Transparent, adaptable, and reproducible data analyses for oncology - Snakemake, Datavzrd, Vembrane and beyond
Johannes Köster
2026
University of Duisburg-Essen
- check computational validity
- apply same analysis to new data
- check methodological validity
- understand analysis
Data analysis
Reproducibility
Transparency
- modify analysis
- extend analysis
Adaptability
>1.6 million downloads since 2015
>3000 citations
>14 citations per week in 2024


dataset
results
dataset
dataset
dataset
dataset
dataset
Define workflows
in terms of rules
Define workflows
in terms of rules
rule mytask:
input:
"path/to/{dataset}.txt"
output:
"result/{dataset}.txt"
script:
"scripts/myscript.R"
rule myfiltration:
input:
"result/{dataset}.txt"
output:
"result/{dataset}.filtered.txt"
shell:
"mycommand {input} > {output}"
rule aggregate:
input:
"results/dataset1.filtered.txt",
"results/dataset2.filtered.txt"
output:
"plots/myplot.pdf"
script:
"scripts/myplot.R"Define workflows
in terms of rules
Define workflows
in terms of rules
rule mytask:
input:
"data/{sample}.txt"
output:
"result/{sample}.txt"
shell:
"some-tool {input} > {output}"rule name
how to create output from input
define
- input
- output
- log files
- parameters
- resources
rule mytask:
input:
"path/to/{dataset}.txt"
output:
"result/{dataset}.txt"
script:
"scripts/myscript.R"
rule myfiltration:
input:
"result/{dataset}.txt"
output:
"result/{dataset}.filtered.txt"
shell:
"mycommand {input} > {output}"
rule aggregate:
input:
"results/dataset1.filtered.txt",
"results/dataset2.filtered.txt"
output:
"plots/myplot.pdf"
script:
"scripts/myplot.R"Automatic inference of DAG of jobs

Boilerplate-free integration of scripts
rule mytask:
input:
"data/{sample}.txt"
output:
"result/{sample}.txt"
script:
"scripts/myscript.py"reusable scripts:
- Python
- R
- Julia
- Rust
- Bash
- Xonsh
- Hy
Reusable wrappers
rule map_reads:
input:
"{sample}.bam"
output:
"{sample}.sorted.bam"
wrapper:
"0.22.0/bio/samtools/sort"reuseable wrappers from central repository
Reusable wrappers
Self-contained HTML reports
Plugins
Many more features
- dynamic DAG rewiring
- service jobs (providing sockets, loading databases, or ramdisks)
- semantic helper functions for minimizing boilerplate code
- fallible rules
- caching of shared results across workflows
- transparent handling of remote storage
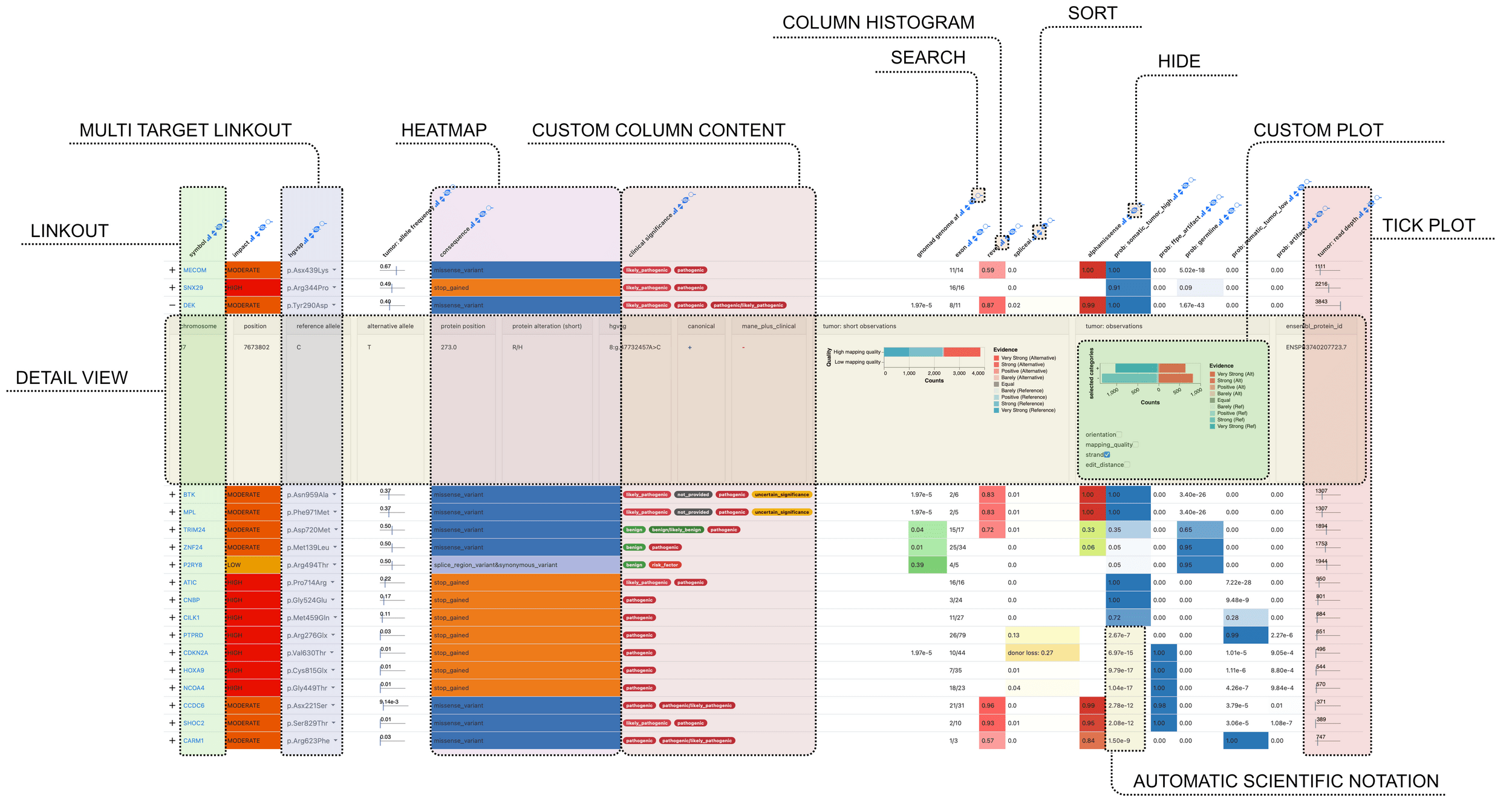
Tables are the central entity
in data analysis

