















Jesús Estévez
Just another simple developer
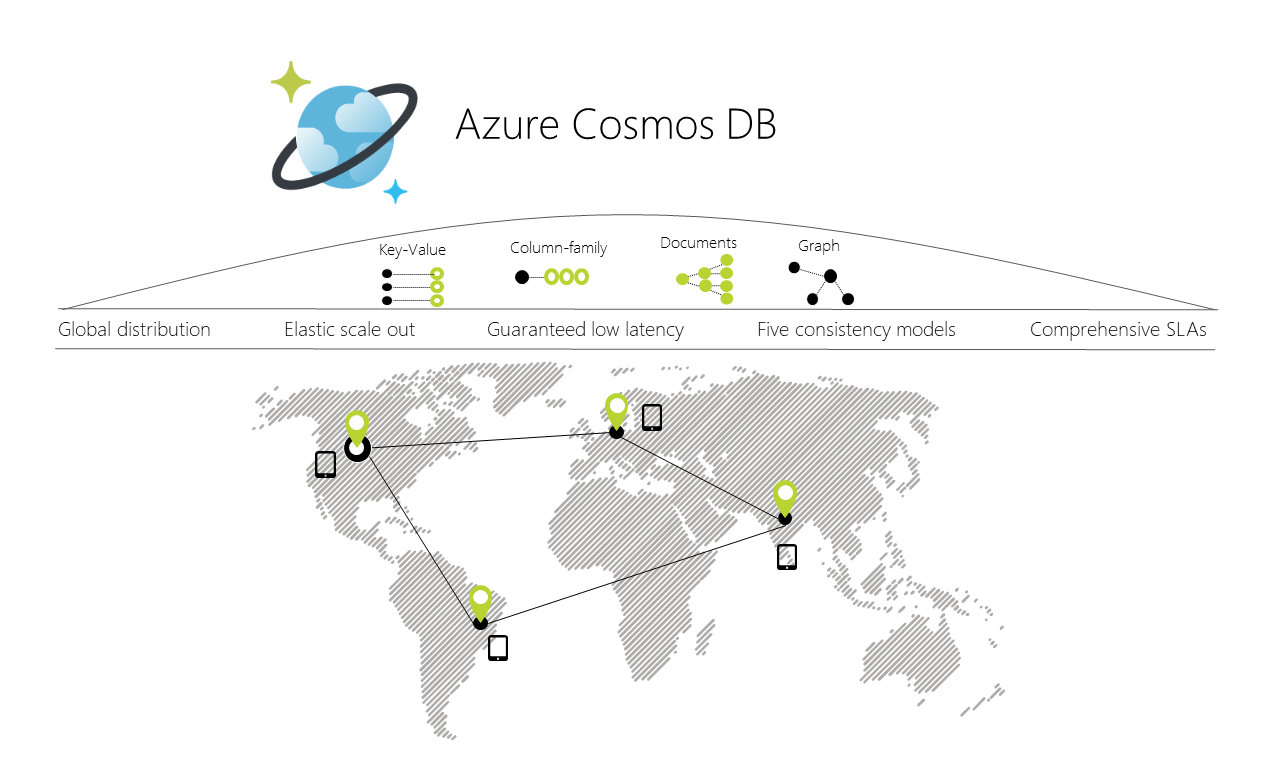
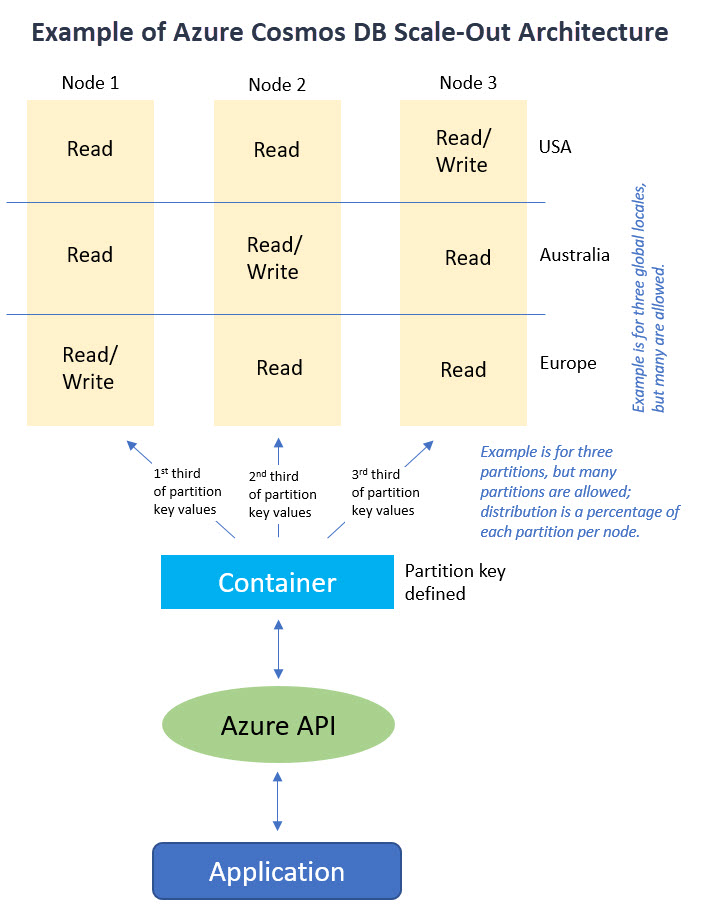
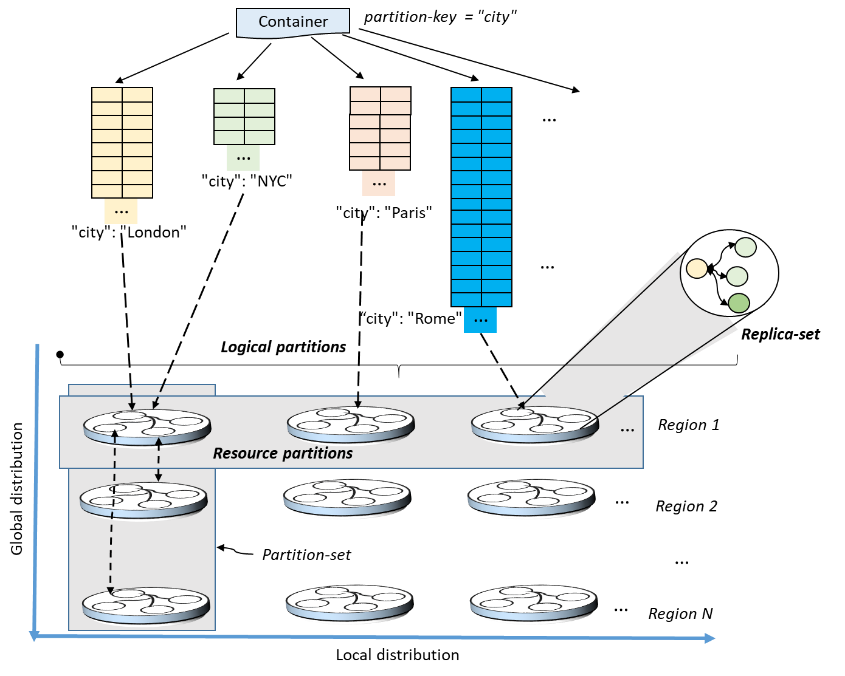
