








lucasw
大佬教麻
你可以叫我 000 / Lucas
建國中學資訊社37th學術長
建國中學電子計算機研習社44th學術
校際交流群創群者
不會音遊不會競程不會數學的笨
資訊技能樹亂點但都一樣爛
專案爛尾大師
IZCC x SCINT x Ruby Taiwan 聯課負責人
建國中學電子計算機研習社44th學術+總務
是的,我是總務。在座的你各位下次記得交社費束脩給我
技能樹貧乏
想拿機器學習做專題結果只學會使用API
上屆社展烙跑到資訊社的叛徒
科班墊神
大型語言模型
說到 AI
除了之前教過的
資料分析、圖像辨識、玩遊戲之外
現今社會中我們最常使用的是什麼?
而這些我們熟知的大語言模型
(Large Language Model)
在做的事情被稱為自然語言處理
(Natural Language Processing)
這也是現今機器學習一門大領域
我們先來看看回到一般的神經網路
他在 NLP 上有什麼不足?
先想想輸入輸出
我們先來看看回到一般的神經網路
他在 NLP 上有什麼不足?
先想想輸入輸出
以一個詞作為輸入
讓他給出回應每個詞的權重(one-hot)
如果給他一句話要他學習
例如:
「會考會考會考會考的」
如果給他一句話要他學習
例如:
「會考會考會考會考的」
名
___ _ _ ___ ___ _
助動
動
名
形
助
如果給他一句話要他學習
例如:
「會考會考會考會考的」
名
___ _ _ ___ ___ _
助動
動
名
形
助
神經網路吃到這句話之後根本無法
正確的了解到每個相同詞的意思
這樣一來 很容易會有理解錯誤導致的亂回答
神經網路吃到這句話之後根本無法
正確的了解到每個相同詞的意思
這樣一來 很容易會有理解錯誤導致的亂回答
: 「明天是會考欸」
AI: 「我覺得不會考」
:
遞迴神經網路
為了解決上一章的問題
便有了能夠學習到上下文資訊的
RNN (Recurrent Neural Network)
讓模型在每一次的計算中都能
包含到上一次的結果
讓模型在每一次的計算中都能
包含到上一次的結果
如此一來
「前面有路,前進」
「前面沒路,後退」
讓模型在每一次的計算中都能
包含到上一次的結果
如此一來
「前面有路,前進」
「前面沒路,後退」
在輸入到這一步時
他便能根據前文推斷下文應該是前進還是後退
(不然對他來說輸入的都是一樣的逗號)
但是到了這步
真的可以好好地進行自然語言處理嗎?
我們可以試想一下
在訓練充足的情況下
他能夠藉由上文從一個詞知道下一個詞
但是這個 「上文」包含到的資料...
來看看 RNN 的算法
一般神經網路
來看看 RNN 的算法
遞迴神經網路
h 也就是我們儲存的資料aka隱藏狀態
h 也就是我們儲存的資料aka隱藏狀態
而我們對不同參數都設有各自獨立的權重
遞迴神經網路
回到我們的問題
你可以發現到這樣會導致說
我們的記憶從上上一個詞得到的影響越來越少
但是在經過多次的更新隱藏狀態後
新狀態也容易受到某個數值大的舊狀態產生過大的影響
遞迴神經網路
而這個問題的解決方式就是妥善管理「記憶」
遞迴神經網路
長短期記憶網路
LSTM (Long Short-Term Memory)
為每個儲存區(記憶)添加了以下內容
LSTM (Long Short-Term Memory)
為每個儲存區(記憶)添加了以下內容
而輸入輸出閥都是可以訓練是否讓資料通過
遺忘閥則是訓練是否將目前存的記憶清除
換成數學式也就是這樣
RNN:
LSTM:
LSTM:
我們把過激勵函數的 gate 輸入值視為權重
美化一下式子
LSTM:
我們把過激勵函數的 gate 輸入值視為權重
美化一下式子
