Photometric Redshifts (in HELP)
Kenneth Duncan
Cosmic Census - Oct 2017
Leiden Observatory
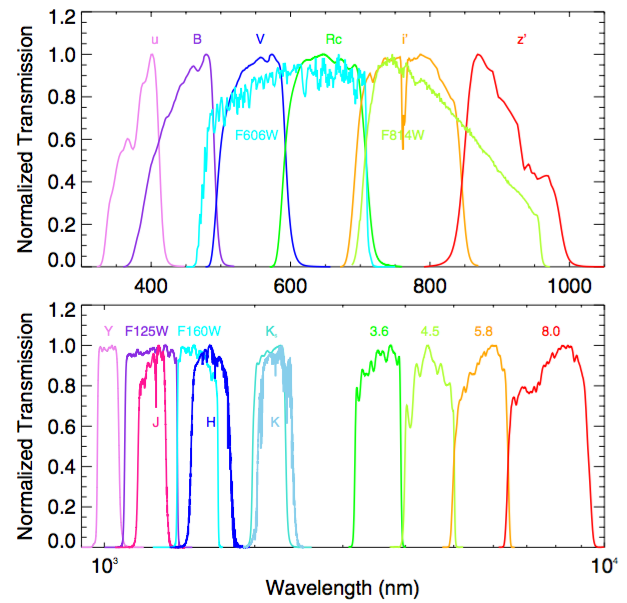
e.g. CANDELS UDS: Galametz et al. (2013)
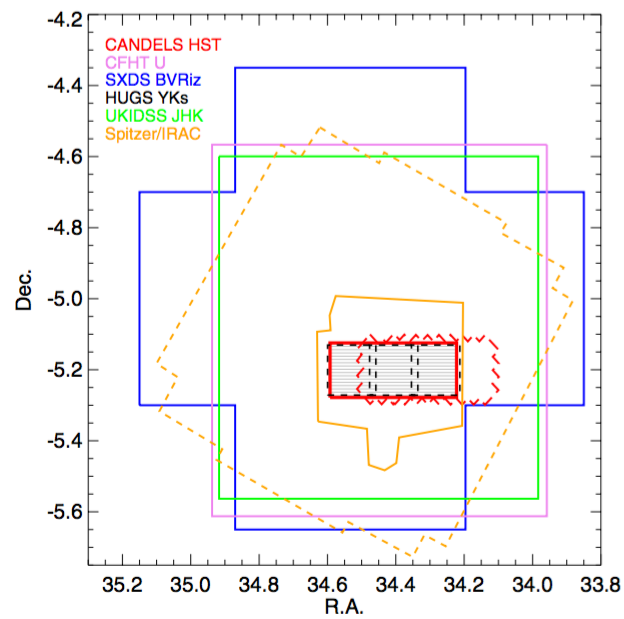
You have your nice new multi-wavelength catalog, now what...
Recipe 1:
Template fitting photo-z estimates
Step 1: The code
