



















Karl Ho
Data Generation datageneration.io
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Prepared for Geoscience Seminar hosted at the Department of Geosciences, School of Natural Sciences and Mathematics University of Texas at Dallas, September 14, 2023
Source: Lary, David J., Amir H. Alavi, Amir H. Gandomi, and Annette L. Walker. 2016. “Machine Learning in Geosciences and Remote Sensing.” Geoscience Frontiers 7(1): 3–10. https://linkinghub.elsevier.com/retrieve/pii/S1674987115000821 (September 14, 2023).
Source: Lary, David J., Amir H. Alavi, Amir H. Gandomi, and Annette L. Walker. 2016. “Machine Learning in Geosciences and Remote Sensing.” Geoscience Frontiers 7(1): 3–10. https://linkinghub.elsevier.com/retrieve/pii/S1674987115000821 (September 14, 2023).
The vision
The vision
The vision
The vision
The vision
Problem of ML
ML techniques to achieve a better design, development, and evaluation of visualizations (Wang et al 2022).
Two questions:
Three big areas and seven Main Visualization Processes Employing ML:
Source: Wang, Qianwen, Zhutian Chen, Yong Wang, and Huamin Qu. 2022. “A Survey on ML4VIS: Applying Machine Learning Advances to Data Visualization.” IEEE Transactions on Visualization and Computer Graphics 28(12): 5134–53.
Seven Main Visualization Processes Employing ML:
Source: Wang, Qianwen, Zhutian Chen, Yong Wang, and Huamin Qu. 2022. “A Survey on ML4VIS: Applying Machine Learning Advances to Data Visualization.” IEEE Transactions on Visualization and Computer Graphics 28(12): 5134–53.
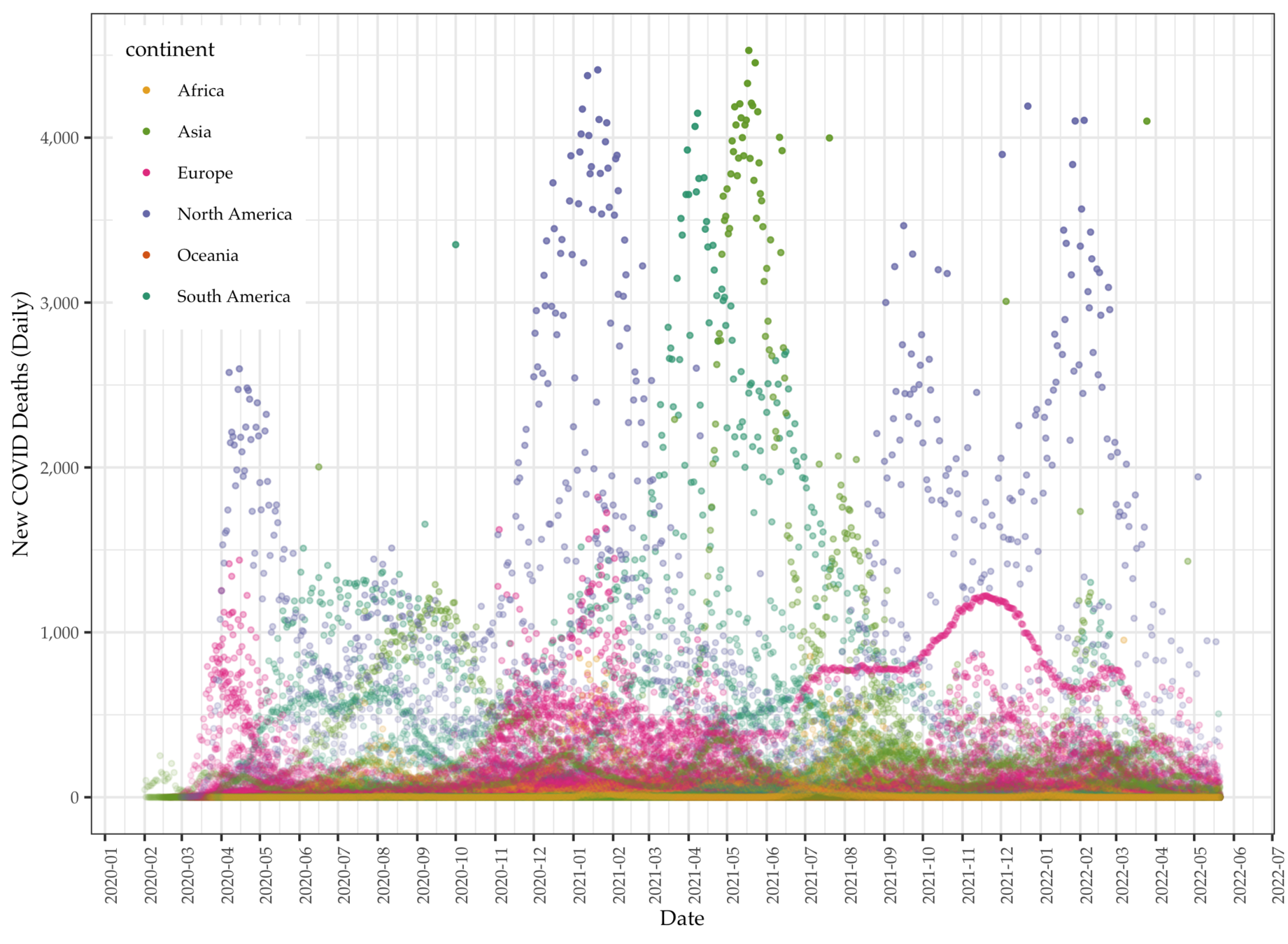
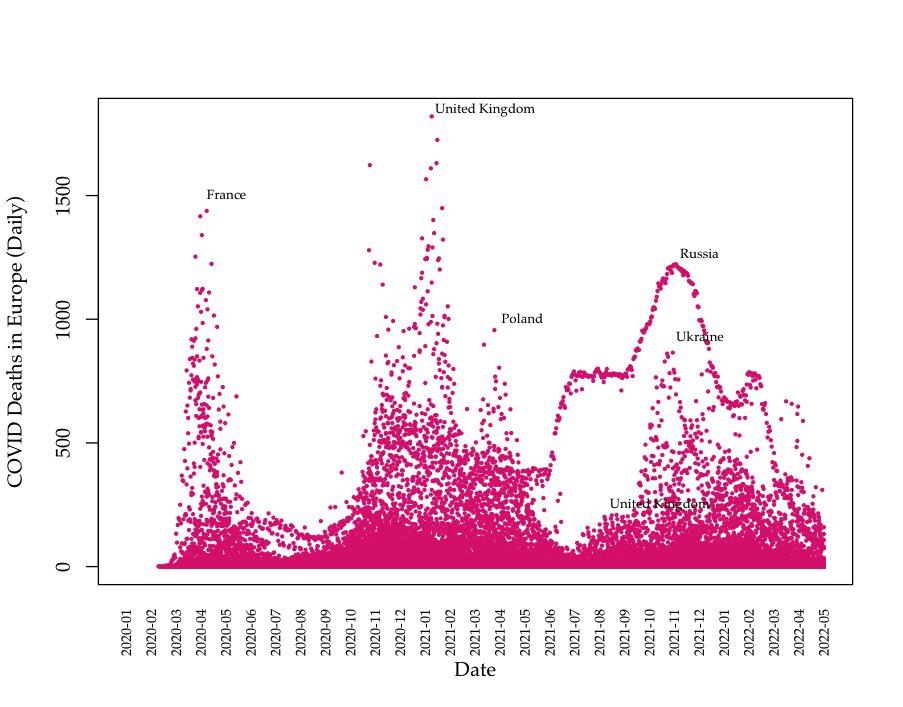
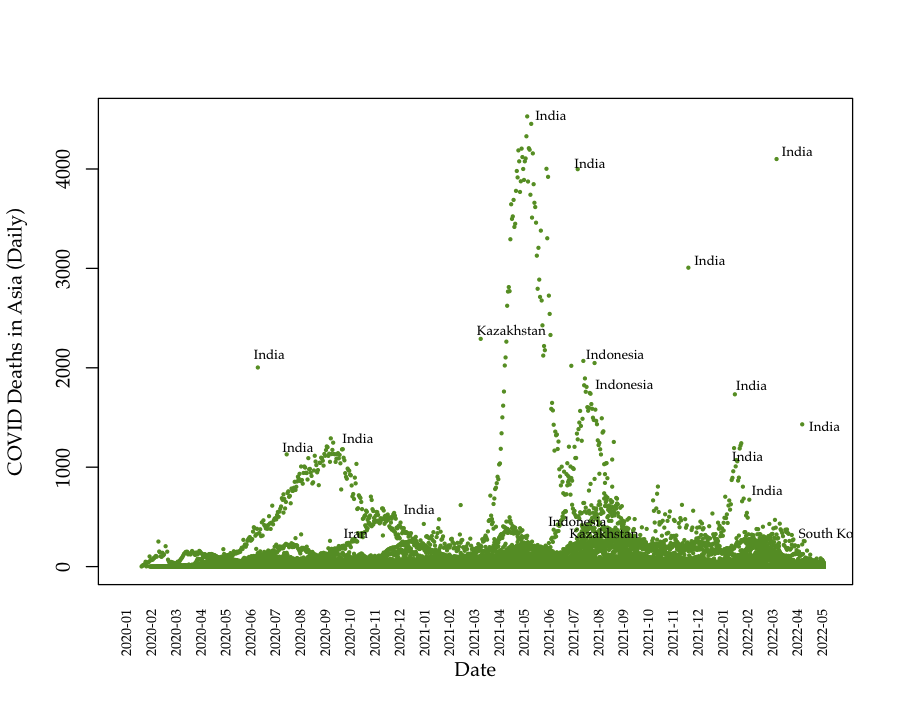
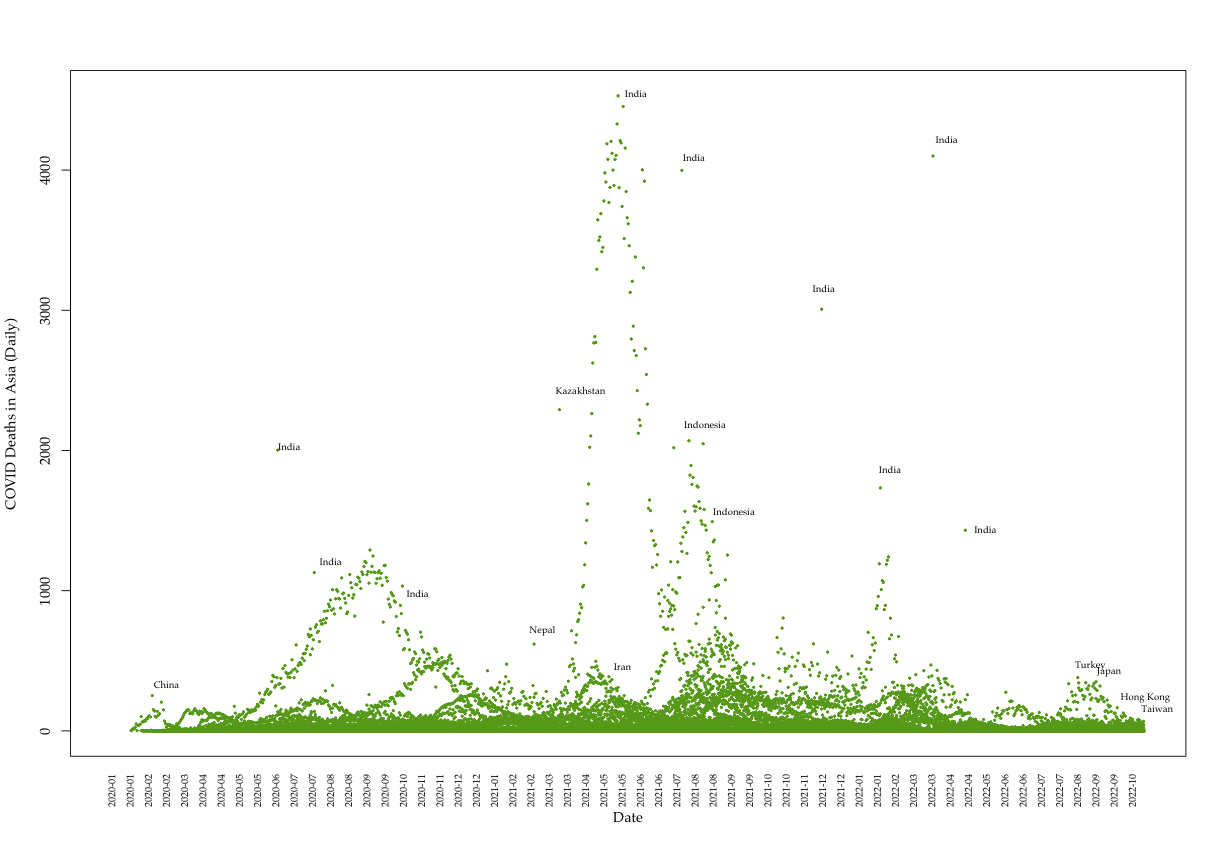
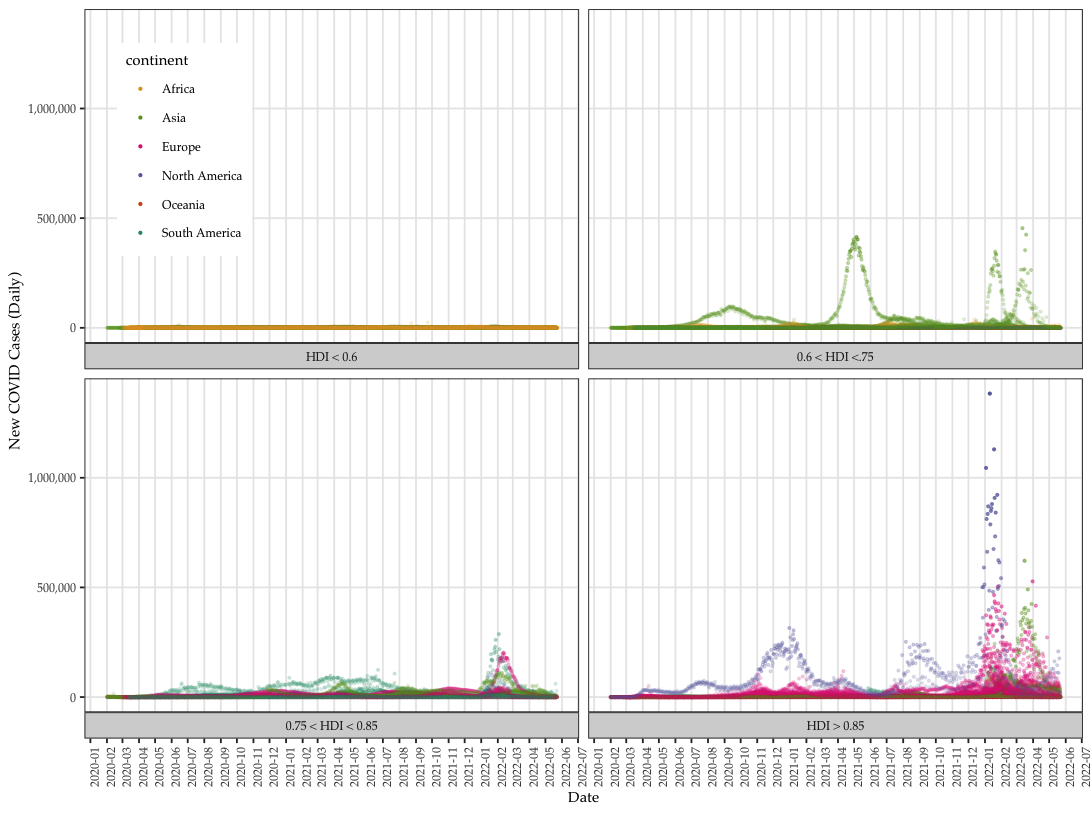
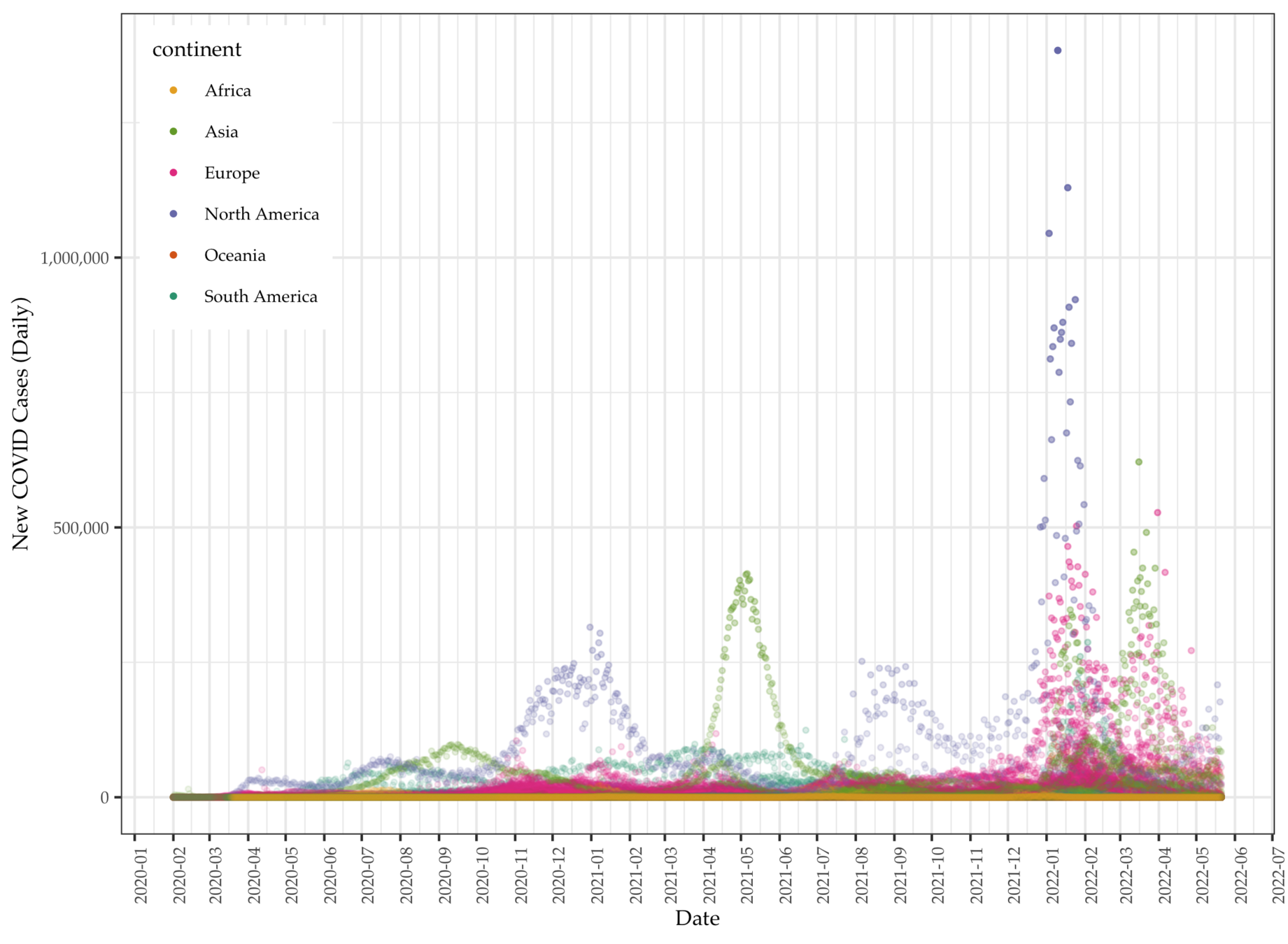
We collect global COVID data from the Our World in Data project, which makes available daily pandemic data from all countries available in real time.
