Robot Learning
Ken Nakahara, Cong Wang, Zdravko Dugonjic, Elia Rühle, and Johannes Busch
Learning, Adaptive Systems, and Robotics (LASR) Lab
Research Seminar


v1.0
Structure of the Course
- You will have to find a group of 3 (exceptions possible) students.
- Each group can select a topic to work on.
- Each topic consists of 3-4 papers.
- The group will have to read the papers, write a report, and present the topic in front of the course.
- The presentation, including questions, should take about 45 minutes.
- The presentation/report should contain:
- Explanation of the provided papers.
- Information on additional papers that fit the respective topic.
- A comparison/Analysis of common patters of the papers.
- Discussion of the topic.
- We will propose a number of topics, but feel free to propose your own.
Evaluation and Grading
- Both the presentation and the report will be graded individually.
- Every group will partner up with a second group. The groups will
- be tasked to lead the question round after the presentation of the other group.
- write a review of the report of the respective other group. The final grading will be done by the course supervisors, but the reviews will be taken into account.
- Attendance will be checked and is mandatory for passing the course.
Schedule
- The seminars will take place from 13.05-15.07, which leaves the first group 4 weeks to prepare. Every seminar will consist of two presentations with questions.
- Please sign up by adding your group the Calendar we will publish on Opal today.
- Put in the topic and the 3 team members.
- Do not input the same topic twice. If you really want to have a specific topic, you can talk to us and we will find a solution.
- If possible, try to reduce the number of events by filling up the second time slot of a date that has the first slot already taken.
- Do not delete other entries.
Deadlines
- Report: 07.07.25
- Review: 30.08.25
Available Topics
Skill-Learning
Papers:
Pertsch, et. al. - Accelerating Reinforcement Learning with Learned Skill Priors
Eysenbach, et. al. - Diversity is All You Need: Learning Skills without a Reward Function
Mishra, et. al. - Generative Skill Chaining: Long-Horizon Skill Planning with Diffusion Models
Liang, et. al. - SkillDiffuser: Interpretable Hierarchical Planning via Skill Abstractions in Diffusion-Based Task Execution
Goal:
The word skill in decision making is used in a broad sense. This work should illuminate and structure the different meanings and show how ideas are connected.
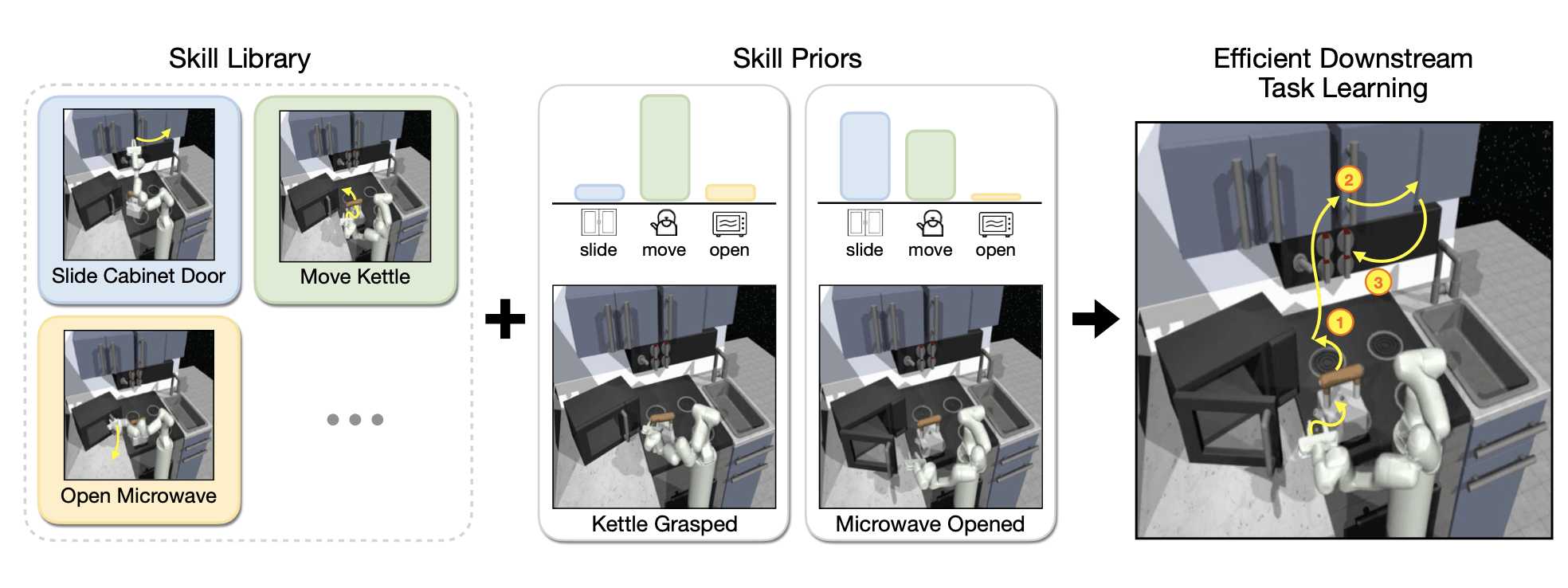
Source: Pertsch, et. al.
Latent World Models
Papers:
Hafner, et. al. - Learning Latent Dynamics for Planning from Pixels
Hafner, et. al. - Dream to Control: Learning Behaviors by Latent Imagination
Hafner, et. al. - Mastering Atari with Discrete World Models
Hafner, et. al. - Mastering Diverse Domains through World Models
Goal:
Show the evolution of Latent World Models.
