





Karl Ho
Data Generation datageneration.io
| Karl Ho |
| University of Texas at Dallas |
Prepared for presentation at the Trilateral Relationship between Taiwan, the United States, and China: The Past, Present, and Future Conference, October 22-23, 2022, St. Thomas University, Houston, TX
Why AML?
Why isotonic regression?
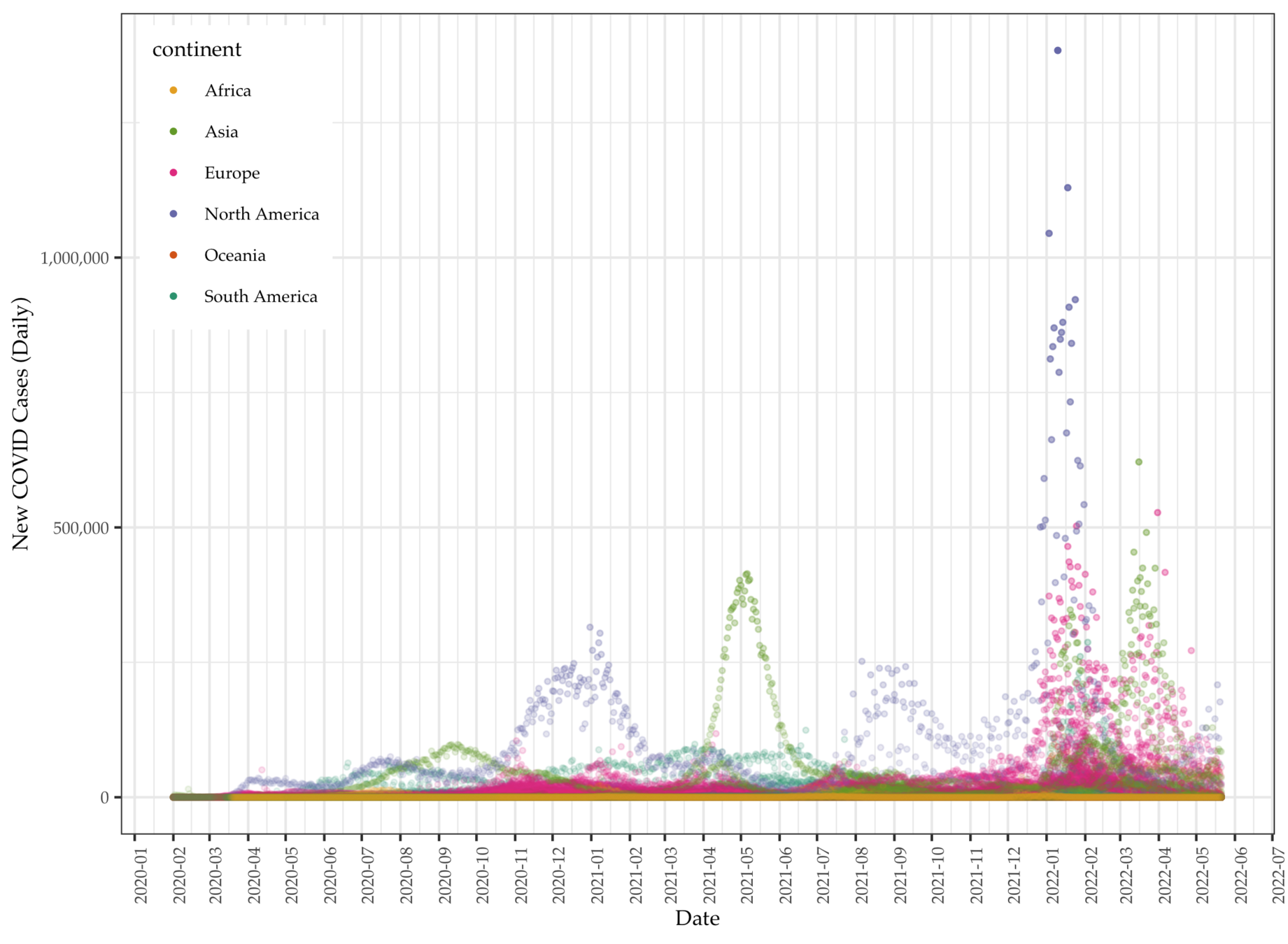