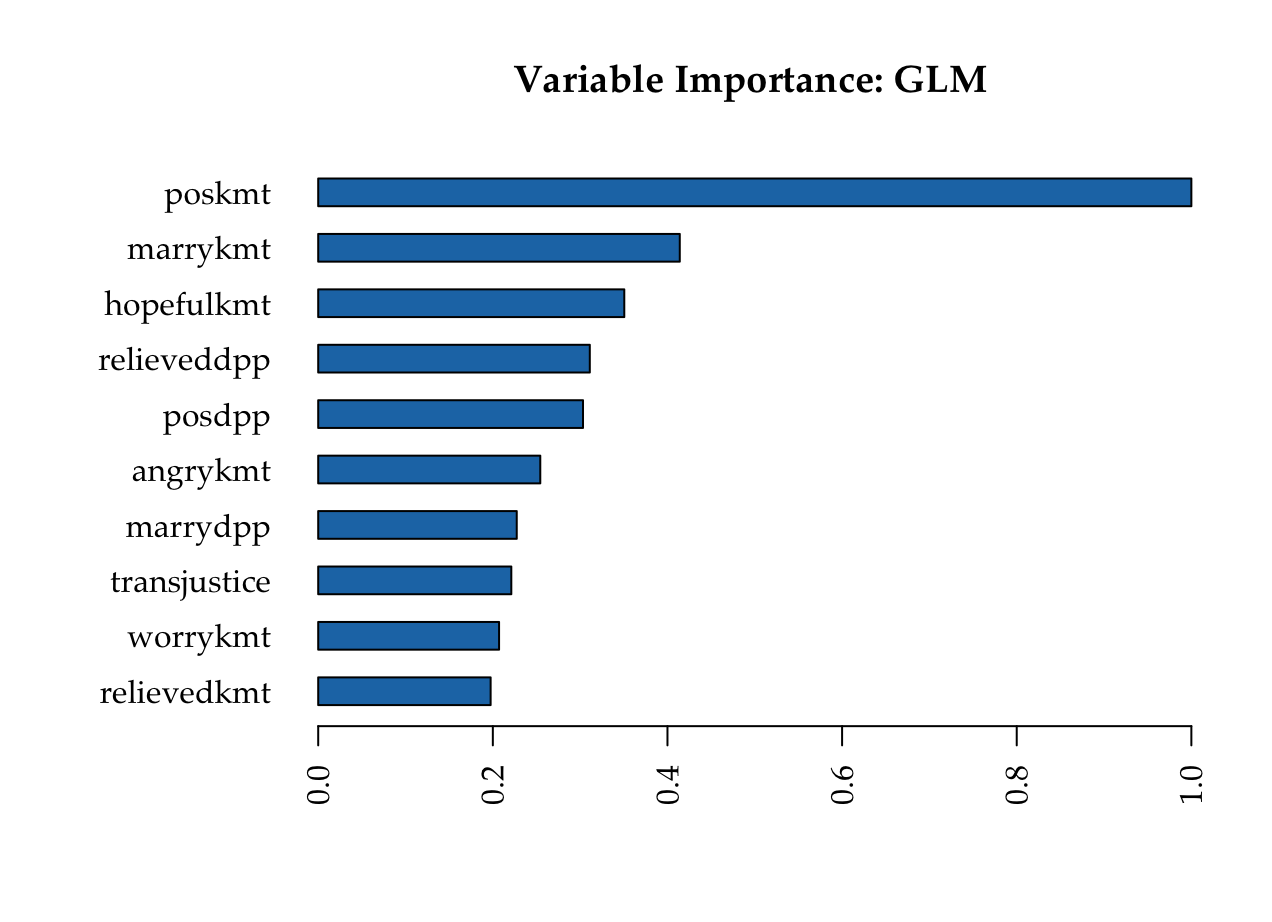
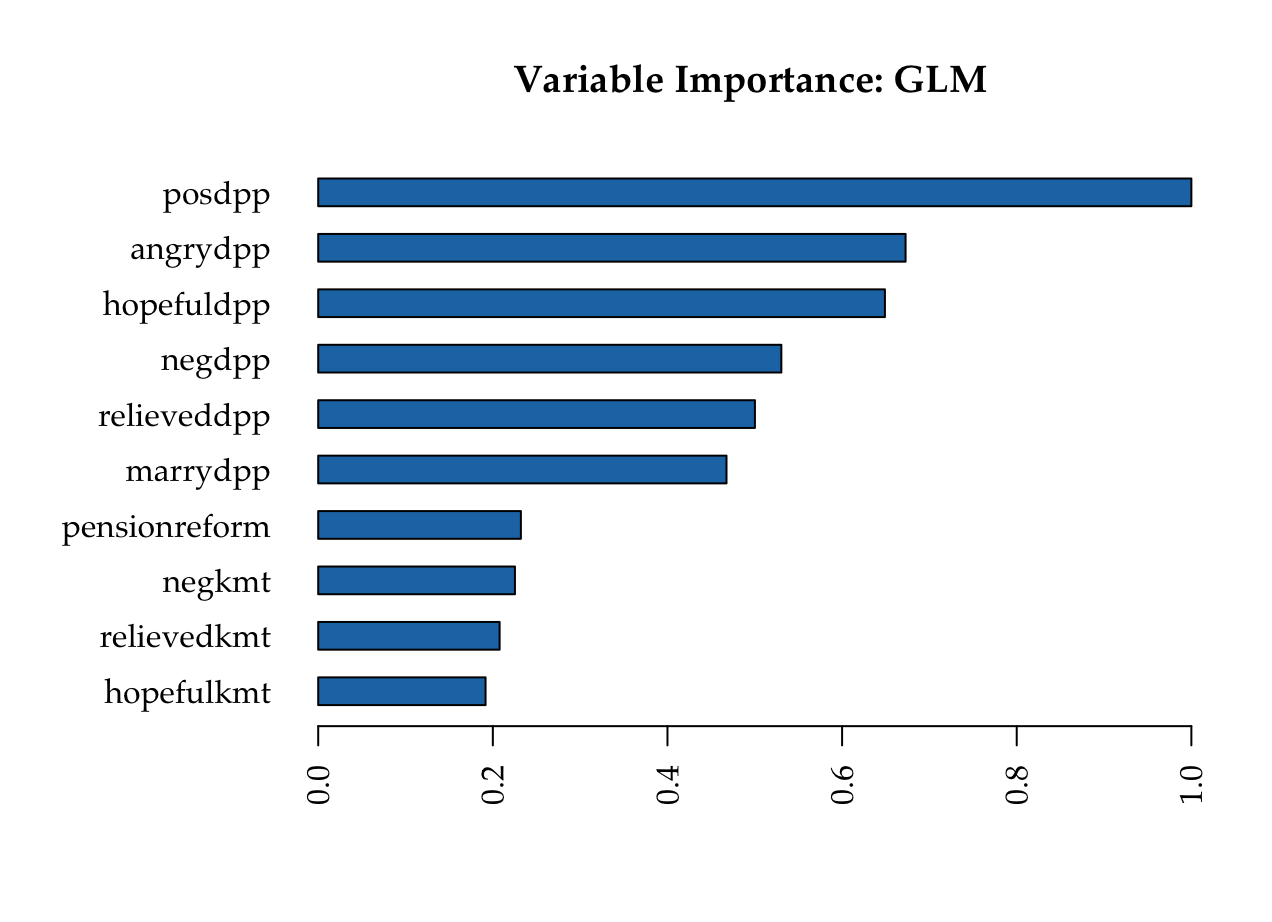
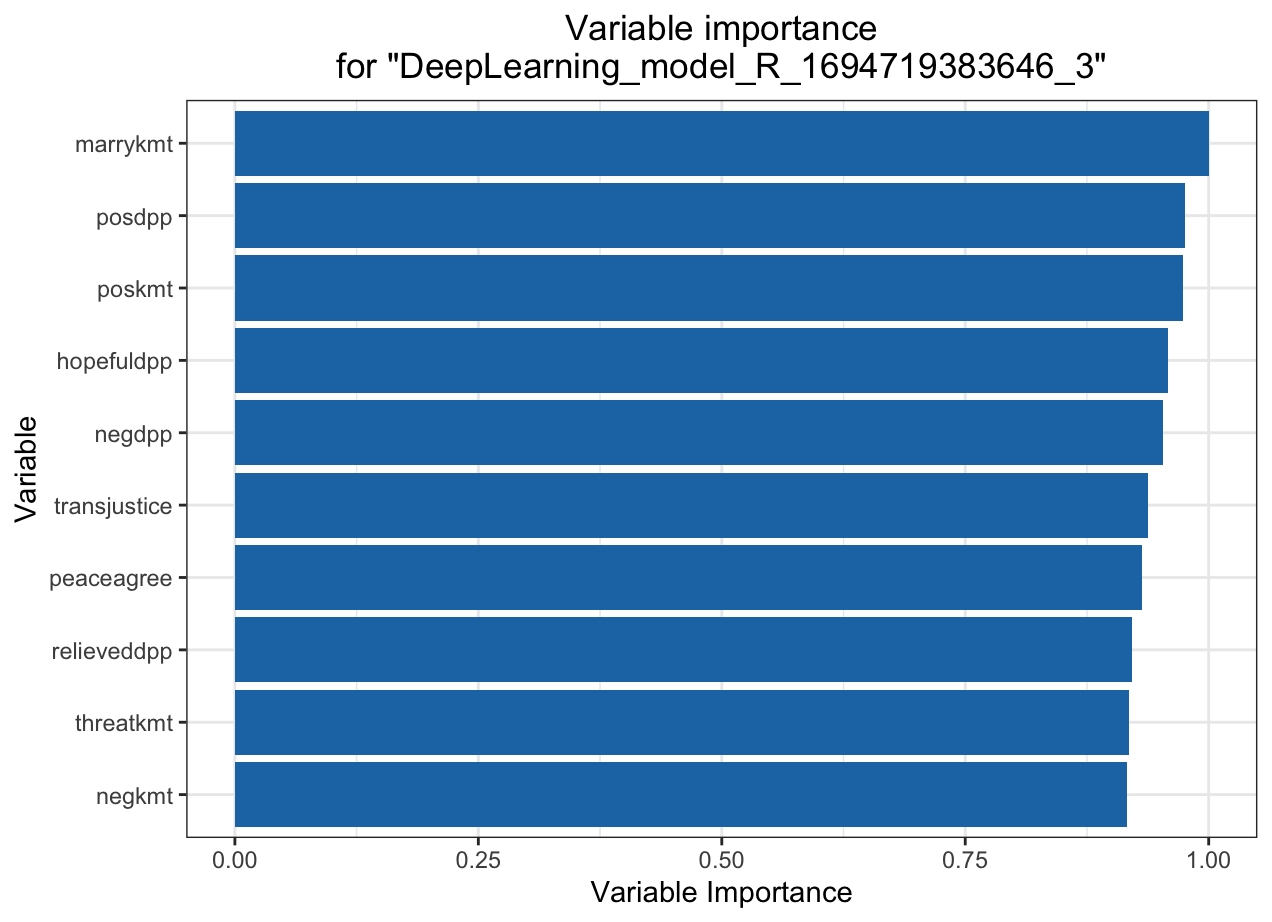
KMT
DPP
KMT
DPP
MSE: 0.05650798
RMSE: 0.2377141
LogLoss: 0.190111
Mean Per-Class Error: 0.07756352
AUC: 0.9773588
AUCPR: 0.9645369
Gini: 0.9547177
MSE: 0.05053361
RMSE: 0.2247968
LogLoss: 0.1659664
Mean Per-Class Error: 0.08273317 AUC: 0.9781768
AUCPR: 0.9399842
Gini: 0.9563536
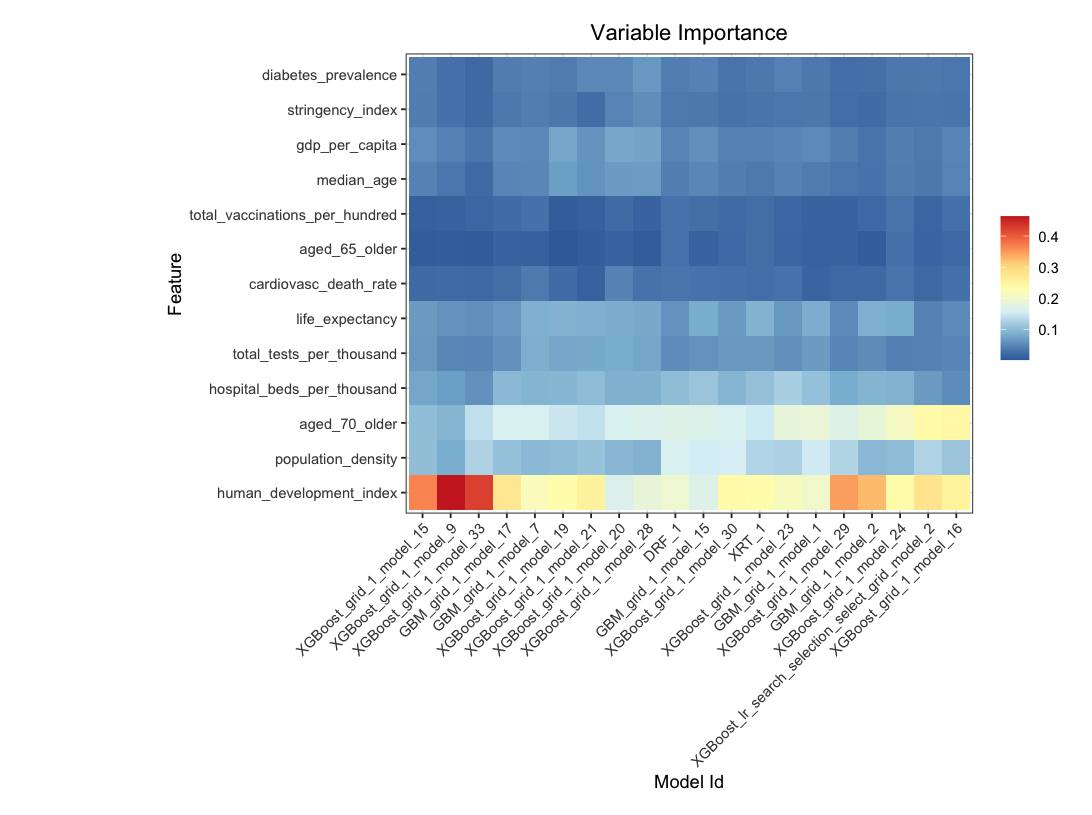
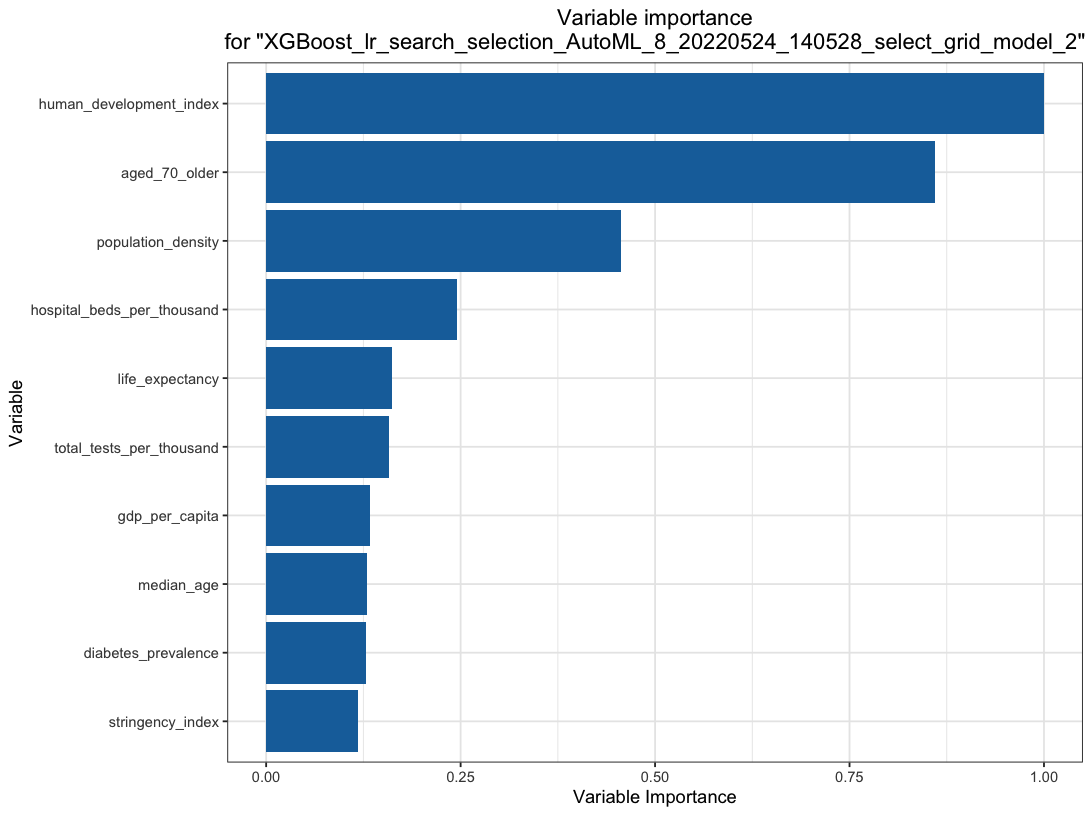
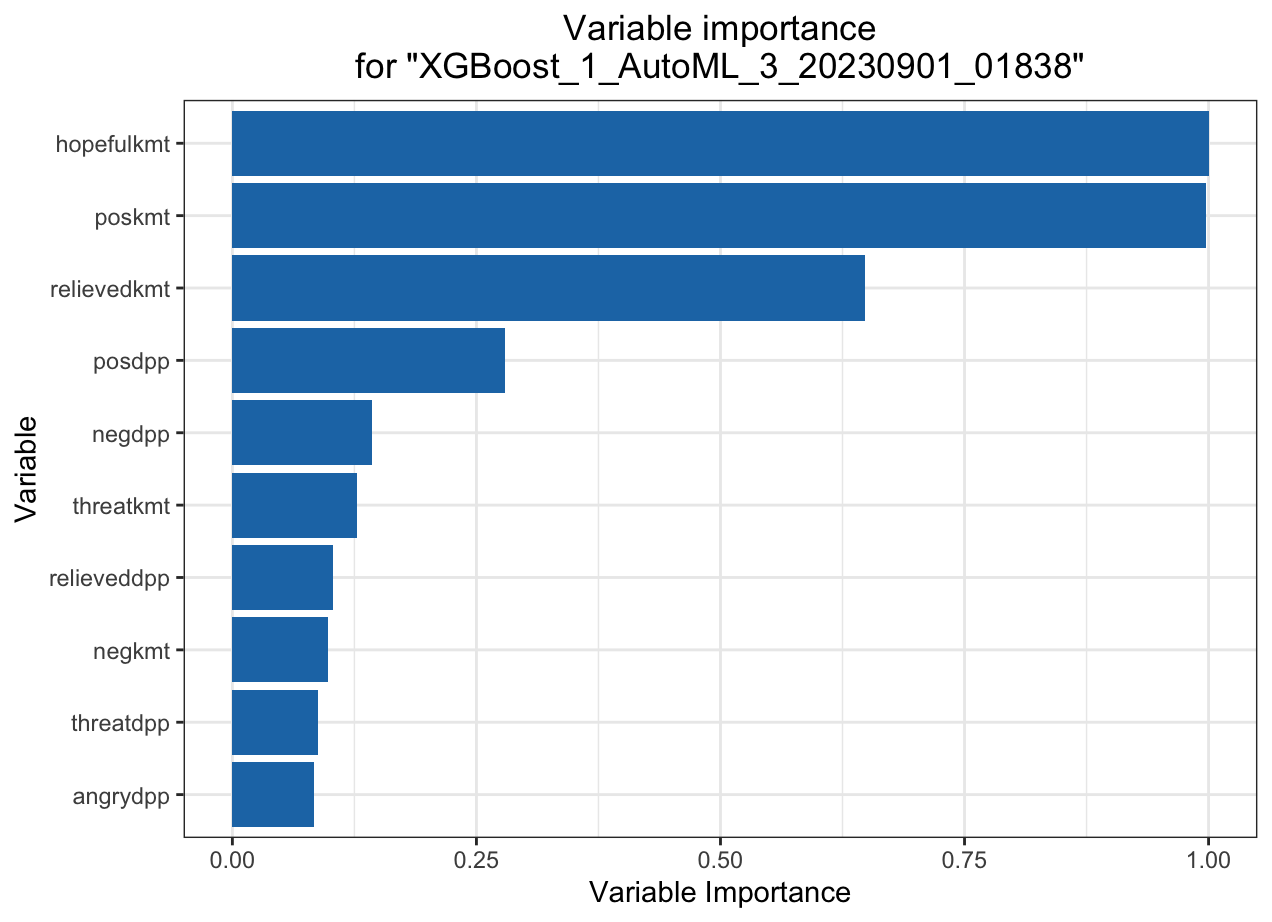
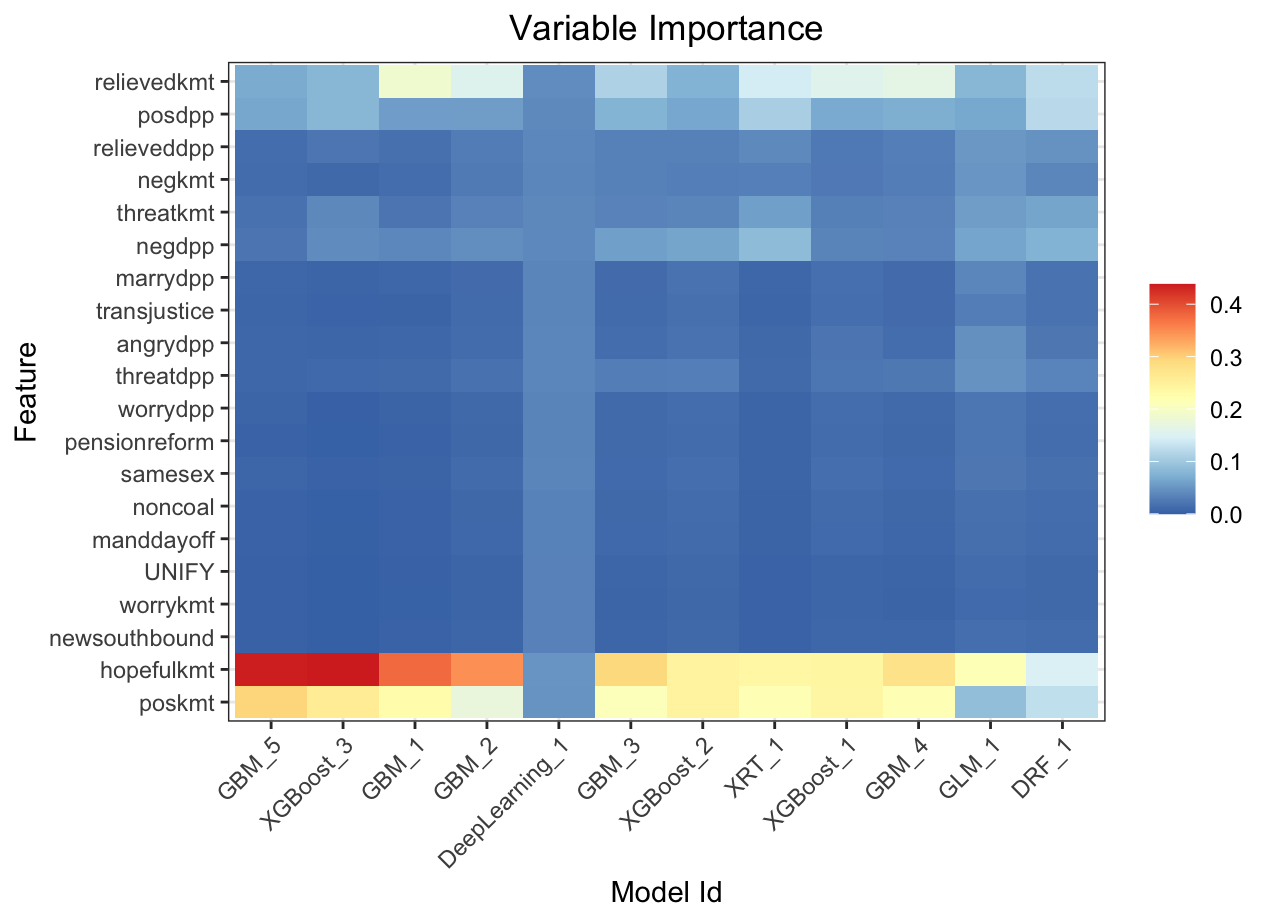
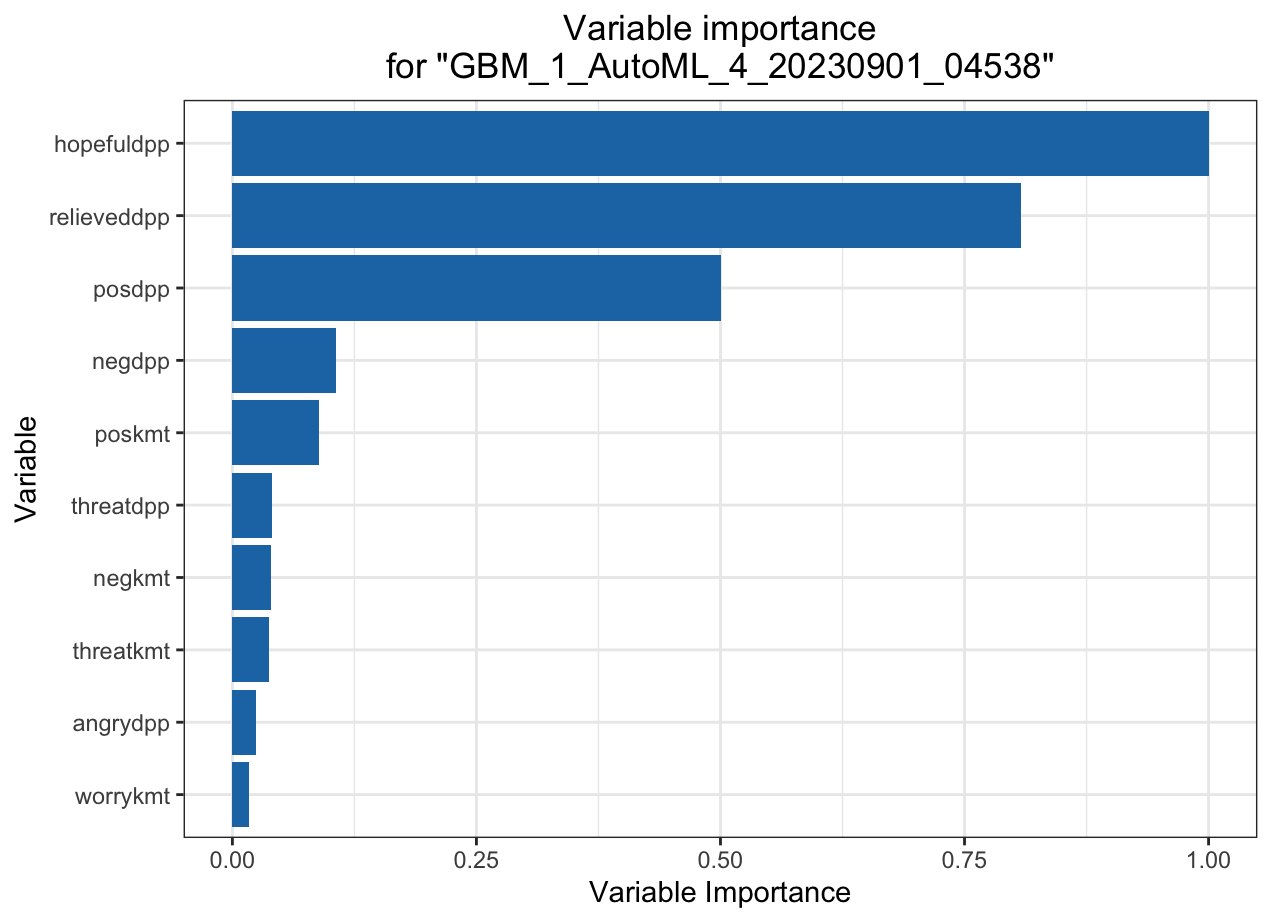
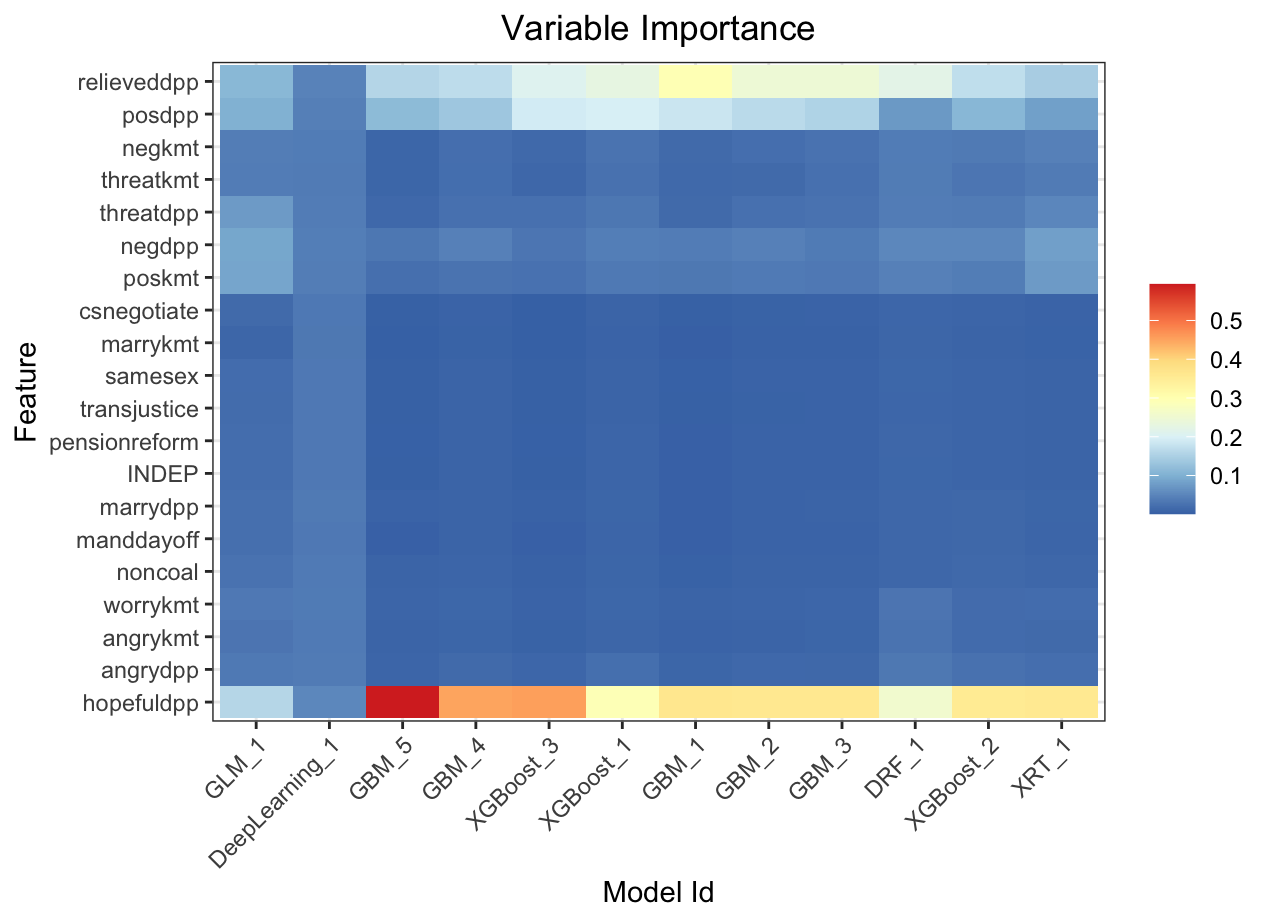