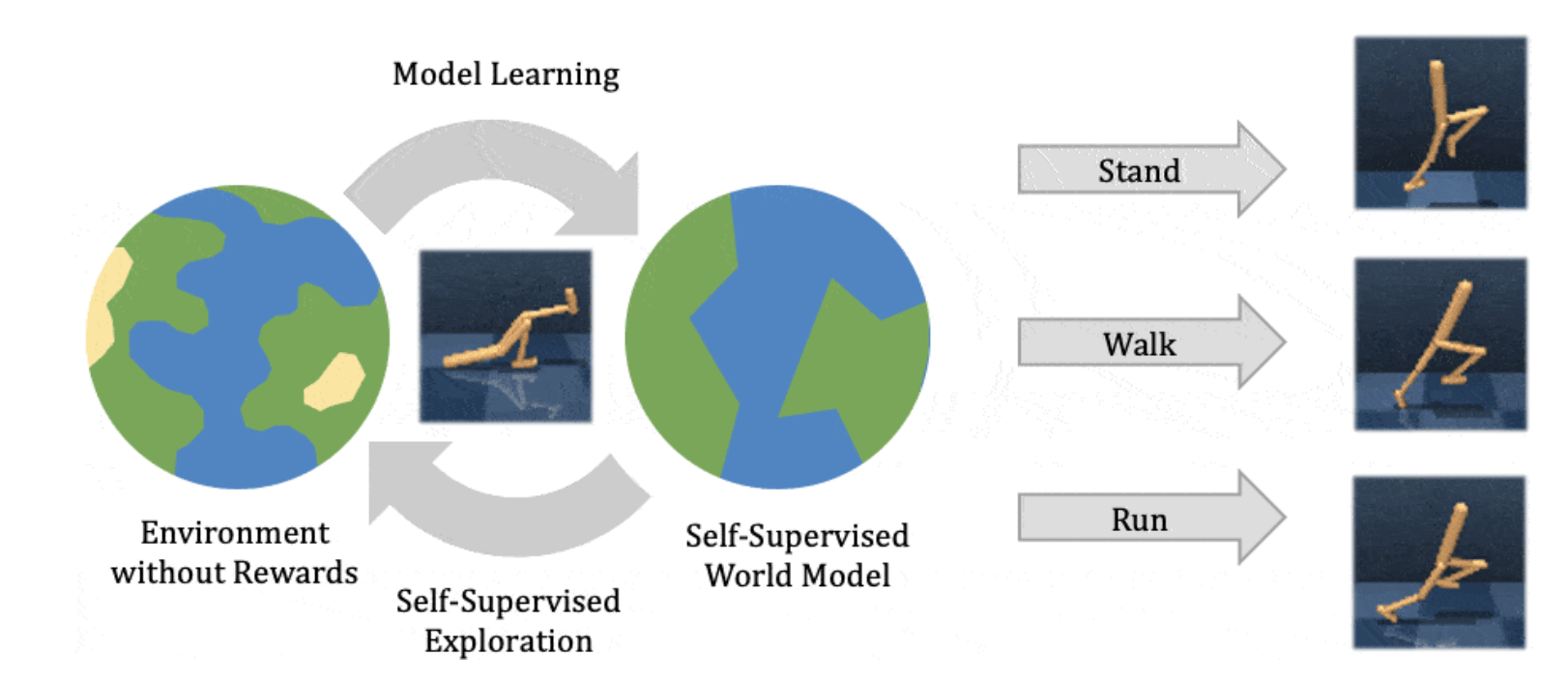
Source: Hafner, et. al.
Diffusion-Generative Models
Papers:
Ho, et. al. - Denoising Diffusion Probabilistic Models
Song, et. al. - Denoising Diffusion Implicit Models
Song, et. al. - Consistency Models
Karras, et. al. - Elucidating the Design Space of Diffusion-Based Generative Models
Goal:
Explain the different mathematical formulations of diffusion models and show how they can be unified.
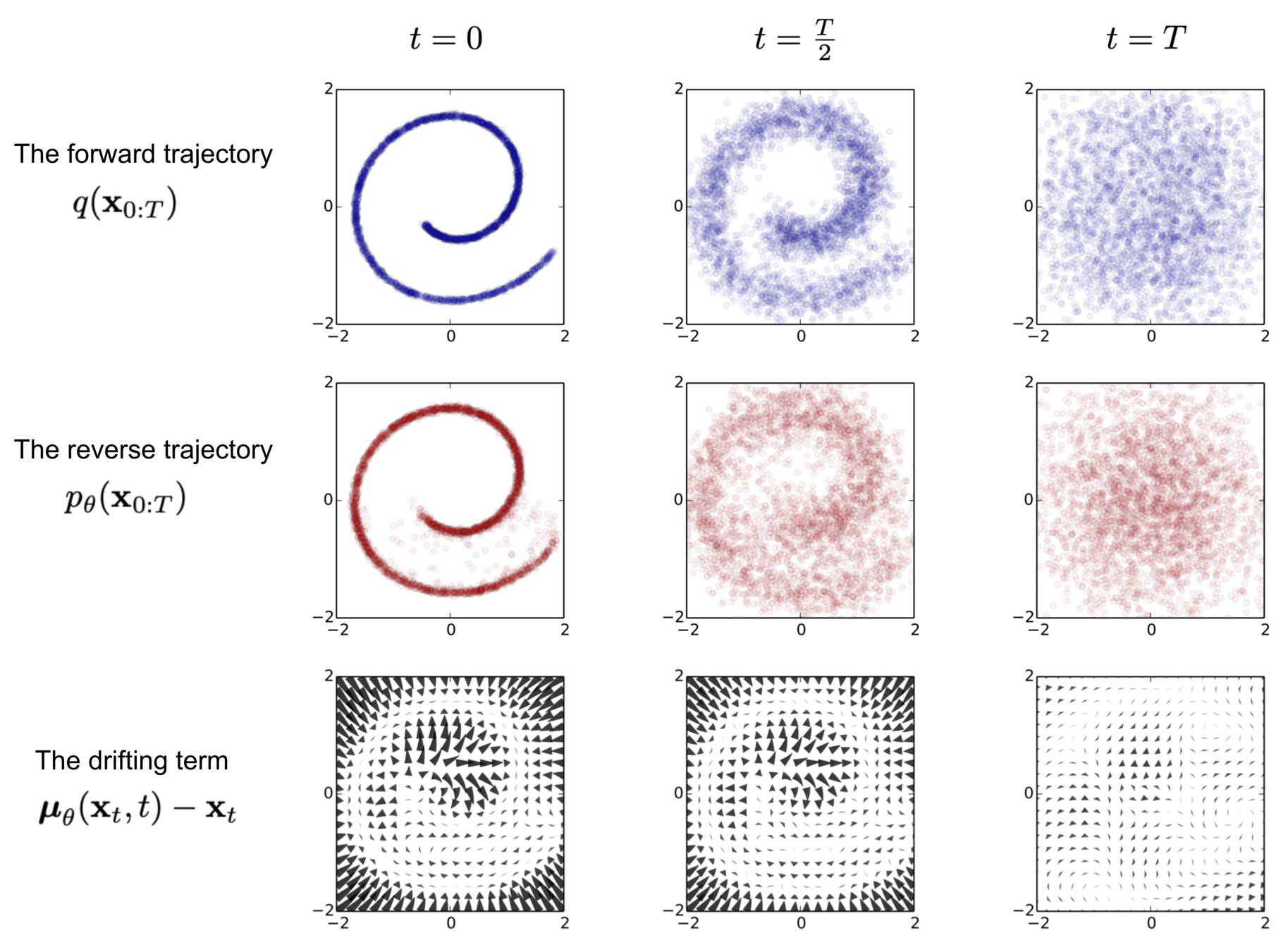
Source: Sohl-Dickstein, et. al.
