Imitation Learning
Johannes Busch
Machine Learning for Robotics - SuSe 24
Learning, Adaptive Systems, and Robotics (LASR) Lab
Practice 12:


v1.0
Imitation Learning
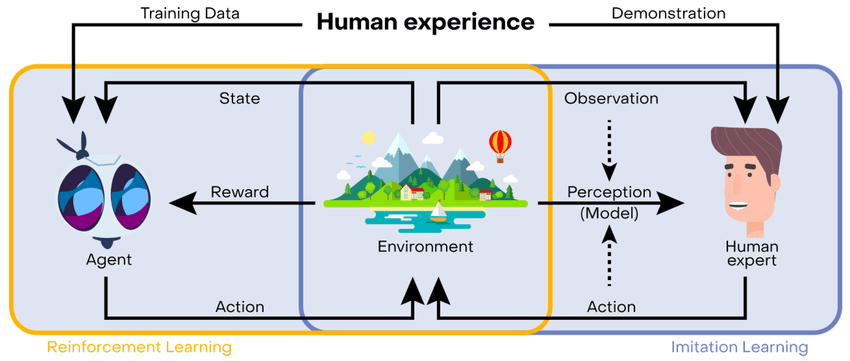
- In Imitation Learning we learn policies from expert data instead of generating data from interaction (RL).
- Expert data can be expensive to obtain.d
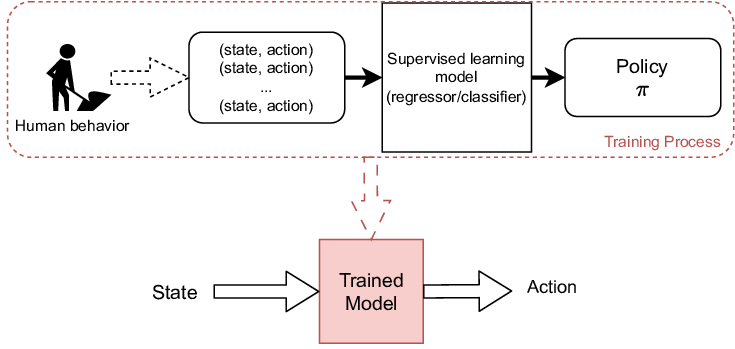
Behavior Cloning
- Behavior Cloning uses SL to learn a policy: action = f(state) from a dataset of demonstrations (state, action).
- For this we have to rely on high-quality data.
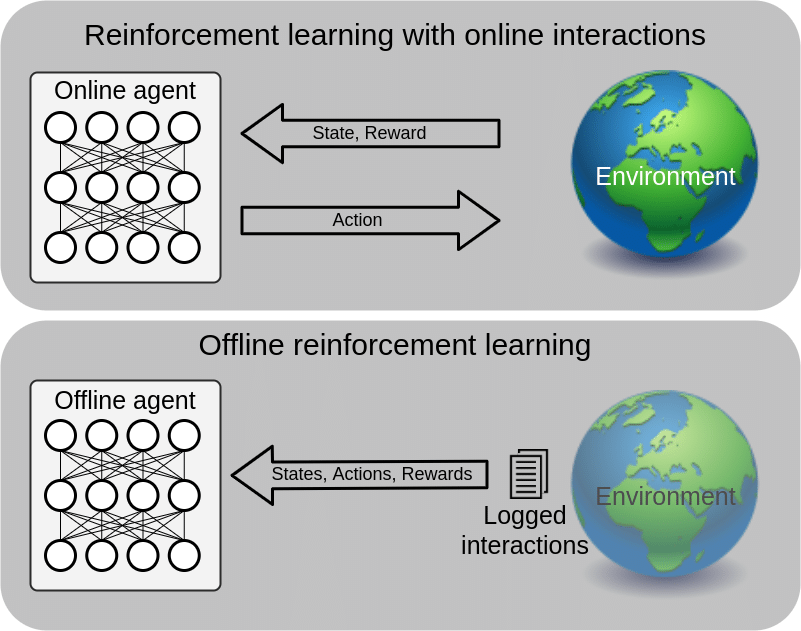
Offline Reinforcement Learning
- Offline RL combines ideas from RL and IL.
- It uses datasets of sub-optimal demonstrations (state, action, reward) to extract high-performing policies.
1.0:
- Offline RL combines ideas from RL and IL.
- It uses datasets of sub-optimal demonstrations (state, action, reward) to extract high-performing policies.
E11_ImitationLearning
By Johannes Busch


