J Rogel
Data scientist, physicist, numerical analyst, machine learner, human
Structured in databases
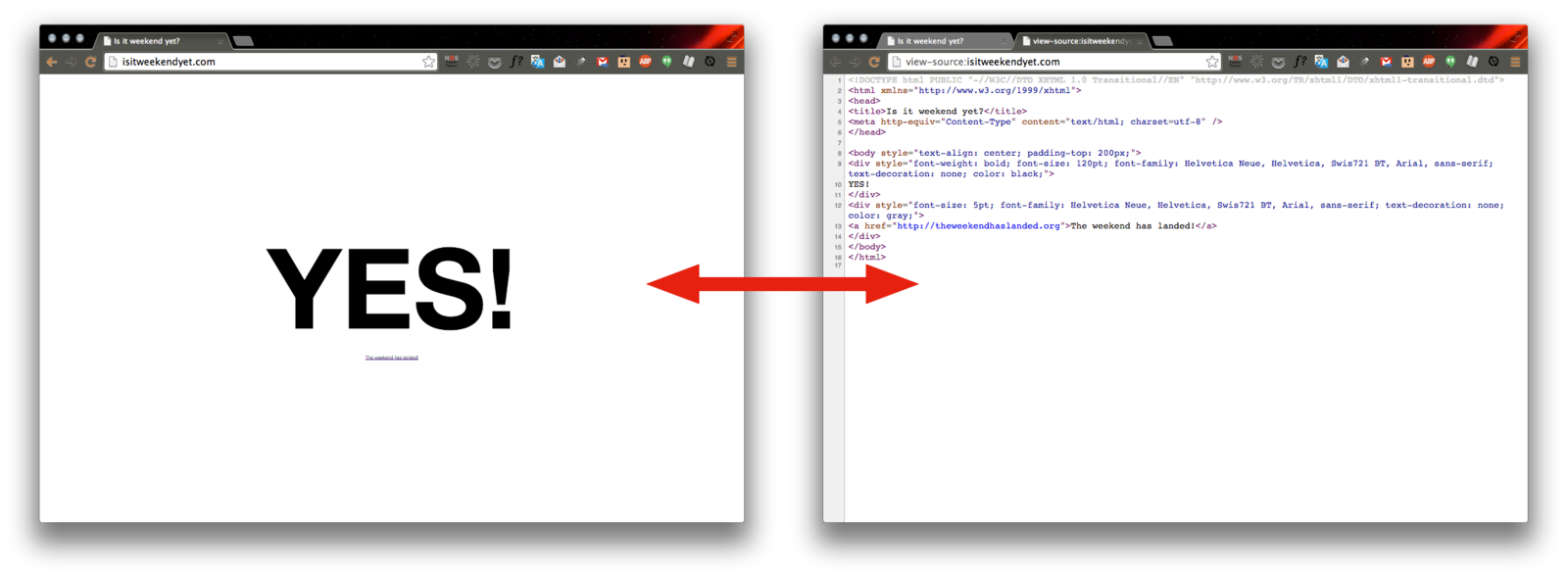
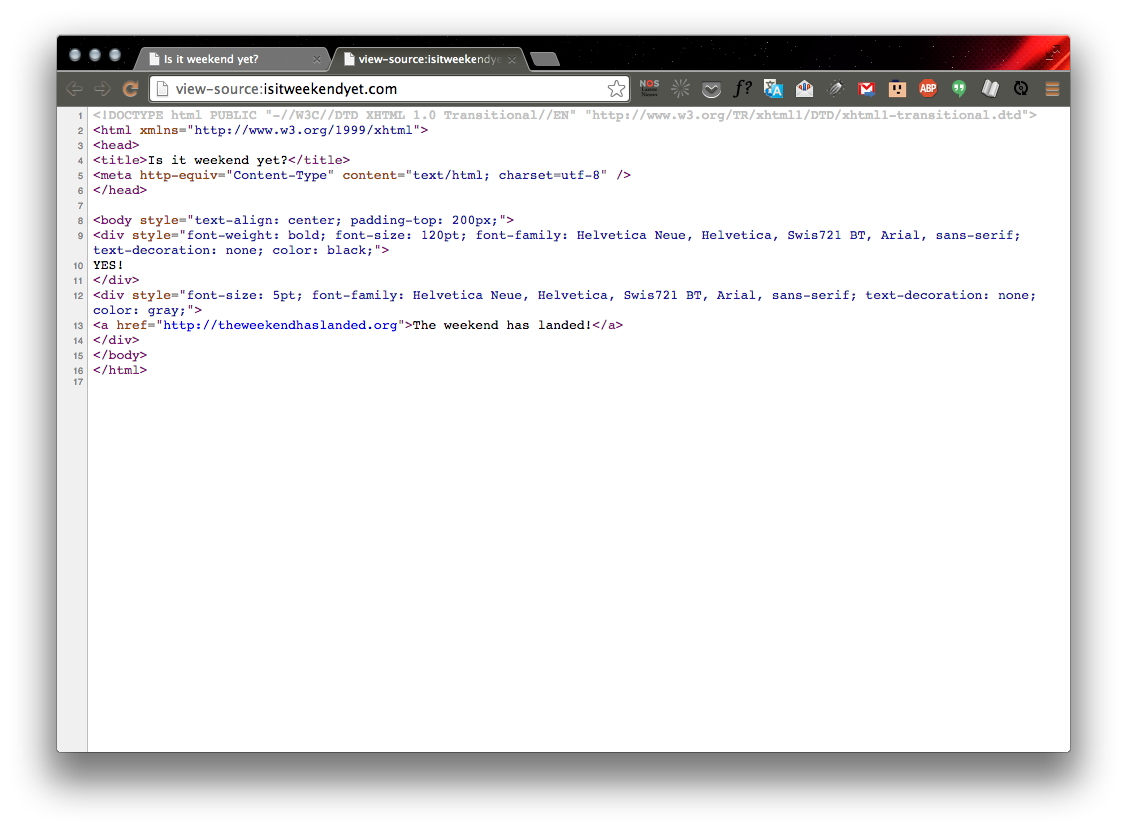
Extracting data from a web page’s source
For example: http://isitweekendyet.com/
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>My First Heading</h1>
<p>My first paragraph.</p>
</body>