Diffusion Policies
Papers:
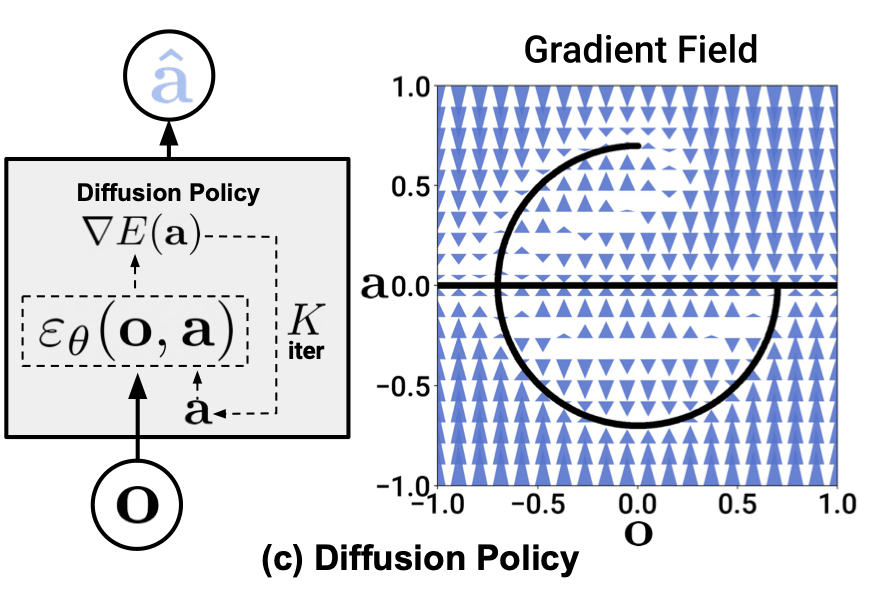
Chi, et. al. - Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Wang, et. al. - Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Lai, et. al. - Diffusion-Reward Adversarial Imitation Learning
Ren, et. al. - Diffusion Policy Policy Optimization
Goal:
Explain and contrast different approaches how diffusion models can be used as expressive policies for decision making.
Source: Chi, et. al.
Generative World Modelling
Papers:
Alonso, et al. - Diffusion for World Modeling: Visual Details Matter in Atari
Bruce, et al. - Genie: Generative Interactive Environments
Savov, et al. - Exploration-Driven Generative Interactive Environments
Russel, et al. - GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Goal:
Outline how generative models can be used to model the world. Highlight how these findings relate to training general capable agents.
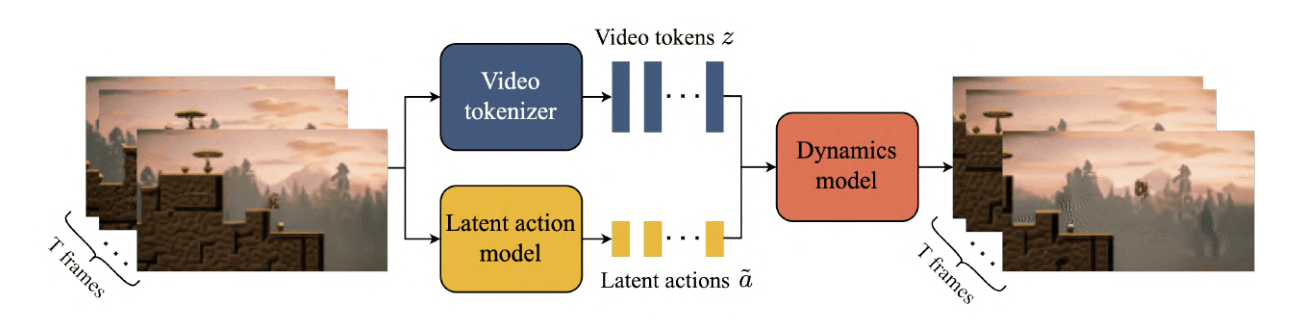
Source: Bruce, et al.
Augmenting Reinforcement Learning with Self-Play
Papers:
Silver, et al. - Mastering the game of Go with deep neural networks and tree search
Vinyals et al. - Grandmaster level in StarCraft II using multi-agent reinforcement learning
Perolat, et al. - Mastering the game of stratego with model-free multiagent reinforcement learning
Berner et al. - Dota 2 with Large Scale Deep Reinforcement Learning
Goal:
Explain how reinforcement learning can benefit from agents playing against themselves to achieve super-human performance.
Source: Vinyals, et al.
