

















































Nat Connors PRO
Nat is a romantic comedy writer, medical scientist and dance teacher, and creator of the Kindletrends newsletter for genre fiction authors.
OCTOBER 2022
Nat 'Nose' Connors
<nat@kindletrends.com>
This is a web-based slide presentation. To go forward, click the slides and press the space bar, use the arrow keys, or swipe if you're on a touchscreen.
To see all the slides at once, press the 'o' key.
A bit about me and my background
Primer on machine learning and computational linguistics
Generative models - covers, speech, text
Long-form fiction analysis: a hard problem
Workflow consequences
Plagiarism: another hard problem
Commercial/legal issues
Roundup - how will it affect you as publishing industry professionals?
(my favourite subject)
Tech writing
Startup culture
Enterprise software development
Cancer research
(gene network modelling)
Author services
(data analysis)
A weekly and monthly genre research newsletter
Research done for you, in your inbox every week
Lots of confusing definitions and taxonomic argy-bargy
Artificial intelligence
Deep learning
Neural networks
Random forests
But here's my definition:
The numbers might represent different things
We might express the output in different ways
2
4
6
8
10
Input data
Output prediction
2
4
6
8
'probably between 9 and 11'
'A dog'
'A dog'
'A dog'
'A dog'
Ask 'where did the data come from?'
Ask 'what is done with the prediction?'
More important than the fine details of the method or galactic amounts of computing power
'Hickory dickory...
'Artificial intelligence' was quite different 1960-2010s (although taxonomy isn't very important)
Made possible by: 1)accessible computing power, and 2)oodles of 'free' metadata-tagged information
But profound questions of attribution, bias, provenance and consequences remain
"The Internet was...the boot loader for AI"
Understanding language using algorithms
(= sets of rules)
Text analysis
...but these tools are oriented toward business writing
Some claims about 'using computers to analyse bestsellers'...
...but I've set to see actionable insights at the story level (why? I think I know...)
Translation
Interpretation (question answering)
Actual language research in the humanities
