弥生株式会社
黒曜
(@kokuyouwind)
$ whoami
-
黒曜
-
@kokuyouwind
-
Misoca → 弥生株式会社 (We're Hiring!)
-
一応Railsエンジニア
-
最近はAWSとかDocker周りを
弄っていることが多い

Railsは便利!
🤔
「どうして」便利なんだろう……?
「いい感じ」に書ける!
「いい感じ」に書ける!
人間の「意図」を
表現しやすい
↓
例えば……
Event.find_by(name: 'Kaigi on Rails')
.sessions
.find_or_create_by(speaker: 'kokuyouwind')
.update(start_time: '10:50')例えば……
イベントの中から「Kaigi on Rails」を探して、
発表者がkokuyouwindのセッションを見つける。
(存在しない場合は作る)
そして、セッション開始時刻を10:50に更新する。
Event.find_by(name: 'Kaigi on Rails')
.sessions
.find_or_create_by(speaker: 'kokuyouwind')
.update(start_time: '10:50')人間の「意図」は
表現しやすい
実際の挙動は?
どんなクエリが、合計何回実行される?
イベントやセッションがたくさんあっても大丈夫?
Event.find_by(name: 'Kaigi on Rails')
.sessions
.find_or_create_by(speaker: 'kokuyouwind')
.update(start_time: '10:50')細かい「挙動」は
把握しづらいことがある
細かい挙動が把握しづらいと……
-
それ自体は悪いことではない
-
低レベルの挙動は抽象化されていたほうが、
高レベルの意図を理解しやすい
-
-
気をつけないと、効率の悪い処理になる場合がある
-
DB処理は ActiveRecord -> SQL -> 実行計画と
2段階に翻訳されるので、より把握しづらい -
パフォーマンス悪化や、最悪応答不能になることも
-
パフォーマンスの計測・改善をしよう!
アジェンダ
-
パフォーマンスの計測
-
DB処理のチューニング
-
CPU処理のチューニング
-
ケーススタディ
-
まとめ
アジェンダ
-
パフォーマンスの計測
-
DB処理のチューニング
-
CPU処理のチューニング
-
ケーススタディ
-