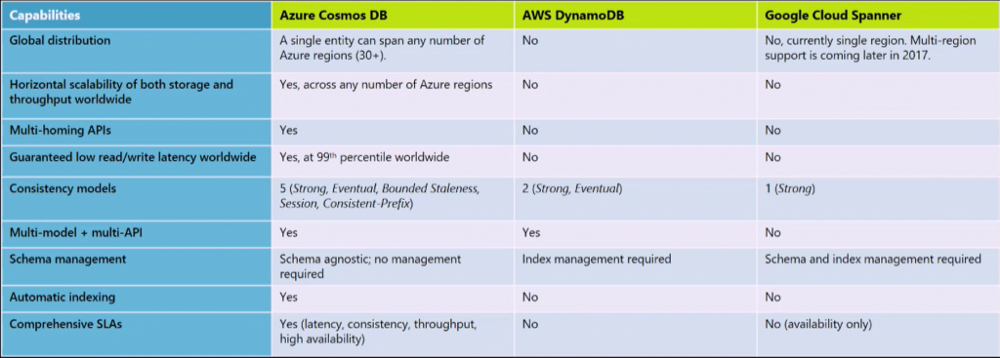
Let's see how Cosmos DB is designed to scale out by utilizing many regional machines and then mirroring this structure geographically to bring content closer to users worldwide.
