
- As a center of a sliding window
- As a "non-center" or context of a sliding window
- Predict the probability of a word occurring in another's context using just their vector similarity
The dog is under the big table
Center
Sliding Window
\mathbb{P}(\text{"dog"} \in \text{context} | \text{center = "under"}) = ...
Going down the rabbit hole
| Center | Context |
|---|---|
v_{\text{under}}
v_{\text{under}}
c_{\text{dog}}
c_{\text{big}}
c_{\text{dog}}^T v_{\text{under}} \approx \text{similarity}
\mathbb{P}(c_{\text{dog}}|v_{\text{under}}) = \frac{\exp{(c_{\text{dog}}^T v_{\text{under}})}}{\sum_{w \in \mathcal{V}} \exp{(c_w^T v_{\text{under}})}}
Going down the rabbit hole
\mathbb{P}(c_{\text{dog}}|v_{\text{under}}) = \frac{\exp{(c_{\text{dog}}^T v_{\text{under}})}}{\sum_{w \in \mathcal{V}} \exp{(c_w^T v_{\text{under}})}}
\hat{J}(V, C) = \frac{1}{T} \sum_{t=1}^T \sum \limits_{-m \leq j \leq m, j \neq 0} -\log{ \mathbb{P}(c_{w_{t + j}} | v_{w_t}) }
Negative Log Likelihood
Over Corpus
Over Window
Cross Entropy
What do we have now?
- For each entry in our training set
- We are progressively getting the vectors "closer together" in our similarity space
- Through maximizing the likelihood
- Something like this happens:
under
dog
table
under
dog
table
Going down the rabbit hole
\mathbb{P}(c_{\text{dog}}|v_{\text{under}}) = \frac{\exp{(c_{\text{dog}}^T v_{\text{under}})}}{\sum_{w \in \mathcal{V}} \exp{(c_w^T v_{\text{under}})}}
Expensive!
Noise Contrastive Estimation
- Task change:
- Tell the context word from "noise words".
- Sum over a random subset of words instead of the entire vocabulary.
under
dog
ring
magic
Center
Context
Noise
1
0
\sigma(c_{\text{dog}}^T v_{\text{under}})
\sigma(c_{\text{n}}^T v_{\text{under}})
Negative Sampling
- Tell the context word from "noise words".
- New hyperparameters:
- Number of negative examples
- Sampling distribution
\hat{J}(V, C) = \frac{1}{T} \sum_{t=1}^T \sum \limits_{-m \leq j \leq m, j \neq 0} -\log{ \text{Err}(c_{w_{t + j}} | v_{w_t}) }
\log{ \text{Err}(c_{w_{t + j}} | v_{w_t}) } \approx \log{\sigma{( c_{w_{t + j}}^T v_{w_t} )}} + \sum_{i=1}^k \mathbb{E}_{c_i \sim P_n(w)} [ \log{(1 - \sigma(c_i^T v_{w_t}))}]
Error on Positive Example
Error on Negative Examples
Over Corpus
Over Window
Cross Entropy Estimate
Subsampling Rate
- Observation:
- Some vectors don't change after many iterations
- Words happen to be common (i.e. "the", "he", ...)
- A frequent word appearing in the context of another won't yield insights about the meaning of either
\mathbb{P}_t(w_i) = 1 - \sqrt{\frac{t}{\text{freq}(w_i)}}
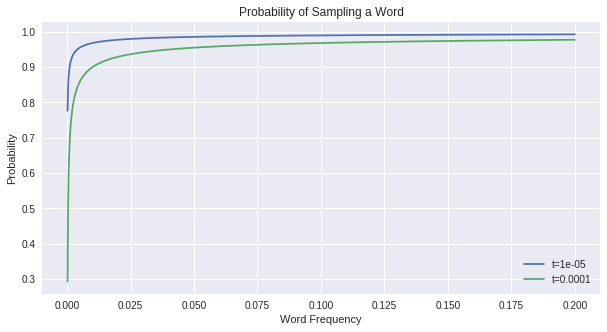
Discard a word from the dataset with probability:
And finally...
from gensim.models import Word2Vec
sentences = [
["hello", "pydata"],
["how", "are", "you", "doing"],
["well", "this", "is", "embarrassing"]]
model = Word2Vec(sentences,
size=300, # Vector dimensions
window=5, # Sliding window size
sg=1, # Use the skip gram model, as exposed here
hs=0, # Use negative sampling, as exposed here
negative=5, # Number of negative samples
ns_exponent=0.75, # Unigram distribution's exponent
sample=1e-4) # Subsampling rate
AWS Budget
Reaping the profits
- Now we have:
- Vector for every word in the corpus
- Similar to words that appear in the same contexts
- Some things we can do:
- Word similarity
- Search by similarity
- Vectors for sentences
- Math between vectors
- ...