Variable importance heatmap shows variable importance across multiple models. Some models return variable importance for one-hot (binary indicator) encoded versions of categorical columns (e.g. Deep Learning, XGBoost). In order for the variable importance of categorical columns to be compared across all model types we compute a summarization of the the variable importance across all one-hot encoded features and return a single variable importance for the original categorical feature. By default, the models and variables are ordered by their similarity.
Variable importance heatmap shows variable importance across multiple models. Some models return variable importance for one-hot (binary indicator) encoded versions of categorical columns (e.g. Deep Learning, XGBoost). In order for the variable importance of categorical columns to be compared across all model types we compute a summarization of the the variable importance across all one-hot encoded features and return a single variable importance for the original categorical feature. By default, the models and variables are ordered by their similarity.
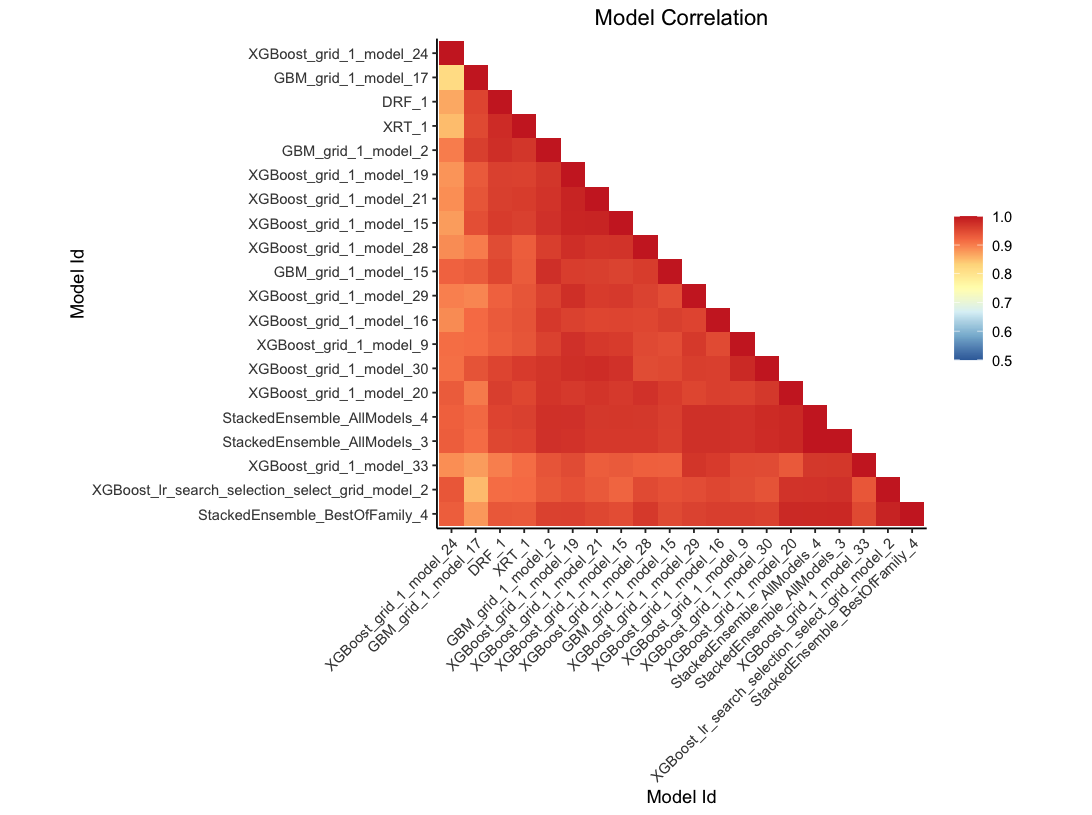
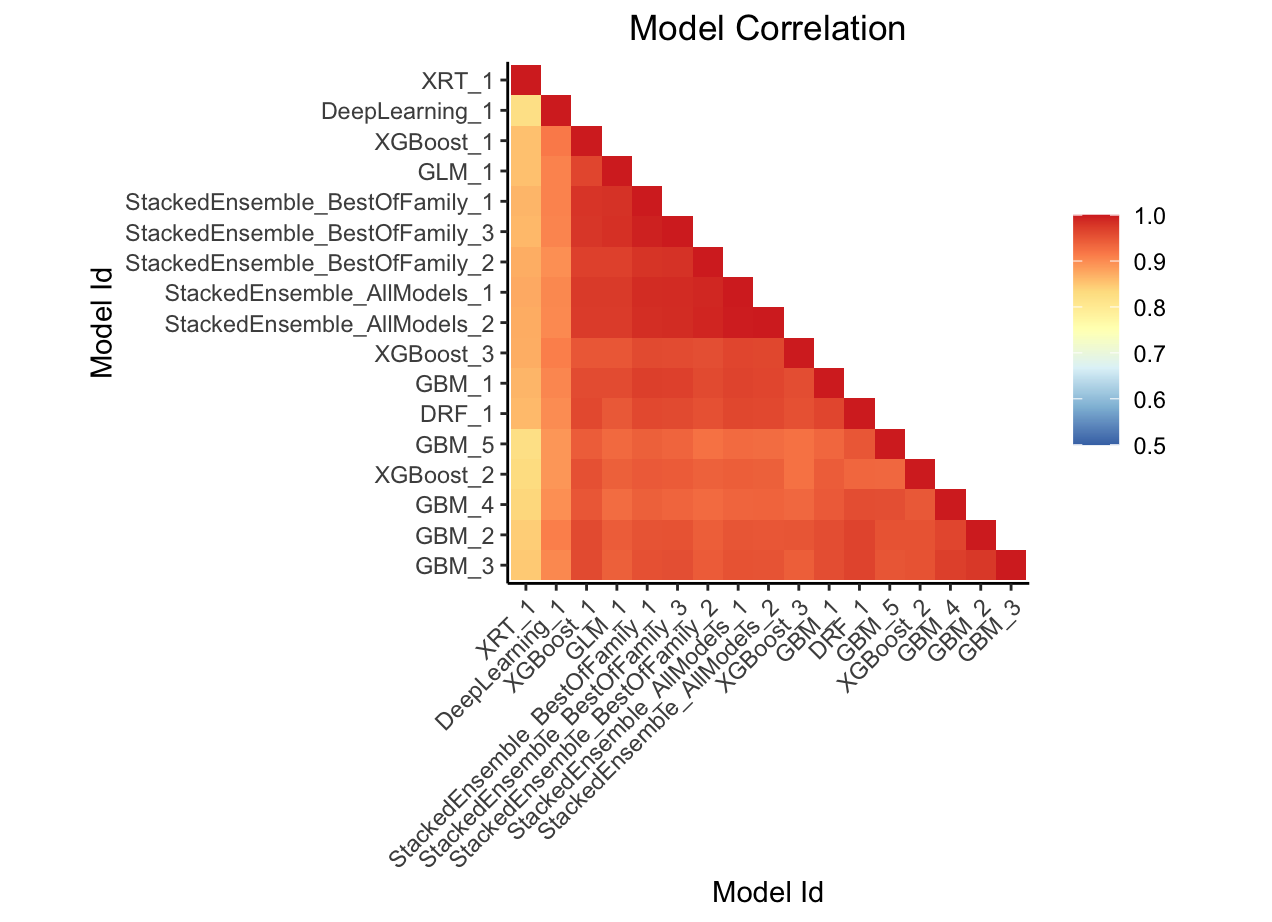
This plot shows the correlation between the predictions of the models. For classification, frequency of identical predictions is used. By default, models are ordered by their similarity (as computed by hierarchical clustering).