LSTM:
你會發現跟 RNN 比起來改變的點不多
其實也就是幫每個權重加入激勵函數與代表的邏輯
我們把過激勵函數的 gate 輸入值視為權重
美化一下式子
LSTM:
你會發現跟 RNN 比起來改變的點不多
其實也就是幫每個權重加入激勵函數與代表的邏輯
這邊的激勵函數常以 Sigmoid 為主
因為能夠把值限縮到0-1之間
表示通過的比例/機率
import os
import numpy as np
import spacy
from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
BASEPATH = os.path.dirname(os.path.abspath(__file__))
MODEL_FILE = "rickroll.h5"
class NLPModel:
def __init__(self):
self.model = None
self.NLP = spacy.load("en_core_web_sm", disable=["parser", "ner", "textcat"])
self.NLP.max_length = 1198623
self.tokenizer = Tokenizer()
self.seq_len = 25
self.sequences = None
self.vocab_size = None
def create_model(self, vocabulary_size):
model: Sequential = Sequential()
model.add(Embedding(vocabulary_size, 25, input_length=self.seq_len))
model.add(LSTM(150, return_sequences=True))
model.add(LSTM(150))
model.add(Dense(150, activation="relu"))
model.add(Dense(vocabulary_size, activation="softmax"))
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.summary()
return model
def preprocess_text(self, texts):
self.tokenizer.fit_on_texts(texts)
sequences = self.tokenizer.texts_to_sequences(texts)
sequences = np.array(sequences)
return sequences
def test_nlp(self, sample_text):
doc = self.NLP(sample_text)
print("Sample text:", sample_text)
for token in doc:
print(f"Token: {token.text}, POS: {token.pos_}, Lemma: {token.lemma_}, Dependency: {token.dep_}")
def preload(self):
with open(os.path.join(BASEPATH, "text.txt"), "r", encoding="utf-8") as file:
data = file.read()
filtered = '!"#$%&().*+,-/:;<=>?@[\\]^_`{|}~\t\n '