</html>

# Python 3
from urllib.request import urlopen
url = 'http://isitweekendyet.com/'
pageSource = urlopen(url).read()
# Python 2
from urllib import urlopen
url = 'http://isitweekendyet.com/'
pageSource = urlopen(url).read()
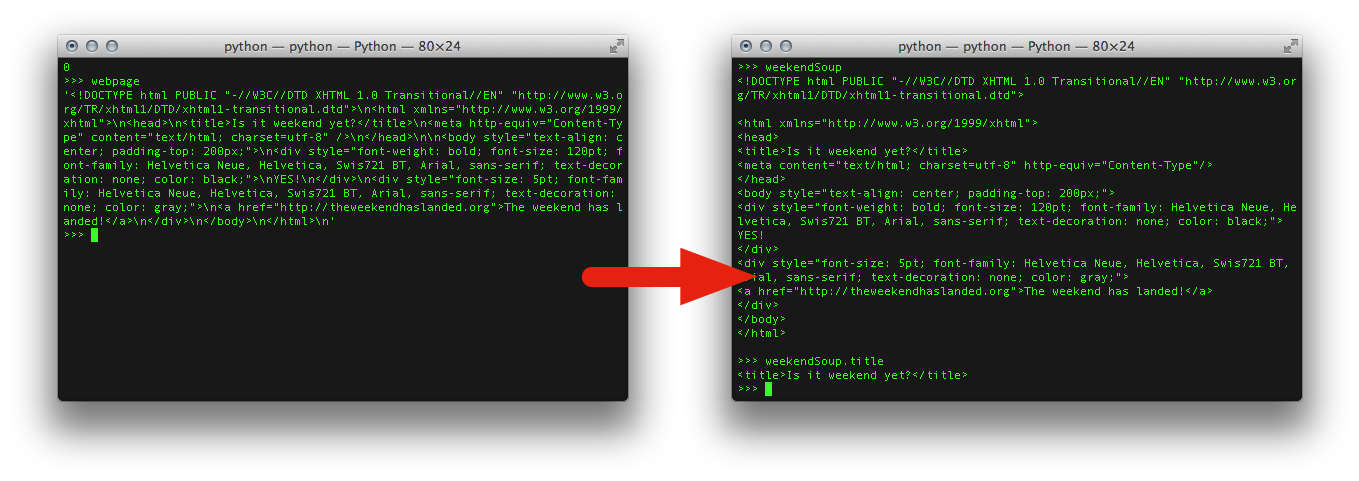
from bs4 import BeautifulSoup
weekendSoup = BeautifulSoup(pageSource, 'lxml')You didn't write that awful page.