まとめ
パフォーマンスを改善するには
問題がどこにあるか
分析する必要がある
パフォーマンスに影響を与える要素
-
CPU
-
フロントエンド
-
サーバサイド
-
-
入出力
-
データベース
-
ファイル
-
ネットワーク
-
パフォーマンスに影響を与える要素
-
CPU
-
フロントエンド
-
サーバサイド
-
-
入出力
-
データベース ← だいたいここが問題
-
ファイル
-
ネットワーク
-
APM
(Application Monitoring Management)

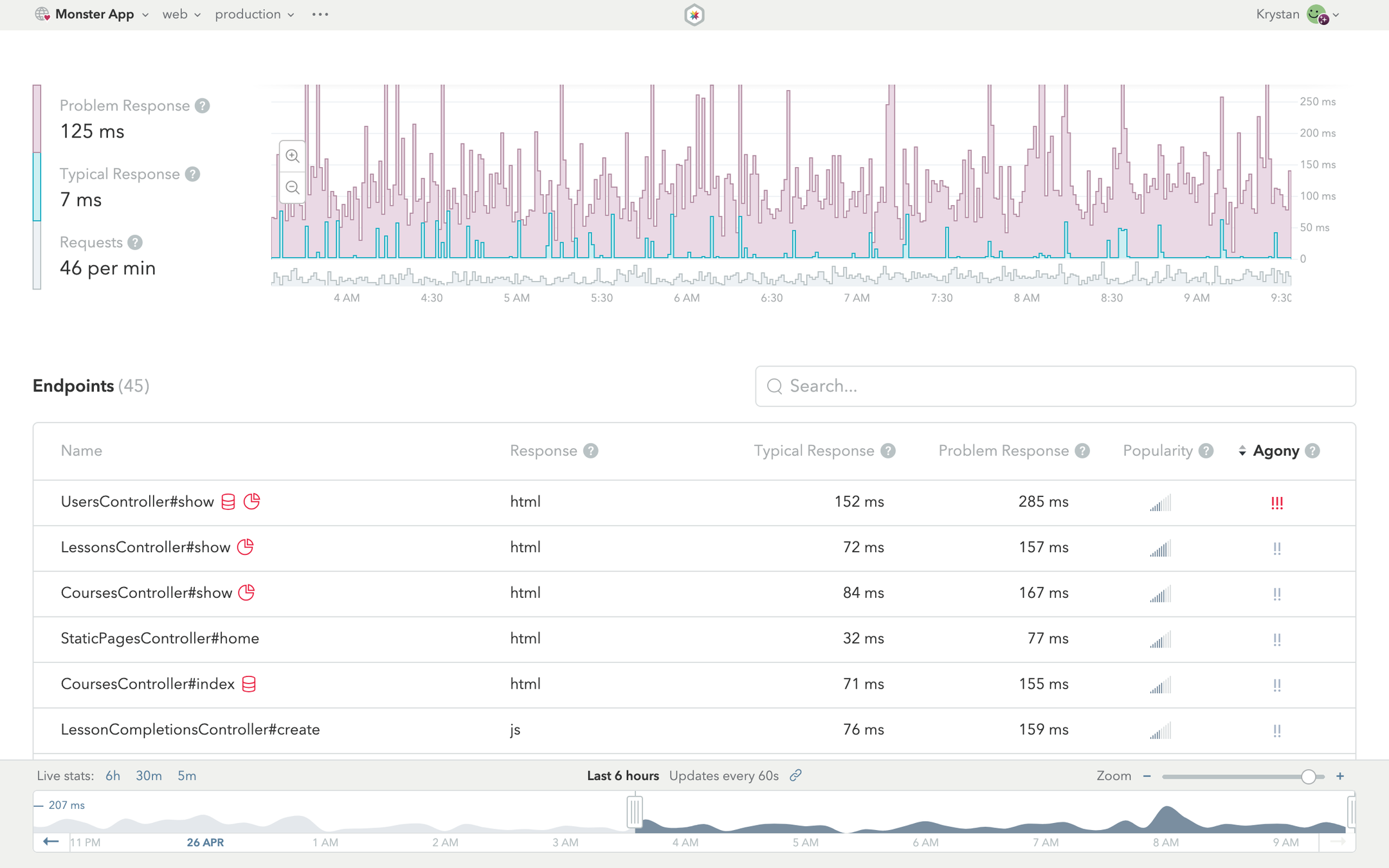
APMツールでわかること
どのエンドポイントが重いか
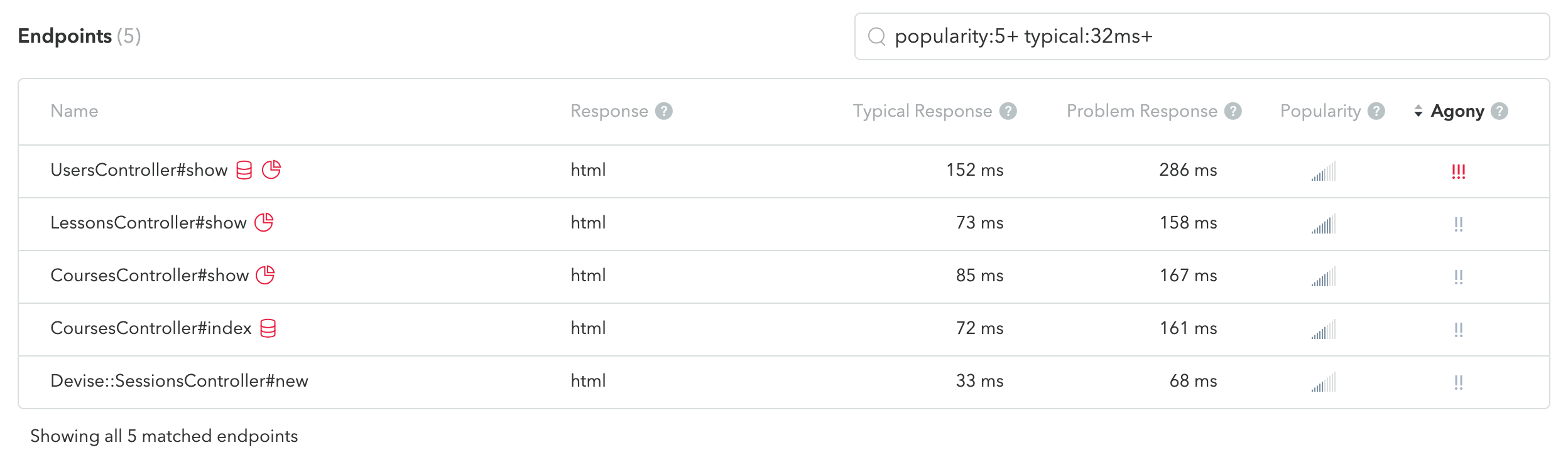
APMツールでわかること
どの処理やクエリに時間がかかっているか
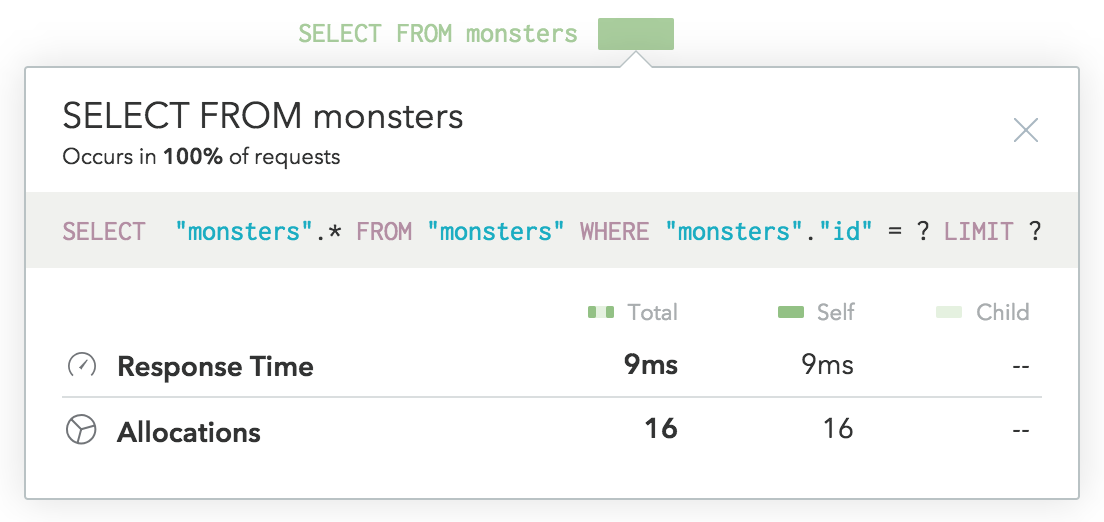
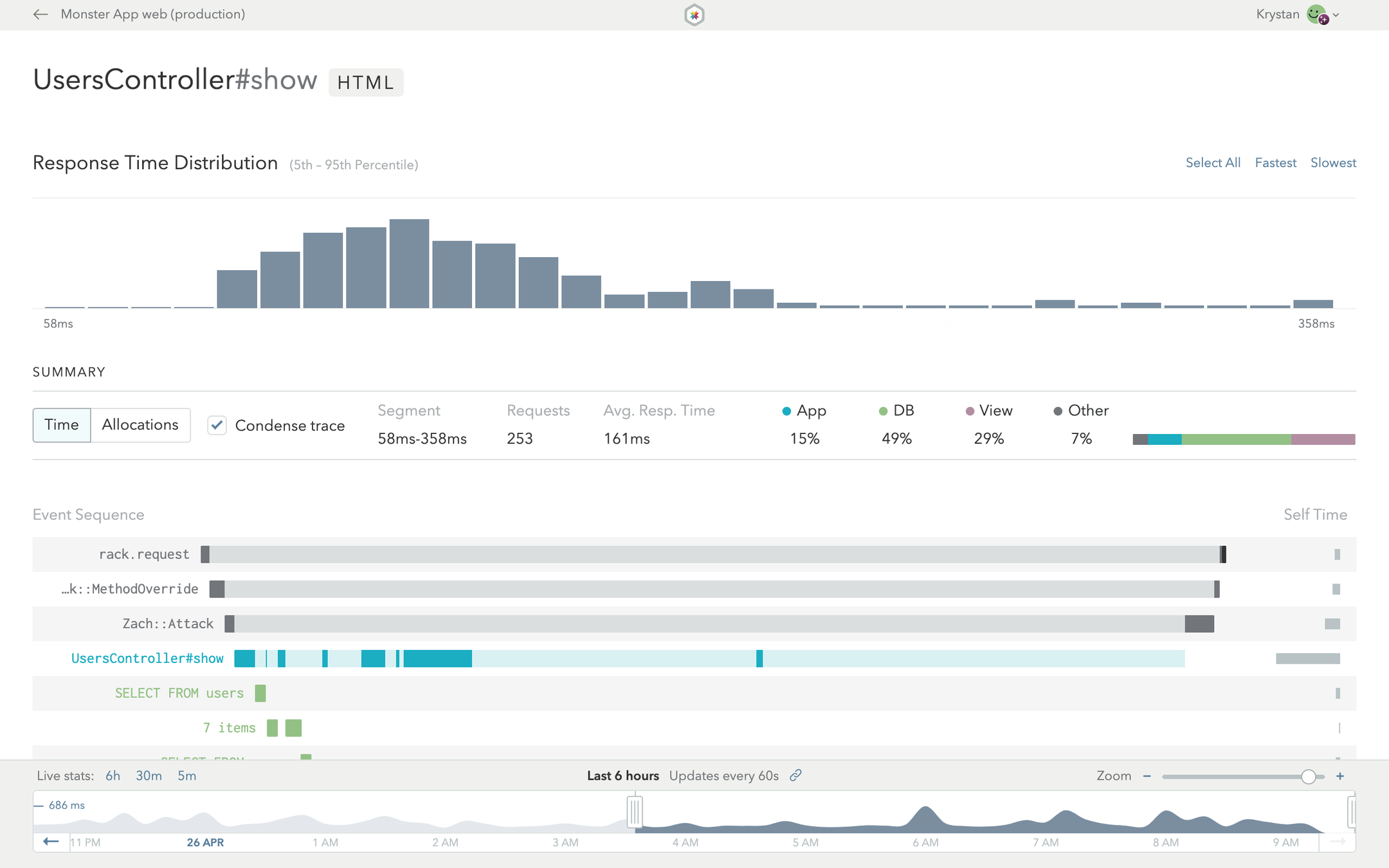
とりあえず好きなAPMツールを
導入するのがオススメ
(定期的に見よう!)
アジェンダ
-
パフォーマンスの計測
-
DB処理のチューニング
-
CPU処理のチューニング
-
ケーススタディ
-
まとめ
重いクエリの要因は色々あるが、
特に重くなりやすい3つを取り上げる
重いクエリ三銃士

N+1
FULL
SCAN
Filesort
MySQLの気持ちになって
考えてみよう

※ MySQL以外を使ってる人は「XXX(任意のRDBMS)の気持ちになって」と読み替えてください
FULL SCAN(テーブルフルスキャン)
N+1
FULL
SCAN
Filesort
FULL SCANの例
| id | speaker | start_time | end_time |
|---|---|---|---|
| 1 | tenderlove | 10:10 | 10:40 |
| 2 | kokuyouwind | 10:50 | 11:10 |
| 3 | toshimaru | 11:10 | 11:30 |
| 4 | lulalala | 11:30 | 11:40 |
| 5 | beta_chelsea | 12:40 | 12:50 |
| 6 | makicamel | 12:50 | 13:10 |
sessions
FULL SCANの例
ジョーカー(joker1007)さんの
セッション開始時刻はいつ?

