Databricks Certified Data Engineer Associate Preparation

Data Ingestion with Delta Lake
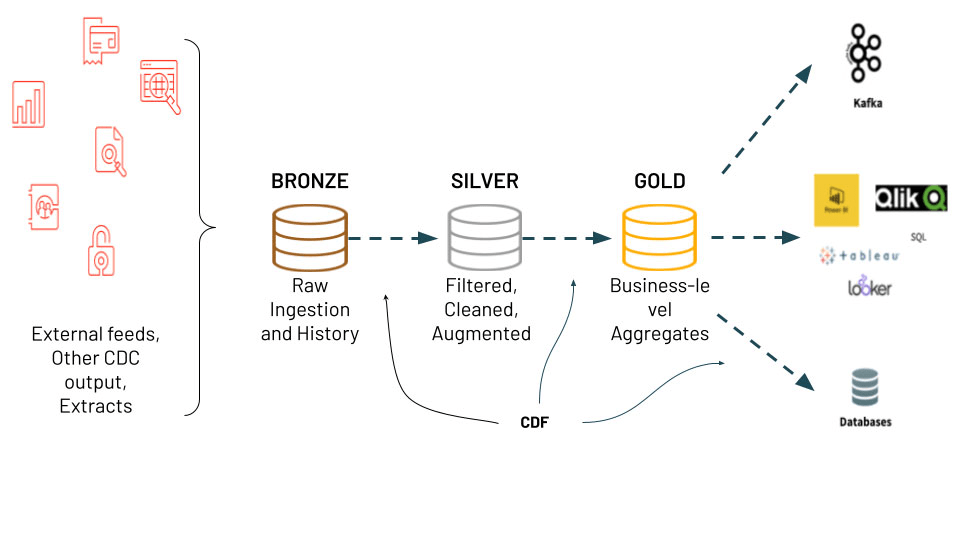
What is Delta Lake?
Reliable storage layer for transactional data.
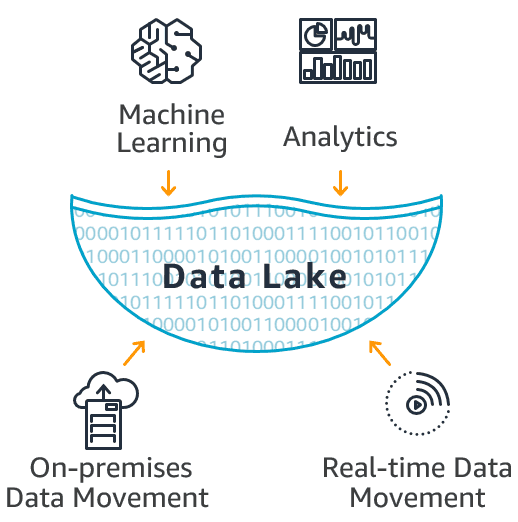
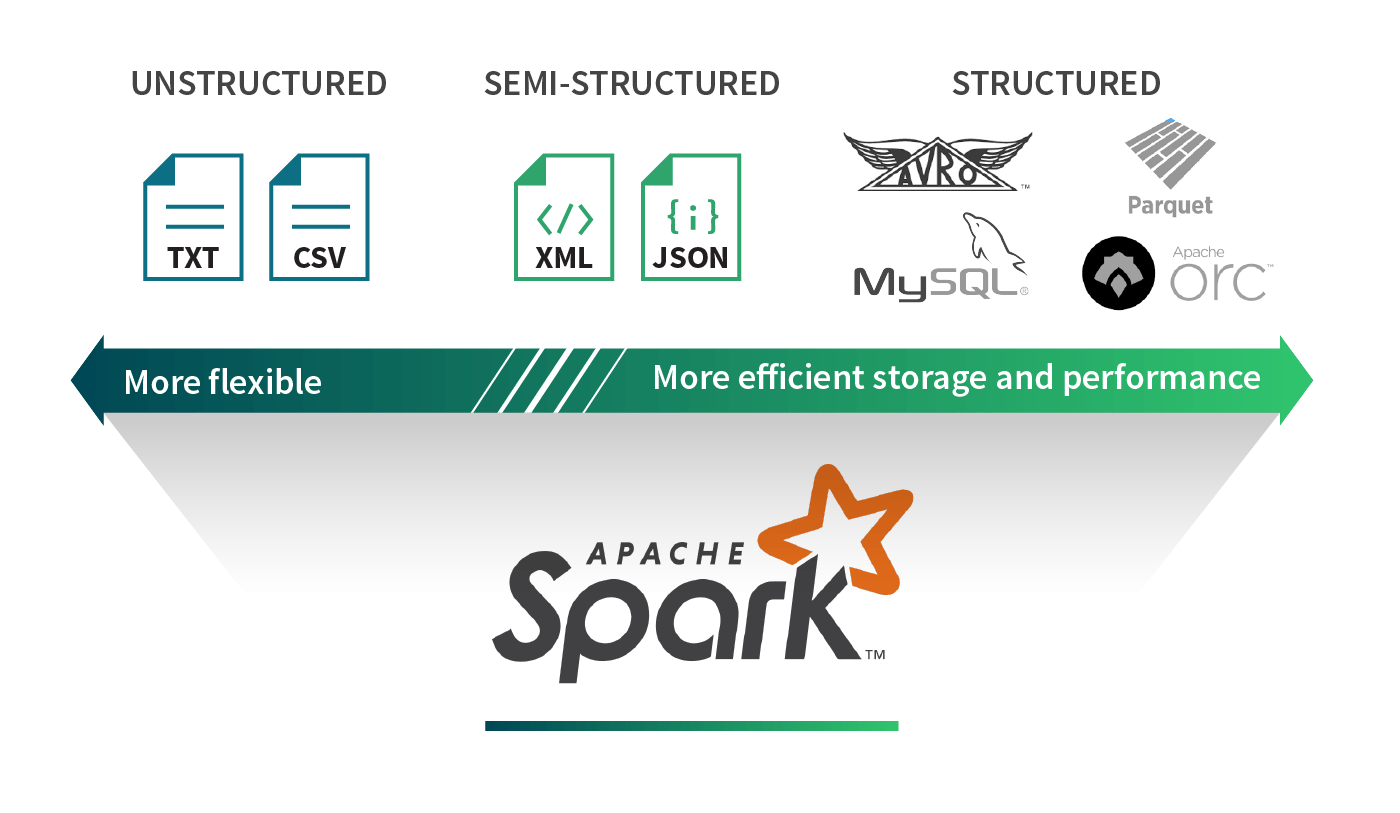
Ingesting Data with Spark
Supports CSV, JSON, and Parquet formats.
Writing as Delta Table
Use command: write.format("delta") for storage.
Data Operations
- MERGE
- UPDATE
- DELETE
Real-Time Ingestion
Utilize Auto Loader for efficient data streaming.

Benefits of Delta Lake
- Data integrity
- History tracking
- Version control
- Transactional consistency
Deploy Workloads with Databricks Workflows
Databricks Workflow
Es el sistema para programar y automatizar la ejecución de trabajos en Databricks.
- Definición de Jobs compuestos por tareas.
- Configuración de dependencias, triggers y notificaciones.
Ejecutar ETL, cargas de datos o procesos programados sin intervención manual.
Build Pipelines with Delta Live Tables (DLT)
Framework declarativo para construir pipelines en SQL o Python.
