




Karl Ho
Data Generation datageneration.io
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
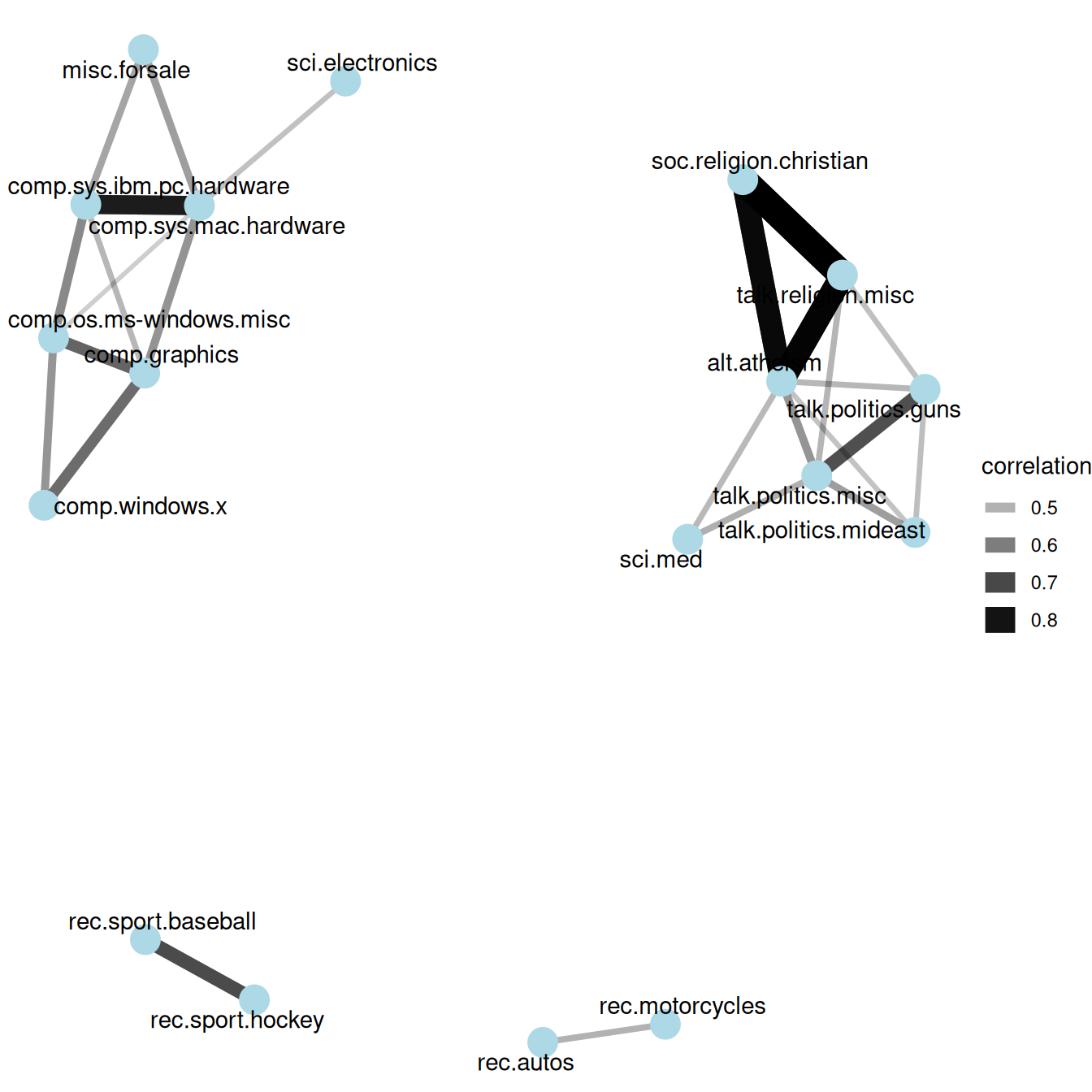
A network of Usenet groups based on the correlation of word counts between them
Silge, Julia. 2019. Text Mining in R
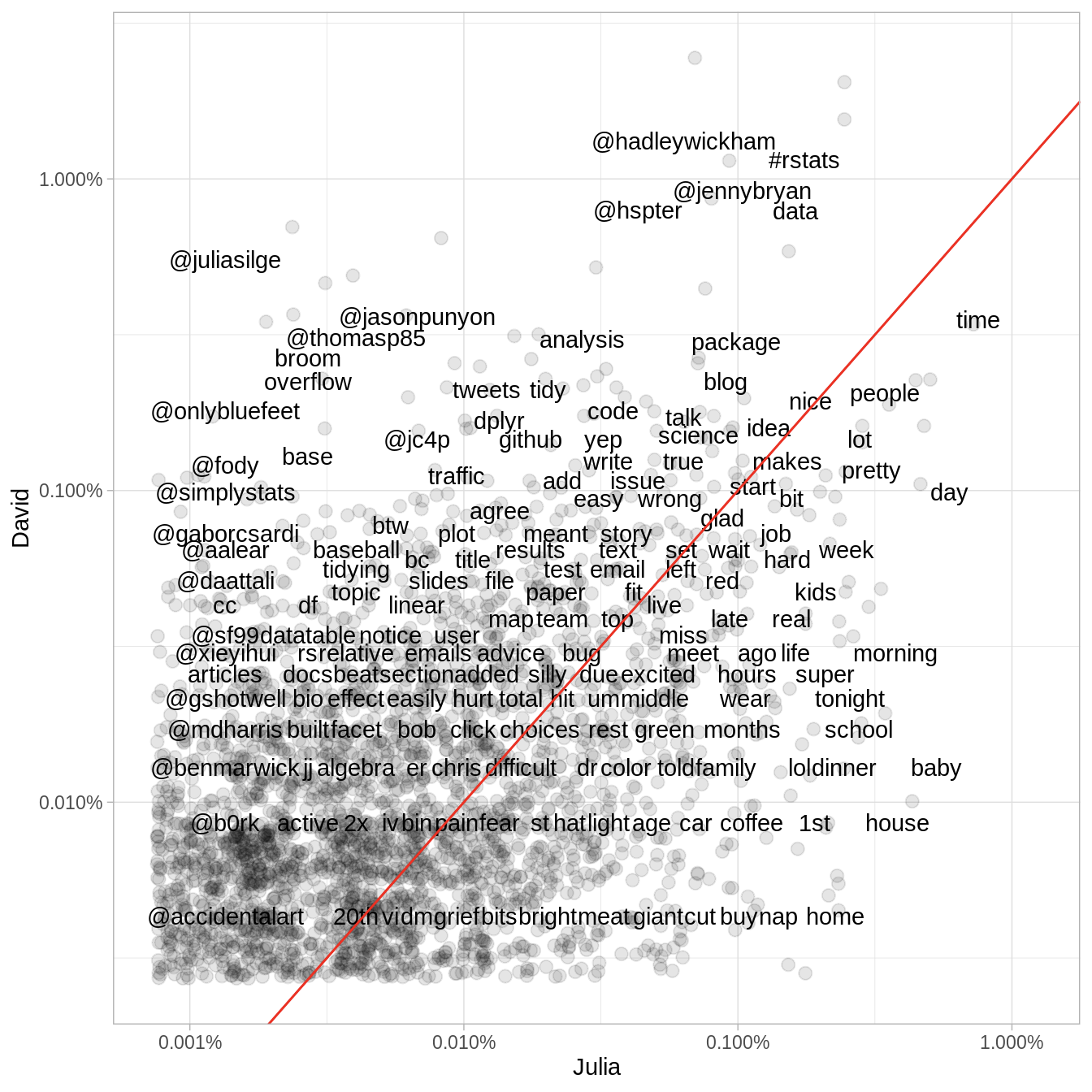
Comparing the frequency of words used by Twitter users
Silge, Julia. 2019. Text Mining in R
Aggarwal, C.C. and Zhai, C. eds., 2012. Mining text data. Springer Science & Business Media.
Ignatow, G. and Mihalcea, R., 2016. Text Mining: A Guidebook for the Social Sciences. Sage Publications.
Grimmer, Justin, Margaret E. Roberts, and Brandon M. Stewart. Text as data: A new framework for machine learning and the social sciences. Princeton University Press, 2022.
By Karl Ho