EAZY
Brammer et al. (2008)
LePhare
Arnouts et al. (1999)
Ilbert et al. (2006)
PhotoZ
Bender et al. (2001)
Hyper-Z
Bolzonella et al. (2000)
ZEBRA
Feldmann et al. (2006)
BPZ
Benitez (2000)
Step 1: The code
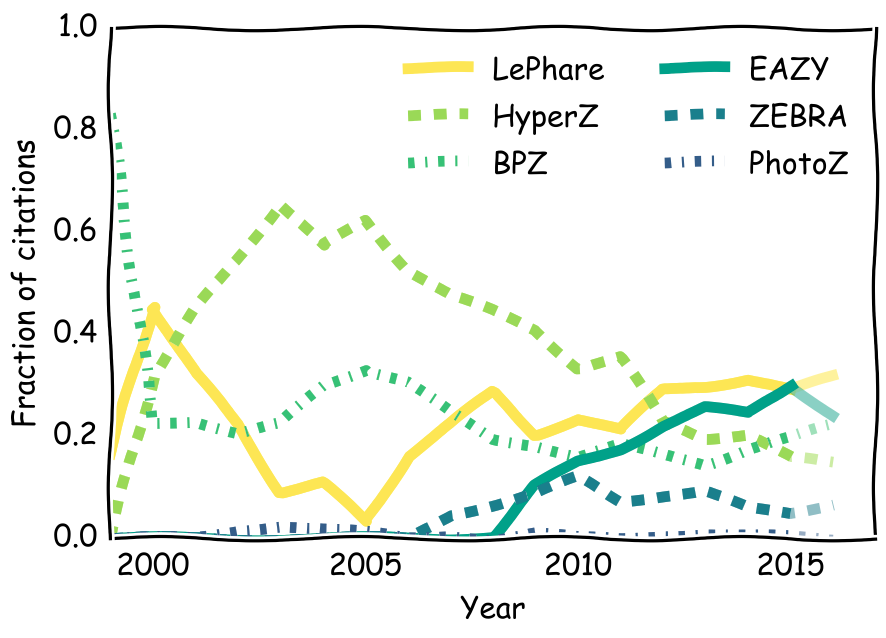
Total citations: ~2800
Then
Now
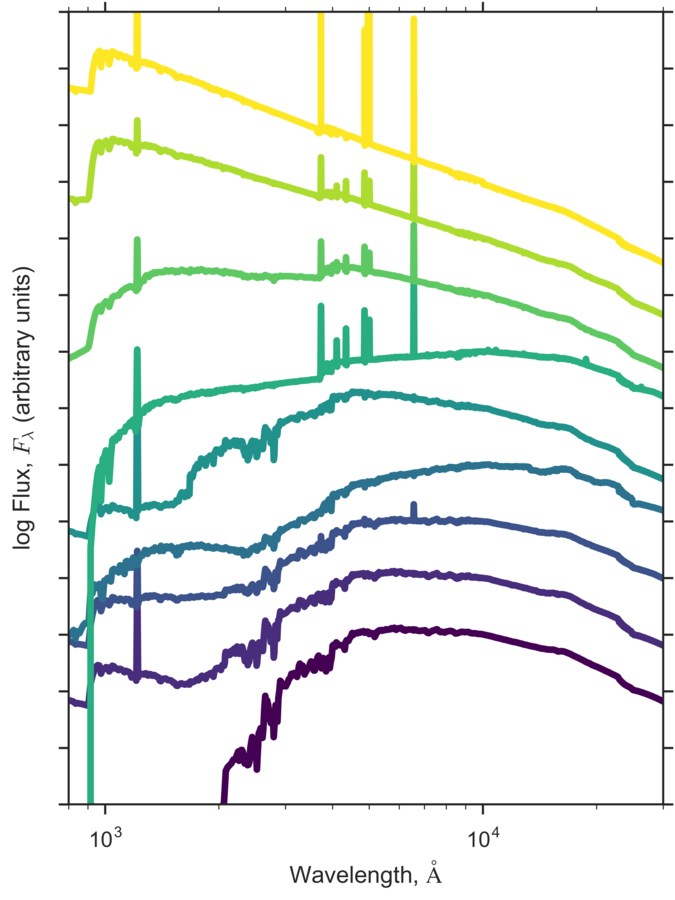