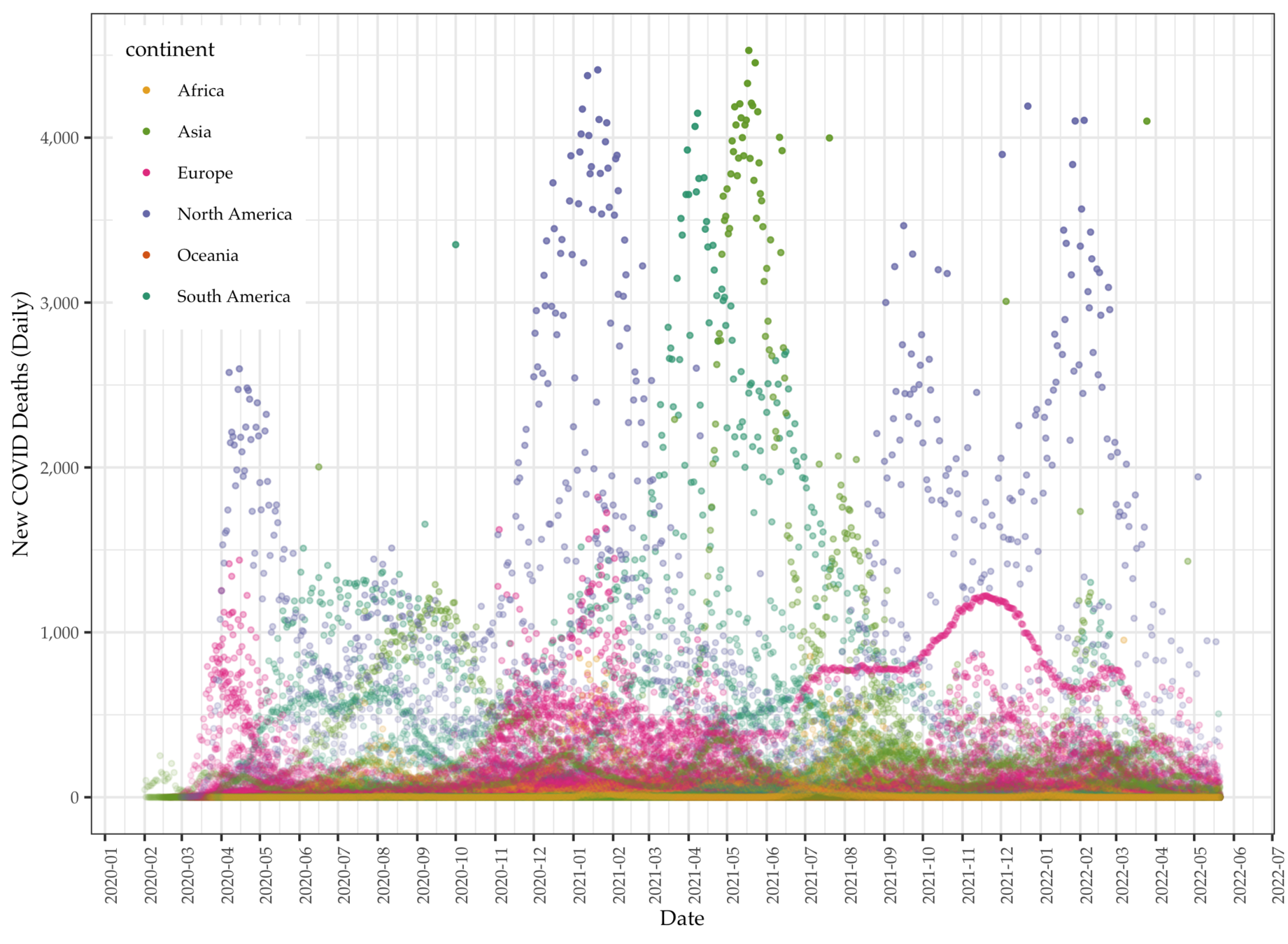
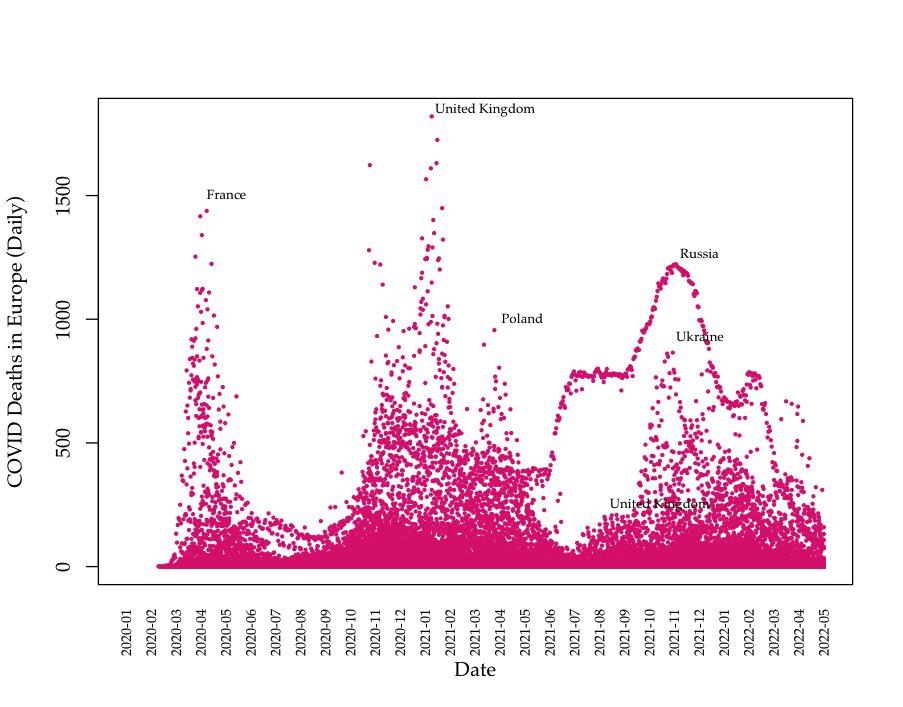
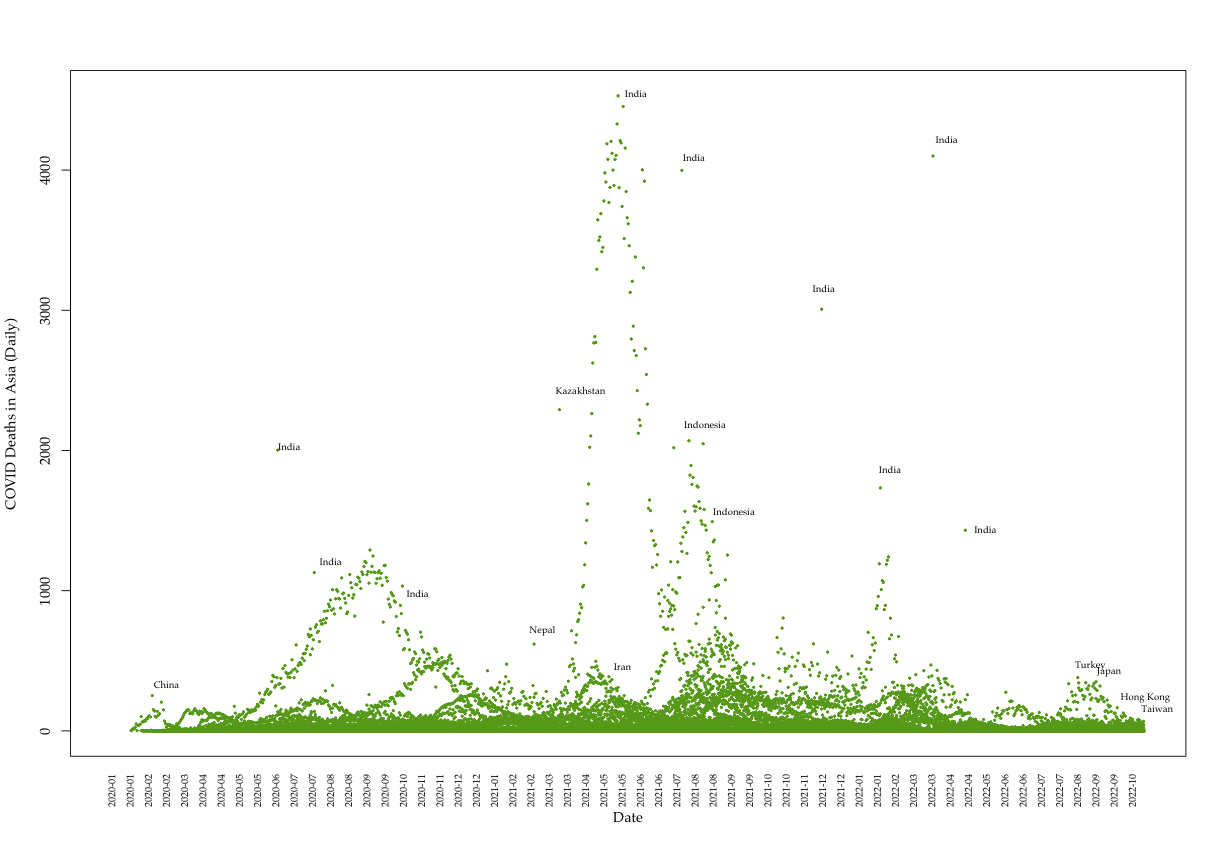
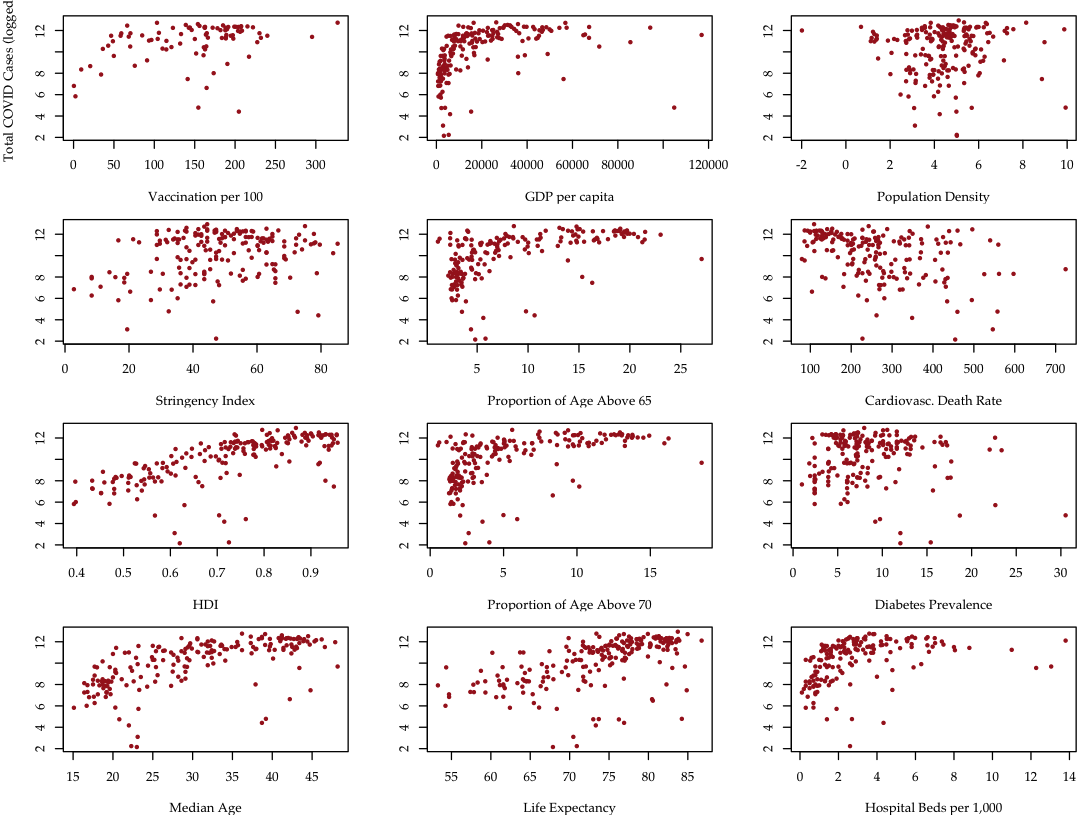
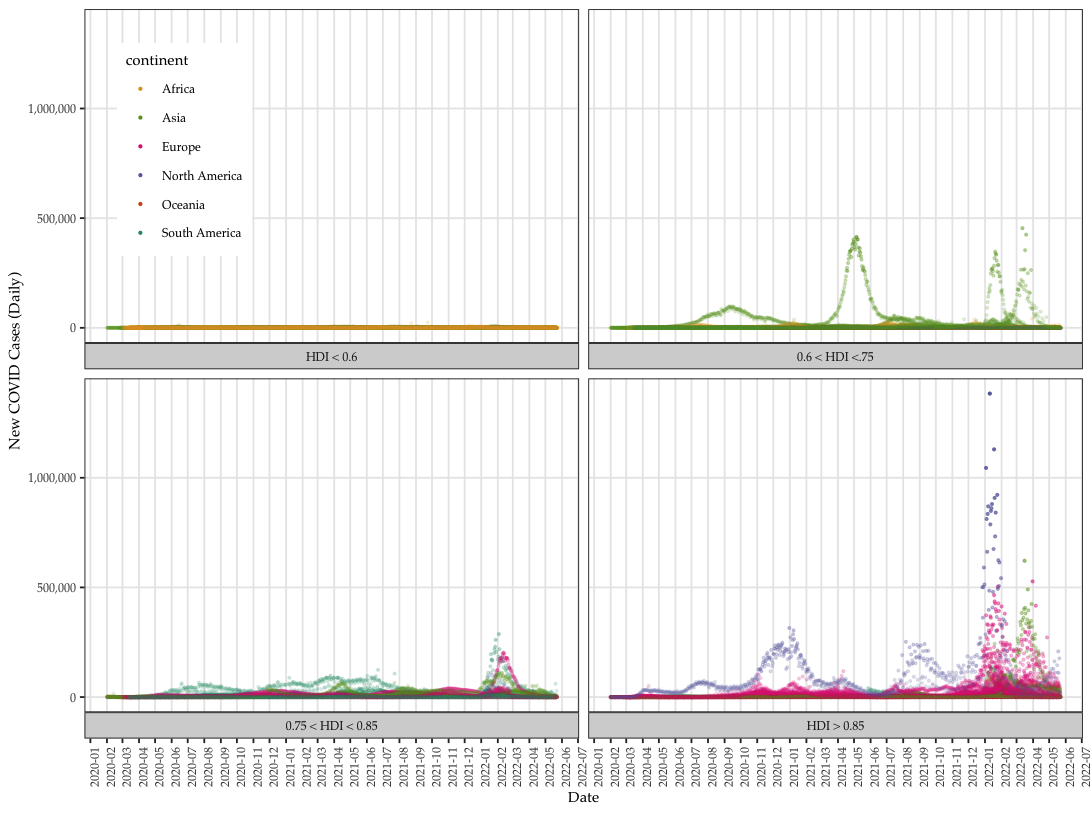