You're just trying to get some data out of it.
Beautiful Soup is here to help.
Since 2004, it's been saving programmers hours or days of work on quick-turnaround screen scraping projects.http://www.crummy.com/software/BeautifulSoup/

>>> from bs4 import BeautifulSoup
>>> weekendSoup = BeautifulSoup(pageSource, 'lxml')
>>> weekendSoup.title
<title>Is it weekend yet?</title>
>>> weekendSoup.title.string
u'Is it weekend yet?'
>>> tag = weekendSoup.div
>>> tag
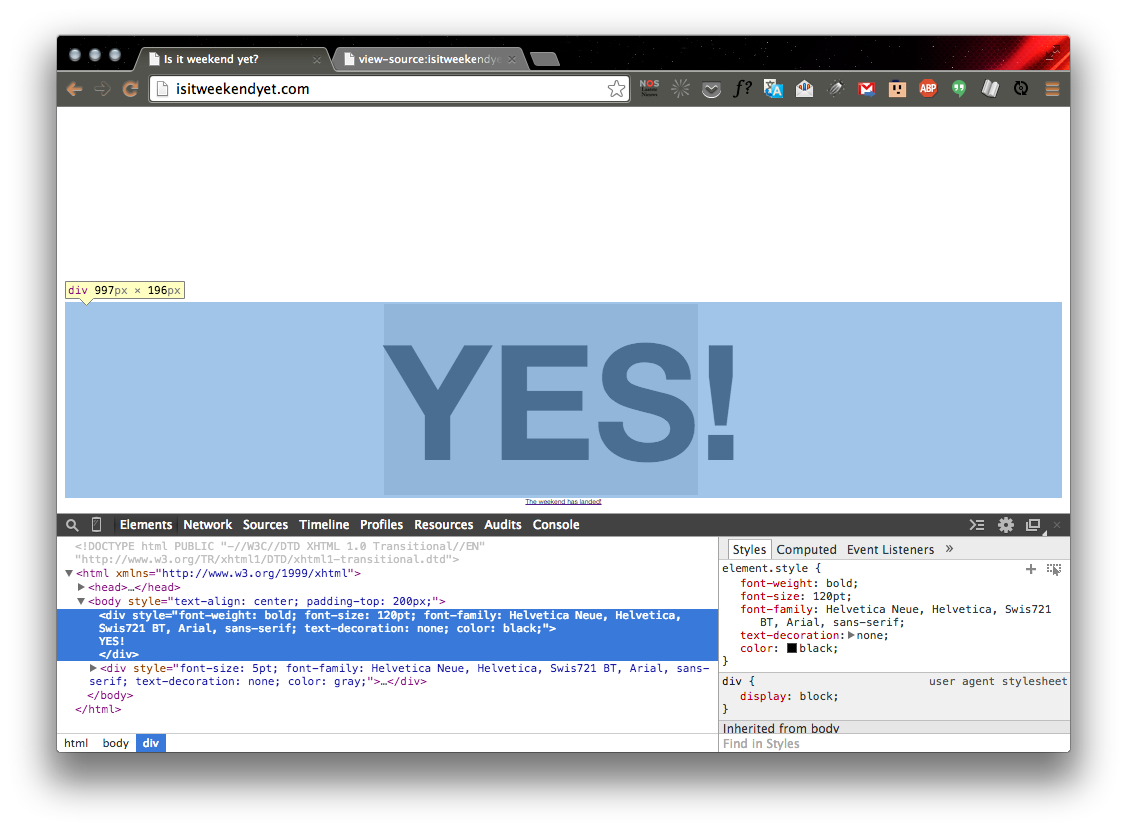
<div style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;">
YES!
