An Introduction to Scrapy
Context: Cinebot
?

Problem: Welcome to the UK

?
- No single source for showtimes data
- Many different cinema companies
- No API to get their data
Solution: Scraping

LET'S GET THE DATA
ON THE GEMBA
Starting small with Curzon cinemas
Limited number of theaters
Decent movie listing
My flatmate can get me free tickets

Curzon "Now Showing" page
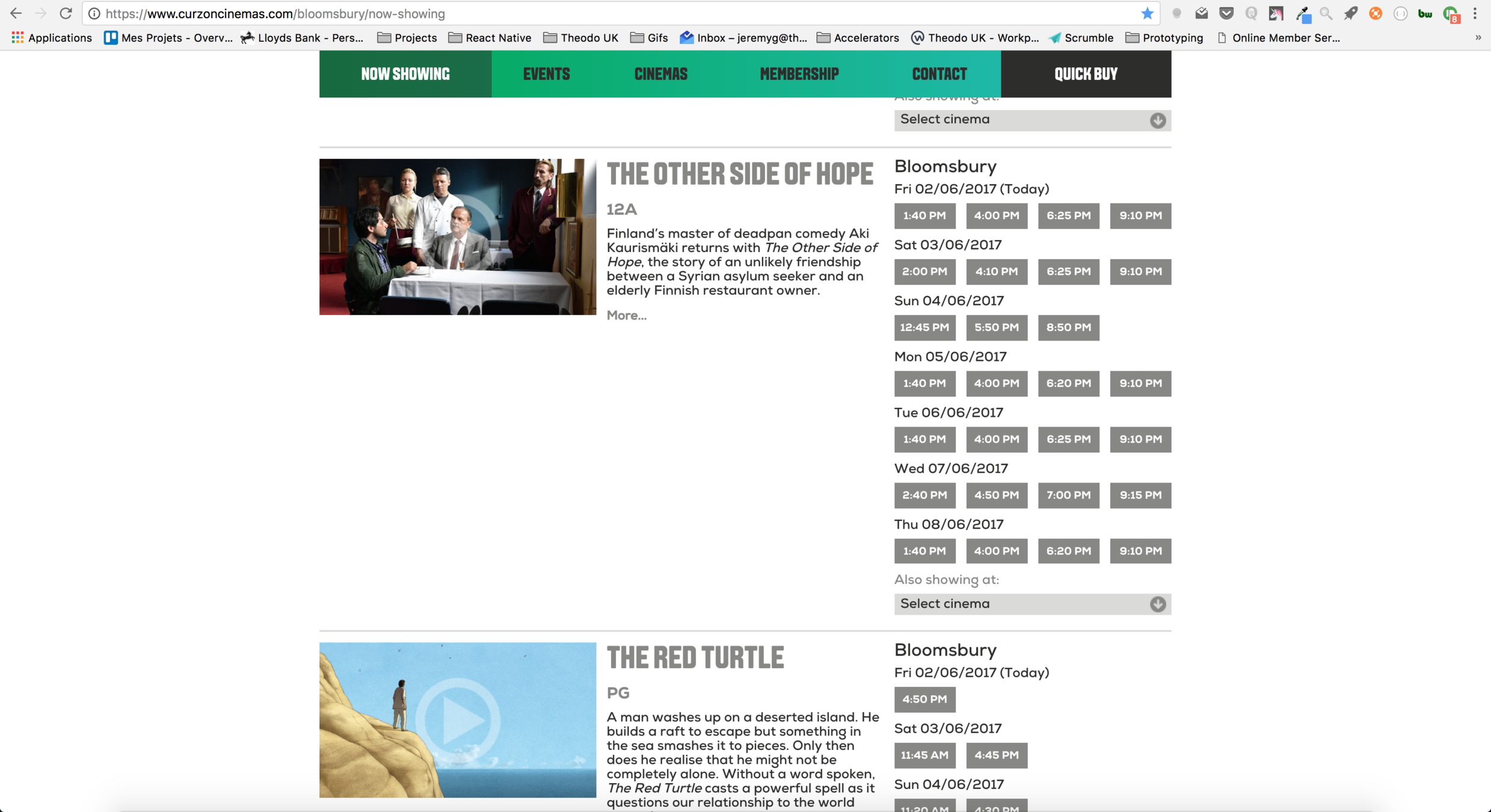
Data needed
{
"place": {
"name": "Le Cinéma des Cinéastes",
"city": "Paris 17e arrondissement",
"postalCode": "75017",
},
"movie": {
"title": "Moonlight",
"language": "Anglais",
"vo": true,
"posterUrl": "http://images.allocine.fr/pictures/17/01/26/09/46/162340.jpg",
"pressRating": 4.18421,
"userRating": 4.07561159,
"url": "http://www.allocine.fr/film/fichefilm_gen_cfilm=242054.html",
"is3D": false,
"releaseDate": "2017-02-01",
"trailerUrl": "http://www.allocine.fr/video/player_gen_cmedia=19565733&cfilm=242054.html"
},
"date": "2017-02-24",
"times": {
"13:15": "https://tickets.allocine.fr/paris-le-brady/reserver/F191274/D1488024900/VO",
"17:30": "https://tickets.allocine.fr/paris-le-brady/reserver/F191274/D1488040200/VO",
"19:45": "https://tickets.allocine.fr/paris-le-brady/reserver/F191274/D1488048300/VO",