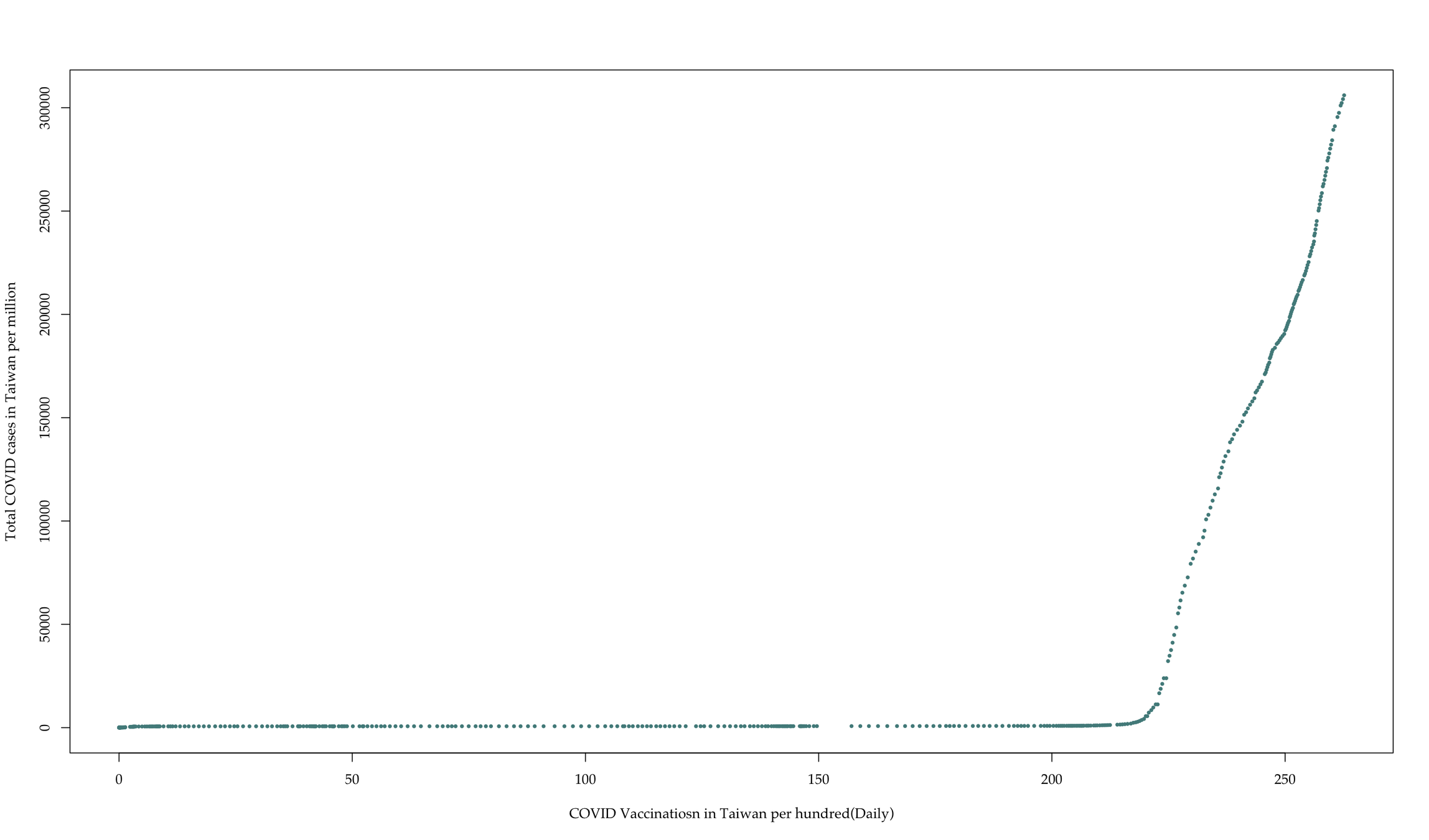
We collect global COVID data from the Our World in Data project, which makes daily pandemic data from all countries available in real time.