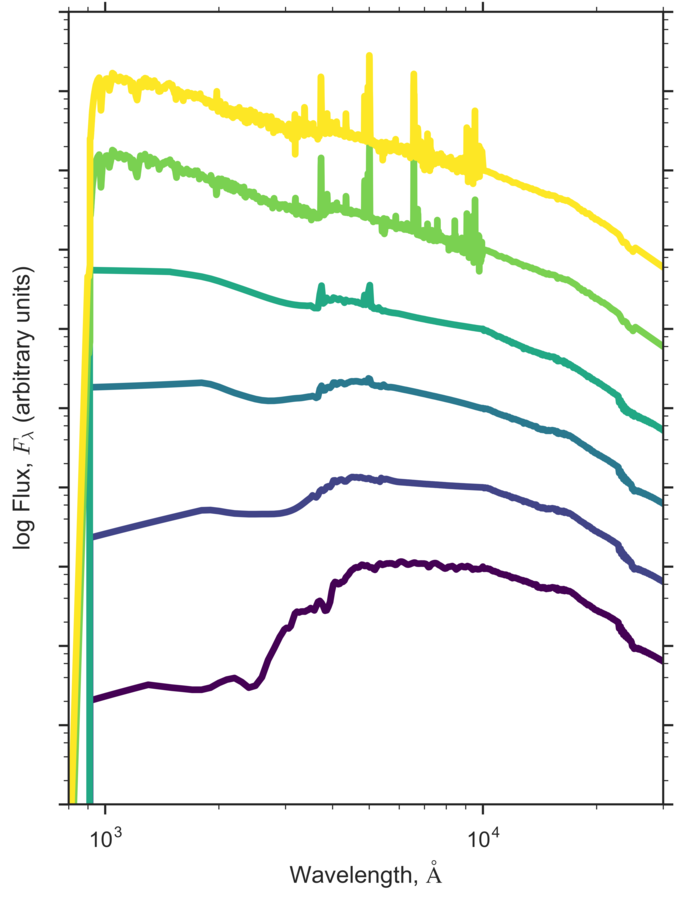
Step 2: The Templates
Step 3: zeropoint offsets and additional smoothing errors
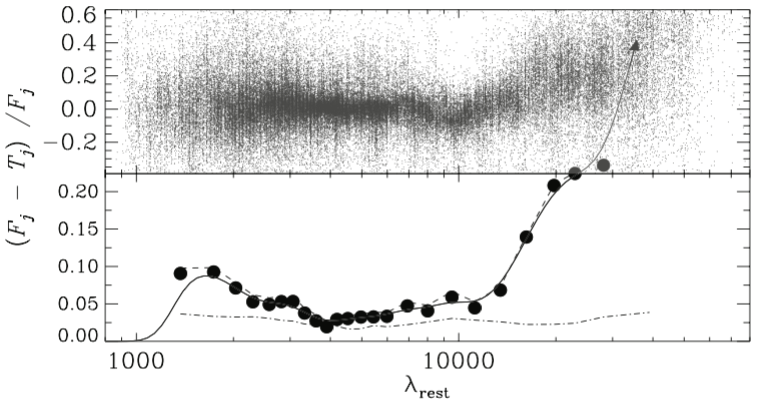
Additional rest-frame errors
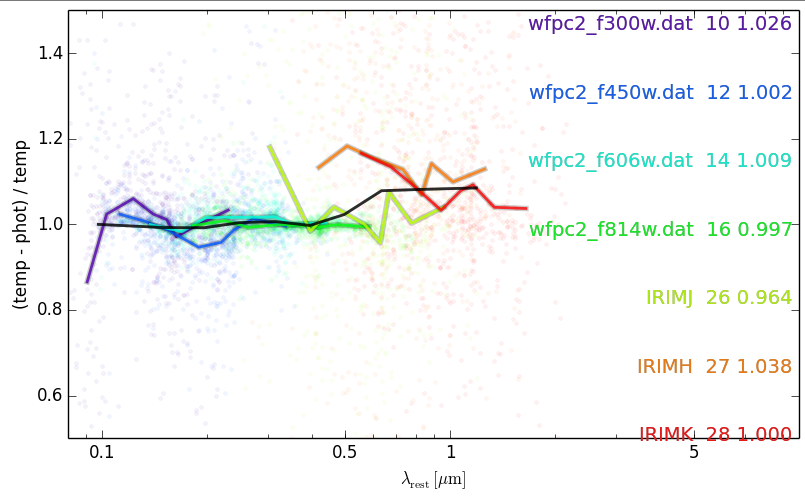
Corrections to the observed zeropoints
Brammer et al. (2008)
Dust
AGB Stars?
PAH/Dust emission/AGN?