Measuring Similarity
\frac{a^T b}{||a|| ||b||} = \cos(\theta)
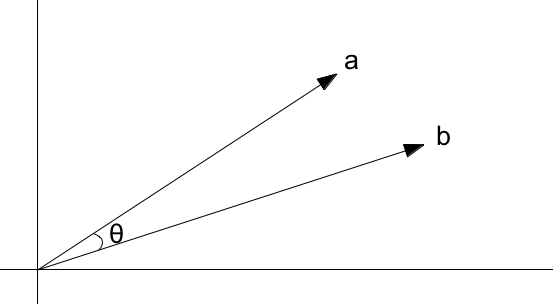
Vector Math
Can we do this for items?
Prod2Vec

Prod2Vec
- Same idea, just change the words:
- Instead of words, we are using Item IDs
- The corpus is composed of user view sequences
However...
New items don't have a vector representation

Meta-Prod2Vec

Just
Add
Metadata

Meta-Prod2Vec
- Sentences are still made up of user's navigation sequences
- Now a sentence also contains metadata for every item
item_id: MLB938974539
cat_l7_id: MLB7264
title: carcaca
title: dodge_dart
domain_id: MLB-CLASSIC_CARS
item_id: MLB972105778
cat_l7_id: MLB3168
title: plymouth
title: sedan
domain_id: MLB-CLASSIC_CARS
item_id: MLB993188183
cat_l7_id: MLB7264
title: dodge
title: van_furgao
item_id: MLB938974539
cat_l7_id: MLB3168
title: dodge



Examples
Most Similar
Examples
Most
Similar (180-200)
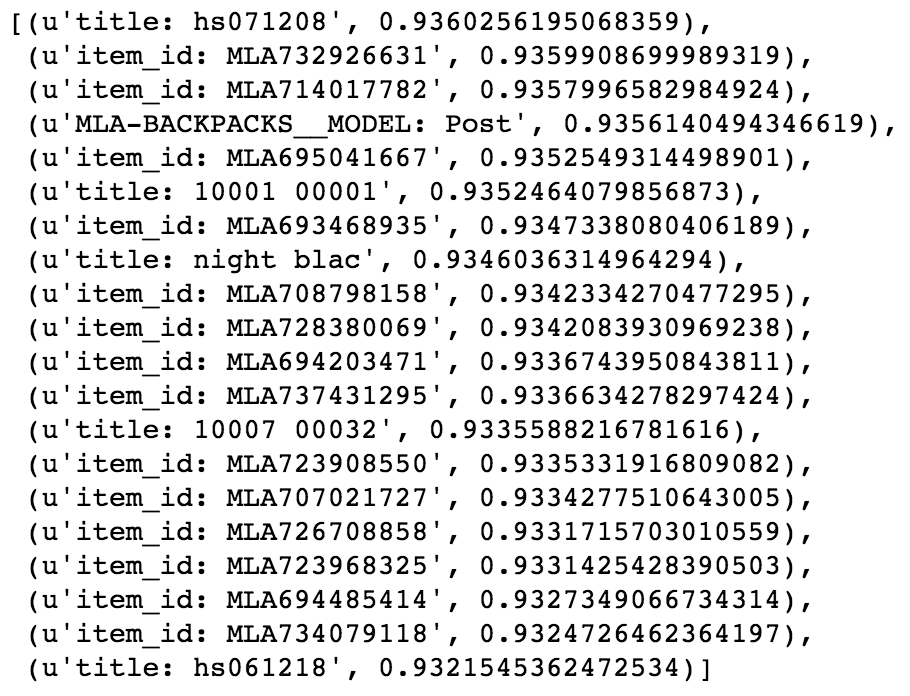

Its the same product all the way down. And then there's turtles.
Vector Math
Most
Similar
Herschel - Bag

Herschel Wallets!

This is actually a pretty bad example, as it is an uncommon product
Inference
- How to deal with a new item?
- Sentence embeddings!
- Fetch embeddings from all of its metadata
- Combine them into an embedding in the same space
- There is a lot of research in this space. We just use the average :)
item_id: ...
prod_id: ...
cat_id: ...
...
Unavailable!
Vector
Vector
...
Avg
Impact
80% CTR
40% BTR
Impact
- How?
- Better candidates
- Better similarity filtering when using other methods
- Good ranking feature
- Productization is also used:
- All carousels
- Building Combos
- Predicting item weight and measurements
- ...
- An improvement in productization impacts all our products
Banana for Scale

- Brazil:
- 37M sessions (15 days)
- 130M items
- Argentina:
- 32M sessions (1 month)
- 35M items
- ~36h per epoch
Looking Forward

Measuring Performance
Extrinsic Metrics
- Evaluation on the final task
- If bad, hard to determine where the problem is
- Examples:
- BTR/CTR Improvement
- Recommendations recall
- Boosting search and measuring NDCG
- ...