Scale-Out Architecture in SQL Server
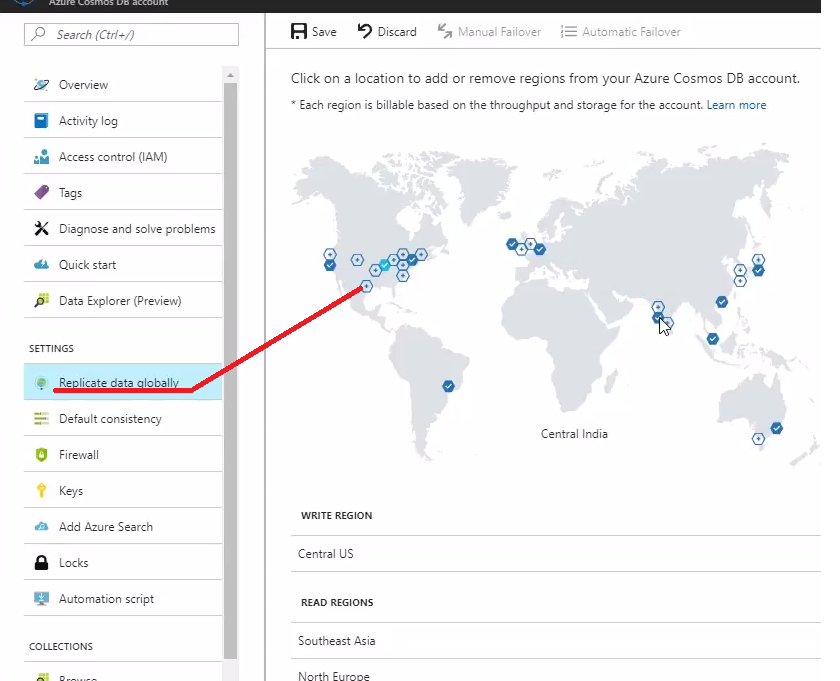
Set up Azure Cosmos DB global distribution using the SQL API
The cost of all database operations is normalized by Cosmos DB and is expressed in terms of
Request Units (RUs) = Get 1-KB item is 1 Request Unit (1 RU)
Throughput measures the number of requests that the service can handle in a specific period of time
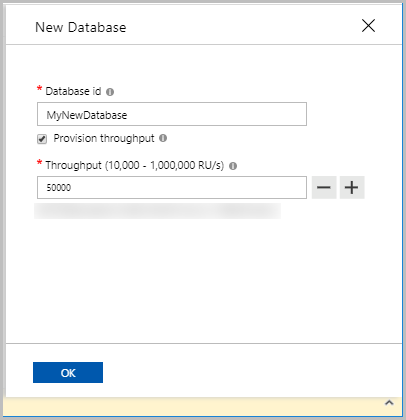
Provision throughput on
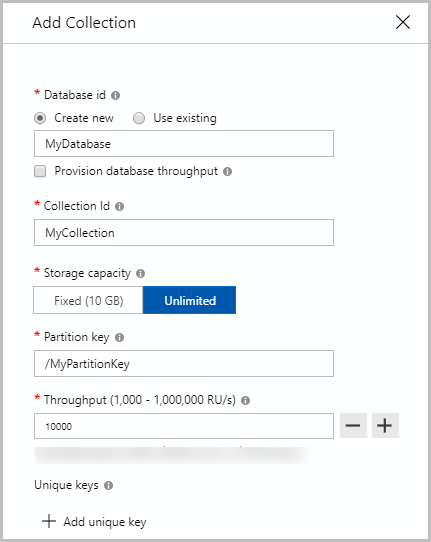
# Create a container with a partition key
and provision throughput of 1000 RU/s
az cosmosdb collection create \
--resource-group $resourceGroupName \
--collection-name $containerName \
--name $accountName \
--db-name $databaseName \
--partition-key-path /myPartitionKey \
--throughput 1000// Create a container with a partition key
// and provision throughput of 1000 RU/s