Step 4: priors (optional)
Brammer et al. (2008)
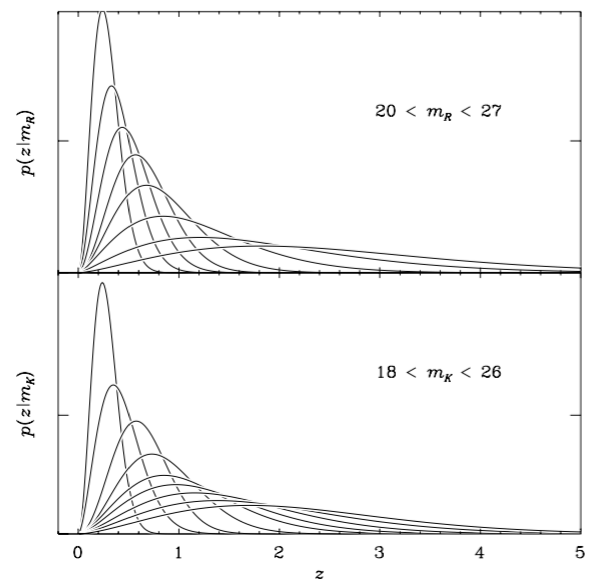
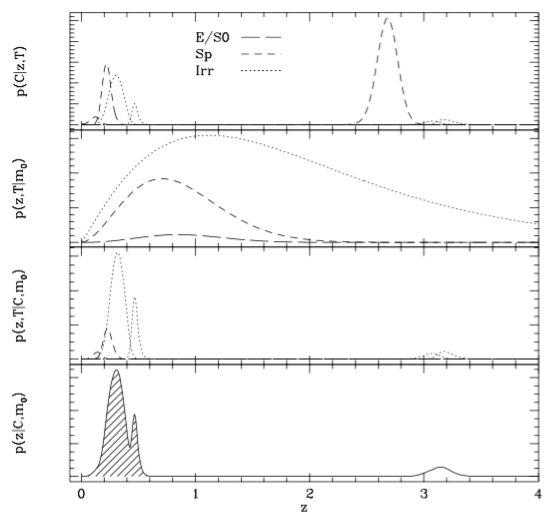
Benitez (2000)
Magnitude
Spectral type
Recipe 2:
Training based photo-z estimates
(aka machine learning)
Aside: Motivations for ML-based Photo-z's


Euclid
LSST
Aside: Motivations for training (ML) based Photo-z's
1. Speed
Euclid: ~1.5 billion galaxies
LSST: ~10 billion galaxies
Estimated time to run EAZY on all sources (on a desktop machine):
~2+ years (Euclid)
~14+ years (LSST)
Motivations for training (ML) based Photo-z's
2. Improvements in accuracy
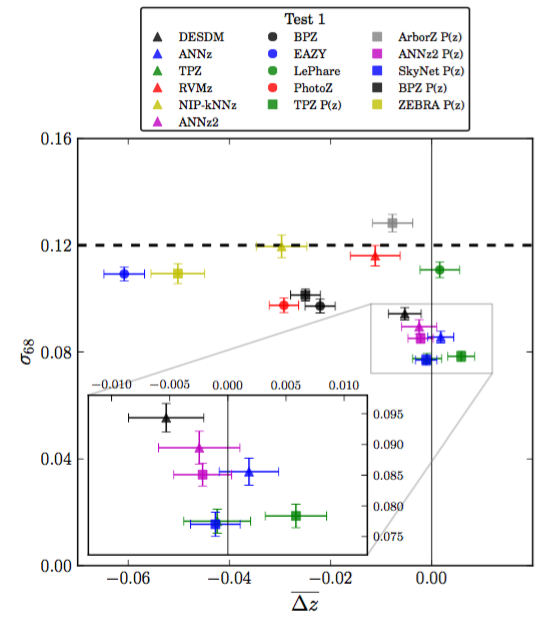
Sanchez et al. (2014)
Weak Lensing requirements:
Scatter
\sigma_{z}/(1+z) < 5\%
\langle z \rangle / (1+z) < 0.2\%
Bias
Step 1: Select your training sample
i.e. a representative subset of your sample with spectroscopic redshifts
Step 2: Pick your favourite regression/classification algorithm
Neural Networks
Self-organizing Maps (SOMs)
Deep learning
Support Vector Machines (SVM)
Naive Bayes
Gaussian Processes
Generalized Linear Models
Bayesian Network
k-Nearest Neighbour
Boosted Decision Trees
Randomised Forests
Relevance vector machines
Radial basis function networks
Normalised inner product nearest neighbour
Directional neighbourhood fitting
Voronoi tesselation density estimator
Non-conditional density estimation
Neural Networks
Self-organizing Maps (SOMs)
Deep learning
Support Vector Machines (SVM)
Naive Bayes
Gaussian Processes
Generalized Linear Models
Bayesian Network
k-Nearest Neighbour
Boosted Decision Trees
Randomised Forests
Relevance vector machines
Radial basis function networks
Normalised inner product nearest neighbour
Directional neighbourhood fitting
Voronoi tesselation density estimator
Non-conditional density estimation
Step 3: Train your regression/classification algorithm
Step 4: Apply to your science sample
magic happens somewhere here
Pros and Cons of ML Photo-z's
Pro:
- Fast and scalable
- Entirely empirical:
no concern about template choice
photometry systematics less of a problem - Simple to include extra information:
properties such as size and morphology can help break degeneracies
Con:
- Entirely dependent on spectroscopic training sample
- Struggle more with inhomogeneous datasets (e.g. missing filters)
- Difficult to physically interpret solutions - e.g. rest-frame colours
Final step: (For all photo-z methods)
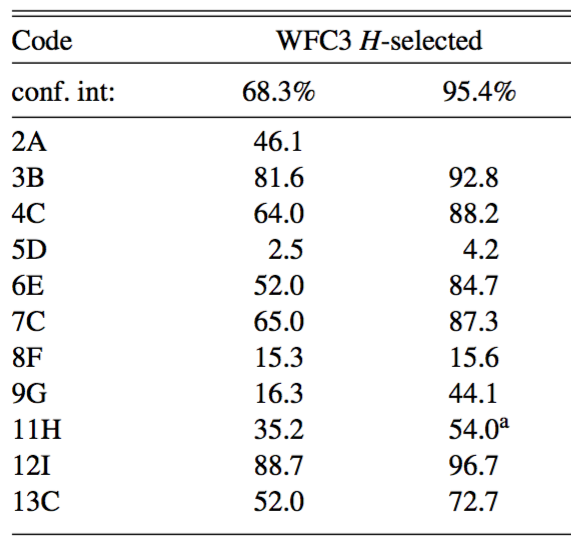
Fraction of spectroscopic redshifts within given confidence interval
Dahlen et al. (2012)
!