tokens = [token.text.lower() for token in self.NLP(data) if token.text not in filtered]
train_len = 26
text_seq = []
print("Total tokens:", len(tokens))
for i in range(train_len, len(tokens)):
seq = tokens[i-train_len:i]
text_seq.append(seq)
self.sequences = self.preprocess_text(text_seq)
self.vocab_size = len(self.tokenizer.word_counts)+1
self.model = self.create_model(self.vocab_size)
print("Vocabulary size:", self.vocab_size)
print("Total sequences:", len(self.sequences))
def train(self, epochs=200, batch_size=64):
x = self.sequences[:, :-1]
y = self.sequences[:, -1]
print("Input shape:", x.shape)
print("Output shape:", y.shape)
y = to_categorical(y, num_classes=self.vocab_size)
self.model.fit(x, y, epochs=epochs, batch_size=batch_size, verbose=1)
self.model.save_weights(os.path.join(BASEPATH, MODEL_FILE))
def generate_text(self, seed_text, num_gen_words):
output_text = []
input_text = seed_text
for i in range(self.seq_len, num_gen_words):
encoded_text = self.tokenizer.texts_to_sequences([input_text])[0]
pad_encoded = pad_sequences([encoded_text], maxlen=self.seq_len, truncating="pre")
predict_x=self.model.predict(pad_encoded, verbose=0)[0]
pred_word_ind=np.argmax(predict_x)
pred_word = self.tokenizer.index_word[pred_word_ind]
input_text += " " + pred_word
output_text.append(pred_word)
return " ".join(output_text)
if __name__ == "__main__":
nlp_model = NLPModel()
nlp_model.preload()
print("================================")
nlp_model.test_nlp("Never gonna give you up")
print("================================")
if os.path.exists(os.path.join(BASEPATH, MODEL_FILE)):