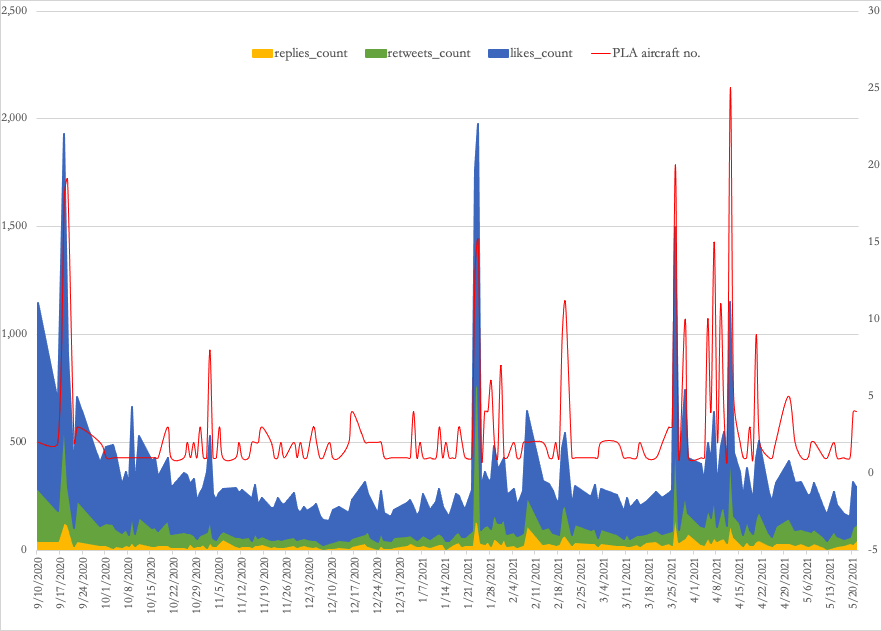
| Days (6/9/2020 - 5/21/2021) | 346 |
|---|---|
| Total dispatch | 455 |
| No. of operations | 167 |
| Max aircraft count | 25 |
| Min aircraft count | 1 |
| Average aircraft count | 2.72 |
| Average interval (days) | 1.53 |
| Average daytime | 5:53:55 AM |
Barlow, R. E., and H. D. Brunk. 1972. “The Isotonic Regression Problem and Its Dual.” Journal of the American Statistical Association 67(337): 140–47.
Dougherty, Michael R. et al. 2015. “An Introduction to the General Monotone Model with Application to Two Problematic Data Sets.” Sociological Methodology 45(1): 223–71.
Henzi, Alexander, Johanna F. Ziegel, and Tilmann Gneiting. 2021. “Isotonic Distributional Regression.” Journal of the Royal Statistical Society: Series B (Statistical Methodology) 83(5): 963–93.
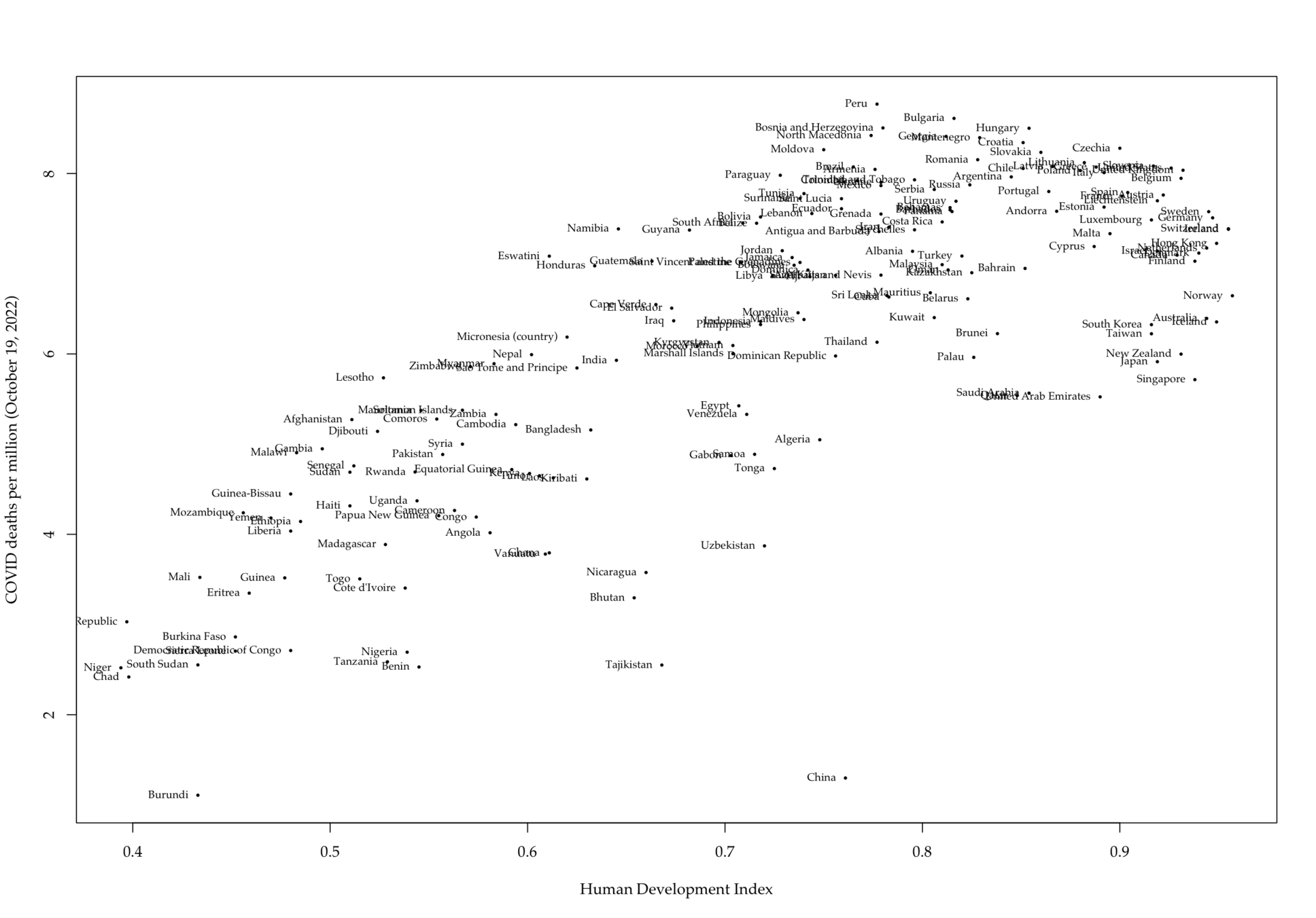
Khazaei, Zaher et al. 2020. “COVID-19 Pandemic in the World and Its Relation to Human Development Index: A Global Study.” Archives of Clinical Infectious Diseases 15(5). https://brief.land/archcid/articles/103093.html (May 25, 2022).
Leeuw, Jan de, Kurt Hornik, and Patrick Mair. 2009. “Isotone Optimization in R : Pool-Adjacent-Violators Algorithm (PAVA) and Active Set Methods.” Journal of Statistical Software 32(5). http://www.jstatsoft.org/v32/i05/ (April 10, 2022).