7/11 submitted photo-z estimates significantly overconfident for 1-sigma errors
Calibrating redshift pdfs
Calibrating redshift pdfs
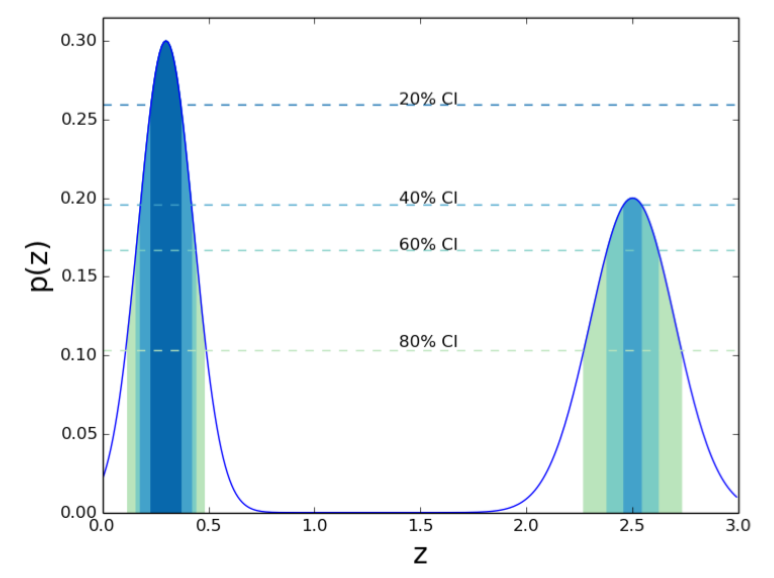
Wittman et al. (2016)
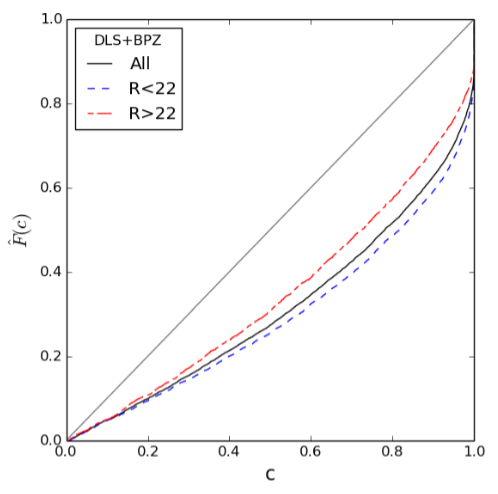
See also Bordoloi et al. (2010)
Under-confident
Over-confident
Improving photo-z estimates even more...