- Usa @dlt.table o CREATE LIVE TABLE
- Encadena transformaciones
- Configura reglas EXPECT para validar calidad de datos
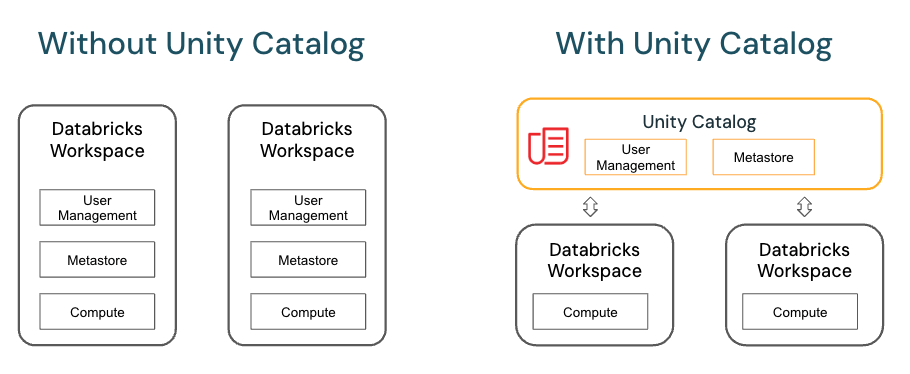
Data Governance con Unity Catalog
Centraliza seguridad y control de acceso a datos en Databricks.
- Creación de catálogos, esquemas y tablas.
- Asignación de permisos (GRANT) por tabla o columna.
- Registro automático de descripciones y lineage.
¿Para qué sirve?
Cumplimiento normativo, control de acceso preciso y descubrimiento de datos.

DevOps Essentials
Colaboración en Ingeniería de Datos
¿Cómo Funciona?
- Conexión a Git
- Versionado de notebooks
- Automatización de despliegues

Streaming con DLT
Procesamiento de datos en tiempo real