SELECT start_time
FROM sessions
WHERE speaker = "joker1007";Sessions.find_by(speaker: 'joker1007')
.pluck(:start_time)FULL SCANの例
| id | speaker | start_time | end_time |
|---|---|---|---|
| 1 | tenderlove | 10:10 | 10:40 |
| 2 | kokuyouwind | 10:50 | 11:10 |
| 3 | toshimaru | 11:10 | 11:30 |
| 4 | lulalala | 11:30 | 11:40 |
| 5 | beta_chelsea | 12:40 | 12:50 |
| 6 | makicamel | 12:50 | 13:10 |
発表者名を順に全部見る(テーブルフルスキャン)
100万件あったら
100万件全部読む(かもしれない)
死

インデックスをつけよう

インデックスのイメージ
| 索引 | speaker | id |
|---|---|---|
| b | beta_chelsea | 5 |
| f | fukajun | 11 |
| j | joker1007 | 17 |
| k | koic | 16 |
| kokuyouwind | 2 | |
| l | lulalala | 4 |
index(speaker on sessions)
インデックスのイメージ
| 索引 | speaker | id |
|---|---|---|
| b | beta_chelsea | 5 |
| f | fukajun | 11 |
| j | joker1007 | 17 |
| k | koic | 16 |
| kokuyouwind | 2 | |
| l | lulalala | 4 |
jから始まるspeakerを一発で見つける
インデックスのイメージ
| 索引 | speaker | id |
|---|---|---|
| j | joker1007 | 17 |
IDからレコードを見つけてstart_timeを見つける
| id | speaker | start_time | end_time |
|---|---|---|---|
| 16 | koic | 16:20 | 16:40 |
| 17 | joker1007 | 16:40 | 17:00 |
| 18 | a_matsuda | 17:10 | 17:40 |

FULL SCANしなくなった
Filesort
N+1
FULL
SCAN
Filesort
Filesortの例
| id | event_id | speaker | start_time | end_time |
|---|---|---|---|---|
| 1 | 1 | tenderlove | 11:45 | 12:10 |
| 2 | 2 | tenderlove | 10:10 | 10:40 |
| 3 | 2 | koic | 16:20 | 16:40 |
| 4 | 1 | koic | 14:00 | 14:25 |
| 5 | 2 | kokuyouwind | 10:50 | 11:10 |
| id | name |
|---|---|
| 1 | RubyKaigi Takeout 2020 |
| 2 | Kaigi on Rails |
events
sessions
Filesortの例
Kaigi on Railsのセッションを
開始時刻順で教えて?
SELECT * FROM events
WHERE name = 'Kaigi on Rails';
SELECT * FROM sessions
WHERE event_id = 2
ORDER BY start_time ASC;Events.find_by(name: 'Kaigi on Rails')
.sessions.order(:start_time)Filesortの例
| 索引 | event_id | id |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 4 | |
| 2 | 2 | 2 |
| 2 | 3 | |
| 2 | 5 |
| id | name |
|---|---|
| 1 | RubyKaigi Takeout 2020 |
| 2 | Kaigi on Rails |
events
index
(event_id on
sessions)
Filesortの例
| id | event_id | speaker | start_time | end_time |
|---|---|---|---|---|
| 2 | 2 | tenderlove | 10:10 | 10:40 |
| 3 | 2 | koic | 16:20 | 16:40 |
| 5 | 2 | kokuyouwind | 10:50 | 11:10 |
sessions
index
(event_id on sessions)
| 索引 | event_id | id |
|---|---|---|
| 2 | 2 | 2 |
| 2 | 3 | |
| 2 | 5 |
↑
順に並んでいない!
Filesortの例
| id | speaker | start_time | end_time |
|---|---|---|---|
| 2 | tenderlove | 10:10 | 10:40 |
| 3 | koic | 16:20 | 16:40 |
| 5 | kokuyouwind | 10:50 | 11:10 |
| id | speaker | start_time | end_time |
|---|---|---|---|
| 2 | tenderlove | 10:10 | 10:40 |
| 5 | kokuyouwind | 10:50 | 11:10 |
| 3 | koic | 16:20 | 16:40 |
見つけたレコードをstart_time順に
メモリ上で並べ替える!
(Filesort)
LIMITで件数を制限しても、
全件(100万件かも)を読み込んで
並び替えないと返せない
死
処理順に合わせて
複合インデックスをつけよう
複合インデックスの例
| 索引 | event_id | start_time | id |
|---|---|---|---|
| (1, 11) | 1 | 11:45 | 1 |
| (1, 14) | 1 | 14:00 | 4 |
| (2, 10) | 2 | 10:10 | 2 |
| 2 | 10:50 | 5 | |
| (2, 16) | 2 | 16:20 | 3 |
index (event_id, start_time on sessions)
↑
event_idとstart_timeを
組み合わせた索引
複合インデックスの例
| 索引 | event_id | start_time | id |
|---|---|---|---|
| (2, 10) | 2 | 10:10 | 2 |
| 2 | 10:50 | 5 | |
| (2, 16) | 2 | 16:20 | 3 |
index
(event_id, start_time on sessions)
| id | speaker | start_time | end_time |
|---|---|---|---|
| 2 | tenderlove | 10:10 | 10:40 |
| 5 | kokuyouwind | 10:50 | 11:10 |
| 3 | koic | 16:20 | 16:40 |
sessions
start_timeでソート済みの状態で取れる!