DocumentCollection myCollection =
new DocumentCollection();
myCollection.Id = "myContainerName";
myCollection.PartitionKey.Paths.Add("/myPartitionKey");
await client.CreateDocumentCollectionAsync(
UriFactory.CreateDatabaseUri("myDatabaseName"),
myCollection,
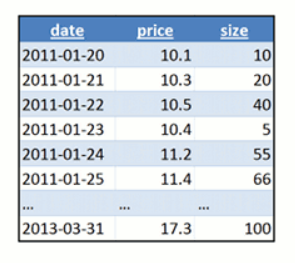
new RequestOptions { OfferThroughput = 1000 });{
"date":"2018-11-22",
"price": 33,
"size": 10
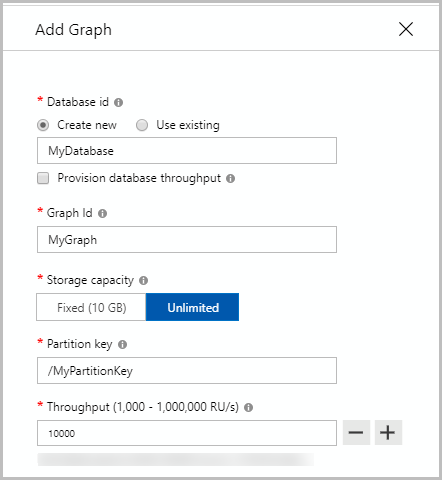
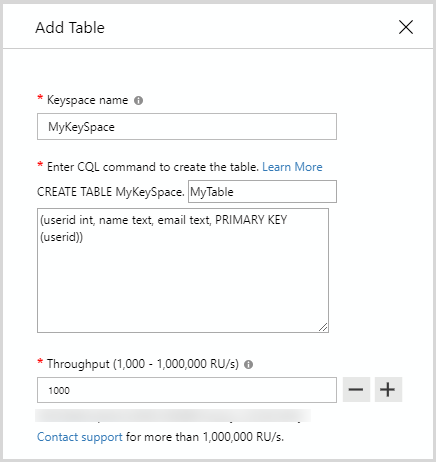
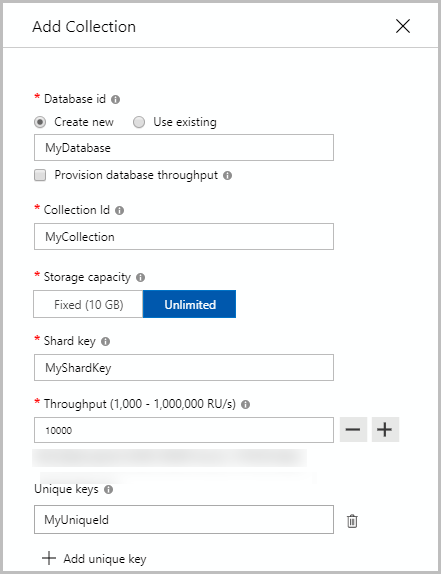
}How to create container in different models
MongoDb
Casandra
Gremlin
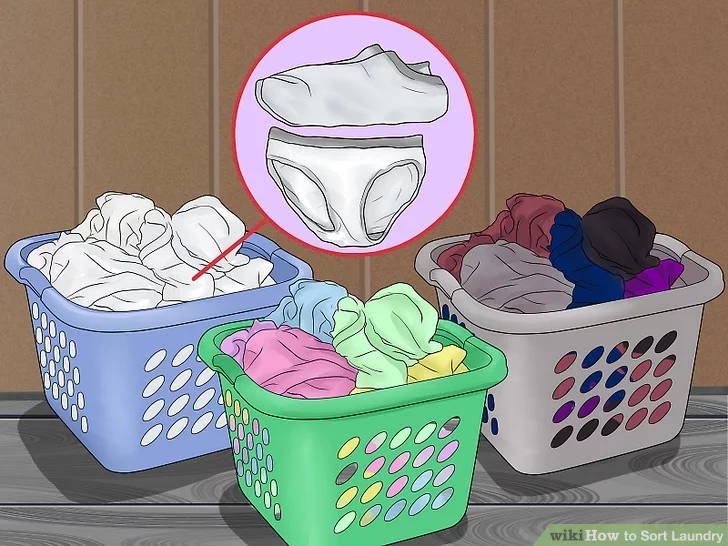
All in the same cloth box?
Partitions of the cloths depending on the colour?
Partitions of the cloths depending on the fabric weight?
Partitions of the cloths depending on how old is it?
Partitions of the cloths depending on the type?
