
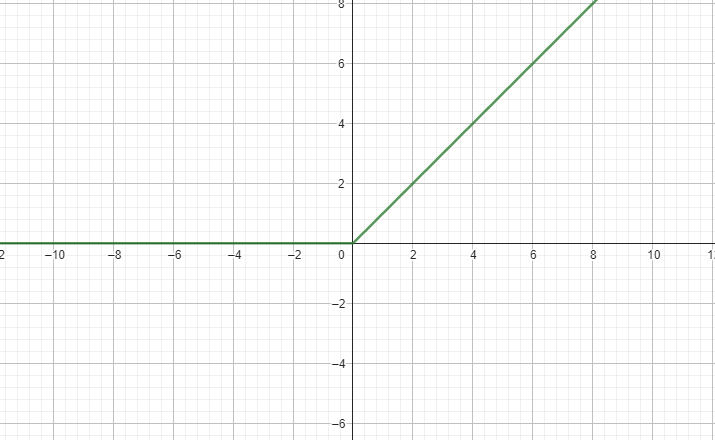





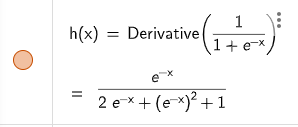
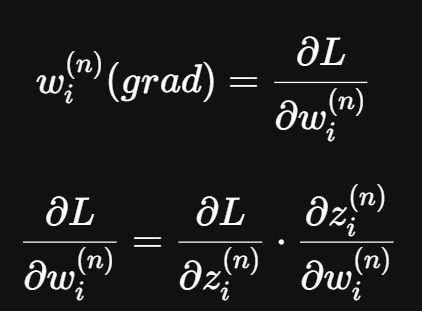

lucasw
大佬教麻
Full Stack
Discord Bot
Machine Learning
Unity
Competitive Programming
Web Crawler
Server Deployment
Minecraft Datapack
Scratch
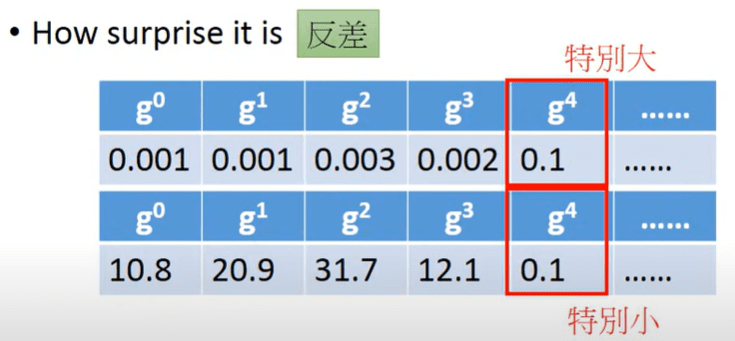
沒有方向性的元素
剛剛矩陣內的每一個元素都是一個純量
只有一維的矩陣
同時表示著一個空間中的向量
數個向量構成的矩陣
兩個向量進行內積時
會如矩陣乘法一般將兩向量每個元素相乘
只不過最後得到的輸出不是矩陣
而是元素相乘值的總和(純量)
在幾何意義上它代表的是 X 向量在 Y 向量上的投影長與 Y 向量長度的積
就是一個包含許多數字的東東
其中每一個數字都被稱作是矩陣的元素
很簡單吧
如果運算的對象是矩陣呢?
兩個矩陣需要一樣形狀
順帶一提這東西沒有交換律
#偷
啊東西呢?
我很想偷但沒得偷QQ
還是自己來搞一篇吧
m=2
m=1
m = Undefined
m = 0
如果我要求函數中無限趨近於一個點上的斜率怎麼做
如果我要求函數中無限趨近於一個點上的斜率怎麼做
設定
Y
X
Y
X
x
x'
Y
X
x
x'
Δx
Y
X
x
x'
Δx
y
y
Δy
y'
Y
X
x
x'
Δx
y
y'
y
Δy
Y
X
m = 0
= 0
後面幾項都因為有h作為係數而歸零了
而若是這樣一個非二維的空間中
我們想要知道圖形上任意點
在特定軸上的斜率
同時也代表的該參數與圖形的關係
在一個多變數的方程式中求特定變數的微分
在一個多變數的方程式中求特定變數的微分
在一個多變數的方程式中求特定變數的微分
在一個多變數的方程式中求特定變數的微分
讓他好看一點
這就是每個Neuron在進行的事情
這就是每個Neuron在進行的事情
把輸入( X )乘上一個Weight並且加上Bias
這就是每個Neuron在進行的事情
把輸入( X )乘上一個Weight並且加上Bias
最後在套上本章的主角 Activation Function
class Neuron:
def __init__(self, w: np.ndarray, b: int) -> None:
self.w = w
self.b = b
def forward(self, x) -> int:
return relu(np.dot(x, self.w.T) + self.b)#$%#*@)$!#)$%(#)$%
如果一直進行wx+b的操作會發現它始終是線性的,這樣一來這整個神經網路能夠擬合出來的函式會被限縮
而激勵函數能夠提供給這個神經網路的方程式非線性的來改善這個問題
如果一直進行wx+b的操作會發現它始終是線性的,這樣一來這整個神經網路能夠擬合出來的函式會被限縮
而激勵函數能夠提供給這個神經網路的方程式非線性的來改善這個問題
並且能夠對每個神經元輸出的值進行一定程度的控制
例如: 限縮範圍,限縮負數成長
def Identity(x):
return x#$%#*@)$!#)$%(#)$%
這有必要放嗎
※幾乎不會用到
def sign(x):