nlp_model.model.load_weights(os.path.join(BASEPATH, MODEL_FILE))
else:
nlp_model.train()
while True:
seed_text = input("Enter seed text (or 'exit' to quit): ")
if seed_text.lower() == "exit": break
num_gen_words = 50
generated_text = nlp_model.generate_text(seed_text, num_gen_words)
print("Generated Text:", generated_text.strip())
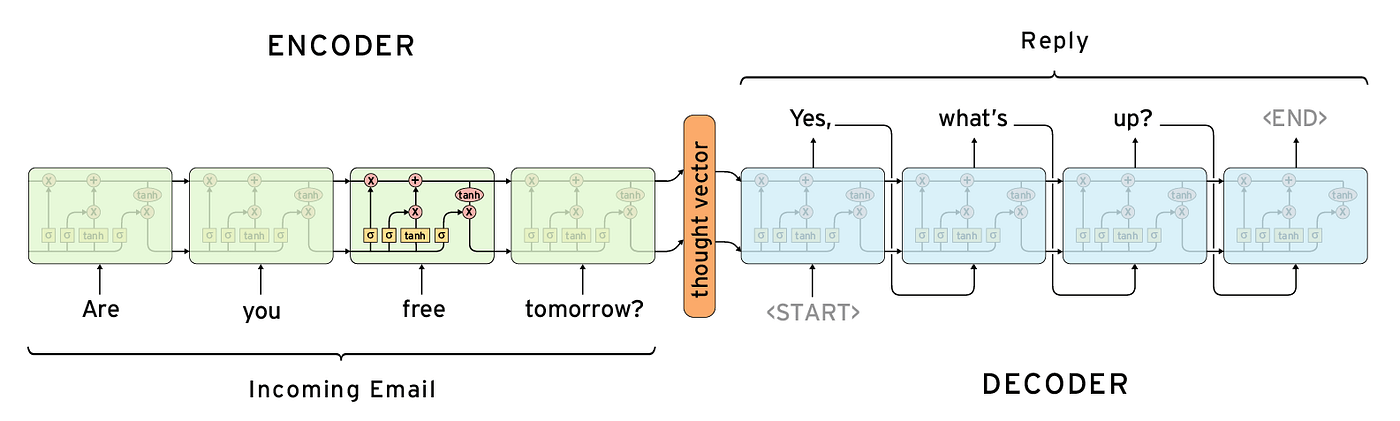
序列映射序列
語言翻譯: 文字 -> 文字
語音翻譯: 語音 -> 文字
聊天回應: 文字 -> 文字
在我們常見的幾種 NLP 中
都有一個與其他學習不同的特性
那就是輸入與輸出都是不定長度的
可以用
Seq2Seq(Sequence to Sequence)
的方式去完成
@#*$)*@*
Seq2Seq (Sequence to Sequence)
將輸入經過 Encoder 轉換為傳遞向量
之後透過接龍的方式從讓 Token 不斷從 Decoder 經過來得到最終的回覆
Seq2Seq (Sequence to Sequence)
將輸入經過 Encoder 轉換為傳遞向量
之後透過接龍的方式從讓 Token 不斷從 Decoder 經過來得到最終的回覆
如此一來
便能夠應用在不定長度的資料
自注意力機制
這樣的一個機制
還有什麼能優化的地方呢?
我們對於詞的處理方式
是藉由上下文
但是在往神經網路輸入資料時
我們能給的還是一個代表特定詞彙的數字編碼
可能 [14] 跟 [15] 數字相近
但是意義截然不同
這時候精通線性代數又學完神經網路的你
想到了可以用向量來表示一個詞
然後藉由訓練來讓一個詞進去能有對應的向量
且相近詞的向量也會相近
這時候精通線性代數又學完神經網路的你
想到了可以用向量來表示一個詞
然後藉由訓練來讓一個詞進去能有對應的向量
且相近詞的向量也會相近
並且訓練對應的向量這個行為也可以用在其他
像是聲音訊號或是其他指標
廢話不多說
下圖&公式
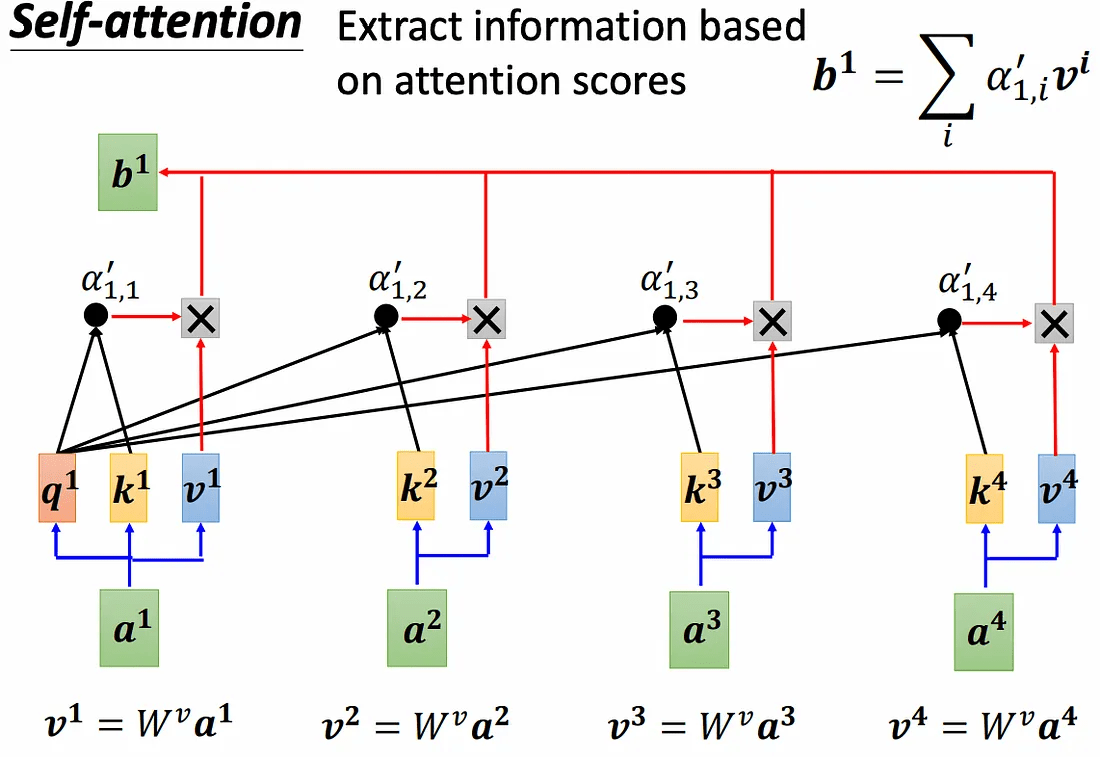
Query(Q):我要找什麼資訊?
Key(K):我提供什麼資訊?
Value(V):真正的資訊內容
by chatgpt
廢話不多說
下圖&公式
透過將查詢Q與鍵值K兩兩做內積拿夾角aka相關程度
除以 d (縮放因子) 以確保數值不會受到內積過度放大
使之後過 Softmax 時值過於極端
最後將值V乘上相關程度權重以獲取加權後的資訊
廢話不多說
下圖&公式
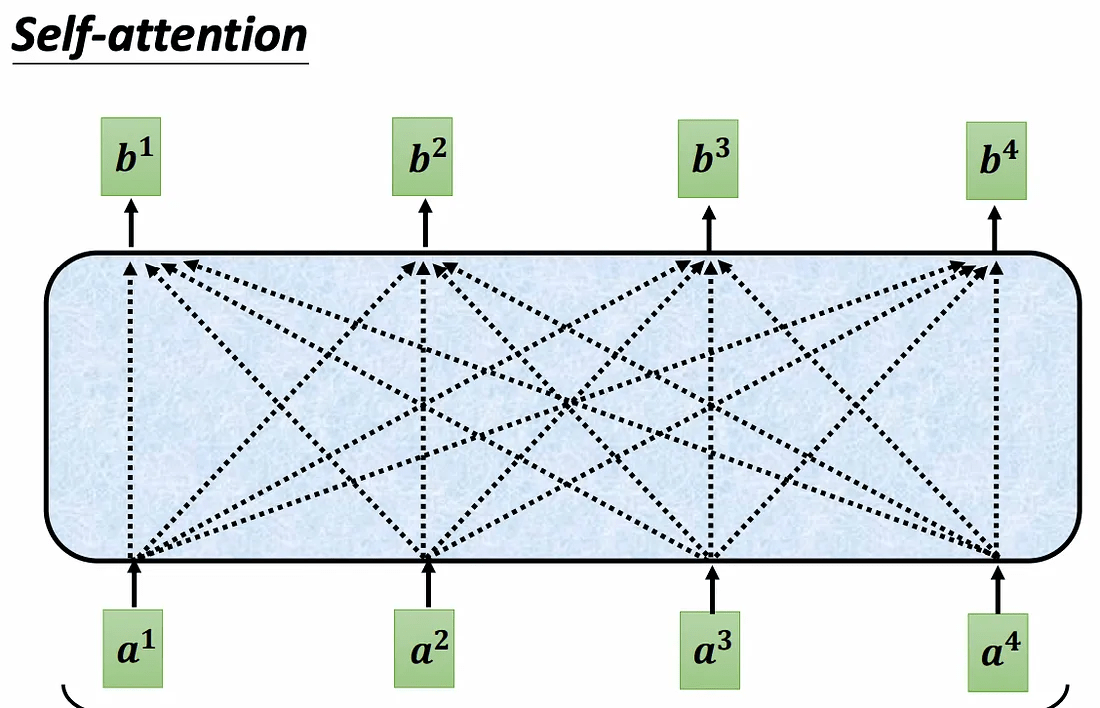
我們會對句子中每個詞跟每個詞分別做 Attention
如此一來就能計算它們的關係
這便是 Self-attetion
廢話不多說
下圖&公式
這麼做還可以優化傳統的
Seq2Seq 的一個地方
那就是他
那就是他
使傳遞的內容從單純的一個向量
變為一組向量進到 Decoder 的 Self-attention
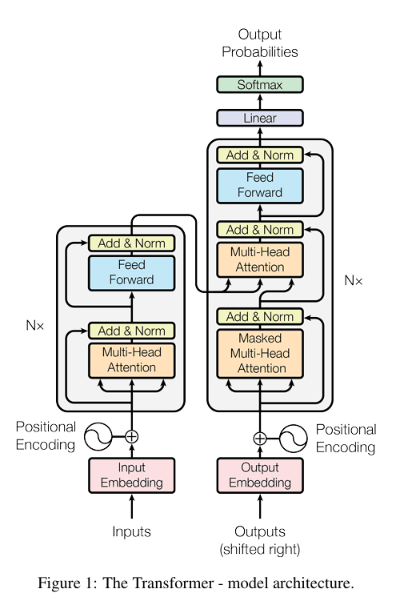
變形金剛
提供了一個完善的架構處理
各式 NLP 的問題
其中使用了 Seq2Seq 的模型