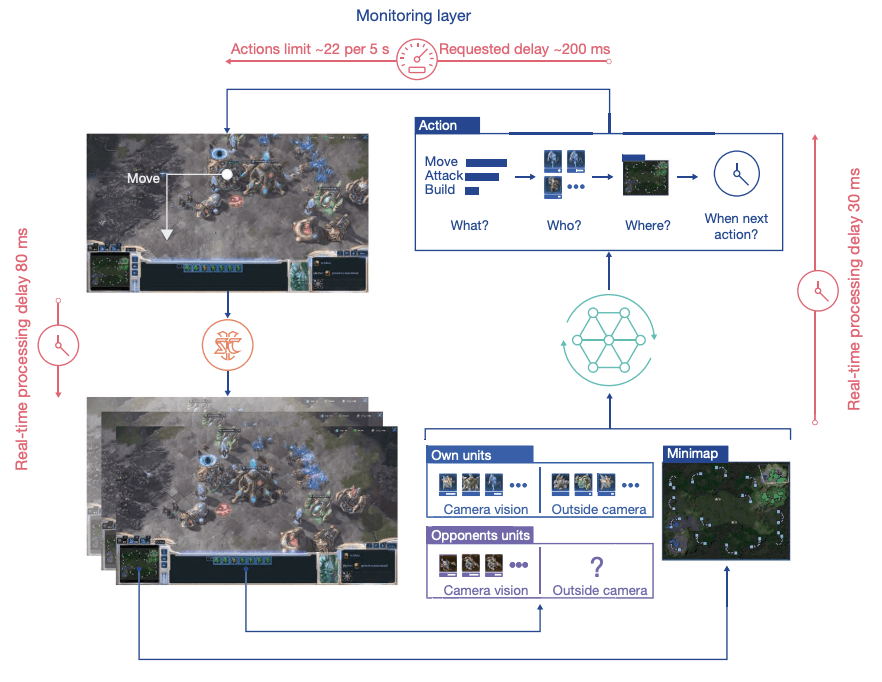
Unsupervised Environment Design for Autocurricula
Papers:
Samvelyan, et al. - MAESTRO - Open-ended Environment Design For Multiagent Reinforcement Learning
Parker-Holder, et al. - Evolving curricula with regret-based environment design
Rutherford, et al. - No Regrets: Investigating and Improving Regret Approximations for Curriculum Discovery
Dennis, et al. - Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design
Goal:
Understand how unsupervised environment design paved the way to open-ended learning.
Source: Rutherford, et al.

Joint Embedding Predictive Architecture for Self-Supervised Learning
Papers:
Assran, et al. - Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Bardes, et al. - MC-JEPA: A Joint-Embedding Predictive Architecture for Self-Supervised Learning of Motion and Content Features
Drozdov, et al. - Video Representation Learning with Joint-Embedding Predictive Architectures
Skenderi, et al. - Graph-level Representation Learning with Joint-Embedding Predictive Architectures
Goal:
Understand how the JEPA-approach differs from current generative models and how it can be used for different modalities.
Source: Assran, et al.
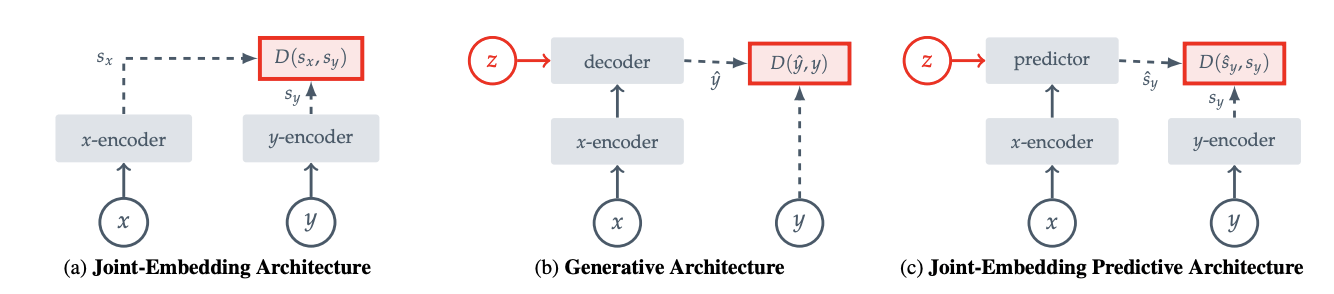
Mental States Attribution to Robotics
Papers:
Thellman et al. - Mental State Attribution to Robots: A Systematic Review of Conceptions, Methods, and Findings
Thellman et al. - Do You See what I See? Tracking the Perceptual Beliefs of Robots
Thellman et al. - Does the Robot Know It Is Being Distracted? Attitudinal and Behavioral Consequences of Second-Order Mental State Attribution in HRI

Source: Thellman et al.