- Utiliza readStream y writeStream de Spark
- Define ventanas de agregación
- Mantiene el estado y control de calidad
¿Cómo funciona?
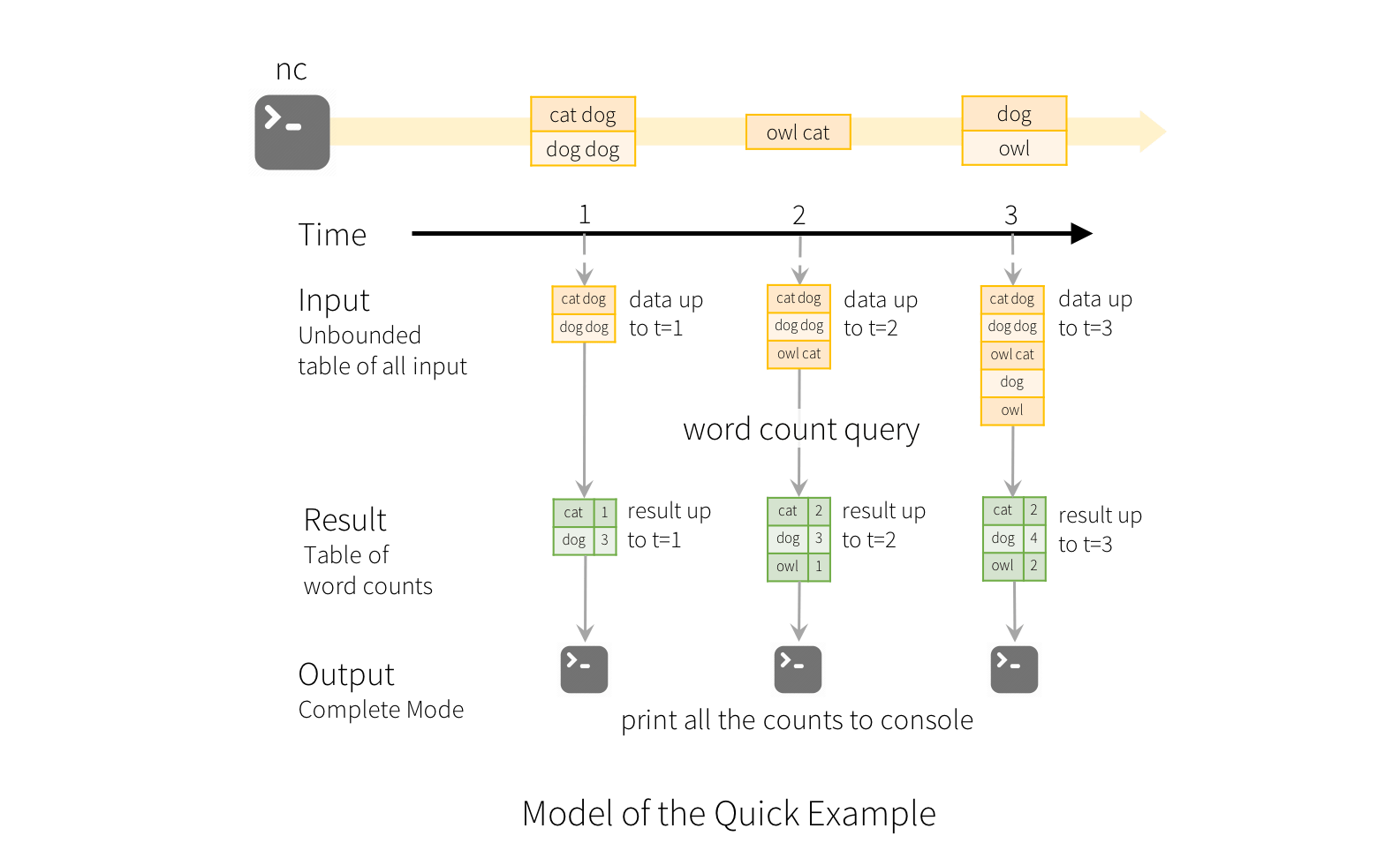
¿Para qué sirve?
Reacción a eventos en tiempo real: sensores, logs y métricas.
Data Privacy
Control sobre datos sensibles y privacidad de los usuarios.
- Permisos a nivel de columna.
- Auditoría de accesos.
- Proteger información confidencial y cumplir con regulaciones (GDPR, HIPAA).


Performance Optimization
Prácticas para mejorar velocidad de procesamiento y lectura.
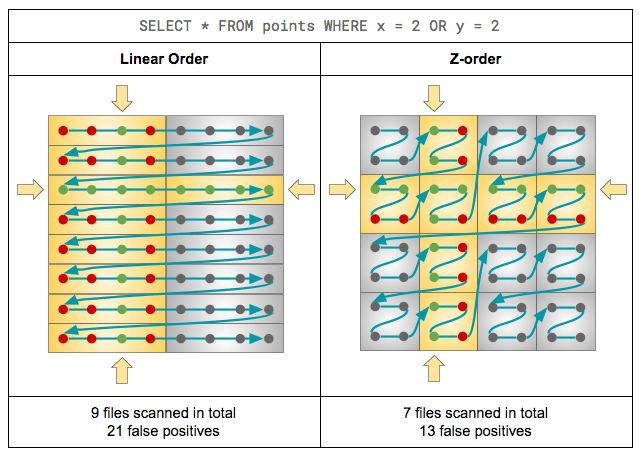
- OPTIMIZE ZORDER BY para ordenar datos.
- VACUUM para eliminar archivos huérfanos.