配合注意力機制
達到更高的不定長度序列處理
與維護訊息的完善性
(注意力機制也是這篇論文引入的)
也是現今幾乎所有的 LLM
背後的模型
分開部件來慢慢解釋
Encoder & Decoder 架構
這應該不用多做解釋了
Input/Output Embedding
將句子或是其他格式的輸入
轉換為向量形式
Positional Encoding
將該詞在序列內的位置
以一個向量表示
畢竟你的 Attention 沒辦法區別
在不同位置的相同向量
Positional Encoding
以這篇論文為例
他使用了這樣的方式做編碼
至於這麼做的好處可以參考
Multi-Head Attention
向神經網路一樣疊加注意力機制
稱為多頭注意力機制
(這邊是橫向的擴張)
將一個詞創造多組的QKV
做出不同的結果
之後將結果加權求和傳遞下去
Masked Multi-Head Attention
為注意力機制加上遮罩
畢竟你在 Decoder 訓練時
不能讓他從序列後面的資訊
去推前面的資訊
(先知道之後的詞那生成他沒意義)
所以會在QK^T的地方將右上做處理
使他無法利用到與後面詞語的資訊
Masked Multi-Head Attention
所以會在QK^T的地方將右上做處理
使他無法利用到與後面詞語的資訊
注:w的表示方式為\(w_{qk}\)
代表該q與該k產生的權重
Masked Multi-Head Attention
所以會在QK^T的地方將右上做處理
使他無法利用到與後面詞語的資訊
就你顯然可以發現他們後者比前者大
1<2、1<3、2<3
那代表前面詞的跟後面的詞產生的權重
將他們清零/填滿其他東西
Masked Multi-Head Attention
所以會在QK^T的地方將右上做處理
使他無法利用到與後面詞語的資訊
就你顯然可以發現他們後者比前者大
1<2、1<3、2<3
那代表前面詞的跟後面的詞產生的權重
將他們清零/填滿其他東西
理論上你們應該都會的東西
Softmax
線性變換
標準化
前饋神經網路
這邊提一下
他在標準化的地方
會與輸入的X做一次相加
防止傳遞過程梯度消失
然後它的標準化是用
Layer Normalization
如此一來你就能看懂他的架構了
import math
import torch
import torch.nn as nn
import torch.optim as optim
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
attn_probs = torch.softmax(attn_scores, dim=-1)
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
Q = self.split_heads(self.W_q(Q))
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
output = self.W_o(self.combine_heads(attn_output))
return output
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.cross_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.fc(dec_output)
return output
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")那麼問題來了
這東西該如何訓練呢?