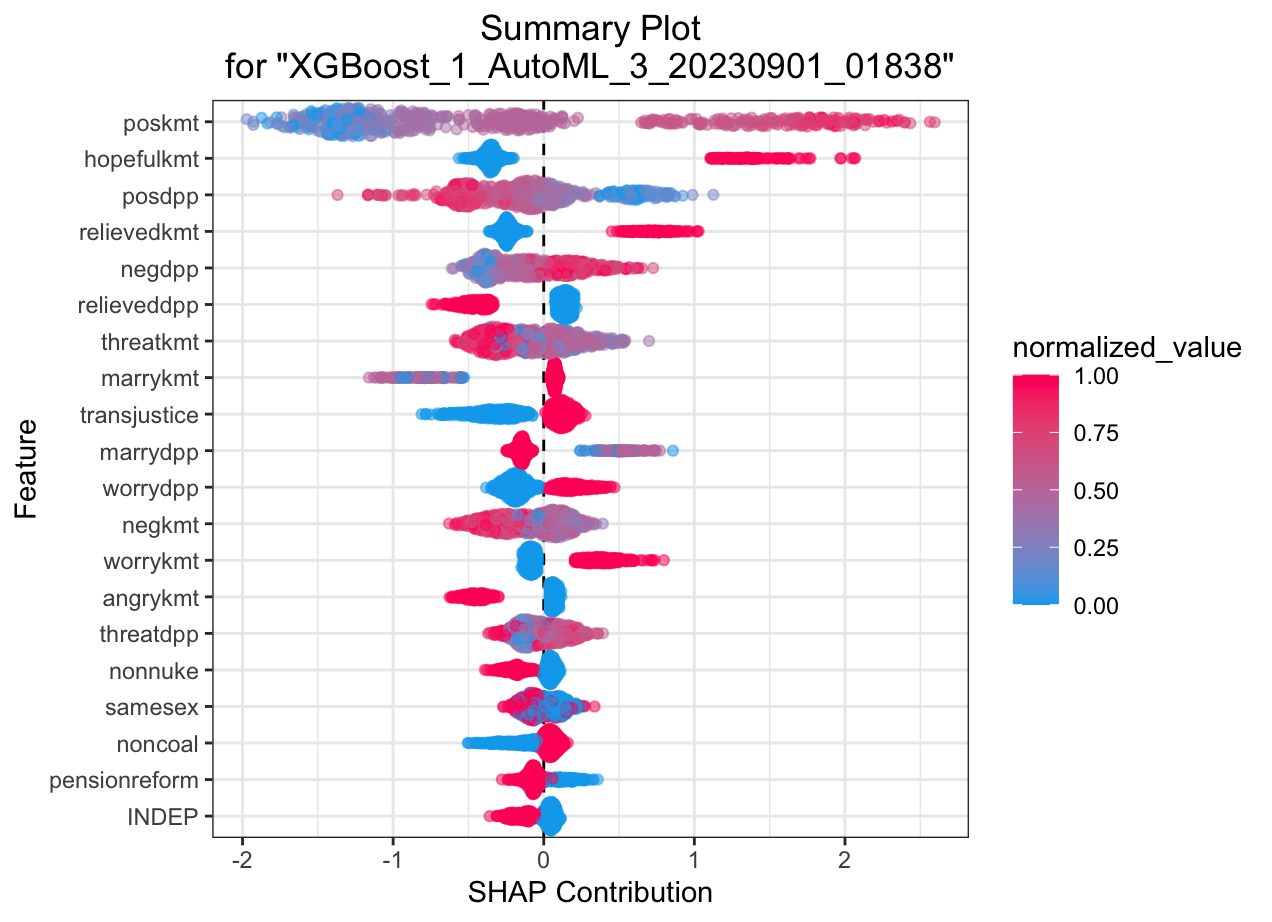
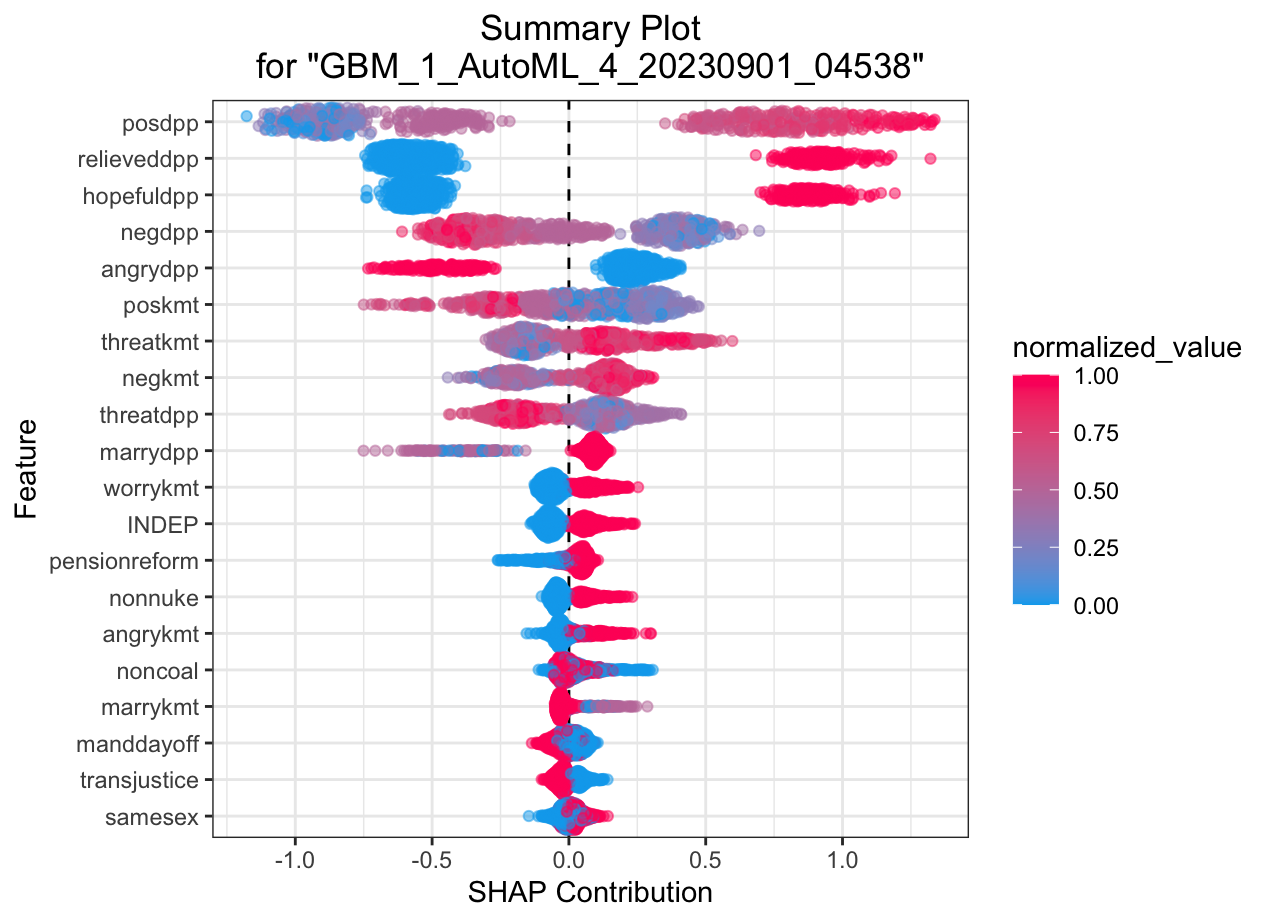
SHAP summary plot shows the contribution of the features for each instance (row of data). The sum of the feature contributions and the bias term is equal to the raw prediction of the model, i.e., prediction before applying inverse link function
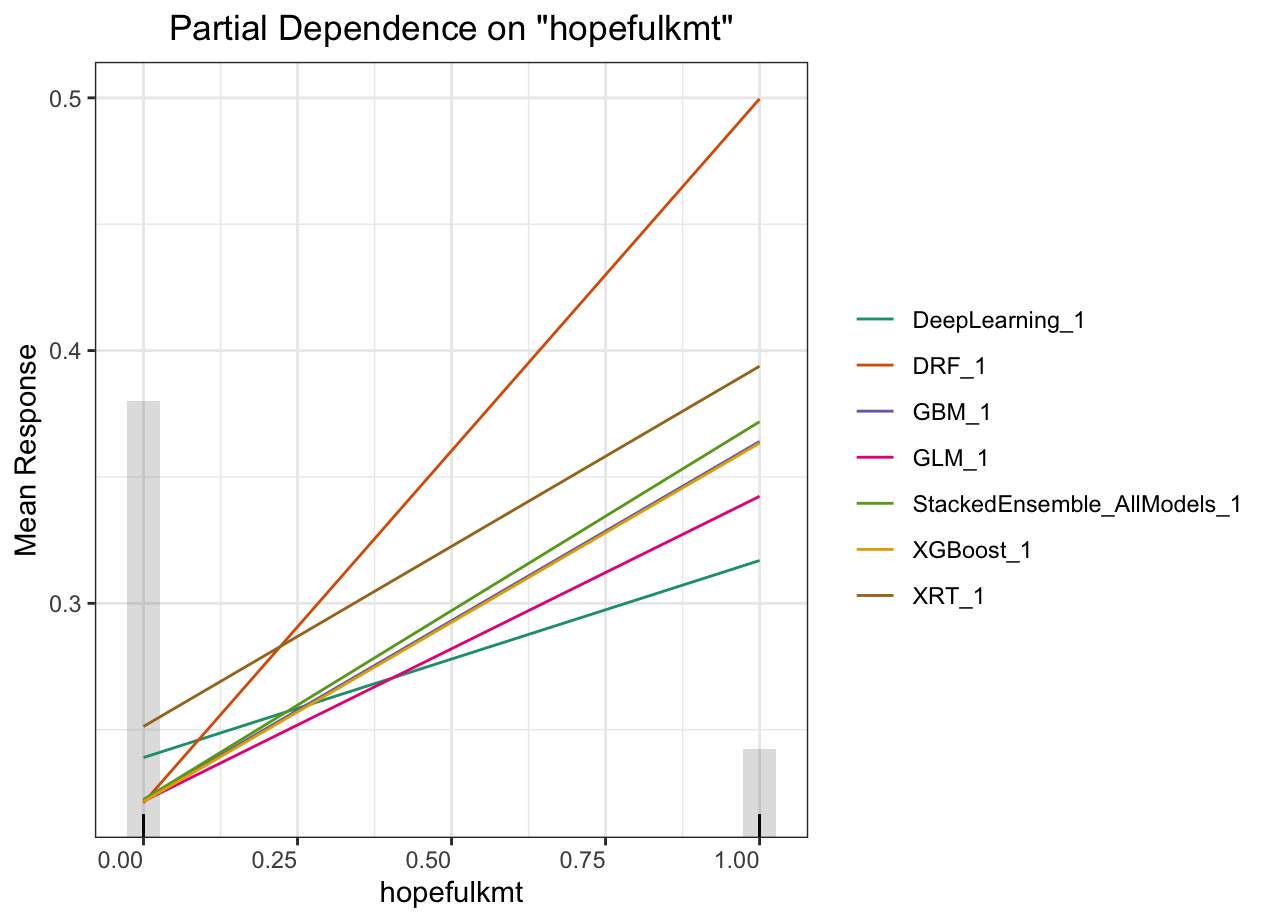
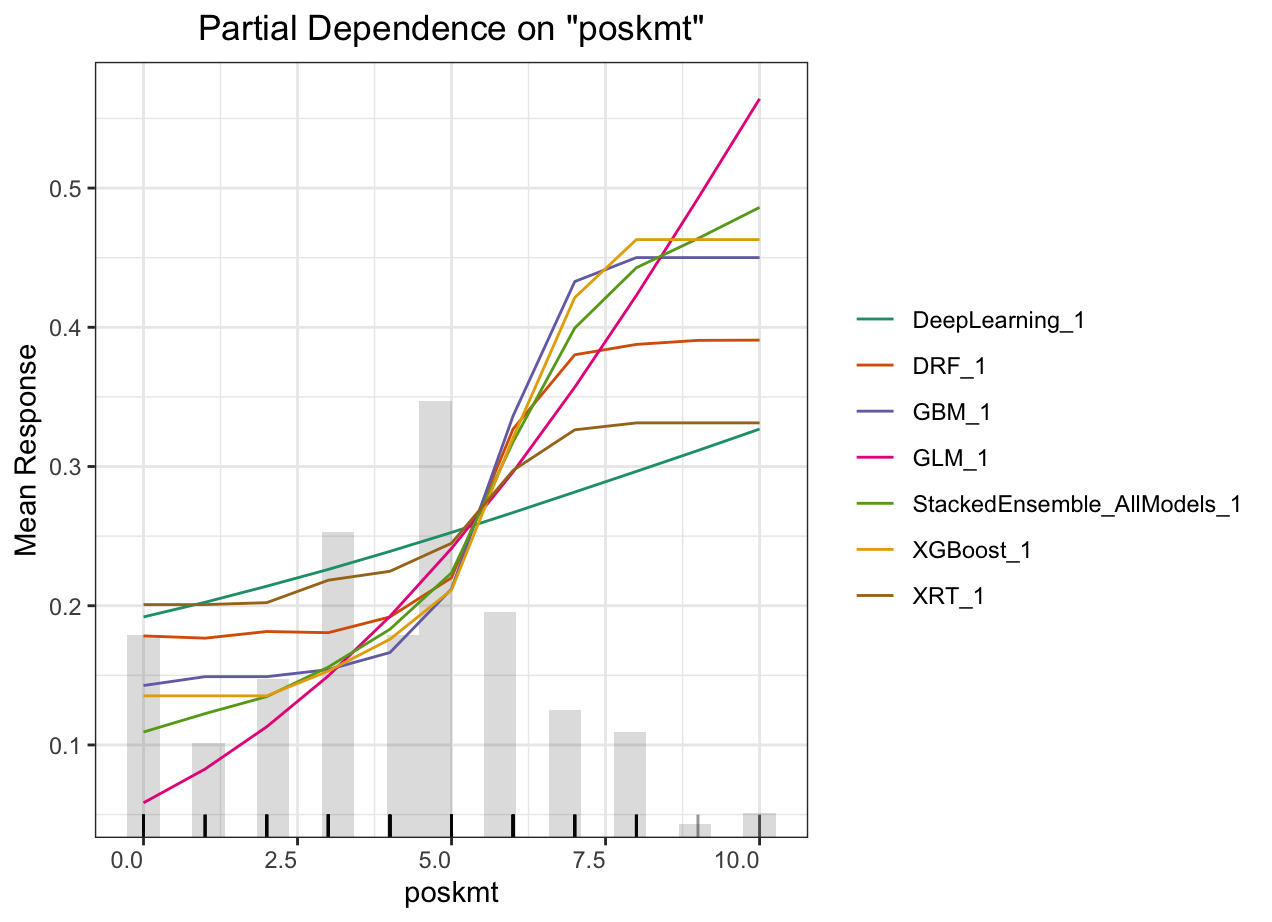
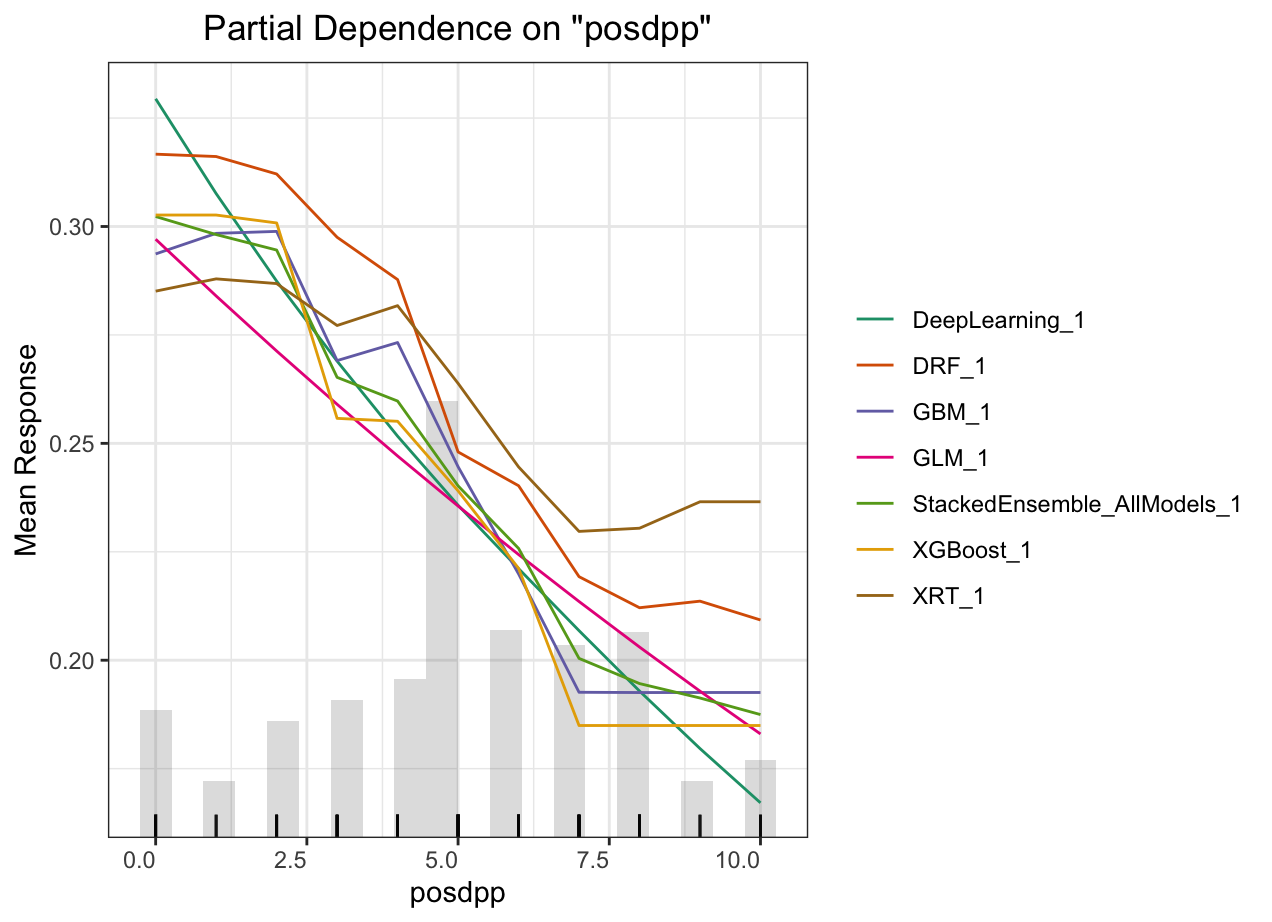
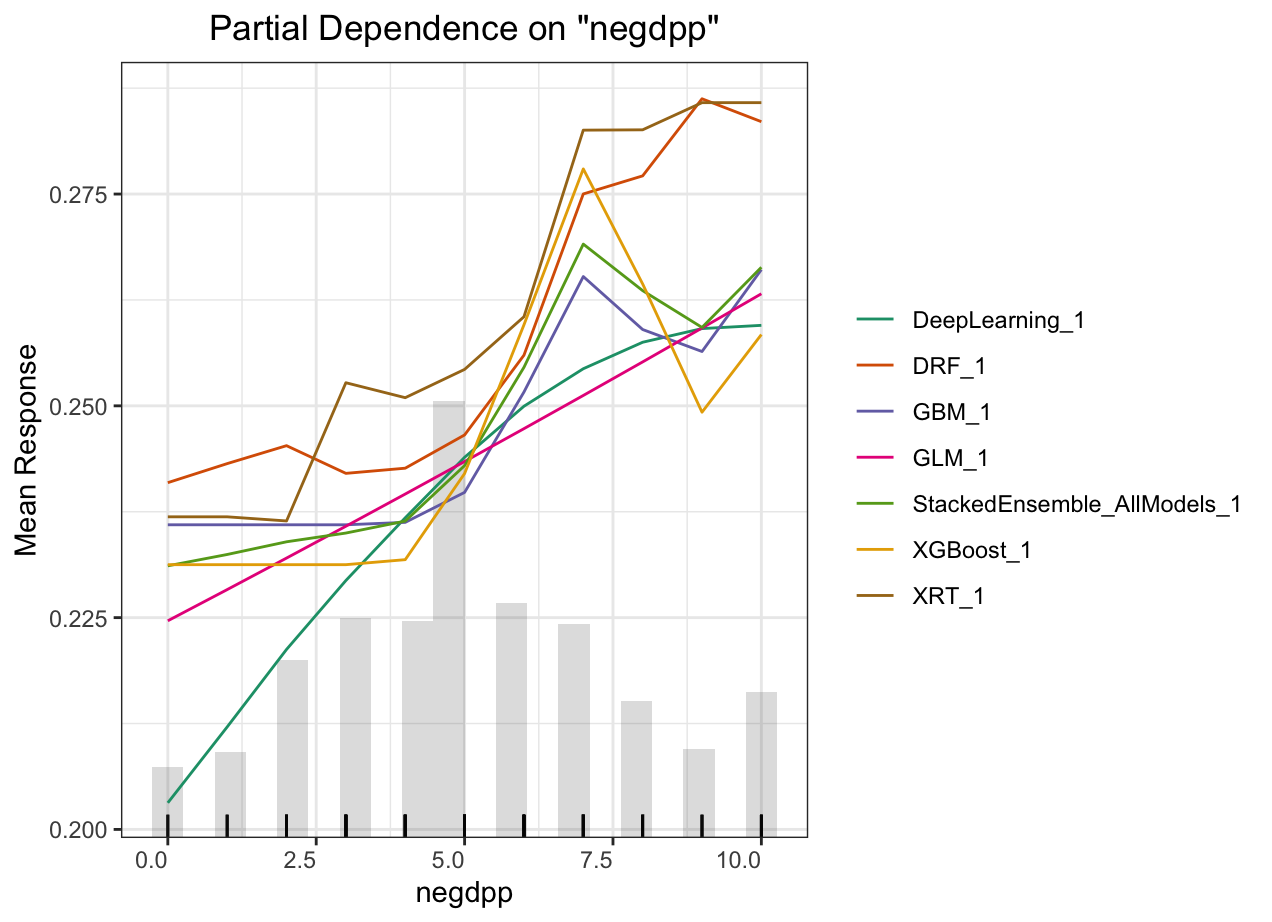
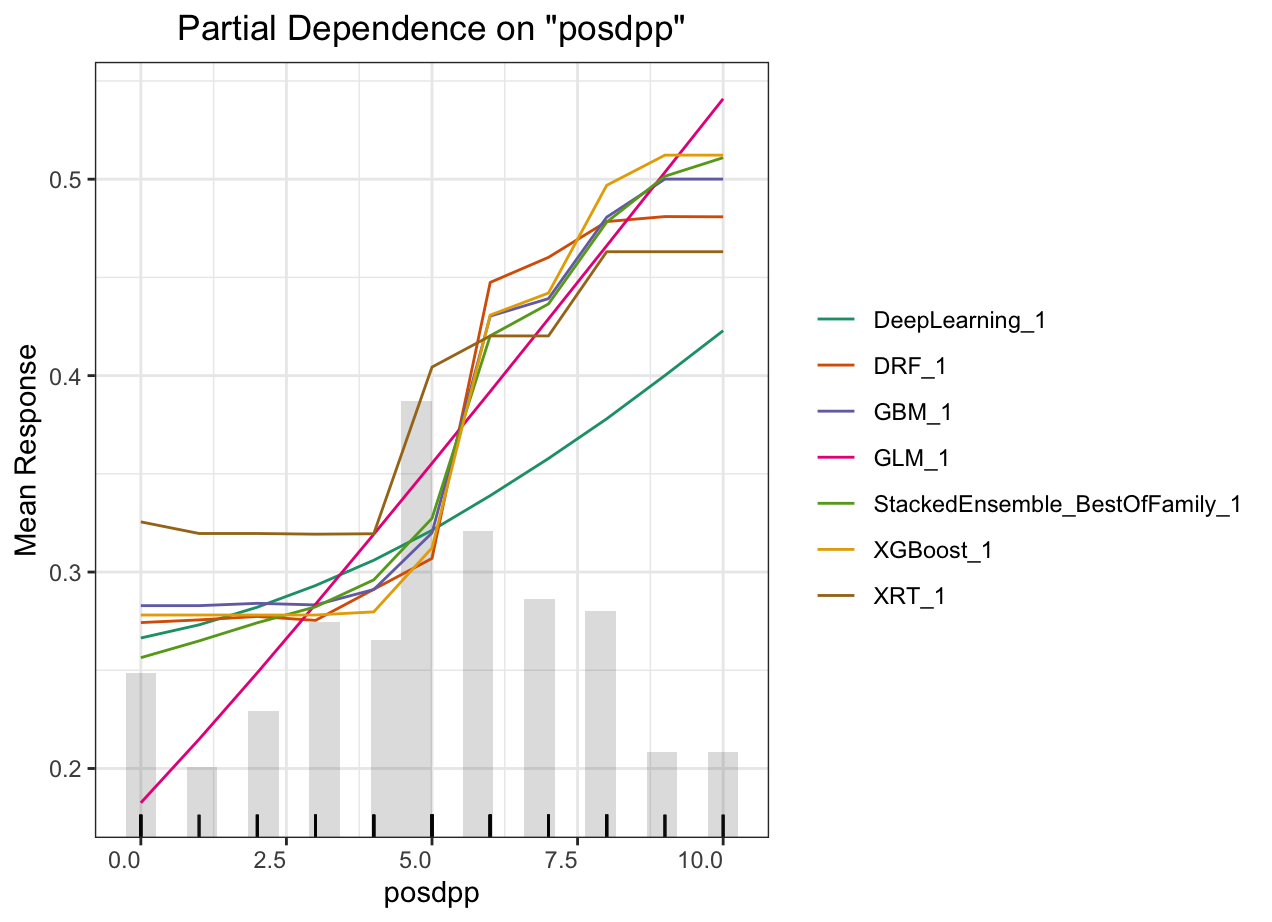
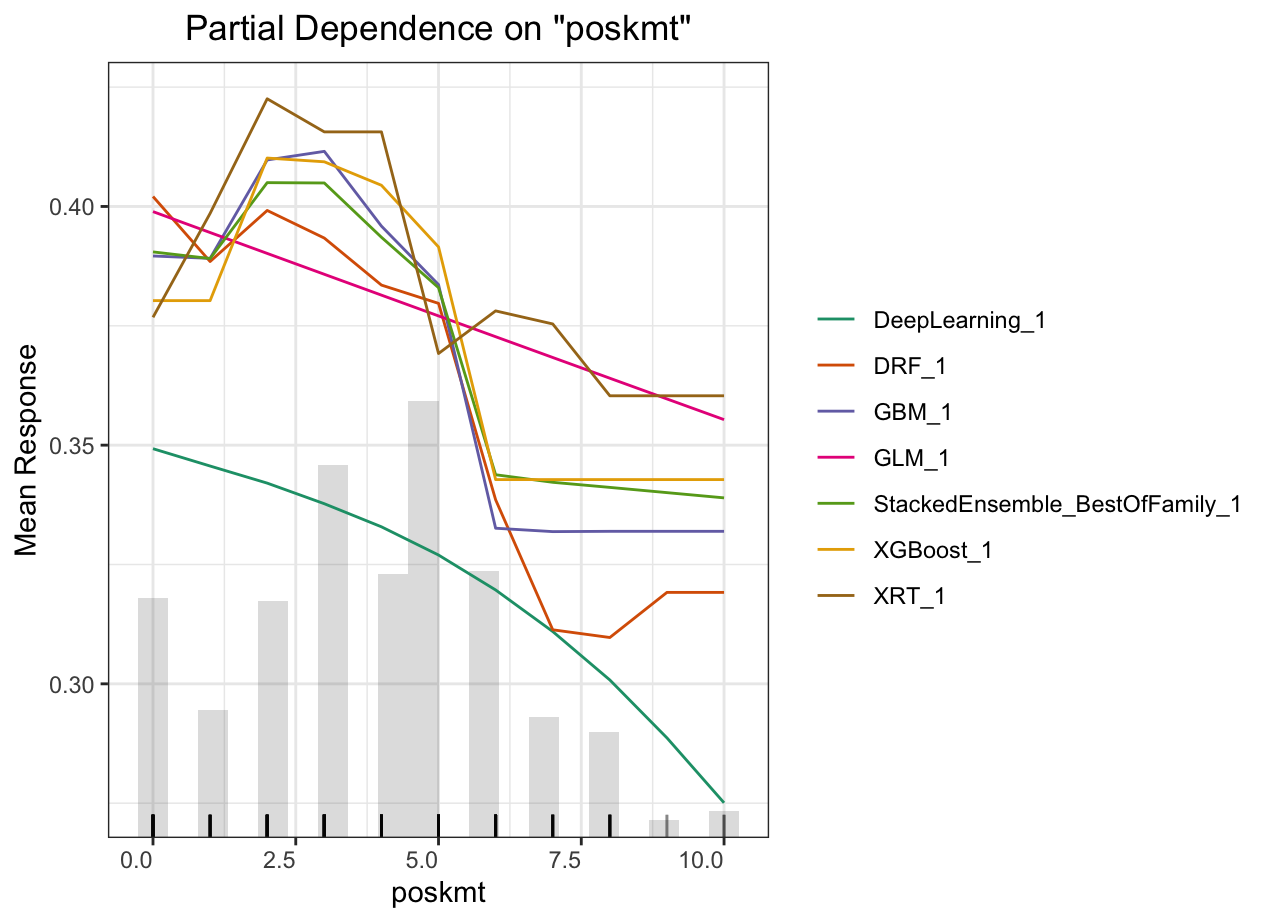
Partial dependence plot (PDP) gives a graphical depiction of the marginal effect of a variable on the response. The effect of a variable is measured in change in the mean response. PDP assumes independence between the feature for which is the PDP computed and the rest.
Partial dependence plot (PDP) gives a graphical depiction of the marginal effect of a variable on the response. The effect of a variable is measured in change in the mean response. PDP assumes independence between the feature for which is the PDP computed and the rest.