In our case...
Good
\iff
Intrinsic Metrics
- Evaluation on a intermediate subtask
- May not correlate with the final task
- Examples:
- Item vs Product similarity
- Item to product links being learnt
- Item vs Item (with same product) similarity
- Same product items are close to each other
- Item vs Averaged Metadata similarity
- Understand performance during inference
- ...
- Item vs Product similarity
Adjusting Embeddings
- Sometimes, items we know should be similar are not
- How
- Same product
- Same L7 category
- Why
- Not enough traffic
- Learning from context
- How
- Classify if two items are the same product.
- Using just the dot product between their vectors
- GloVe-like approach, with the co-counts between words replaced by post-purchase co-counts
Merging Embeddings


Merging Embeddings
- We have many different kinds of embeddings
- Metadata
- Titles
- Images
- ...
- Can we merge them all into an ULTRA EMBEDDING?
- Common approach here is to just use one layer to merge them.
- Why?
- Better embeddings! :D

Multilingual Embeddings
- Train using data from many sites
- Work for all of them
- Learn cross-site relationships
- Why?
- Weights and measurements estimation
- Missing attributes imputation
- Data analysis
- ...
We're Hiring!

WOLOLO!
Slides & Qs: bit.ly/pydata-cordoba-2018-slides
Notebook: bit.ly/pydata-cordoba-2018-ipy
Doing this at home

Hyperparameters
| Parameter | Value |
|---|---|
| Method | Skip-Gram |
| Embedding Size | 128 |
| Window Size | 40 |
| Negative Examples | 20 |
| Negative Sampling Exponent | -0.5 |
| Subsampling Rate | 10e-4 |
| Minimum Count | 10 |
Lots of metadata!
Sample infrequent items
Disclaimer: most of these were found through experimentation
How to improve
... or not to...
Matrix Factorization
- Build the User to Item co-occurrence matrix
- Apply matrix factorization techniques like in the Netflix challenge
- Decided not to explore it explicitly:
- Over 90% of users purchase less than once per month.
- Would turn into a very sparse matrix, likely bad representations.
- We actually do something similar :wink:
Next Steps
- The long tail, albeit less important, still holds a huge amount of our CTR/BTR.
- First positions are reasonably good, so improve the long tail.
Distributional Hypothesis
The dog is under the table
cat
bird
beside
over
bed
sofa
Applied to words
Going down the rabbit hole
The dog is under the big table
Center
Sliding Window
| Center | Context |
|---|---|
v_{\text{under}}
v_{\text{under}}
c_{\text{dog}}
c_{\text{big}}
Negative Sampling Distribution
- The Unigram distribution is used to sample words
- Higher frequency => Higher probability
- r allows us to distort it
\mathbb{P}_r(w_i) = \frac{ {f(w_i)}^{r} }{\sum_{j=0}^{T}\left( {f(w_j)}^{r} \right) }
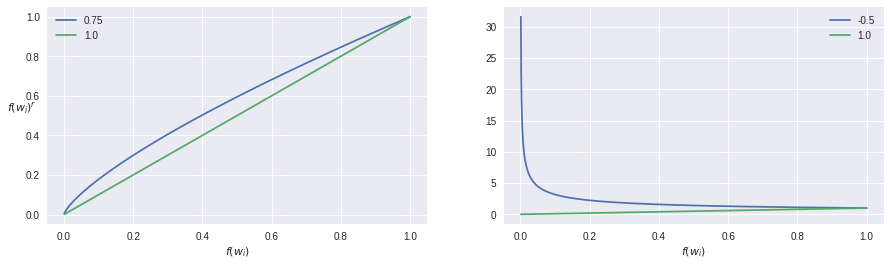
r \in (-1, 0)
r \in (0, 1)
Meta-Prod2Vec
- There are many kinds of vectors now:
- Item
- Title N-grams
- Category
- Domain
- ...
- From a technical standpoint, this can be seen as a change in the loss function:
L_{\text{MP2V}} = L_{\text{J | I}} + \lambda ( L_{\text{M | I}} + L_{\text{J | M}} + L_{\text{M | M}} + L_{\text{I | M}})
Regularization (Implicit)
There is one of M for every kind of metadata added
PyData Córdoba 2018: Fantastic Recommendations and Where To Find Them
By Julian Bayardo