return 1 if x >= 0 else 0#$%#*@)$!#)$%(#)$%
#matrix
def sign(x):
return 1 * (x >= 0)#matrix numpy
def sign(x):
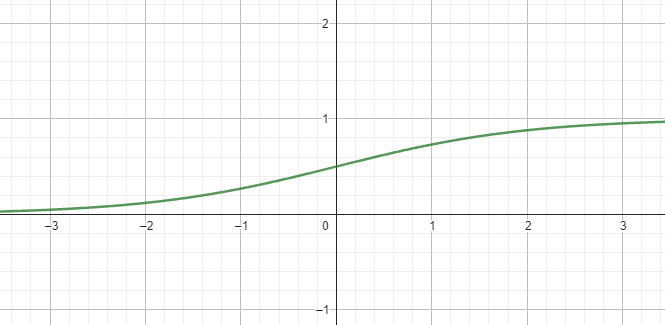
return np.where(x >= 0, 1, 0)def sigmoid(x):
return 1 / (1 + np.exp(-x))#$%#*@)$!#)$%(#)$%
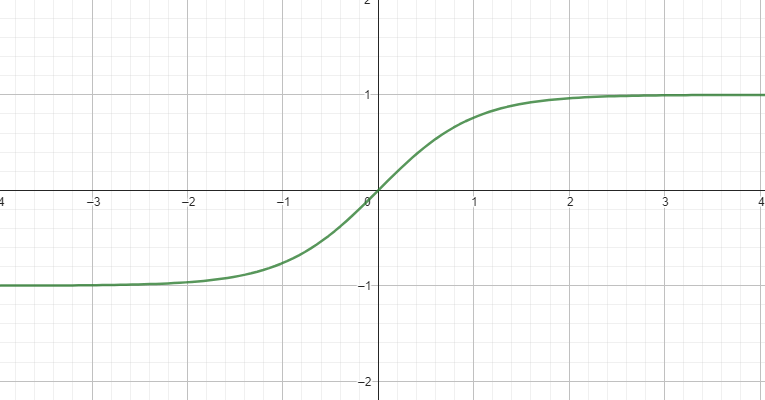
def tanh(x):
return np.tanh(x)#$%#*@)$!#)$%(#)$%
貼心的numpy已經有現成的了
def relu(x):
return np.maximum(0, x)
def leaky_relu(x, n: float=1e-3):
return x if max(0, x) else n*x#$%#*@)$!#)$%(#)$%
簡單提一下Leaky ReLU
它會將小於0的數字乘上一個很小的數字
讓負數也能保留數值之間的差距而不是直接歸0
它使用於多筆資料
會將每項資料的數值做e^x之後
對每筆資料計算該資料在總和之間的比例
簡單來說
每筆資料的數值總和會是1
可以用來做比例 / 機率分配等應用
簡單來說
每筆資料的數值總和會是1
可以用來做比例 / 機率分配等應用
通常被應用在神經網路的輸出層上
花朵圖像辨識(Input: 圖, Output: 花名)
def softmax(x):
return np.exp(x) / np.sum(np.exp(x))#$%#*@)$!#)$%(#)$%
def softmax(x):
return np.exp(x - np.max(x) / np.sum(np.exp(x - np.max(x)))layer
#&#%(@$#@)*%
#&#%(@$#@)*%
#&#%(@$#@)*%
#&#%(@$#@)*%
#&#%(@$#@)*%
Input Layer
#&#%(@$#@)*%
Input Layer
Hidden Layer
#&#%(@$#@)*%
Input Layer
Hidden Layer
Output Layer
#&#%(@$#@)*%
Input Layer
Hidden Layer
Output Layer
#&#%(@$#@)*%
Input Layer
Hidden Layer
Output Layer
#&#%(@$#@)*%
我們的目的就是幫要解決的問題
找出一個完美的函式
使同一類問題的輸入都能夠得到正確的輸出
#&#%(@$#@)*%
但是我要怎麼知道
每個神經元的參數應該要是多少呢?
我們的目的就是幫要解決的問題
找出一個完美的函式
使同一類問題的輸入都能夠得到正確的輸出
如何讓他們成為應該成為這個
目標函式的正確參數?
很多的權重與偏移
先隨便帶入任意數字
為正確的數據
為輸出的數據
我們先把算式簡化(適用於單一結果正確情況)
我們先把算式簡化(適用於單一結果正確情況)
代表著當x的比例越低 數值越高
我們先把算式簡化(適用於單一結果正確情況)
當預測值偏離1(正確)越遠,熵增加的越快
所以說我們要讓Loss越低越好
def cross_entropy(self, y_output: np.ndarray, y_label: np.ndarray) -> int:
return -np.dot(y_label, np.log2(y_output))得到了Loss之後
就可以準備來更新參數了
def cross_entropy(self, y_output: np.ndarray, y_label: np.ndarray) -> int:
return -np.dot(y_label, np.log2(y_output))Loss
W
我們要做的就是找到圖中Loss最低點
並將W更新
Loss
W
我們要做的就是找到圖中Loss最低點
並將W更新
問題是要怎麼讓程式知道最低點呢?
Loss
W
直接把每個組合試過一遍
Loss
W
Loss
W
Loss
W
Loss
W
直接把每個組合試過一遍
各位競程大師用腳想都知道那個時間複雜度會爆炸
Loss
W
Loss
W
Loss
W
Loss
W
況且我們還不只一個參數
看起來很難懂
看起來很難懂
直接上圖
Loss
W
Loss
W
目標點
Loss
W
起始點
Loss
W
起始點
對起始點做微分
Loss
W
對起始點做微分
從微分後得到的斜率就可以判斷低點是在左邊還是右邊
Loss
W
對起始點做微分
從微分後得到的斜率就可以判斷低點是在左邊還是右邊
Loss
W
對起始點做微分
從微分後得到的斜率就可以判斷低點是在左邊還是右邊
Loss
W
對起始點做微分
從微分後得到的斜率就可以判斷低點是在左邊還是右邊
並且向那個方向前進直到斜率=0
Loss
W
對起始點做微分
從微分後得到的斜率就可以判斷低點是在左邊還是右邊
並且向那個方向前進直到斜率=0
但是我們的參數顯然不是只有一個
所以要對每個參數分別進行偏微分
下一次的位置
下一次的位置
這次的位置
下一次的位置
這次的位置
學習率
下一次的位置
這次的位置
學習率
偏微分
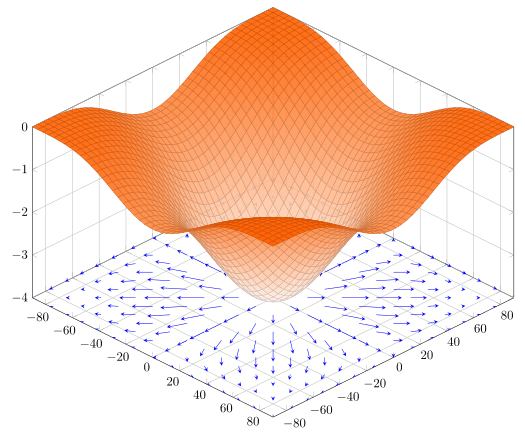
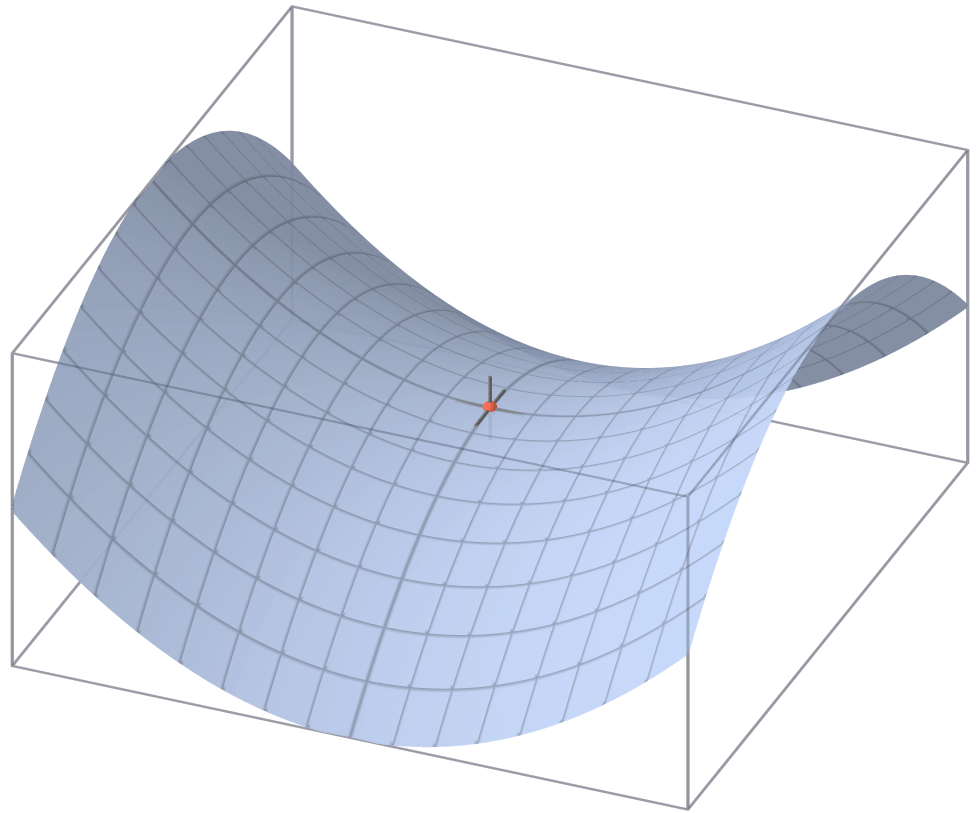
有機率找到的不是全域最小值
而是局部最小值
長得像鞍一樣的形狀
若是結果趨近於這種形狀
將會產生其中一軸最低點
=另一軸最高點
在梯度下降時便會容易卡在裡面
如果一部份的路徑過於平緩可能會
導致梯度下降的速度變很慢
當學習率過高時有可能一直卡在一個谷中找不到最低點
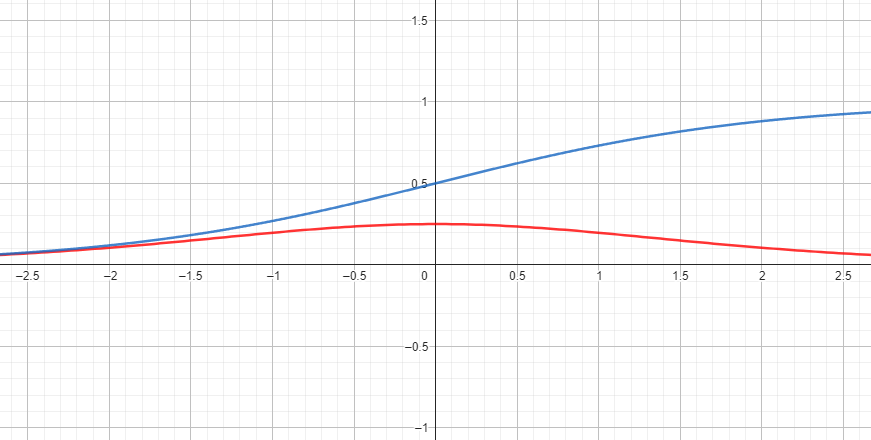
反向傳播時重複對梯度做微分後的activation function
有時候會造成梯度快速減少最終消失
舉個例子
Sigmoid在微分過後函數落在[1/4, 0]之區間
若重複進行便有可能會使梯度趨近於0
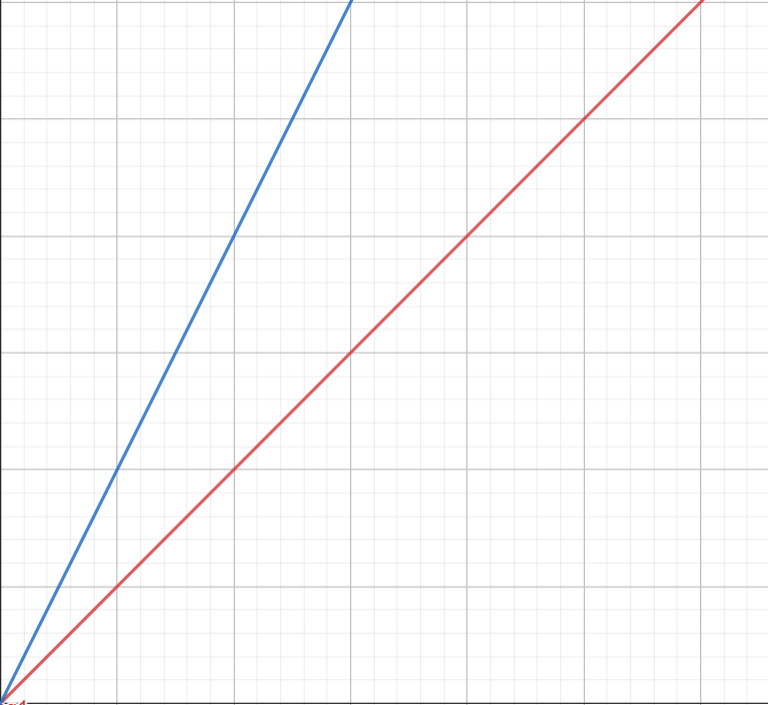
藍線: 原
紅線: 微分後
同理於梯度消失
當梯度不斷變大之後會發生超過程式上限的狀況
最終會導致bug
這種優化方式會讓每次梯度下降時
只要與之前的更新方向相同便加快速度(v)
反之減慢速度(v)
第一次操作與一般梯度下降相同
之後的操作則會以前一次的速度乘上
運動量阻力係數( ) ※這東西小於等於1
再拿去跟前一次的梯度做差
僅是一個極小的數
用以防止分母為0無法計算
※
對過去時間點的所有梯度做平方和後開根號
可得到過去梯度的大致數值
而拿當前時間點的梯度除以過去時間點的梯度
便可得知當前時間點的梯度與過去的偏差
有點難理解?
沒關係 直接上圖!
總而言之就是如果這次的梯度特別大/小
這次的學習率便提升/降低
反之如果梯度差異不大
學習率便隨著更新次數降低
是不是覺得有點眼熟呢?