the wisdom of crowds
Combine multiple photo-z estimates
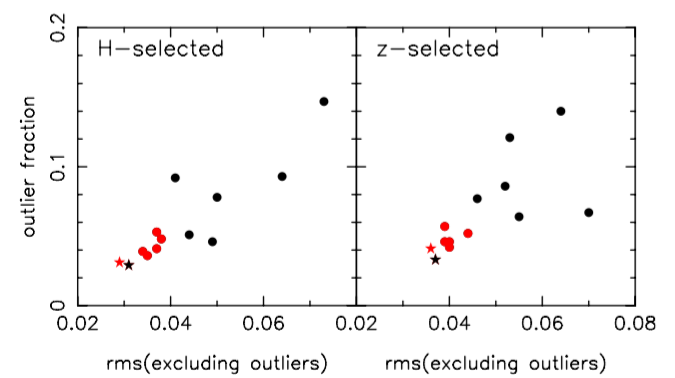
Dahlen et al. (2012)
= Median of all photo-z estimates
= Median of best 5 photo-z estimates
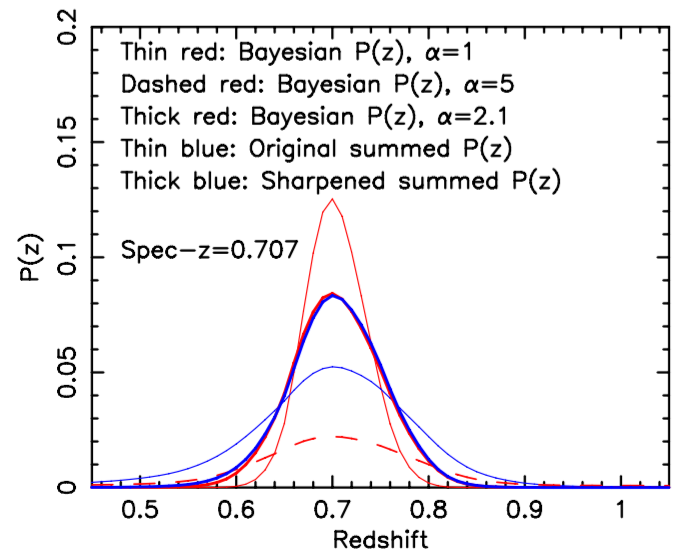
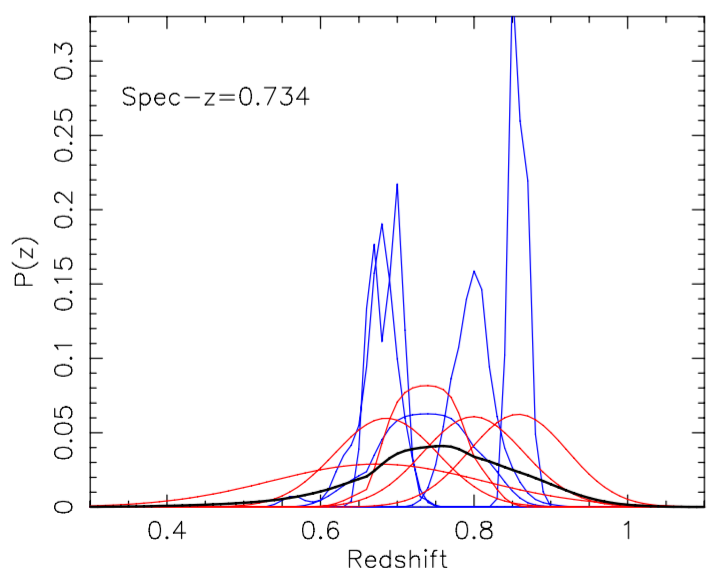
See also Carraso Kind & Brunner (2014)
Also works for diff. templates with the same code
Photometric redshift strategy for HELP
Gory details presented in...
Duncan et al. (2017a, 1709.09183)
and Duncan et al. (2017b, in prep)
Overall strategy for HELP
-
Run photo-z estimates using 3 different template libraries:
- eazy templates (stellar only)
- Salvato et al. XMM-COSMOS library (stellar and AGN/QSO)
- Michael Brown’s ‘Atlas of Galaxy SEDs’ (stellar and AGN)
-
Separate galaxies and AGN dominated sources where possible (optical/IR/X-ray selection) -> optimise magnitude priors and calibration procedure for each set
- Combine individual estimates to produce consensus P(z) using hierarchical Bayesian Combination
Overall strategy for HELP
-
Run photo-z estimates using 3 different template libraries:
- eazy templates (stellar only)
- Salvato et al. XMM-COSMOS library (stellar and AGN/QSO)
- Michael Brown’s ‘Atlas of Galaxy SEDs’ (stellar and AGN)
a) Zeropoint offset calculated separately for each individual template set
b) Lazy parallelisation of eazy, field split into many chunks and run in parallel.
