Some trials to improve A3C algorithm under Breakout-v0 environment
{Ligh,yaodi,qinsheng}@shanghaitech.edu.cn
What is Reinforcement Learning ?




Q-learning
How do we get the Q-function(Bellman equation)

Q-Learning algorithm

Function Approximator


Use a function(with parameters) to approximate the Q-function


Q-network

Deep Q-network
Deep Q-network used in the DeepMind paper
Estimating the Q-Network
Recall the Bellman Equation:



Compute the loss:
Optimize objective by SGD:
Learning Stability
- Non-linear function approximator(Q-Network) is not very stable.
- How to improve?
- Exploration-Exploitation
- Experience Replay
Exploration-Exploitation Dilemma
- During training,how do we choose an action at time t?
(探索)Exploration:random guessing
(利用)Exploitation:choose the best one according to the Q-value
- ε−greedy policy


Experience Replay
- To remove correlations,build data-set from agent’s own experience
DQN-Nature Version


Policy gradient:directly predict action

- Compute the distribution of action
- Sample the distribution and act

Deriving Policy Gradients
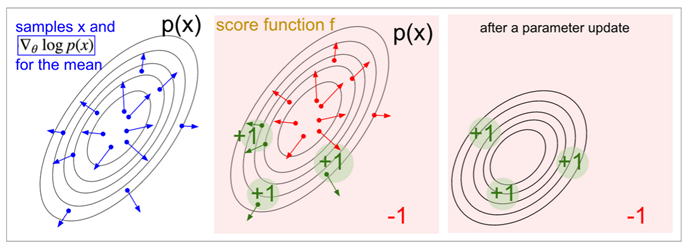

Asynchronous advantage actor-critic(A3C)


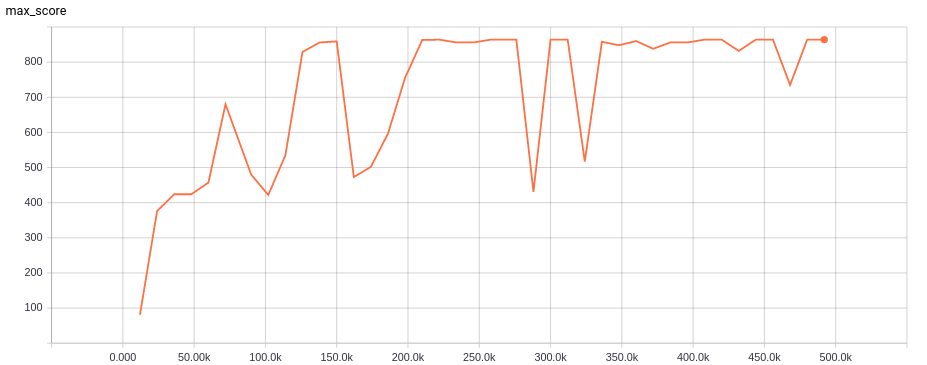
Figure 1: mean scores of original architecture
Figure 2: max scores of original architecture



Figure 3: mean scores of bn trial
Figure 4: max scores of bn trial
Harm perfermance




Figure 6: Loss of our dueling policy network
Figure 7: mean scores of dueling policy network
Figure 8: max scores our dueling policy network
Do not converge
A novel idea get better performance


Figure 9: mean scores of our idea
Figure 10: max scores of our idea

9% improvement than original net
A novel idea get better performance
Figure 9: mean scores of our idea
Figure 10: max scores of our idea
d \theta \leftarrow d \theta + (1+c*w(s_i;\theta_w^\prime))\bigtriangledown_{\theta^\prime}log\pi(a_i|s_i;\theta^\prime)(R-V(s_i;\theta_v\prime));c=0.5
d \theta \leftarrow d \theta + (10^{c*w(s_i;\theta_w^\prime)})\bigtriangledown_{\theta^\prime}log\pi(a_i|s_i;\theta^\prime)(R-V(s_i;\theta_v\prime));c=3
d \theta \leftarrow d \theta + \bigtriangledown_{\theta^\prime}log\pi(a_i|s_i;\theta^\prime)(R-V(s_i;\theta_v\prime))
or
Other trials
Inception Block



A little improvement but deeper

Other trials
LSTM
Other trials
High action dimension game


Thank you
thank to Yi ma and TAs
deck
By ligh1994