Satyadev, Nihal et al. 2022. “Machine Learning for Predicting Discharge Disposition After Traumatic Brain Injury.” Neurosurgery 90(6): 768–74.
Tibshirani, Robert. 1996. “Regression Shrinkage and Selection Via the Lasso.” Journal of the Royal Statistical Society: Series B (Methodological) 58(1): 267–88.
Tibshirani, Ryan J., Holger Hoefling, and Robert Tibshirani. 2011. “Nearly-Isotonic Regression.” Technometrics 53(1): 54–61.
Barlow, R. E., and H. D. Brunk. 1972. “The Isotonic Regression Problem and Its Dual.” Journal of the American Statistical Association 67(337): 140–47.
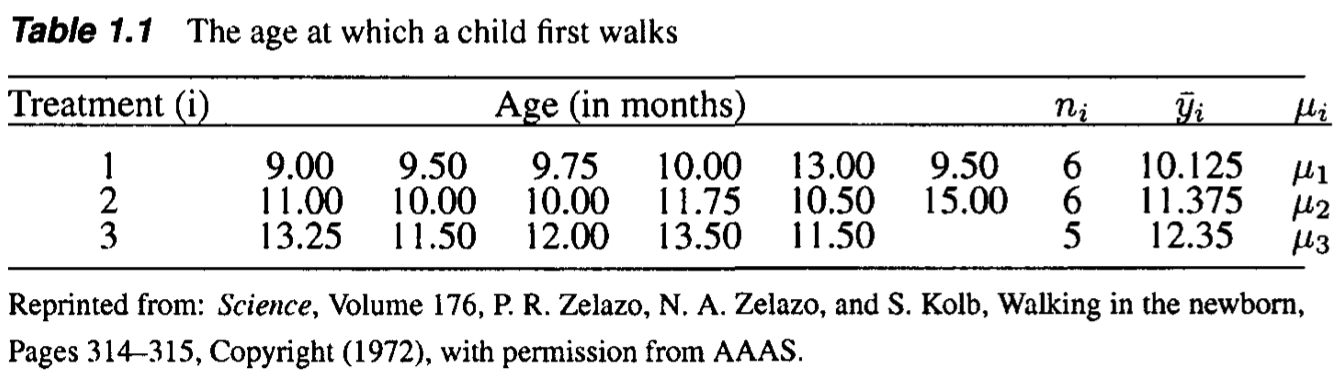
Zelazo, P. R., Zelazo, N. A., & Kolb, S. (1972). " Walking" in the Newborn. Science, 176(4032), 314-315.
Silvapulle, M. J., & Sen, P. K. 2011. Constrained statistical inference: Order, inequality, and shape constraints (Vol. 912). John Wiley & Sons.
Robertson, T., & Wright, F. T., Dykstra, R. L 1988. Order restricted statistical inference. Wiley Series in Probability and Mathematical Statistics: Probability and Mathematical Statistics. John Wiley & Sons, Ltd., Chichester.
Evaluate the effect of exercise on the age at which a child starts to walk.
Q: \(\mu_1=\mu_2=\mu_3\)
holds assuming \(\mu_1\leq \mu_2 \leq \mu_3\)?