Find the correct way to store your cloth to save money
Find the correct way to store your cloth to save money
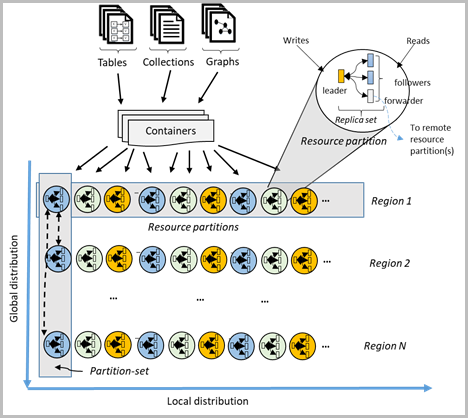
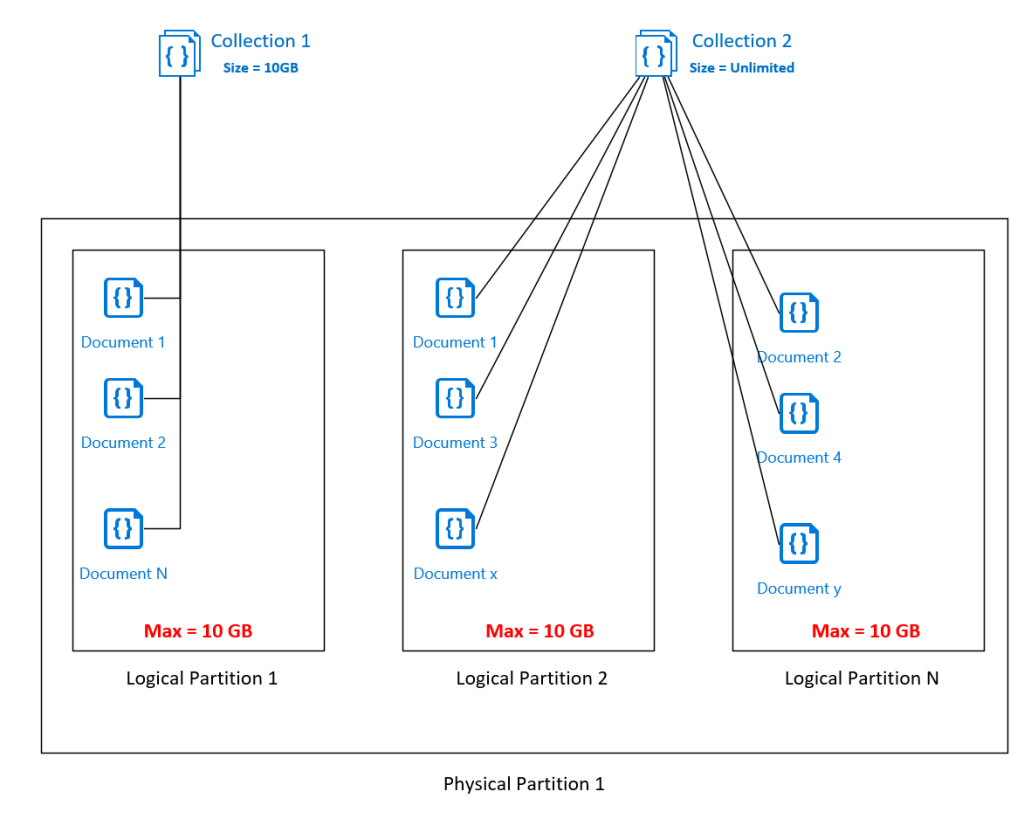
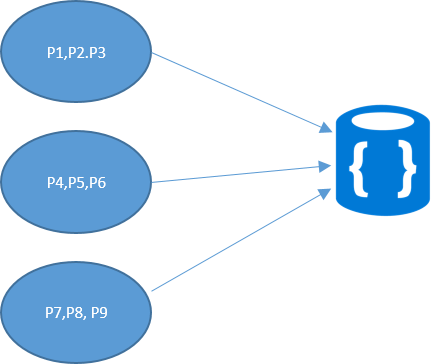
Set of items with the same key is a
logical partition.
The fact of spreading the documents across multiple Logical Partitions, is called partitioning
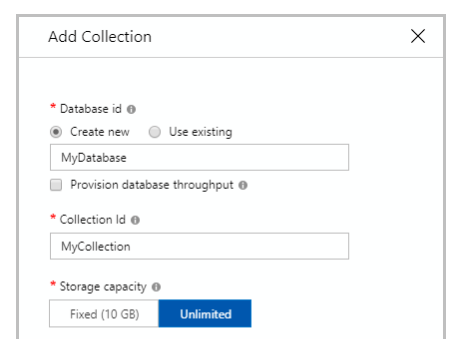
When the size of a container exceeds 10GB, We needs to spread data over multiple Logical Partitions.