(generative models)
Just like our dog example
Associate pictures with words, and group 'similar' items together.
Input a phrase or picture -> get back a 'similar' picture
'dog' using DALL-E 2
'A dog'
'A dog'
'A dog'
'beast romance fantasy photorealistic'
'man chest black and white'
fantasy castle, book cover, illustration, artstation
DALL-E/DALL-E 2 (OpenAI)
Stable Diffusion (StabilityAI)
Imagen (Google)
Midjourney (maybe)
Craiyon (open source)
https://www.artbreeder.com/
https://www.wombo.art/
https://accomplice.ai
https://www.midjourney.com
https://replicate.com/
https://nightcafe.studio/
etc.
Making new models is hard work/expensive
What are they trained on?
What is the output?
LAION/Common Crawl
MSCOCO
YFCC100M
ImageNet
Text
Related image
Related image
Image
'Related' is defined wholly by the data used to make ('train') the model
So you get some unexpected effects
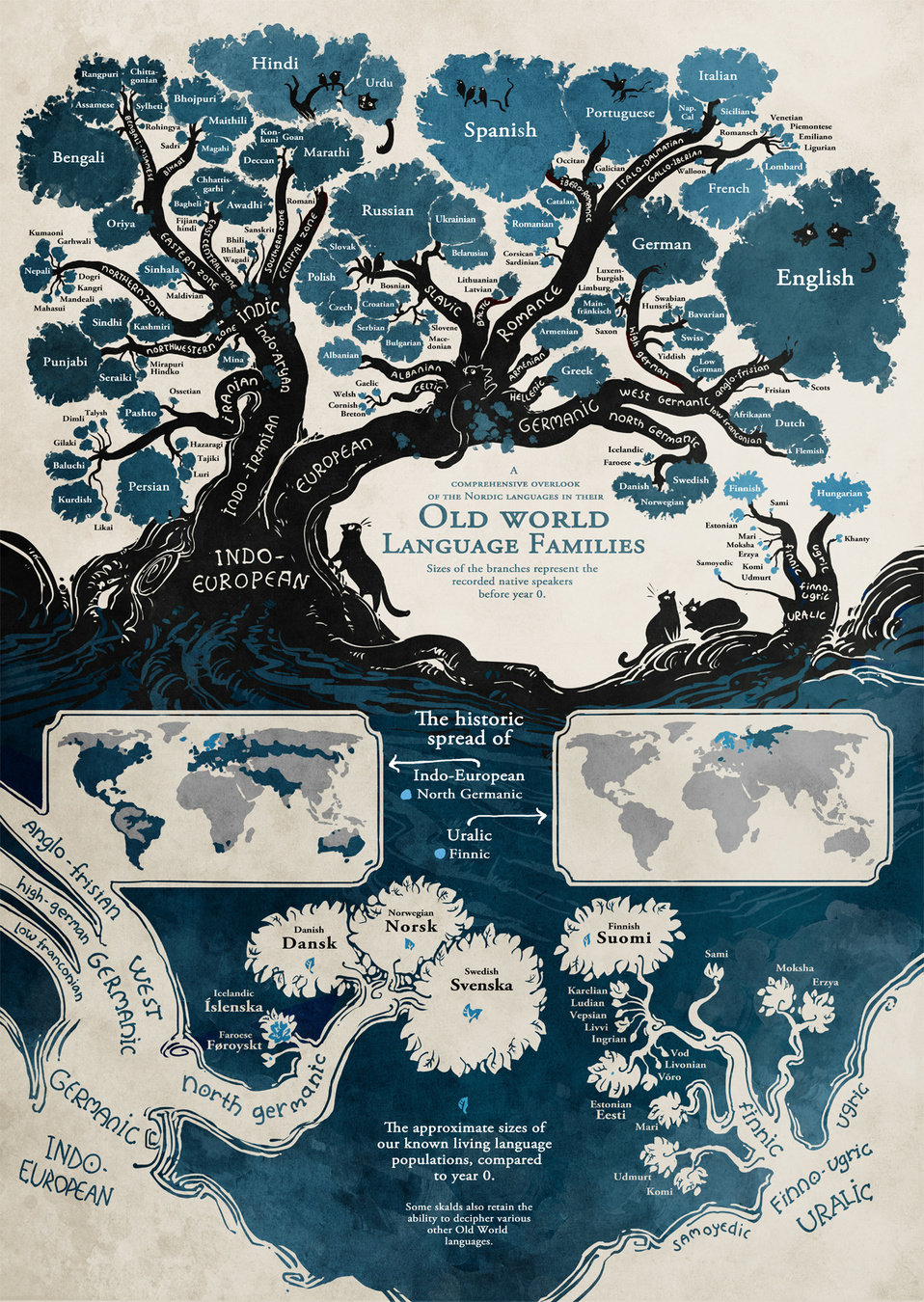
Who?
Prolific fantasy artist who has a large portfolio online
Carefully added metadata to his portfolio
Result > 50x more frequently used as a prompt than Michaelangelo/Picasso/da Vinci
...he's not making a cent off it
Logos turning up in pictures (sort of)
https://twitter.com/amoebadesign/status/1534542037814591490
Attribution/copyright is murky
"Images for ImageNet were collected from various online sources. ImageNet doesn't own the copyright for any of the images."
"If you become aware that any social media website uses any Content in a manner that exceeds your license hereunder, you agree to remove all derivative works incorporating Content from such Social Media Site, and to promptly notify Shutterstock of each such social media website's use."
Bias in the input data > bias in the output
'a CEO seated at a desk'
Stable Diffusion
(via Accomplice)
DALL-E 2
If you want anything outside the norm for a cover/other illustration, it may not be easy to produce
It will be much more likely to bear a close resemblance to the input data -> increased commercial risk
Publishing outside the Anglosphere requires quite different stylistic elements in cover design (cf. Cozy Mysteries)
Here, sequences of numbers represent sounds (words or parts of words)
But the same principles apply
What are they trained on?
What is the output?