沒錯!!! Adam其實就是融合了上面2種優化型而誕生的東西
同時也是目前使用率最高的Optimizer
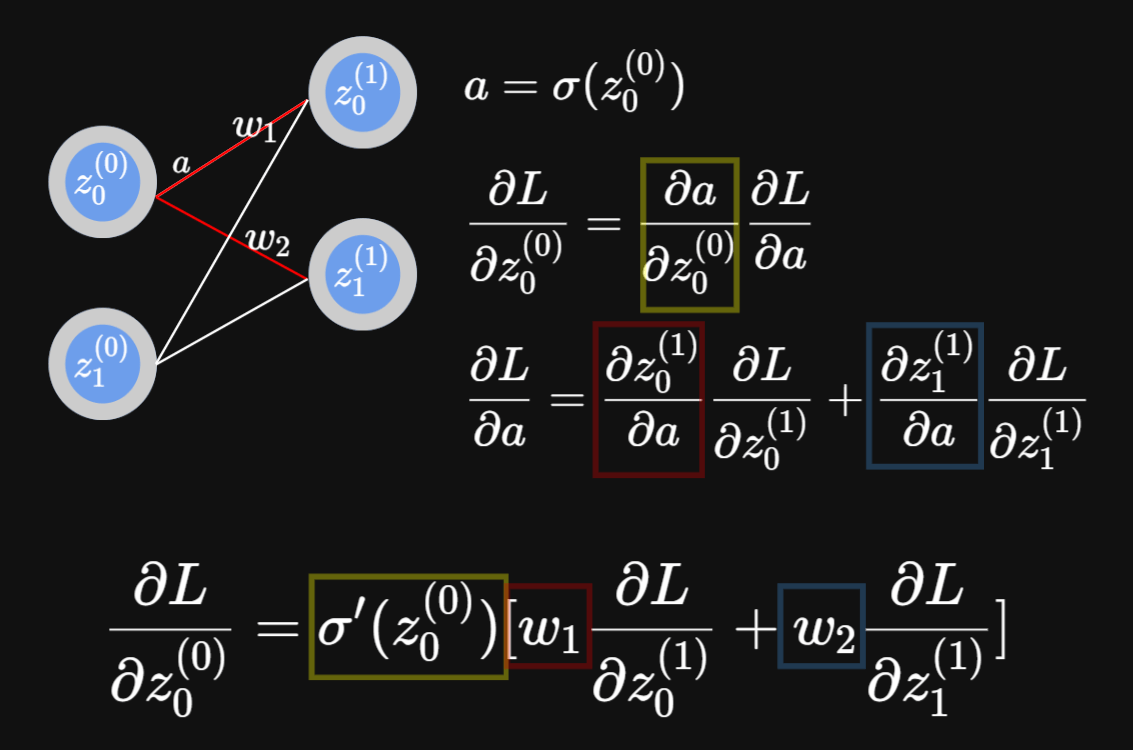
以z表示該神經元過激勵函數前的輸出
以y表示神經網路的輸出
以L表示Loss
Loss
W
該w的梯度為在整個產生Loss的函式中對w微分的結果
該w的梯度為在整個產生Loss的函式中對w微分的結果
我們先來求在該神經元中對w微分
->
->
->
->
->
->
這邊的算式可得知欲求之值之後其實就是前一項的a
(a亦為乘上權重前的參數)
回到這一頁
接下來求整個函式中對該神經元的微分
這邊可以發現說其實我們可以藉由這個遞迴關係直接拿最後面的資訊往前算
至於最後面的資訊....
根據選用的loss function不同計算也會不一樣
如果是範例中的softmax + cross entropy的話
微分過後會變成
由此可知先記錄一開始向前傳播時拿到的資訊(z)後
從後方再進行一次傳播便可獲得每個參數的梯度
->
->
統整一下整個神經網路的最佳化流程
->
->
資訊傳入
->
->
過神經網路運算
->
->
得到結果與Loss
<-
<-
從結果計算反向傳播時的輸入
<-
<-
更新參數
<-
<-
更新參數完畢
pip install numpy
pip install matplotlib
pip install keras
pip install tensorflownumpy:提供矩陣功能
matplotlib:繪製圖表使用
keras&tensorflow:提供MNIST資料庫
MNIST數據集:一堆手寫數字圖片的數據集
常被用於人工智慧測試辨識數字使用
# act.py
import numpy as np
def relu(x):
return np.maximum(0, x)
def drelu(x):
return np.where(x > 0, 1, 0)np.maximum(a, x)
相當於對陣列內每個元素取 max(a, x)
np.where(condition, a, b)
會將x的每一項使用參數中的判斷式做判斷
根據 true or false 會將輸出陣列的那一項
設定為a or b
第一步先來初始化一個神經網路的物件
class NeuralNetwork:
def __init__(self, layers: list[int], activation_function: Callable, dactivation_function: Callable=None, learning_rate: float=1e-3) -> None:
self.layers = layers
self.learning_rate = learning_rate
self.act = activation_function
self.dact = dactivation_function or self.d(activation_function)
self.delta = 1e-10
self.Z: list[np.ndarray] = [np.zeros(layers[0])]
self.W: list[np.ndarray] = [np.zeros(layers[0])]
self.B: list[np.ndarray] = [np.zeros(layers[0])]
self.output: list[np.ndarray] = [np.zeros(layers[0])]
for i in range(1, len(self.layers)):
self.W.append(np.random.randn(self.layers[i], self.layers[i-1]) * np.sqrt(2/layers[i-1]))
self.B.append(np.zeros(self.layers[i]))
self.Z.append(np.zeros(self.layers[i]))
self.output.append(np.zeros(self.layers[i]))
def d(self, f: Callable) -> Callable:
delta = 1e-10j
def df(x): return f(x + delta).imag / delta.imag
return df第一步先來初始化一個神經網路的物件
class NeuralNetwork:
def __init__(self, layers: list[int], activation_function: Callable, dactivation_function: Callable=None, learning_rate: float=1e-3) -> None:
self.layers = layers
self.learning_rate = learning_rate
self.act = activation_function
self.dact = dactivation_function or self.d(activation_function)
self.delta = 1e-10
self.Z: list[np.ndarray] = [np.zeros(layers[0])]
self.W: list[np.ndarray] = [np.zeros(layers[0])]
self.B: list[np.ndarray] = [np.zeros(layers[0])]
self.output: list[np.ndarray] = [np.zeros(layers[0])]
for i in range(1, len(self.layers)):
self.W.append(np.random.randn(self.layers[i], self.layers[i-1]) * np.sqrt(2/layers[i-1]))
self.B.append(np.zeros(self.layers[i]))
self.Z.append(np.zeros(self.layers[i]))
self.output.append(np.zeros(self.layers[i]))
def d(self, f: Callable) -> Callable:
delta = 1e-10j
def df(x): return f(x + delta).imag / delta.imag
return df我們希望能夠透過輸入來決定神經網路的結構
e.g. layers = [16, 32, 64, 32, 10]
那麼輸入層 = 16 輸出層 = 10 其他層同理
class NeuralNetwork:
def __init__(self, layers: list[int], activation_function: Callable, dactivation_function: Callable=None, learning_rate: float=1e-3) -> None:
self.layers = layers
self.learning_rate = learning_rate
self.act = activation_function
self.dact = dactivation_function or self.d(activation_function)
self.delta = 1e-10
self.Z: list[np.ndarray] = [np.zeros(layers[0])]
self.W: list[np.ndarray] = [np.zeros(layers[0])]
self.B: list[np.ndarray] = [np.zeros(layers[0])]
self.output: list[np.ndarray] = [np.zeros(layers[0])]
for i in range(1, len(self.layers)):
self.W.append(np.random.randn(self.layers[i], self.layers[i-1]) * np.sqrt(2/layers[i-1]))
self.B.append(np.zeros(self.layers[i]))
self.Z.append(np.zeros(self.layers[i]))
self.output.append(np.zeros(self.layers[i]))
def d(self, f: Callable) -> Callable:
delta = 1e-10j
def df(x): return f(x + delta).imag / delta.imag
return df
設定學習率 梯度下降會使用到
class NeuralNetwork:
def __init__(self, layers: list[int], activation_function: Callable, dactivation_function: Callable=None, learning_rate: float=1e-3) -> None:
self.layers = layers
self.learning_rate = learning_rate
self.act = activation_function
self.dact = dactivation_function or self.d(activation_function)
self.delta = 1e-10
self.Z: list[np.ndarray] = [np.zeros(layers[0])]
self.W: list[np.ndarray] = [np.zeros(layers[0])]
self.B: list[np.ndarray] = [np.zeros(layers[0])]
self.output: list[np.ndarray] = [np.zeros(layers[0])]
for i in range(1, len(self.layers)):
self.W.append(np.random.randn(self.layers[i], self.layers[i-1]) * np.sqrt(2/layers[i-1]))
self.B.append(np.zeros(self.layers[i]))
self.Z.append(np.zeros(self.layers[i]))
self.output.append(np.zeros(self.layers[i]))
def d(self, f: Callable) -> Callable:
delta = 1e-10j
def df(x): return f(x + delta).imag / delta.imag
return df設定 activation functions
另外構建了一個函數在未給予dact的情況下自動微分
class NeuralNetwork:
def __init__(self, layers: list[int], activation_function: Callable, dactivation_function: Callable=None, learning_rate: float=1e-3) -> None:
self.layers = layers
self.learning_rate = learning_rate
self.act = activation_function
self.dact = dactivation_function or self.d(activation_function)
self.delta = 1e-10
self.Z: list[np.ndarray] = [np.zeros(layers[0])]
self.W: list[np.ndarray] = [np.zeros(layers[0])]
self.B: list[np.ndarray] = [np.zeros(layers[0])]
self.output: list[np.ndarray] = [np.zeros(layers[0])]
for i in range(1, len(self.layers)):
self.W.append(np.random.randn(self.layers[i], self.layers[i-1]) * np.sqrt(2/layers[i-1]))
self.B.append(np.zeros(self.layers[i]))
self.Z.append(np.zeros(self.layers[i]))
self.output.append(np.zeros(self.layers[i]))
def d(self, f: Callable) -> Callable:
delta = 1e-10j
def df(x): return f(x + delta).imag / delta.imag
return df設定一個很小的數字
用以防止特定地方可能除以0導致程式發生錯誤
class NeuralNetwork:
def __init__(self, layers: list[int], activation_function: Callable, dactivation_function: Callable=None, learning_rate: float=1e-3) -> None:
self.layers = layers
self.learning_rate = learning_rate
self.act = activation_function
self.dact = dactivation_function or self.d(activation_function)
self.delta = 1e-10
self.Z: list[np.ndarray] = [np.zeros(layers[0])]
self.W: list[np.ndarray] = [np.zeros(layers[0])]
self.B: list[np.ndarray] = [np.zeros(layers[0])]
self.output: list[np.ndarray] = [np.zeros(layers[0])]
for i in range(1, len(self.layers)):
self.W.append(np.random.randn(self.layers[i], self.layers[i-1]) * np.sqrt(2/layers[i-1]))
self.B.append(np.zeros(self.layers[i]))
self.Z.append(np.zeros(self.layers[i]))
self.output.append(np.zeros(self.layers[i]))
def d(self, f: Callable) -> Callable:
delta = 1e-10j
def df(x): return f(x + delta).imag / delta.imag
return df建立存放參數的陣列
並且事先以填充0初始化每個神經元的參數陣列大小
class NeuralNetwork:
def __init__(self, layers: list[int], activation_function: Callable, dactivation_function: Callable=None, learning_rate: float=1e-3) -> None:
self.layers = layers
self.learning_rate = learning_rate
self.act = activation_function
self.dact = dactivation_function or self.d(activation_function)
self.delta = 1e-10
self.Z: list[np.ndarray] = [np.zeros(layers[0])]
self.W: list[np.ndarray] = [np.zeros(layers[0])]
self.B: list[np.ndarray] = [np.zeros(layers[0])]
self.output: list[np.ndarray] = [np.zeros(layers[0])]
for i in range(1, len(self.layers)):
self.W.append(np.random.randn(self.layers[i], self.layers[i-1]) * np.sqrt(2/layers[i-1]))
self.B.append(np.zeros(self.layers[i]))
self.Z.append(np.zeros(self.layers[i]))
self.output.append(np.zeros(self.layers[i]))
def d(self, f: Callable) -> Callable:
delta = 1e-10j
def df(x): return f(x + delta).imag / delta.imag
return df有人可能會好奇這行的初始化方式
關於參數的初始化方式詳細會在
Problems 章節進行說明
def softmax(self, x):
exp_x = np.exp(x - np.max(x))
return exp_x / np.sum(exp_x)
def cross_entropy(self, y: np.ndarray) -> np.float64:
return -np.dot(y.T, np.log(self.output[-1] + self.delta))在物件內建立好待會會使用到的算式
另外前面提到的delta在cross entropy時便使用到了
np.dot(x, y)
內積 詳細可見線性代數章節
np.exp(x)
對每個x的元素取 e^x
def save_params(self, filename: str="params.json"):
with open(filename, "w") as f:
json.dump({"W": self.W, "B": self.B}, f, indent=4, cls=NumpyArrayEncoder)
def load_params(self, filename: str="params.json"):
with open(filename, "r") as f:
params = json.load(f)
self.W = []
self.B = []
for w in params["W"]: self.W.append(np.asarray(w))
for b in params["B"]: self.B.append(np.asarray(b))設定個儲存參數的東西
可以避免每次都要重複花時間去訓練
def save_params(self, filename: str="params.json"):
with open(filename, "w") as f:
json.dump({"W": self.W, "B": self.B}, f, indent=4, cls=NumpyArrayEncoder)
def load_params(self, filename: str="params.json"):
with open(filename, "r") as f:
params = json.load(f)
self.W = []
self.B = []
for w in params["W"]: self.W.append(np.asarray(w))
for b in params["B"]: self.B.append(np.asarray(b))設定個儲存參數的東西
可以避免每次都要重複花時間去訓練
另外由於 numpy array 無法被 json 序列化
因此需要使用自訂的 encoder
# encoder.py
import json
import numpy as np
class NumpyArrayEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.ndarray):
return obj.tolist()
return json.JSONEncoder.default(self, obj)另外由於 numpy array 無法被 json 序列化
因此需要使用自訂的 encoder
自訂 encoder 會將物件內的每個 numpy array
進行 tolist() 操作
讓他可以變成 python 內建的 list 被儲存到 json
def forward(self, x: np.ndarray) -> np.ndarray:
assert x.shape[0] == self.layers[0]
self.output[0] = x
for i in range(1, len(self.layers)):
self.Z[i] = np.dot(self.W[i], self.output[i-1]) + self.B[i]
if i == len(self.layers)-1: self.output[i] = self.softmax(self.Z[i])
else: self.output[i] = self.act(self.Z[i])
return self.output[-1]前向傳播 啟動
def forward(self, x: np.ndarray) -> np.ndarray:
assert x.shape[0] == self.layers[0]
self.output[0] = x
for i in range(1, len(self.layers)):
self.Z[i] = np.dot(self.W[i], self.output[i-1]) + self.B[i]
if i == len(self.layers)-1: self.output[i] = self.softmax(self.Z[i])
else: self.output[i] = self.act(self.Z[i])