Partitioning is mandatory if you select Unlimited storage for your container
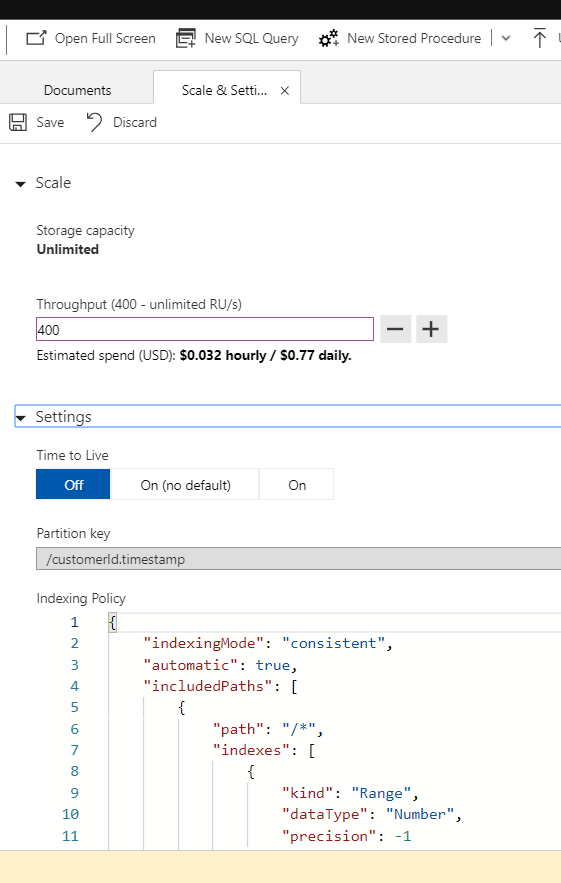
Minimum throughput of 400 RU/s and the cost in 2018 is around 0.77$ per day
how logical partitions are mapped to physical partitions that are distributed globally
Connection policy: Use direct connection mode
Gateway
Direct Mode
Recommended with limited conection like azure functions
Better performance
When you do a query without partition key you are querying all the logical partitions!!
Then you need to wait to all of them
They run in parallel.
The number of queries in parallel is MaxParalelDegree flag.
You need to have enabled CrossPartition flag!!
2
The throughput of the queries are generated depending of the next factors:
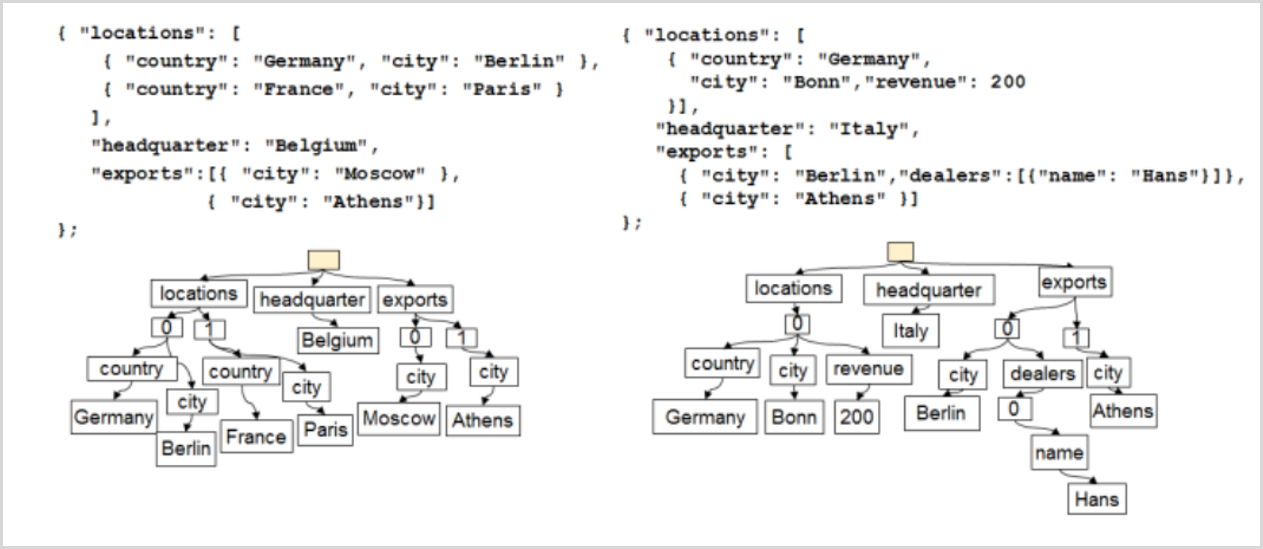
Each document has a uri that is a selflink to identify directly the document in the collection.