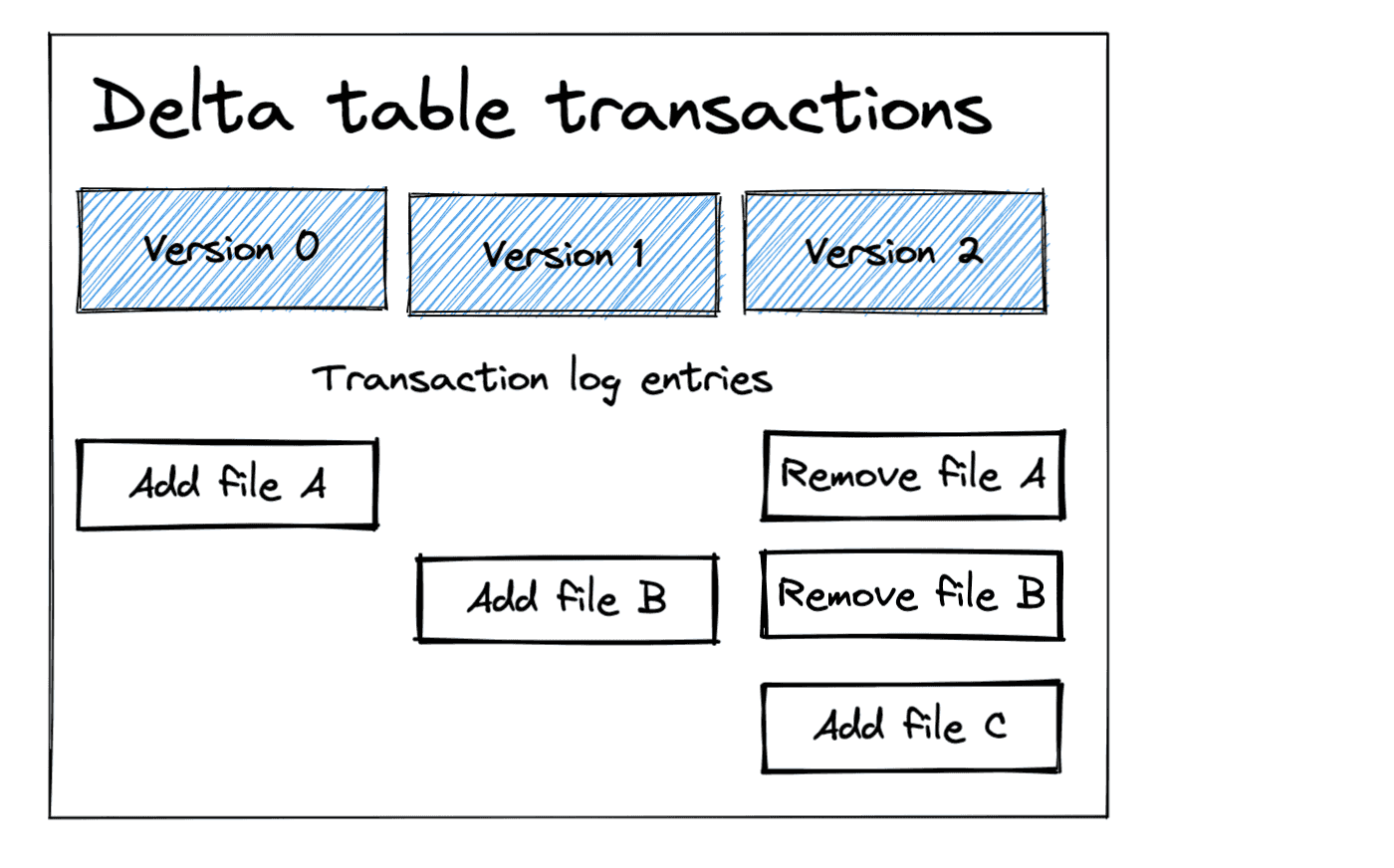
Automated Deployment con Asset Bundles
Define y despliega trabajos de Databricks como código YAML.