Partial dependence plot (PDP) gives a graphical depiction of the marginal effect of a variable on the response. The effect of a variable is measured in change in the mean response. PDP assumes independence between the feature for which is the PDP computed and the rest.
Partial dependence plot (PDP) gives a graphical depiction of the marginal effect of a variable on the response. The effect of a variable is measured in change in the mean response. PDP assumes independence between the feature for which is the PDP computed and the rest.
How to bridge and converge the two subfields in Data Science:
Both Data visualization and Machine learning training programs warrant solid foundation of what, how and why.
Endert, A. et al. 2017. “The State of the Art in Integrating Machine Learning into Visual Analytics.” Computer Graphics Forum 36(8): 458–86. https://onlinelibrary.wiley.com/doi/abs/10.1111/cgf.13092 (September 7, 2023).
Lary, David J., Amir H. Alavi, Amir H. Gandomi, and Annette L. Walker. 2016. “Machine Learning in Geosciences and Remote Sensing.” Geoscience Frontiers 7(1): 3–10. https://linkinghub.elsevier.com/retrieve/pii/S1674987115000821 (September 14, 2023).
Talbot, Justin, Bongshin Lee, Ashish Kapoor, and Desney S. Tan. 2009. “EnsembleMatrix: Interactive Visualization to Support Machine Learning with Multiple Classifiers.” In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’09, New York, NY, USA: Association for Computing Machinery, 1283–92. https://dl.acm.org/doi/10.1145/1518701.1518895 (September 7, 2023).
Vellido, Alfredo. 2020. “The Importance of Interpretability and Visualization in Machine Learning for Applications in Medicine and Health Care.” Neural Computing and Applications 32(24): 18069–83. https://doi.org/10.1007/s00521-019-04051-w (September 7, 2023).
Wang, Qianwen et al. 2021. “Visual Analysis of Discrimination in Machine Learning.” IEEE Transactions on Visualization and Computer Graphics 27(2): 1470–80.
Wang, Qianwen, Zhutian Chen, Yong Wang, and Huamin Qu. 2022. “A Survey on ML4VIS: Applying Machine Learning Advances to Data Visualization.” IEEE Transactions on Visualization and Computer Graphics 28(12): 5134–53.
By Karl Ho