The traditional ANOVA does not work because the maximum likelihood estimators (sample means) say \(\hat{\mu}_1 = \overline{Y}_1, \hat{\mu}_2=\overline{Y}_2,\) and \(\hat{\mu}_3 = \overline{Y}_3\), do not have to satisfy the trend \(\mu_1\leq\mu_2\leq\mu_3\). One should take the natural trend into account in the MLE (least-squares equivalently), that is,
\[(\tilde{\mu}_1, \tilde{\mu}_2, \tilde{\mu}_3 ) = \arg\min_{\mu_1\leq \mu_2\leq\mu_3}\sum_{i=1}^3\sum_{j=1}^{n_i} (Y_{ij} -\mu_i)^2 \]
where \(Y_{ij}\stackrel{iid}{\sim} N(\mu_i,\sigma^2)\) for \(j=1,\ldots,n_i\). Then \(\tilde{\mu}_1\leq \tilde{\mu}_2 \leq \tilde{\mu}_3\) (hurestically, equal means will be rejected when the overall mean \(\overline{Y}_\cdot\) under \(\mu_1=\mu_2=\mu_3\) are too different from \(\tilde{\mu}_1, \tilde{\mu}_2, \tilde{\mu}_3\).)
If \(\sigma^2\) varies, consider the weighted least squares (WLS):
\[(\tilde{\mu}_1, \tilde{\mu}_2, \tilde{\mu}_3 ) = \arg\min_{\mu_1\leq \mu_2\leq\mu_3}\sum_{i=1}^3\sum_{j=1}^{n_i} (Y_{ij} -\mu_i)^2 w_i \]
where \(Y_{ij}\stackrel{iid}{\sim} N(\mu_i,\sigma_i^2)\), \(w_i = n_i/\sigma_i^2\), and \(\tilde{\mu}_1\leq \tilde{\mu}_2 \leq \tilde{\mu}_3\), too.
In fact, in the weighted least squares, it suffices to optimize
\[(\tilde{\mu}_1, \tilde{\mu}_2, \tilde{\mu}_3 ) = \arg\min_{\mu_1\leq \mu_2\leq\mu_3}\sum_{i=1}^3(\overline{Y}_i -\mu_i)^2 w_i\]
where \(\overline{Y}_i\stackrel{iid}{\sim} N(\mu_i,\sigma_i^2/n_i)\) and \(w_i = n_i/\sigma_i^2\), i=1,2,3.
Above algorithm is the Pool Adjacent Violators Algorithm (PAVA)
Consider a conditional mean function \(\mu\) with \(\mu_i = \mu(x_i)\), and \(\mu(x)\) is increasing in \(x\), we can include the covariate \(x_i\) in isotonic regression model. For example, assume that \(Y_{ij}\stackrel{iid}{\sim} N(\mu(x_i),\sigma_i^2)\), where \(x_1\leq\ldots\leq x_n\), the MLE of \(\mu_i = \mu(x_i)\) is given by
\[(\tilde{\mu}_1, \ldots, \tilde{\mu}_n ) = \arg\min_{\mu_1\leq\ldots\leq\mu_n}\sum_{i=1}^n(\overline{Y}_i -\mu_i)^2 w_i\]
where \(w_i = n/\sigma_i^2\). In this case,
When \(Y_{ij}\stackrel{iid}{\sim}\) Bernoulli\((p(x_i))\), or \(\sum_{j=1}^{n_i}Y_{ij}\sim\)Binomial\( (n_i, p(x_i)) \) with \(0\leq p(x_i) \leq 1\) and \(p\) is increasing with \(p_i=p(x_i)\), the likelihood can be optimized similarly because
\[(\tilde{p}_1, \ldots, \tilde{p}_n ) = \arg\max_{p_1\leq \ldots\leq p_n}\prod_{i=1}^n p_i^{\sum_{j=1}^{n_i} Y_{ij}}(1-p_i)^{n_i-\sum_{j=1}^{n_i} Y_{ij}}\]
\[ = \arg\min_{p_1\leq \ldots\leq p_n}\sum_{i=1}^n (\overline{Y}_i - p_i)^2 n_i. \]
When \(Y_i\sim\) Poisson\((\lambda(x_i)T_i)\), \(\lambda(x_i) > 0\), where \(Y_i\) is the number of occurences in a Poisson process within time \([0,T_i]\) and hazard rate \(\lambda(x)\) is increasing in \(x\), then
\[(\tilde{\lambda}_1, \ldots, \tilde{\lambda}_n ) = \arg\max_{\lambda_1\leq \ldots\leq\lambda_n}\prod_{i=1}^n \left\{ \frac{(\lambda_i T_i)^{Y_i}\exp(-\lambda_i T_i)}{Y_i !} \right\}\]
\[ = \arg\min_{\lambda_1\leq \ldots\leq\lambda_n}\sum_{i=1}^n (g_i - \lambda_i)^2 w_i , \]
where \(w_i = T_i\) and \(g(x_i) = Y_i/T_i\), for \(i=1,\ldots,k\).
In summary,
The last point motivates this study: if a natural tendency of the target function, such as mean, probability, or hazard, is expected, the isotonic regression provides naive options of partitioning or grouping of covariates in terms of the relationship between the target function and the covariates, which will be helpful in classifying and clustering (this cannot be achieved by linear regression or other smoothed models.)