Overall strategy for HELP
2. Separate galaxies and AGN dominated spectra where possible - optimise magnitude priors and calibration procedure for each set
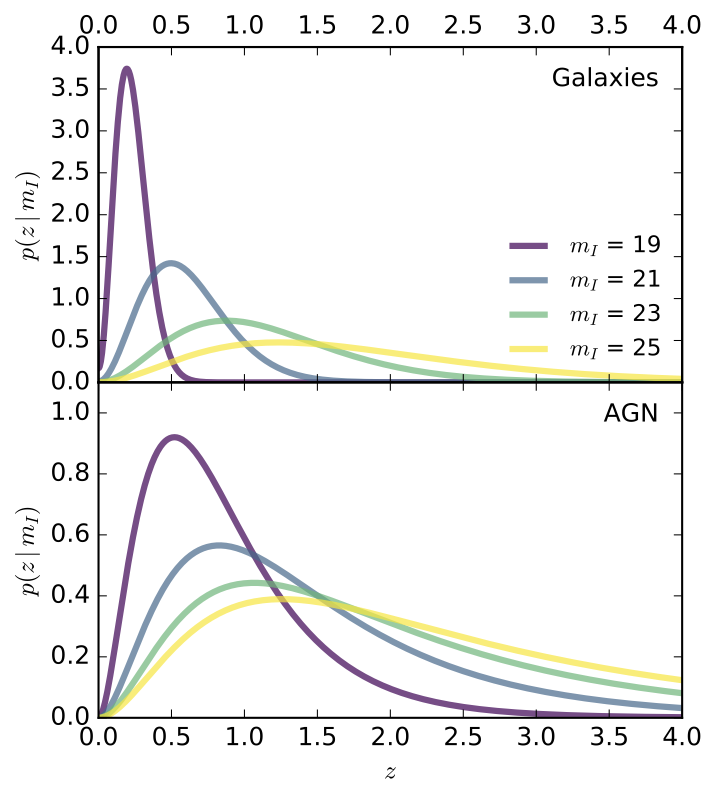
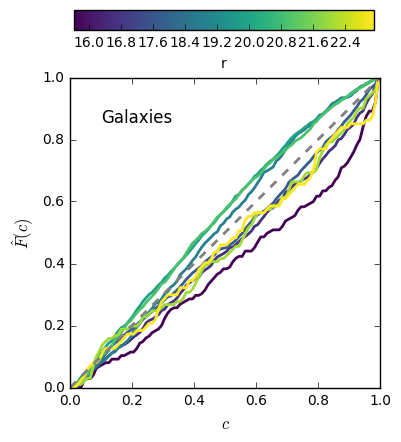
Overall strategy for HELP
-
Run photo-z estimates using 3 different template libraries:
- eazy templates (stellar only)
- Salvato et al. XMM-COSMOS library (stellar and AGN/QSO)
- Michael Brown’s ‘Atlas of Galaxy SEDs’ (stellar and AGN)
-
Separate galaxies and AGN dominated sources where possible (optical/IR/X-ray selection) -> optimise magnitude priors and calibration procedure for each set
- Combine individual estimates to produce consensus P(z) using hierarchical Bayesian Combination
What HELP will produce
What HELP will produce
1. Photometric redshift catalogs, including:
- Primary and secondary solutions
- Calibrated uncertainty estimates
What HELP will produce
1. Photometric redshift catalogs, including:
- Primary and secondary solutions
- Calibrated uncertainty estimates
- A range of corresponding diagnostic plots for each field
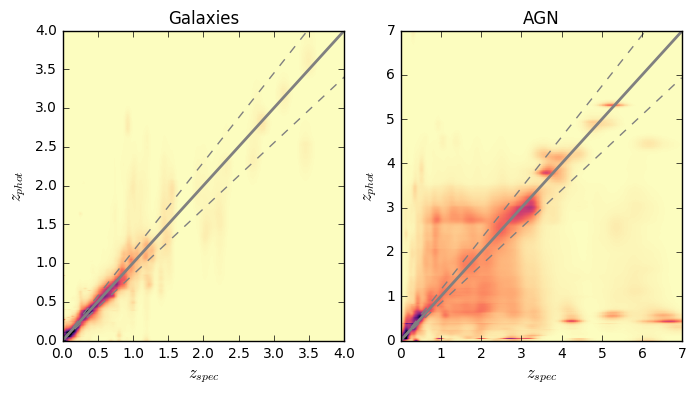
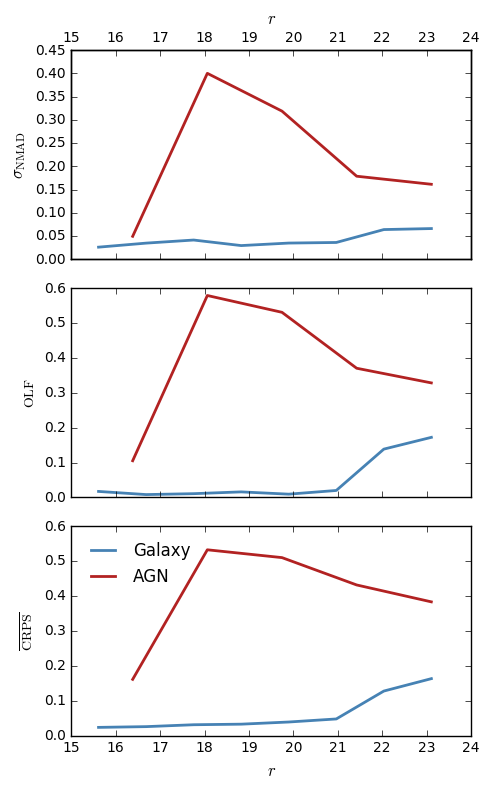