filesortしなくなった
複合インデックス(悪い例)
| 索引 | start_time | event_id | id |
|---|---|---|---|
| (10, 2) | 10:10 | 2 | 1 |
| 10:50 | 2 | 4 | |
| (11, 1) | 11:45 | 1 | 2 |
| (14, 1) | 14:00 | 1 | 5 |
| (16, 2) | 16:20 | 2 | 3 |
index (start_time, event_id on sessions)
↑
start_timeが先だと、
event_id=2を索引から探せない!
複合インデックス(悪い例)
| 索引 | start_time | speaker | id |
|---|---|---|---|
| (10:10, t) | 10:10 | tenderlove | 1 |
| (10:50, k) | 10:50 | kokuyouwind | 2 |
| (11:10, t) | 11:10 | toshimaru | 3 |
| (11:30, l) | 11:30 | lulalala | 4 |
index (start_time, speaker on sessions)
start_timeだけで昇順に並ぶため、speakerはソートされない
必要ならam/pm区分カラムなどを作る必要がある
Sessions.where(start_time: '0:00'..'12:00')
.order_by(:speaker)N+1クエリ
N+1
FULL
SCAN
Filesort
N+1クエリの例
イベントごとに、イベント名と
セッションの発表者を表示して?
SELECT * FROM events;
SELECT * FROM sessions WHERE event_id = 1;
SELECT * FROM sessions WHERE event_id = 2;Events.each do |event|
p event.name
event.sessions.each { p _1.speaker }
endN+1クエリの例
イベントが100個あると…
SELECT * FROM events;
-- => 100個のイベント
SELECT * FROM sessions WHERE event_id = 1;
SELECT * FROM sessions WHERE event_id = 2;
SELECT * FROM sessions WHERE event_id = 3;
-- ...
SELECT * FROM sessions WHERE event_id = 99;
SELECT * FROM sessions WHERE event_id = 100;
SQLクエリを繰り返し大量に発行する
死…ぬほどではないけど
めっちゃ重い
includesをつかおう
includesの例
SELECT * FROM events;
-- => 100個のイベント
SELECT * FROM sessions WHERE event_id IN (1, 2, ..., 100);Events.includes(:sessions).each do |event|