Common Voice (Mozilla)
Speech recognition services? (Google, Microsoft, Apple)
Probably large private datasets
Text
Audio waveform
'Authenticity' of speech is heavily affected by context
...but the results can be impressive
...possibly, but 'synthetic voice producer' will be a new job
Has a long history predating machine learning
'Musical dice games' were popular in the 18th century
'Plotto', a book from 1928, generates (quite involved) plots from a systematic process
I made a (simple) generator for 5K short romance stories! It was...not the money-printing machine I had hoped for
Computational approaches started with 'Markov chain' methods
- read in a lot of text and look at what word follows what
- kind of like a dice game too
I
am
a
fireman
lamp-post
0.5
0.5
Actually work very well for short, structured things without much context
The sea darkens;
the daffodil
bending at a postThis first snow
falls from the water jar
on the year ending rainWine reviews (a favourite!):
There once was a young man
Who never smiled as he walked.
And his smile always looked to be
A frown, and his eyes were cold.
He didn't laugh or grin,
Just glared at the world around him.
I looked at the pistol on the mantelpiece, and
as I did so a thought occurred to me. It was a logical thought, but it took some time before I realised that I had never seen myself as being part of the logic.
'You're going to have to kill me,' I said.
GPT-2/GPT-3 family (OpenAI)
https://www.sudowrite.com/
https://inferkit.com/
https://novelai.net/
Making new models is hard work/expensive
BERT family (Google)
What are they trained on?
What is the output?
'BooksCorpus'
Text
Text (sentence/
paragraph) completions
Distributions of words and phrases
Most of these methods 'fall off a cliff' at about 500 words or so
Fiction has 'long-range' structures as well as short-range ones
Phrases
Sentences
Paragraphs
Plot arc(s)
Character arc(s)
Themes
Motifs
(which is a fancy way of saying 'carrying meaning that isn't explicitly encoded')
Computational notions of similarity don't match human notions of similarity
(possibly because of the previous point)
I made a plagiarism detector based on 'n-gram overlap'
It sort-of worked but cannot talk humans out of their feelings/beliefs
Attribution is murky
CC/other permissive licenses aren't the free-for-all they are believed to be
Those making the tools don't profit from the images
Similarity is a subjective issue
Bias in datasets, both present and introduced
Guided iteration on a concept
Change management for books - a whole separate (interesting!) issue
Customers iterating toward options/choices on their own?
Don't panic
Creative work will change its toolset, but it will remain creative
Example: 'AI prompt generator' is now a job!
Familiarise yourself with the major generative tools in your area
Work out how they were trained
Use your nous+experience to perceive their consequent biases and act accordingly
An upside: generative technologies may help with work-for-hire
There may be value in positioning your client's work relative to others
Consider 'visualisation' tools to explain to clients what you are doing - a fascinating area
Help me make an editing tool which provides actionable insights at the whole story level!
Positioning relative to other titles may become more precise/fine-grained
Rapidly generating variations may allow for targeting to specific audiences (e.g. audio)
New channels are coming out all the time - stay alert to the possibility of generative content for them (= Tiktok!)
'Success' metrics should be treated with suspicion
Don't rely on your legal team to safeguard you against copyright/plagiarism exposure
Support your team to learn about new technologies - they will see the specifics where you may not
Harry for giving me the chance to speak
Susie for organising everything
Authors and artists who helped with this talk
Lana Love
Sansa Rayne
Sacha Black
Rachael Herron
Steffanie Holmes
The SPA Girls
Relay staff
For the slides for this talk:
https://slides.com/kindletrends/technology-trends-in-indie-publishing
Accomplice AI: https://accomplice.ai/ - a good starting point for playing with image generation
Have I Been Trained: https://haveibeentrained.com - a resource for artists to check their work
How DALL-E 2 works: https://www.assemblyai.com/blog/how-dall-e-2-actually-works/ - a good nontechnical explanation
State of AI 2022 presentation: https://www.stateof.ai/ - long and very general (not publishing-focused) but comprehensive
https://waxy.org/2022/08/exploring-12-million-of-the-images-used-to-train-stable-diffusions-image-generator/ - detailed analysis of the sources of many training images
Prompter: https://www.thedreamingstate.com/portfolio/art/prompter/ - a useful tool for getting started with making image prompts
Whisper (OpenAI): https://openai.com/blog/whisper/ - alarmingly good speech recognition
By Nat Connors