"22:00": "https://tickets.allocine.fr/paris-le-brady/reserver/F191274/D1488056400/VO"
},
"_geoloc": {
"lat": 48.883658,
"lng": 2.327202
}
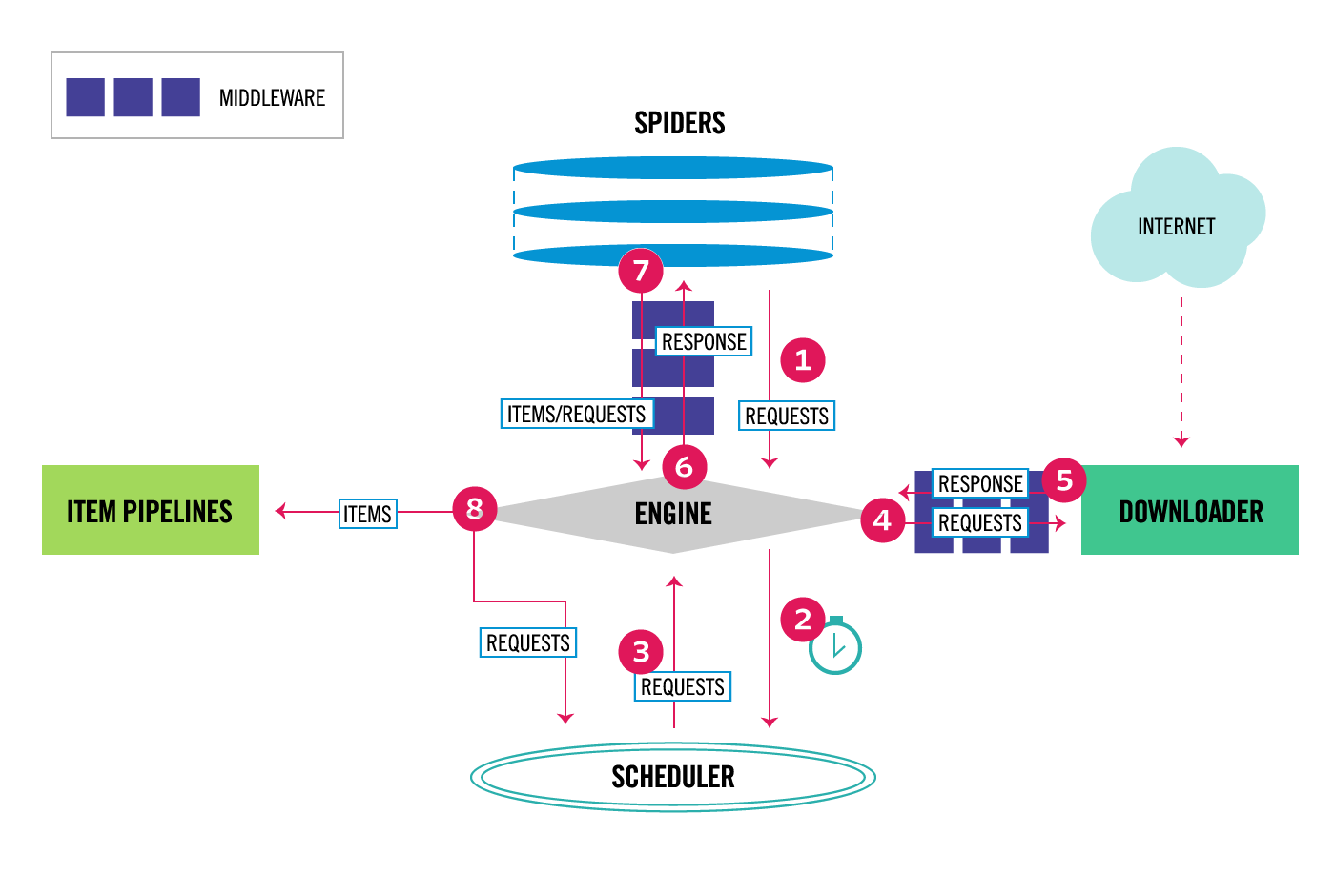
}Scrapy: a Python framework for web-scraping
- Python
- Elegant data flow to write reusable code
- Asynchronous
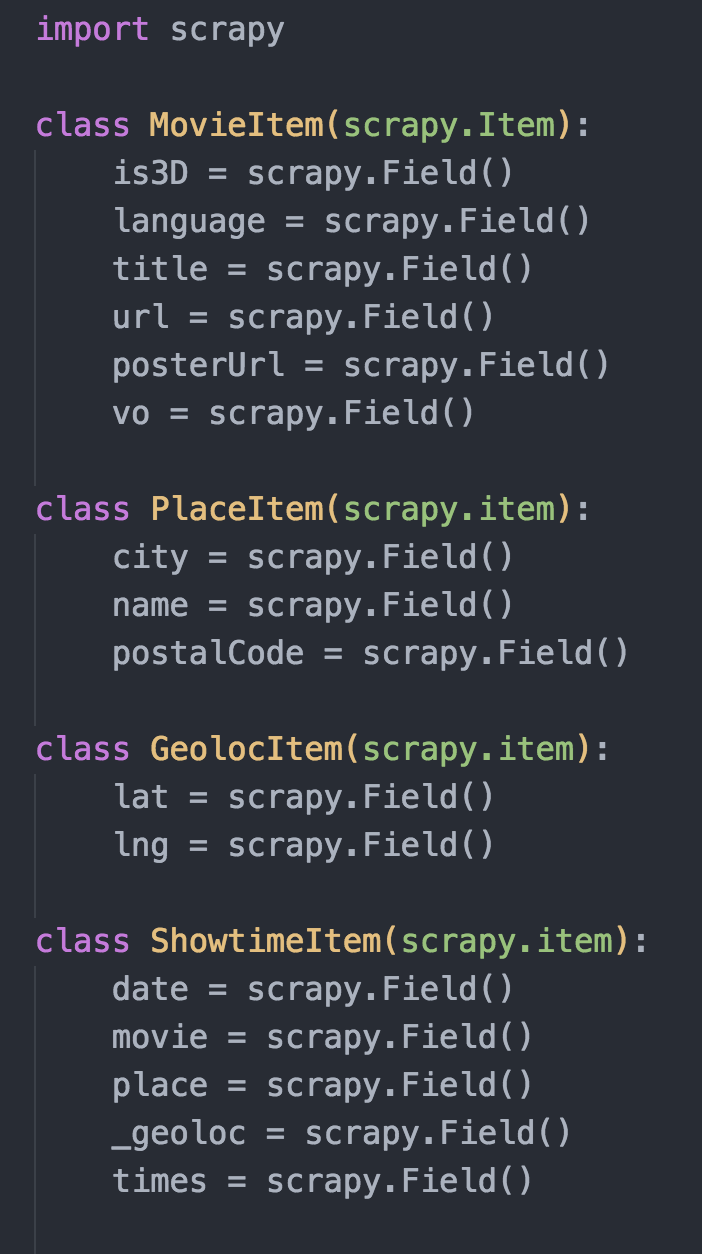
Declaring Items
Creating Pipeline to Algolia
# pipelines.py
from algoliasearch import algoliasearch
import time
TODAY = time.strftime('%Y-%m-%d')
class CurzonScraperPipeline(object):
def open_spider(self, spider):
self.client = algoliasearch.Client('Th30d0', 'L34n1s4J0uRn3Y')
self.index = self.client.init_index('pariscine_seances')
def process_item(self, item, spider):
if(item['date'] == TODAY):
self.index.add_object(item)
return item
# settings.py
ITEM_PIPELINES = {
'curzon_scraper.pipelines.CurzonScraperPipeline': 300,
}Multiple pipelines
# pipelines.py
class CurzonScraperDateFilterPipeline(object):
def process_item(self, item, spider):
if(item.get('date') == TODAY):
return item
else:
raise DropItem('Dropping showtime %s not for today' % item)
class CurzonScraperAlgoliaPipeline(object):
def open_spider(self, spider):
self.client = algoliasearch.Client('Th30d0', 'L34n1s4J0uRn3Y')
self.index = self.client.init_index('pariscine_seances')