p event.name
event.sessions.each { p _1.speaker }
endクエリ2回で完了!
N+1クエリしなくなった
問題の見極め方
APMなどで時間のかかっているクエリを特定する
問題の見極め方
1クエリで時間がかかっている場合、EXPLAINを見る

typeに "ALL" や "index" がいたらFULL SCAN

typeがrefなどで、keyが使われてればOK!
問題の見極め方
extrasに "Using filesort" がいたらFilesort
"Using filesort"が消えればOK!


1クエリで時間がかかっている場合、EXPLAINを見る
問題の見極め方
APMで同じクエリが何回も流れていたらN+1クエリを疑う
NewRelicは
呼び出し回数を教えてくれる


Skylightは
マークを付けてくれる
アジェンダ
-
パフォーマンスの計測
-
DB処理のチューニング
-
CPU処理のチューニング
-
ケーススタディ
-
まとめ
CPU処理のチューニング
-
「単独で重い処理」はそんなに多くない
-
軽い処理でも繰り返し回数が多いと重くなる
-
以下のコードはA, Bがそれぞれ1,000件の配列だと
member?内の比較処理を1,000,000回呼び出す -
(比較処理が1ナノ秒の処理でも1秒かかる)
-
A.filter { B.member?(_1) }対策1: データ構造とアルゴリズムの見直し
-
Arrayは全件探索になりやすいデータ構造
-
「キーから値を探す」ならHash
-
「共通部分や差分を取る」ならSet
-
RDBやRedisなどのミドルウェア側で処理する手も
-
-
アルゴリズムを見直すことで効率が良くなる可能性
-
一般的なアルゴリズムを調べる
-
ループを早く打ち切れるように処理順を変える
-
対策2: メモ化・キャッシュを利用する
-
同じ処理が何度も行われる場合に効果的
-
リクエストごとで十分ならメモ化
-
リクエストを跨いで保持したいならRailsキャッシュ
-
-
根本的解決ではないため注意が必要
-
初回処理時は重い(必要ならキャッシュを温める)
-
古いキャッシュがバグを起こすこともあるので
キャッシュキーの選定には熟慮が必要
-
アジェンダ
-
パフォーマンスの計測
-
DB処理のチューニング
-
CPU処理のチューニング
-
ケーススタディ
-
まとめ
ケース1: 関連文書の取得
請求書から、関連文書
(変換した・された見積書・納品書)を取る際に
N+1が発生していた



ケース1: 関連文書の取得
任意の2要素に関連を持たせるため、
クラス名とIDから自力でLookupしていた
| FromType | FromID | ToType | ToID |
|---|---|---|---|
| Estimate | 1 | Invoice | 1 |
| Invoice | 1 | DeliverySlip | 1 |
| Invoice | 1 | DeliverySlip | 2 |