Unexpected Robot Behavior
Papers:
Schadenberg et al. - “I See What You Did There”: Understanding People’s Social Perception of a Robot and Its Predictability
Abe et al. - Human Understanding and Perception of Unanticipated Robot Action in the Context of Physical Interaction
Honig et al. - Understanding and Resolving Failures in Human-Robot Interaction: Literature Review and Model Development
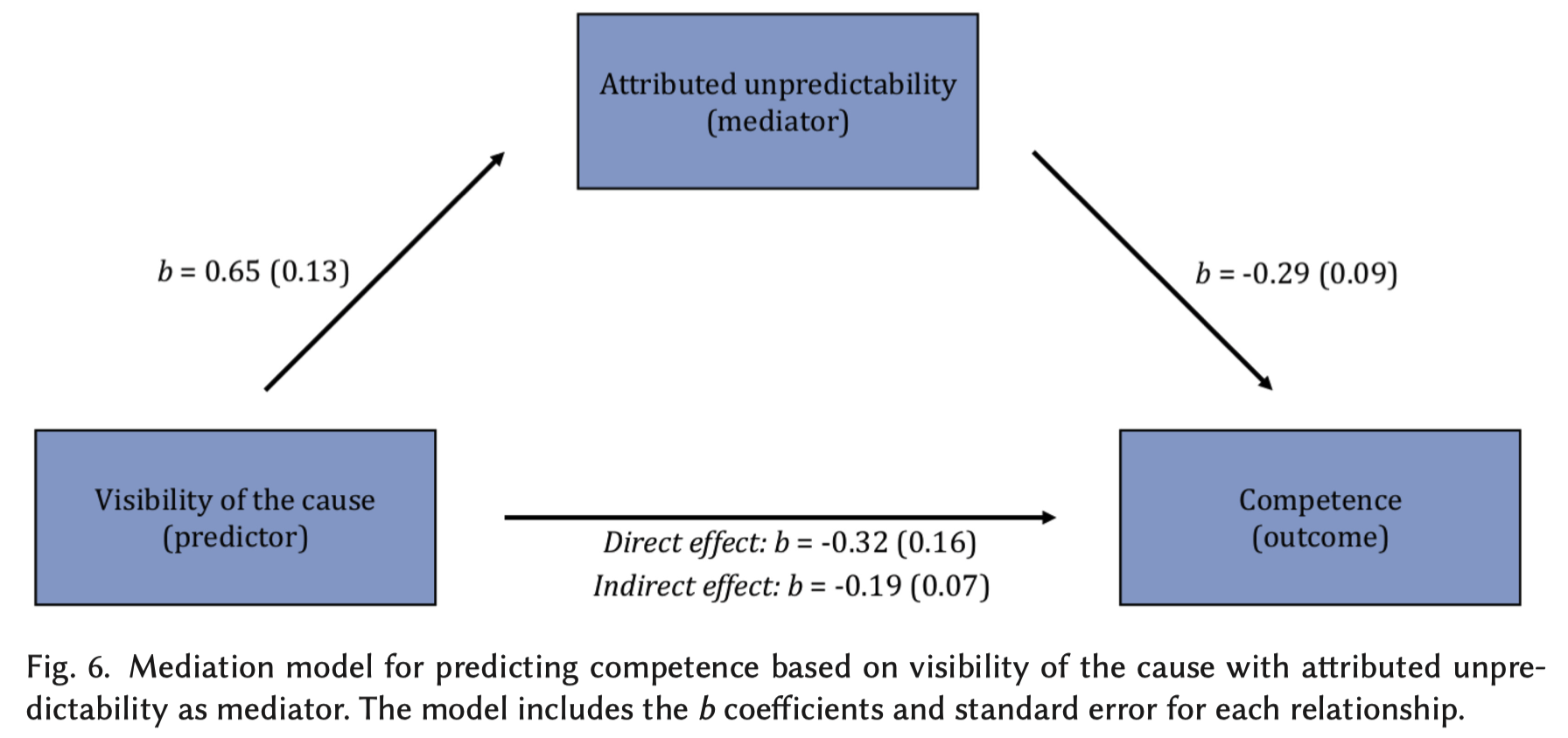
Source: Schadenberg et al.
Robot Intent Expression and Communication
Papers:
Prascher et al. - How to Communicate Robot Motion Intent: A Scoping Review
Bodden et al. -A flexible optimization-based method for synthesizing intent-expressive robot arm motion
Yi et al. - Your Way Or My Way: Improving Human-Robot Co-Navigation Through Robot Intent and Pedestrian Prediction Visualisations.
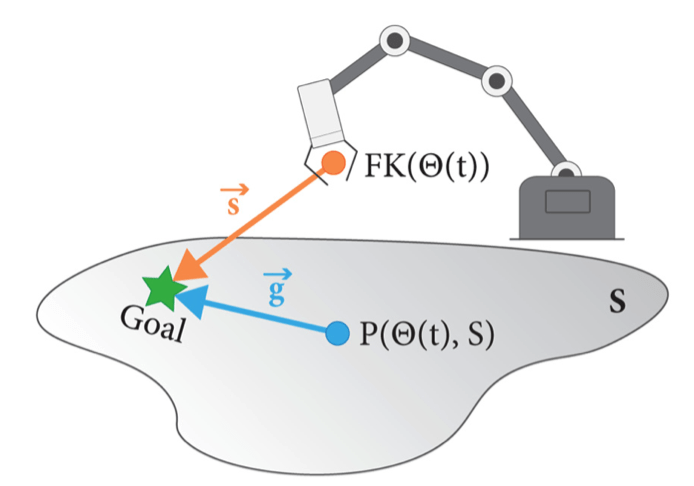
Source: Bodden et al.
Knowledge Representation in Service Robotics
Papers:
Beetz et al. - Know Rob 2.0 — A 2nd Generation Knowledge Processing Framework for Cognition-Enabled Robotic Agents
Hughes et al. - Foundations of spatial perception for robotics: Hierarchical representations and real-time systems
Paulius et al. - A Survey of Knowledge Representation in Service Robotics
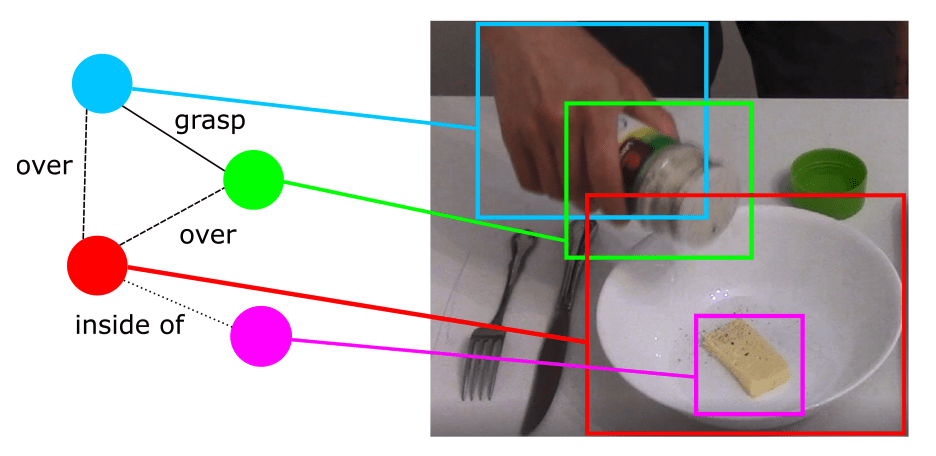
Source: Paulius et al.