return self.output[-1]def forward(self, x: np.ndarray) -> np.ndarray:
assert x.shape[0] == self.layers[0]
self.output[0] = x
for i in range(1, len(self.layers)):
self.Z[i] = np.dot(self.W[i], self.output[i-1]) + self.B[i]
if i == len(self.layers)-1: self.output[i] = self.softmax(self.Z[i])
else: self.output[i] = self.act(self.Z[i])
return self.output[-1]def backward(self, y: np.ndarray) -> None:
x = self.output[-1] - y
for i in range(len(self.layers)-1, 0, -1):
t = x * self.dact(self.Z[i])
x = np.dot(self.W[i].T, t)
self.W[i] -= self.learning_rate * np.outer(t, self.output[i-1])
self.B[i] -= self.learning_rate * t反向傳播 啟動
def backward(self, y: np.ndarray) -> None:
x = self.output[-1] - y
for i in range(len(self.layers)-1, 0, -1):
t = x * self.dact(self.Z[i])
x = np.dot(self.W[i].T, t)
self.W[i] -= self.learning_rate * np.outer(t, self.output[i-1])
self.B[i] -= self.learning_rate * tdef backward(self, y: np.ndarray) -> None:
x = self.output[-1] - y
for i in range(len(self.layers)-1, 0, -1):
t = x * self.dact(self.Z[i])
x = np.dot(self.W[i].T, t)
self.W[i] -= self.learning_rate * np.outer(t, self.output[i-1])
self.B[i] -= self.learning_rate * tdef backward(self, y: np.ndarray) -> None:
x = self.output[-1] - y
for i in range(len(self.layers)-1, 0, -1):
t = x * self.dact(self.Z[i])
x = np.dot(self.W[i].T, t)
self.W[i] -= self.learning_rate * np.outer(t, self.output[i-1])
self.B[i] -= self.learning_rate * tdef backward(self, y: np.ndarray) -> None:
x = self.output[-1] - y
for i in range(len(self.layers)-1, 0, -1):
t = x * self.dact(self.Z[i])
x = np.dot(self.W[i].T, t)
self.W[i] -= self.learning_rate * np.outer(t, self.output[i-1])
self.B[i] -= self.learning_rate * tdef backward(self, y: np.ndarray) -> None:
x = self.output[-1] - y
for i in range(len(self.layers)-1, 0, -1):
t = x * self.dact(self.Z[i])
x = np.dot(self.W[i].T, t)
self.W[i] -= self.learning_rate * np.outer(t, self.output[i-1])
self.B[i] -= self.learning_rate * t將反向傳播得到的資訊
乘上權重
def backward(self, y: np.ndarray) -> None:
x = self.output[-1] - y
for i in range(len(self.layers)-1, 0, -1):
t = x * self.dact(self.Z[i])
x = np.dot(self.W[i].T, t)
self.W[i] -= self.learning_rate * np.outer(t, self.output[i-1])
self.B[i] -= self.learning_rate * tdef backward(self, y: np.ndarray) -> None:
x = self.output[-1] - y
for i in range(len(self.layers)-1, 0, -1):
t = x * self.dact(self.Z[i])
x = np.dot(self.W[i].T, t)
self.W[i] -= self.learning_rate * np.outer(t, self.output[i-1])
self.B[i] -= self.learning_rate * t因此w要多乘一個過未經微分的sigmoid的x
def fit(self, x: np.ndarray, y: np.ndarray) -> np.float64:
self.forward(x)
loss = self.cross_entropy(y)
self.backward(y)
return loss每次進行一次最佳化就
過一次正向傳播計算loss後
進行反向傳播更新參數
# act.py
import numpy as np
def relu(x):
return np.maximum(0, x)
def drelu(x):
return np.where(x > 0, 1, 0)# *)#$#*)%*)#$#)*%
# encoder.py
import json
import numpy as np
class NumpyArrayEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.ndarray):
return obj.tolist()
return json.JSONEncoder.default(self, obj)# *)#$#*)%*)#$#)*%
# nn.py
import numpy as np
import json
from typing import Callable
from encoder import NumpyArrayEncoder
class NeuralNetwork:
def __init__(self, layers: list[int], activation_function: Callable, dactivation_function: Callable=None, learning_rate: float=1e-3) -> None:
self.layers = layers
self.learning_rate = learning_rate
self.act = activation_function
self.dact = dactivation_function or self.d(activation_function)
self.delta = 1e-10
self.Z: list[np.ndarray] = [np.zeros(layers[0])]
self.W: list[np.ndarray] = [np.zeros(layers[0])]
self.B: list[np.ndarray] = [np.zeros(layers[0])]
self.output: list[np.ndarray] = [np.zeros(layers[0])]
for i in range(1, len(self.layers)):
self.W.append(np.random.randn(self.layers[i], self.layers[i-1]) * np.sqrt(2/layers[i-1]))
self.B.append(np.zeros(self.layers[i]))
self.Z.append(np.zeros(self.layers[i]))
self.output.append(np.zeros(self.layers[i]))
def d(self, f: Callable) -> Callable:
delta = 1e-10j
def df(x): return f(x + delta).imag / delta.imag
return df
def softmax(self, x):
exp_x = np.exp(x - np.max(x))
return exp_x / np.sum(exp_x)
def cross_entropy(self, y: np.ndarray) -> np.float64:
return -np.dot(y.T, np.log(self.output[-1] + self.delta))
def forward(self, x: np.ndarray) -> np.ndarray:
assert x.shape[0] == self.layers[0]
self.output[0] = x
for i in range(1, len(self.layers)):
self.Z[i] = np.dot(self.W[i], self.output[i-1]) + self.B[i]
if i == len(self.layers)-1: self.output[i] = self.softmax(self.Z[i])
else: self.output[i] = self.act(self.Z[i])
return self.output[-1]
def backward(self, y: np.ndarray) -> None:
x = self.output[-1] - y
for i in range(len(self.layers)-1, 0, -1):
t = x * self.dact(self.Z[i])
x = np.dot(self.W[i].T, t)
self.W[i] -= self.learning_rate * np.outer(t, self.output[i-1])
self.B[i] -= self.learning_rate * t