def process_item(self, item, spider):
self.index.add_object(item)
return item
# settings.py
ITEM_PIPELINES = {
'curzon_scraper.pipelines.CurzonScraperFilterPipeline': 300,
'curzon_scraper.pipelines.CurzonScraperAlgoliaPipeline': 350,
}Creating a Spider
import scrapy, json, time, re
from curzon_scraper.items import *
class CurzonSpider(scrapy.Spider):
name = 'curzon'
start_urls = ['https://www.curzoncinemas.com/bloomsbury/now-showing']
def parse(self, response):
yield {
'date': '',
'movie': {},
'_geoloc': {},
'place': {},
'times': {},
}
Selectors: CSS vs Xpath

Selectors: CSS vs Xpath
| Goal | CSS 3 | XPATH |
|---|---|---|
| All Elements | * | //* |
| All div Elements | div | //div |
| All child elements | div > * | //div/* |
| Element By ID | #foo | //*[@id=’foo’] |
| Element By Class | .foo | //*[contains(@class,’foo’)] |
| Element With Attribute | *[title] | //*[@title] |
| All <div> with an <a> child | Not possible | //div[a] |
| First Child of All <div> | div > *:first-child | //div/*[0] |
| Next Element | div + * | //div/following-sibling::*[0] |
In a Nutshell
-
CSS is faster
-
Easier to guess from page-inspection
- More readable

CSS
LESS COOLEST
Live Scraping
CSS
LES COOLEST
Questions?
CSS
LES COOLEST
An Introduction to Scrapy
By Jeremy Gotteland