Evaluation Methods for Robot Explainability
Papers:
Wachowiak et al. - A Survey of Evaluation Methods and Metrics for Explanations in Human–Robot Interaction (HRI)
Doshi-Velez et al. - Towards A Rigorous Science of Interpretable Machine Learning
Sakai et al. - Implementation and Evaluation of Algorithms for Realizing Explainable Autonomous Robots
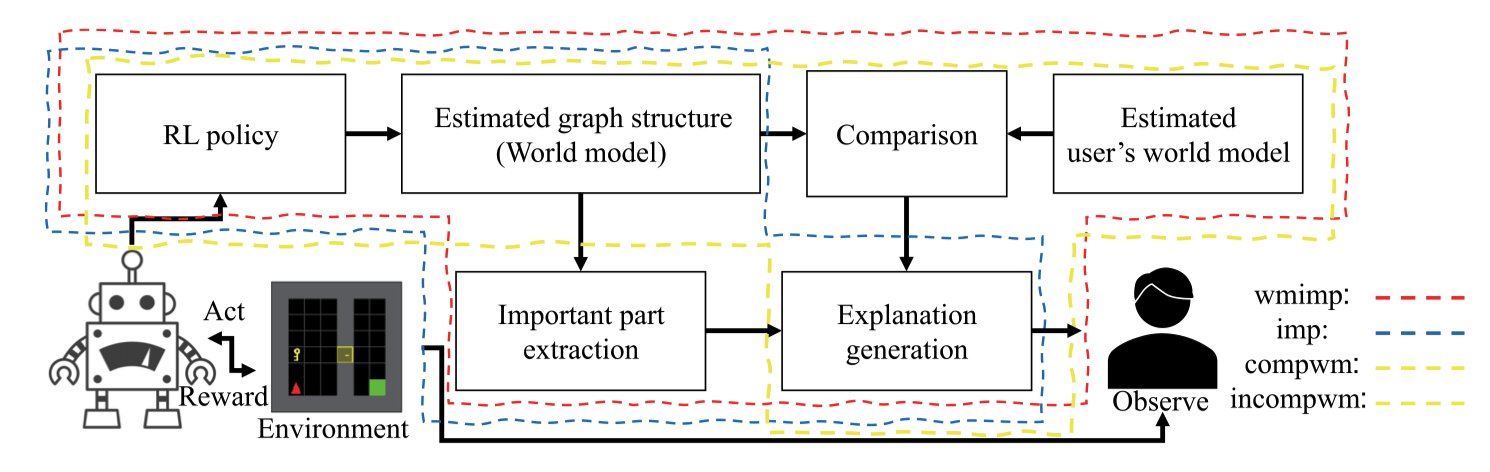
Source: Sakai et al.
Learning Stable Grasping for Any Objects
Papers:
Xu, et al. - LeTac-MPC: Learning Model Predictive Control for Tactile-reactive Grasping
Zhong, et al. - DexGrasp Anything: Towards Universal Robotic Dexterous Grasping with Physics Awareness
Calandra, et al. - More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch
Mahler, et al. - Dex-Net 2.0: Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics
Source: Xu, et al.

Robotic In-hand Rotation and Its Application
Papers:
Qi, et al. - From Simple to Complex Skills: The Case of In-Hand Object Reorientation
Yuan, et al. - Robot synesthesia: In-hand manipulation with visuotactile sensing
Yang, et al. - AnyRotate: Gravity Invariant In-Hand Object Rotation with Sim-to-Real Touch
Suresh, et al. - Neural feels with Neural Fields: Visuo-tactile Perception for In-Hand Manipulation
Source: Qi, et al.

In-hand Manipulation in Various Scenarios
Papers:
Funabashi, et al. - Focused Blind Switching Manipulation Based on Constrained and Regional Touch States of Multi-Fingered Hand Using Deep Learning
Yin, et al. - Learning In-Hand Translation Using Tactile Skin With Shear and Normal Force Sensing
Wang, et al. - Lessons from Learning to Spin “Pens”
OpenAI - Learning dexterous in-hand manipulation
Source: Funabashi, et al.

Bimanual Manipulation with Multi-fingered Robotic Hands
Papers:
Lin, et al. - Learning Visuotactile Skills with Two Multifingered Hands
Chen, et al. - Bi-DexHands: Towards Human-Level Bimanual Dexterous Manipulation
Shaw, et al. - Bimanual Dexterity for Complex Tasks
Lin, et al. - Twisting Lids Off with Two Hands
Source: Lin, et al.