def fit(self, x: np.ndarray, y: np.ndarray) -> np.float64:
self.forward(x)
loss = self.cross_entropy(y)
self.backward(y)
return loss
def save_params(self, filename: str="params.json"):
with open(filename, "w") as f:
json.dump({"W": self.W, "B": self.B}, f, indent=4, cls=NumpyArrayEncoder)
def load_params(self, filename: str="params.json"):
with open(filename, "r") as f:
params = json.load(f)
self.W = []
self.B = []
for w in params["W"]: self.W.append(np.asarray(w))
for b in params["B"]: self.B.append(np.asarray(b))# *)#$#*)%*)#$#)*%
我們期望運行神經網路的流程如下
訓練神經網路 => 測試模型準確率
也就是說我們的啟動檔案
會匯入模型以及MNIST
並且進行訓練與測試
最後會得到準確率的結果與過程的loss變化
建立一個 main.py
此時檔案結構應如下
接著來編寫 main.py
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from nn import NeuralNetwork
from act import relu, drelu先引入所需函式庫
設定參數
learning_rate: 學習率
data_size: 資料大小(等同輸入層的層數)
batch_size: 每次訓練並輸出的批次量
max_trains: 最大訓練次數
epochs: 總共訓練幾個epoch
save: 是否要儲存參數
learning_rate = 1e-3
data_size = 784
batch_size = 64
max_trains = 60000
epochs = 3
save = True(x_train_image, y_train_label), (x_test_image, y_test_label) = mnist.load_data()
x_trains = np.array(x_train_image).reshape(len(x_train_image), 784).astype("float64")/255
x_tests = np.array(x_test_image).reshape(len(x_test_image), 784).astype("float64")/255
y_trains = np.eye(10)[y_train_label]
y_tests = np.eye(10)[y_test_label]從MNIST中載入資料
並且將圖片轉換成一維陣列後設定型別
除以255是為了讓灰階區間從[0, 255]->[0, 1]
(x_train_image, y_train_label), (x_test_image, y_test_label) = mnist.load_data()
x_trains = np.array(x_train_image).reshape(len(x_train_image), 784).astype("float64")/255
x_tests = np.array(x_test_image).reshape(len(x_test_image), 784).astype("float64")/255
y_trains = np.eye(10)[y_train_label]
y_tests = np.eye(10)[y_test_label]np.eye(n)會建立一個n*n的單位矩陣
(x_train_image, y_train_label), (x_test_image, y_test_label) = mnist.load_data()
x_trains = np.array(x_train_image).reshape(len(x_train_image), 784).astype("float64")/255
x_tests = np.array(x_test_image).reshape(len(x_test_image), 784).astype("float64")/255
y_trains = np.eye(10)[y_train_label]
y_tests = np.eye(10)[y_test_label]np.eye(n)會建立一個n*n的單位矩陣
(x_train_image, y_train_label), (x_test_image, y_test_label) = mnist.load_data()
x_trains = np.array(x_train_image).reshape(len(x_train_image), 784).astype("float64")/255
x_tests = np.array(x_test_image).reshape(len(x_test_image), 784).astype("float64")/255
y_trains = np.eye(10)[y_train_label]
y_tests = np.eye(10)[y_test_label]那為什麼要這麼做呢
因為我們要讓label的形式轉換一下
(x_train_image, y_train_label), (x_test_image, y_test_label) = mnist.load_data()
x_trains = np.array(x_train_image).reshape(len(x_train_image), 784).astype("float64")/255
x_tests = np.array(x_test_image).reshape(len(x_test_image), 784).astype("float64")/255
y_trains = np.eye(10)[y_train_label]
y_tests = np.eye(10)[y_test_label]那為什麼要這麼做呢
因為我們要讓label的形式轉換一下
※它給的label是0-based 不用減一
nn = NeuralNetwork(layers=[784, 256, 128, 64, 10], activation_function=relu, dactivation_function=drelu, learning_rate=learning_rate)
train_loss = nn.train(x_trains, y_trains, epochs, batch_size, max_trains, save)
test_loss = nn.predict(x_tests, y_tests)創建神經網路物件
並依序從訓練及預測函式拿到loss
(函式內容會在後面章節提到)
plt.plot(train_loss, label="Train Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()使用matplotlib函式庫繪製loss的變化圖表
# *)#$#*)%*)#$#)*%
# main.py
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from nn import NeuralNetwork
from act import relu, drelu
learning_rate = 1e-3
data_size = 784
batch_size = 64
max_trains = 60000
epochs = 3
save = True
(x_train_image, y_train_label), (x_test_image, y_test_label) = mnist.load_data()
x_trains = np.array(x_train_image).reshape(len(x_train_image), 784).astype("float64")/255
x_tests = np.array(x_test_image).reshape(len(x_test_image), 784).astype("float64")/255
y_trains = np.eye(10)[y_train_label]
y_tests = np.eye(10)[y_test_label]
nn = NeuralNetwork(layers=[784, 256, 128, 64, 10], activation_function=relu, dactivation_function=drelu, learning_rate=learning_rate)
train_loss = nn.train(x_trains, y_trains, epochs, batch_size, max_trains, save)
test_loss = nn.predict(x_tests, y_tests)
plt.plot(train_loss, label="Train Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()接著來處理訓練(train)跟預測(predict)的函式
為了讓每次訓練的輸出
不要因為單次的偏差而顯得數據差過大
我們通常會以一個批次(batch)為單位去做訓練
而批次的大小
而訓練也可以藉由重複訓練來加強參數
每個epoch便是將整個數據集訓練一遍
而epoch的次數越高 訓練時長越高
但相對的準確率就會提高
另外
最大訓練次數純粹是因為我懶得訓練太久而強制中止的東東
def train(self, x_trains: np.ndarray, y_trains: np.ndarray, epochs: int, batch_size: int=64, max_trains: int=60000, save: bool=False) -> list[np.float64]:
train_loss = []
for epoch in range(epochs):
max_trains = min(max_trains, len(x_trains))
batch_loss = 0
for i in range(0, max_trains, batch_size):
x_batch = x_trains[i:i + batch_size]
y_batch = y_trains[i:i + batch_size]
for x_train, y_train in zip(x_batch, y_batch):
batch_loss += self.fit(x_train, y_train)