https://datavzrd.github.io
Not always a single table
oncoprint + individual variant calls
differentially expressed genes + expression matrix
https://datavzrd.github.io
Not always just a table
oncoprint + individual variant calls +
differentially expressed genes + expression matrix +

https://datavzrd.github.io
State of the art
Individual tables (tsv, excel) and plots:
- easy to publish
- limited interactivity
- no jumping between corresponding items
Web applications (custom, shiny, ...):
- running server (or local installation)
- implementation overhead
- long-term maintenance is challenging
https://datavzrd.github.io
The problem
Input:
- set of tables
- relations between tables
- set of rendering definitions
Output:
portable interactive visual presentation
https://datavzrd.github.io

https://datavzrd.github.io
Datavzrd
https://datavzrd.github.io
Datavzrd
https://datavzrd.github.io
Datavzrd + Snakemake
rule datavzrd:
input:
config="resources/{sample}.datavzrd.yaml",
table="data/{sample}.tsv",
output:
report(
directory("results/datavzrd-report/{sample}"),
htmlindex="index.html",
),
wrapper:
"v4.6.0/utils/datavzrd"https://datavzrd.github.io
Vembrane


harmonize
- variant filtration
- variant prioritization
- variant exchange (FHIR)
https://vembrane.github.io
(not {'risk_factor','pathogenic', 'drug_response'}.isdisjoint(ANN['CLIN_SIG'])) and
(ANN['IMPACT'] in {'LOW', 'MODERATE', 'HIGH'}) and
(ANN['REVEL'] is NA or ANN['REVEL'] >= 0.5)pathogenic/risk-factor/drug-response (vembrane filter)
relevant VAFs (vembrane filter)
(FORMAT['AF']['tumor'] >= 0.05 and (ANN['gnomADg_AF'] is NA or ANN['gnomADg_AF'] < 0.01))desc(quantize(max(FORMAT['AF'][sample] for sample in SAMPLES), 1 / 3)), \
desc(ANN["REVEL"]), \
desc(FORMAT['AF']['tumor'])sort by descending relevance (vembrane sort)
Vembrane
Adaptable and unified small-variant/structural-variant/fusion calling on any scenario



Snakemake + Datavzrd + Vembrane + Varlociraptor =
reference pipeline project
samples:
jane:
sex: female
somatic-effective-mutation-rate: 1e-10
tumor:
inheritance:
clonal:
from: jane
contamination:
by: jane
fraction: 0.1
somatic-effective-mutation-rate: 1e-6
relapse:
inheritance:
clonal:
from: jane
contamination:
by: jane
fraction: 0.2
somatic-effective-mutation-rate: 1e-6expressions:
somatic_tumor: "jane:0.0 & tumor:]0.0,1.0]"
events:
germline: "jane:0.5 | jane:1.0"
somatic: "jane:]0.0,0.5["
somatic_tumor_no_increase: "$somatic_tumor & l2fc(relapse,tumor) < 1"
somatic_tumor_increase: "$somatic_tumor & l2fc(relapse,tumor) >= 1"
somatic_relapse: "jane:0.0 & tumor:0.0 & relapse:]0.0,1.0]"
https://varlociraptor.github.io
varlociraptor
Dual use in research and clinics


Conclusion
Snakemake + Datavzrd
generic, transparent, human readable, adaptable, portable, and scalable data analysis and visualization
Vembrane
Unified DSL for filtering, sorting and transforming genomic variants/fusions/CNVs
Varlociraptor + Pipeline
unified, adaptable small/structural variant calling for any scenario
deck
By Johannes Köster