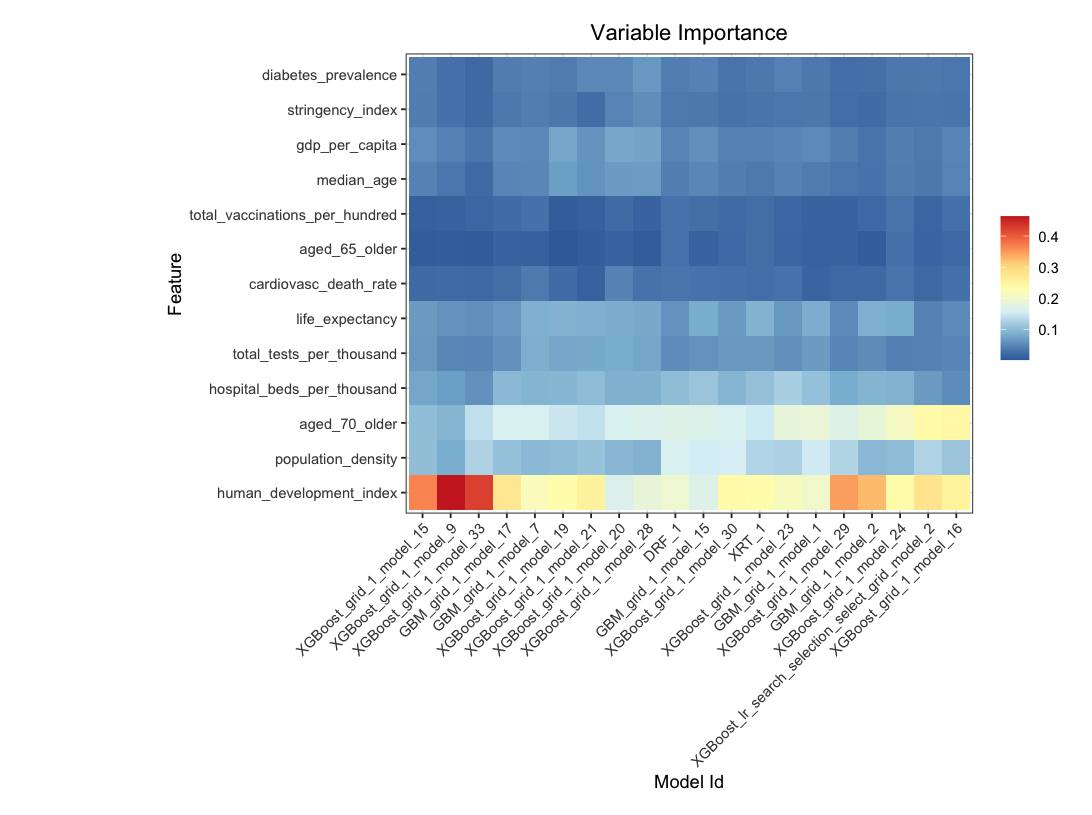
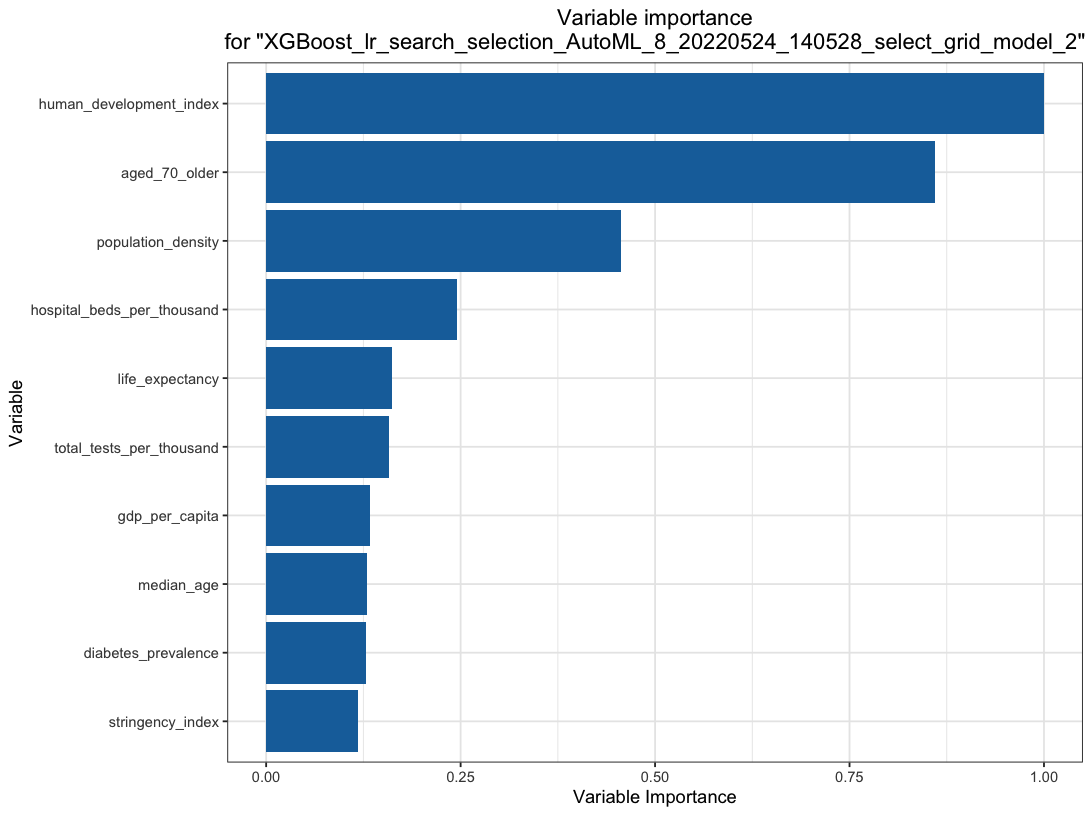
Q: What are the important covariates corresponding to the target function?
Machine learning can help!
By Karl Ho