</div>
>>> type(tag)
<class 'bs4.element.Tag'> >>> tag.string
u'\nYES!\n'
>>> type(tag.string) <class 'bs4.element.NavigableString'>
>>> type(weekendSoup)weekendSoup.name <class 'bs4.BeautifulSoup'>
>>>u'[document]'
>>> markup = "<b><!--This is a very special message--></b>"
>>> cSoup = BeautifulSoup(markup)
>>> comment = cSoup.b.string
>>> type(comment)
<class 'bs4.element.Comment'>
>>> print(cSoup.b.prettify())
<b>
<!--This is a very special message-->
</b>
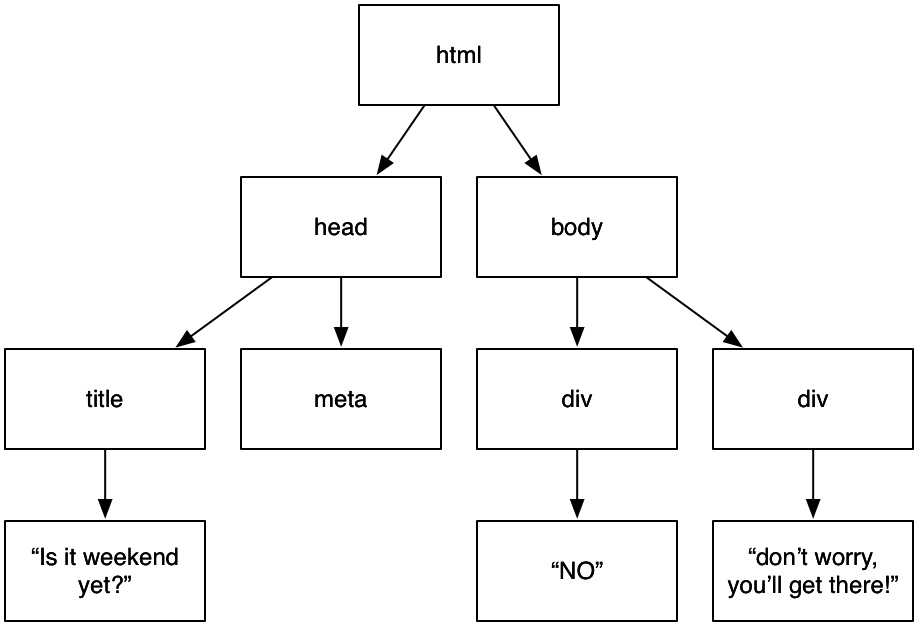
>>> bodyTag = weekendSoup.body
>>> bodyTag.contents
[u'\n', <div class="answer text" id="answer" style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;">
YES!
</div>, u'\n', <div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;">
<a href="http://theweekendhaslanded.org">The weekend has landed!</a>
</div>, u'\n']
<div class="answer text" id="answer" style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;">
YES!
</div>
<div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;">
<a href="http://theweekendhaslanded.org">The weekend has landed!</a>
</div>
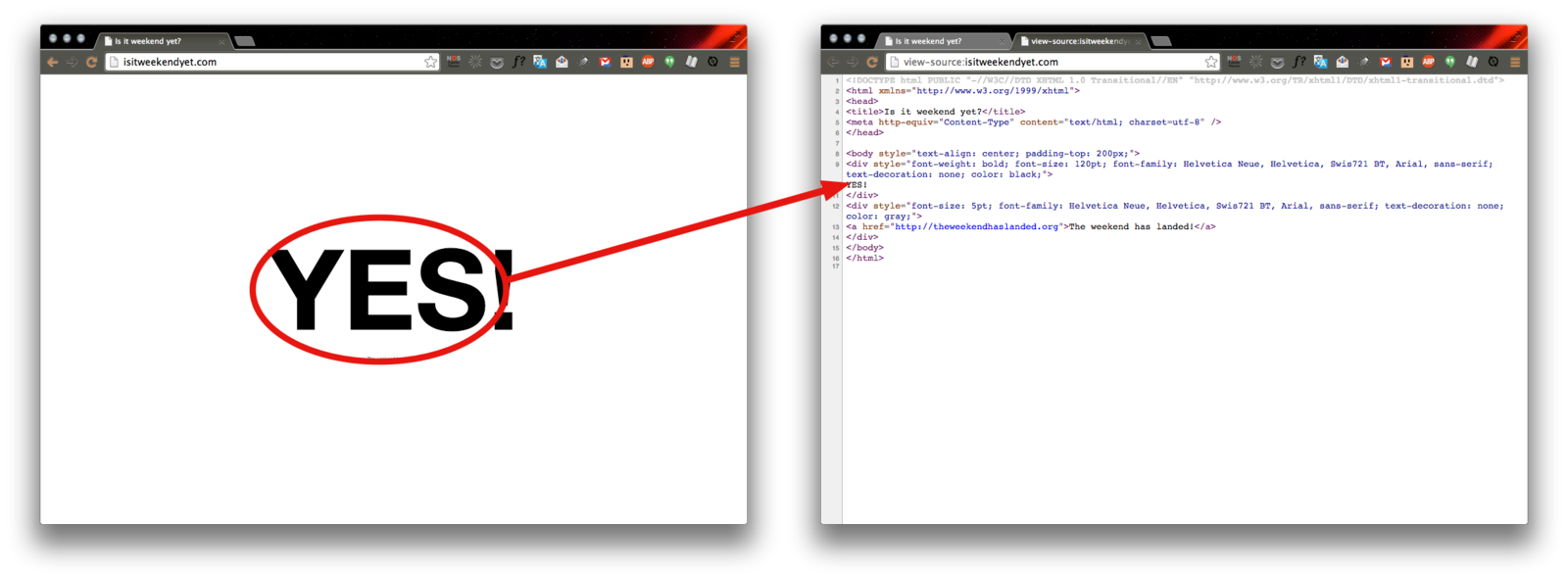
>>> weekendSoup.div.string
u'\nYES!\n'
>>> for ss in weekednSoup.div.stripped_strings:
print(ss)
...
YES!
>>> for d in bodyTag.descendants: print d... <div class="answer text" id="answer" style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;"> YES! </div> YES! <div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;"> <a href="http://theweekendhaslanded.org">The weekend has landed!</a> </div> <a href="http://theweekendhaslanded.org">The weekend has landed!</a> The weekend has landed!