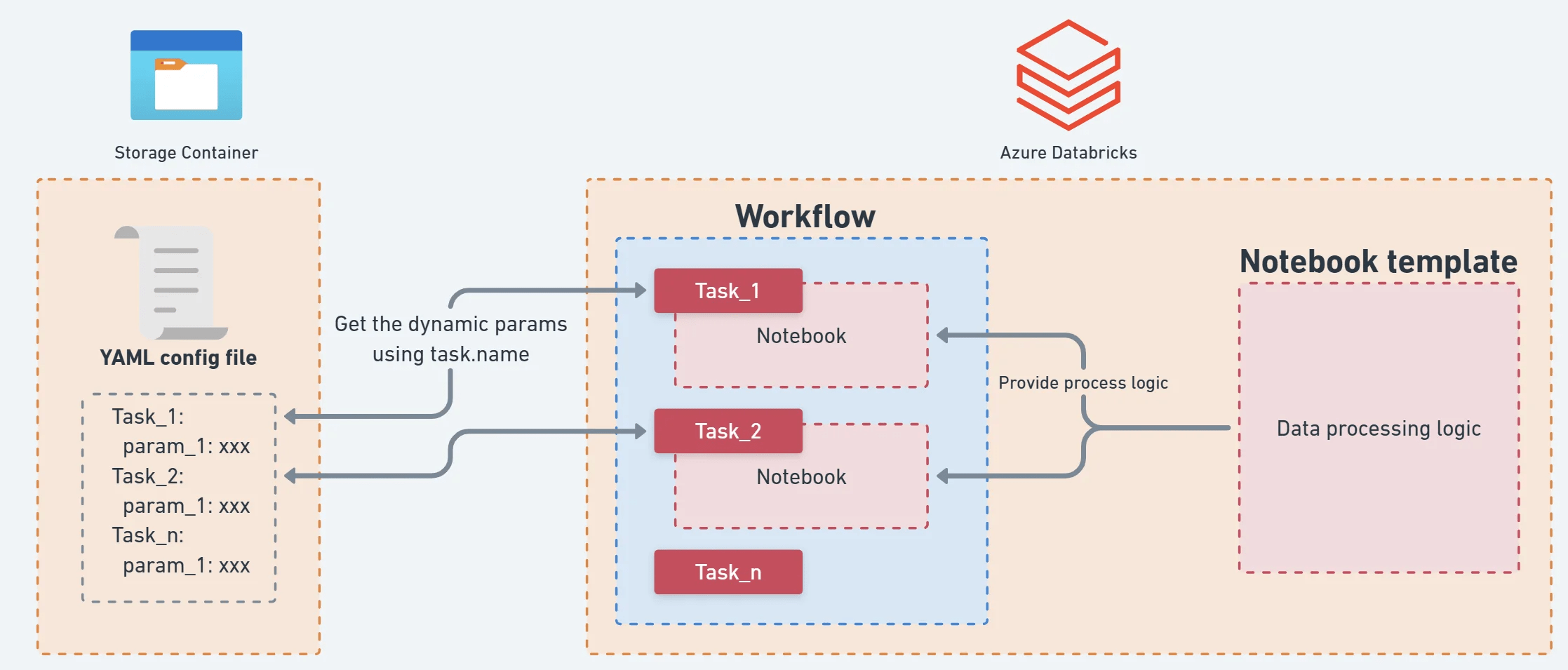
- Crear bundle.yml con definición de jobs y clústeres.
- Usar CLI de Databricks para desplegar.
Proyecto Sugerido:
Predicción de Demanda y Recomendación de Stock para Vehículos Usados
Construir un sistema inteligente que prediga la demanda futura de autos usados (por marca, modelo, año y ciudad), y recomiende niveles óptimos de stock a distribuidores o concesionarios.
Tecnologías y herramientas en Databricks
-
Delta Lake: ingestión y versionado de inventario, ventas y búsquedas
-
Auto Loader: conexión continua a nuevas ventas o búsquedas desde APIs
-
Delta Live Tables (DLT): pipeline declarativo
-
MLflow: entrenamiento y despliegue del modelo de predicción
-
Unity Catalog: gobernanza del dato (control por ciudad o distribuidor)
-
Databricks SQL Dashboard: para mostrar insights y alertas
Fuentes
Databricks Fundamentals Learning Plan:
https://customer-academy.databricks.com/learn/learning-plans/215/databricks-fundamentals-learning-plan
Data Engineer Learning Plan:
https://customer-academy.databricks.com/learn/learning-plans/10/data-engineer-learning-plan
Questions?
Databricks Cert Presentation
By Lucas Carpio