def converted_docs
DocumentConversion
.find_by(from_type: 'Invoice', from_id: id)
.map do |doc|
doc.to_type.constantize.find(doc.to_id)
end
endケース1: 関連文書の取得
ポリモーフィック関連付けに書き換え、
includesを指定できるようにした
class Invoice
has_many :document_conversions, as: :source_document
has_many :converted_delivery_slips,
through: :document_conversions,
source: :converted_document,
source_type: 'DeliverySlip'
end
# usage
Invoice.all.includes(:converted_delivery_slips)
ケース2: PDF変換
gemを更新したら
PDF生成処理が急に重くなった

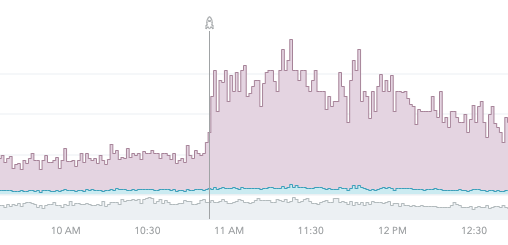
ケース2: PDF変換
stackprofを使って調査した結果、gem内から
CompareWithRange#cover?が大量に呼ばれていた
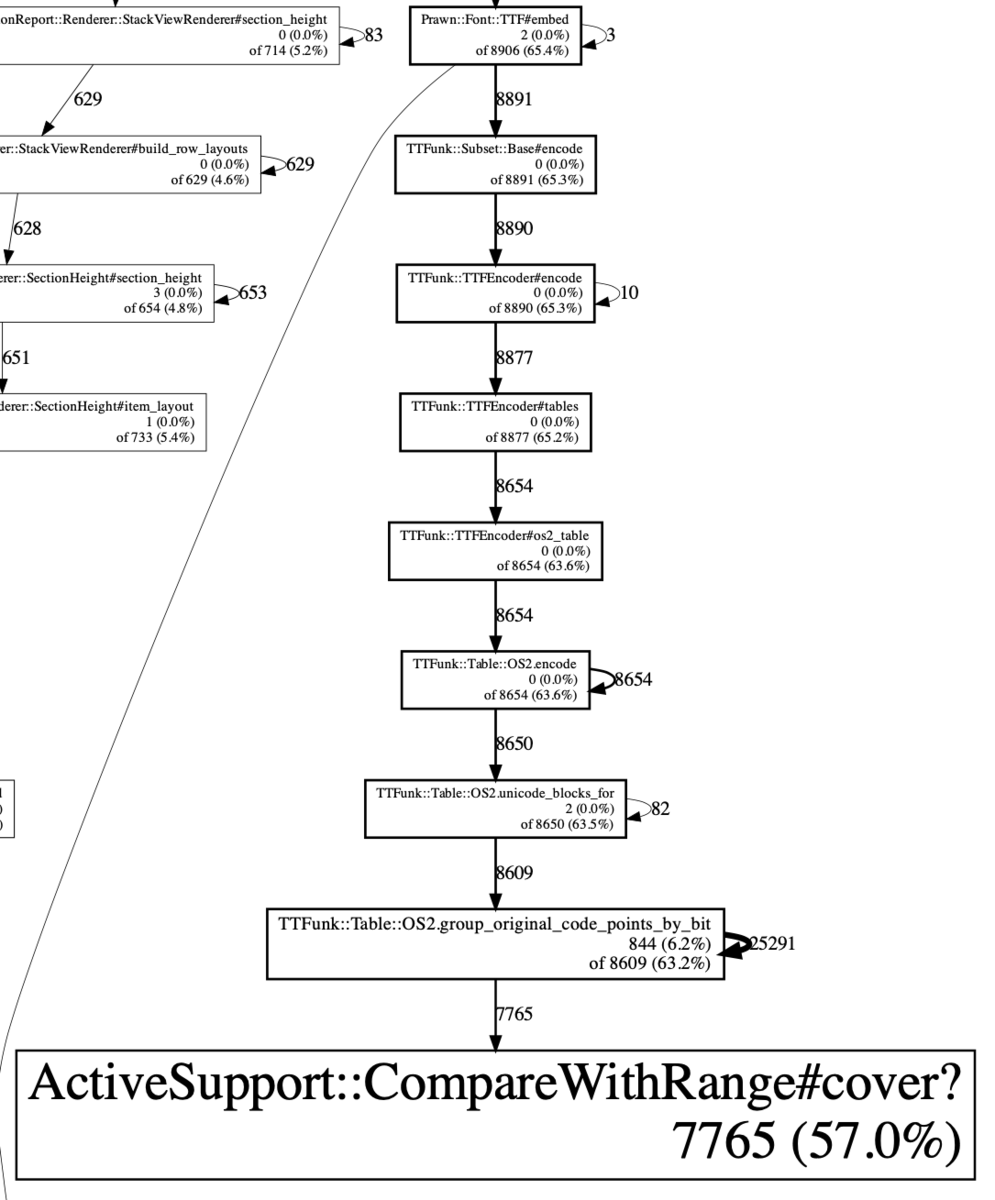
ケース2: PDF変換
def group_original_code_points_by_bit(os2)
Hash.new { |h, k| h[k] = [] }.tap do |result|
os2.file.cmap.unicode.first.code_map.each_key do |code_point|
# === ↓2重ループ内で cover? を呼んでいる!!! ===
range = UNICODE_RANGES.find { |r| r.cover?(code_point) }
# ...ケース2: PDF変換
アルゴリズムを変えて、
cover?の呼び出しを減らすPull Requestを送った
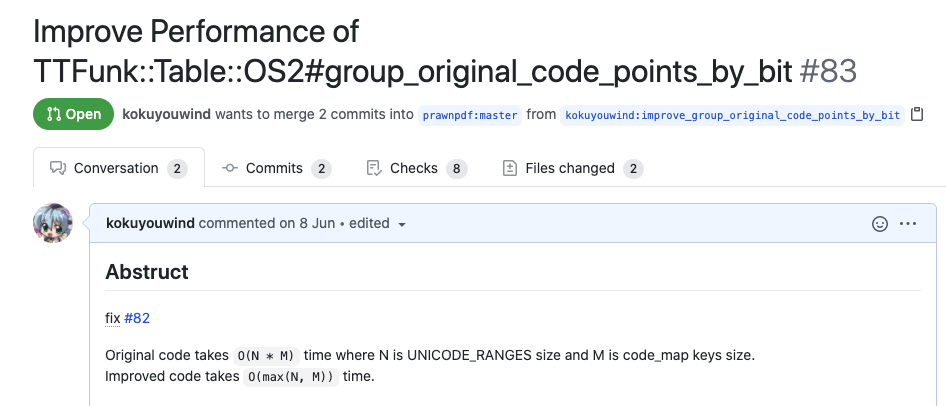
アジェンダ
-
パフォーマンスの計測
-
DB処理のチューニング
-
CPU処理のチューニング
-
ケーススタディ
-
まとめ
まとめ
-
パフォーマンス改善には、まず計測から
-
とりあえずAPMツールを入れて、定期的に見よう
-
-
重いDBクエリはEXPLAINしてインデックスを貼ろう
-
FULL SCANやfilesortは重いので倒そう
-
複合インデックスは効き方を想像して貼ろう
-
-
N+1クエリが発生しないようincludesしよう
-
CPU処理の問題は、プロファイラで根本原因を調査しよう
-
データ構造やアルゴリズムを見直せないか考えよう
-
Railsパフォーマンス・チューニング入門
By 黒曜
Railsパフォーマンス・チューニング入門
Kaigi on Railsの発表資料です https://kaigionrails.org/