>>> weekendSoup.a.parent.name
u'div'
>>> for p in weekendSoup.a.parents: print p.name
...
div
body
html
[document]
>>> weekendSoup.div.next_sibling
u'\n'
>>> weekendSoup.div.next_sibling.next_sibling
<div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;">
<a href="http://theweekendhaslanded.org">The weekend has landed!</a>
</div>
Write a script:
Use Beautiful Soup to navigate to the answer to our question:
Is it weekend yet?
'''A simple script that tells us if it's weekend yet'''
# import modules
from urllib.request import urlopen
from bs4 import BeautifulSoup
# open webpage
# parse HTML into Beautiful Soup
# extract data from parsed soup
Using a filter in a search function
to zoom into a part of the soup
most simple matching
>>> weekendSoup.find_all('div')[<div style="font-weight: bold; font-size: 120pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: black;">
NO
</div>, <div style="font-size: 5pt; font-family: Helvetica Neue, Helvetica, Swis721 BT, Arial, sans-serif; text-decoration: none; color: gray;">
don't worry, you'll get there!
</div>]
besides using a String as argument in a search function, you can also use:
Regular Expression
List
True
Function
more details: http://www.crummy.com/software/BeautifulSoup/bs4/doc/#kinds-of-filters
>>> import re
>>> for tag in weekendSoup.find_all(re.compile("^b")):
... print(tag.name)
...
body
>>> weekendSoup.find_all(["a", "li"])
[<a href="http://theweekendhaslanded.org">The weekend has landed!</a>]
[<a href="http://theweekendhaslanded.org">The weekend has landed!</a>]
>>> for tag in weekendSoup.find_all(True):
... print(tag.name)
...