print(f"Batch {i//batch_size+1}/{max_trains//batch_size+1}, Loss: {batch_loss/(i+1)}")
avg_loss = batch_loss / max_trains
train_loss.append(avg_loss)
if save:
self.save_params()
print(f"Epoch {epoch+1}/{epochs}, Loss: {avg_loss}, Save: {save}")
return train_loss幾乎同訓練
不過不會更新參數
並且加上準確率
def predict(self, x_tests: np.ndarray, y_tests: np.ndarray) -> list[np.float64]:
test_loss = []
accuracy = 0
for i, (x_test, y_test) in enumerate(zip(x_tests, y_tests)):
output = self.forward(x_test)
loss = self.cross_entropy(y_test)
correct = output.argmax() == y_test.argmax()
if correct:
accuracy += 1
test_loss.append(loss)
print(f"Test Data: {i+1}/{len(x_tests)}, Loss: {loss}, Correct: {correct}")
print(f"Average test loss: {sum(test_loss) / len(test_loss)}")
print(f"Accuracy: {accuracy / len(x_tests)}")
return test_loss# nn.py
import numpy as np
import json
from typing import Callable
from encoder import NumpyArrayEncoder
class NeuralNetwork:
def __init__(self, layers: list[int], activation_function: Callable, dactivation_function: Callable=None, learning_rate: float=1e-3) -> None:
self.layers = layers
self.learning_rate = learning_rate
self.act = activation_function
self.dact = dactivation_function or self.d(activation_function)
self.delta = 1e-10
self.Z: list[np.ndarray] = [np.zeros(layers[0])]
self.W: list[np.ndarray] = [np.zeros(layers[0])]
self.B: list[np.ndarray] = [np.zeros(layers[0])]
self.output: list[np.ndarray] = [np.zeros(layers[0])]
for i in range(1, len(self.layers)):
self.W.append(np.random.randn(self.layers[i], self.layers[i-1]) * np.sqrt(2/layers[i-1]))
self.B.append(np.zeros(self.layers[i]))
self.Z.append(np.zeros(self.layers[i]))
self.output.append(np.zeros(self.layers[i]))
def d(self, f: Callable) -> Callable:
delta = 1e-10j
def df(x): return f(x + delta).imag / delta.imag
return df
def softmax(self, x):
exp_x = np.exp(x - np.max(x))
return exp_x / np.sum(exp_x)
def cross_entropy(self, y: np.ndarray) -> np.float64:
return -np.dot(y.T, np.log(self.output[-1] + self.delta))
def forward(self, x: np.ndarray) -> np.ndarray:
assert x.shape[0] == self.layers[0]
self.output[0] = x
for i in range(1, len(self.layers)):
self.Z[i] = np.dot(self.W[i], self.output[i-1]) + self.B[i]
if i == len(self.layers)-1: self.output[i] = self.softmax(self.Z[i])
else: self.output[i] = self.act(self.Z[i])
return self.output[-1]
def backward(self, y: np.ndarray) -> None:
x = self.output[-1] - y
for i in range(len(self.layers)-1, 0, -1):
t = x * self.dact(self.Z[i])
x = np.dot(self.W[i].T, t)
self.W[i] -= self.learning_rate * np.outer(t, self.output[i-1])
self.B[i] -= self.learning_rate * t
def fit(self, x: np.ndarray, y: np.ndarray) -> np.float64:
self.forward(x)
loss = self.cross_entropy(y)
self.backward(y)
return loss
def predict(self, x_tests: np.ndarray, y_tests: np.ndarray) -> list[np.float64]:
test_loss = []
accuracy = 0
for i, (x_test, y_test) in enumerate(zip(x_tests, y_tests)):
output = self.forward(x_test)
loss = self.cross_entropy(y_test)
correct = output.argmax() == y_test.argmax()
if correct:
accuracy += 1
test_loss.append(loss)
print(f"Test Data: {i+1}/{len(x_tests)}, Loss: {loss}, Correct: {correct}")
print(f"Average test loss: {sum(test_loss) / len(test_loss)}")
print(f"Accuracy: {accuracy / len(x_tests)}")
return test_loss
def train(self, x_trains: np.ndarray, y_trains: np.ndarray, epochs: int, batch_size: int=64, max_trains: int=60000, save: bool=False) -> list[np.float64]:
train_loss = []
for epoch in range(epochs):
max_trains = min(max_trains, len(x_trains))
batch_loss = 0
for i in range(0, max_trains, batch_size):
x_batch = x_trains[i:i + batch_size]
y_batch = y_trains[i:i + batch_size]
for x_train, y_train in zip(x_batch, y_batch):
batch_loss += self.fit(x_train, y_train)
print(f"Batch {i//batch_size+1}/{max_trains//batch_size+1}, Loss: {batch_loss/(i+1)}")
avg_loss = batch_loss / max_trains
train_loss.append(avg_loss)
if save:
self.save_params()
print(f"Epoch {epoch+1}/{epochs}, Loss: {avg_loss}")
return train_loss
def save_params(self, filename: str="params.json"):
with open(filename, "w") as f:
json.dump({"W": self.W, "B": self.B}, f, indent=4, cls=NumpyArrayEncoder)
def load_params(self, filename: str="params.json"):
with open(filename, "r") as f:
params = json.load(f)
self.W = []
self.B = []
for w in params["W"]: self.W.append(np.asarray(w))
for b in params["B"]: self.B.append(np.asarray(b))# *)#$#*)%*)#$#)*%
有人可能會好奇為什麼不連矩陣一起手刻
因為numpy的程式是基於C語言
因此可以有比一般Python程式更快速的運算速度
有人可能會好奇為什麼不連矩陣一起手刻
因為numpy的程式是基於C語言
因此可以有比一般Python程式更快速的運算速度
但它還是有個缺點
那就是它是使用CPU在跑
讓numpy可以使用GPU跑的函式庫
使用方式就是把原本的
import numpyimport cupy缺點是安裝麻煩一點
視情況要根據你的cuda版本安裝不同的函式庫
所有需要由使用者自行調整的皆為超參數
像是每層的神經元個數、批次大小、學習率等
這些參數在設定時可以參考現有模型的設定
或是網路上的文章教學
拿前人試出的結果總比自己花時間試好 (?
你會發現它在辨識不在資料集內的圖片時
表現的成果異常拙劣
一部份是由於沒給到其他風格的資料
但另一部份是我們的辨識方式
沒有經由特徵的判斷
而是直接根據像素點的位置去做計算
這要如何改善呢?
這要如何改善呢?
By lucasw
使用Python手刻神經網路