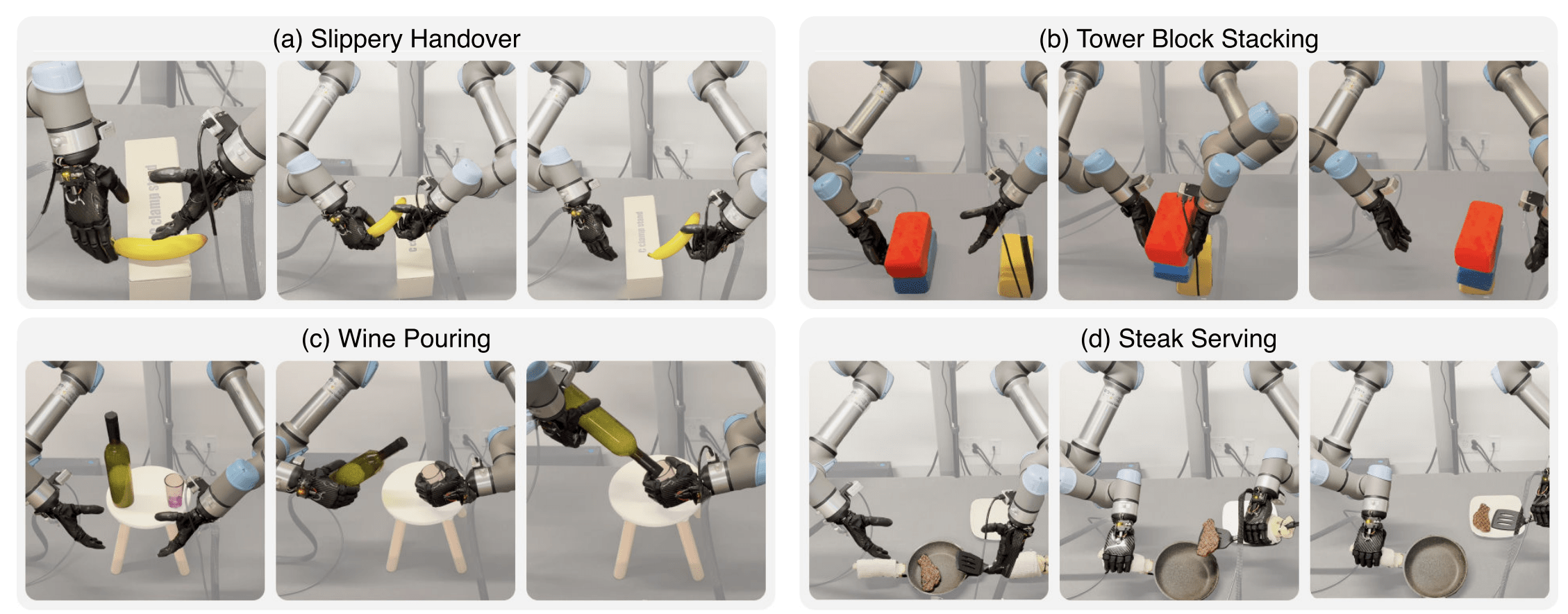
Manipulation Tasks on Humanoids
Papers:
Li, et al. - OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
Ze, et al. - Generalizable Humanoid Manipulation with 3D Diffusion Policies
Lin, et al. - Sim-to-Real Reinforcement Learning for Vision-Based Dexterous Manipulation on Humanoids
Qiu, et al. - Humanoid Policy ∼ Human Policy
Source: Li, et al.

Robot Foundation Models
Papers:
Physical Intelligence - π0: A Vision-Language-Action Flow Model for General Robot Control
Octo Model Team - Octo: An Open-Source Generalist Robot Policy
Kawaharazuka, et al. - Real-world robot applications of foundation models: a review
Source: Physical Intelligence
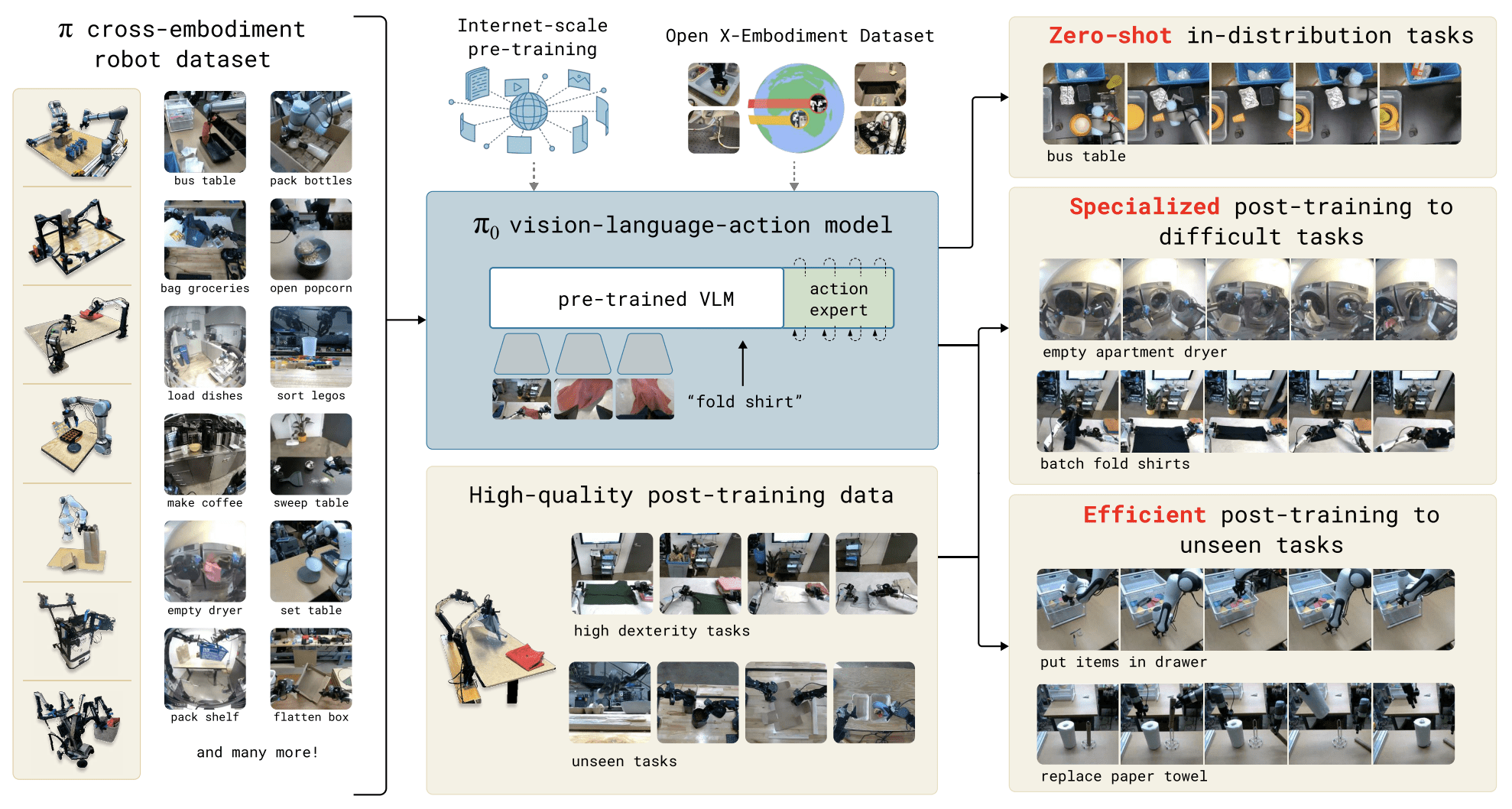
Neural Representations and Emerging Vision Capabilities
Papers:
Tiwary, et al. - What if Eye...? Computationally Recreating Vision Evolution
Tang, et al. - Emergent Correspondence from Image Diffusion
Zholus, et al. - TAPNext: Tracking Any Point (TAP) as Next Token Prediction
Eslami, et al. - Neural Scene Representation and Rendering
Source: https://eyes.mit.edu/what-if/

Learning Simulation from Data
Papers:
Alonso, et al. - Diffusion for World Modeling: Visual Details Matter in Atari
Kanervisto, et al. - World and Human Action Models towards gameplay ideation
Chen, et al. - Model as a Game: On Numerical and Spatial Consistency for Generative Games
Source: https://diamond-wm.github.io/
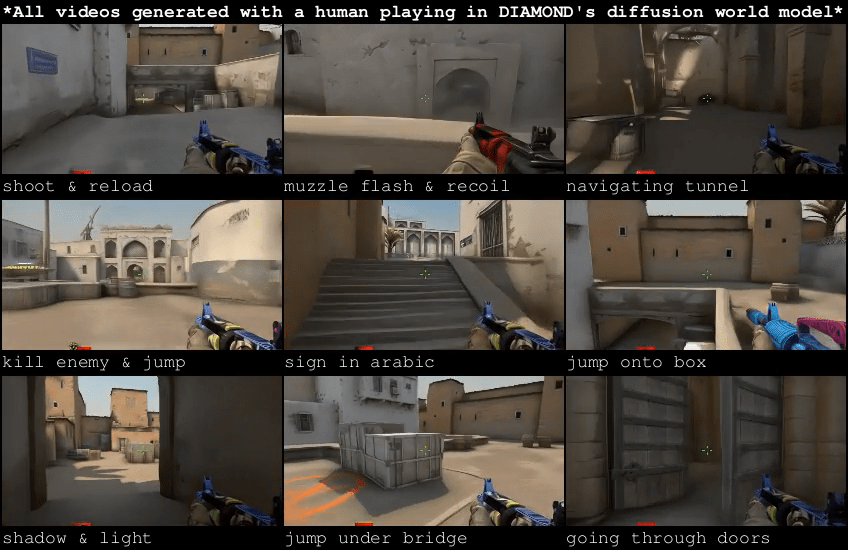
Understanding Physics Through Video
Papers:
Liu, et al. - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Li, et al. - Sora Generates Videos with Stunning Geometrical Consistency
Radford, et al. - Learning Transferable Visual Models From Natural Language Supervision
Motamed, et al. - Do generative video models understand physical principles?
Source: https://physics-iq.github.io/
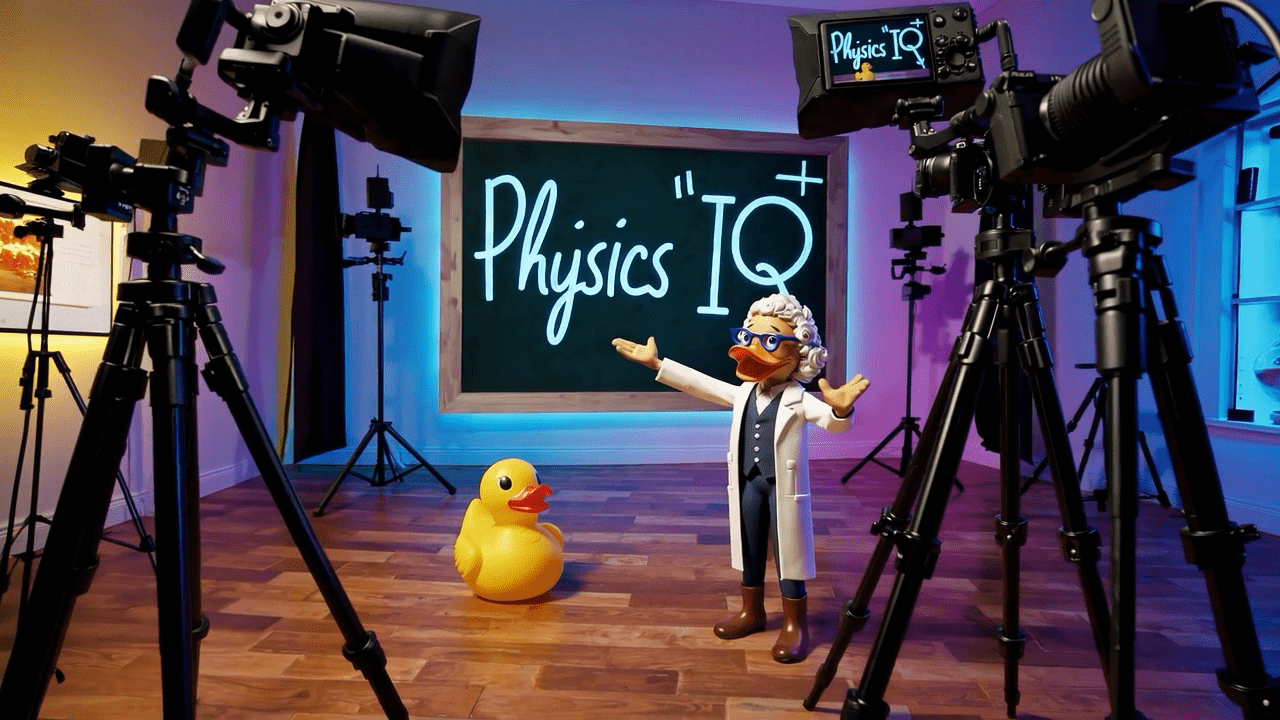
Deformable Object Representations
Papers:
Pumarola, et al. - D-NeRF: Neural Radiance Fields for Dynamic Scenes
Wu, et al. - 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering
Liu, et al. - LGS: A Light-weight 4D Gaussian Splatting for Efficient Surgical Scene Reconstruction
Cao, et al. - HexPlane: A Fast Representation for Dynamic Scenes

Research Seminar SuSe25
By Johannes Busch