訓練
人工智慧
機器學習
監督式學習
非監督式學習
強化學習
深度學習
監督式學習
非監督式學習
強化學習
監督式學習
非監督式學習
強化學習
我們的 Transformer 架構
能夠在不同的訓練方式下獲得不同的效益
並且是一個循序漸進的過程
讓我們一個一個來看
Pre-train
Fine-tune
RLHF
預訓練
在監督式學習中
給予模型一句合理句子
使其學習前一個詞推理到下一個詞的過程
(假設這邊的一個詞對應一個 token)
類似於我們一般在訓練神經網路時的樣子
而這東西一般人不太可能去做
畢竟動輒上億參數的 LLM
這訓練時間與需要的設備都很誇張
也因此我們通常會拿人家預訓練好的模型
去再做後面的微調等等
讓他能夠符合我們的需求
想當然沒有範例
有人要贊助電研一個TPU嗎
微調
對已經預訓練過(基本上已經具有 NLP 能力)的模型
在維持大部分舊有參數的情況下
去做調整
通常是希望讓模型能夠在某些領域能夠有更好的發揮
又或是讓他能夠吃到更適合的訓練資料
常見的幾個方法
將原有參數全數凍結
在任意位置(通常是前饋神經網路前後)
放入可被訓練的線性層
接著對他做更新
常見的幾個方法
將原有權重(預訓練的)加上微調的權重\(\Delta W_x\)
然後為了減少參數量降低訓練成本
將\(\Delta W_x\)化為兩個矩陣(A、B)相乘
如此一來就可以訓練較低的參數去修改到
原始的大量參數
基於人類回饋強化學習
RLHF
(Reinforcement Learning from Human Feedback)
名稱非常直白 也沒有什麼特別的翻譯
簡單來說
就是利用強化學習的概念
由使用者使用時給出的反饋作為 reward
讓你的模型能夠做更細微的調整
RLHF
目前不少方法都是基於 PPO 強化學習方法
去做更多的延伸
RLHF
比較常見到的實例就是
我們有時候在用 GPT 時
他會顯示兩個回覆 然後問你喜歡哪個
這就是在拿 RLHF 的人類回饋
故事是這樣的
我的電腦跑不動這個
所以就交由讀者自行練習了
from datasets import load_dataset
from trl import DPOConfig, DPOTrainer
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
model_name = "gpt2"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto")
ref_model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
dpo_config = DPOConfig(
beta=0.1,
learning_rate=5e-6,
per_device_train_batch_size=2,
num_train_epochs=1,
logging_steps=1,
max_prompt_length=64,
max_length=128,
remove_unused_columns=False
)
dpo_trainer = DPOTrainer(
model=model,
ref_model=ref_model,
args=dpo_config,
processing_class=tokenizer,
train_dataset=dataset,
)
dpo_trainer.train()
dpo_trainer.save_model(model_name)
text_generator = pipeline("text-generation", model=model_name, tokenizer=tokenizer)
while True:
user_input = input("Enter your prompt: ")
if user_input.lower() == "exit":
break
generated_text = text_generator(user_input, max_length=50, num_return_sequences=1)
print("Generated text:", generated_text[0]['generated_text'])雜項
你就算沒聽過應該也用過
簡單來說就是讓模型有查詢資料的能力
最熟悉的應該是他
給出一個讓模型掉用工具的統一標準格式
類似於 API
這樣就能讓 LLM 完成很多方便的功能
這些可以被調用的內容架在 MCP Server 上
也就是你的電腦
而 LLM 做的就是跟伺服器請求資料
他的應用有 Github、檔案控制、Browser等等
VSCode有插件可以直接體驗
一些怪怪的變體
文章
其他
By lucasw