html
head
title
meta
body
div
div
a
>>> def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
>>> weekendSoup.find_all(has_class_but_no_id)
[]
careful to use "class_" when filtering based on class name
urlGA = 'https://gallery.generalassemb.ly/' pageSourceGA = urlopen(urlGA).read() GASoup = BeautifulSoup(pageSourceGA, 'lxml') wdiLinks = GASoup.find_all('a', href='WD') projects = GASoup.find_all('li', class_='project')
>>> soup.find_all('title', limit=1) [<title> Monty Python's reunion is about nostalgia and heroes, not comedy | Stage | theguardian.com </title>]>>> soup.find('title') <title> Monty Python's reunion is about nostalgia and heroes, not comedy | Stage | theguardian.com </title>
soup.select("#content")soup.select("div#content")
soup.select(".byline")soup.select("li.byline")
soup.select("#content a") soup.select("#content > a") soup.select('a[href]')
soup.select('a[href="http://www.theguardian.com/profile/brianlogan"]')soup.select('a[href^="http://www.theguardian.com/"]')
soup.select('a[href$="info"]')
[<a class="link-text" href="http://www.theguardian.com/info">About us,</a>, <a class="link-text" href="http://www.theguardian.com/info">About us</a>]
>>> guardianSoup.select('a[href*=".com/contact"]')
[<a class="rollover contact-link" href="http://www.theguardian.com/contactus/2120188" title="Displays contact data for guardian.co.uk"><img alt="" class="trail-icon" src="http://static.guim.co.uk/static/ac46d0fc9b2bab67a9a8a8dd51cd8efdbc836fbf/common/images/icon-email-us.png"/><span>Contact us</span></a>]We generally want to:
clean up
calculate
process
>>> answer = soup.div.string
>>> answer
'\nNO\n'
>>> cleaned = answer.strip()
>>> cleaned
'NO'
>>> isWeekendYet = cleaned == 'YES'
>>> isWeekendYet
False # print info to screen
print('Is it weekend yet? ', isWeekendYet)
import csv
with open('weekend.csv', 'w', newline='') as csvfile:
weekendWriter = csv.writer(csvfile)
if isWeekendYet:
weekendWriter.writerow(['Yes'])
else:
weekendWriter.writerow(['No'])
google; “python” + your problem / question
python.org/doc/; official python documentation, useful to find which functions are available
stackoverflow.com; huge gamified help forum with discussions on all sorts of programming questions, answers are ranked by community
codecademy.com/tracks/python; interactive exercises that teach you coding by doing
wiki.python.org/moin/BeginnersGuide/Programmers; tools, lessons and tutorials
Python Usage Survey 2014 visualised
http://www.randalolson.com/2015/01/30/python-usage-survey-2014/
Python 2 & 3 Key Differences
'''
Extracting the Iris dataset table from Wikipedia
'''
# import modules
from urllib.request import urlopen
from bs4 import BeautifulSoup
# open webpage
url = 'https://en.wikipedia.org/wiki/Iris_flower_data_set'
pageSource = urlopen(url).read()
# parse HTML into Beautiful Soup
IrisSoup = BeautifulSoup(pageSource, 'lxml')
# Get the table
right_table=IrisSoup.find('table', class_='wikitable sortable')
# Extract rows
tmp = right_table.find_all('tr')
first = tmp[0]
allRows = tmp[1:]
# Construct headers
headers = [header.get_text().strip() for header in first.find_all('th')]
# Construct results
results = [[data.get_text() for data in row.find_all('td')]
for row in allRows]
#import pandas to convert list to data frame
import pandas as pd
df = pd.DataFrame(data = results,
columns = headers)
df['Species'] = df['Species'].map(lambda x: x.replace('\xa0',' '))
import pandas as pd
%pylab inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
iris_data = pd.read_csv('irisdata.csv')
iris_data.head()
iris_data.shape
iris_data[0:10][['Sepal width', 'Sepal length' ]]
# Summarise the data
iris_data.describe()
# Now let's group the data by the species
byspecies = iris_data.groupby('Species')
byspecies.describe()
byspecies['Petal length'].mean()
# Histograms
iris_data.loc[iris_data['Species'] == 'I. setosa', 'Sepal width'].hist(bins=10)
iris_data['Sepal width'].plot(kind="hist")
>>> from urllib.request import urlopen
>>> from bs4 import BeautifulSoup
>>> url = "http://isitweekendyet.com/"
>>> source = urlopen(url).read()
>>> soup = BeautifulSoup(source, 'lxml')
>>> soup.body.div.string
'\nNO\n'
# an alternative:
>>> list(soup.body.stripped_strings)[0]
'NO'
By J Rogel
A practical introduction to webscraping with Python