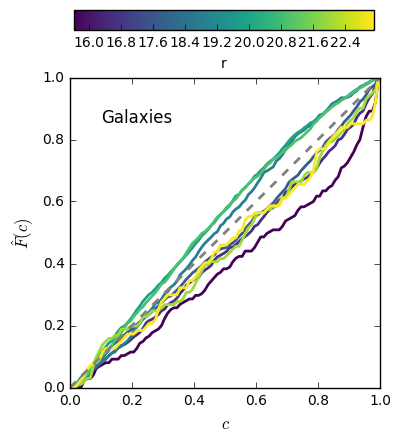
What HELP will produce
2. Selection functions:
For a source with a given set of photometric properties...
a) what is the probability of a photo-z estimate existing in the HELP database
b) what is the probability of a reliable* photo-z estimate existing in the HELP database
*a very flexible definition
Where HELP can help in future...
Compilation and homogenisation of datasets make machine learning estimates a more viable option for some fields
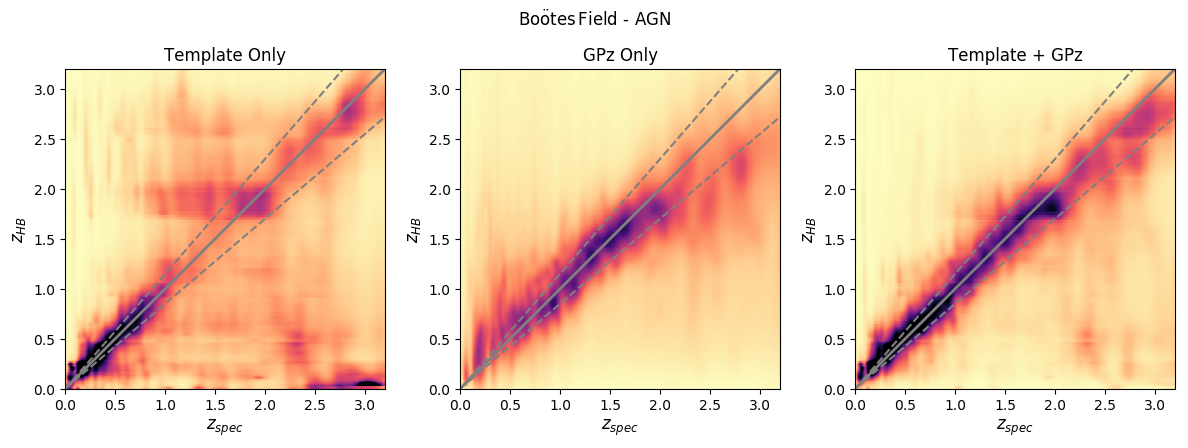
Incorporating targeted ML estimates can dramatically improve estimates for AGN
Summary
Producing consistent high quality photo-zs for 1300sq.deg of the sky is a challenge...but manageable
The heterogeneous nature of the datasets makes template fitting the only feasible starting point
Bayesian combination of multiple redshift estimates provides near optimal solutions across multiple fields/source types
Calibrate your photo-z errors!
Photometric redshifts in HELP
By Kenneth Duncan
Photometric redshifts in HELP
Review of photometric redshifts past, present and future. For the Lorentz Workshop Jun 20th-24th