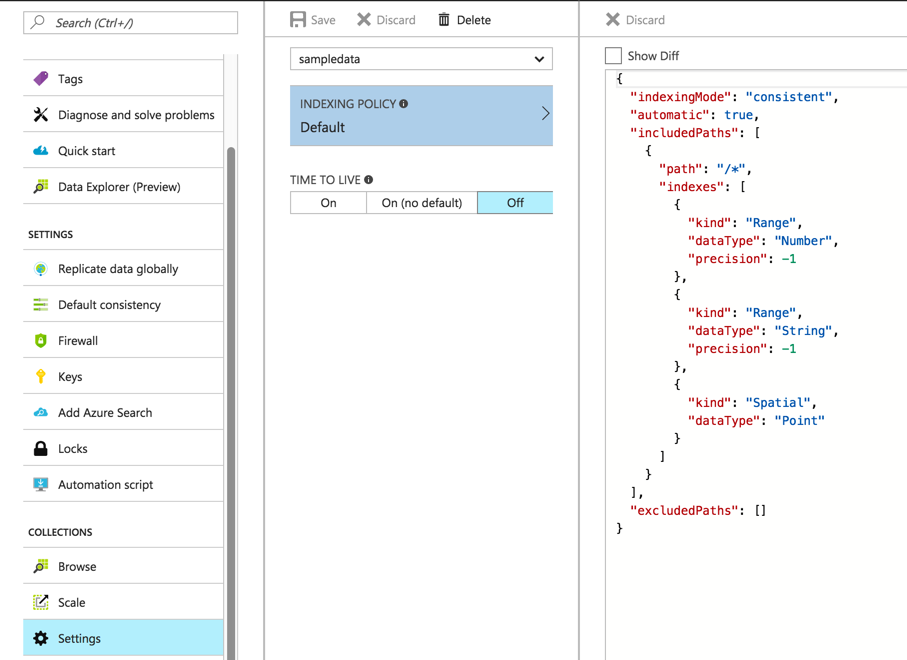
It is a slow operation because in cosmos we index all the fields by default.
Last Microsoft Update
Now we are able to insert one millon of document in just one insert. It is much faster.
bulkExecutor.
BulkImportResponse bulkImportResponse = await bulkExecutor.BulkImportAsync( documents: documentsToImportInBatch, enableUpsert: true, disableAutomaticIdGeneration: true, maxConcurrencyPerPartitionKeyRange: null, maxInMemorySortingBatchSize: null, cancellationToken: token);
With partition Key
With Partition Key
Query partition keys with id even faster!!
Add partition keys and ids to everything and the problems start
The maximun length is 30720 characters
deviceId-customerId-type-month-year
where deviceId=2 && customerId="b52f92a3-f88f-4532-a3f6-02da94d4d0c2" and type="3"
and month="6" and year="2018"where partitionKey="1-b52f92a3-f88f-4532-a3f6-02da94d4d0c2-3-5-2018"Split the query into different partition keys queries:
When we have to many task in parallel doing querys you can get HTTP 429 error. To many Request.
Once, you have got the values with the best thoughput possible
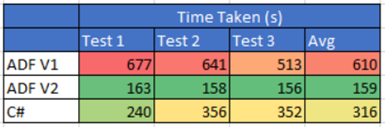
It was really slow!
MaxItemCount = 20000;
while (query.HasMoreResults)
{
var results = query.ExecuteNextAsync<CosmosPeriodHour>()).ConfigureAwait(false);
periodHours.AddRange(results.ToList());
}Real problem. Get the latest two weeks/ 1 months documents from a collections for a device.
You do not know when was the latest date for that device.
Select top 1 * from c where c.deviceId=95394 order by c.timestamp desc
Select top 300 * from c where c.deviceId=95394 order by c.timestamp desc
Solution
Each new data insert new data in the other collection. I modified the subcollection
One quick access,
I get all the data
Document size is important!
By Jesús Estévez



